
文章目录
一、Spark Core
在Spark的执行过程中,涉及到一些关键角色和概念,如Client、Job、Master、Worker、Driver、Stage、Task以及Executor。
- Client: Client是Spark应用程序的驱动程序,通常运行在用户的本地计算机上。它是Spark应用程序的入口点,负责与集群的Master通信,并提交作业给集群执行。Client负责创建SparkContext,并通过SparkContext与集群通信。
- Job:Job是Spark应用程序中的一个作业,它是一个包含多个阶段(Stage)的计算任务。一个Spark应用程序可以由多个作业组成,每个作业包含一系列转换操作和行动操作,这些操作构成了一个有向无环图(DAG)。
- Master:Master是Spark集群中的主节点,负责资源的调度和作业的执行。它接收Client提交的作业,并将作业切分为不同的Stage,然后将Stage分配给集群中的Worker节点执行。
- Worker:Worker是Spark集群中的工作节点,负责执行Master分配的任务。每个Worker节点运行一个或多个Executor进程,Executor是Spark中实际执行计算任务的进程。
- Driver:Driver是运行Spark应用程序的进程,它运行在Client中。Driver负责管理Spark应用程序的执行流程,并通过SparkContext与集群通信。Driver会将作业划分为阶段,并将每个阶段的任务发送给Executor执行。
- Stage:Stage是Spark作业的一个阶段,它是一个任务划分的单元。一个作业可能由多个Stage组成,Stage划分的依据是宽依赖(Shuffle Dependency)。一个Stage中的任务可以并行执行,但Stage之间必须串行执行,Stage之间通过数据的Shuffle进行数据交换。
- Task:Task是Spark中最小的执行单元,它是对数据分区上计算操作的封装。每个Stage由多个Task组成,Task在Executor上执行实际的计算任务。
- Executor:Executor是运行在Worker节点上的计算任务执行进程,它负责在分布式集群上执行任务。每个Executor可以并行执行多个Task,它们运行在独立的JVM进程中,并在内存中保存数据以供计算使用。
Spark应用程序从Client提交到Master,由Master将作业划分为不同的Stage并分配给Worker节点上的Executor执行。每个Executor并行执行多个Task,最终完成Spark应用程序的计算任务。
常见的Spark部署模式:
- Local 模式:在Local模式下,Spark运行在单个机器上,通常用于开发和测试目的。在这种模式下,Spark只使用单个线程进行计算,并且不涉及分布式计算和集群。这是最简单的部署模式,适用于在本地机器上快速验证Spark应用程序。
- Standalone 模式:Standalone模式是Spark自带的独立部署模式,它是一种简单的分布式模式,支持在独立的集群上运行Spark应用程序。在这种模式下,Spark Master和Worker都运行在同一个集群上,Spark应用程序通过连接到Spark Master进行任务的提交和分配。
- YARN 模式: YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,Spark可以在YARN上运行,利用Hadoop集群的资源进行计算。在YARN模式下,Spark作为YARN的客户端,通过YARN资源管理器向集群请求资源,并在集群上运行Spark应用程序。
- Mesos 模式:Mesos是一个通用的集群管理器,Spark可以在Mesos上运行,充分利用集群资源进行计算。在Mesos模式下,Spark作为Mesos的框架,通过Mesos Master向集群请求资源,并在Mesos Slave上运行Spark应用程序。
- Kubernetes 模式:Kubernetes是一个容器编排平台,Spark可以在Kubernetes上运行,利用容器化的方式进行资源管理和任务调度。在Kubernetes模式下,Spark应用程序作为Kubernetes的Pod运行,并通过Kubernetes调度器管理资源。
不同的部署模式适用于不同的场景和需求。Local模式适用于开发和测试,Standalone模式适用于简单的分布式部署,YARN和Mesos模式适用于与Hadoop或Mesos集成的部署,而Kubernetes模式适用于容器化的部署。
1. SparkContext:
SparkContext是PySpark的核心组件之一,它是与Spark集群通信的主要入口点。在Spark中,SparkContext实例化之后,可以使用它来创建RDD和广播变量,还可以配置Spark应用程序的行为。
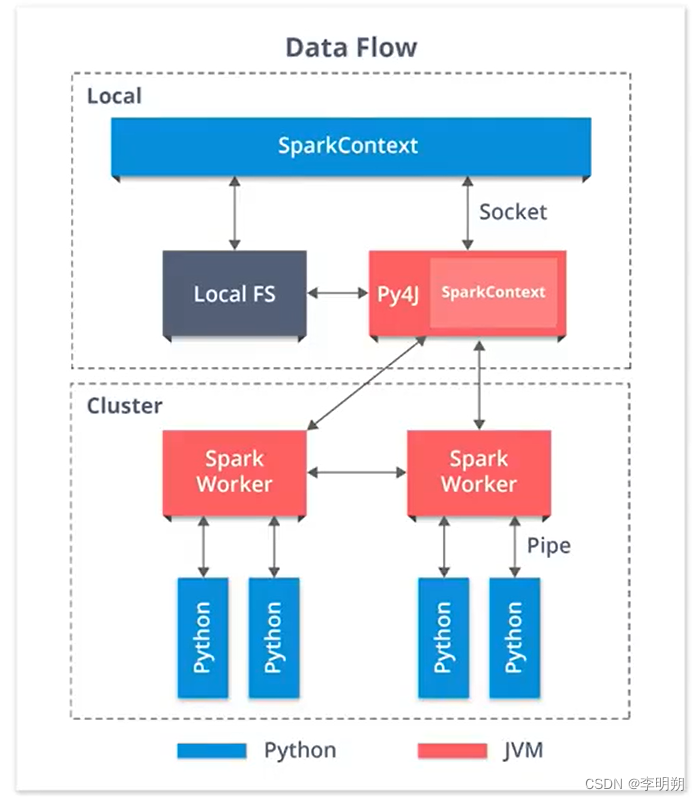
2. Spark Session
Spark Session是一个代表Spark应用程序与Spark集群交互的入口点。它是Spark 2.0及以上版本中引入的概念,取代了之前版本中的SparkContext和SQLContext,并将它们的功能整合在一个统一的接口中。
Spark Session提供了许多功能,使得在Spark应用程序中更加方便地使用Spark的各项功能,包括:
- 创建DataFrame和DataSet:Spark Session允许您通过读取外部数据源(如CSV、JSON、Parquet等)或在内存中创建数据集,来轻松地创建DataFrame和DataSet。DataFrame和DataSet是Spark中最常用的数据抽象,用于处理结构化数据。
- 注册临时表:Spark Session允许您将DataFrame注册为临时表,从而可以在Spark SQL中进行SQL查询。通过将DataFrame注册为表,可以方便地使用SQL语句对数据进行分析和处理。
- 执行SQL查询:Spark Session支持直接执行SQL查询,无需显式地创建DataFrame。您可以直接使用SQL语句对临时表或DataFrame进行查询操作。
- 配置Spark应用程序:Spark Session提供了许多配置选项,允许您设置Spark应用程序的各种属性,如应用程序名称、资源分配、日志级别等。
- 创建StreamingContext:如果您需要在Spark应用程序中使用Spark Streaming,Spark Session也可以创建对应的StreamingContext,从而支持实时数据流处理。
在Python中,创建Spark Session非常简单,只需要使用SparkSession.builder创建一个Spark Session实例,并通过getOrCreate()方法获取Spark Session。例如:
from pyspark.sql import SparkSession
# 创建Spark Session
spark = SparkSession.builder \
.appName("MySparkApp") \
.config("spark.some.config.option","config-value") \
.getOrCreate()# 使用Spark Session创建DataFrame或执行SQL查询等操作
在Spark应用程序中,通常只需要一个Spark Session实例,它会自动根据需要懒惰地初始化SparkContext和SQLContext,并自动对其进行管理。
3. RDD
RDD(弹性分布式数据集)是Spark的核心数据抽象,是一个分布式的、不可变的数据集合。它是Spark中最基本的数据单元,表示分布在集群中多个节点上的数据项的集合。RDD是可并行计算的,可以在集群的多个节点上同时进行计算。
在RDD(弹性分布式数据集)中,有两种主要类型的操作:转换操作(Transformations)和行动操作(Actions)。这些操作是用来处理和计算分布在Spark集群中的数据。
- 转换操作(Transformations):转换操作是RDD上的延迟执行操作,当您调用转换操作时,Spark并不立即计算结果,而是会将转换操作添加到RDD的转换计划中。只有当行动操作触发时,Spark才会执行实际的计算。这种延迟执行的机制允许Spark进行优化,以在整个转换计划中实现更高效的执行。常见的转换操作有: - map(func): 对RDD中的每个元素应用函数func,返回一个新的RDD。- filter(func): 根据满足条件的元素筛选RDD中的数据,返回一个新的RDD。- flatMap(func): 类似于map操作,但对每个输入元素返回一个或多个输出元素,最终将所有输出元素组成一个新的RDD。- union(otherRDD): 返回一个包含两个RDD中所有元素的新RDD。- distinct(): 返回去重后的RDD,去除重复元素。- groupByKey(): 将RDD中的键值对按键进行分组。- reduceByKey(func): 将RDD中的键值对按键进行聚合,使用给定的函数func。
- 行动操作(Actions):行动操作是RDD上的实际计算操作,当您调用行动操作时,Spark会触发计算并返回结果,这些结果可能是Scala对象(在本地模式下)或存储在外部存储中(在集群模式下)。常见的行动操作有: - collect(): 将RDD中的所有元素收集到Driver节点,返回一个本地的Python列表。- count(): 返回RDD中元素的数量。- first(): 返回RDD中的第一个元素。- take(n): 返回RDD中的前n个元素。- reduce(func): 使用给定的函数func,对RDD中的元素进行逐个聚合。- foreach(func): 对RDD中的每个元素应用函数func,通常用于对RDD进行一些副作用操作,如写入数据库等。
4. Broadcast、 Accumulator:
Broadcast变量允许在集群的所有节点上缓存一个只读变量,这样每个节点都可以有效地共享同一个变量,从而减少数据的传输开销。Accumulator用于在集群的所有节点上聚合数据,例如用于累加计数。例如
broadcast_var = sc.broadcast([1,2,3,4,5])
accumulator = sc.accumulator(0)# 初始化一个累加器# 在RDD上累加值
rdd.foreach(lambda x: accumulator.add(x))
5. Sparkconf
SparkConf是Spark的配置类,用于设置和配置Spark应用程序的参数。它允许您在创建SparkContext或SparkSession之前,指定Spark应用程序的各种配置选项。
6. SparkFiles
SparkFiles是一个工具类,用于在Spark集群的所有节点上分发文件和访问这些文件。通常,当您需要在Spark任务中使用文件时,可以使用SparkFiles将文件分发到集群的所有节点,然后在任务中使用分发的文件路径。
SparkFiles提供了两个主要功能:
- addFile(filename): 将文件分发到集群的所有节点。该方法会将文件复制到每个工作节点上的临时目录中,以供任务使用。
- get(filename): 获取分发的文件的路径。在Spark任务中,您可以使用SparkFiles.get(filename)来获取分发文件的本地路径。
以下是示例
from pyspark import SparkFiles
# 将文件分发到集群的所有节点
sc.addFile("file.txt")# 在任务中使用分发的文件defprocess_file(file_path):withopen(file_path,"r")asfile:
data =file.read()# 在此处处理文件内容return data
# 获取分发文件的本地路径
file_path = SparkFiles.get("file.txt")# 在任务中使用文件
result = sc.parallelize([file_path]).map(process_file).collect()
7. Storage Level
Storage Level(存储级别)是用于控制RDD(弹性分布式数据集)持久化的选项。RDD的持久化是将RDD的数据存储在内存或磁盘上,以便可以在后续的计算中重复使用,避免重复计算。存储级别可以控制RDD的数据在内存和磁盘之间的存储和处理方式,以平衡性能和资源使用。
在PySpark中,有多种存储级别可供选择,每种存储级别都有不同的特性和适用场景。以下是一些常见的存储级别:
- MEMORY_ONLY:将RDD的数据存储在JVM的堆内存中。如果数据不能完全放入堆内存,可能会导致内存不足的问题,此时可以使用MEMORY_AND_DISK。
- MEMORY_AND_DISK:将RDD的数据首先存储在内存中,如果内存不足,则存储在磁盘上。当需要使用数据时,首先尝试从内存中获取,如果内存中不存在,则从磁盘中加载数据。这样可以在一定程度上避免频繁的磁盘读写,但可能会导致一些性能损失。
- MEMORY_ONLY_SER:将RDD的数据以序列化的形式存储在JVM的堆内存中。序列化后的数据占用更少的内存空间,适用于内存不足的情况。但是在获取数据时需要进行反序列化,会导致额外的CPU开销。
- MEMORY_AND_DISK_SER:将RDD的数据以序列化的形式存储在内存中,如果内存不足,则存储在磁盘上。适用于大数据集,可以节省内存空间,但需要进行序列化和反序列化。
- OFF_HEAP:将RDD的数据存储在堆外内存中,即Spark的Off-Heap内存。堆外内存不受JVM堆内存限制,适用于处理大规模数据。
# 在创建RDD时,可以使用persist()或cache()方法来指定存储级别
data =[1,2,3,4,5]
rdd = sc.parallelize(data)# 使用MEMORY_AND_DISK_SER存储级别持久化RDD
rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)
二、Spark SQL
Spark SQL是Apache Spark的结构化数据处理组件,它提供了在Spark中使用SQL语言进行数据查询和处理的功能。Spark SQL允许您在Spark应用程序中使用标准的SQL语法,来处理结构化数据,包括表格数据、CSV文件、Parquet文件、JSON数据等。它为开发人员提供了一种更简单、更直观的方式来处理结构化数据,而无需编写复杂的Spark代码。
1.读取数据
spark sql读取数据的方法
- 从文本文件读取数据
- 从CSV文件读取数据
- 从Parquet文件读取数据
- 从JSON数据读取数据
- 从Hive表读取数据
- 从JDBC数据库读取数据
- 读取hive、MySQL数据库
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder \
.appName("ReadTextFileExample") \
.getOrCreate()# 从文本文件读取数据并创建DataFrame
text_df = spark.read.text("data.txt")# 从CSV文件读取数据并创建DataFrame
csv_df = spark.read.csv("data.csv", header=True, inferSchema=True)# 从Parquet文件读取数据并创建DataFrame
parquet_df = spark.read.parquet("data.parquet")# 从JSON数据读取数据并创建DataFrame
json_df = spark.read.json("data.json")# 从JDBC数据库读取数据并创建DataFrame,定义数据库连接属性
url ="jdbc:mysql://localhost:3306/your_database_name"
properties ={"user":"your_username","password":"your_password","driver":"com.mysql.jdbc.Driver"}
jdbc_df = spark.read.jdbc(url, table="your_table_name", properties=properties)# 从Hive表读取数据并创建DataFrame
spark = SparkSession.builder \
.appName("ReadHiveTableExample") \
.enableHiveSupport() \
.getOrCreate()
hive_df = spark.table("your_hive_table_name")# 读取hive数据库
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
spark.sql("LOAD DATA LOCAL INPATH 'data/kv1.txt' INTO TABLE src")
df = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")# 5.2 读取mysql数据库
url ="jdbc:mysql://localhost:3306/test"
df = spark.read.format("jdbc") \
.option("url", url) \
.option("dbtable","runoob_tbl") \
.option("user","root") \
.option("password","8888") \
.load()\
2. 保存/写入数据
在PySpark中,您可以使用DataFrame API或RDD API将数据保存或写入不同的数据源。Spark支持将数据写入到各种格式的文件(如CSV、Parquet、JSON等),以及数据库(如Hive、MySQL等)。以下是保存数据的一些常见方法:
- 使用DataFrame API保存数据:使用DataFrame API时,可以使用write方法将数据保存到指定的数据源。
- 使用RDD API保存数据:使用RDD API时,可以使用相应的方法将RDD保存到指定的数据源。
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("SaveDataFrameToCSV") \
.getOrCreate()
df = spark.read.csv("data.csv", header=True, inferSchema=True)# 保存为CSV文件
df.write.csv("output.csv", header=True)# 保存为Parquet文件
df.write.parquet("output.parquet")# 保存为JSON文件
df.write.json("output.json")# 保存到Hive表
df.write.saveAsTable("hive_table_name")
3. Dataframes
DataFrame是一个类似于SQL表的分布式数据集,是Spark中最常用的数据结构之一。DataFrame提供了更高级的API和更多的优化,用于处理和分析结构化数据。它是由行和列组成的分布式数据集合,类似于pandas里的dataframe。创建DataFrame的常见方式有:
- 从本地集合创建DataFrame
- 使用RDD来创建
- 从文件创建DataFrame(如CSV文件)
# 从本地集合创建DataFrame
data =[("Alice",34),("Bob",45),("Cathy",29)]
columns =["Name","Age"]
df = spark.createDataFrame(data, columns)# 从RDD创建
rdd = sc.parallelize([("Sam",28,88),("Flora",28,90),("Run",1,60)])
df = rdd.toDF(["name","age","score"])# 从文件创建DataFrame
df = spark.read.csv("data.csv", header=True, inferSchema=True)
可以使用Spark SQL来执行SQL查询和操作DataFrame。通过SparkSession可以将DataFrame注册为临时表或全局表,然后可以使用SQL语句查询这些表。
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("MyApp") \
.master("local") \
.getOrCreate()
data =[("Alice",34),("Bob",45),("Cathy",29)]
columns =["Name","Age"]
df = spark.createDataFrame(data, columns)# 通过SparkSession可以将DataFrame注册为临时表
df.createOrReplaceTempView("people")
result = spark.sql("SELECT * FROM people WHERE Age > 30")
3. pyspark SQL函数
在PySpark中,SQL函数(SQL Functions)是一组用于数据处理和转换的内置函数,它们可以在SQL查询或DataFrame API中使用。PySpark提供了许多常见的SQL函数,用于字符串处理、数值计算、日期时间操作等,以及自定义函数的创建和使用。
以下是一些常用的PySpark SQL函数示例:
字符串处理函数:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, concat_ws, upper
# 创建SparkSession
spark = SparkSession.builder \
.appName("SQLFunctionsExample") \
.getOrCreate()# 创建DataFrame
data =[("John","Doe"),("Alice","Smith"),("Mike","Brown")]
df = spark.createDataFrame(data,["first_name","last_name"])# 使用concat_ws函数连接两列,以空格分隔
df.withColumn("full_name", concat_ws(" ", col("first_name"), col("last_name"))).show()# 使用upper函数将文本转换为大写
df.withColumn("upper_first_name", upper(col("first_name"))).show()
数值计算函数:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col,round, sqrt
# 创建SparkSession
spark = SparkSession.builder \
.appName("SQLFunctionsExample") \
.getOrCreate()# 创建DataFrame
data =[(1,2),(3,4),(5,6)]
df = spark.createDataFrame(data,["col1","col2"])# 使用round函数对列进行四舍五入
df.withColumn("rounded_col1",round(col("col1"),2)).show()# 使用sqrt函数计算平方根
df.withColumn("sqrt_col2", sqrt(col("col2"))).show()
日期时间函数:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, current_date, date_format
# 创建SparkSession
spark = SparkSession.builder \
.appName("SQLFunctionsExample") \
.getOrCreate()# 创建DataFrame
data =[(1,"2023-07-25"),(2,"2023-07-26"),(3,"2023-07-27")]
df = spark.createDataFrame(data,["id","date_str"])# 使用current_date函数获取当前日期
df.withColumn("current_date", current_date()).show()# 使用date_format函数格式化日期
df.withColumn("formatted_date", date_format(col("date_str"),"yyyy-MM-dd")).show()
三、Spark Streaming
PySpark Streaming是Apache Spark中的实时数据流处理组件,它允许您对实时数据流进行高效处理,并将数据流切分为小批次进行分布式处理。PySpark Streaming使用微批处理的方式,将连续的实时数据划分为小批次,然后在Spark集群上并行处理这些小批次,从而实现实时的数据处理和分析。
使用PySpark Streaming的一般步骤如下:
- 创建SparkContext和StreamingContext。
- 指定数据源,使用socketTextStream()、kafkaStream()等方法来接收实时数据流。
- 使用转换操作(Transformations)对数据进行处理,如map()、filter()、reduceByKey()等。
- 使用行动操作(Actions)触发实际的计算。
- 启动StreamingContext,开始接收和处理数据流。
- 等待StreamingContext终止,或手动终止StreamingContext。
四、MLlib
MLlib(Machine Learning Library)是Spark中用于机器学习的库,提供了各种常见的机器学习算法和工具,如分类、回归、聚类、特征提取等。
MLlib的功能可以分为以下几个方面:
- 数据处理: - 特征提取:MLlib提供了各种特征提取方法,如TF-IDF、Word2Vec、CountVectorizer等,用于将原始数据转换为可供机器学习算法使用的特征向量。- 特征转换:MLlib支持特征转换操作,例如标准化、归一化、离散化等,以便更好地适应不同的机器学习算法和数据分布。- 数据清洗:MLlib提供了数据清洗工具,用于处理缺失值、异常值等,以确保数据质量。
- 机器学习算法: - 监督学习算法:包括线性回归、逻辑回归、决策树、随机森林、梯度提升树等,用于解决分类和回归问题。- 无监督学习算法:包括K-means聚类、Gaussian Mixture Model聚类、主成分分析(PCA)等,用于无标签数据的聚类和降维。- 协同过滤:MLlib提供了基于ALS(交替最小二乘)的协同过滤算法,用于推荐系统和推荐引擎。
- 模型评估和调优: - 模型评估:MLlib提供了一系列评估指标,如准确率、F1值、均方误差(MSE)等,用于评估机器学习模型的性能。- 模型调优:MLlib支持使用交叉验证等技术进行模型调优,帮助选择最优的超参数。
- 数据流处理: - PySpark Streaming:MLlib支持在实时数据流上进行在线机器学习,可以结合PySpark Streaming进行实时数据处理和模型预测。
- 其他工具: - Spark ML Pipelines:MLlib提供了Spark ML Pipelines,用于构建复杂的机器学习工作流,并将特征提取、转换、模型训练等步骤组合在一起。- 分布式计算:MLlib充分利用Spark的分布式计算能力,在大规模数据集上高效地进行机器学习训练和预测。
版权归原作者 李明朔 所有, 如有侵权,请联系我们删除。