
流式数据湖存储技术,Apache Paimon是什么?
00 导读
2023年3月12日,
Flink Table Store
项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为
Apache Paimon (incubating)
。
Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。
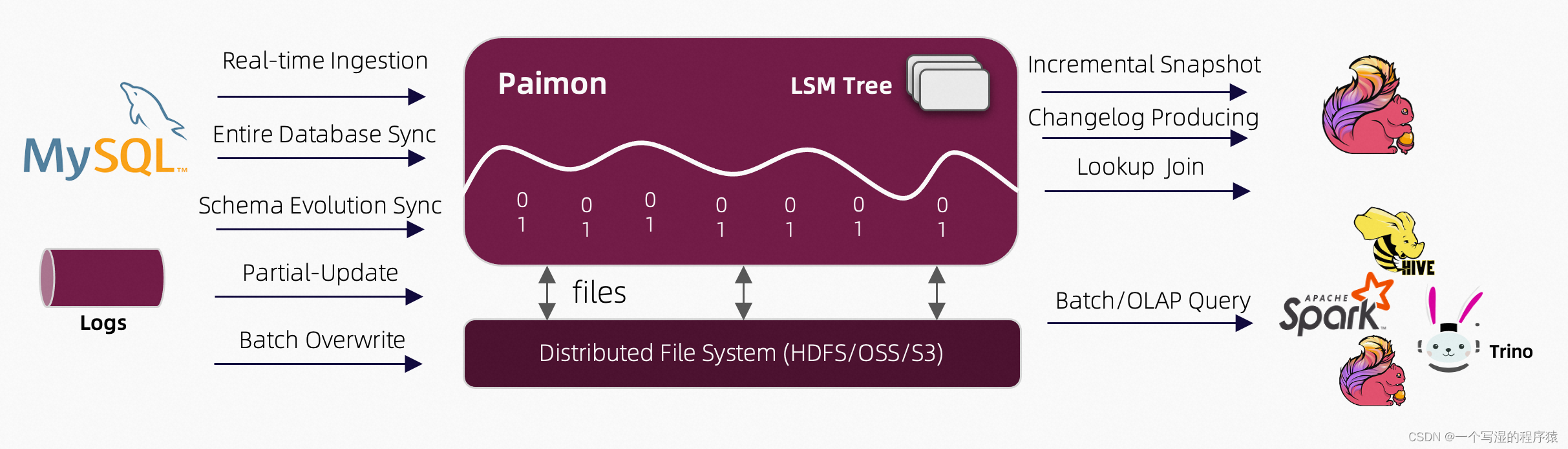
01 什么是 Apache Paimon
Apache Paimon (incubating)
是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。
Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
02 开放的数据格式
Paimon 以湖存储的方式基于分布式文件系统管理元数据,并采用开放的
ORC、Parquet、Avro
文件格式,支持各大主流计算引擎,包括
Flink、Spark、Hive、Trino、Presto
。未来会对接更多引擎,包括 Doris 和 Starrocks。
03 大规模实时更新
得益于
LSM
数据结构的追加写能力,Paimon 在大规模的更新数据输入的场景中提供了出色的性能。
Paimon 创新的结合了
湖存储 + LSM + 列式格式 (ORC, Parquet)
,为湖存储带来大规模实时更新能力,Paimon 的 LSM 的文件组织结构如下:
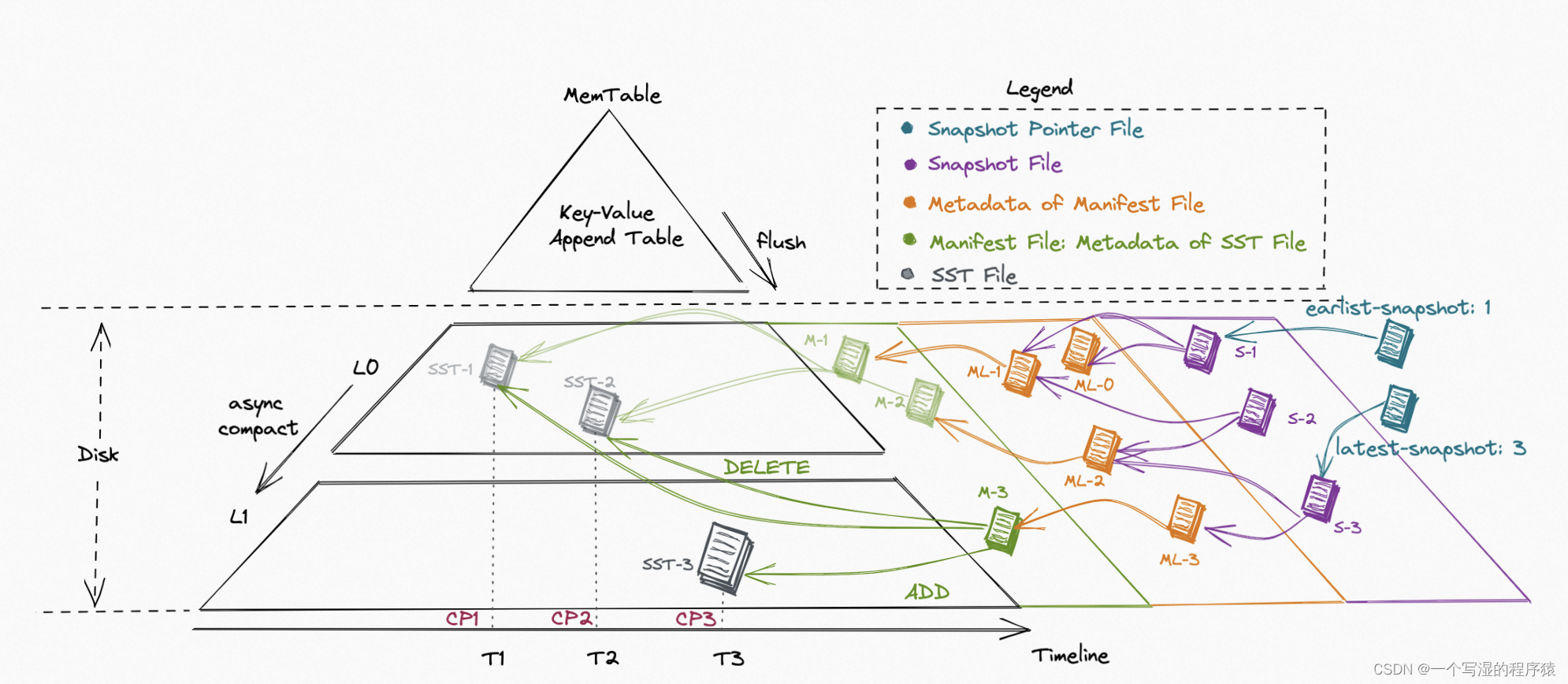
- 高性能更新:LSM 的 Minor Compaction,保障写入的性能和稳定性
- 高性能合并:LSM 的有序合并效率非常高
- 高性能查询:LSM 的 基本有序性,保障查询可以基于主键做文件的 Skipping
在最新的版本中,Paimon 集成了 Flink CDC,通过 Flink DataStream 提供了两个核心能力:
- 实时同步 Mysql 单表到 Paimon 表,并且实时将上游 Mysql 表结构(Schema)的变更同步到下游的 Paimon 表中。
- 实时同步 Mysql 整库级别的表结构和数据到 Paimon 中,同时支持表结构变更的同步,并且在同步过程中复用资源,只用少量资源,就可以同步大量的表。
通过与 Flink CDC 的整合,Paimon 可以让的业务数据简单高效的流入数据湖中。
04 数据表局部更新
在数据仓库的业务场景下,经常会用到宽表数据模型,宽表模型通常是指将业务主体相关的指标、维表、属性关联在一起的模型表,也可以泛指将多个事实表和多个维度表相关联到一起形成的宽表。
Paimon 的 Partial-Update 合并引擎可以根据相同的主键实时合并多条流,形成 Paimon 的一张大宽表,依靠 LSM 的延迟 Compaction 机制,以较低的成本完成合并。合并后的表可以提供批读和流读:
- 批读:在批读时,读时合并仍然可以完成 Projection Pushdown,提供高性能的查询。
- 流读:下游可以看到完整的、合并后的数据,而不是部分列。

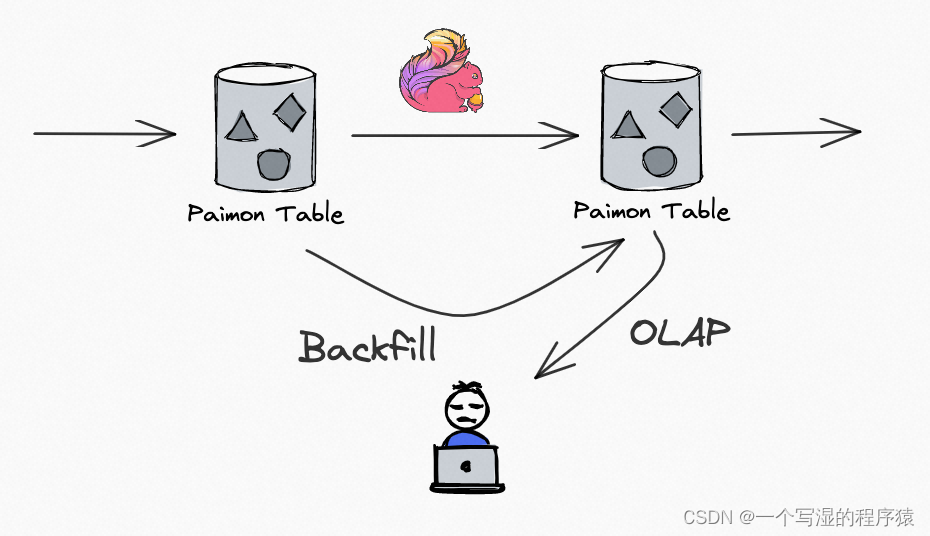
05 流批一体数据读写
Paimon 作为一个流批一体的数据湖存储,提供流写流读、批写批读,你使用 Paimon 来构建 Streaming Pipeline,并且数据沉淀到存储中。
在 Flink Streaming 作业实时更新的同时,可以 OLAP 查询各个 Paimon 表的历史和实时数据,并且也可以通过 Batch SQL,对之前的分区 Backfill,批读批写。
不管输入如何更新,或者业务要求如何合并 (比如 partial-update),使用 Paimon 的 Changelog 生成功能,总是能够在流读时获取完全正确的变更日志。
当面对主键表时,为什么你需要完整的 Changelog:
- 你的输入并不是完整的 changelog,比如丢失了 UPDATE_BEFORE (-U),比如同个主键有多条 INSERT 数据,这就会导致下游的流读聚合有问题,同个主键的多条数据应该被认为是更新,而不是重复计算。
- 当你的表是 Partial Update,下游需要看到完整的、合并后的数据,才可以正确的流处理。
你可以使用 Lookup 来实时生成 Changelog:
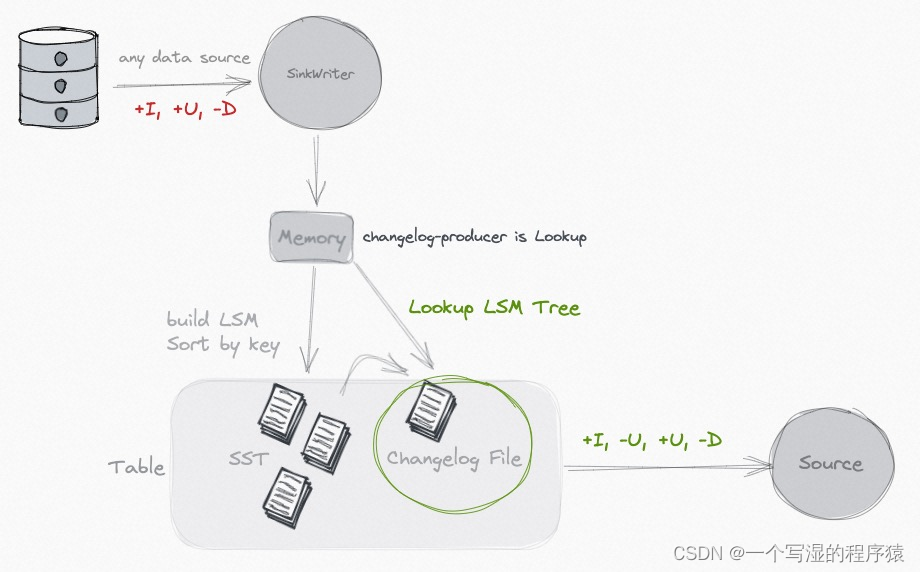
如果你觉得成本过大,你也可以解耦 Commit 和 Changelog 生成,通过 Full-Compaction 和对应较大的时延,以非常低的成本生成 Changelog。
版权归原作者 一个写湿的程序猿 所有, 如有侵权,请联系我们删除。