
Web Spider NEX XX国际货币经纪 - PDF下载 & 解析
首先声明: 此次案例只为学习交流使用,切勿用于其他非法用途
文章目录
前言
目标网站:https://www.cfets-nex.com.cn/
提示:以下是本篇文章正文内容,下面案例可供参考
一、任务说明
1.PDF下载
提示:下载2019年1月1日-至今的"银行间货币市场"PDF文件
下图网址:https://www.cfets-nex.com.cn/Market/marketOverview/dailyReview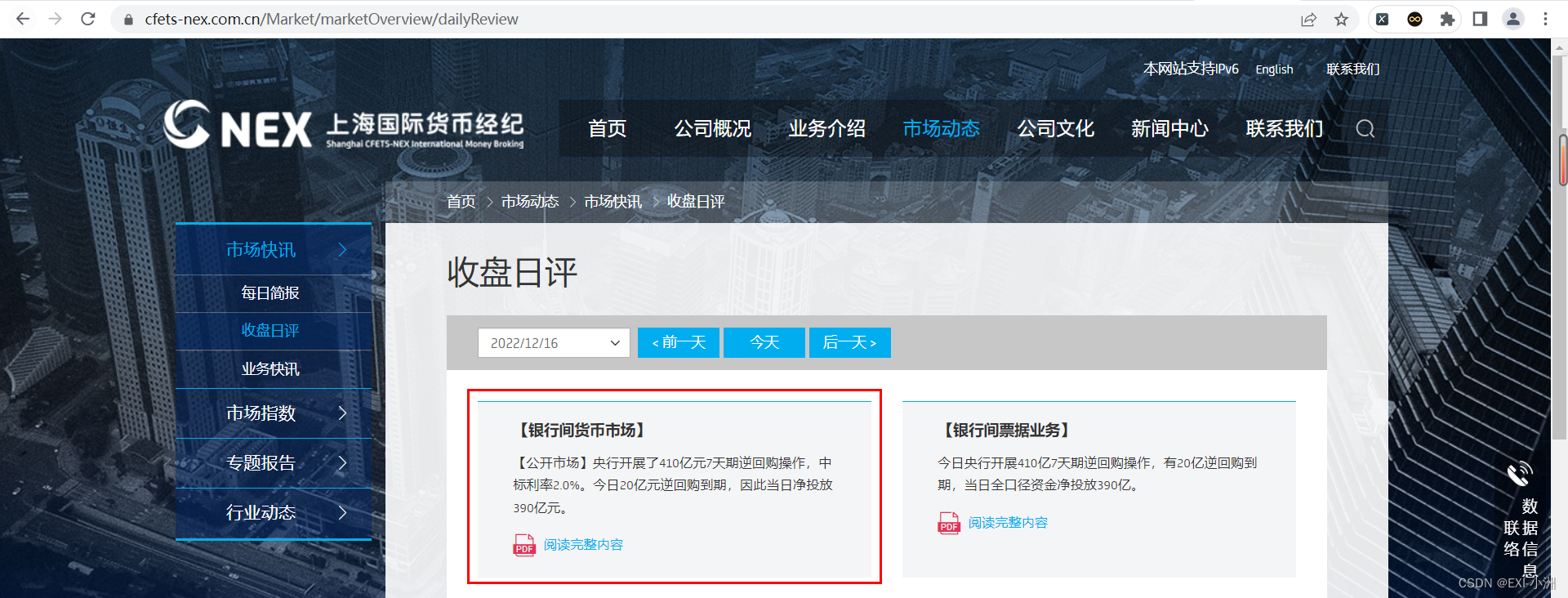
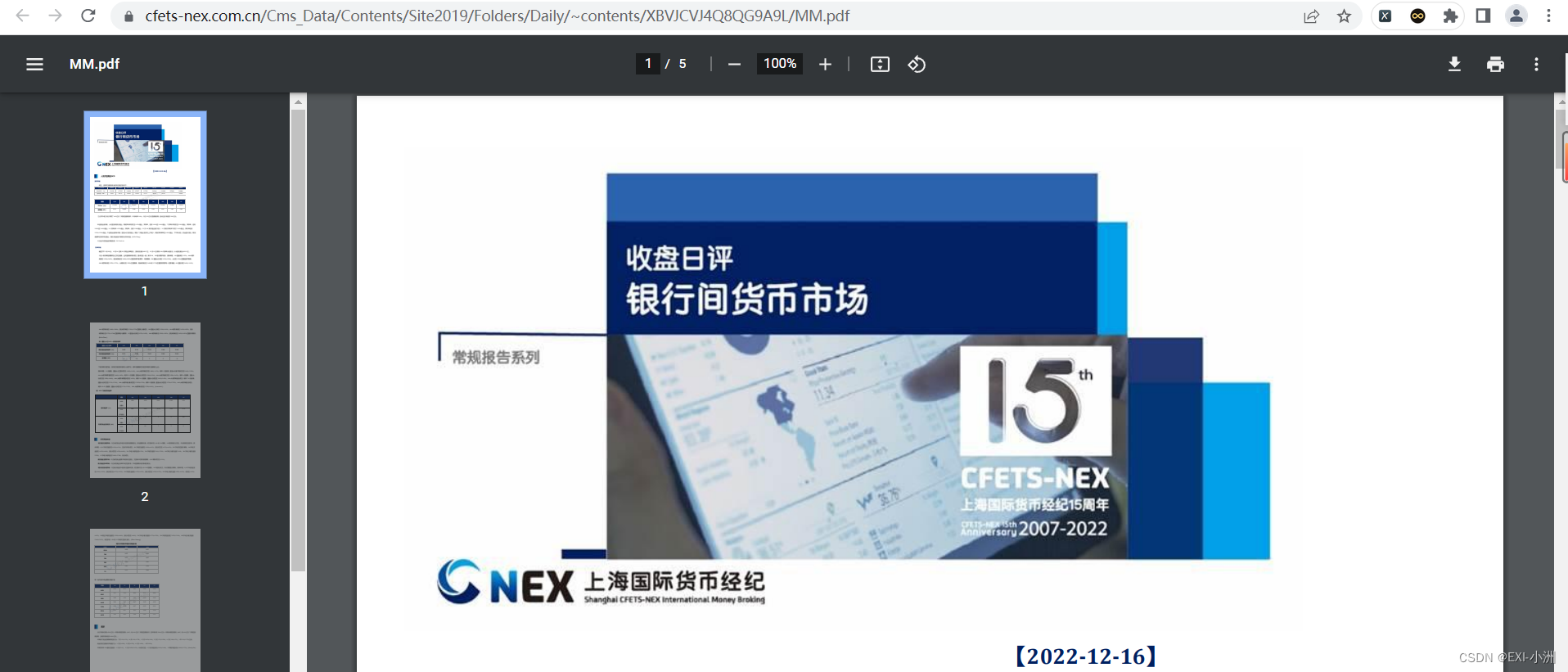
2.PDF解析提取关键词数据
提取关键词数据说明
- 提取下图标红框处位置的内容,如果不存在则赋值"None";
- 红框处1:以"今日资金面"开头,句号(。)结束;
- 红框处2:以"资金面情绪指数"开头,换行(\n)结束;
- 以上为主要的提取部分,有些开头的关键词不同,需要另外写点匹配规则,参考案例;
提示:如果有更好的提取方式可以在评论处留言或者私信我,让我们在IT社区平台共同进步,感谢!
二、Pip模块安装
镜像地址
- 清华:https://pypi.tuna.tsinghua.edu.cn/simple
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
- 华中理工大学:http://pypi.hustunique.com/
- 山东理工大学:http://pypi.sdutlinux.org/
- 豆瓣:http://pypi.douban.com/simple/
案例使用到的模块以及对应版本
- pandas==1.1.3
- PyPDF2==2.12.1
- requests==2.27.0
pip指定模块安装:pip install 模块名 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip指定requirements.txt文件安装:pip install -i https://pypi.doubanio.com/simple/ -r requirements.txt
三、网站分析
1、打开链接,可以发现一个规律,每天收盘日评的网站链接是由相应的日期字符串组成;
链接后面的时间字符串为:2022/12/15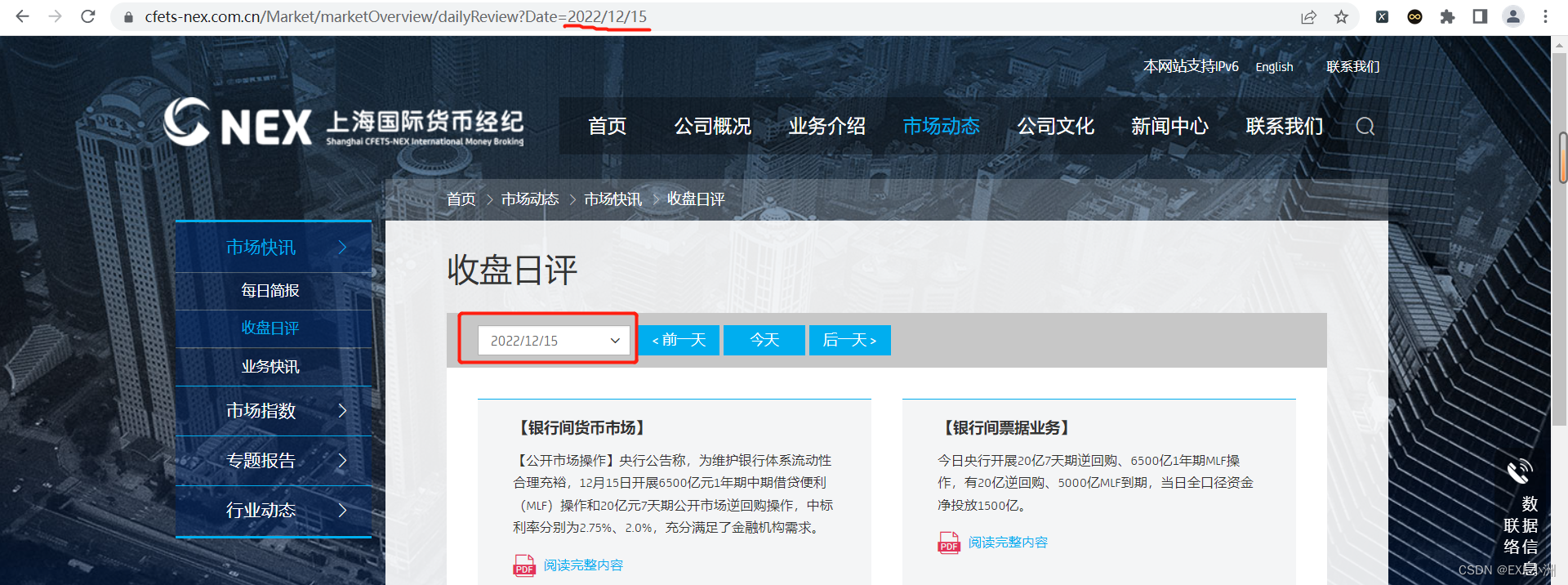
链接后面的时间字符串为:2022/12/16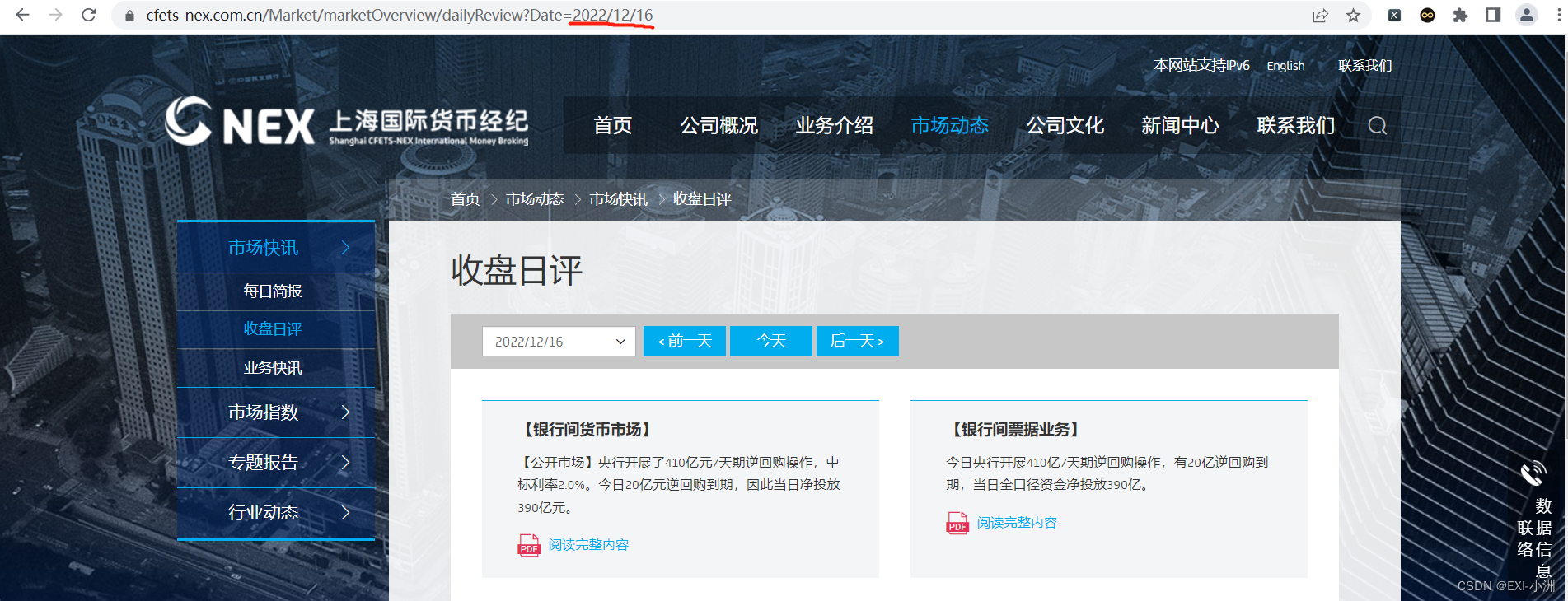 2、按F12进入开发者模式,可以直接看到PDF的链接,直接请求网站就完事了;
2、按F12进入开发者模式,可以直接看到PDF的链接,直接请求网站就完事了;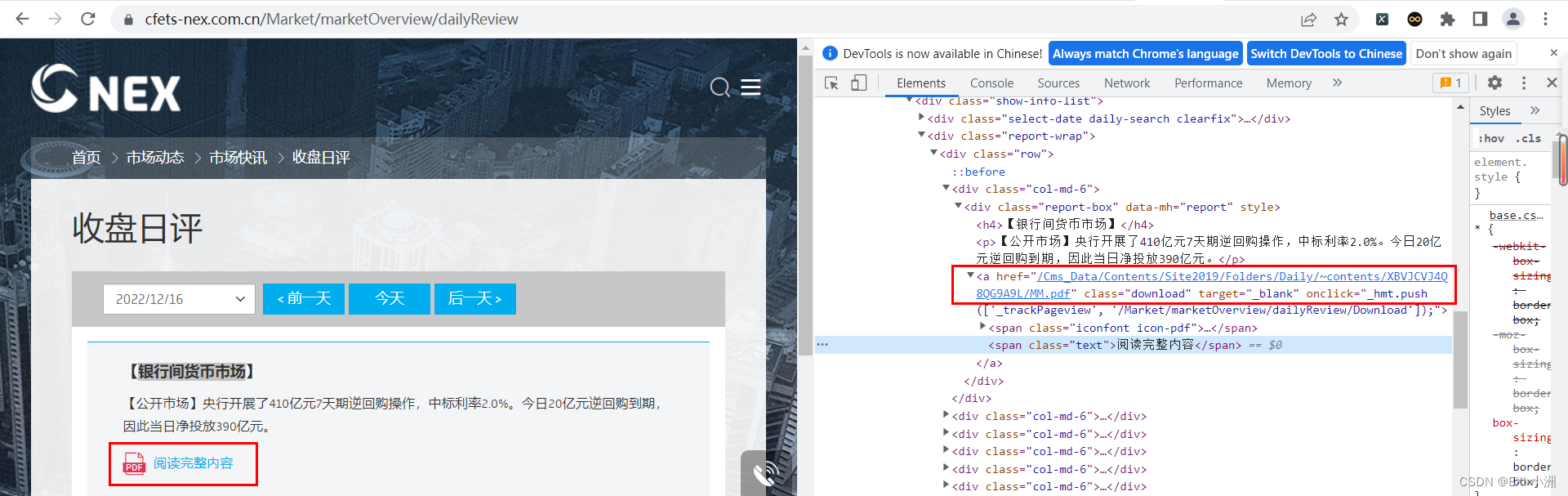
标签a的href:/Cms_Data/Contents/Site2019/Folders/Daily/contents/XBVJCVJ4Q8QG9A9L/MM.pdfcontents/XBVJCVJ4Q8QG9A9L/MM.pdf
根据经验前缀需要加上:https://www.cfets-nex.com.cn
组合后可以直接打开PDF:https://www.cfets-nex.com.cn/Cms_Data/Contents/Site2019/Folders/Daily/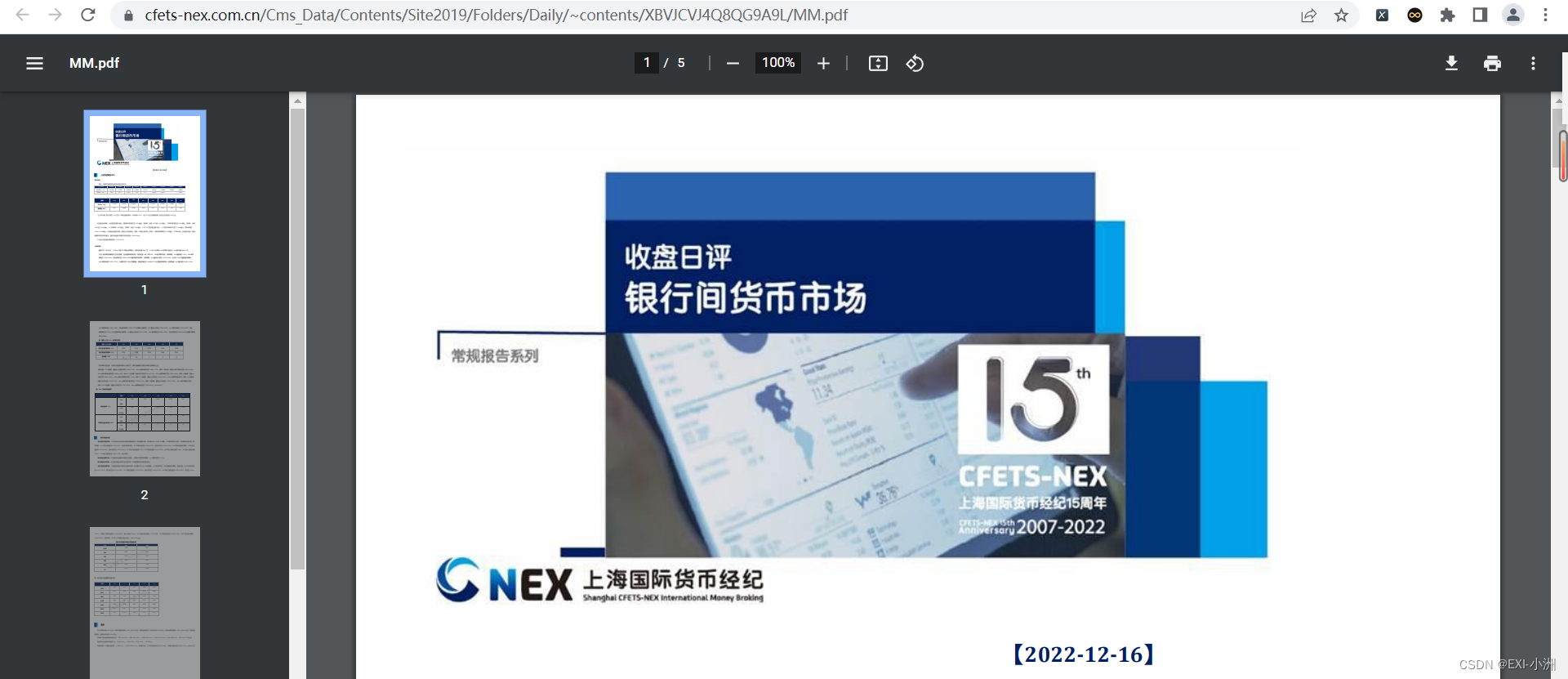
四、核心代码注释
1.创建2019年1月1日-至今的时间字符串,存入列表中
import datetime
start_string ='2019-01-01'
def create_date_list():
start_date = datetime.datetime.strptime(start_string ,"%Y-%m-%d") # 将指定的字符串转为时间格式
now_date =(datetime.datetime.now()).strftime("%Y-%m-%d") # 获取当前的时间
date_string_list =list()
i =0while True:
date_i =(start_date + datetime.timedelta(days=i)).strftime('%Y-%m-%d')
date_string =str(date_i).replace('-','/')print("创建时间字符串 - 存储成功:", date_string)
date_string_list.append(date_string)if date_i < now_date:
i +=1else:breakreturn date_string_list
2.pdf下载
import requests
headers ={'user-agent': 'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
def pdf_download():
file_path ="result.pdf"
pdf_url ='https://xxxx.pdf'
response = requests.get(url=pdf_url, headers=headers, timeout=5)
with open(file_path,'wb') as fis:for chunk in response.iter_content(chunk_size=1000):
fis.write(chunk)
fis.flush()print(f'下载完成:{file_path}')return True
3.pdf读取解析
import PyPDF2
pdffile =open(file=file_path, mode='rb') # 读取pdf文件;
pdfreader = PyPDF2.PdfFileReader(pdffile)
pdf_content =''for i in range(pdfreader.numPages): # 获取pdf的总页数;
page_content = pdfreader.getPage(i) # 获取第i页的对象;
pdf_content += page_content.extractText() # 提取第i页的对象内容,字符串类型;parse(pdf_content) # 自定义一个解析内容的方法,根据自己的需求提取相应的内容;
五、运行结果
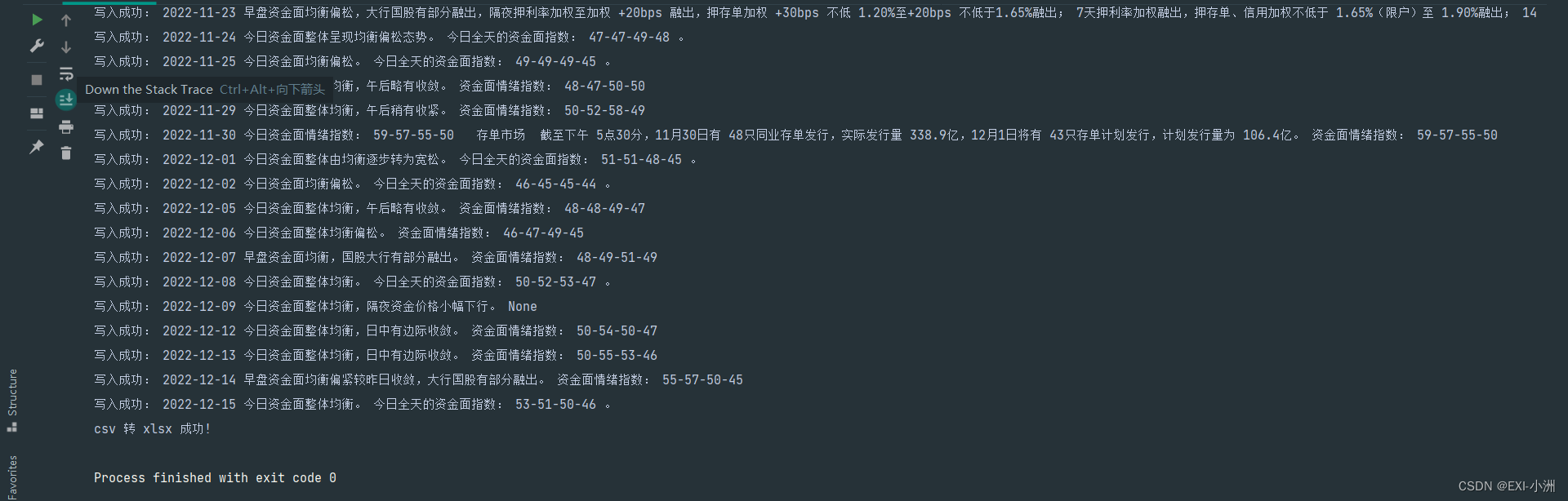
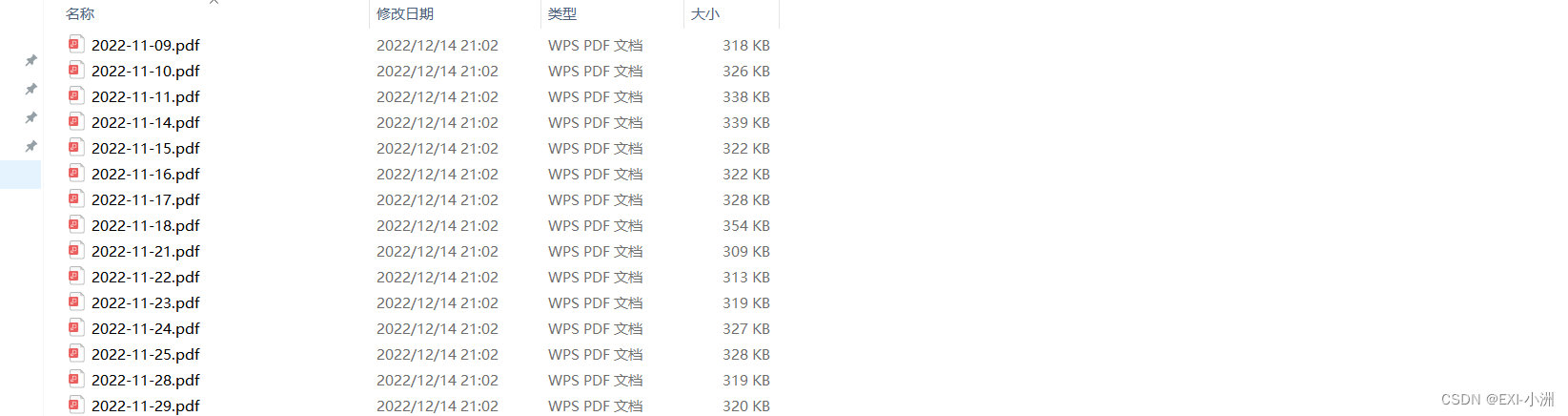
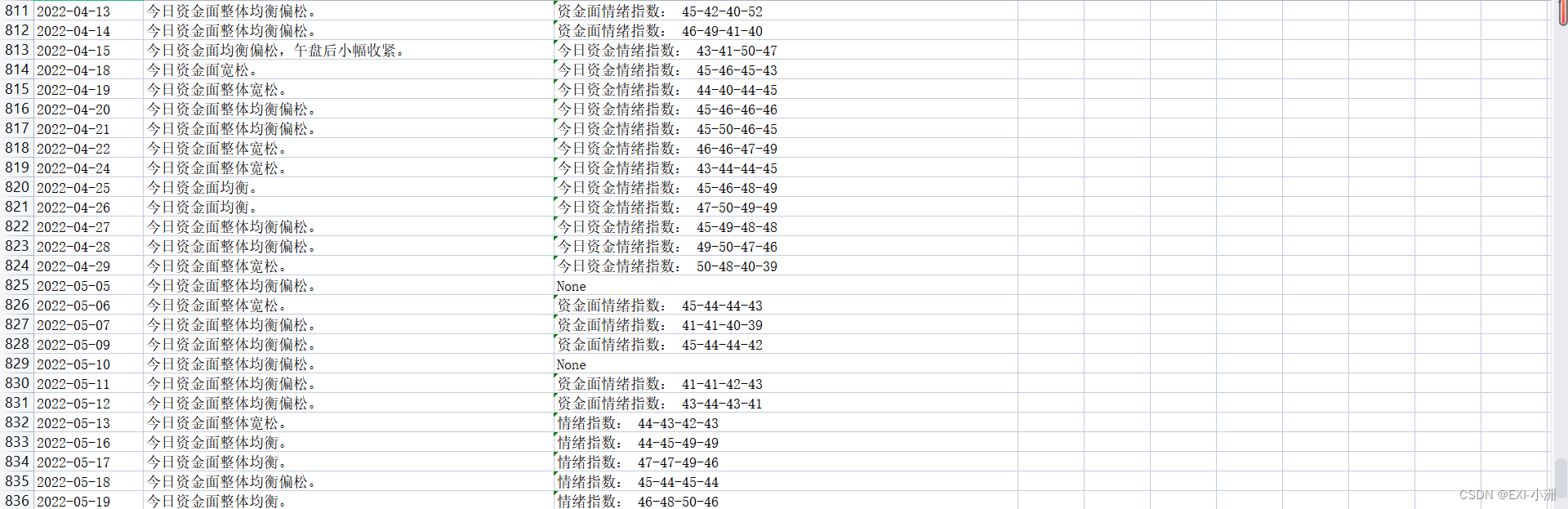
六、示例代码
import os
import re
import time
import PyPDF2
import datetime
import requests
import pandas as pd
from requests import exceptions as request_exceptions
class SHICEconomy(object):
def __init__(self):
self.headers ={'user-agent': 'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) '
'Chrome/95.0.4638.69 Safari/537.36'
}
self.start_string ='2019-01-01'
self.resource_path ='resource'
self.result_file_path ='result.csv'
def create_date_list(self):
start_date = datetime.datetime.strptime(self.start_string,"%Y-%m-%d") # 将指定的字符串转为时间格式
now_date =(datetime.datetime.now()).strftime("%Y-%m-%d") # 获取当前的时间
date_string_list =list()
i =0while True:
date_i =(start_date + datetime.timedelta(days=i)).strftime('%Y-%m-%d')
date_string =str(date_i).replace('-','/')print("创建时间字符串 - 存储成功:", date_string)
date_string_list.append(date_string)if date_i < now_date:
i +=1else:breakreturn date_string_list
def request_server(self, url):
request_count =0
request_total =3
result ={'status': False}while request_count < request_total:
try:
response = requests.get(url=url, headers=self.headers, timeout=5)
result ={'status': True,'response': response}break
except request_exceptions.ConnectTimeout:print(f'{url} - 请求失败 ConnectTimeout!\n', end='')
except request_exceptions.RequestException:print(f'{url} - 请求失败 RequestException!\n', end='')
request_count +=1
time.sleep(1)return result
def pdf_download(self, file_path, pdf_url):""" pdf下载 """
download_result ={'status': False}
request_result = self.request_server(url=pdf_url)if request_result['status'] is False:return download_result
response = request_result['response']
with open(file_path,'wb') as fis:for chunk in response.iter_content(chunk_size=1000):
fis.write(chunk)
fis.flush()print(f'下载完成:{file_path}')
download_result ={'status': True}return download_result
def read_finished_download_path(self):
finished_download_pdf_list =list()for path in os.listdir(self.resource_path):
file_path = f'{self.resource_path}/{path}'
finished_download_pdf_list.append(file_path)return finished_download_pdf_list
def pdf_download_controller(self, date_string_list=[]):""" pdf下载控制 """
finished_download_pdf_list = self.read_finished_download_path() # 获取已经下载的pdf地址
for date_string in date_string_list:
file_path = f"{self.resource_path}/{date_string.replace('/', '-')}.pdf" # 拼接下载文件路径
if file_path in finished_download_pdf_list:print(f"已下载:{file_path}")continue
url = f'https://www.cfets-nex.com.cn/Market/marketOverview/dailyReview?Date={date_string}'
request_result = self.request_server(url=url)if request_result['status'] is False: # pdf请求状态
print(f"请求失败:{url}")continue
html_text = request_result['response'].text
pdf_re = re.search(pattern="银行间货币市场.*?href='(.*?)'", string=html_text, flags=re.S) # 匹配pdf下载地址
pdf_prefix ='https://www.cfets-nex.com.cn'if pdf_re is None:print(f"当天无数据(或还未发布数据):{url}")continueelse:
pdf_suffix = pdf_re.group(1)
pdf_url = pdf_prefix + pdf_suffix
download_result = self.pdf_download(file_path, pdf_url) # 下载pdf
if download_result['status'] is False: # pdf下载状态
print(f"下载失败:{url}")continue
finished_download_pdf_list.append(file_path) # 存储下载成功之后的文件地址
return finished_download_pdf_list
def pdf_parse(self, pdf_path_list):for file_path in pdf_path_list:
column1_content = file_path.split('/')[-1].split('.pdf')[0]
try:
pdffile =open(file=file_path, mode='rb') # 读取pdf文件
pdfreader = PyPDF2.PdfFileReader(pdffile)
except Exception:
content = f"{column1_content},None,None\n"
self.csv_save(content)print(f"{file_path} - PDF读取异常")continue
pdf_content =''for i in range(pdfreader.numPages): # 获取pdf的总页数
page_content = pdfreader.getPage(i) # 获取第i页的对象
pdf_content += page_content.extractText() # 提取第i页的对象内容
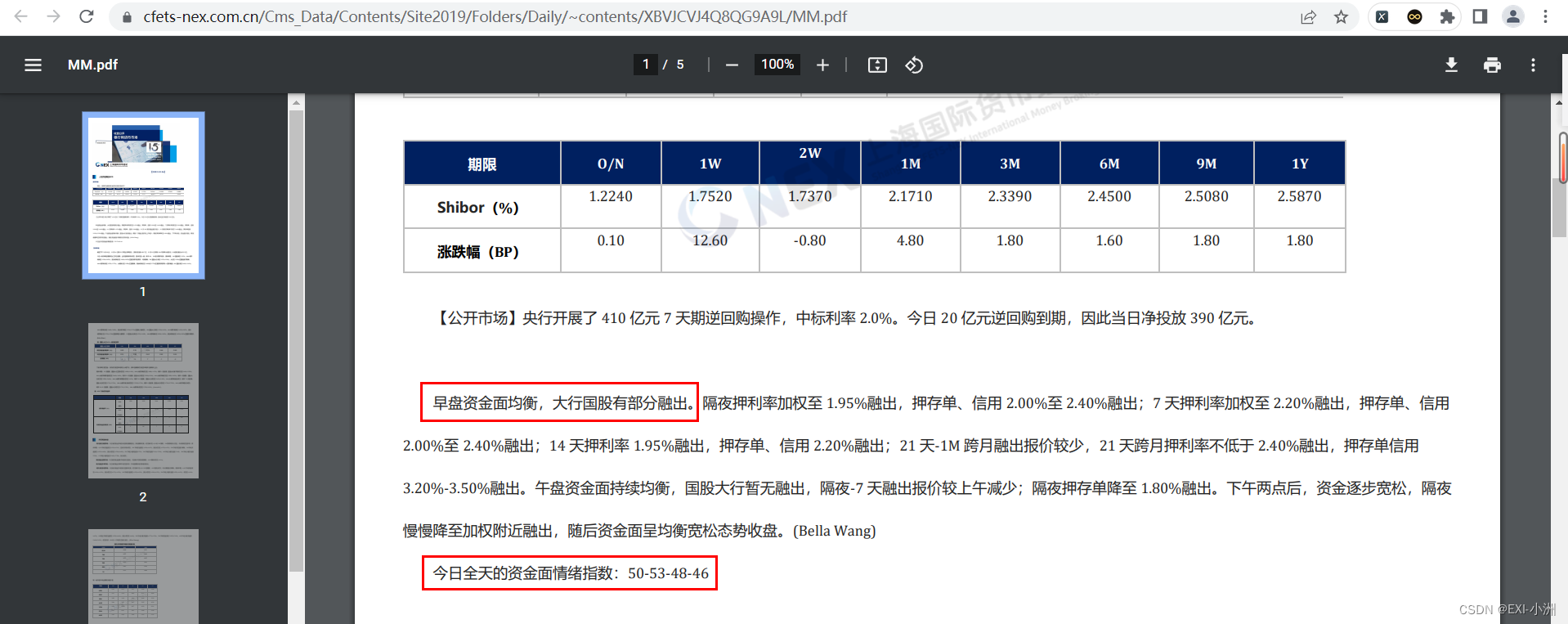
column2_1_re = re.search(pattern='今.{0,1}资金面(.*?)。', string=pdf_content, flags=re.S)
column2_2_re = re.search(pattern='早盘资金面(.*?)。', string=pdf_content, flags=re.S)if column2_1_re:
column2_content = f'{column2_1_re.group()}'.replace('\n','').replace(',',',')
elif column2_2_re:
column2_content = f'{column2_2_re.group()}'.replace('\n','').replace(',',',')else:
column2_content ='None'
column3_1_re = re.search(pattern='资金面情绪指数(.*?)\n', string=pdf_content, flags=re.S)
column3_2_re = re.search(pattern='今日全天的资金面指数(.*?)\n', string=pdf_content, flags=re.S)
column3_3_re = re.search(pattern='今日资金.{0,1}情绪指数(.*?)\n', string=pdf_content, flags=re.S)
column3_4_re = re.search(pattern='情绪指数(.*?)\n', string=pdf_content, flags=re.S)if column3_1_re:
column3_content = f'资金面情绪指数{column3_1_re.group(1)}'.replace('\n','').replace(',',',')
elif column3_2_re:
column3_content = f'今日全天的资金面指数{column3_2_re.group(1)}。'.replace('\n', '').replace(',', ',')
elif column3_3_re:
column3_content = f'{column3_3_re.group()}'.replace('\n','').replace(',',',')
elif column3_4_re:
column3_content = f'{column3_4_re.group()}'.replace('\n','').replace(',',',')else:
column3_content ='None'
content = f"{column1_content},{column2_content},{column3_content}\n"
self.csv_save(content)print("写入成功:", column1_content, column2_content, column3_content)return True
def create_file(self):if os.path.exists(self.resource_path) is False:
os.mkdir(self.resource_path)
with open(file=self.result_file_path, mode='w', encoding='utf-8') as fis:
fis.write('日期,今日资金面,资金面情绪指数\n')
def csv_save(self, content):
with open(file=self.result_file_path, mode='a+', encoding='utf-8') as fis:
fis.write(content)
def csv_save_as_xlsx(self):""" 读取csv文件将结果写入xlsx """
filename_prefix = os.path.splitext(self.result_file_path)[0] # 切割文件路径以及后缀
df = pd.read_csv(self.result_file_path, encoding='utf-8', dtype='object')
df.to_excel(f"{filename_prefix}.xlsx", index=False)print("csv 转 xlsx 成功!")
def runs(self):
self.create_file()
date_string_list = self.create_date_list()
pdf_path_list = self.pdf_download_controller(date_string_list)
self.pdf_parse(pdf_path_list)
self.csv_save_as_xlsx()if __name__ =='__main__':SHICEconomy().runs()
总结
此次案例只为学习交流使用,若有侵犯网站利益的地方请及时联系我下架该博文;
在此我抛出两个问题,欢迎在评论区讨论或者私信我,感谢赐教!:
问题1:如何通过requests请求pdf链接拿到二进制内容后直接使用pdf解析模块进行解析;
问题2:如何以更好的方式提取pdf的关键词内容;
版权归原作者 EXI-小洲 所有, 如有侵权,请联系我们删除。