

sql差不多就是这个样子 疯狂join,然后别人说这个sql跑不动了。报错
INFO] 2022-09-20 11:26:58.500 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:26:52,814 Stage-3_0: 11(+1,-2)/12
INFO : 2022-09-20 11:26:55,823 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:03.504 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:26:58,832 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:08.507 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:01,841 Stage-3_0: 11(+1,-2)/12
INFO : 2022-09-20 11:27:04,850 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:13.512 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:07,860 Stage-3_0: 11(+1,-2)/12
INFO : 2022-09-20 11:27:10,869 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:18.518 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:13,878 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:23.524 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:16,887 Stage-3_0: 11(+1,-2)/12
INFO : 2022-09-20 11:27:19,896 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:28.527 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:22,905 Stage-3_0: 11(+1,-2)/12
INFO : 2022-09-20 11:27:25,914 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:33.534 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:28,924 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:38.538 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:31,933 Stage-3_0: 11(+1,-2)/12
INFO : 2022-09-20 11:27:34,942 Stage-3_0: 11(+1,-2)/12
[INFO] 2022-09-20 11:27:39.058 - [taskAppId=TASK-1850-1276992-1359844]:[127] - -> INFO : 2022-09-20 11:27:37,951 Stage-3_0: 11(+1,-2)/12
ERROR : Spark job[3] failed
java.util.concurrent.ExecutionException: Exception thrown by job
at org.apache.spark.JavaFutureActionWrapper.getImpl(FutureAction.scala:337) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.JavaFutureActionWrapper.get(FutureAction.scala:342) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:404) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:365) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_181]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_181]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_181]
Caused by: org.apache.spark.SparkException: Job 3 cancelled
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1890) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.scheduler.DAGScheduler.handleJobCancellation(DAGScheduler.scala:1825) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2077) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2060) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2049) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) ~[spark-core_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
ERROR : FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed due to: Job 3 cancelled
INFO : Completed executing command(queryId=hive_20220920112336_c6ae7869-4649-4e2b-92d8-de2de872623b); Time taken: 240.664 seconds
提取有用信息
Stage-3_0: 11(+1,-2)/12 一直这个
很明显stage3有12个task有一个或者2个一直报错,然后最后有一个跑不动了
报错信息ERROR : FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed due to: Job 3 cancelled
这个就看不出啥。
去spark看日志
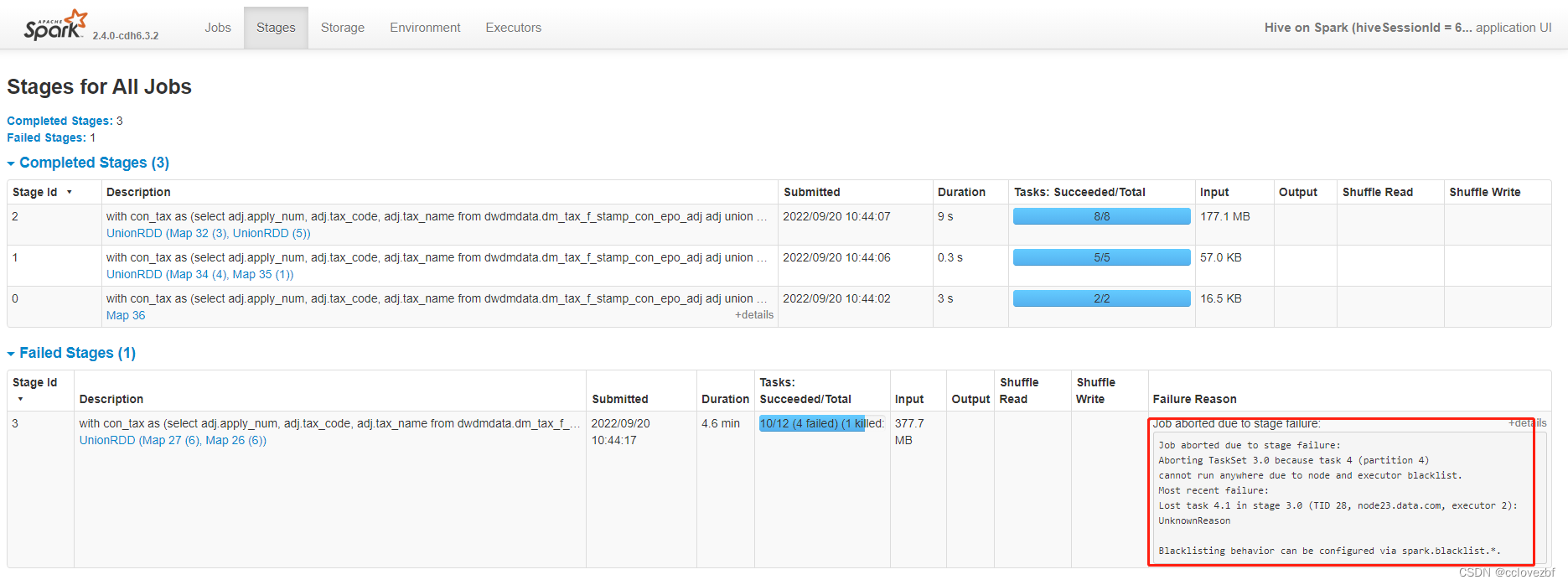 好像也没啥,点进stage看日志。
好像也没啥,点进stage看日志。
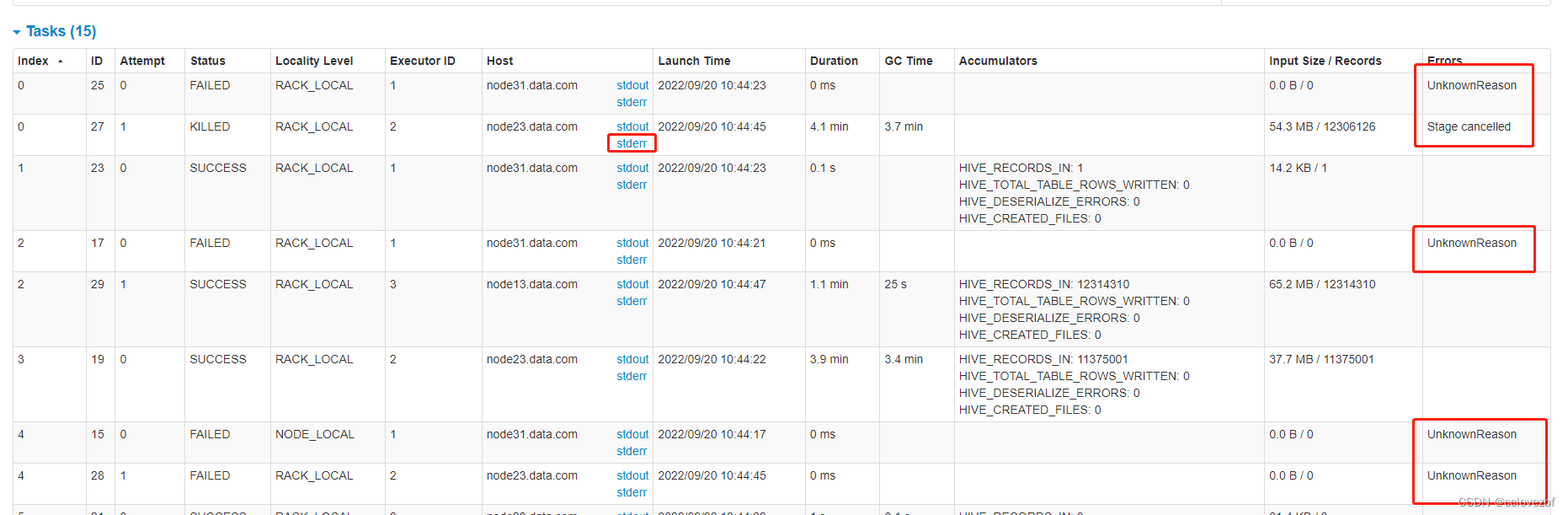
继续点stderr
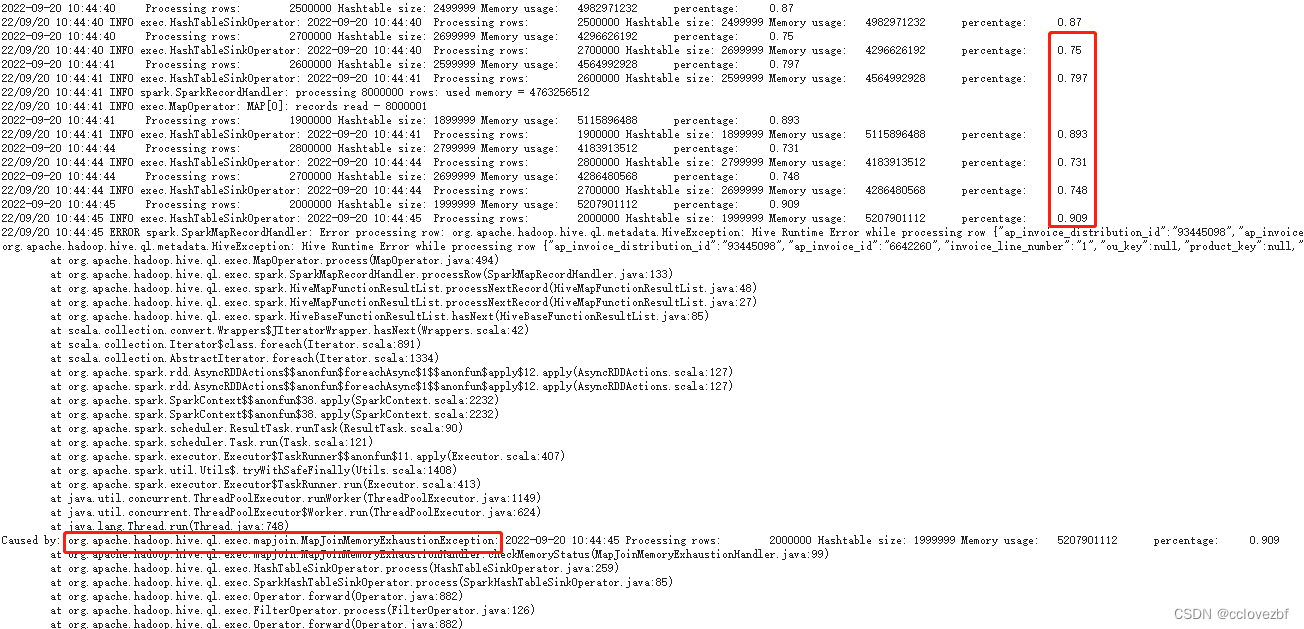
22/09/20 10:44:41 INFO spark.SparkRecordHandler: processing 8000000 rows: used memory = 4763256512 22/09/20 10:44:41 INFO exec.MapOperator: MAP[0]: records read - 8000001 2022-09-20 10:44:41 Processing rows: 1900000 Hashtable size: 1899999 Memory usage: 5115896488 percentage: 0.893 22/09/20 10:44:41 INFO exec.HashTableSinkOperator: 2022-09-20 10:44:41 Processing rows: 1900000 Hashtable size: 1899999 Memory usage: 5115896488 percentage: 0.893 2022-09-20 10:44:44 Processing rows: 2800000 Hashtable size: 2799999 Memory usage: 4183913512 percentage: 0.731 22/09/20 10:44:44 INFO exec.HashTableSinkOperator: 2022-09-20 10:44:44 Processing rows: 2800000 Hashtable size: 2799999 Memory usage: 4183913512 percentage: 0.731 2022-09-20 10:44:44 Processing rows: 2700000 Hashtable size: 2699999 Memory usage: 4286480568 percentage: 0.748 22/09/20 10:44:44 INFO exec.HashTableSinkOperator: 2022-09-20 10:44:44 Processing rows: 2700000 Hashtable size: 2699999 Memory usage: 4286480568 percentage: 0.748 2022-09-20 10:44:45 Processing rows: 2000000 Hashtable size: 1999999 Memory usage: 5207901112 percentage: 0.909 22/09/20 10:44:45 INFO exec.HashTableSinkOperator: 2022-09-20 10:44:45 Processing rows: 2000000 Hashtable size: 1999999 Memory usage: 5207901112 percentage: 0.909 22/09/20 10:44:45 ERROR spark.SparkMapRecordHandler: Error processing row: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row {"ap_invoice_distribution_id":"93445098","ap_invoice_id":"6642260","invoice_line_number":"1","ou_key":null,"product_key":null,"region_key":null,"account_key":null,"erp_channel_key":null,"org_key":null,"po_header_id":null,"po_release_id":null,"po_line_id":null,"currency_code":null,"base_currency_code":null,"distribution_type":null,"set_of_book_id":null,"gl_flag":null,"gl_date":null,"unit_price":null,"distribution_amount":null,"base_amount":null,"account_desc":null,"creation_date":null,"creator_id":null,"creator_name":null,"last_update_date":null,"last_updater_id":null,"last_updater_name":null,"etl_create_batch_id":null,"etl_last_update_batch_id":null,"etl_create_job_id":null,"etl_last_update_job_id":null,"etl_create_date":null,"etl_last_update_by":null,"etl_last_update_date":null,"etl_source_system_id":null,"etl_delete_flag":"N","prepay_distribution_id":null} org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row {"ap_invoice_distribution_id":"93445098","ap_invoice_id":"6642260","invoice_line_number":"1","ou_key":null,"product_key":null,"region_key":null,"account_key":null,"erp_channel_key":null,"org_key":null,"po_header_id":null,"po_release_id":null,"po_line_id":null,"currency_code":null,"base_currency_code":null,"distribution_type":null,"set_of_book_id":null,"gl_flag":null,"gl_date":null,"unit_price":null,"distribution_amount":null,"base_amount":null,"account_desc":null,"creation_date":null,"creator_id":null,"creator_name":null,"last_update_date":null,"last_updater_id":null,"last_updater_name":null,"etl_create_batch_id":null,"etl_last_update_batch_id":null,"etl_create_job_id":null,"etl_last_update_job_id":null,"etl_create_date":null,"etl_last_update_by":null,"etl_last_update_date":null,"etl_source_system_id":null,"etl_delete_flag":"N","prepay_distribution_id":null} at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:494) at org.apache.hadoop.hive.ql.exec.spark.SparkMapRecordHandler.processRow(SparkMapRecordHandler.java:133) at org.apache.hadoop.hive.ql.exec.spark.HiveMapFunctionResultList.processNextRecord(HiveMapFunctionResultList.java:48) at org.apache.hadoop.hive.ql.exec.spark.HiveMapFunctionResultList.processNextRecord(HiveMapFunctionResultList.java:27) at org.apache.hadoop.hive.ql.exec.spark.HiveBaseFunctionResultList.hasNext(HiveBaseFunctionResultList.java:85) at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:42) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$12.apply(AsyncRDDActions.scala:127) at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$12.apply(AsyncRDDActions.scala:127) at org.apache.spark.SparkContext$$anonfun$38.apply(SparkContext.scala:2232) at org.apache.spark.SparkContext$$anonfun$38.apply(SparkContext.scala:2232) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:121) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.hadoop.hive.ql.exec.mapjoin.MapJoinMemoryExhaustionException: 2022-09-20 10:44:45 Processing rows: 2000000 Hashtable size: 1999999 Memory usage: 5207901112 percentage: 0.909 at org.apache.hadoop.hive.ql.exec.mapjoin.MapJoinMemoryExhaustionHandler.checkMemoryStatus(MapJoinMemoryExhaustionHandler.java:99) at org.apache.hadoop.hive.ql.exec.HashTableSinkOperator.process(HashTableSinkOperator.java:259) at org.apache.hadoop.hive.ql.exec.SparkHashTableSinkOperator.process(SparkHashTableSinkOperator.java:85) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:882) at org.apache.hadoop.hive.ql.exec.FilterOperator.process(FilterOperator.java:126) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:882) at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:130) at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.forward(MapOperator.java:146) at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:484) ... 19 more
这里好像比较清楚了。首先
Memory usage: 5207901112 percentage: 0.909
好像是内存到一个阈值了,然后就报错了。个人感觉是0.9
然后保错的具体原因是 org.apache.hadoop.hive.ql.exec.mapjoin.MapJoinMemoryExhaustionException
注意这个异常 一个mapjoin 一个memory 超过
这个时候有两个选择
1.直接百度 2.去查源码
肯定先选1
https://www.jianshu.com/p/962fa4b4ca13
得到解决答案 set hive.auto.convert.join=false
那么开始假装研究2
下载hive源码 找到 SparkMapRecordHandler类 ,搜索Error processing row
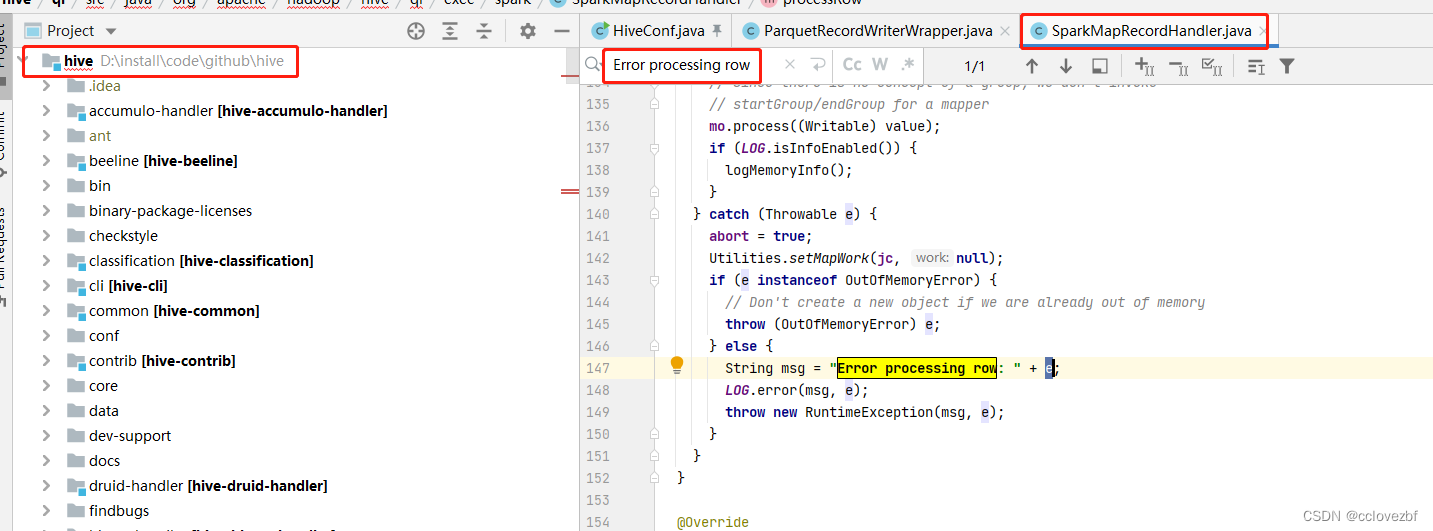
@Override
public void processRow(Object key, Object value) throws IOException {
if (!anyRow) {
OperatorUtils.setChildrenCollector(mo.getChildOperators(), oc);
anyRow = true;
}
// reset the execContext for each new row
execContext.resetRow();
try {
// Since there is no concept of a group, we don't invoke
// startGroup/endGroup for a mapper
mo.process((Writable) value);
if (LOG.isInfoEnabled()) {
logMemoryInfo();
}
} catch (Throwable e) {
abort = true;
Utilities.setMapWork(jc, null);
if (e instanceof OutOfMemoryError) {
// Don't create a new object if we are already out of memory
throw (OutOfMemoryError) e;
} else {
String msg = "Error processing row: " + e;
LOG.error(msg, e);
throw new RuntimeException(msg, e);
}
}
注意这个代码 我们肯定是mo.process处理value的时候报错
那这个mo是啥呢?继续看
if (mrwork.getVectorMode()) {
mo = new VectorMapOperator(runtimeCtx);
} else {
mo = new MapOperator(runtimeCtx);
}
这个是啥,看过我其他文章的我都会提到这个,这个vector叫矢量化,也就是看你开启矢量化
set hive.vectorized.execution.enabled=false;
set hive.vectorized.execution.reduce.enabled=false;
我们再看这两个mapOperator的process的区别 说实话源码有点难看。先不看了,根据日志是普通mapOperator()
日志里有
spark.SparkRecordHandler: maximum memory = 5726797824=5.33G
这个是因为我们之前设置的excutor.memory=6G,其中有一些reseverd啥的。
然后跑着跑着就快跑到了 5251681352。
这里就很奇怪 数据库里总数据才6000多w 我这个task直接处理了2400w都ok,
下面的处理了1000w怎么就开始叫唤了?没法继续看日志
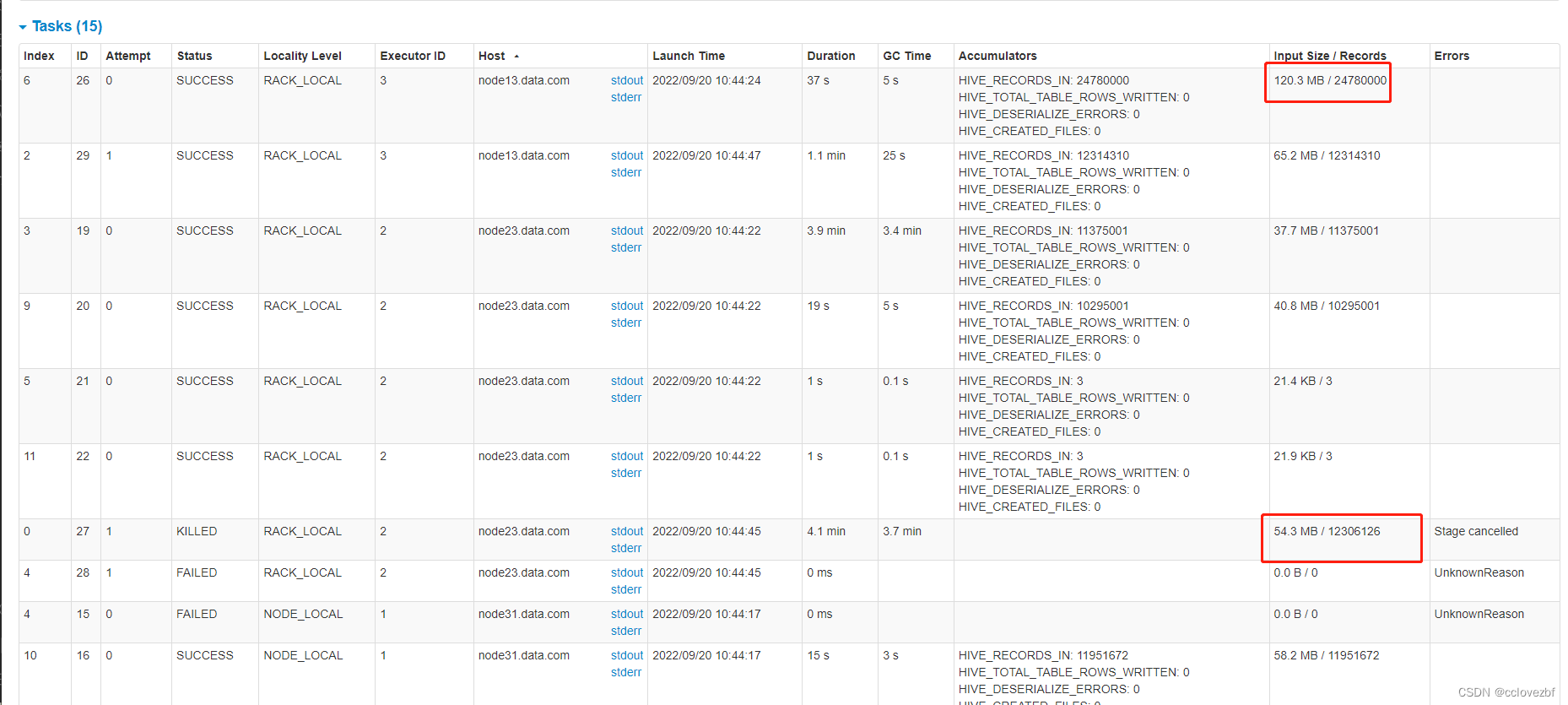
注意这个ui图
node13 处理了 task 2 和task6 其中task2是因为node31的task2失败了重试的。
为什么node13 处理task2和6没失败呢?
task 6有24780000, task2有12314310

注意task2是在6都快干了一半的时候才开始的 。
再接着看node13的日志
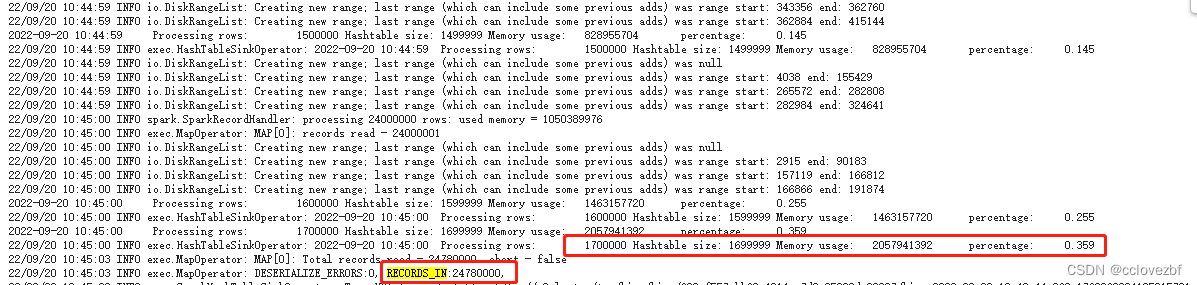
task6 process
Processing rows: 1700000 Hashtable size: 1699999 Memory usage: 2057941392 percentage: 0.359
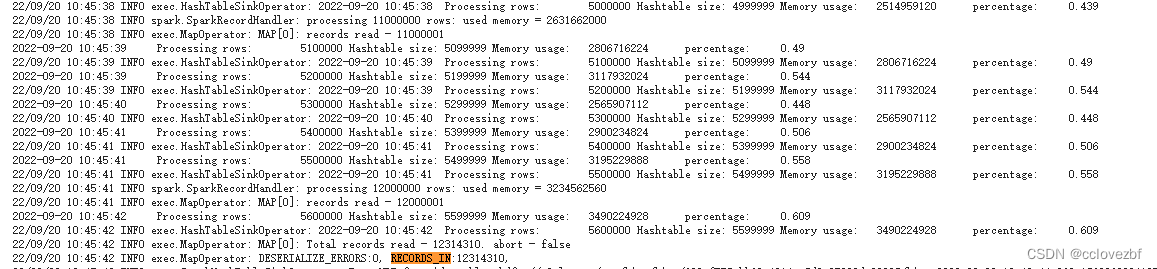
**task2 **process 这里也勉强能够看到 0.49->0.544->0.448 这里变少了 肯定有GC
Processing rows: 5600000 Hashtable size: 5599999 Memory usage: 3490224928 percentage: 0.609
接着 我们看node23的日志

不看了,写的太累了。 还要各种截图。
简单的来说吧,为什么报错
executor node23就6G 两个任务同时运行GC 来不及,所以oom了。
怎么解决?
1.加大executor.memory 最简单的办法,所有任务都可以用这个。
2.注意这里是mapjoin,需要加载数据到内存里,所以别人的文章都是关闭convert.join
我也试了确实ok
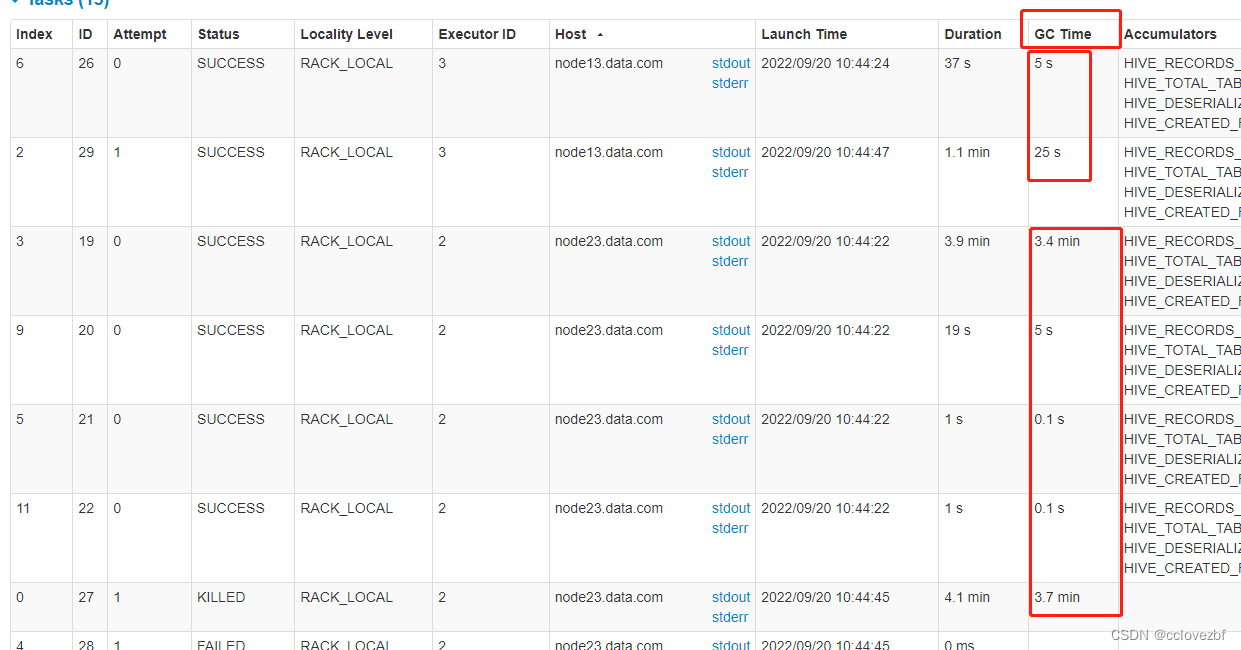
3.增加task的数量。如下图 这个文件格式如下 是真的垃圾。大的打 小的小

 看这个图很容易看出node13 和node23处理的数据差不多,只是数据分布不均而已。
看这个图很容易看出node13 和node23处理的数据差不多,只是数据分布不均而已。
4.增加内存使用率 默认0.9 改为0.99 感觉就一点卵用
HIVEHASHTABLEMAXMEMORYUSAGE("hive.mapjoin.localtask.max.memory.usage", (float) 0.90,
"This number means how much memory the local task can take to hold the key/value into an in-memory hash table. \n" +
"If the local task's memory usage is more than this number, the local task will abort by itself. \n" +
"**It means the data of the small table is too large to be held in memory**."),
5.看网上的文章也说过 好像是把大表的kv放到内存里了,那么可以尝试使用hint 指定mapjoin
6.gc太垃圾,换个好点的GC,这块研究不多只知道parallel GC cms
版权归原作者 cclovezbf 所有, 如有侵权,请联系我们删除。