
面试官:一千万的数据,你是怎么查询的?
1 先给结论
对于1千万的数据查询,主要关注分页查询过程中的性能
针对偏移量大导致查询速度慢:
先对查询的字段创建唯一索引
根据业务需求,先定位查询范围(对应主键id的范围,比如大于多少、小于多少、IN)
查询时,将第2步确定的范围作为查询条件
针对查询数据量大的导致查询速度慢:
查询时,减少不需要的列,查询效率也可以得到明显提升 一次尽可能按需查询较少的数据条数 借助nosql缓存数据等来减轻mysql数据库的压力
2 准备数据
2.1 创建表
CREATE TABLE `user_operation_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`ip` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`op_data` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr3` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr4` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr5` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr6` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr7` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr8` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr9` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr10` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr11` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`attr12` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`)USING BTREE
) ENGINE =InnoDB AUTO_INCREMENT =1CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT =Dynamic;
2.2 造数据脚本
采用批量插入,效率会快很多,而且每1000条数就commit,数据量太大,也会导致批量插入效率慢
DELIMITER ;;CREATE DEFINER=`root`@`%` PROCEDURE `batch_insert_log`()
BEGIN
DECLARE i INT DEFAULT1;
DECLARE userId INT DEFAULT10000000;
set @execSql= 'INSERT INTO `big_data`.`user_operation_log`(`user_id`, `ip`, `op_data`, `attr1`, `attr2`, `attr3`, `attr4`, `attr5`, `attr6`, `attr7`, `attr8`, `attr9`, `attr10`, `attr11`, `attr12`) VALUES';
set @execData= '';
WHILE i<=10000000 DO
set @attr="rand_string(50)";
set @execData=concat(@execData,"(", userId + i,", '110.20.169.111', '用户登录操作'",",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,",",@attr,")");if i %1000=0
then
set @stmtSql=concat(@execSql,@execData,";");
prepare stmt from @stmtSql;
execute stmt;
DEALLOCATE prepare stmt;
commit;
set @execData="";else
set @execData=concat(@execData,",");
end if;SET i=i+1;END WHILE;END
DELIMITER ;
delimiter $$
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
#chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare chars_str varchar(100)default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255)default '';
declare i intdefault0;while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i +1;
end while;return return_str;
end $$
2.3 执行存储过程函数
因为模拟数据流量是1000W,我这电脑配置不高,耗费了不少时间,应该个把小时吧
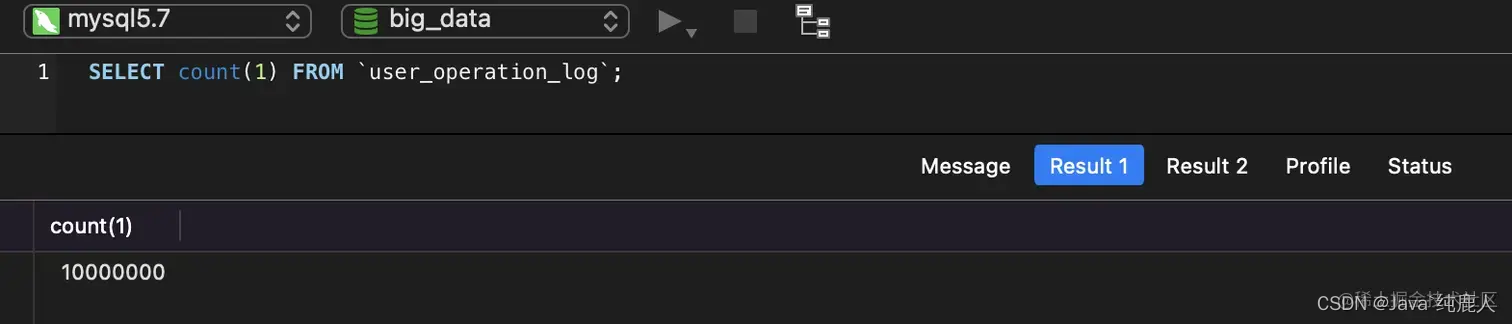
SELECTcount(1) FROM `user_operation_log`;
2.4 普通分页查询
MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
MySQL分页查询语法如下:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
- 第一个参数指定第一个返回记录行的偏移量
- 第二个参数指定返回记录行的最大数目
下面我们开始测试查询结果:
SELECT * FROM `user_operation_log` LIMIT10000,10;
查询3次时间分别为: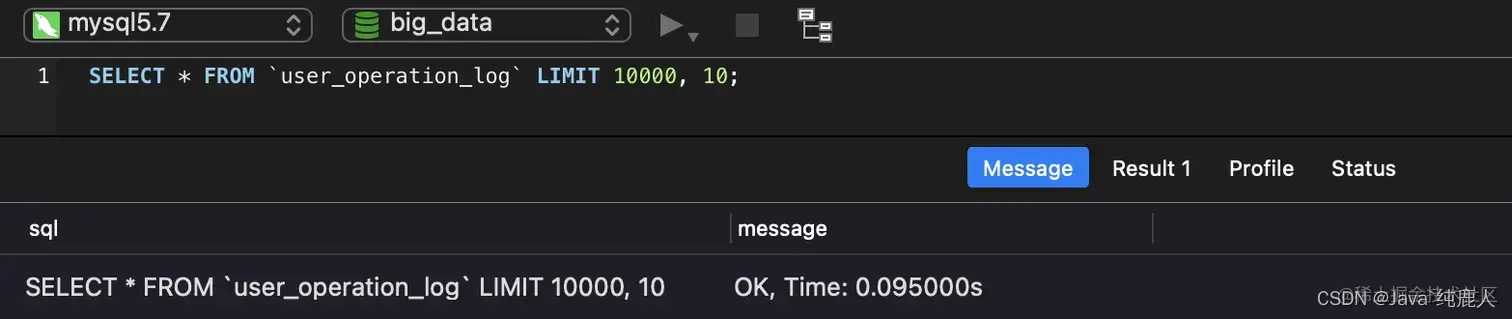


这样看起来速度还行,不过是本地数据库,速度自然快点。
换个角度来测试
相同偏移量,不同数据量
SELECT * FROM `user_operation_log` LIMIT10000,10;
SELECT * FROM `user_operation_log` LIMIT10000,100;
SELECT * FROM `user_operation_log` LIMIT10000,1000;
SELECT * FROM `user_operation_log` LIMIT10000,10000;
SELECT * FROM `user_operation_log` LIMIT10000,100000;
SELECT * FROM `user_operation_log` LIMIT10000,1000000;
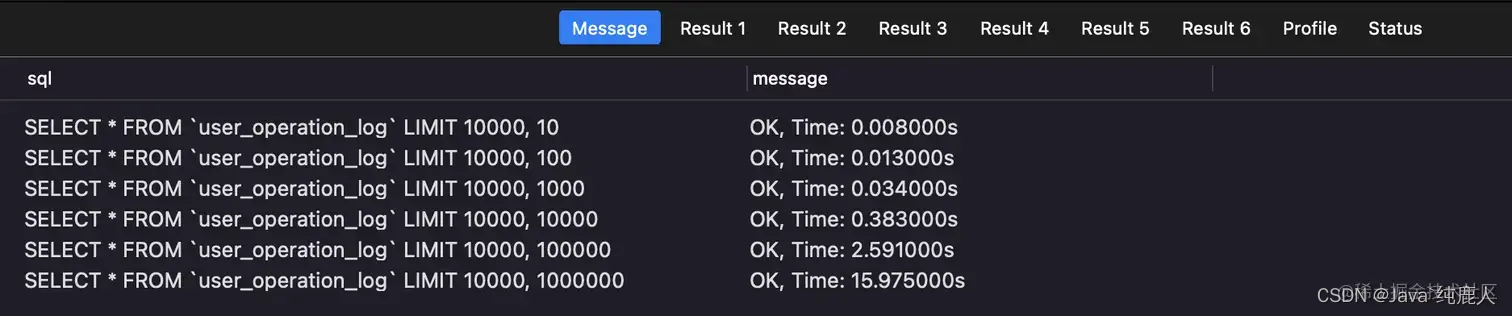
从上面结果可以得出结束:数据量越大,花费时间越长(这不是废话吗?)
相同数据量,不同偏移量
SELECT * FROM `user_operation_log` LIMIT100,100;
SELECT * FROM `user_operation_log` LIMIT1000,100;
SELECT * FROM `user_operation_log` LIMIT10000,100;
SELECT * FROM `user_operation_log` LIMIT100000,100;
SELECT * FROM `user_operation_log` LIMIT1000000,100;

从上面结果可以得出结束:偏移量越大,花费时间越长
3 如何优化
既然我们经过上面一番的折腾,也得出了结论,针对上面两个问题:偏移大、数据量大,我们分别着手优化
3.1 优化数据量大的问题
SELECT * FROM `user_operation_log` LIMIT1,1000000
SELECT id FROM `user_operation_log` LIMIT1,1000000SELECT id, user_id, ip, op_data, attr1, attr2, attr3, attr4, attr5, attr6, attr7, attr8, attr9, attr10, attr11, attr12 FROM `user_operation_log` LIMIT1,1000000
查询结果如下:
上面模拟的是从1000W条数据表中 ,一次查询出100W条数据,看起来性能不佳,但是我们常规业务中,很少有一次性从mysql中查询出这么多条数据量的场景。可以结合nosql缓存数据等等来减轻mysql数据库的压力。
因此,针对查询数据量大的问题:
查询时,减少不需要的列,查询效率也可以得到明显提升 一次尽可能按需查询较少的数据条数 借助nosql缓存数据等来减轻mysql数据库的压力
第一条和第三条查询速度差不多,这时候你肯定会吐槽,那我还写那么多字段干啥呢,直接 * 不就完事了
注意本人的 MySQL 服务器和客户端是在同一台机器上,所以查询数据相差不多,有条件的同学可以测测客户端与MySQL分开
SELECT * 它不香吗?
在这里顺便补充一下为什么要禁止 SELECT *。难道简单无脑,它不香吗?
主要两点:
- 用 "SELECT * " 数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
- 增大网络开销,* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。特别是MySQL和应用程序不在同一台机器,这种开销非常明显。
3.2 优化偏移量大的问题
3.2.1 采用子查询方式
我们可以先定位偏移位置的 id,然后再查询数据
SELECT id FROM `user_operation_log` LIMIT1000000,1;
SELECT * FROM `user_operation_log` WHERE id >=(SELECT id FROM `user_operation_log` LIMIT1000000,1)LIMIT10;
查询结果如下:
这种查询效率不理想啊!!!奇怪,id是主键,主键索引不应当查询这么慢啊???
先EXPLAIN分析下sql语句:
EXPLAIN SELECT id FROM `user_operation_log` LIMIT1000000,1;
EXPLAIN SELECT * FROM `user_operation_log` WHERE id >=(SELECT id FROM `user_operation_log` LIMIT1000000,1)LIMIT10;
奇怪,走了索引啊,而且是主键索引,如下

带着十万个为什么和千万个不甘心,尝试给主键再加一层唯一索引
ALTER TABLE `big_data`.`user_operation_log`
ADD UNIQUE INDEX `idx_id`(`id`)USING BTREE;
由于数据量有1000W,所以,加索引需要等待一会儿,毕竟创建1000W条数据的索引,一般机器没那么快。
然后再次执行上面的查询,结果如下: 天啊,这查询效率的差距不止十倍!!!
天啊,这查询效率的差距不止十倍!!!
再次EXPLAIN分析一下:

命中的索引不一样,命中唯一索引的查询,效率高出不止十倍。
结论:
对于大表查询,不要太相信主键索引能够带来多少的性能提升,老老实实根据查询字段,添加相应索引吧!!!
但是上面的方法只适用于id是递增的情况,如果id不是递增的,比如雪花算法生成的id,得按照下面的方式:
注意:
- 某些 mysql 版本不支持在 in 子句中使用 limit,所以采用了多个嵌套select
- 但这种缺点是分页查询只能放在子查询里面
SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT1000000,10)AS t);
查询所花费时间如下:
EXPLAIN一下
EXPLAIN SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT1000000,10)AS t);

3.2.2 采用 id 限定方式
这种方法要求更高些,id必须是连续递增(注意是连续递增,不仅仅是递增哦),而且还得计算id的范围,然后使用 between,sql如下
SELECT * FROM `user_operation_log` WHERE id between 1000000 AND 1000100LIMIT100;
SELECT * FROM `user_operation_log` WHERE id >=1000000LIMIT100;

可以看出,查询效率是相当不错的
注意:这里的 LIMIT 是限制了条数,没有采用偏移量
还是EXPLAIN分析一下
EXPLAIN SELECT * FROM `user_operation_log` WHERE id between 1000000 AND 1000100LIMIT100;
EXPLAIN SELECT * FROM `user_operation_log` WHERE id >=1000000LIMIT100;


因此,针对分页查询,偏移量大导致查询慢的问题:
先对查询的字段创建唯一索引 根据业务需求,先定位查询范围(对应主键id的范围,比如大于多少、小于多少、IN) 查询时,将第2步确定的范围作为查询条件
版权归原作者 Java`纯鹿人 所有, 如有侵权,请联系我们删除。