
hbase特点
1,大:一个表可以有数十亿行,上百万列;
2,无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中 不同的行可以有截然不同的列;
3,面向列:面向列(族)的存储和权限控制,列(族)独立检索;
4,稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
5,数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入 时的时间戳;
6,数据类型单一:Hbase中的数据都是字符串,没有类型;
hbase使用场景
hbase架构图
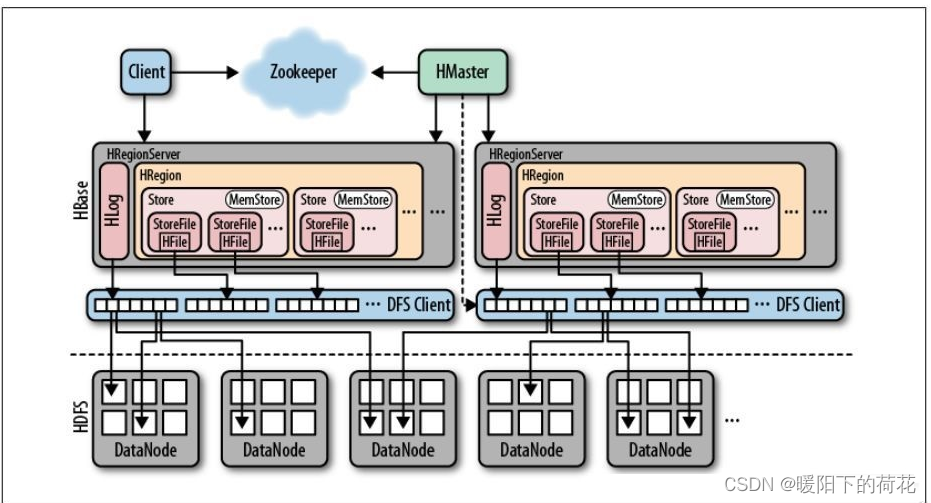
hbase架构
hbase读写流程
hbase读流程
1,获取meta表的rootregion的位置信息
客户端执行读流程时,第一次读时,先通过zk获取meta表对应region位置信息,并加到进程缓存中,后续在有读的操作,直接读取缓存中meta信息中的region信息即可。
2,找数据写在哪个region上
根据上面获取到的rootregion位置信息,请求region所在的region server服务,根据库名.表名.rowkey找meta表中对应region信息
找到小于并且最接近rowkey的startkey对应的region 便是目标region
3,发起实际的读取请求
** **向region对应的region server发起读取请求
4,先从memstore中查找数据 找到返回,没找到下一步操作
5,在从blockcache中查找数据 找到返回,没找到下一步操作
6,在从storefile中查找数据找到返回 没找到返回null
如果从storefile中读取到的数据 先要写入到blockcache后在进行返回客户端
hbase写流程
1,获取meta.的rootregion位置信息
在客户端写进程内,第1次写时,Client先通过zookeeper获取从.META.表对应的region位置信息, 并加入到进程缓存中,后续再读或再 写时,直接读取缓存的.meta.信息对应的region信息即可
2,找到数据要写到哪个region上
根据上面获取到的rootregion位置信息,请求region所在的region server服务,根据库名.表名.rowkey找meta表中对应region信息
找到小于并且最接近rowkey的startkey对应的region 便是目标region
3,发起实际的写入请求
** **向region对应的region server发起写入请求
4,WAL log写入
将插入/更新写入WAL中。当客户端发起put/delete请求时,考虑到写入内存MemStore会有丢失数据的风险, 因此在写入缓存前, HBase会先写入到Write Ahead Log (WAL)中(WAL存储在HDFS中) , 那么即使发生宕机,也可以通过WAL还原初始数据
5,memstore写入与StoreFile落盘
将更新写入memstore中,当增加到一定大小,达到预设的Flush size阈值时, 会触发flush memstore,把memstore中的数据写出到 hdfs上,生成- -个storefile
6,StoreFile合并
随着Storefile文件的不断增多,当增长到一定阈值后,触发compact合并操作,将多个storefile合并成- 一个, 同时进行版本合并和数据删 除
storefile通过不断compact合并操作,逐步形成越来越大的storefile
7,Region拆分
单个stroefile大小超过- -定阈值后, 触发split操作, 把当前region拆分成两个,新拆分的2个region会被hbase master分配到相应的2个regionserver上。
hbase优化
标签:
hbase
本文转载自: https://blog.csdn.net/m0_55425657/article/details/126742353
版权归原作者 暖阳下的荷花 所有, 如有侵权,请联系我们删除。
版权归原作者 暖阳下的荷花 所有, 如有侵权,请联系我们删除。