
1、提前准备 --- jdk8、hadoop3.1.3
创建目录:/home/software
一、配置jdk
1、上传jdk
将jdk压缩包拖拽到software
2、tar zxvf 压缩包的名称 -- 解压
3、配置系统环境变量
vim /etc/profile
在末尾添加

source /etc/profile -- 使环境变量生效
java -version -- 查看Java版本
二、配置Hadoop
1、关闭防火墙
[root@localhost software]# systemctl stop firewalld -- 一次生效(下次服务重启就会打开)
[root@localhost software]# systemctl disable firewalld -- 永久生效
2、配置主机名
vim /etc/hostname -- 配置自己的主机名
3、配置主机名和虚拟机ip的映射
vim /etc/hosts
配置 192.168.195.100 hadoop01
注意:写自己的IP以及主机名
4、关闭SELINUX
vim /etc/selinux/config
将enforcing改为disabled
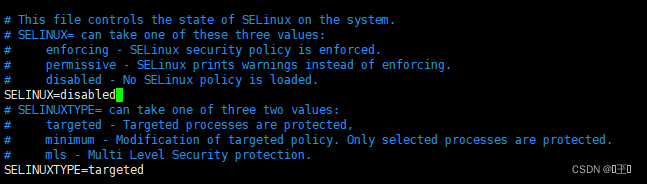
5、重启 -- reboot(必须重启)
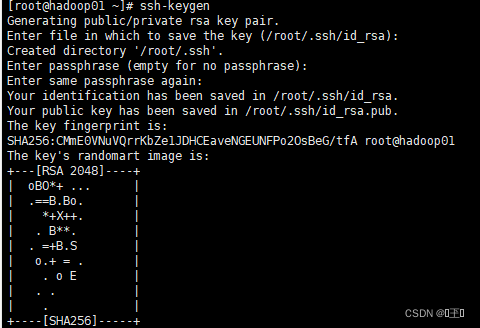
6、配置免密登录
ssh-keygen -- 生成密钥 回车四次 出现图片
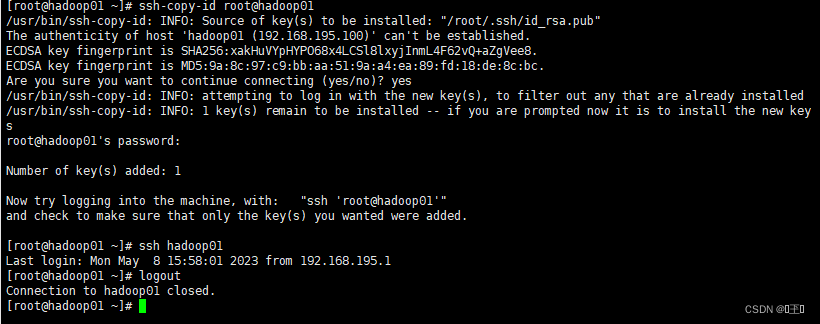
ssh-copy-id root@hadoop01 -- 把生成的密钥发送给自己的主机(因为只有一个主机)
ssh hadoop01 -- 免密登录主机 如果不需要输入密码说明免密配置成功
logout -- 退出登录
7、上传和解压Hadoop
tar zxvf hadoop3.1.3
8、进入到hadoop配置文件的位置
cd hadoop3.1.3/etc/hadoop
9、配置Hadoop的环境(依赖java)
第一个配置文件:
vim hadoop-env.sh

source hadoop-env.sh -- 让环境生效
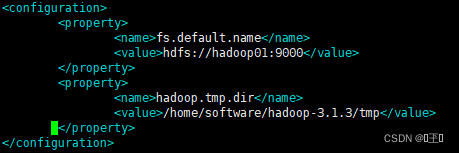
第二个配置文件:
vim core-site.xml
元数据默认存放在hadoop-3.1.3/tmp
第三个配置文件:
vim hdfs-site.xml
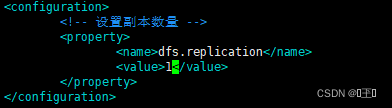
第四个配置文件:
vim mapred-site.xml
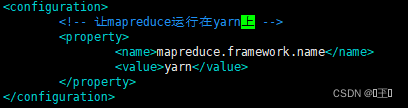
第五个配置文件:
vim yarn-site.xml
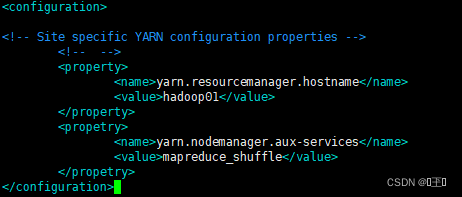
第六个配置文件:
vim workers -- 注意hadoop2.x版本是配置slaves
配置主机名 hadoop01
第七个配置文件:
配置系统环境变量(可以让Hadoop指令任意位置生效)
vim /etc/profile

source /etc/profile -- 让文件生效
10、格式化namenode(检测之前的配置是否正确)
hadoop namenode -format
11、进入hadoop安装目录的子目录sbin下(启动和关闭服务的命令)
cd /home/software/hadoop3.1.3/sbin
12、编辑启动命令
vim start-dfs.sh(开启hdfs的服务)
在文件头部添加:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SERCURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
启动HDFS服务
start-dfs.sh
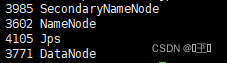
通过jps命令查看进程 会出现三个进程说明启动成功
vim start-yarn.sh
在文件头部添加:
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
YARN_NODEMANAGER_USER=root
启动YARN服务(包含MapReduce)
start-yarn.sh
通过jps查看进程 会发现多出两个进程
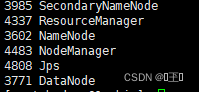
13、配置关闭命令
vim stop-dfs.sh
在文件的头部添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SERCURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vim stop-yarn.sh
在文件的头部添加
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
YARN_NODEMANAGER_USER=root
本文转载自: https://blog.csdn.net/qq_53356327/article/details/130571825
版权归原作者 ℘玊๓ 所有, 如有侵权,请联系我们删除。
版权归原作者 ℘玊๓ 所有, 如有侵权,请联系我们删除。