
文章目录
前言
本文适用于《Spark大数据技术与应用》第九章-菜品推荐项目环境配置:`
跟着做就行…
资源都在网盘里面,纯粹的无脑配置…
提示:以下是本篇文章正文内容,所用资源版本过低,用于课本实验
,且已有Java环境
一、下载资源
scala:2.12.8
spark:1.6.2
hadoop:2.6.4
hadoop启动文件exe
JAVA
如果按照我的方法在仍然不能使用的话,那大概率就是你的JAVA环境有问题,那么你就用我的JAVA文件找一篇JAVA配置的文章把JAVA环境换成我的
链接:https://pan.baidu.com/s/1dVLt3q_D3AQuwRZ0Q2TVvg 提取码:rfwb

二、本地配置步骤
1.解压
记住:解压到根目录下或者父目录不带空格 还不如直接这样直接搞到D盘下面(反正你水完课设再也不用了)
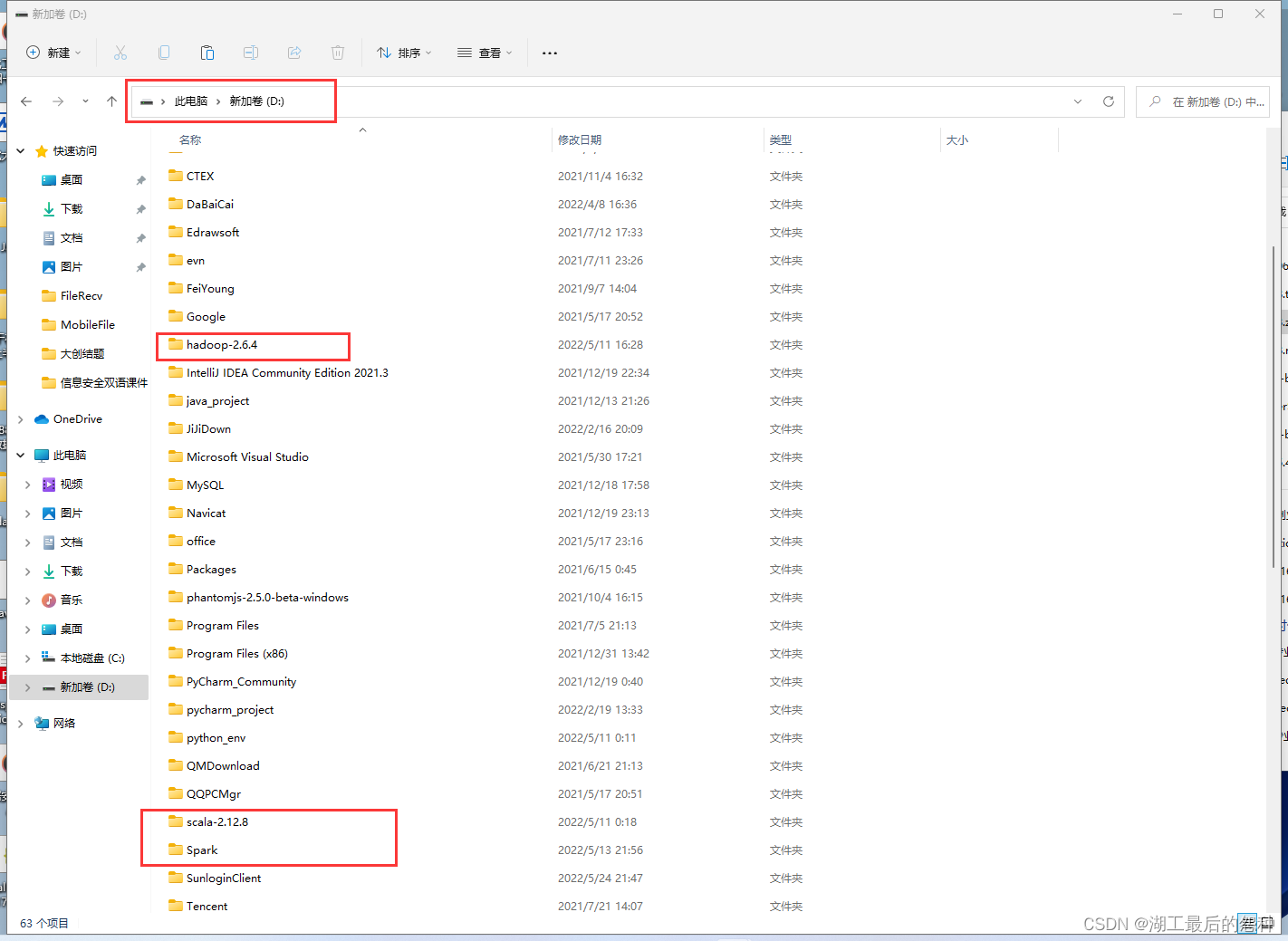
2.引入本地环境
1.打开高级环境配置并且找到“环境变量”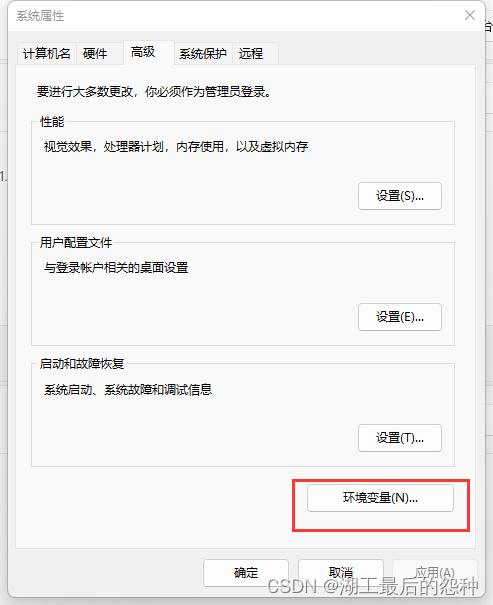
2.进入之后在系统变量里面找到path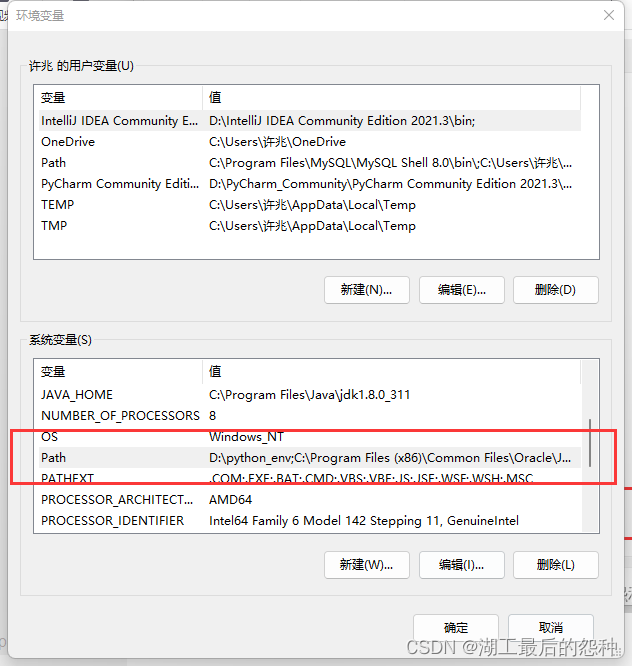
3.将Spark,Hadoop,scala三个文件的bin文件路径引入path里面
注意:Hadoop文件的bin和sbin都要引入
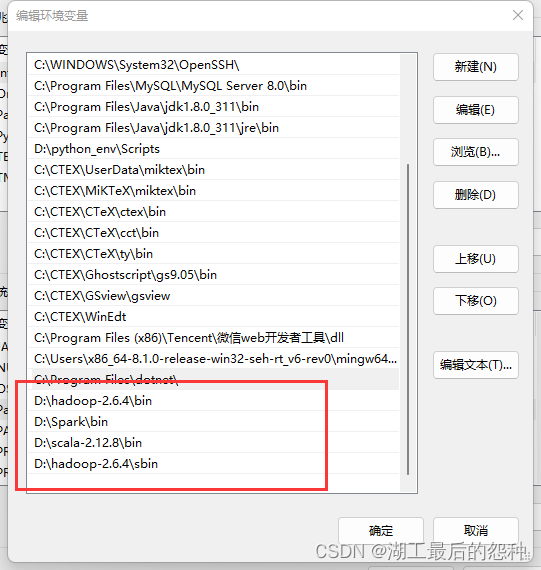
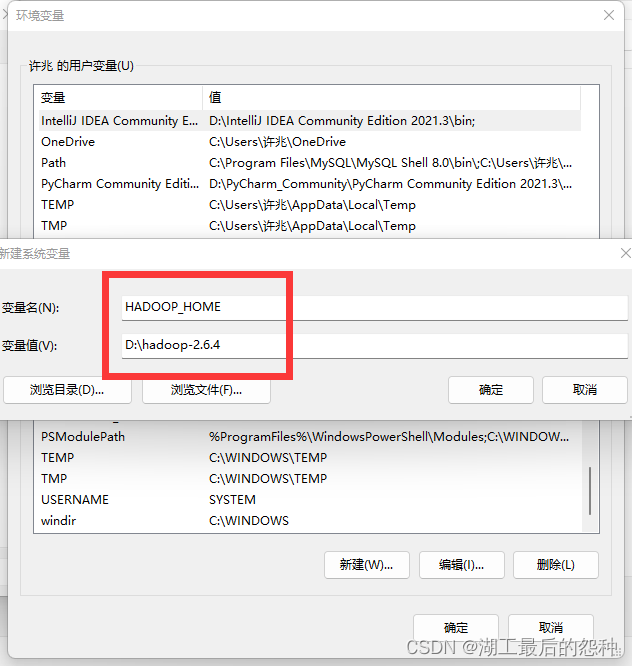
4.系统编辑新建名为HADOOP_HOME的变量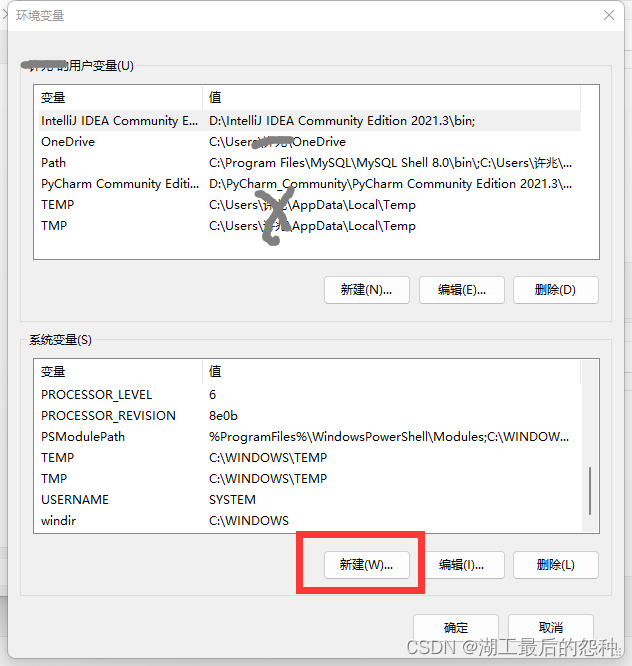
3.启动HADOOP文件
首先你要检查你的C盘
有没有tmp文件,tmp文件下面有没有hive文件,没有你要手动创建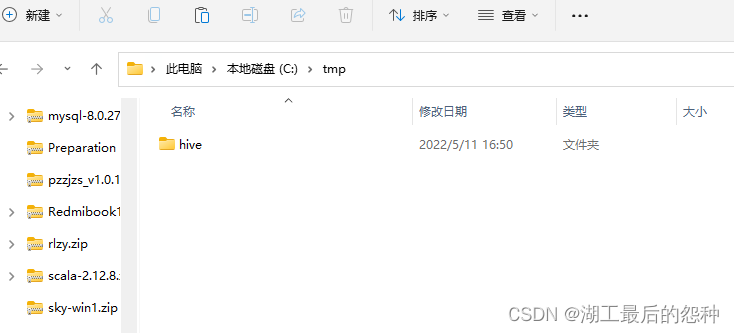
将winutils.exe文件复制到hadoop的bin目录下面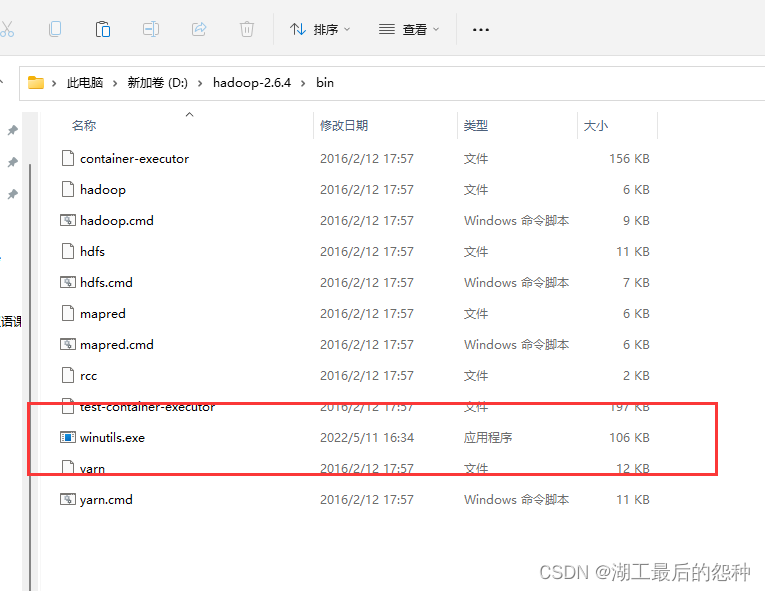
打开cmd
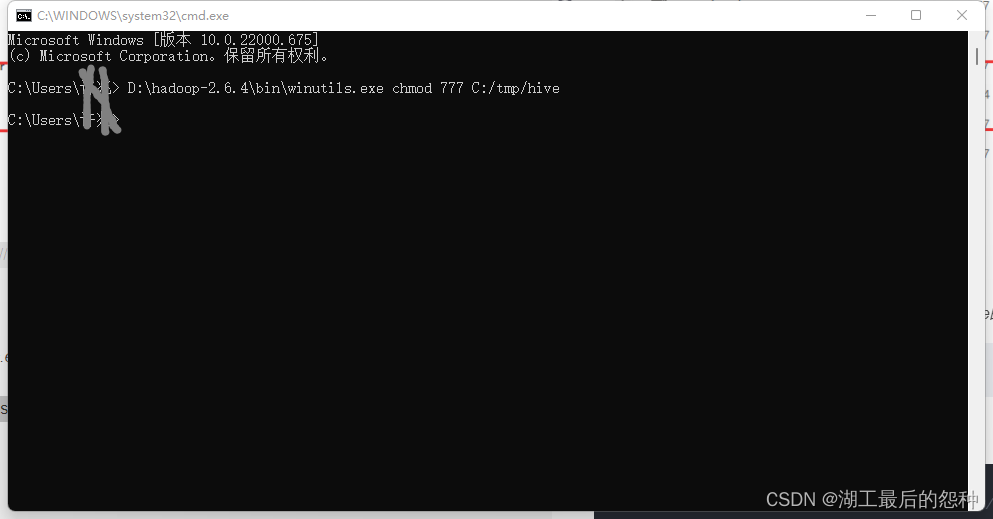
输入
前面半句是你自己的winutils.exe路径,后半句是C盘hive的路径,不要无脑复制
D:\hadoop-2.6.4\bin\winutils.exe chmod 777 C:\tmp\hive
4.进行Spark测试
打开cmd
输入
spark-shell
出现这两句话即为成功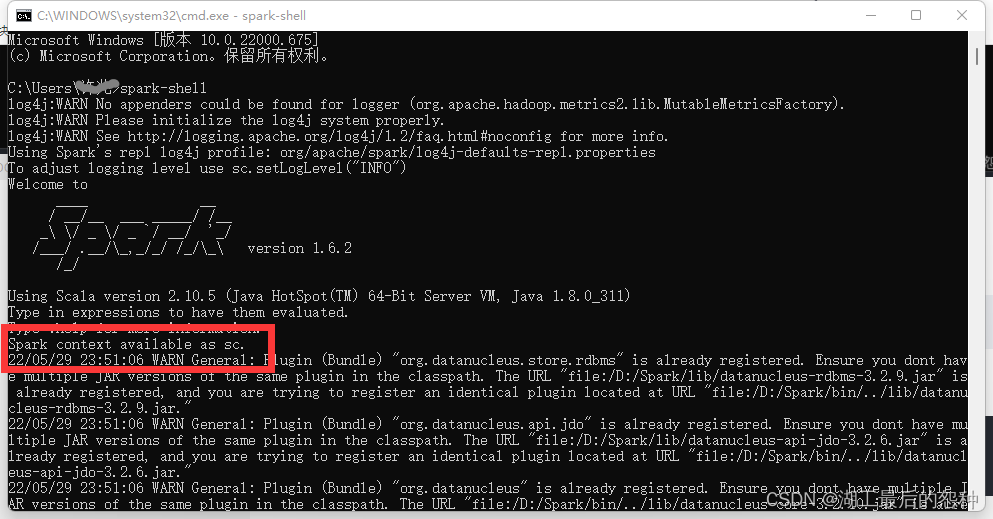
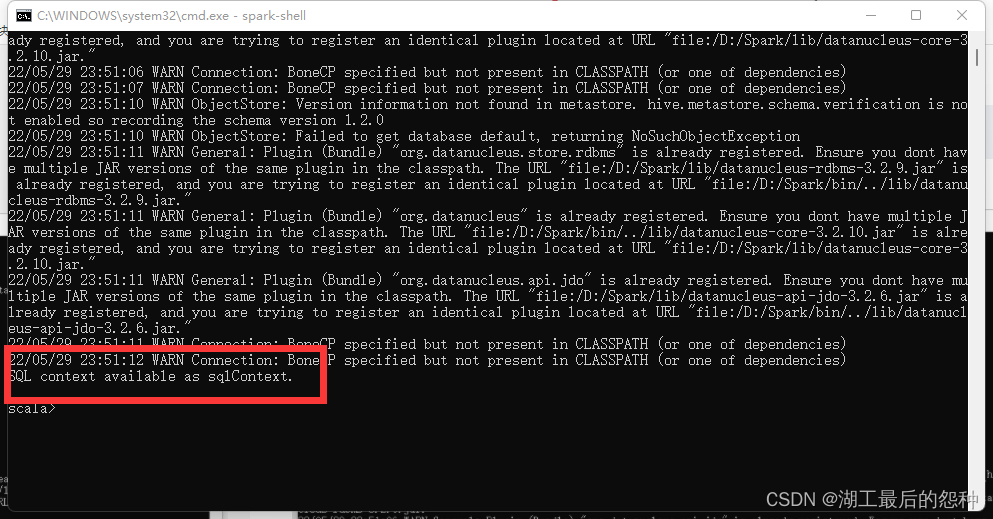
注:一般问题
1.出现CMD出现Spark字母,但是出现如下
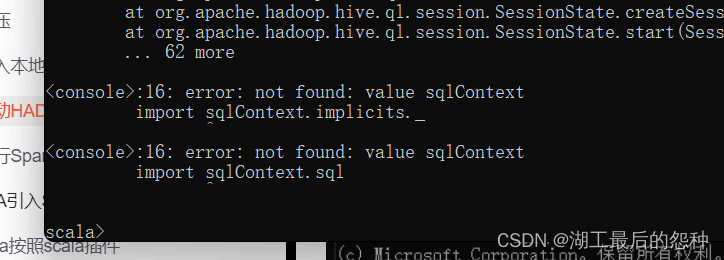
说明是Hadoop的配置问题。重新看我的过程
2.连字母都出现不了而且scala和spark配置没有问题
说明是JAVA环境问题
三、IDEA引入Spark项目
1.idea按照scala插件
在
File->Plugins->搜索scala->然后下载按照->重启idea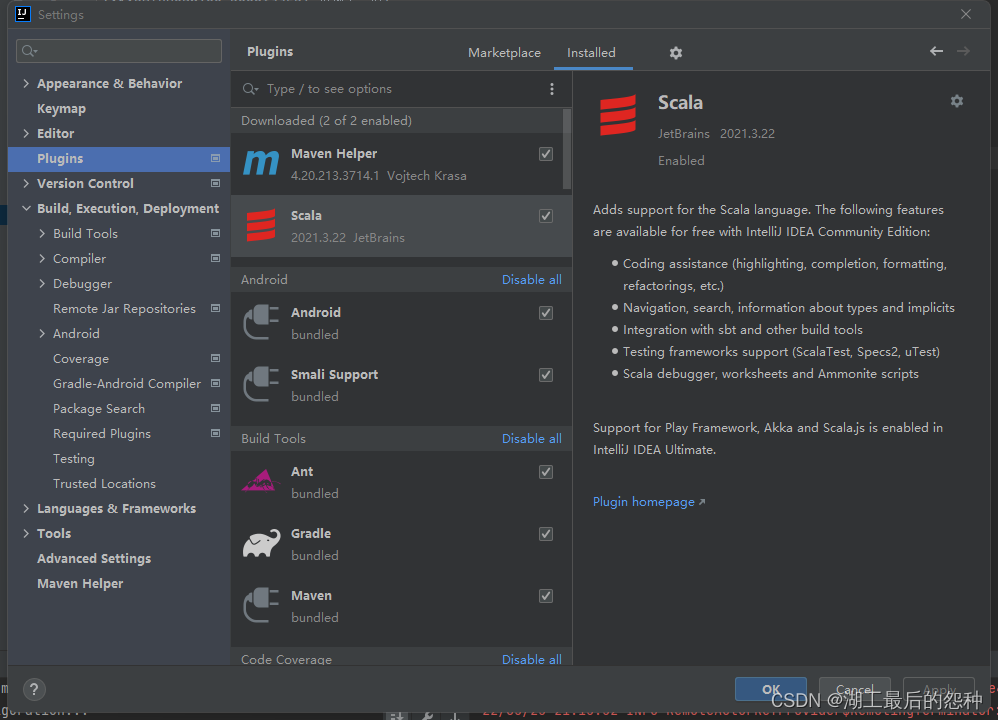
2.新建scala项目
点这个创建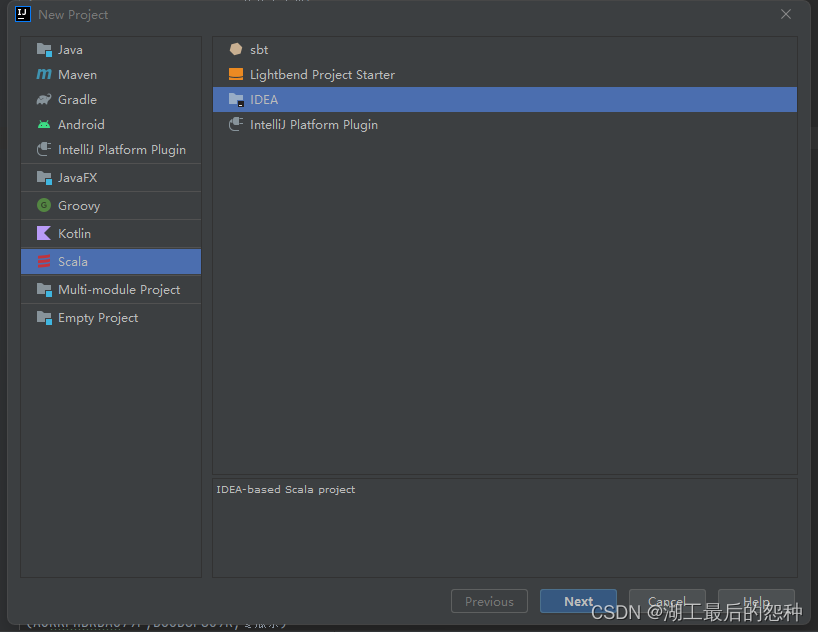
java用本地的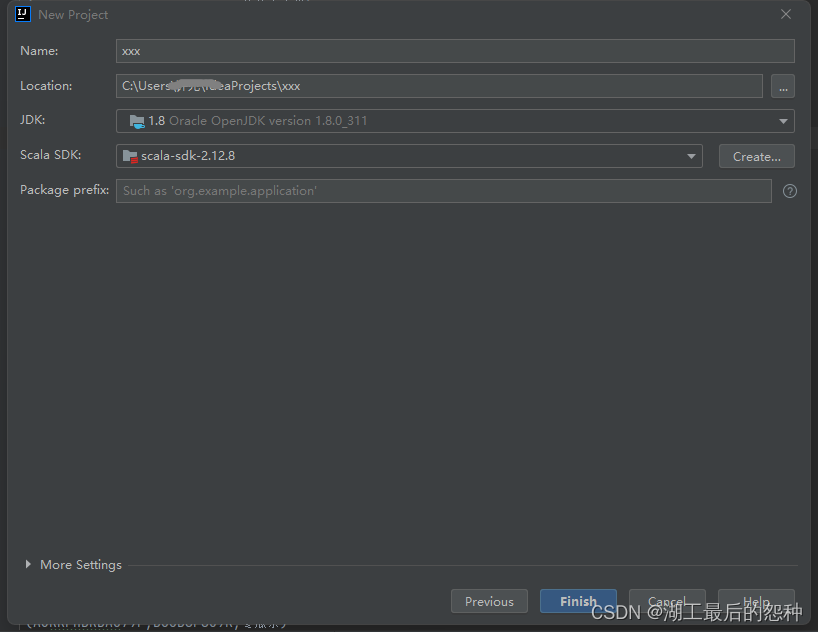
3.配置项目
在File->Projct structure->Libraies
点击左上角加号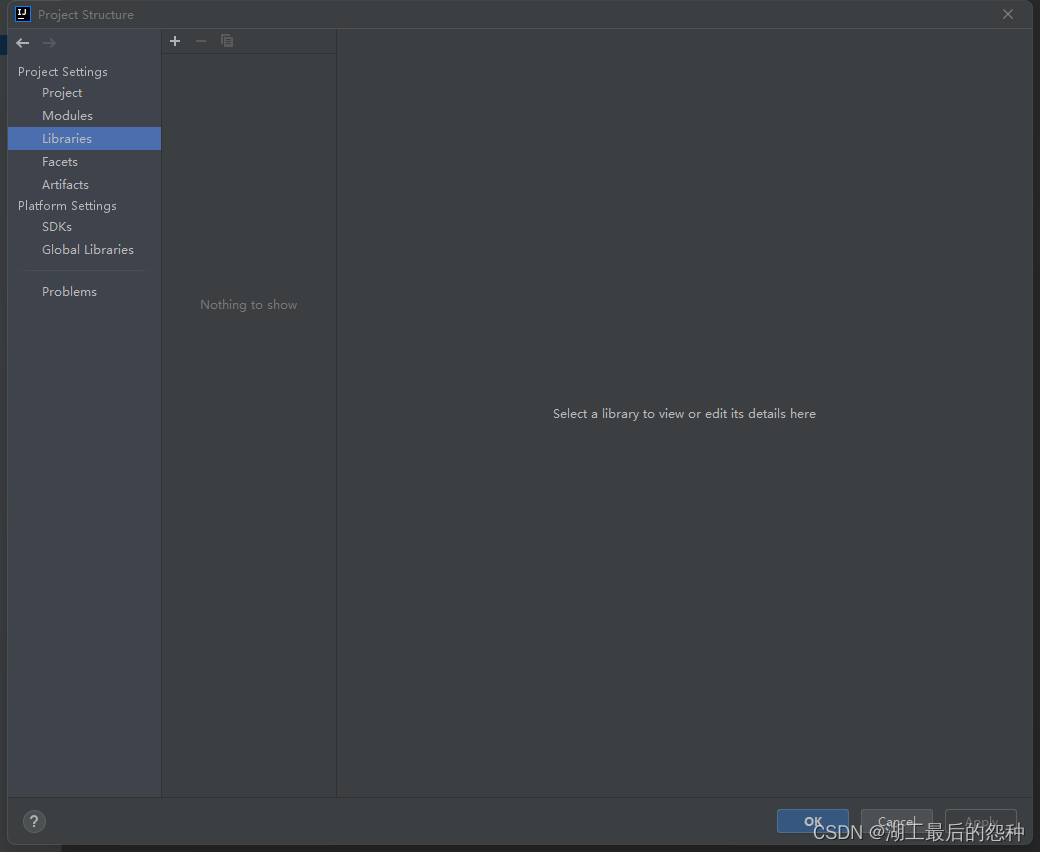
点击java引入包
找到你下载的Spark文件下面的lib文件点击引入
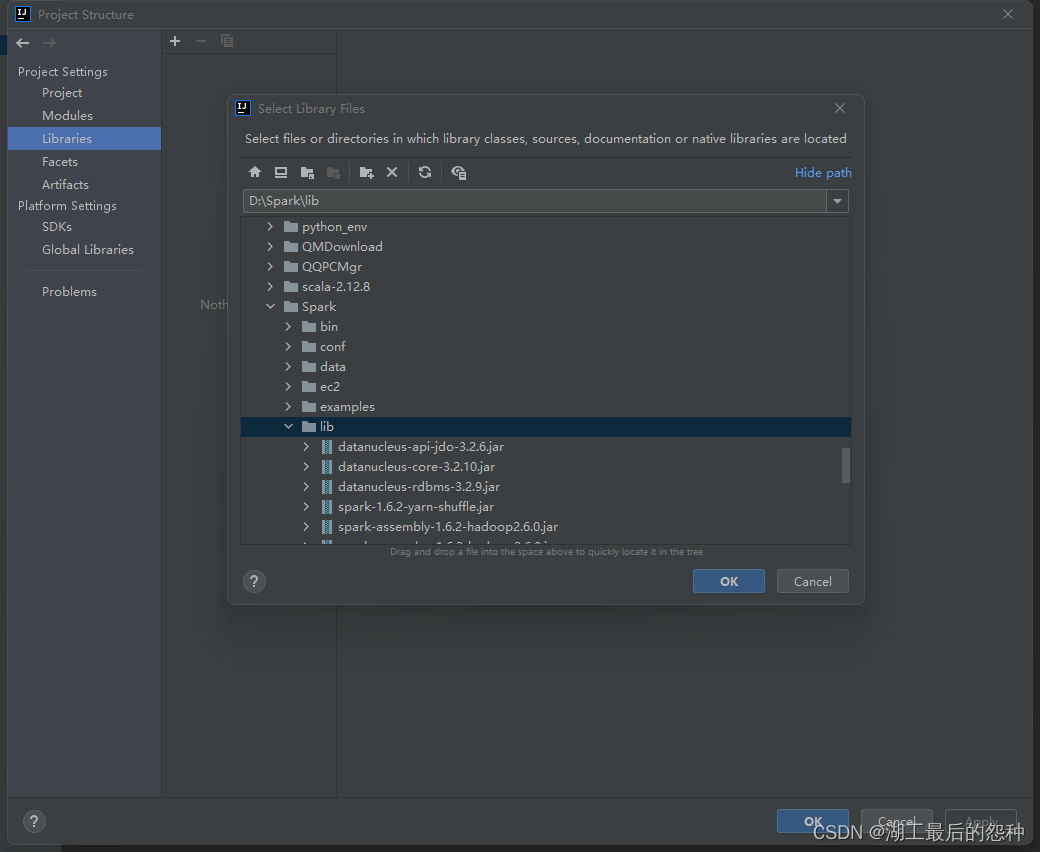
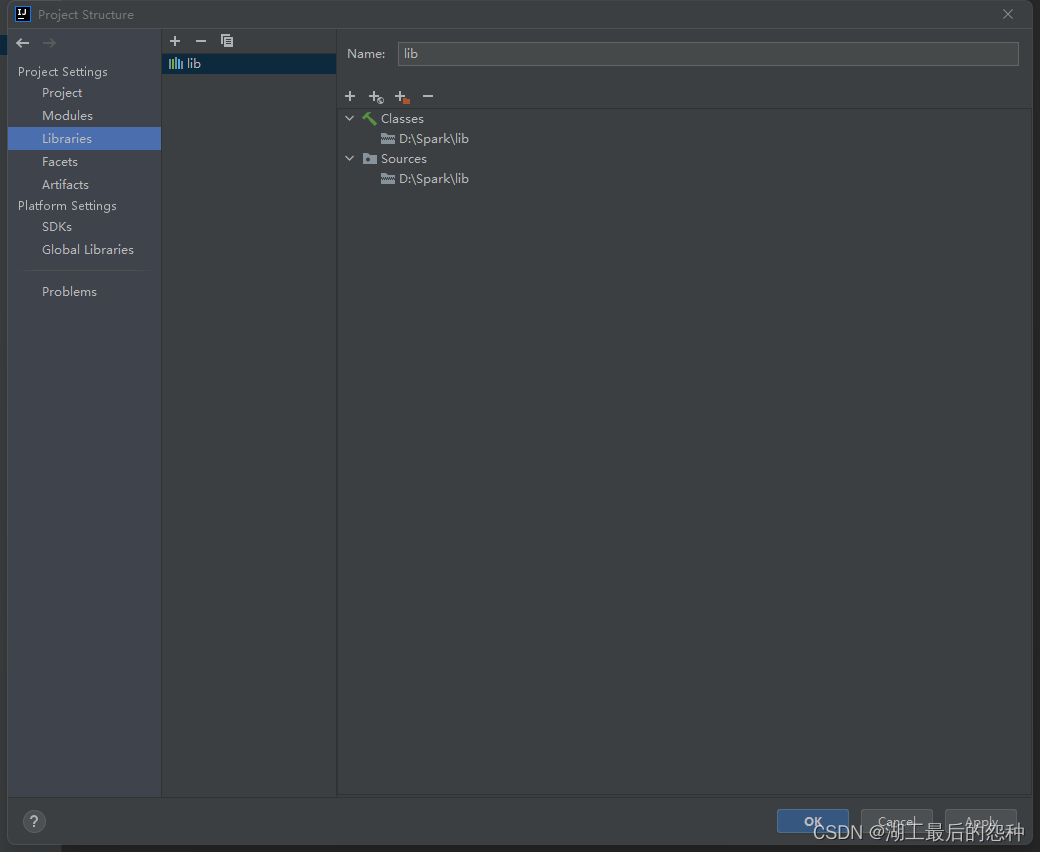
再次点击加号,点击scala
点击下方browse按钮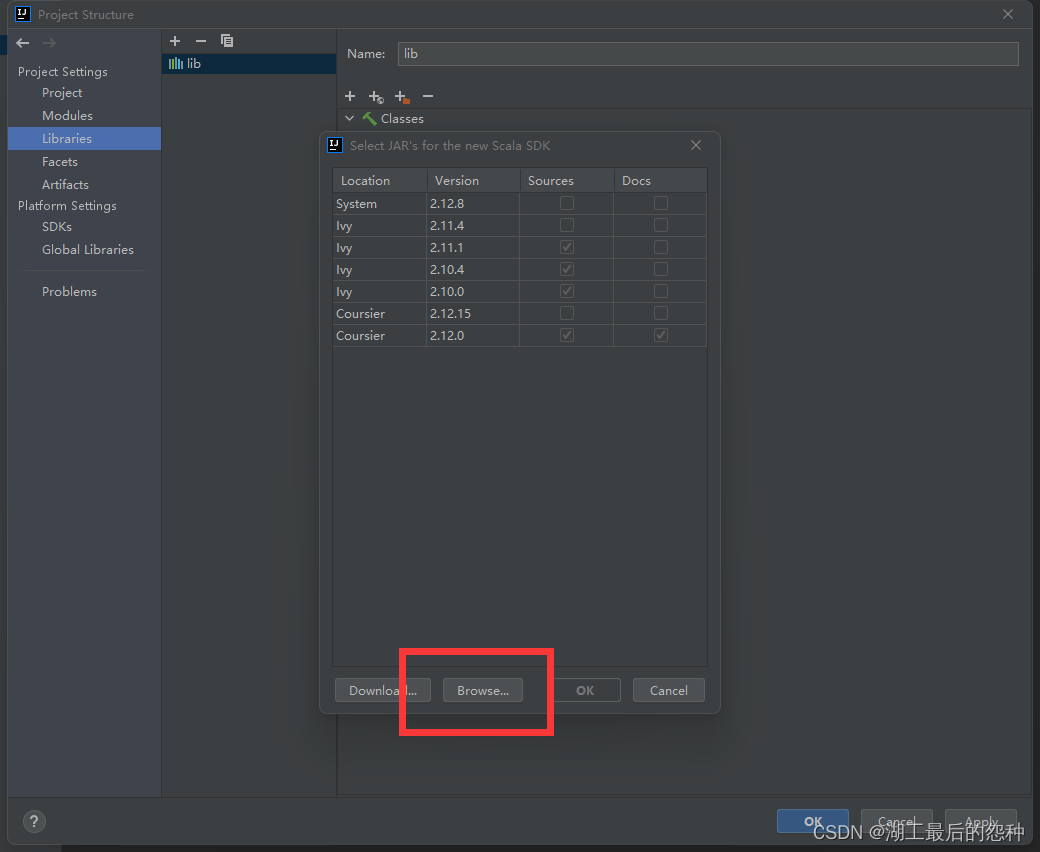
找到本地scala的文件引入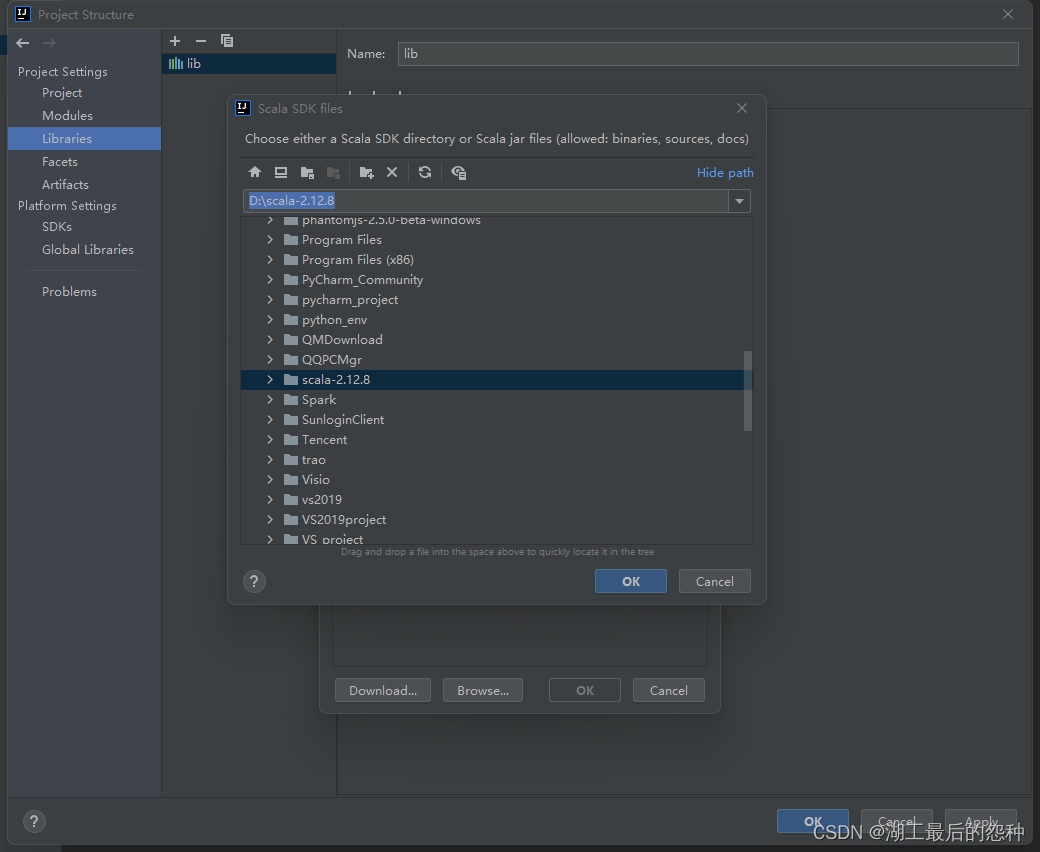
成功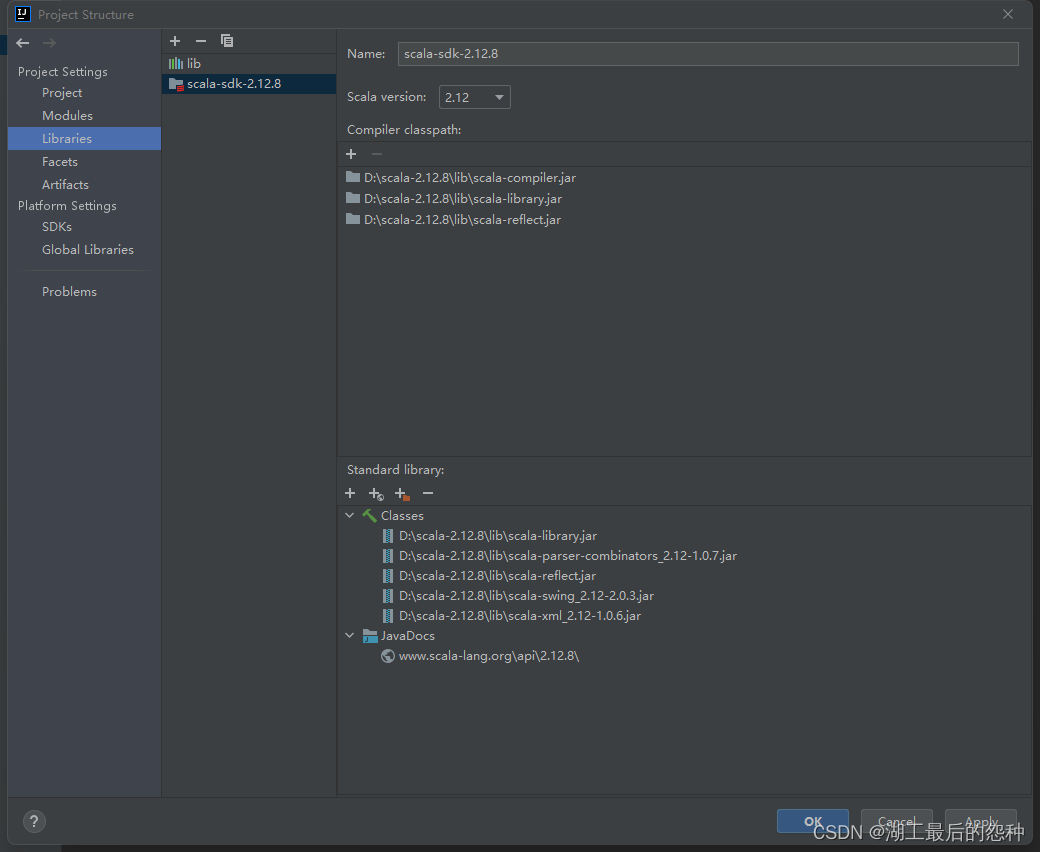
4.新建scala类

点击Object,输入类名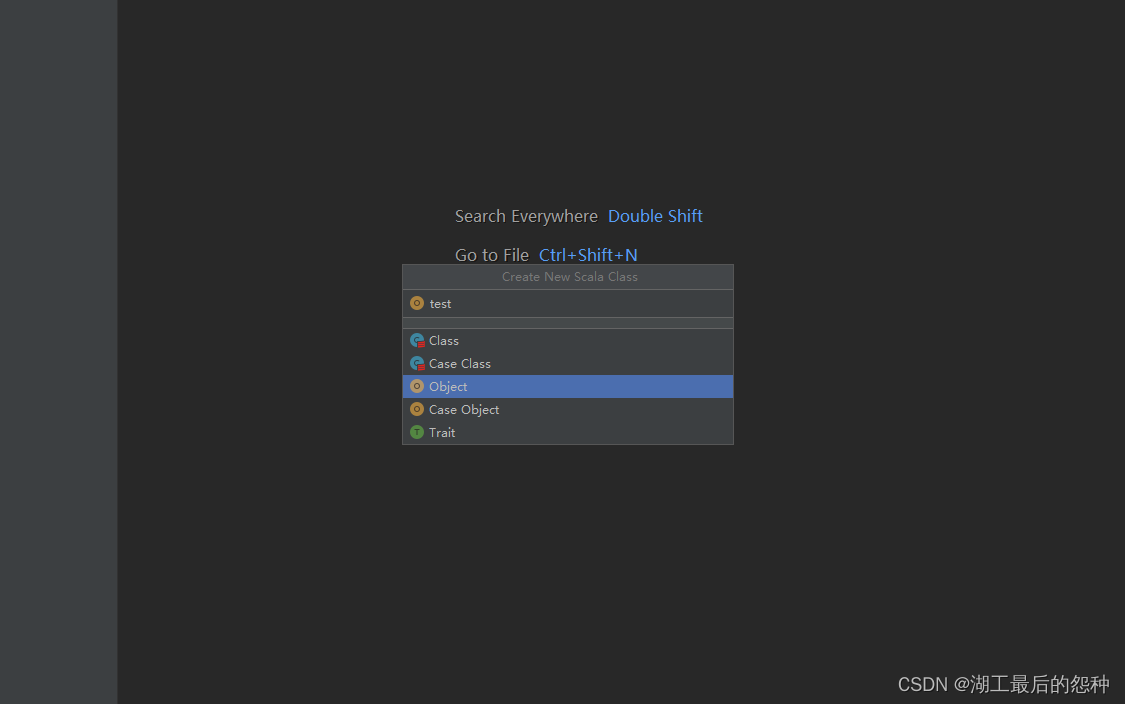
完成
版权归原作者 湖工最后的怨种 所有, 如有侵权,请联系我们删除。