
1.克隆两台虚拟机,作为从机使用
右击创建好的虚拟机hadoop base,选择管理-克隆-点击下一步-虚拟机中的当前状态-下一步-创建完整克隆-下一步-设置克隆机名称,安装位置-完成。
2.从机ip设置
启动两台从机,打开终端,修改主机名称分别为ljl01,ljl02。设置静态ip,与主节点ljl的hosts文件保持一致,设置成功重启网络。
3.Xshell连接
打开Xshell7,左上角新建文件,在弹出框设置两个从节点的名称和ip地址,然后连接,随后输入root账号密码完成连接。
4.配置免密登录
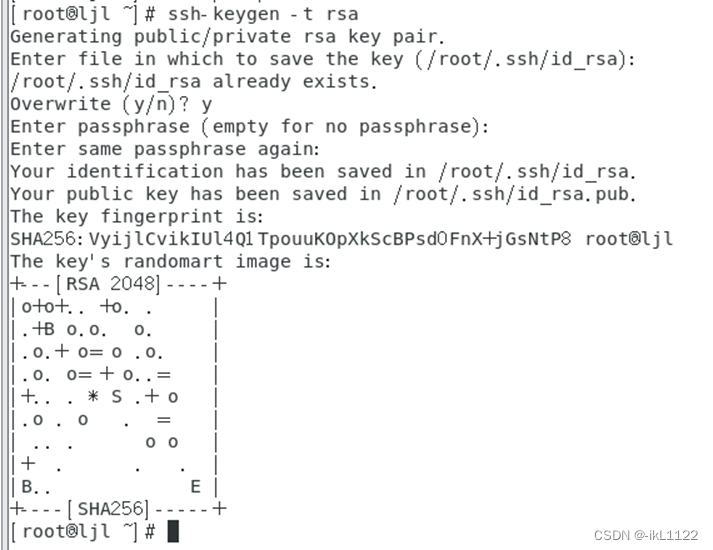
回到主节点ljl,执行ssh-keygen -t rsa命令
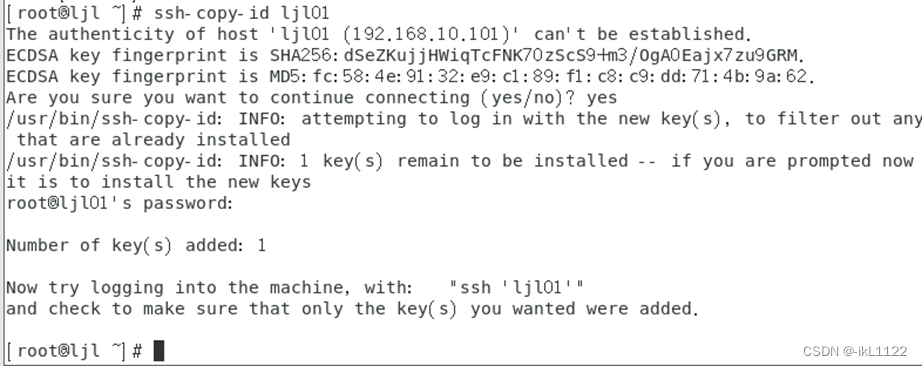
把公钥复制到各个节点,第一次登陆会让你输入密码
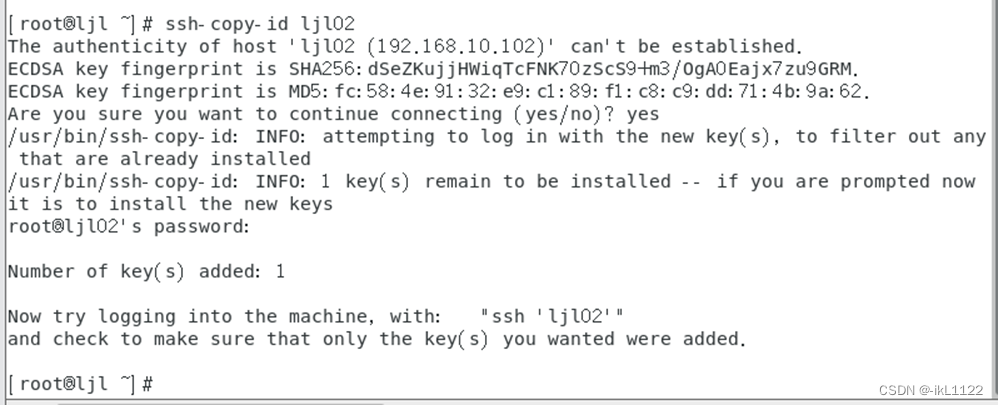
对自己也需要设置免密登录

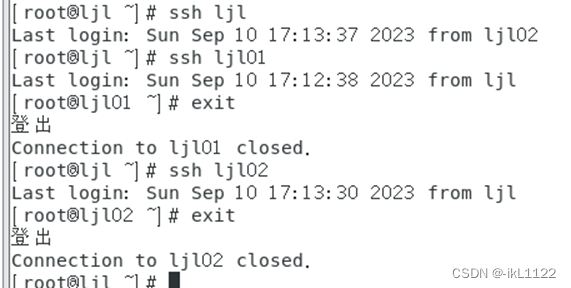
测试免密登录是否配置成功
测试成功之后,exit回到ljl节点
5.配置环境变量
在上一节,jdk和hadoop的环境变量都以配置好

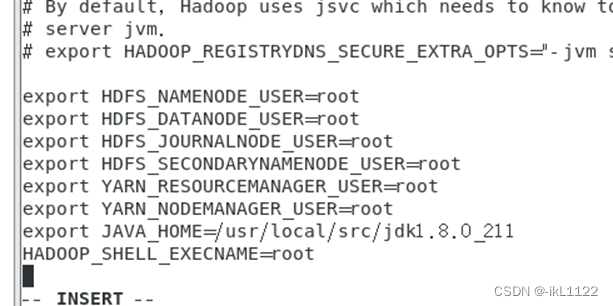
6.配置hadoop-env.sh文件及其他重要文件
首先进入hadoop所在配置文件目录/usr/local/src/Hadoop-3.3.6/etc/hadoop,在此目录打开终端。
vim Hadoop-env.sh
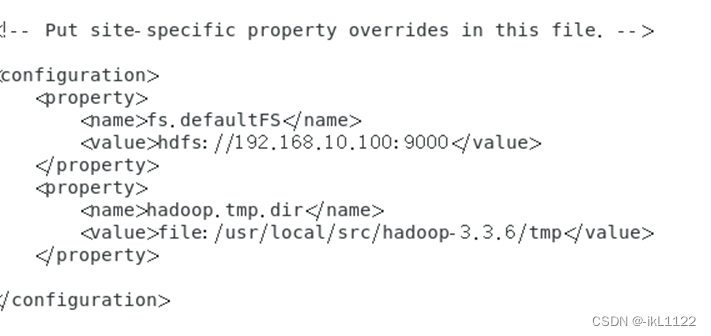
修改core-site.xml, vim core-site.xml
修改hdfs-site.xml文件
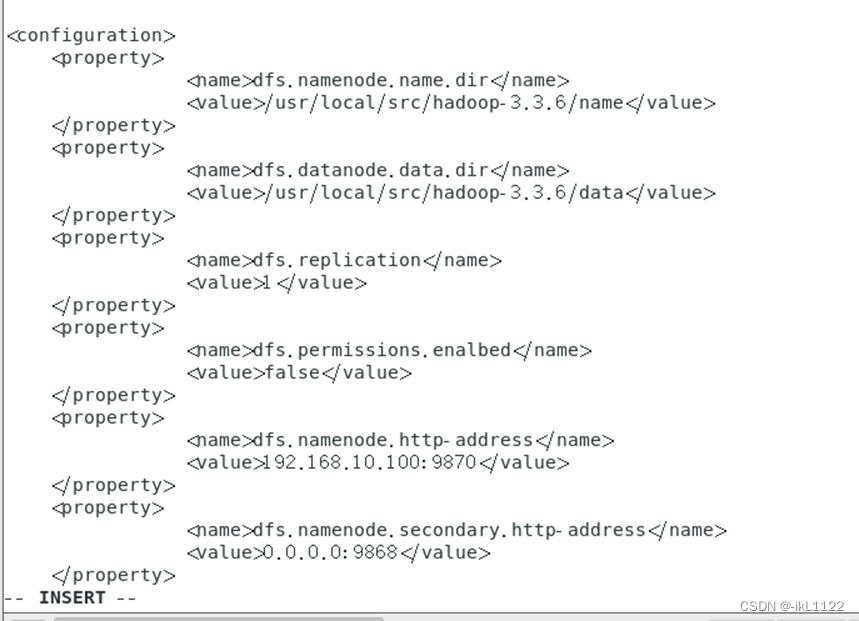
修改yarn-site.xml文件

修改mapred-site.xml文件

修改workers

7.分发文件
cd /usr/local/src# 分发jdk,$PWD:获取当前所在目录的绝对路径 scp -r jdk1.8.0_211 root@ljl01:$PWD scp -r jdk1.8.0_211 root@ljl02:$PWD # 分发hadoop scp -r hadoop-3.3.6 root@ljl01:$PWD scp -r hadoop-3.3.6 root@ljl02:$PWD # 分发/etc/hosts scp /etc/hosts root@ ljl01:/etc/ scp /etc/hosts root@ ljl02:/etc/ # 分发/etc/profile scp /etc/profile root@ ljl01:/etc/ scp /etc/profile root@ ljl02:/etc/

然后在两个从节点上执行 source /etc/profile

8.启动hadoop集群并测试
启动hdfs
start-dfs.sh
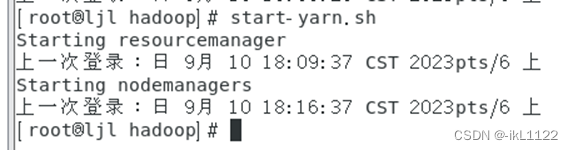
启动yarn
start-yarn.sh
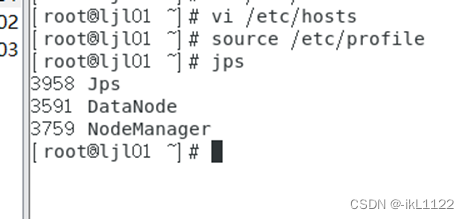
jps 分别查看三个节点的进程



9.访问web界面
主节点的地址+端口号(如:192.168.10.100:9870)
10.运行官方案例
统计每个单词出现的频率
vi words.txt 然后添加如下内容
hadoop hdfs hdfs Hadoop mapreduce mapreduce Hadoop hdfs Hadoop yarn yarn
hdfs dfs -mkdir /input #在hdfs上创建文件夹
hdfs dfs -put words.txt /input/ #把words.txt上传到dfs的input 文件夹中
后运行wordcount

hdfs dfs -ls /output #查看结果

集群搭建结束。
版权归原作者 -ikL1122 所有, 如有侵权,请联系我们删除。