
**编号:2461701 **
项目+LW(说明书)+任务书(开题报告)
完整项目联系方式在文章最下面
项目简介
在大数据时代,天气数据作为一种重要的公共资源,不仅影响人们的日常生活,还对农业、交通、能源等多个领域产生深远影响。通过对天气数据的全面处理和展示,可以帮助人们更好地理解和预测天气变化,从而做出更加科学的决策。我们设计并实现了一个基于Spark的天气数据分析系统,该系统通过数据采集、清洗、分析和可视化,为用户提供了高效、准确的天气数据分析服务。
技术架构
后端技术
- Spark:用于大规模数据处理和分析,利用其内存计算的优势,高效地处理和分析大规模天气数据。
- Selenium:用于自动化数据采集,模拟用户操作,自动化地从网络上抓取天气数据。
- Pandas:用于数据清洗和预处理,确保数据的质量和一致性。
- Flask:轻量级Web框架,用于构建Web应用的后端服务,处理用户请求和响应。
前端技术
- ECharts:用于数据可视化,展示天气数据的分析结果,包括气温变化、空气质量指数等,为用户提供直观的决策支持。
- HTML/CSS/JavaScript:用于构建用户友好的界面,确保系统的易用性和交互性。
系统功能
1. 数据采集
使用Selenium从指定的天气网站上抓取历史天气数据,并将数据保存为CSV文件。采集的数据包括每个月的平均高温、平均低温、极端高温、极端低温、平均空气质量指数等,以及每日的详细天气情况。
2. 数据清洗
使用Pandas对采集到的原始数据进行清洗,移除冗余符号,将字符串类型的数据转换为数值类型,并对日期格式进行处理,确保数据的一致性和可用性。
3. 数据分析
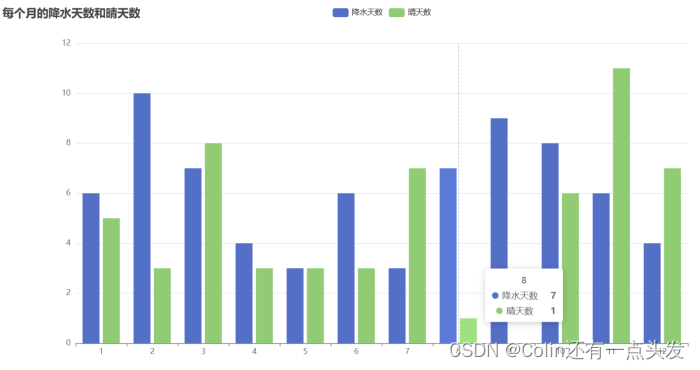
在Linux环境下使用Spark进行数据分析,提取有价值的信息。分析内容包括每个月的平均气温、空气质量指数、极端温度、最常见的天气类型、降水天数和晴天数等。
4. 数据可视化
通过Flask和ECharts进行数据可视化展示,将分析结果以图表的形式直观展示给用户。用户可以通过Web界面查看每个月的平均气温变化、空气质量指数分布、极端温度变化、天气类型分布等。
系统特色
1. 全面数据处理
系统涵盖了从数据采集、清洗、分析到可视化展示的完整流程,确保数据处理的高效性和准确性。
2. 高效大数据处理
利用Spark的内存计算优势,系统能够高效处理和分析大规模天气数据,快速提取出有价值的信息。
3. 直观的数据展示
通过ECharts进行数据可视化,系统能够以直观、易理解的方式展示天气数据的分析结果,帮助用户更好地理解数据。
4. 用户友好的界面
系统采用Flask框架构建Web应用,提供简洁、易用的用户界面,用户可以轻松浏览和查询天气数据的分析结果。
部分运行截图
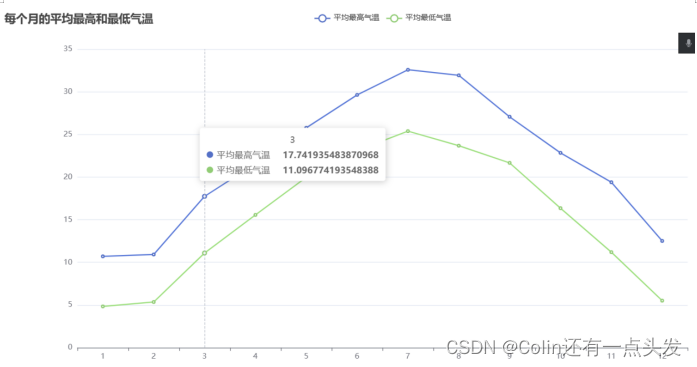
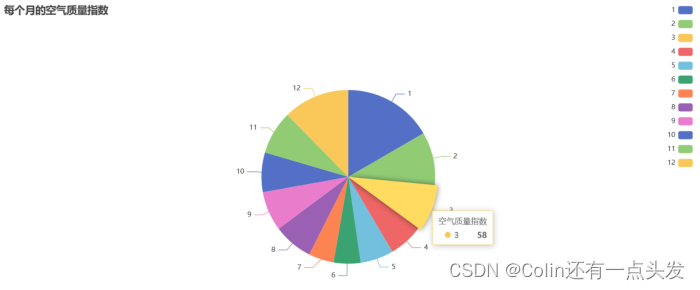
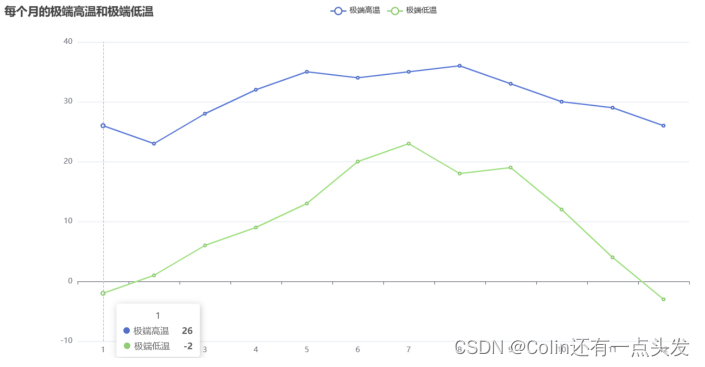
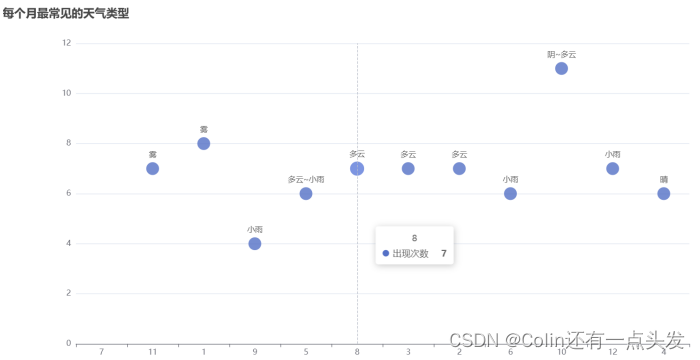
通过本系统的开发和实施,不仅实现了对天气数据的全面分析和展示,也为天气数据的科学决策提供了有力支持。未来,我们将继续优化数据分析算法,提升系统性能,并增加更多数据源和分析维度,力求为用户提供更优质的天气数据分析服务。
V - WeiDaPang_T
Q - 977266623
版权归原作者 Colin还有一点头发 所有, 如有侵权,请联系我们删除。