
文章目录
Hadoop(伪分布)+ Spark(Local)软件安装及环境配置
前言
为了对数据进行分析,我们必须进行环境搭建。对于初学者来说,我们一般用Linux搭建环境,本文介绍的就是在Ubuntu上搭建Hadoop(伪分布式 )+ Spark(Local模式)环境。
一、安装虚拟机
1.下载Ubuntu16.04镜像
镜像源文件:下载地址
提取码:ontd
下载完成之后,进行虚拟机安装及配置,镜像位置选择下载好的Ubuntu16.04镜像。
二、Hadoop安装及配置(伪分布式)
1.创建hadoop用户
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudouseradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudopasswd hadoopShell 命令
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo
最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
2.更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudoapt-get update
如果安装过慢,可以设置安装镜像源,打开设置,点击软件和更新
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存失败,源站可能有防盗链机制,建议将图片保存下来直接上传下上传(iQmjFW4ls6HY-1653725488831)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220402155132852.png)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220402155132852.png)]](https://img-blog.csdnimg.cn/71ce0e2b86cf40088548ecd28241e592.png)
点击下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PzUjuVuh-1653725488832)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220402155225278.png)]](https://img-blog.csdnimg.cn/370120c372054500a6286f585f374778.png)
打开后,选择其他站点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M4yyy88O-1653725488833)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220402155316233.png)]](https://img-blog.csdnimg.cn/c8b17950eb5746639c46ca391d0570ab.png)
点击选择最佳服务器等待片刻后系统找到最优服务器点击选择服务器退出等待即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WSEB6mwO-1653725488833)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220402155341443.png)]](https://img-blog.csdnimg.cn/dc418ede877546888aeba44841e3582d.png)
后续需要更改一些配置文件,我比较喜欢用的是 vim(vi增强版,基本用法相同),建议安装一下(如果你实在还不会用 vi/vim 的,请将后面用到 vim 的地方改为 gedit,这样可以使用文本编辑器进行修改,并且每次文件更改完成后请关闭整个 gedit 程序,否则会占用终端):
sudoapt-getinstallvim
安装软件时若需要确认,在提示处输入 y 即可。
3.安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudoapt-getinstall openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit# 退出刚才的ssh localhostcd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhostssh-keygen -t rsa # 会有提示,都按回车就可以cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用
ssh localhost
命令,无需输入密码就可以直接登陆了。
4.安装Java环境
Hadoop3.1.3需要JDK版本在1.8及以上。需要按照下面步骤来自己手动安装JDK1.8。
我们已经把JDK1.8的安装包jdk-8u321-linux-x64.tar.gz放在了百度云盘,
链接:https://pan.baidu.com/s/1Ty_H_SQ17qPK05Xvv5EOTg?pwd=6zm5
提取码:6zm5
请把压缩格式的文件jdk-8u162-linux-x64.tar.gz下载到本地电脑,假设保存在“/home/hadoop/Downloads(或者)/”目录下。
在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
cd /usr/lib
sudomkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件cd ~ #进入hadoop用户的主目录cd Downloads 或者 cd 下载 #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下sudotar -zxvf ./jdk-8u321-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
上面使用了解压缩命令tar,如果对Linux命令不熟悉,可以参考常用的Linux命令用法。
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_321目录。
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc
上面命令使用vim编辑器(查看vim编辑器使用方法)打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_321
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
java -version
如果能够在屏幕上返回如下信息,则说明安装成功:
hadoop@hadoop-virtual-machine:/usr/local/hadoop$ java -version
java version "1.8.0_321"
Java(TM) SE Runtime Environment (build 1.8.0_321-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.321-b07, mixed mode)
至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
5.安装Hadoop3.1.3
Hadoop安装文件,可以到Hadoop官网下载hadoop-3.1.3.tar.gz。
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudotar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中cd /usr/local/sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoopsudochown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wYddEM1e-1653725488834)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220402165848161.png)]](https://img-blog.csdnimg.cn/d70345721c1043a78d7602294420e864.png)
6.Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
cd /usr/local/hadoop
gedit ./etc/hadoop/core-site.xml
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便:
gedit ./etc/hadoop/core-site.xml
),将当中的
<configuration></configuration>
XML
修改为下面配置:
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
XML
同样的,修改配置文件 hdfs-site.xml:
cd /usr/local/hadoop
gedit ./etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property></configuration>
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 的提示,具体返回信息类似如下:
2022-04-01 10:31:31,560 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.3
*************************************************************/
......
2022-04-01 10:31:31 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name **has been successfully formatted**.
2022-04-01 10:31:31,700 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2022-04-01 10:31:31,770 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .
2022-04-01 10:31:31,810 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2022-04-01 10:31:31,816 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2022-04-01 10:31:31,816 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop/127.0.1.1
*************************************************************/
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。如果已经按照前面教程在.bashrc文件中设置了JAVA_HOME,还是出现 Error: JAVA_HOME is not set and could not be found. 的错误,那么,请到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,然后,再次启动Hadoop。
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
若出现如下SSH提示,输入yes即可。
启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,并不会影响正常使用。
启动 Hadoop 时提示 Could not resolve hostname
如果启动 Hadoop 时遇到输出非常多“ssh: Could not resolve hostname xxx”的异常情况
这个并不是 ssh 的问题,可通过设置 Hadoop 环境变量来解决。首先按键盘的 ctrl + c 中断启动,然后在 ~/.bashrc 中,增加如下两行内容(设置过程与 JAVA_HOME 变量一样,其中 HADOOP_HOME 为 Hadoop 的安装目录):
exportHADOOP_HOME=/usr/local/hadoop
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
保存后,务必执行
source ~/.bashrc
使变量设置生效,然后再次执行
./sbin/start-dfs.sh
启动 Hadoop。
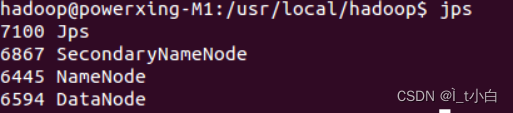
启动完成后,可以通过命令
jps
来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
此外,若是 DataNode 没有启动,可尝试如下的方法(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做):
# 针对 DataNode 没法启动的解决方法cd /usr/local/hadoop./sbin/stop-dfs.sh # 关闭rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
./bin/hdfs namenode -format # 重新格式化
NameNode./sbin/start-dfs.sh # 重启
成功启动后,可以访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1BnHvvcQ-1653725488835)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220402170006011.png)]](https://img-blog.csdnimg.cn/54cd42dfd90f4d9792b023a14189ffe7.png)
若要关闭 Hadoop,则运行
cd /usr/local/hadoop
./sbin/stop-dfs.sh
三、安装 Spark2.4.0
1.下载Spark2.4.0
首先需要下载Spark安装文件。访问Spark官方下载地址,按照如下图下载。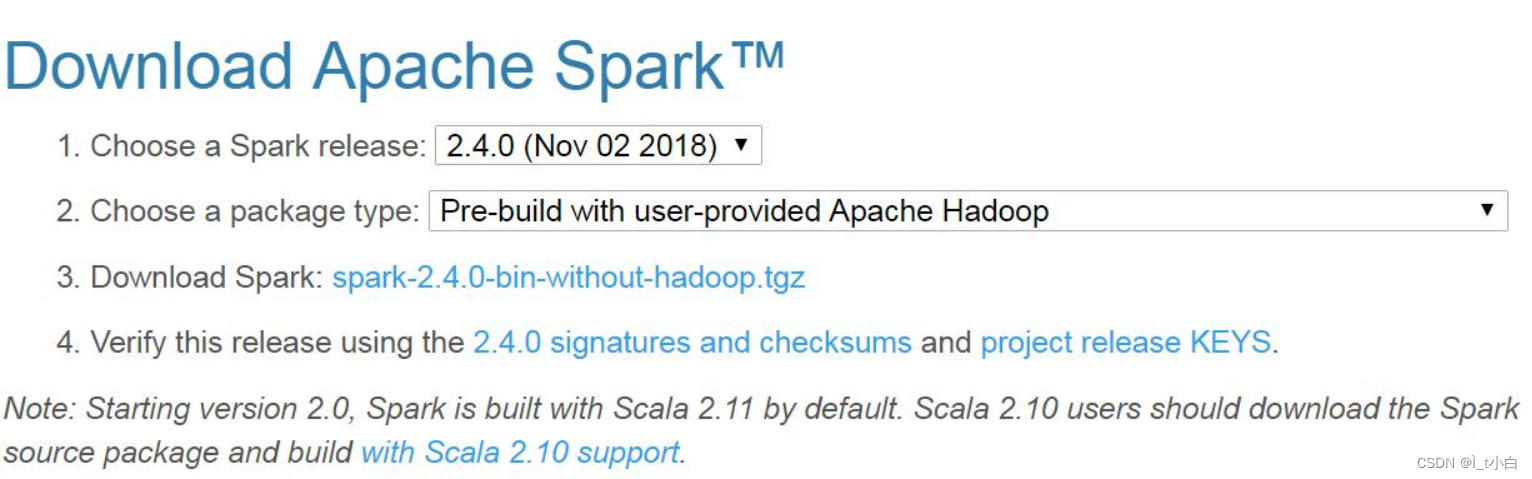
为确保各软件的兼容性,本教程的具体运行环境如下:
- Hadoop 3.1.3
- Java JDK 1.8
- Spark 2.4.0
需要注意的是,本教程内容中Spark采用Local模式进行安装,也就是在单机上运行Spark,因此,在安装Hadoop时,需要按照伪分布式模式进行安装。在单台机器上按照“Hadoop(伪分布式)+Spark(Local模式)”。
2.安装Spark(Local模式)
sudotar -zxf ~/下载/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/cd /usr/local
sudomv ./spark-2.4.0-bin-without-hadoop/ ./spark
sudochown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
安装后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
cd /usr/local/spark
bin/run-example SparkPi 2>&1|grep"Pi is"
3.启动Spark Shell
cd /usr/local/spark
bin/spark-shell
启动spark-shell后,会自动创建名为sc的SparkContext对象和名为spark的SparkSession对象,如图: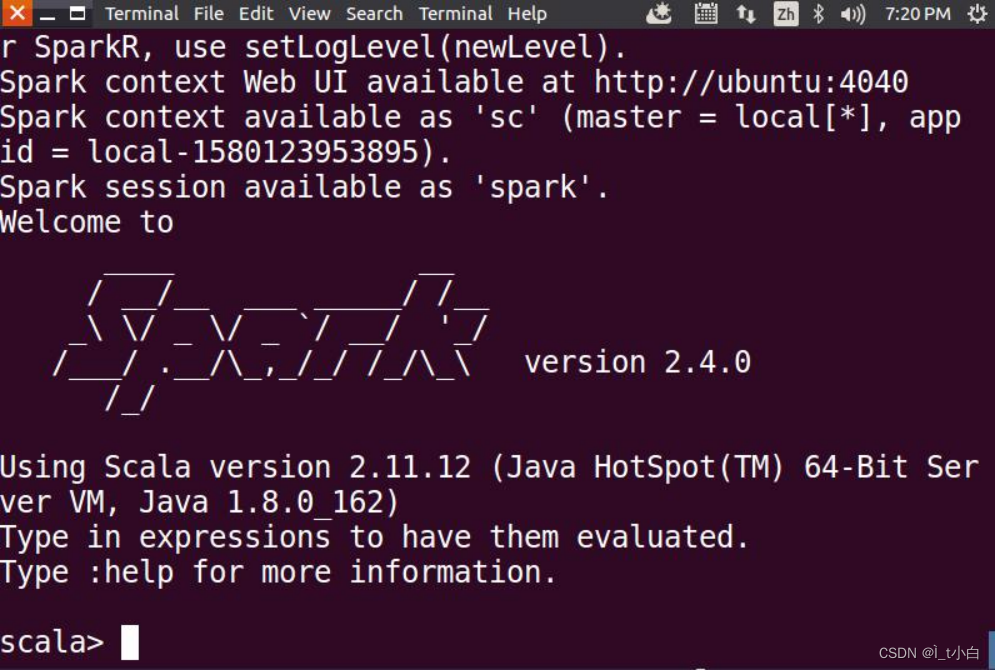 至此,环境搭建完成。
至此,环境搭建完成。
4.退出Spark Shell
输入exit或者:quit,即可退出spark shell
:quit
exit
总结
上述就是Hadoop(伪分布式 )+ Spark(Local模式)软件安装及环境配置,在此基础上我们就可以进行大数据分析。下期给大家带来RDD编程。
注:本文章仅用于参考学习,如有错误,请大家指正。
版权归原作者 Ì_t小白 所有, 如有侵权,请联系我们删除。