
一.、创建虚拟机
(10条消息) CentOS 7 虚拟机的搭建_仄言2997的博客-CSDN博客
1. 创建虚拟机
2. 安装 CentOS
二、虚拟机网络设置
(10条消息) 虚拟机网络配置_仄言2997的博客-CSDN博客
三、 安装JDK
(10条消息) 虚拟机安装jdk,运行java文件_仄言2997的博客-CSDN博客
四、 安装 Hadoop
(10条消息) 虚拟机安装Hadoop_仄言2997的博客-CSDN博客
1. 下载并解压
2. 修改配置
五、组成集群(本章)
1、虚拟机克隆与主机配置
2、配置每台主机
** ** (1)主机配置:更改IP地址
(2) 修改主机名(重启后永久生效)
(3)设置ip和域名映射,四台主机都需要修改
3. 免密登录
4、Hadoop集群的配置
(1)修改文件#############workers
** (2) 创建数据和临时文件夹**
5.、格式化 HDFS
六、 启动集群(本章)
1、关闭防火墙
2、 宿主机上做节点映射
3、Hadoop环境变量配置 (对所有节点)
七、 关闭集群(本章)
在上几篇文章中我们已经完成了jdk 以及Hadoop的安装和配置,下面我们就开始Hadoop集群的配置。
组成集群
虚拟机克隆与主机配置
(1)这里推荐采用完整克隆方式,克隆时需要虚拟机处于关机状态。
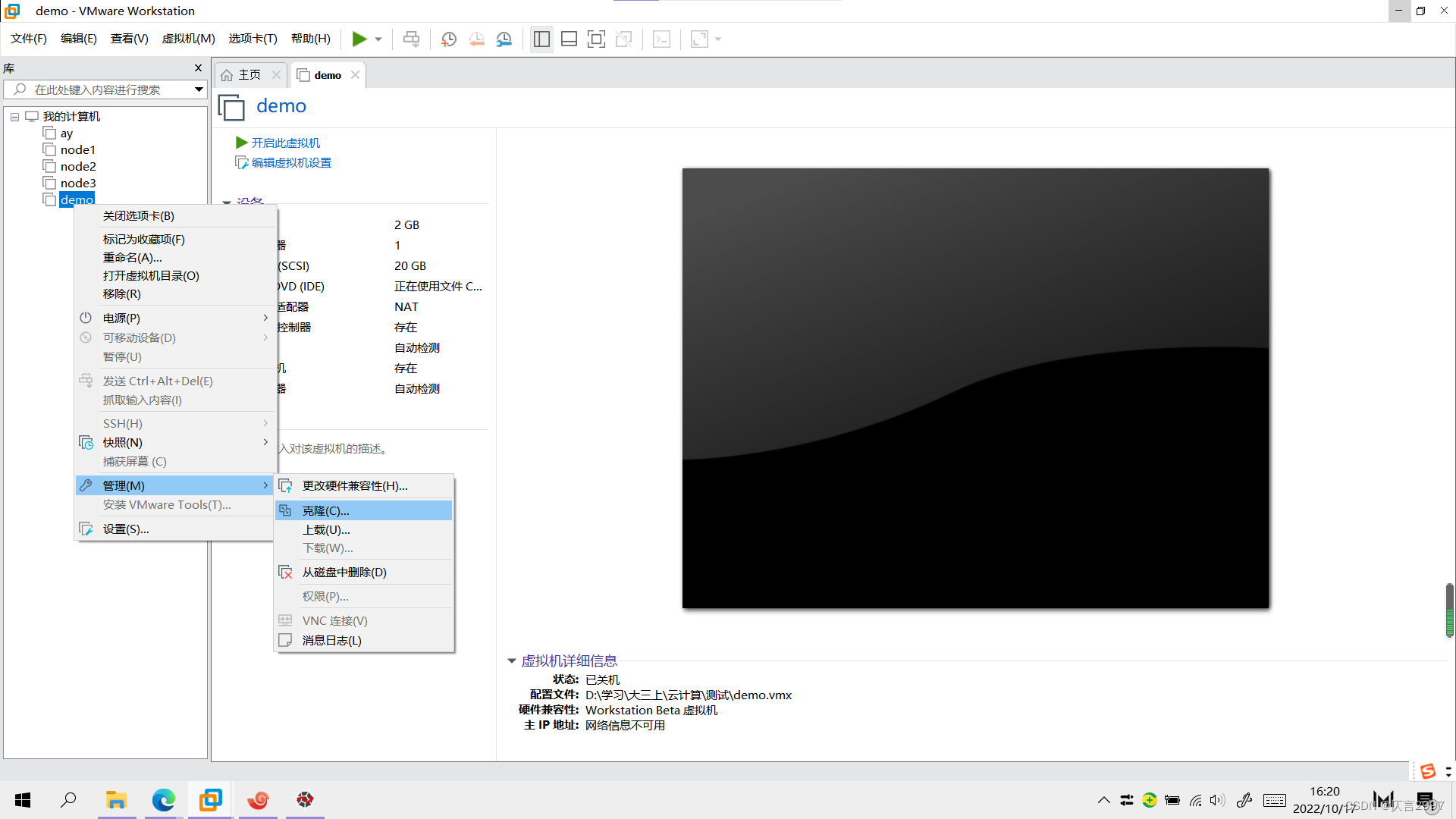
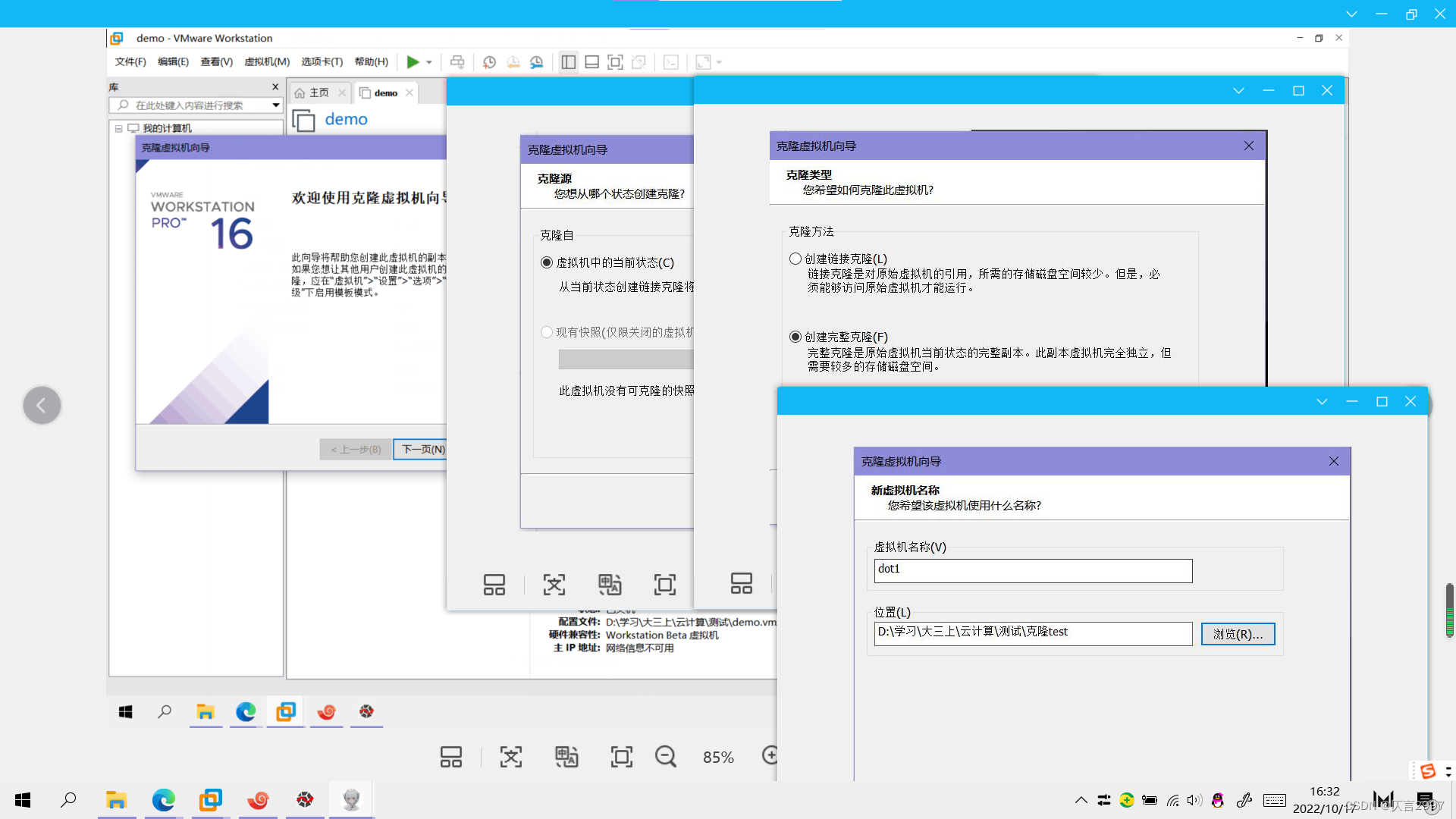
- 配置每台主机
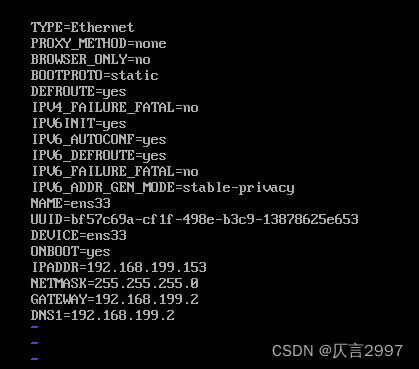
** (1)主机配置:**更改IP地址
设置固定IP命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
dot1: 192.168.230.151
dot2: 192.168.230.152
dot3: 192.168.230.153
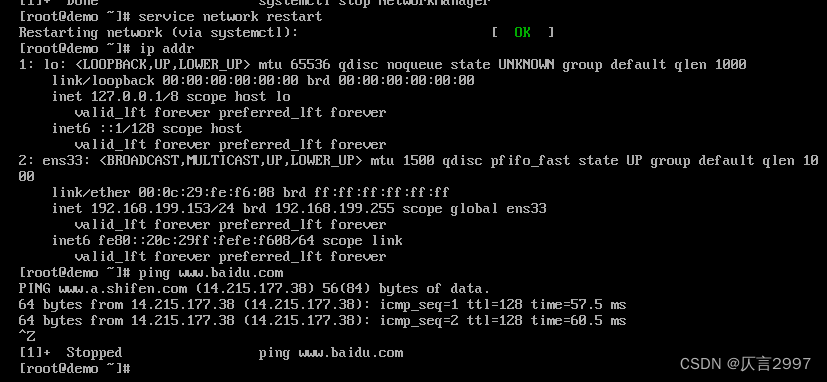
使用ip addr查看ip地址,ping www.baidu.com,ping通表示成功。
**(2) **修改主机名(重启后永久生效)
命令:vi /etc/sysconfig/network
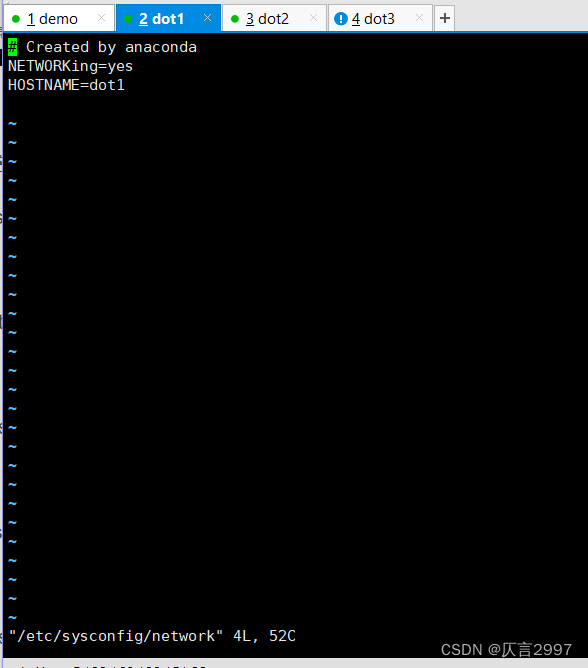
或者 命令:vi /etc/hostname
对于其他节点:
dot1 - vi /etc/hostname
dot1
dot2 - vi /etc/hostname
dot2
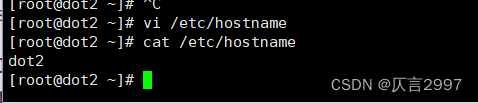
dot3 - vi /etc/hostname
dot3
(3)设置ip和域名映射,四台主机都需要修改
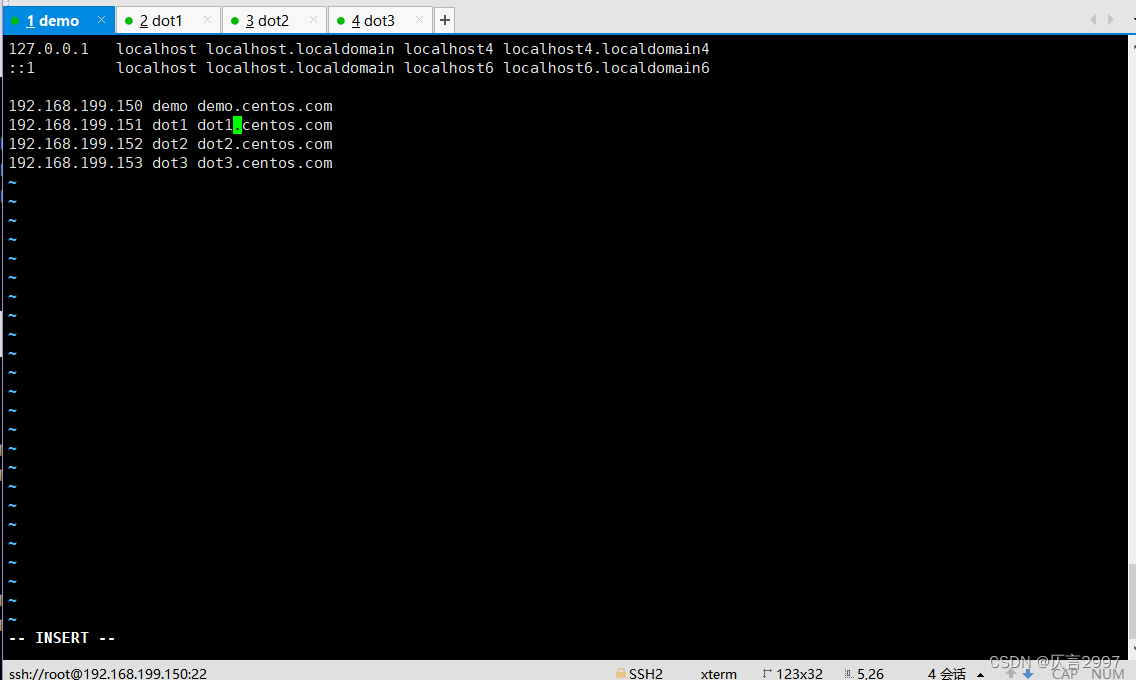
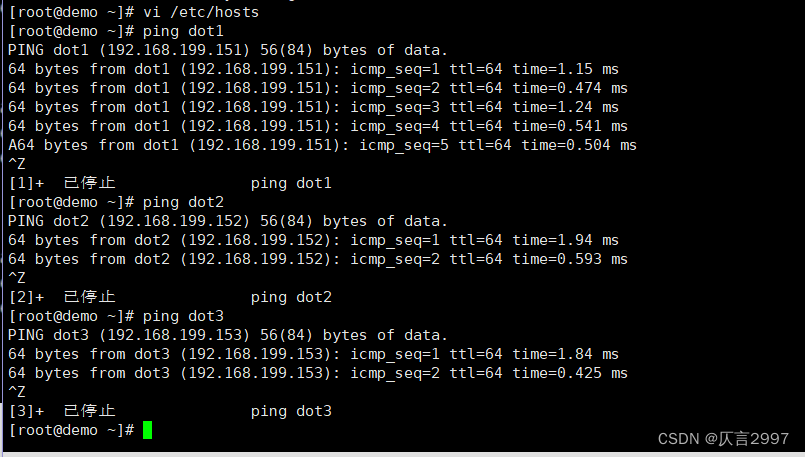
命令:vi /etc/hosts
192.168.199.150 demo demo.centos.com
192.168.199.151 dot1 dot1.centos.com
192.168.199.152 dot2 dot2.centos.com
192.168.199.153 dot3 dot3.centos.com
3. 免密登录
** 免密登录设置步骤**
第一步:四台机器生成公钥与私钥
在四台机器执行以下命令,生成公钥与私钥
ssh-keygen -t rsa
执行该命令之后,按下三个回车即可
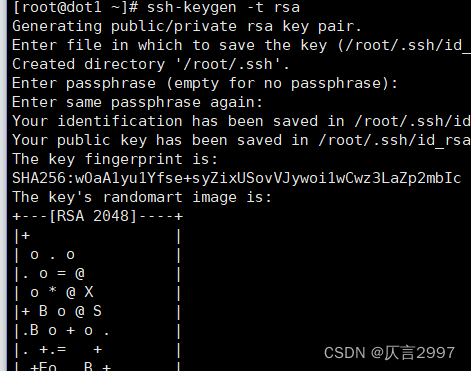
第二步:拷贝公钥到同一台机器
四台机器将拷贝公钥到demo机器
四台机器执行命令:
ssh-copy-id demo
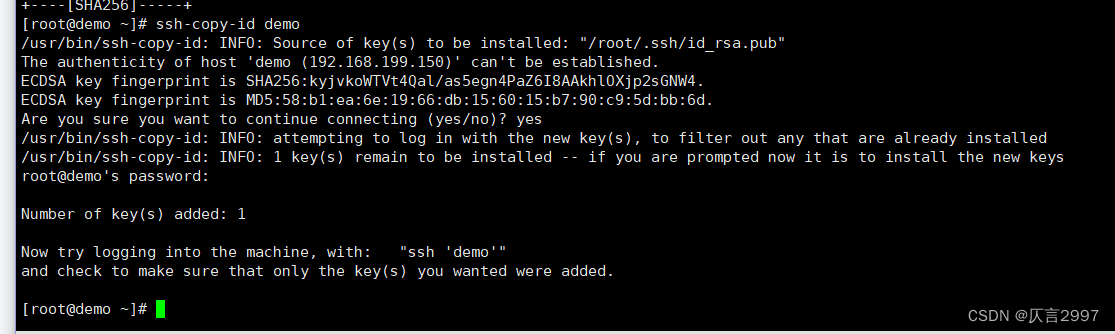
第三步:复制第一台机器的认证到其他机器
将demo机器的公钥拷贝到其他机器上
在demo机器上面指向以下命令
scp /root/.ssh/authorized_keys dot1:/root/.ssh
scp /root/.ssh/authorized_keys dot2:/root/.ssh
scp /root/.ssh/authorized_keys dot3:/root/.ssh

各机器之间实现免密登录
ssh master
ssh node1
ssh node2
ssh node3
exit
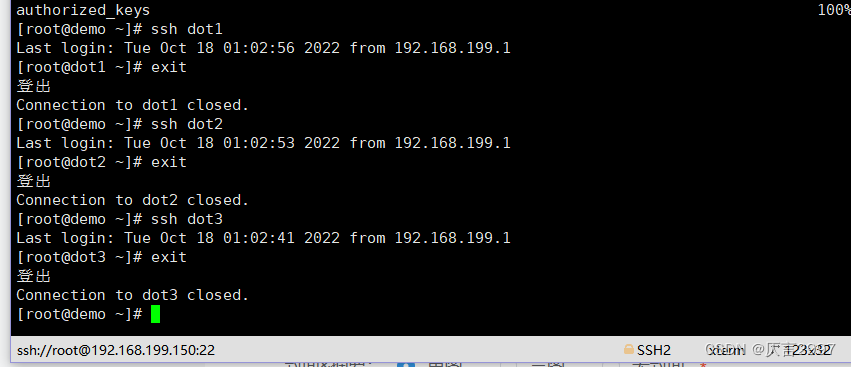
4. 格式化 HDFS
2、Hadoop集群的配置
(1)修改文件#############workers
dot1
dot2
dot3
 (2) 创建数据和临时文件夹
(2) 创建数据和临时文件夹
(3)** 创建数据和临时文件夹**
demo 主节点:
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode
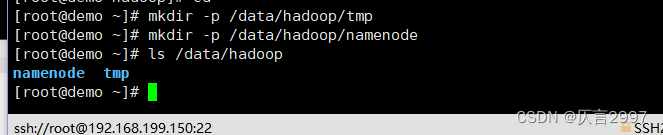
Other dots:
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/datanode
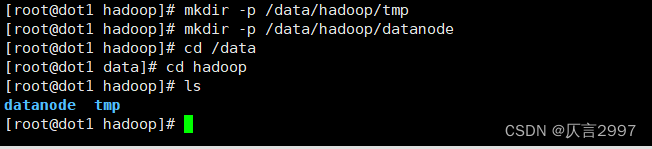
或者在dot节点shell :
ssh dot1“mkdir -p /data/hadoop/tmp & mkdir -p/data/hadoop/datanode”
ssh dot2“mkdir -p /data/hadoop/tmp & mkdir -p/data/hadoop/datanode”
ssh dot3“mkdir -p /data/hadoop/tmp & mkdir -p/data/hadoop/datanode”
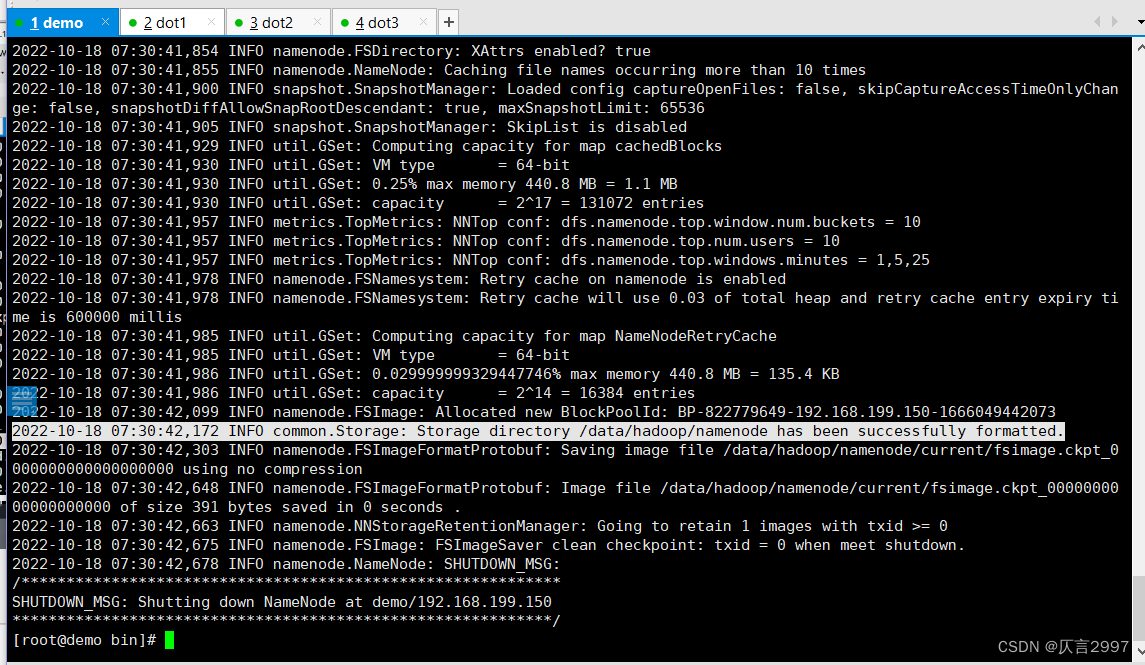
格式化 HDFS
在demo上面:
cd /opt/hadoop-3.1.4
cd bin
./hdfs namenode -format demo
5. 启动集群
** 启动集群**
在demo上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver 或者 mapred --daemon start historyserver
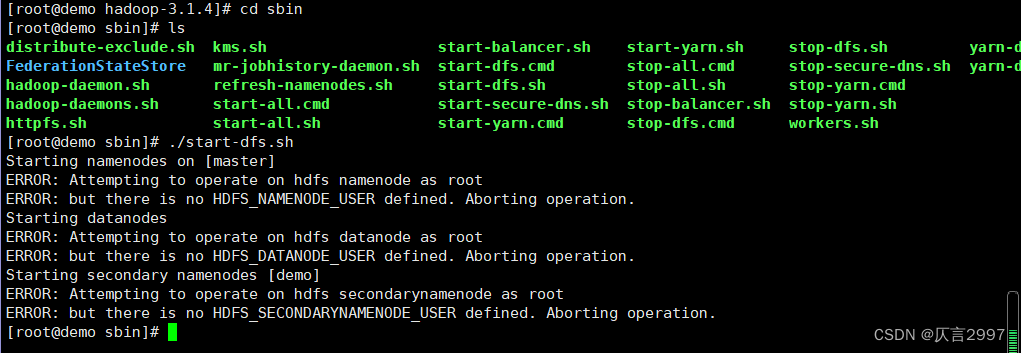 !!!报错:设置hadoop-env.sh
!!!报错:设置hadoop-env.sh
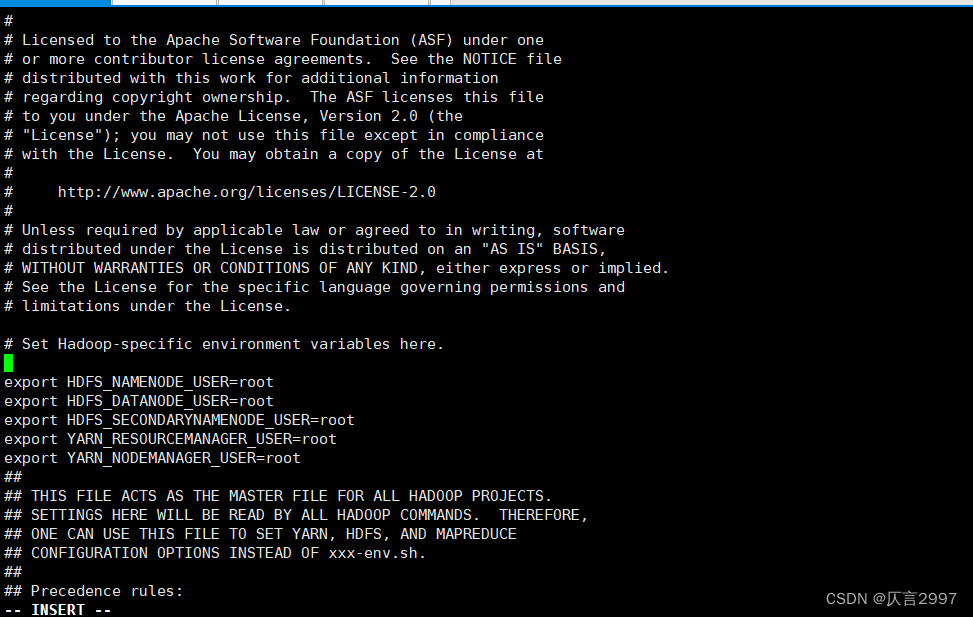
/opt/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
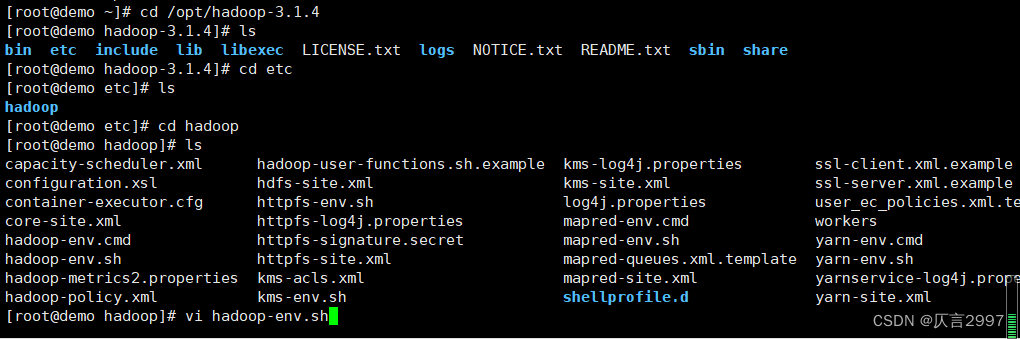 在demo上设置,添加授权:
在demo上设置,添加授权:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
 拷贝文件到其他节点:
拷贝文件到其他节点:
scp hadoop-env.sh dot1:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh dot2:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh dot3:/opt/hadoop-3.1.4/etc/hadoop/
[root@demo hadoop]# scp hadoop-env.sh dot1:/opt/hadoop-3.1.4/etc/hadoop/
hadoop-env.sh 100% 16KB 4.8MB/s 00:00
[root@demo hadoop]# scp hadoop-env.sh dot2:/opt/hadoop-3.1.4/etc/hadoop/
hadoop-env.sh 100% 16KB 4.4MB/s 00:00
[root@demo hadoop]# scp hadoop-env.sh dot3:/opt/hadoop-3.1.4/etc/hadoop/
hadoop-env.sh 100% 16KB 4.7MB/s 00:00
[root@demo hadoop]#
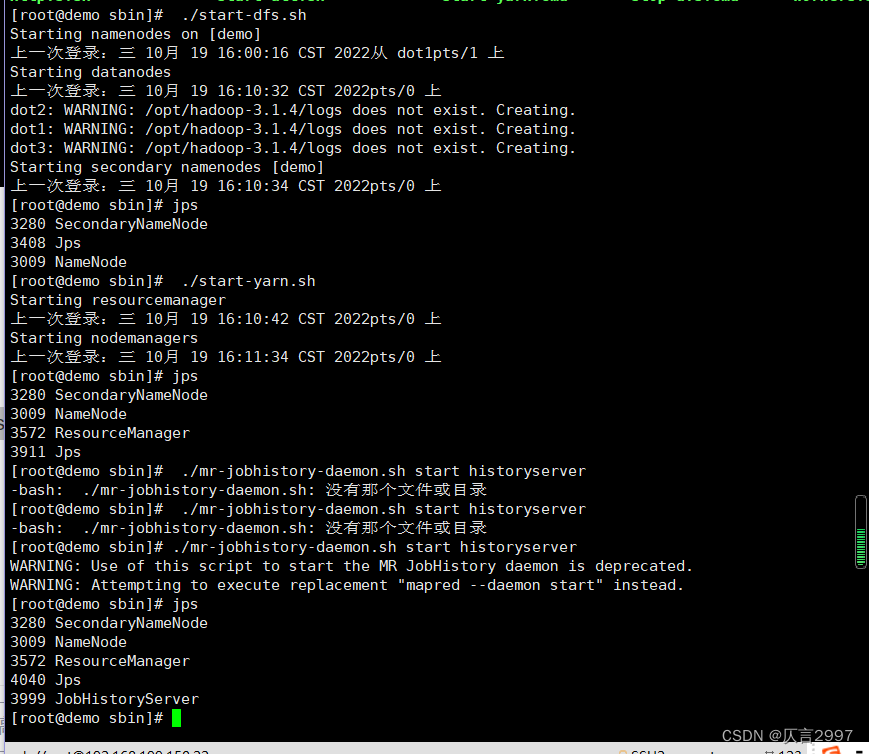
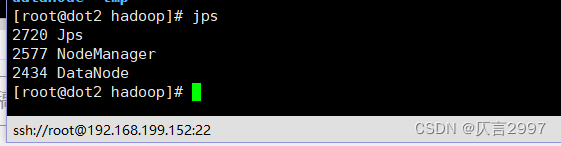
 **-> **再重复2步骤,通过jps查看进程
**-> **再重复2步骤,通过jps查看进程
在demo上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意启动顺序:
[root@master sbin]# ./start-dfs.sh
[root@master sbin]# ./start-yarn.sh
[root@master sbin]# ./mr-jobhistory-daemon.sh start historyserver 或者 mapred --daemon start historyserver
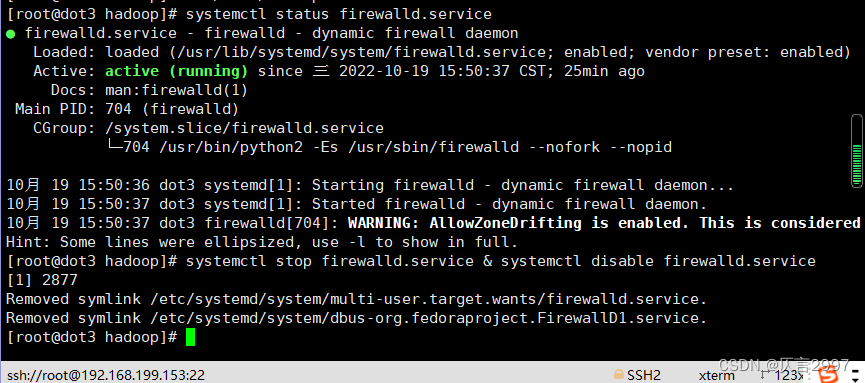
**6. 关闭防火墙 **
**** (对所有节点,可以考虑在克隆之前完成)****
systemctl status firewalld.service
systemctl stop firewalld.service & systemctl disable firewalld.service

点击链接:
http://192.168.199.150:50070/dfshealth.html#tab-overview
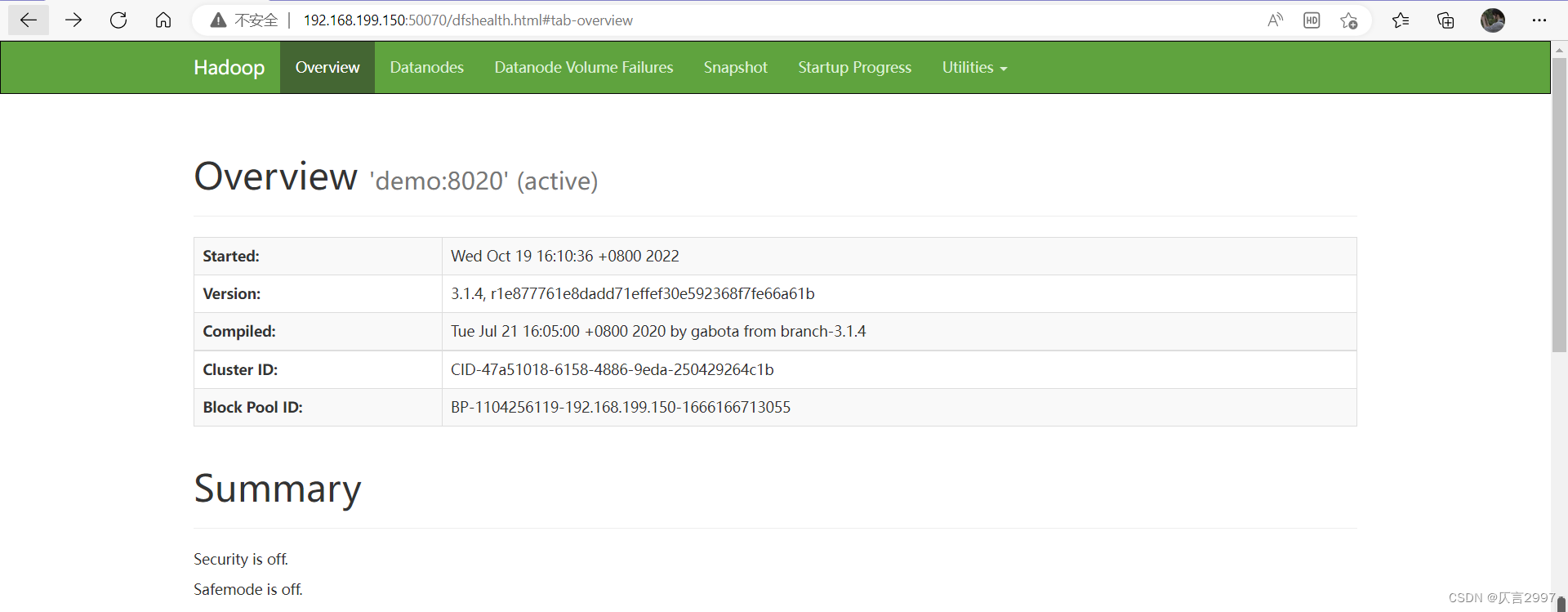
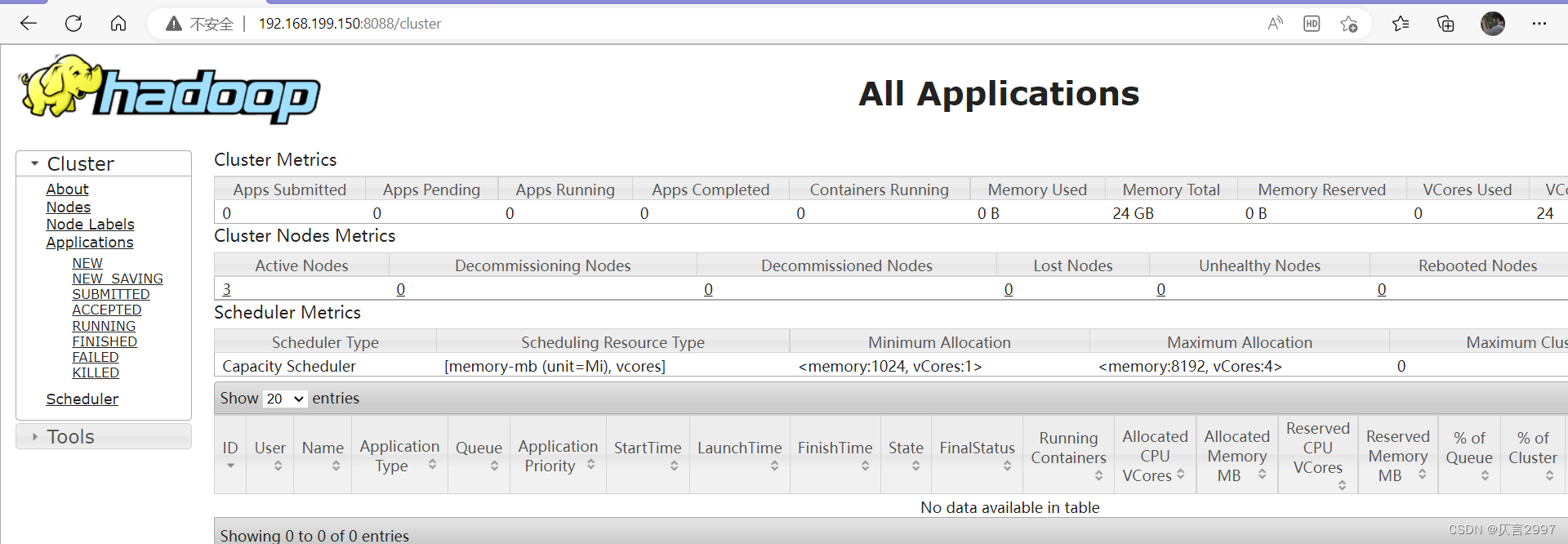
http://192.168.199.150:8088/cluster
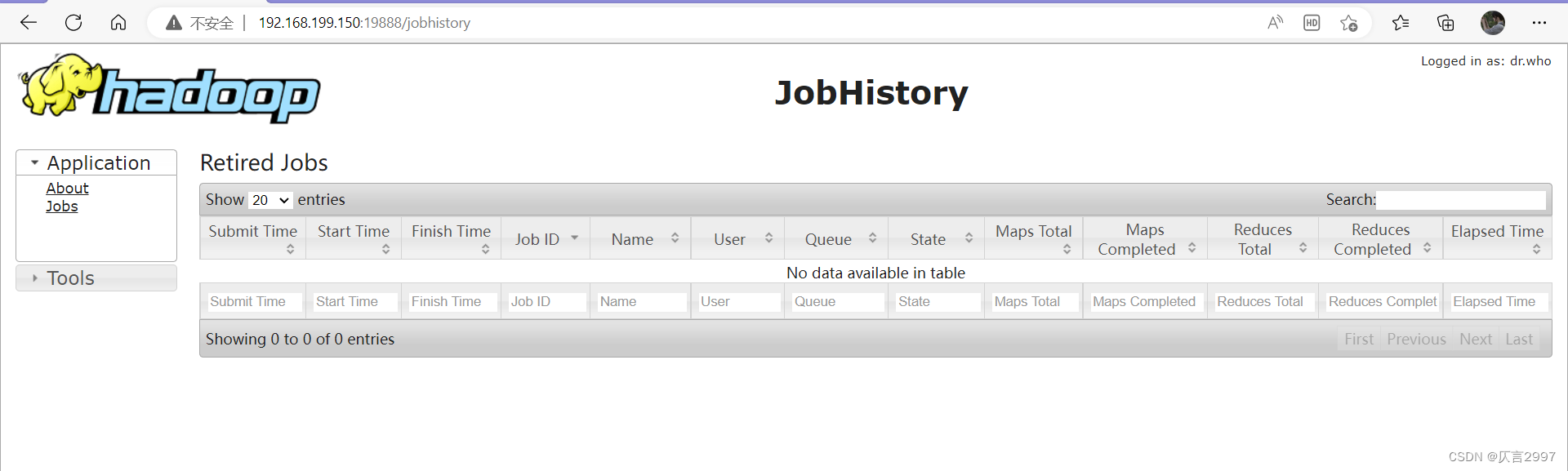
http://192.168.199.150:19888/jobhistory
7. 宿主机上做节点映射
宿主机上修改,host文件
/C:/Windows/System32/drivers/etc/hosts
192.168.199.150 demo demo.centos.com
192.168.199.151 dot1 dot1.centos.com
192.168.199.152 dot2 dot2.centos.com
192.168.199.153 dot3 dot3.centos.com
编辑文件

8**. Hadoop环境变量配置** ****
** (对所有节点)**
vi /etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin
[root@demo ~]# vi /etc/profile
[root@demo ~]# source /etc/profile
[root@demo ~]# echo $HADOOP_HOME
/opt/hadoop-3.1.4
[root@demo ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/opt/hadoop-3.1.4/bin
**6. **关闭集群
在master上操作,cd到sbin文件夹 (/opt/hadoop-3.1.4/sbin),注意关闭顺序:
[root@master sbin]# ./stop-dfs.sh
[root@master sbin]# ./stop-yarn.sh
[root@master sbin]#./mr-jobhistory-daemon.sh stop historyserver 或者 mapred --daemon stop historyserver
poweroff

Hadoop集群就配置成功啦!
版权归原作者 仄言2997 所有, 如有侵权,请联系我们删除。