
“ Hadoop在大数据的应用可以说是非常广泛,国产大数据平台中很多也是引用了Hadoop大数据的技术框架。了解hadoop对于学习大数据技术是一个非常基础的要求和前提条件。"

Hadoop简介
Hadoop是一个开源的分布式存储和计算框架,最初由Apache软件基金会开发。它的发展背景可以追溯到Google的MapReduce和Google File System(GFS)的论文,这两篇论文启发了Hadoop的设计。Hadoop的主要应用场景包括大数据存储、处理和分析,特别是在需要处理海量数据的互联网和企业环境中。它被广泛用于日志分析、数据挖掘、机器学习、图像处理等领域。Hadoop的生态系统还包括许多相关项目,如Hive、HBase、Spark等,为大数据处理提供了丰富的工具和技术。
虽然当前提出hadoop的缺点以及弊端,但是当前hadoop的全功能性还是能解决大型项目的大多数问题。学习hadoop变较为必要。
分布式存储(HDFS):
Hadoop Distributed File System(HDFS)是Hadoop的分布式存储系统,它将大数据集分割成小块并在多个节点上进行分布式存储,提供高可靠性和容错性。
分布式计算(MapReduce):
Hadoop使用MapReduce编程模型,将任务分解成Map和Reduce两个阶段,实现对大规模数据的并行处理,从而加速数据分析和处理过程。
YARN(资源管理):
Yet Another Resource Negotiator(YARN)是Hadoop的资源管理系统,负责集群中资源的调度和管理,支持多个应用程序共享集群资源,提高资源利用率。
数据存储:
大文件被切分为小块,并在集群中的多个节点上进行分布式存储,每个数据块默认被复制到多个节点以提高容错性。
MapReduce计算:
用户定义Map和Reduce任务,Map任务对输入数据进行处理生成键值对,Reduce任务对Map输出进行聚合和汇总。
分布式计算:
MapReduce框架将任务分发到集群中的多个节点,节点间通过网络传输数据和中间结果,实现并行处理。
Hadoop被设计用于处理PB级别的数据,为企业提供了高度可扩展的解决方案。Hadoop生态系统包括Hive、Pig、HBase等工具,为不同的数据处理需求提供了全面的解决方案。很多企业在构建大数据基础设施时选择Hadoop,用于存储、处理和分析海量数据,支持智能决策制定。Hadoop能够无缝集成到主流云计算平台,提供灵活的大数据处理解决方案,使其在云端环境中得到广泛应用。大多数云服务厂商底层框架还是hadoop的框架。
系统基础配置
在安装集群之前,对于各个节点之间的ssh免密登录、IP映射、时钟同步等相关的基础配置调整。
ip/hostname映射(所有节点)
为方便集群节点之间通过hostname相互通信,在hosts文件中分别为每个节点配置hostname与IP之间的映射关系,具体操作如下所示。
vim /etc/hosts
加入以下信息
10.0.0.105 vm05
10.0.0.106 vm06
10.0.0.107 vm07
时钟同步
集群对节点的时间同步要求比较高,要求各个节点的系统 时间不能相差太多,否则会造成很多问题,比如最常见的连接超时问题。所以需要集群节点的系统时间与互联网时间保持同步,但是在实际生产环境中,集群中大部分节点是不能连接外网的,这时可以在内网搭建一个自己的时钟服务器(如NTP服务器),然后让ZK集群的 各个节点与此时钟服务器的时间保持同步。
查看所有节点时间
date

检查NTP服务是否已经安装。
rpm -qa|grep ntp
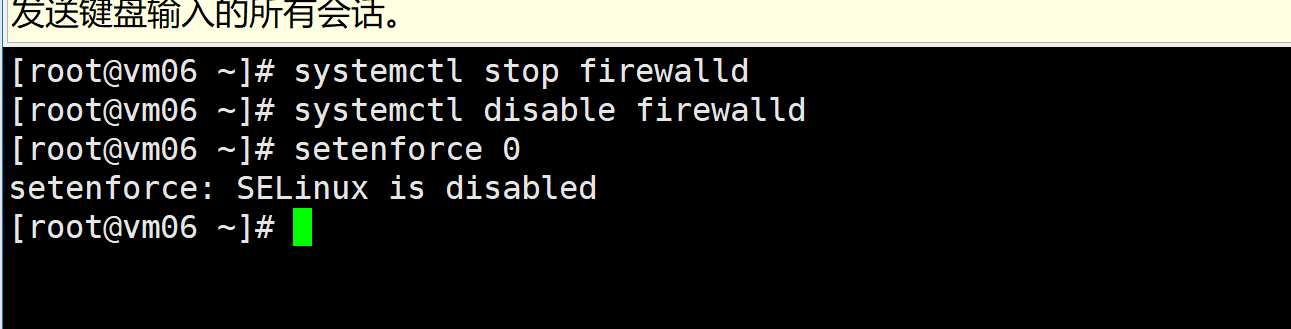
关闭防火墙、seliunx(所有节点同步)
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
安装ntp工具(所有节点同步)
yum install -y ntp
在内网情况下自行导入rpm包
选择vm06节点来配置NTP服务器,集群其他节点定时同步vm06节点时间即可。
更改时间服务器配置(所有节点同步)
vim /etc/ntp.conf
注释一下内容
#restrict default nomodify notrap nopeer noquery
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
对于以上得解释
#restrict default nomodify notrap nopeer noquery:
restrict 是用来限制对 NTP 服务器的访问权限的指令。
default 表示这个限制是针对默认的访问权限。
nomodify 表示不允许修改服务器上的时间设置。
notrap 表示不允许使用 trap 服务,这是一种用于远程管理和监视的 NTP 服务。
nopeer 表示不允许与其他 NTP 对等服务器进行对等通信。
noquery 表示不允许查询服务器的状态信息。
#server 0.centos.pool.ntp.org iburst:
server 是用来指定 NTP 服务器的指令。
0.centos.pool.ntp.org 是一个 NTP 服务器的主机名或者 IP 地址,这里以 0.centos.pool.ntp.org 为例。
iburst 表示使用快速启动(initial burst)方式与服务器同步时间。
#server 1.centos.pool.ntp.org iburst、#server 2.centos.pool.ntp.org iburst、#server 3.centos.pool.ntp.org iburst:
类似于第二条注释,这里列出了另外三个 NTP 服务器的主机名或者 IP 地址,用来作为备用的时间服务器。
开启ntpdate服务(所有节点同步)
systemctl start ntpdate
systemctl enable ntpdate
systemctl status ntpdate
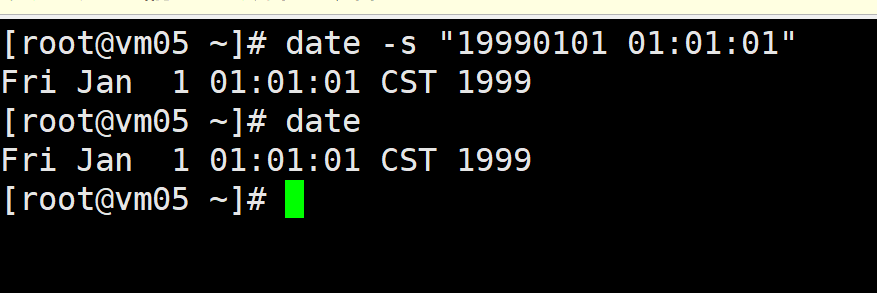
将vm05、vm07 时间进行更改一遍后面测试验证
date -s "19990101 01:01:01"
date
设置定时同步任务(vm05、vm07)
crontab -e
每分钟同步一次vm06得时间
*/1 * * * * /usr/sbin/ntpdate -u 10.0.0.106
每分钟执行一次 /usr/sbin/ntpdate -u 10.0.0.106 命令,以同步系统时间与指定的 NTP 服务器。一分钟之后使用date指令进行查看时间同步情况。
jdk安装
1)下载JDK。
登录Oracle官网,进行下载安装包jdk-8u391-linux-x64.tar.gz
上传到其中一个节点再使用SCP分发到其他节点中去
scp jdk-8u391-linux-x64.tar.gz root@vm05:/root
scp jdk-8u391-linux-x64.tar.gz root@vm07:/root
2)解压JDK。
使用tar命令对jdk-8u51-linux-x64.tar.gz安装包进行解压,详细操作如下所示。
tar -zxf jdk-8u391-linux-x64.tar.gz
迁移到根下
[root@vm06 ~]# mv jdk1.8.0_391/ /jdk
[root@vm06 ~]# cd /jdk
[root@vm06 jdk]# pwd
/jdk
配置环境变量
vim /etc/profile
###加入以下内容
export JAVA_HOME=/jdk/
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
退出保存后加载环境变量
source /etc/profile
验证
java -version

zookeepeer安装
创建hadoop 用户和用户组
groupadd hadoop
useradd hadoop -g hadoop
##为Hadoop设置密码
passwd hadoop
设置sudo 权限
visudo
找到一下行
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
在添加以下用户
hadoop ALL=(ALL) NOPASSWD:ALL
切换到hadoop用下下载zookeeper 安装包,进入
zookeeper官网,选择
注意:安装有名称有带bin 和不带bin的,选择带bin的会自带有依赖的JAR包,不选带BIN没有配置标准的JDK包 会导致ZK启动失败 Error contacting service. It is probably not running. 的报错。本文虽然配置环境变量CLASSPATH
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
避免读者在实操过程中出现问题依然使用带bin的安装进行演示,此时ZK启动会优先从自带lib查找依赖包
使用wget下载zookeeper压缩包
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.1/apache-zookeeper-3.9.1-bin.tar.gz --no-check-certificate
解压zookeeper,并设置软连接方便后期版本升级替换
tar -zxf apache-zookeeper-3.9.1-bin.tar.gz
ln -s apache-zookeeper-3.9.1-bin zookeeper
编辑zoo.cfg配置文件
这个配置文件默认选择命名为zoo.cfg,并保存在conf子目录中,配置文件的具体内容如下所示.安装包给出了模板配置文件zoo_sample.cfg
cd zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
zoo.cfg中编辑如以下内容
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#日志目录
dataLogDir=/home/hadoop/zookeeper/zklog
#数据目录
dataDir=/home/hadoop/zookeeper/zkdata
# the port at which the clients will connect
#访问ZK的默认端口号
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
#server.节点编号=对应节点的hostname:集群通讯端口:选举端口
server.1=vm05:2888:3888
server.2=vm06:2888:3888
server.3=vm07:2888:3888
该文件中除了配置server编号外 还有几个参数,以下做解释。
·tickTime=2000:这是ZooKeeper服务器的时间单位,以毫秒为单位。此值决定了ZooKeeper服务器中的时间,以及各种超时和会话时间。默认值是2000毫秒(2秒)。
·initLimit=10:这是ZooKeeper服务器初始化时等待客户端完成连接的时间限制(以tickTime为单位)。如果在该时间内没有足够数量的客户端连接到服务器,那么服务器将关闭。默认值是10。
·syncLimit=5:这是ZooKeeper服务器同步其数据给其他服务器的时间限制(以tickTime为单位)。如果在该时间内没有完成数据同步,那么同步将被中止。默认值是5。
·dataLogDir=/home/hadoop/zookeeper/zklog:这是ZooKeeper服务器存储其数据日志的目录。数据日志包含服务器状态的持久化信息。
·dataDir=/home/hadoop/zookeeper/zkdata:这是ZooKeeper服务器存储其数据的目录。数据包含诸如配置文件、事务日志和快照等的信息。
·clientPort=2181:这是ZooKeeper服务器监听的客户端连接端口。默认情况下,ZooKeeper在端口2181上监听来自客户端的连接请求。
创建zookeeper数据目录和日志目录
mkdir -p /home/hadoop/zookeeper/zklog
mkdir -p /home/hadoop/zookeeper/zkdata
创建zookeeper服务编号
cd /home/hadoop/zookeeper/zkdata
rm -rf myid
touch myid
echo "2">myid
cat myid
注意:这里得编号需要和zoo.cfg中配置得
server.1=vm05:2888:3888
server.2=vm06:2888:3888
server.3=vm07:2888:3888
服务编号一一对应
编辑环境变量
cd /home/hadoop
vim .bash_profile
加入以下环境信息
source /etc/profile
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
加载环境变量
source .bash_profile
启动zookeeper
zkServer.sh start
zkServer.sh status

配置SSH免密登录
首先在控制台,使用su命令切换到hadoop用户,具体操作下图所示。在hadoop用户的根目录下使用mkdir命令创建.ssh目录,使用命令ssh-keygen-t rsa(ssh-keygen是秘钥生成器,-t是一个参数,rsa是一种加密算法)生成秘钥对(即公钥文件id_rsa.pub和私钥文件id_rsa),
su - hadoop
mkdir -p .ssh
ssh-keygen -t rsa
cd .ssh
cp id_rsa.pub authorized_keys
cat authorized_keys
将每个节点的 authorized_keys 密钥内容汇总到一起, 然后分发到每个节点中去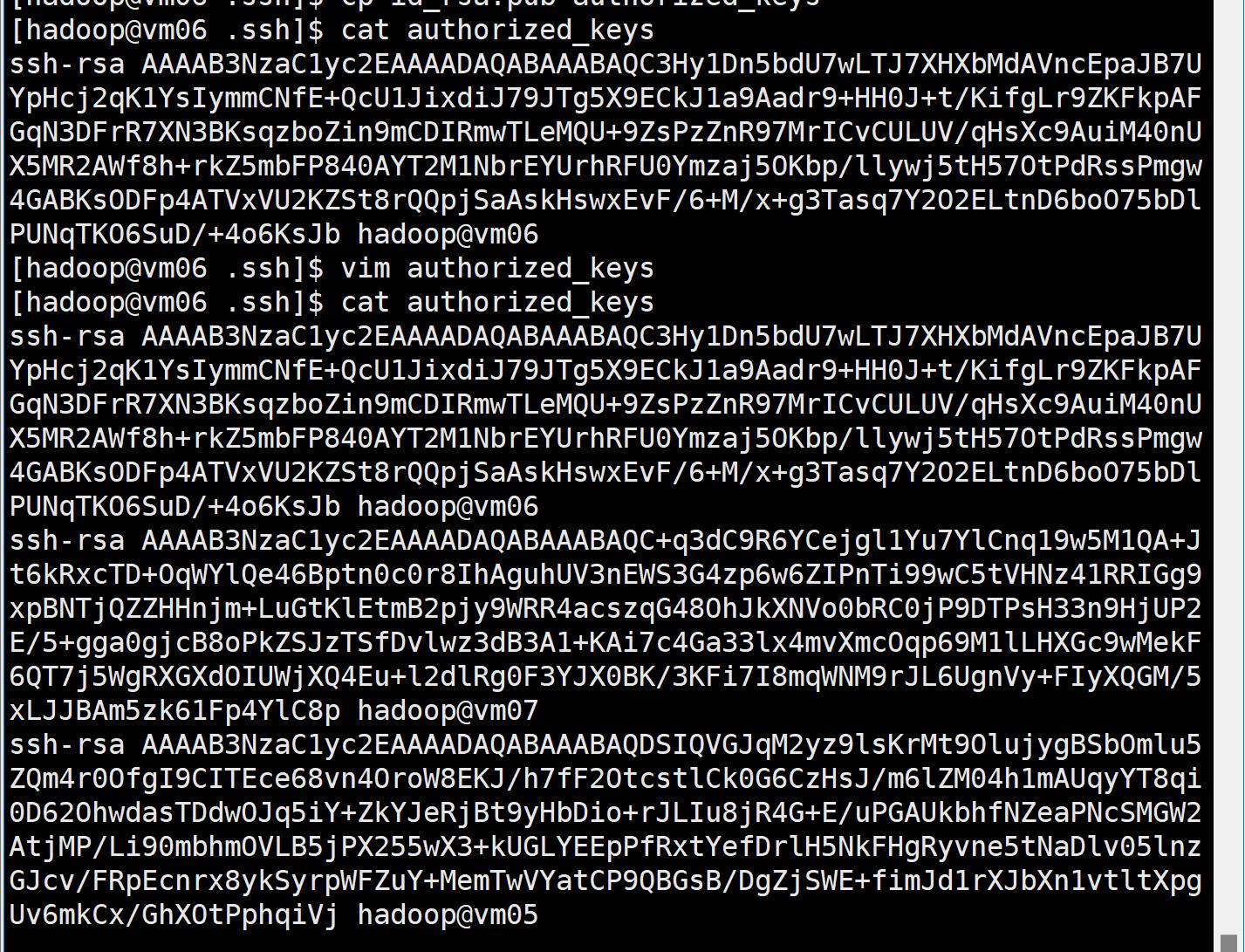
为.ssh授权
[hadoop@vm06 .ssh]$ cd
[hadoop@vm06 ~]$ chmod 700 .ssh/
[hadoop@vm06 ~]$ chmod 600 .ssh/*
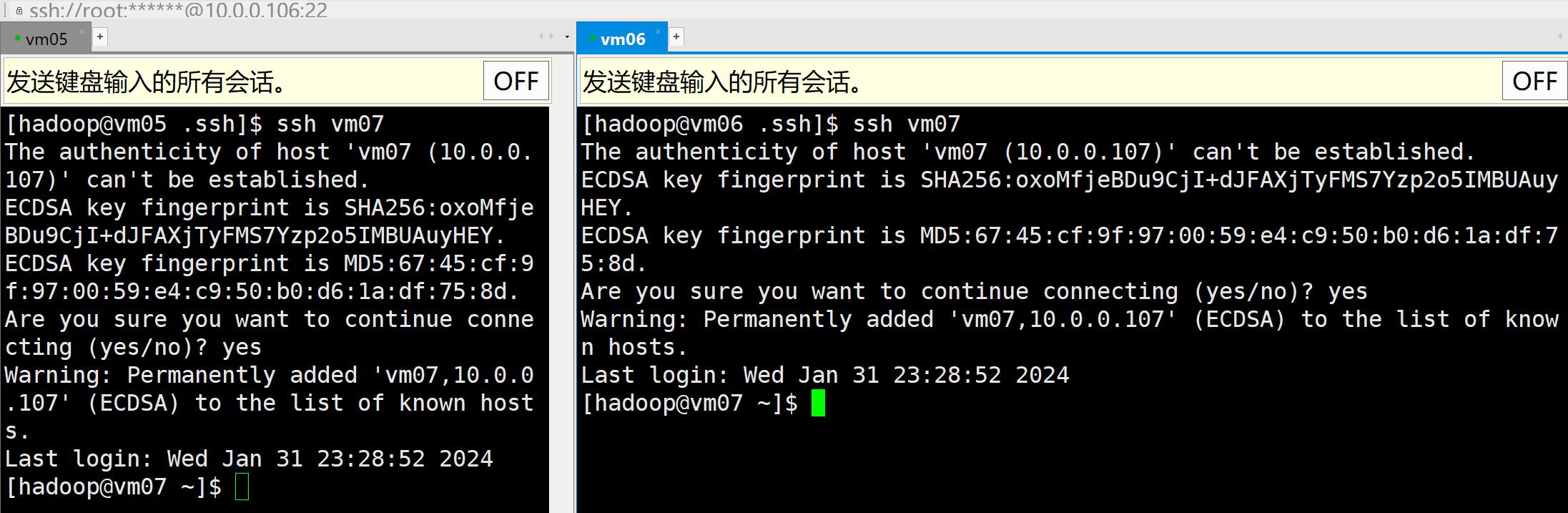
ssh 登录其他节点测试,首次登录到其他节点需要“yes”确认
ssh vm07
安装Hadoop
进入hadoop官网下载hadoop-3.3.6.tar.gz程序包
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz --no-check-certificate
解压压缩包,并设置软连接
tar -zxf hadoop-3.3.6.tar.gz
ln -s hadoop-3.3.6 hadoop
hadoop-env.sh配置
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
添加JAVA_HOME的路径。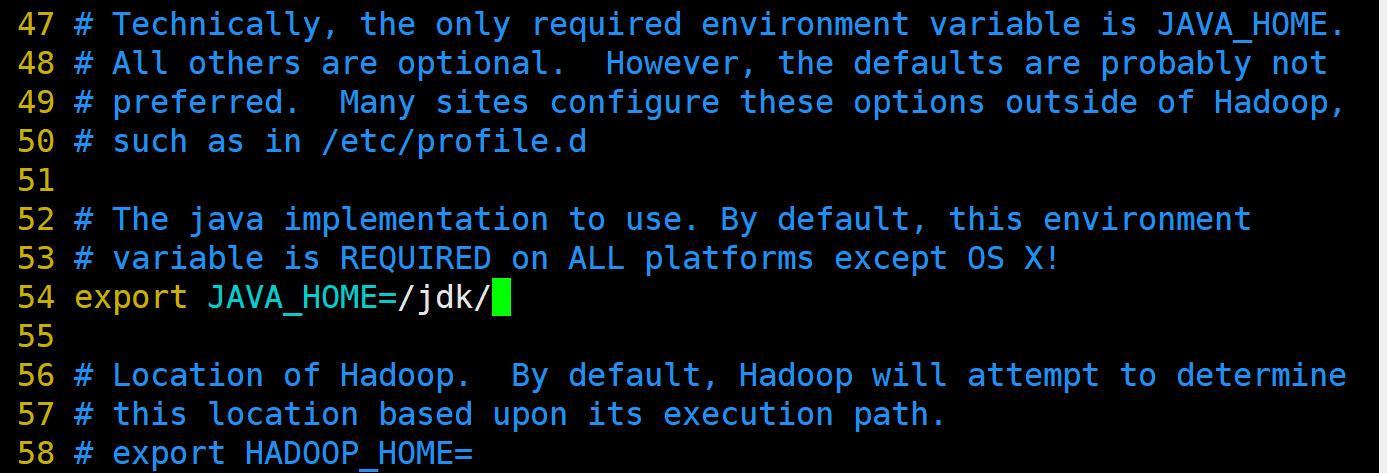
core-site.xml配置
加入以下信息
<!-- core-site.xml -->
<configuration>
<!-- 指定Hadoop文件系统的默认块大小 -->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- 指定Hadoop文件系统的默认副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data</value>
</property>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 配置zookeeper管理hdfs -->
<property>
<name>ha.zookeeper.quorum</name>
<value>vm05:2181,vm06:2181,vm07:2181</value>
</property>
</configuration>
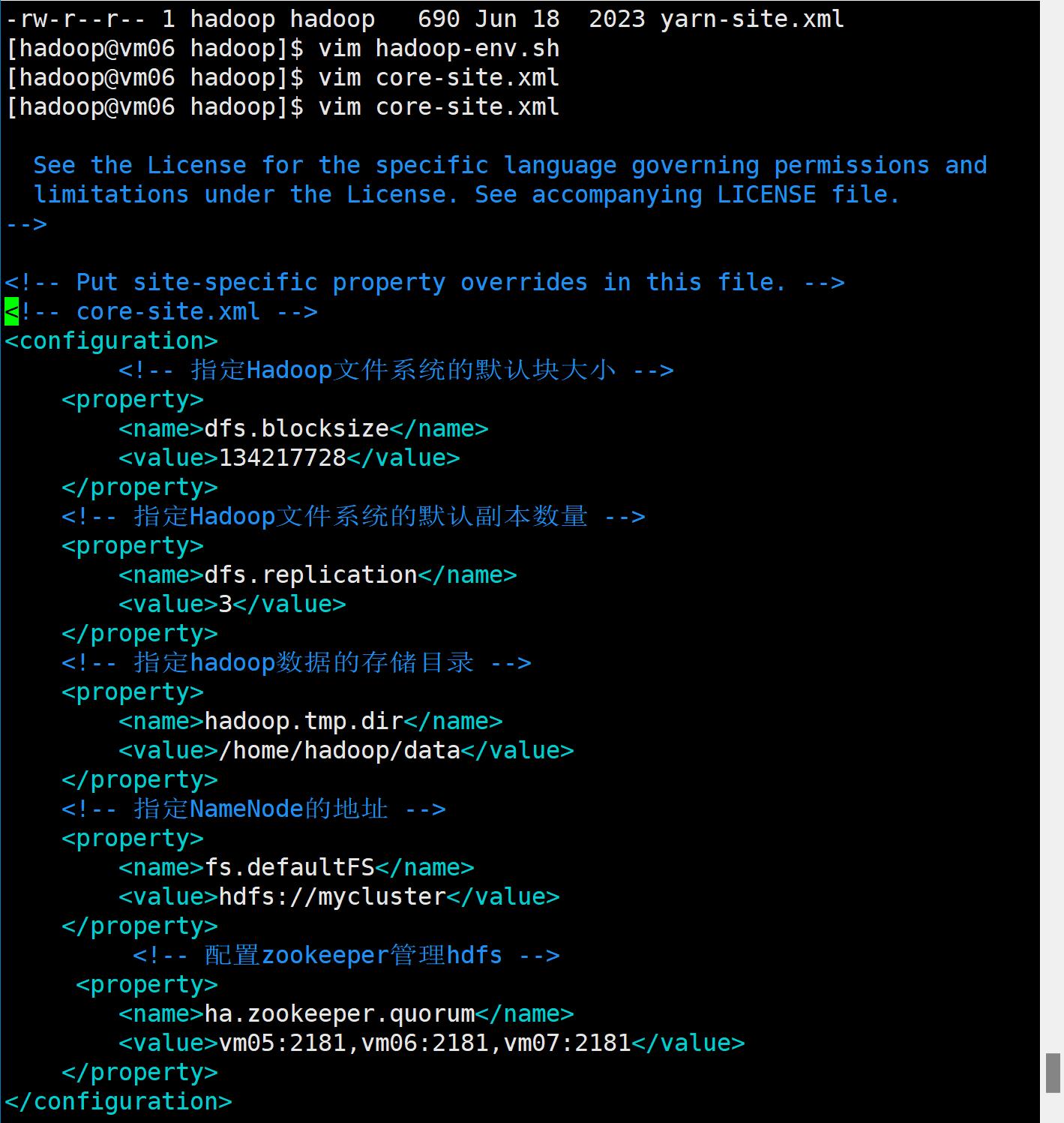
hdfs-site.xml配置
hdfs-site.xml文件主要配置和HDFS相关的属性, 同样位于hadoop/etc/hadoop路径下
<!--hdfs-site.xml配置-->
<configuration>
<!-- NameNode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- NameNode的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>vm06:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>vm07:8020</value>
</property>
<!-- NameNode的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>vm06:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>vm07:9870</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://vm06:8485;vm07:8485/mycluster</value>
</property>
<!-- 访问代理类:client用于确定哪个NameNode为Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml配置
<configuration>
<!-- ResourceManager连接的最大等待时间(毫秒) -->
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>2000</value> <!-- 设置ResourceManager连接的最大等待时间为2000毫秒 -->
</property>
<!-- 启用ResourceManager的高可用性 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value> <!-- 启用ResourceManager的高可用性 -->
</property>
<!-- 启动故障自动恢复 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enable</name>
<value>true</value> <!-- 启动故障自动恢复 -->
</property>
<!-- 启用内嵌式的故障自动恢复 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value> <!-- 启用内嵌式的故障自动恢复 -->
</property>
<!-- 设置ResourceManager所属的集群ID -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value> <!-- 设置ResourceManager所属的集群ID为 yarn-rm-cluster -->
</property>
<!-- 设置ResourceManager的ID列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value> <!-- 设置ResourceManager的ID列表为 rm1,rm2 -->
</property>
<!-- 设置ResourceManager节点rm1的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>vm05</value> <!-- 设置ResourceManager节点rm1的主机名为 vm05 -->
</property>
<!-- 设置ResourceManager节点rm2的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>vm07</value> <!-- 设置ResourceManager节点rm2的主机名为 vm07 -->
</property>
<!-- 启用ResourceManager的状态恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value> <!-- 启用ResourceManager的状态恢复 -->
</property>
<!-- 设置存储ResourceManager状态信息的ZooKeeper地址 -->
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>vm05:2181,vm06:2181,vm07:2181</value> <!-- 设置存储ResourceManager状态信息的ZooKeeper地址为 -->
</property>
<!-- 设置ResourceManager节点rm1的地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>vm05:8032</value> <!-- 设置ResourceManager节点rm1的地址为 vm05:8032 -->
</property>
<!-- 设置ResourceManager节点rm1的调度器地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>vm05:8034</value> <!-- 设置ResourceManager节点rm1的调度器地址为 vm05:8034 -->
</property>
<!-- 设置ResourceManager节点rm1的Web应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>vm05:8088</value> <!-- 设置ResourceManager节点rm1的Web应用地址为 vm05:8088 -->
</property>
<!-- 设置ResourceManager节点rm2的地址 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>vm06:8032</value> <!-- 设置ResourceManager节点rm2的地址为 vm06:8032 -->
</property>
<!-- 设置ResourceManager节点rm2的调度器地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>vm06:8034</value> <!-- 设置ResourceManager节点rm2的调度器地址为 vm06:8034 -->
</property>
<!-- 设置ResourceManager节点rm2的Web应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>vm06:8088</value> <!-- 设置ResourceManager节点rm2的Web应用地址为 vm06:8088 -->
</property>
<!-- 设置ZooKeeper的地址,用于协调ResourceManager的高可用性和故障自动恢复 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>vm05:2181,vm06:2181,vm07:2181</value> <!-- 设置ZooKeeper的地址,用于协调ResourceManager的高可用性和故障自动恢复为vm05:2181,vm06:2181,vm07:2181 -->
</property>
<!-- 启用日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value> <!-- 启用日志聚合 -->
</property>
<!-- 设置Hadoop使用的ZooKeeper地址 -->
<property>
<name>hadoop.zk.address</name>
<value>vm05:2181,vm06:2181,vm07:2181</value> <!-- 设置Hadoop使用的ZooKeeper地址为 vm05:2181,vm06:2181,vm07:2181 -->
</property>
<!-- 设置NodeManager的辅助服务 -->
<property>
<name>yarn.nodemanager.aux-sevices</name>
<value>mapreduce_shuffle</value> <!-- 设置NodeManager的辅助服务为 mapreduce_shuffle -->
</property>
<!-- 设置MapReduce Shuffle服务的类 -->
<property>
<name>yarn.nodemanager.aux-sevices.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value> <!-- 设置MapReduce Shuffle服务的类为 org.apache.hadoop.mapred.ShuffleHandle -->
</property>
</configuration>
workers文件配置
workers文件的名称是在hadoop-env.sh 文件中指定的。在 hadoop-env.sh 文件中,可以找到一个环境变量
#export HADOOP_WORKERS="${HADOOP_CONF_DIR}/workers"
,它指定了workers 文件的路径。通常情况下,HADOOP_WORKERS 的默认值是 ${HADOOP_CONF_DIR}/workers ,其中 ${HADOOP_CONF_DIR} 是指向 Hadoop 配置文件目录的环境变量。
注意:旧版本的hadoop中这里使用的是slaves
cd /home/hadoop/hadoop/etc/hadoop
vim workers
键入以下信息
vm05
vm06
vm07
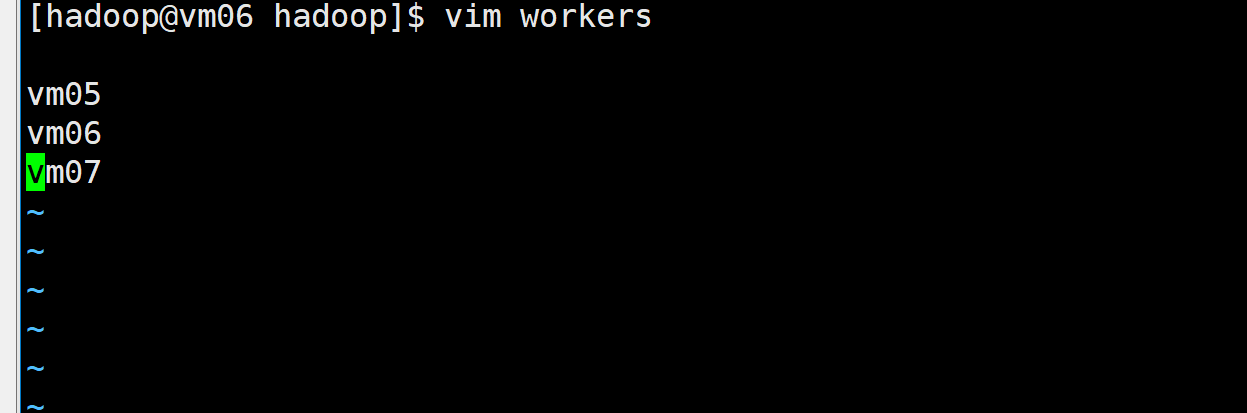
此文件配置集群中的所有hostname。
注:所有节点配置内容保持一致
启动JournalNode集群
在Hadoop中,JournalNode集群用于存储NameNode的编辑日志。它们帮助确保在NameNode发生故障时不会丢失数据,并支持NameNode的高可用性和故障转移。 JournalNode集群是Hadoop分布式文件系统(HDFS)的关键组件,用于维护持久化的NameNode编辑日志,以便在发生故障时进行恢复。
hadoop/sbin/hadoop-daemon.sh start journalnode
jps
出现JournalNode进程说明启动正常
格式化namenode
本文中设置了vm06、vm07为namenode节点,在vm06节点执行以下指令
## 在vm06节点(NameNode主节点)上,使用以下命令对 NameNode进行格式化
hadoop/bin/hdfs namenode -format
hadoop/bin/hdfs zkfc -formatZK
hadoop/bin/hdfs namenode
##在备用节点vm07进行同步主节点的元数据
hadoop/bin/hadoop namenode -bootstrapStandby
##所有节点关闭zookeeper集群
zkServer.sh stop
##所有节点关闭 journalnode集群
/home/hadoop/hadoop/bin/hdfs --daemon stop journalnode
##所有节点启动zookeeper集群
zkServer.sh start
#主节点vm06启动集群
hadoop/sbin/start-all.sh

查看启动正常之后,根据配置的路径配置环境变量
完善环境变量
cd
vim /etc/profile
完善以下环境变量值
source /etc/profile
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
export HADOOP_HOME=/home/hadoop/hadoop/
export PATH=${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/sbin/:${HADOOP_HOME}/bin/:$PATH
加载环境变量
source .bash_profile
如果对各位读者有帮助欢迎关注、点赞、转发,后续会继续更新关于hadoop内部组件的相关操作文章。
版权归原作者 necessary653 所有, 如有侵权,请联系我们删除。