
在流处理的应用中,最佳的数据源是可重置偏移量的消息队列kafka;它不仅可以提供数据重放的功能,而且天生就是以流的方式存储和处理数据的。实际项目中也经常会看到以Kafka 作为数据源和写入的外部系统的应用。
具体参考详见:【Flink】如何实现端到端的一致性?_机智的小天文的博客-CSDN博客
Flink 内部
Flink 内部可以通过检查点机制保证状态和处理结果的精确一次的语义。
输入端
输入数据源端的 Kafka 可以对数据进行持久化保存,并可以重置偏移量offset。所以可以在 Source 任务中将当前读取的偏移量保存为算子状态,写入到检查点中;当发生故障时,从检查点中读取恢复状态,并由连接器向Kafka重新提交偏移量,就可以重新消费数据、保证结果至少一次的一致性。
输出端
输出端保证精确一次的最佳实现,就是两阶段提交。Flink 官方实现的 Kafka 连接器中,提供了写入到 Kafka 的 FlinkKafkaProducer,它就实现 了 TwoPhaseCommitSinkFunction 接口。也就是说,写入 Kafka 的过程实际上是一个两段式的提交:处理完毕得到结果,写入 Kafka 时是基于事务的“预提交”;等到检查点保存完毕,才会提交事务进行“正式提交”。如果中间出现故障,事务进行回滚,预提交就会被放弃;恢复状态之后,也只能恢复所有已经确认提交的操作。
具体步骤
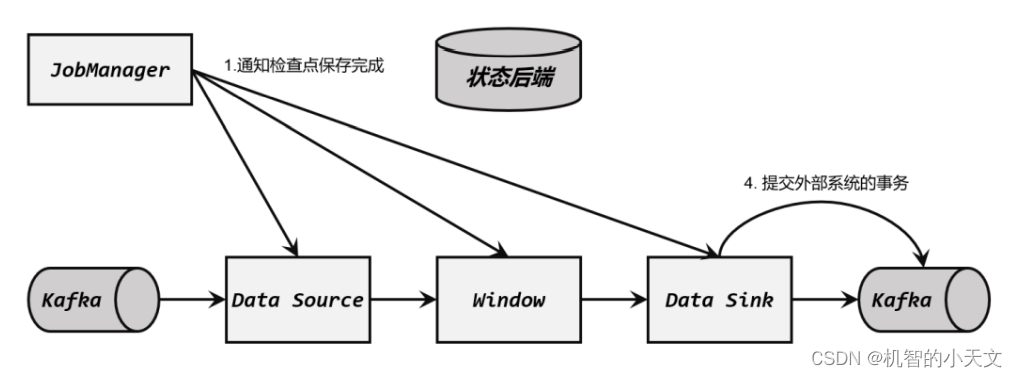
这是一个 Flink 与 Kafka 构建的完整数据管道,Source 任务从 Kafka 读取数据,经过一系列处理,然后由 Sink 任务将结果再写入 Kafka。
Flink 与 Kafka 连接的两阶段提交,离不开检查点的配合,这个过程需要 JobManager 协调各个 TaskManager 进行状态快照,而检查点具体存储位置则是由状态后端(State Backend)来配置管理的。一般情况,我们会将检查点存储到分布式文件系统上。
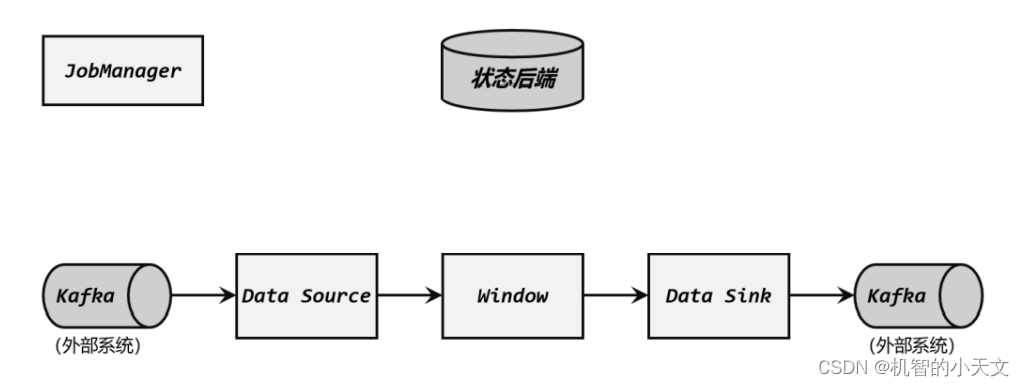
** (1)启动检查点保存**
检查点保存的启动,标志着我们进入了两阶段提交协议的“预提交”阶段。但此时现在还没有具体提交的数据。
JobManager 通知各个 TaskManager 启动检查点保存,Source 任务会将检查点分界线(barrier)注入数据流。这个 barrier 可以将数据流中的数据,分为进入当前检查点的集合和进入下一个检查点的集合。
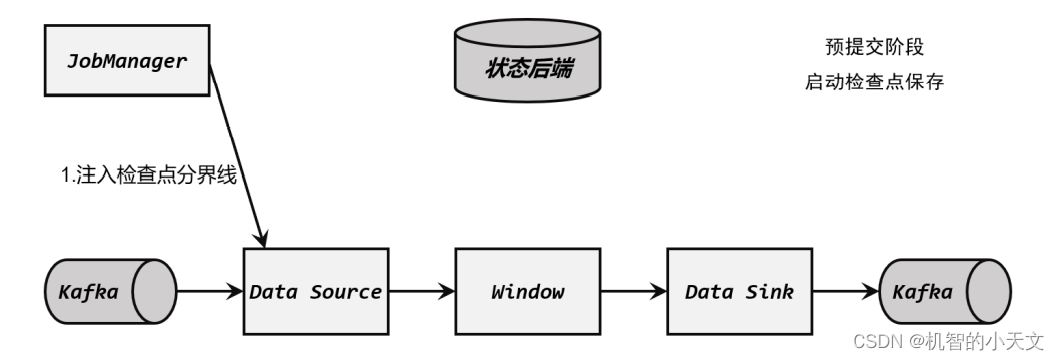
(2)算子任务对状态做快照
分界线(barrier)会在算子间传递下去。每个算子收到 barrier 时,会将当前的状态做个快 照,保存到状态后端。
Source 任务将 barrier 插入数据流后,也会将当前读取数据的偏移量作为状态写入检查点,存入状态后端;然后把 barrier 向下游传递,自己就可以继续读取数据了。 接下来 barrier 传递到了内部的 Window 算子,它同样会对自己的状态进行快照保存,写入远程的持久化存储。
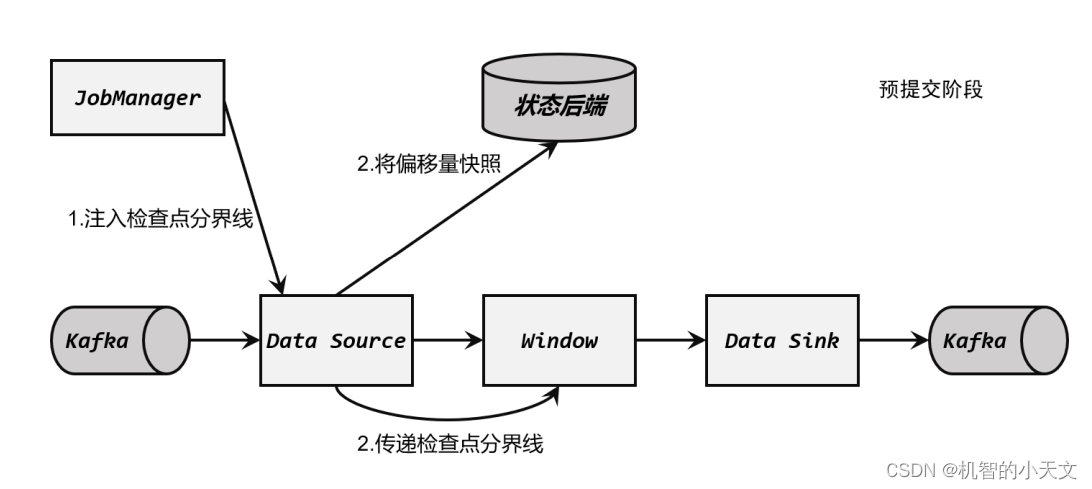
**(3)Sink 任务开启事务,进行预提交 **
分界线(barrier)终于传到了 Sink 任务,这时 Sink 任务会开启一个事务。接下来到来的所有数据,Sink 任务都会通过这个事务来写入 Kafka。这里 barrier 是检查点的分界线,也是事务的分界线。由于之前的检查点可能尚未完成,因此上一个事务也可能尚未提交;此时 barrier 的到来开启了新的事务,上一个事务尽管可能没有被提交,但也不再接收新的数据了。 对于 Kafka 而言,提交的数据会被标记为“未确认”(uncommitted)。这个过程就是所谓 的“预提交”(pre-commit)。
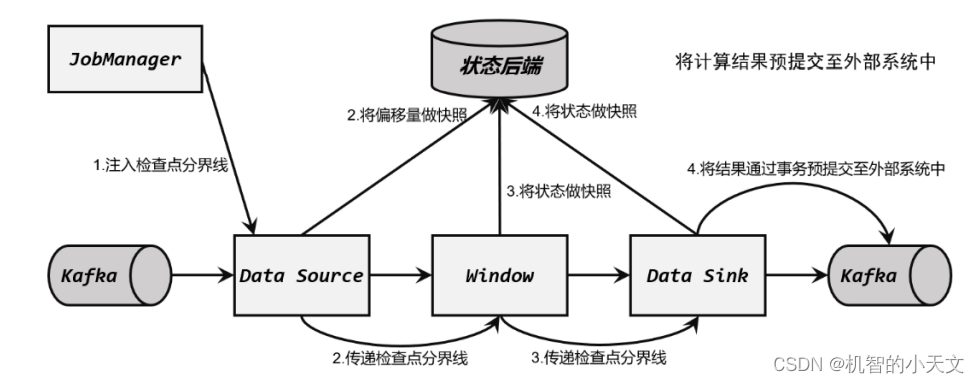
(4)检查点保存完成,提交事务
当所有算子的快照都完成,也就是这次的检查点保存最终完成时,JobManager 会向所有任务发确认通知,告诉大家当前检查点已成功保存。
当 Sink 任务收到确认通知后,就会正式提交之前的事务,把之前“未确认”的数据标为 “已确认”,接下来就可以正常消费了。 在任务运行中的任何阶段失败,都会从上一次的状态恢复,所有没有正式提交的数据也会回滚。这样,Flink 和 Kafka 连接构成的流处理系统,就实现了端到端的 exactly-once 状态一致性。
本文转载自: https://blog.csdn.net/qq_43744420/article/details/126357939
版权归原作者 甜食赛高 所有, 如有侵权,请联系我们删除。
版权归原作者 甜食赛高 所有, 如有侵权,请联系我们删除。