
文章目录
MapReduce介绍
- Hadoop MapReduce是一个分布式计算框架,用于轻松编写分布式应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)。
- MapReduce是一种面向海量数据处理的一种指导思想,也是一种用于对大规模数据进行分布式计算的编程模型,由于计算时长及效率不高,所以现在基于大数据的分布式计算框架mapreduce并不常用,但是有些软件依然依赖于mapreduce设计思想。
MapReduce特点
- 易于编程: Mapreduce框架提供了用于二次开发的接口;简单地实现一些接口,就可以完成一个分布式程序。任务计算交给计算框架去处理,将分布式程序部署到hadoop集群上运行,集群节点可以扩展到成百上千个等。
- 良好的扩展性: 当计算机资源不能得到满足的时候,可以通过增加机器来扩展它的计算能力。基于MapReduce的分布式计算得特点可以随节点数目增长保持近似于线性的增长,这个特点是MapReduce处理海量数据的关键,可以扩展为成百上千个节点很容易地处理数百TB甚至PB级别的离线数据。
- 高容错性: Hadoop集群是分布式部署的,如果任意一个节点宕机了,它可以把上面的计算任务转移到另一个节点上运行,不影响整个作业任务得完成,过程完全是由Hadoop内部完成的。
- 海量数据离线处理 TB、PB级别的海量数据。
- KV键值存储 整个MapReduce程序中,数据都是以kv键值对的形式流转的。
MapReduce缺点及局限性
- 实时计算能力差: MapReduce主要应用于离线作业,无法作到秒级或者是亚秒级的数据响应。
- 不能进行流式计算: 流式计算特点是数据是源源不断地计算,并且数据是动态的;而MapReduce作为一个离线计算框架,主要是针对的是静态数据集而数据是不能动态变化的。
MapReduce实例进程
一个完整的MapReduce程序在分布式运行时有三类
- MRAppMaster:负责整个MR程序的过程调度及状态协调。
- MapTask:负责map阶段的整个数据处理流程。
- ReduceTask:负责reduce阶段的整个数据处理流程。
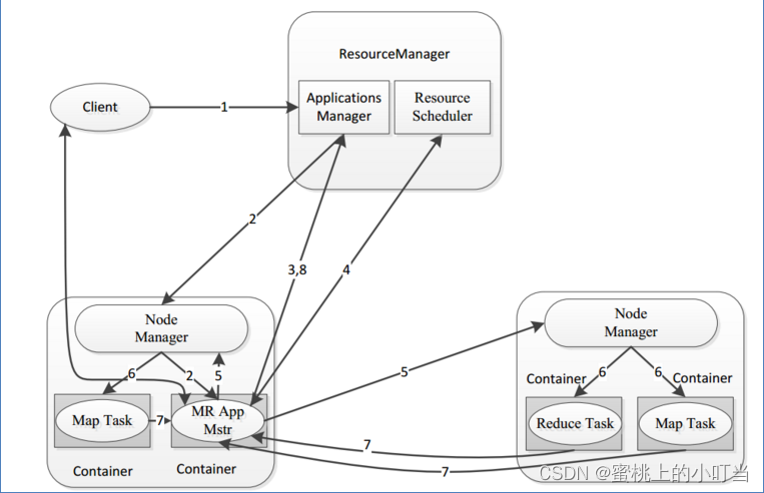
MapReduce阶段组成
- 一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段,不能有诸如多个map阶段,多个reduce阶段;如果业务逻辑复杂,只能用多个mapreduce串行运行。
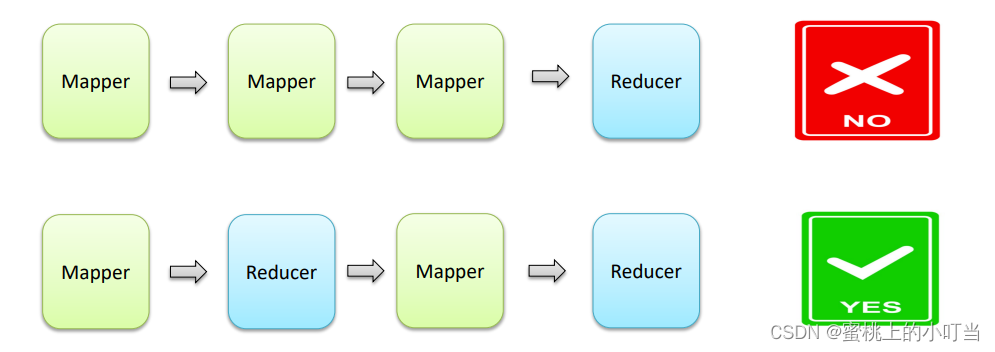
MapReduce执行流程
- MapReduce整体执行流程图
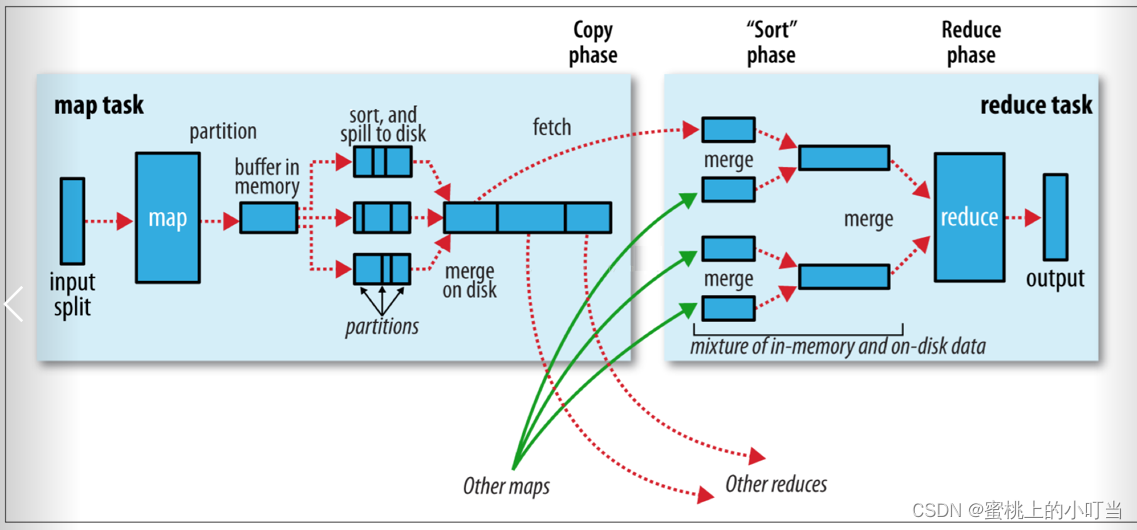
Map阶段执行流程
- 把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认Split size = Block size(128M),每一个切片由一个MapTask处理(getSplits)。
- 对切片中的数据按照一定的规则读取解析返回KV键值对。默认是按行读取数据。key是每一行的起始位置偏移量,value是本行的文本内容(TextInputFormat)。
- 调用Mapper类中的map方法处理数据。每读取解析出来的一个KV ,调用一次map方法。
- 按照一定的规则对Map输出的键值对进行分区partition。默认不分区,因为只有一个reduceTask。分区的数量就是reducetask运行的数量。
- Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候根据key进行排序sort。
- 对所有溢出文件进行最终的merge合并,成为一个文件。
Reduce阶段执行过程
- ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据。
- 把拉取来数据全部进行合并merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。
Shuffle机制
Shuffle介绍
- Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。
- 而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则洗成具有一定规则的数据,以便reduce端接收处理。
- 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。

Map端的shuffle操作
- Collect阶段:将MapTask的结果收集输出到默认大小为100M的环形缓冲区,保存之前会对key进行分区的计算,默认Hash分区。
- Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
- Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
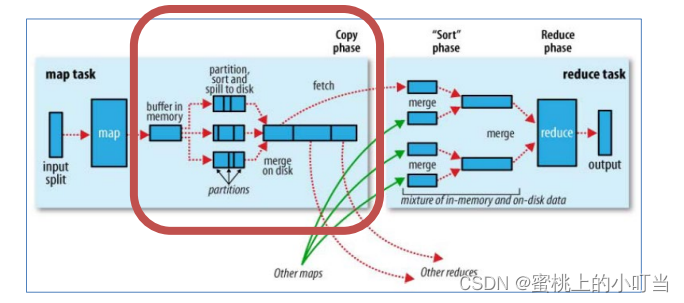
Reduce端的shuffle操作
- Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据。
- Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
- Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
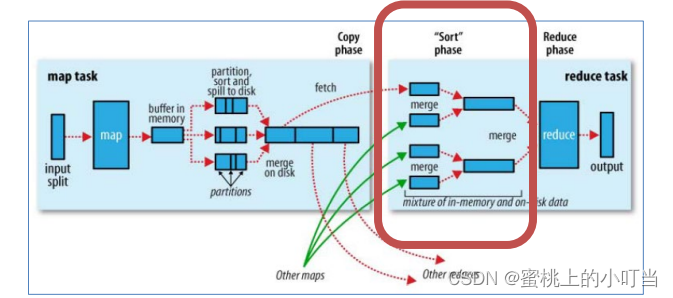
Shuffle操作的缺点
- 相比于spark flink计算引擎,计算非常缓慢,主要原因就是数据频繁的在内存和磁盘之间多次往返。
MapReduce官方示例Wordcount
- wordcount执行流程图
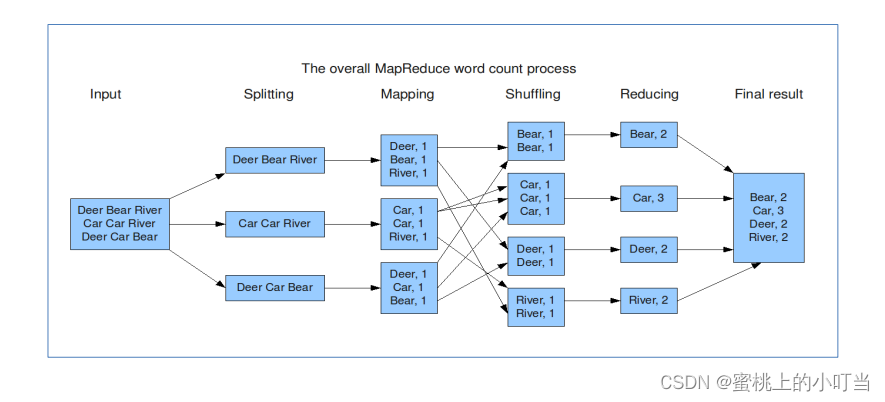
Wordcount思路
- map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。
- shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的KV键值对。
- reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,得到单词总数。
具体操作
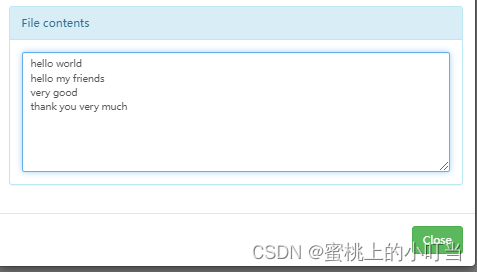
- 上传文件数据
hadoop fs -mkdir /input
hadoop fs -put abc.txt /input
2. 执行mapreduce操作
cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
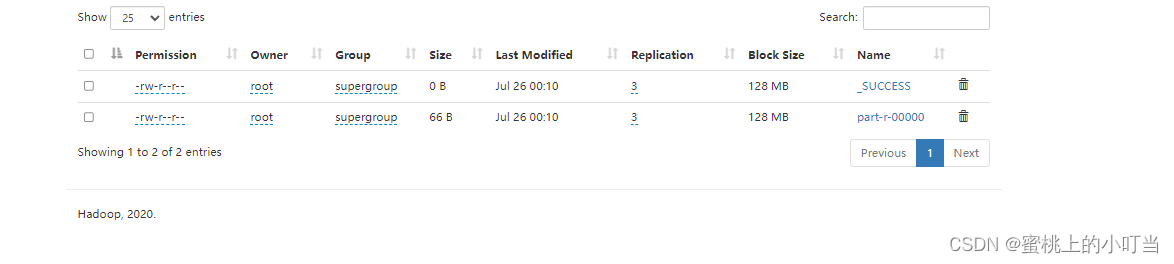
- 执行成功输出

Tips:如果出现以下报错:
Couldn't preview the file. NetworkError: Failed to execute 'send' on 'XMLHttpRequest': Failed to load 'http://node3:9864/webhdfs/v1/input/abc.txt?op=OPEN&namenoderpcaddress=node1:8020&offset=0&_=1658766058385'.
- 需要在hdfs-stie.xml文件中添加如下示例
<property><name>dfs.webhdfs.enabled</name><value>true</value></property>
- 需要在windows中的hosts文件中添加Hadoop群集的node IP。
本文转载自: https://blog.csdn.net/sinat_31854967/article/details/125985049
版权归原作者 蜜桃上的小叮当 所有, 如有侵权,请联系我们删除。
版权归原作者 蜜桃上的小叮当 所有, 如有侵权,请联系我们删除。