
目录
使用Prometheus+Grafana搭建监控系统,主要监控内容包括机器硬件资源,基础服务,应用程序,业务接口数据。
一、Promethues
Prometheus - Monitoring system & time series database
Prometheus是一个开源的服务监控系统和时间序列数据库。Prometheus生态系统由多个组件组成,包括负责数据采集和存储并提供PromQL查询语言支持的Prometheus Server,提供多语言的客户端SDK,支持临时性Job主动推送指标的中间网关Push Gateway,数据采集组件Exporter,它负责从目标处搜集数据,并将其转化为Prometheus支持的格式以及提供告警功能的Alertmanager。
Promethues Exporter组件与传统的数据采集组件不同的是它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取,prometheus提供多种类型的exporter用于采集各种不同服务的运行状态。
Promethues官网提供的生态系统架构图:
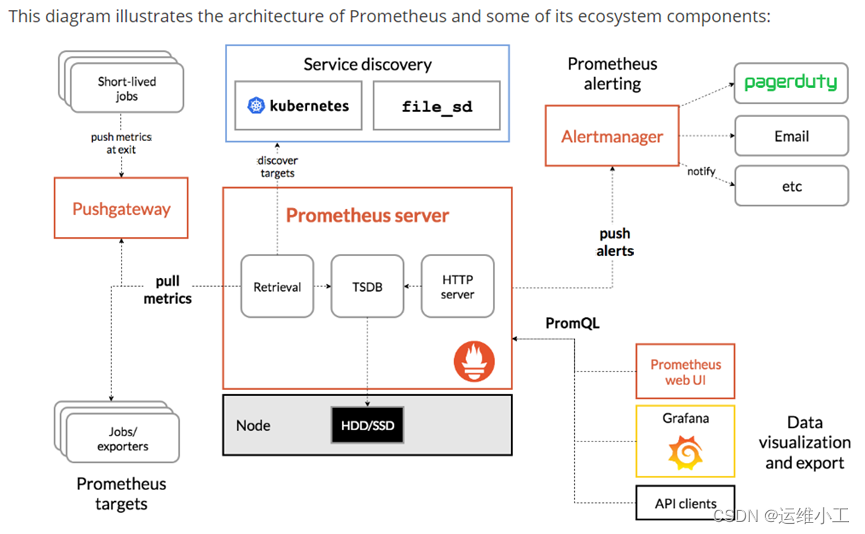
二、Grafana
Grafana: The open observability platform | Grafana Labs
Grafana是一个跨平台的开源的度量分析和可视化工具,支持从多种数据源(如prometheus)获取数据进行可视化数据展示。
三、环境准备
&&&监控服务器的硬件资源:cpu 8核、内存32G、磁盘250G、网卡。
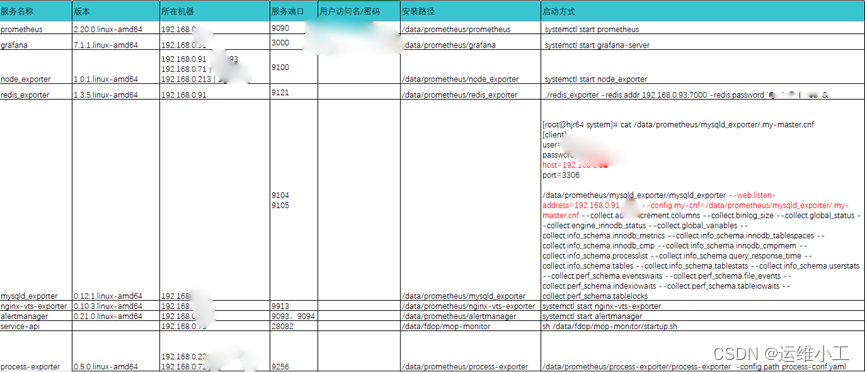
Prometheus及其它监控服务部署安排如下:
1.查看操作系统版本
[root@node64 ~]# cat /etc/redhat-release
CentOS Linux release 7.1.1503 (Core)
[root@node64 ~]# getconf LONG_BIT
64
2.查看网卡IP及配置
[root@node64 ~]# ip a
eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether fa:16:3e:a3:89:25 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.91/24 brd 192.168.0.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fea3:8925/64 scope link
valid_lft forever preferred_lft forever
[root@node64 ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth1
NAME=eth1
TYPE=Ethernet
BOOTPROTO=dhcp
DEVICE=eth1
ONBOOT=yes
IPV4_ROUTE_METRIC=100
四、安装Prometheus与Grafana
1.创建安装目录 mkir /data/prometheus
groupadd prometheus
useradd -g prometheus -s /sbin/nologin prometheus
chown -R prometheus:prometheus prometheus
2.下载prometheus,grafana安装包及prometheus插件包,
包括node_exporter、mysqld_exporter、nginx-vts-exporter、redis_exporter、alertmanager
Prometheus安装包参考如下:
Grafana安装包参考如下:
wget https://dl.grafana.com/oss/release/grafana-7.1.1.linux-amd64.tar.gz

3.解压安装
五、配置Prometheus与Grafana
1、配置prometheus
a.修改配置文件prometheus.yml
vi /data/prometheus/prometheus/prometheus.yml
scrape_configs:
metrics_path: /prometheus/metrics
static_configs:
- targets: ['192.168.0.91:9090']
b.检查配置文件
/data/prometheus/prometheus
[root@node64 prometheus]# ./promtool check config prometheus.yml
注:使prometheus配置生效 pgrep -fl prometheus
c.将prometheus注册为系统服务
[root@node64 prometheus]# cat /usr/lib/systemd/system/prometheus.service
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
User=root
ExecStart=/data/prometheus/prometheus/prometheus --web.external-url=prometheus --web.enable-admin-api --config.file=/data/prometheus/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/prometheus/data --storage.tsdb.retention=15d --log.level=info --web.enable-lifecycle
Restart=on-failure
[Install]
WantedBy=multi-user.target
d.启动并查看prometheus服务
systemctl enable prometheus
systemctl start prometheus
systemctl status prometheus
[root@node64 prometheus]# netstat -anp | grep 9090

e. nginx转发prometheus服务
Prometheus 的 Node Exporter 并没有提供任何认证支持。不过,借助 Nginx 作为反向代理服务器,我们可以很容易地为 Node Exporter 添加 HTTP Basic Auth 功能。
yum -y install httpd
[root@node23 conf]# htpasswd -c .htpasswd_prometheus Prometheus
Iampwd
location /prometheus/ {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_pass http://192.168.0.91:9090;
proxy_redirect off;
proxy_buffering off;
proxy_read_timeout 90;
proxy_send_timeout 90;
auth_basic "Prometheus";
auth_basic_user_file ".htpasswd";
}
f. web访问prometheus
https://***.com:9091/prometheus/
prometheus/Iampwd

2、配置grafana
a.修改配置文件default.ini
vi /data/prometheus/grafana/conf/defaults.ini
http_port = 3000
root_url = %(protocol)s://%(domain)s:%(http_port)s/grafana/
b.将grafana注册为系统服务
[root@node64 conf]# cat /usr/lib/systemd/system/grafana-server.service
[Unit]
Description=Grafana
After=network.target
[Service]
Type=notify
ExecStart=/data/prometheus/grafana/bin/grafana-server -homepath /data/prometheus/grafana
Restart=on-failure
[Install]
WantedBy=multi-user.target
c.启动并查看grafana服务
systemctl enable grafana-server
systemctl start grafana-server
systemctl status grafana-server
d. nginx转发grafana服务
location /grafana/ {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_pass http://192.168.0.91:3000/;
proxy_redirect off;
proxy_buffering off;
proxy_read_timeout 90;
proxy_send_timeout 90;
}
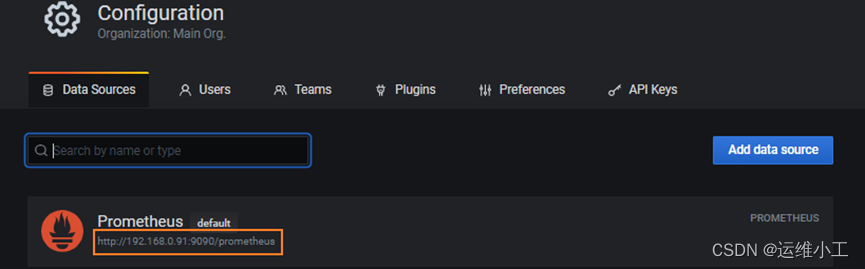
e. web访问grafana并配置数据源
https://***.com:9091/grafana/
admin/Iampwd
数据源URL: http://192.168.0.91:9090/prometheus

六、监控机器硬件资源
Prometheus使用node_exporter插件监控机器硬件资源,prometheus主动从安装了node_exporter服务的网络互通的机器上抓取所需的数据
1.在需要监控的机器上安装node_exporter
2.将node_exporter注册为系统服务
[root@node64 conf]# cat /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
ExecStart=/data/prometheus/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
3.启动并查看node_exporter服务
systemctl enable node_exporter
systemctl start node_exporter
systemctl status node_exporter
4.修改prometheus.yml并重启prometheus服务
scrape_configs:
- job_name: 'node_exporter'
static_configs:
-targets:['192.168.0.91:9100','192.168.0.92:9100'…]
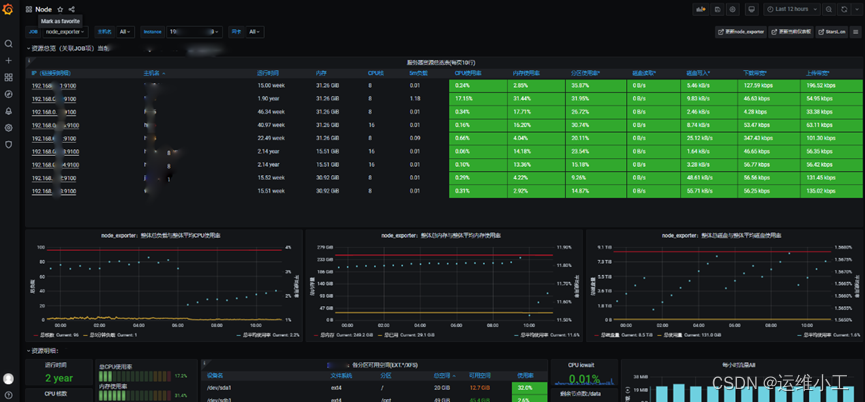
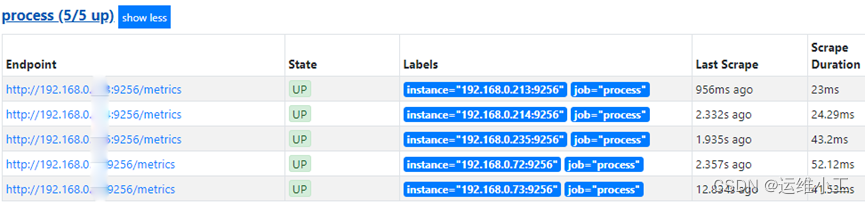
5.访问prometheus查看监控状态

6.引入grafana监控面板
Dashboards | Grafana Labs
node_exporter 8919
mysql_exporter 11323
mysql overview 7362
nginxvts 2949
redis 11835
七、监控基础服务
1、监控NGINX
Nginx通过nginx-module-vts模块获取nginx的某些指标数据, Prometheus再通过nginx-vts-exporter组件采集nginx信息。
a、在nginx服务器安装nginx-module-vts模块
- https://github.com/vozlt/nginx-module-vts ——(选择zip包下载)
- 编译安装nginx
./configure --prefix= /data/nginx --with-http_gzip_static_module --with-http_stub_status_module --with-http_ssl_module --with-pcre --with-file-aio --with-http_realip_module --add-module=/data/nginx-module-vts
make && make install
- 修改nginx.conf文件
http{
vhost_traffic_status_zone;
vhost_traffic_status_filter_by_host on;
location /status {
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}
}

b、在nginx服务器与prometheus服务器都下载安装nginx-vts-exporter插件
wget
c、在nginx服务器(192.168.0.71)将nginx-vts-exporter注册为系统服务
cat /etc/systemd/system/nginx-vts-exporter.service
[Unit]
Description=nginx_exporter
After=network.target
[Service]
Type=simple
User=root
ExecStart=/data/nginx-vts-exporter/nginx-vts-exporter -nginx.scrape_uri=https://公网IP:9091/status/format/json
Restart=on-failure
[Install]
WantedBy=multi-user.target
d、在prometheus服务器(192.168.0.91)将nginx-vts-exporter注册为系统服务
cat /etc/systemd/system/nginx-vts-exporter.service
[Unit]
Description=nginx_exporter
After=network.target
[Service]
Type=simple
User=root
ExecStart=/data/prometheus/nginx-vts-exporter/nginx-vts-exporter -nginx.scrape_uri=https://192.168.0.71:9091/status/format/json
Restart=on-failure
[Install]
WantedBy=multi-user.target
e、在nginx服务器与prometheus服务器启动并查看nginx-vts-exporter服务
systemctl enable nginx-vts-exporter
systemctl start nginx-vts-exporter
systemctl status nginx-vts-exporter
f、在prometheus服务器上修改配置文件prometheus.yml并重启prometheus服务
- job_name: 'nginx'
static_configs:
- targets: ['192.168.0.91:9913']
https://公网IP:9091/statusg、查看nginx页面监控
https://公网IP:9091/status
在grafana上导入nginx监控面板 nginx-vts-exporter 2949并查看面板
https://***.com:9091/grafana/d/5-RKCVxGk/nginx-vts-stats?orgId=1


2、监控MYSQL
Prometheus通过mysqld_exporter组件采集MySQL主从服务器的相关数据。
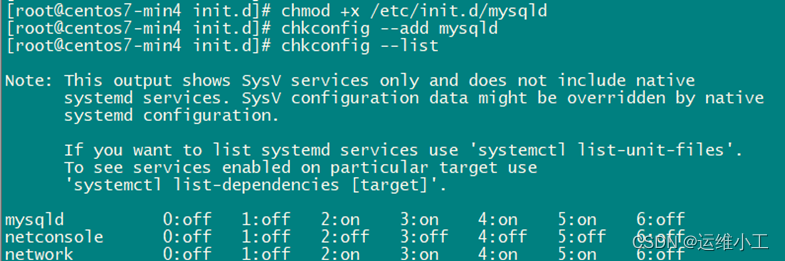
1)使用自动化脚本安装mysql后将mysql服务加入系统服务并设置开机自启
[root@centos7-min4 nginx]# cp /opt/mysql57/support-files/mysql.server /etc/rc.d/init.d/mysqld

chmod +x /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig --list
systemctl start mysqld
systemctl status mysqld

[mysql@centos7-min4 nginx]$ mysql -uroot -p —— 123456
mysql> select version();
+------------+
| version() |
+------------+
| 5.7.24-log |
2)在prometheus服务器上安装mysqld_exporter组件
prometheus监控mysql主从服务器
- 登录mysql为exporter创建账号并授权
create user 'exporter'@'192.168.0.%' identified by 'Abc123';
grant process,replication client,select on . to 'exporter'@'192.168.0.%';
flush privileges;
- 在Prometheus服务器上安装mysqld_exporter服务,同时监控mysql主从服务
ls -al /data/prometheus/mysqld_exporter/
.my-master.cnf
.my-slave.cnf
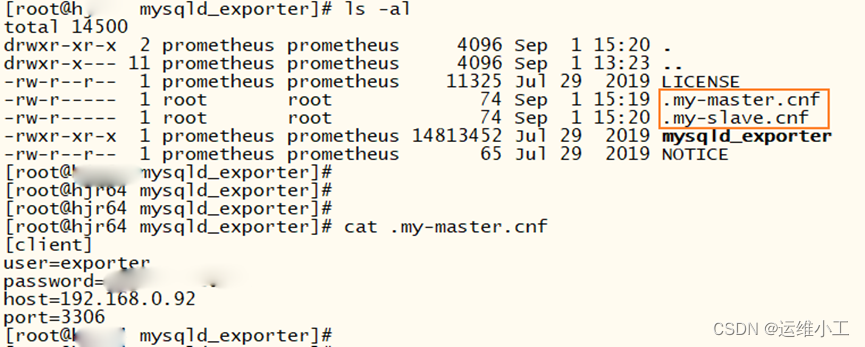
root@node64 mysqld_exporter]# cat .my-master.cnf
[client]
user=exporter
password=Abc123
host=192.168.0.92
port=3306
[root@node64 mysqld_exporter]# cat .my-slave.cnf
[client]
user=exporter
password=Abc123
host=192.168.0.93
port=3306
- 启动mysqld_exporter服务
为mysql主从服务分别启动一个服务:
Mysql主服务启动
/data/prometheus/mysqld_exporter/mysqld_exporter --web.listen-address=192.168.0.91:9104 --config.my-cnf=/data/prometheus/mysqld_exporter/.my-master.cnf --collect.auto_increment.columns --collect.binlog_size --collect.global_status --collect.engine_innodb_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.info_schema.innodb_tablespaces --collect.info_schema.innodb_cmp --collect.info_schema.innodb_cmpmem --collect.info_schema.processlist --collect.info_schema.query_response_time --collect.info_schema.tables --collect.info_schema.tablestats --collect.info_schema.userstats --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks
Mysql从服务启动
/data/prometheus/mysqld_exporter/mysqld_exporter --web.listen-address=192.168.0.91:9105 --config.my-cnf=/data/prometheus/mysqld_exporter/.my-slave.cnf
(注:其余参数请与上面Mysql主服务启动保持一致)
3)修改prometheus配置文件信息并重启prometheus
prometheus.yml
job_name: 'mysql_exporter'
static_configs:
- targets: ['192.168.0.92:9104','192.168.0.93:9104']
- labels: instance: master:3306 # grafana显示的实例的别名 - targets: - 192.168.0.91:9104 # mysqld_exporter暴露的端口 - labels: instance: slave:3306 # grafana显示的实例的别名 - targets: - 192.168.0.91:9105 # mysqld_exporter暴露的端口
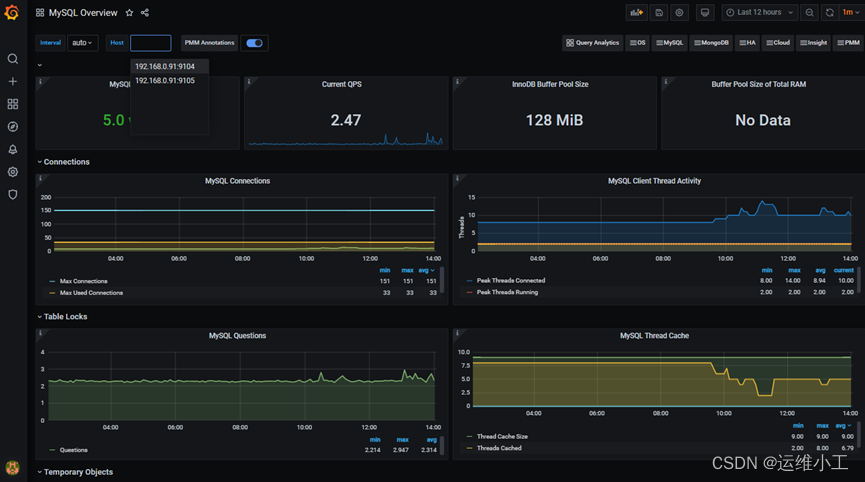
4)查看prometheus与grafana面板的mysql数据,导入mysql监控面板
mysql_exporter 11323
mysql overview 7362
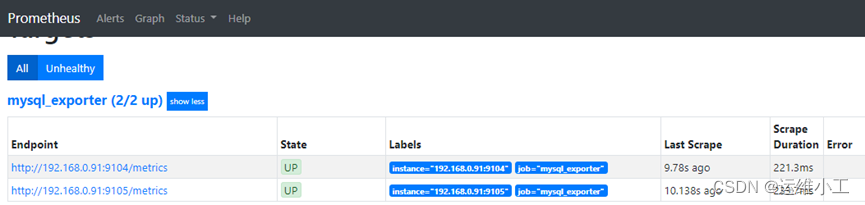
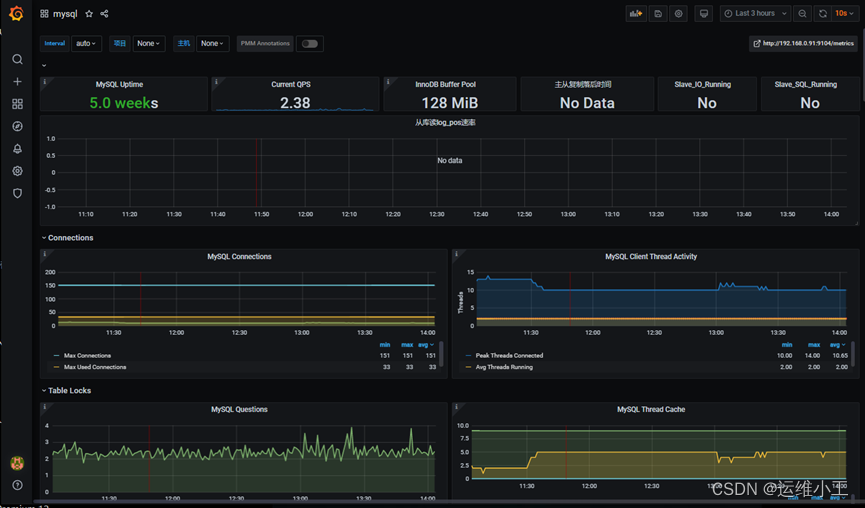

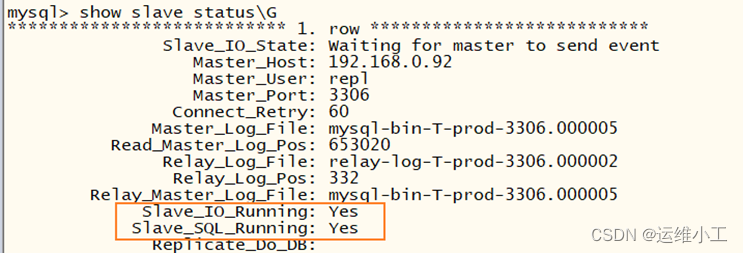
PS: mysql同步故障处理: Slave_SQL_Running: No
分析:造成mysql数据同步失败的原因
- 程序可能在slave上进行了写操作
- 可能是slave机器重启后,事务回滚造成的
处理办法:首先停掉slave服务,查看主服务器上主机状态,并根据File和Position对应的值同步到从服务器,最后启动slave服务,查看同步状态
主服务器:
mysql> show master status;

从服务器:
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql>
mysql> change master to master_host='192.168.0.92',
-> master_user='repl',
-> master_password='123456',
-> master_log_file='mysql-bin-T-prod-3306.000005',
-> master_log_pos=653020;
Query OK, 0 rows affected, 2 warnings (0.05 sec)
mysql> start slave;
3、监控 REDIS
使用redis_exporter组件监控三主三从的redis集群。
1)使用自动化脚本安装redis三主三从集群
2)在prometheus服务器下载并安装redis_exporter服务
3)监控redis集群中其中一台服务器即可监控整个已创建好的集群
cd /data/prometheus/redis_exporter
./redis_exporter -redis.addr 192.168.0.93:7000 -redis.password 'zxcvb123' &

4)修改prometheus配置文件信息并重启prometheus
job_name: 'redis_exporter_targets'
static_configs:
- targets: - redis://192.168.0.3:7000 - redis://192.168.0.2:7003 - redis://192.168.0.72:7002 - redis://192.168.0.35:7001 - redis://192.168.0.14:7004 - redis://192.168.0.13:7005metrics_path: /scrape
relabel_configs:
- source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: 192.168.0.91:9121job_name: 'redis_exporter'
static_configs:
targets:
- 192.168.0.91:9121
5)查看prometheus与grafana面板数据,导入面板redis 11835


八、监控应用程序
Prometheus使用node_exporter组件监控应用程序
1)在需要监控的应用程序服务器上安装process-exporter组件
wget
2)配置应用程序监控信息
process-conf.yml
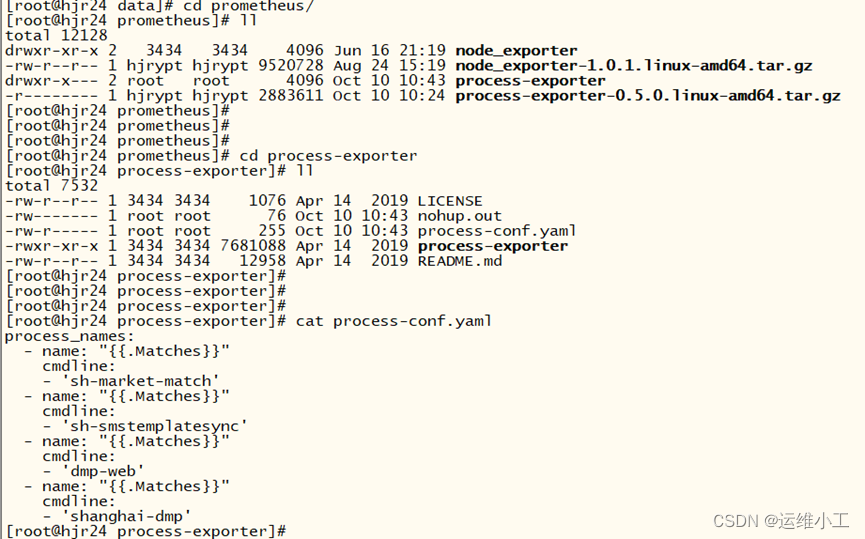
3)启动应用程序监控服务并指定配置文件
./process-exporter -config.path process-conf.yml &
4)修改prometheus配置信息并重启prometheus
[root@node64 prometheus]# vi prometheus.yml
- job_name: process
static_configs:
targets: ['192.168.0.35:9256','192.168.0.13:9256'…]
5)查看prometheus与grafana面板数据
process-exporter对应的dashboard为:Named processes | Grafana Labs

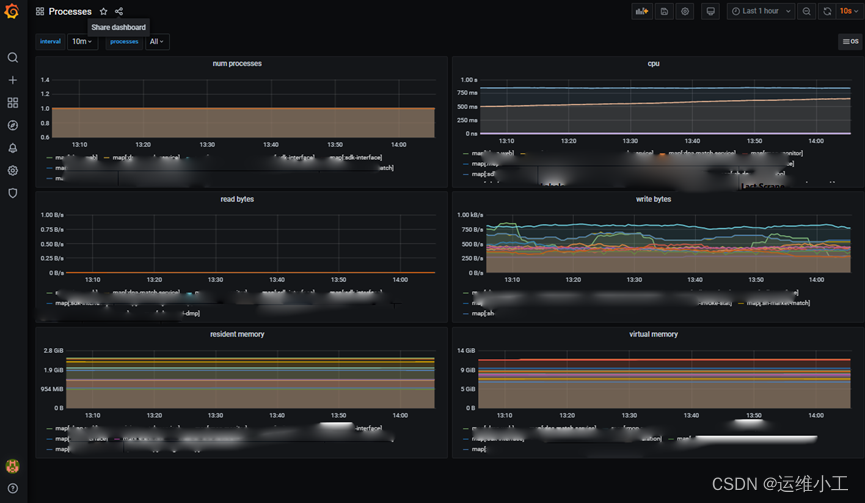
九、监控业务接口数据
根据开发提供的业务监控接口数据配置grafana数据展示。
https://***.com:9092/api
- 注意:
1.Grafana不保存普罗米修斯的数据。它查询Prometheus并显示UI。在这种情况下,您必须查看清除普罗米修斯数据。
Prometheus默认具有15天的保留期。但这可以通过-storage.local.retention标志进行调整以满足您的需求
2.prometheus会把过期数据置NaN,sum()求和函数不支持NaN,需要调整metric:
sum(st_invoke_count{app_id=~'$appid',road_type='1'}>0)
3.Grafana全局变量
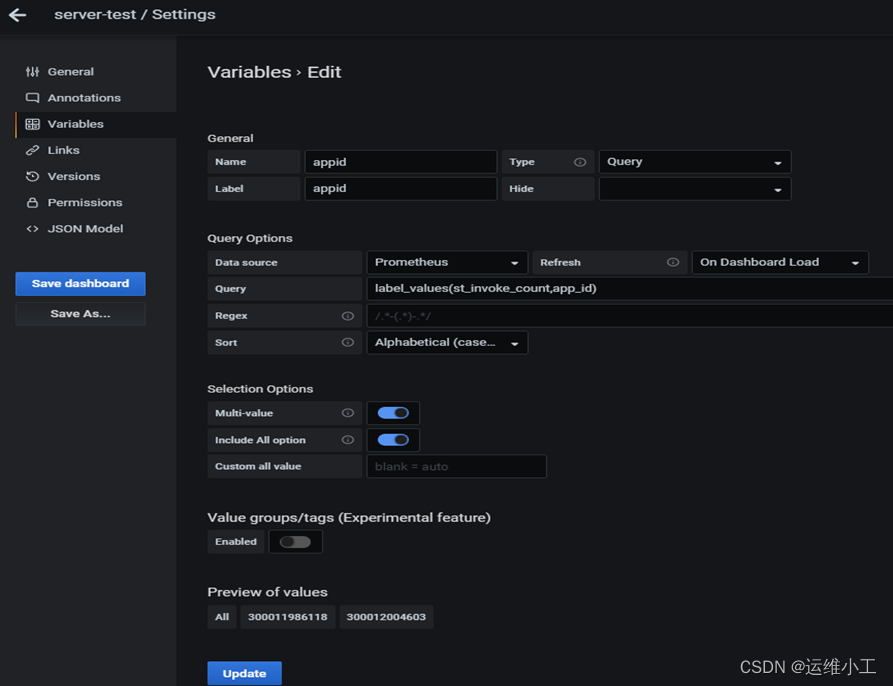
4.Grafana菜单级联
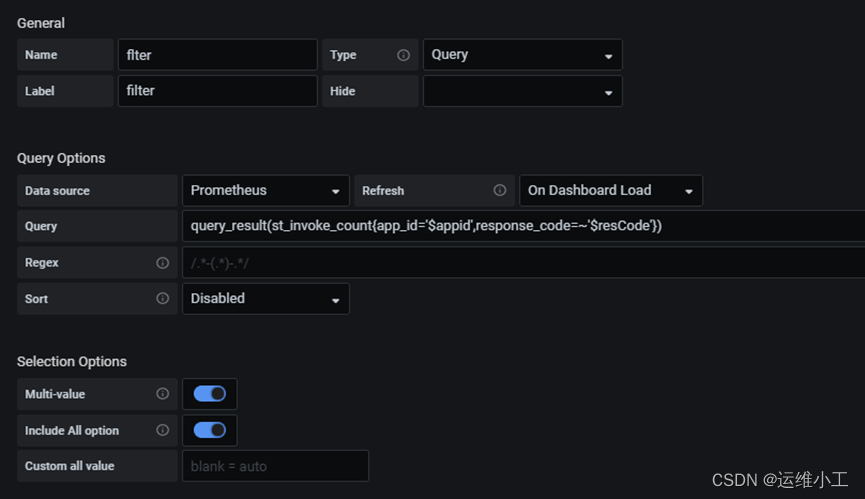
十、告警设置
1、设置告警方式
Prometheus
Prometheus通过组件alertmanager实现告警,Alertmanager接收prometheus发送的告警并对告警进行一系列的处理后发送给指定的用户。
prometheus--->触发阈值--->超出持续时间--->alertmanager--->分组|抑制|静默--->媒体类型--->邮件、钉钉、微信等。
1)安装alertmanager
2)修改alertmanager配置文件信息alertmanager.yml

3)开启smtp服务
4)配置告警通知模板
[root@centos7-min4 alertmanager-0.21.0]# cat template/test.tmpl
{{ define "test.html" }}
| 报警项 | 事项 | 报警阀值 | 开始时间 |
| {{ index $alert.Labels "alertname" }} | {{ index $alert.Labels "instance" }} | {{ index $alert.Annotations "value" }} | {{ $alert.StartsAt }} |
{{ end }}
5)启动alertmanager服务
(1)指定配置文件启动
[root@centos7-min4 alertmanager-0.21.0]# ./alertmanager --config.file=alertmanager.yml &
(2)配置成系统服务启动
[root@centos7-min4 alertmanager-0.21.0]# cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/opt/alertmanager-0.21.0/alertmanager --config.file=/opt/alertmanager-0.21.0/alertmanager.yml
[Install]
WantedBy=multi-user.target
systemctl enable alertmanager
systemctl start alertmanager
systemctl status alertmanager
6)修改prometheus配置文件并重启prometheus
Alertmanager configuration
alerting:
alertmanagers:
static_configs:
targets:
- 192.168.0.91:9093
Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/data/prometheus/rules/node.yml"
- "/data/prometheus/rules/redis.yml"
- "/data/prometheus/rules/mysql.yml"
- "/data/prometheus/rules/nginx.yml"
- "/data/prometheus/rules/service-api.yml"
Grafana
2、设置告警规则
①/data/prometheus/rules/node.yml
groups:
name: NodeProcess
rules:
alert: NodeStatus
expr: up == 0
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}:服务器宕机"
description: "{{$labels.instance}}:服务器延时超过5分钟"
alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=
"ext4|xfs"} / node_filesystem_size_bytes{fstype="ext4|xfs"} * 100) > 80for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用过高"
description: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用大于 80% (当前值: {{ $value }})"
alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 内存使用过高"
description: "{{$labels.instance}}: 内存使用大于 80% (当前值: {{ $value }})"
alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: CPU使用过高"
description: "{{$labels.instance}}: CPU使用大于 80% (当前值: {{ $value }})"
alert: LoadCPU
expr: node_load5 > 5
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 负载过高"
description: "{{$labels.instance}}: 5分钟内平均负载超过5 (当前值: {{ $value }})"
alert: DiskIORead
expr: irate(node_disk_read_bytes_total{device="sda"}[1m]) > 30000000
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: I/O读负载过高"
description: "{{$labels.instance}}: I/O 每分钟读已超过 30MB/s (当前值: {{ $value }})"
alert: DiskIOWrite
expr: irate(node_disk_written_bytes_total{device="sda"}[1m]) > 30000000
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: I/O写负载过高"
description: "{{$labels.instance}}: I/O 每分钟写已超过 30MB/s (当前值: {{ $value }})"
alert: 流入网络带宽
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.|veth.|br.|docker.|virbr*|lo*'}[5m])) by (instance)) / 100) > 18432
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于18M. RX带宽使用率{{$value}}"
alert: 流出网络带宽
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.|veth.|br.|docker.|virbr*|lo*'}[5m])) by (instance)) / 100) > 18432
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过高!"
description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于18M. RX带宽使用率{{$value}}"
alert: 网络连接数
expr: node_sockstat_TCP_inuse > 240
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.mountpoint}} 连接数过高!"
description: "{{$labels.mountpoint }}当前连接数{{$value}}"
② /data/prometheus/rules/redis.yml
groups:
name: Redis
rules:
alert: RedisDown
expr: redis_up == 0
for: 5m
labels:
severity: warning
annotations:
summary: "Redis down (instance {{ $labels.instance }})"
description: "Redis集群节点故障\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
alert: OutOfMemory
expr: redis_memory_used_bytes / redis_total_system_memory_bytes * 100 > 90
for: 5m
labels:
severity: warning
annotations:
summary: "Out of memory (instance {{ $labels.instance }})"
description: "Redis is running out of memory (> 90%)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
alert: ReplicationBroken
expr: delta(redis_connected_slaves[1m]) < 0
for: 5m
labels:
severity: warning
annotations:
summary: "Replication broken (instance {{ $labels.instance }})"
description: "Redis instance lost a slave\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
alert: TooManyConnections
expr: redis_connected_clients > 1000
for: 5m
labels:
severity: warning
annotations:
summary: "Too many connections (instance {{ $labels.instance }})"
description: "Redis instance has too many connections\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
alert: RejectedConnections
expr: increase(redis_rejected_connections_total[1m]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: "Rejected connections (instance {{ $labels.instance }})"
description: "Some connections to Redis has been rejected\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
alert: AofSaveStatus
expr: redis_aof_last_bgrewrite_status < 1
for: 5m
lables:
serverity: warning
annotations:
summary: "Missing backup (instance {{ $labels.instance }})"
description: "Redis AOF persistence failed\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
③/data/prometheus/rules/mysql.yml
groups:
- name: MySQL
rules:
- alert: MySQL Status
expr: mysql_up == 0
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: MySQL has stop !!!"
description: "检测MySQL数据库运行状态"
- alert: MySQL Slave IO Thread Status
expr: mysql_slave_status_slave_io_running != 1
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: MySQL Slave IO Thread has stop !!!"
description: "检测MySQL主从IO线程运行状态"
- alert: MySQL Slave SQL Thread Status
expr: mysql_slave_status_slave_sql_running != 1
for: 5s
labels:
severity: warning
annotations:
summary: '{{$labels.instance}}: MySQL Slave SQL Thread has stop !!!'
description: "检测MySQL主从SQL线程运行状态"
- alert: MySQL Slave Delay Status
expr: mysql_slave_status_sql_delay == 30
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: MySQL Slave Delay has more than 30s !!!"
description: "检测MySQL主从延时状态"
- alert: Mysql_Too_Many_Connections
expr: rate(mysql_global_status_threads_connected[5m]) > 200
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 连接数过多"
description: "{{$labels.instance}}: 连接数过多,请处理 ,(current value is: {{ $value }})"
④/data/prometheus/rules/nginx.yml
groups:
name: nginx
rules:
alert: Nginx Status
expr: up{instance="192.168.0.91:9913",job="nginx"} == 0
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: Nginx has stop !!!"
description: "检测Nginx运行状态异常"
版权归原作者 运维小工 所有, 如有侵权,请联系我们删除。