
起因是tomcat 调用servlet输出的System.out.println(也就是所说的控制台输出流)中文乱码,但是正常输出没有受到影响,提供了两种解决方案,要理解原因请务必看到最后。
运行环境:JDK 21 Tomcat 10.1.30 IDEA 2024.2.2 Windows 11 23H2
省流:从tomcat处启动的java虚拟机没有提供输出流的编码,导致其默认调用的是windows本地字符集(我们是GBK),UTF8控制台接一个GBK字符串,可想而知结果一定是乱码
不配置虚拟机选项(VMOptions)
- IDEA控制台的编码改成GBK,tomcat9开始会自动把URL编码解码成UTF-8,而不是ISO-8859-1,这也是乱码的根源,具体原因在下面说。
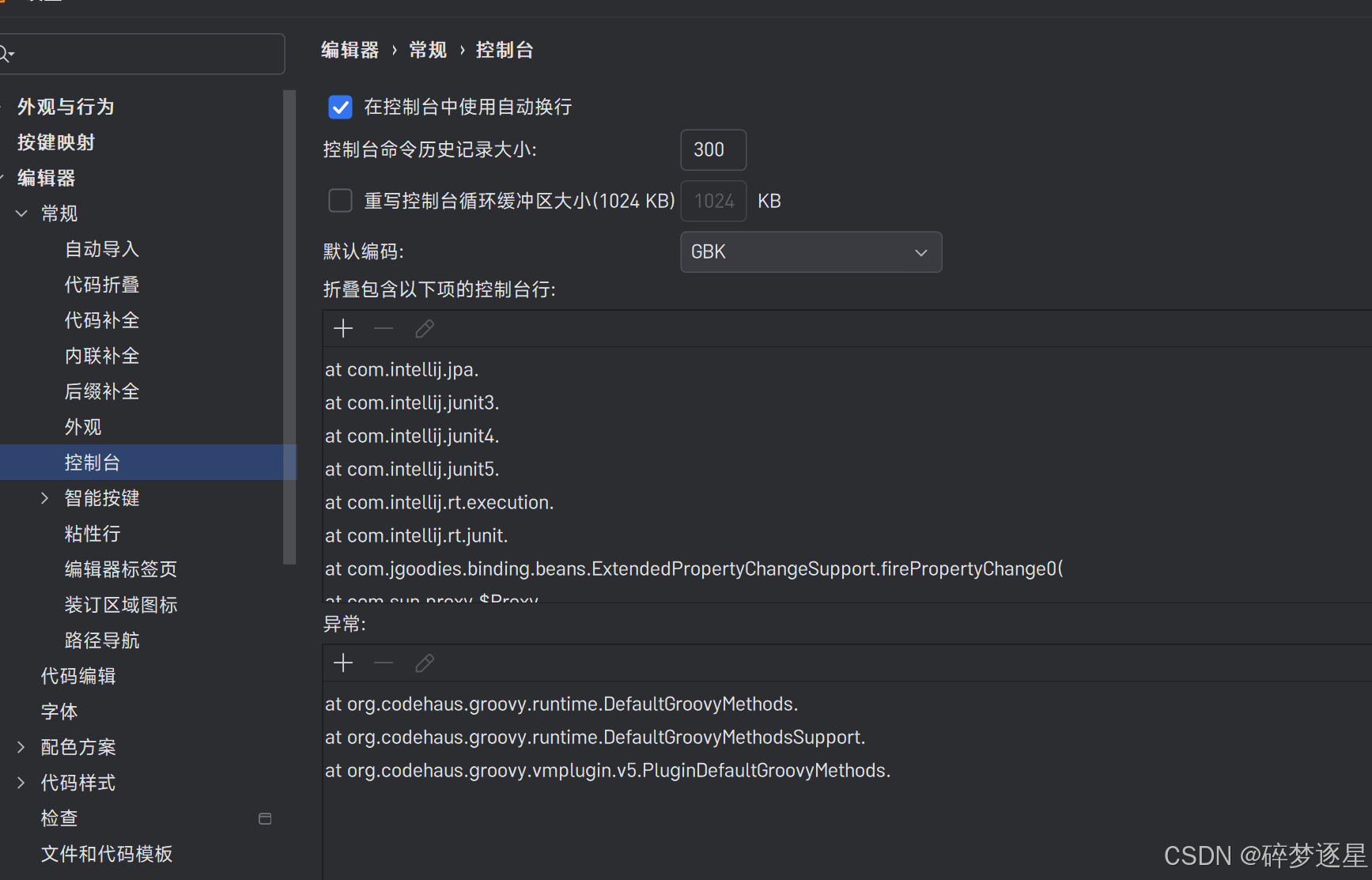
- conf/logging.properties 五个编码,最后一个改成GBK,适应上文的GBK控制台
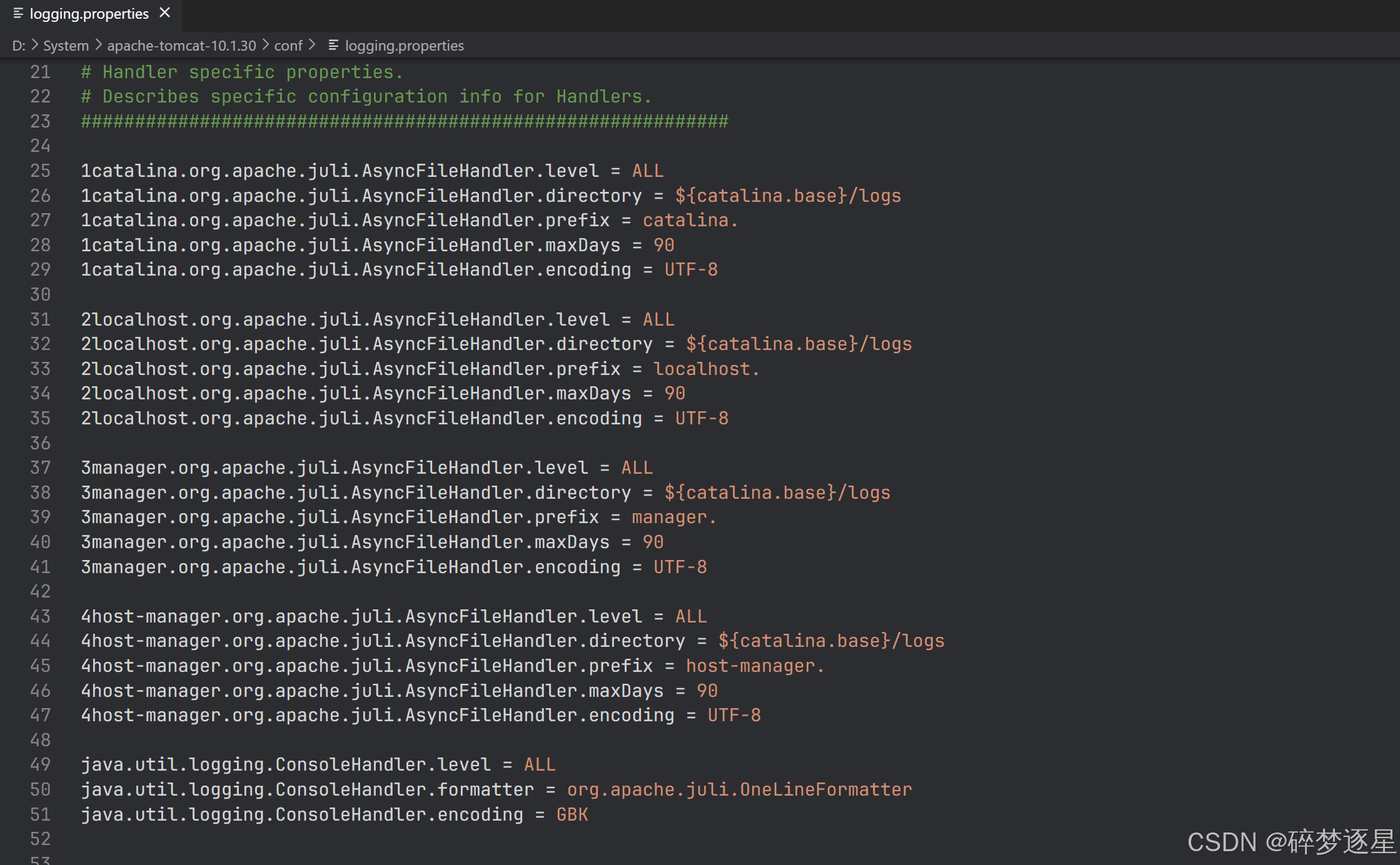
有意思的一点是,这里正常输出println到控制台能正确显示中文,我源代码是utf-8,这些字符串也理应是utf8的编码,拿System流自带的getProperty方法拿到的输出流编码也是utf-8。但我的idea控制台是GBK编码,即使从控制台输入中文也能正确解析,这里估计是idea的控制台能自己转换。

总结一下,日志编码和println输出流的编码是不一样的,为了更好的兼容性,我们文件里的编码一定要全部用utf-8,毕竟控制台只是一个临时调试的地方,主要功能是显示内容,gbk控制台不会影响输出的内容,这种方法是自己摸索出来的,如果要完全统一编码格式为utf-8请用下面这种方法
配置VMOptions
我是JDK21,普通的UTF-8控制台能输出中文但是到了tomcat就输出乱码
这是目前找到唯一修改虚拟机参数能有效解决乱码的方法,参数跟着服务器走,也很方便,如果有乱码的情况加这两个参数就行了。
参考解决 Java 18 以上 IDEA 中文输出乱码问题 - 知乎 (zhihu.com)
在对应服务器配置的虚拟机选项处添加 -Dstdout.encoding=UTF-8 -Dstderr.encoding=UTF-8(JDK19-21有效),记得把logging.properties里面全部改回UTF-8

乱码终极原因探究
参考JEP 400: UTF-8 by Default (openjdk.org) 通过调用getProperty方法获取默认字符集
System.out.println("Java Runtime version " + System.getProperty("java.runtime.version"));
System.out.println("---------------------------------------------------------");
System.out.println("Charset.defaultCharset() = " + Charset.defaultCharset());//全局默认编码 JDK21是UTF
System.out.println("System.getProperty(\"file.encoding\") = " + Charset.defaultCharset().displayName());//默认文件的编码,这个应该是字节码文件
System.out.println("System.getProperty(\"native.encoding\") = " + System.getProperty("native.encoding"));//获取的是本地的字符集编码,中文windows系统应该是gbk
System.out.println("System.getProperty(\"sun.jnu.encoding\") = " + System.getProperty("sun.jnu.encoding"));
System.out.println("System.getProperty(\"sun.stdout.encoding\") = " + System.getProperty("sun.stdout.encoding"));//这个是输出流的默认字符集编码
System.out.println("System.getProperty(\"sun.stderr.encoding\") = " + System.getProperty("sun.stderr.encoding"));//这个是错误流的默认编码
System.out.println("System.console().charset() = " + System.console().charset());//console默认编码

全局默认文件编码就是UTF-8,这个指的是文件的内容编码,从JDK18开始就是UTF-8,这个没有疑问,问题就在于stdout.encoding, stderr.encoding, jnu.encoding。
先说jnu.encoding,这个的用途写得比较清楚,用于java.nio解析文件路径以及文件名,这个跟本地操作系统的默认编码native.encoding一样,不然会出很大的问题。

再说回控制台输出流,JEP400提到大部分API都转换成了Charset.defaultCharset字符集,也就是UTF-8。BUT,out和err流被排除在外,他们的字符集将被**Console.charset()**确定,同时也指出,JDK18并没有支持这三个参数设置(实际上可以设定)实际上直到JDK 19 才将这两个参数正式作为新特性添加,默认他们是依赖于平台的,当平台没有提供控制台的流时,将根据 native.encoding(GBK)编码。
而如果不通过方法二把参数加上,tomcat 10.1.30 就不会指定输出流的字符编码,导致虽然能把URL编码解析成UTF-8字符串,但是通过输出流发送到idea控制台就变成GBK字符串了,在idea这边可以设置一个GBK控制台接收 tomcat输出流 输出的GBK字符串,这就是第一种方法可行的原因。如果idea这边的控制台是UTF-8,就会乱码,下面来看几个调用的实例。
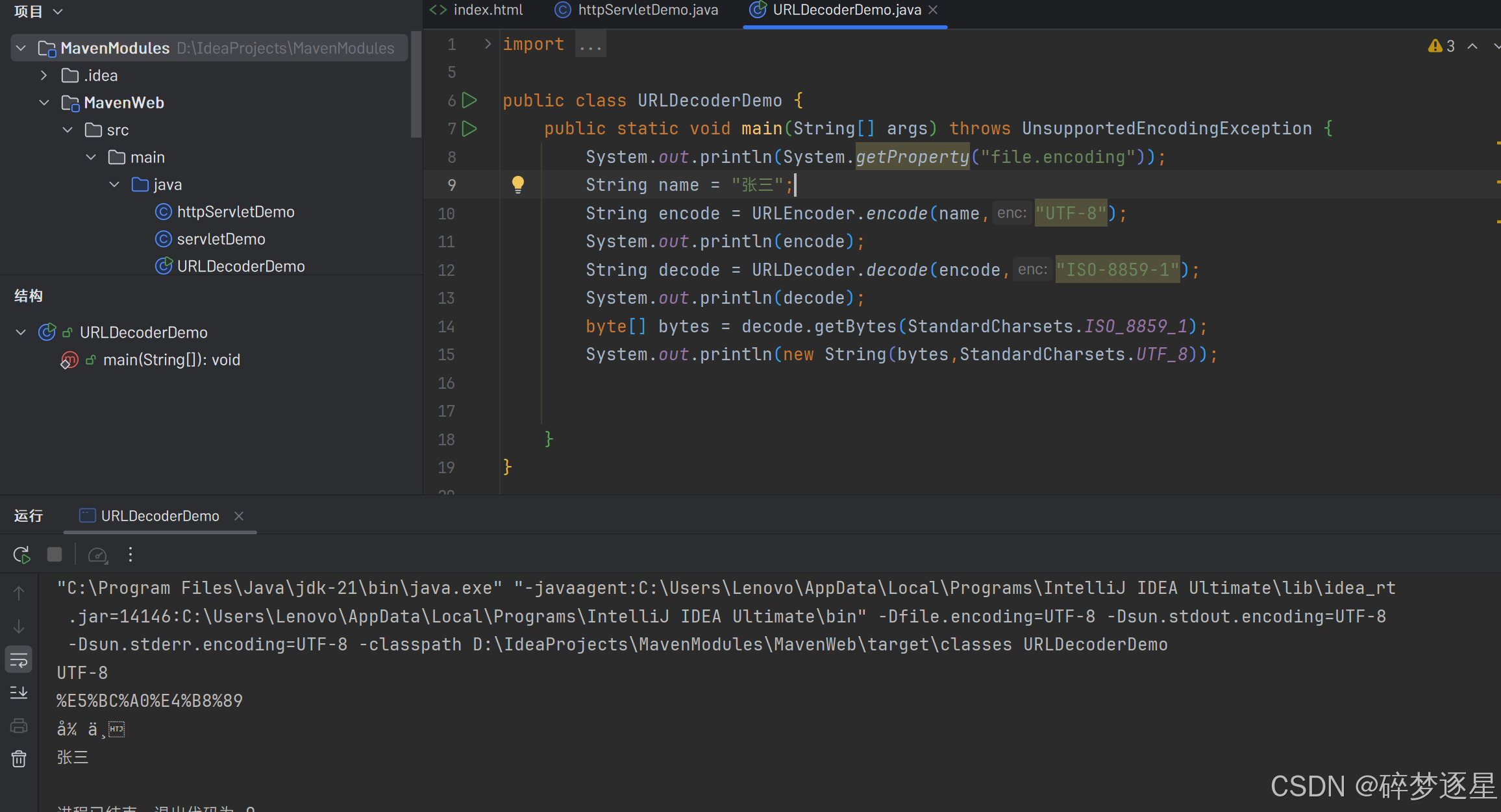
新建一个类,本地通过main调用方法,设置UTF-8控制台接收,显然idea指定了这两个参数
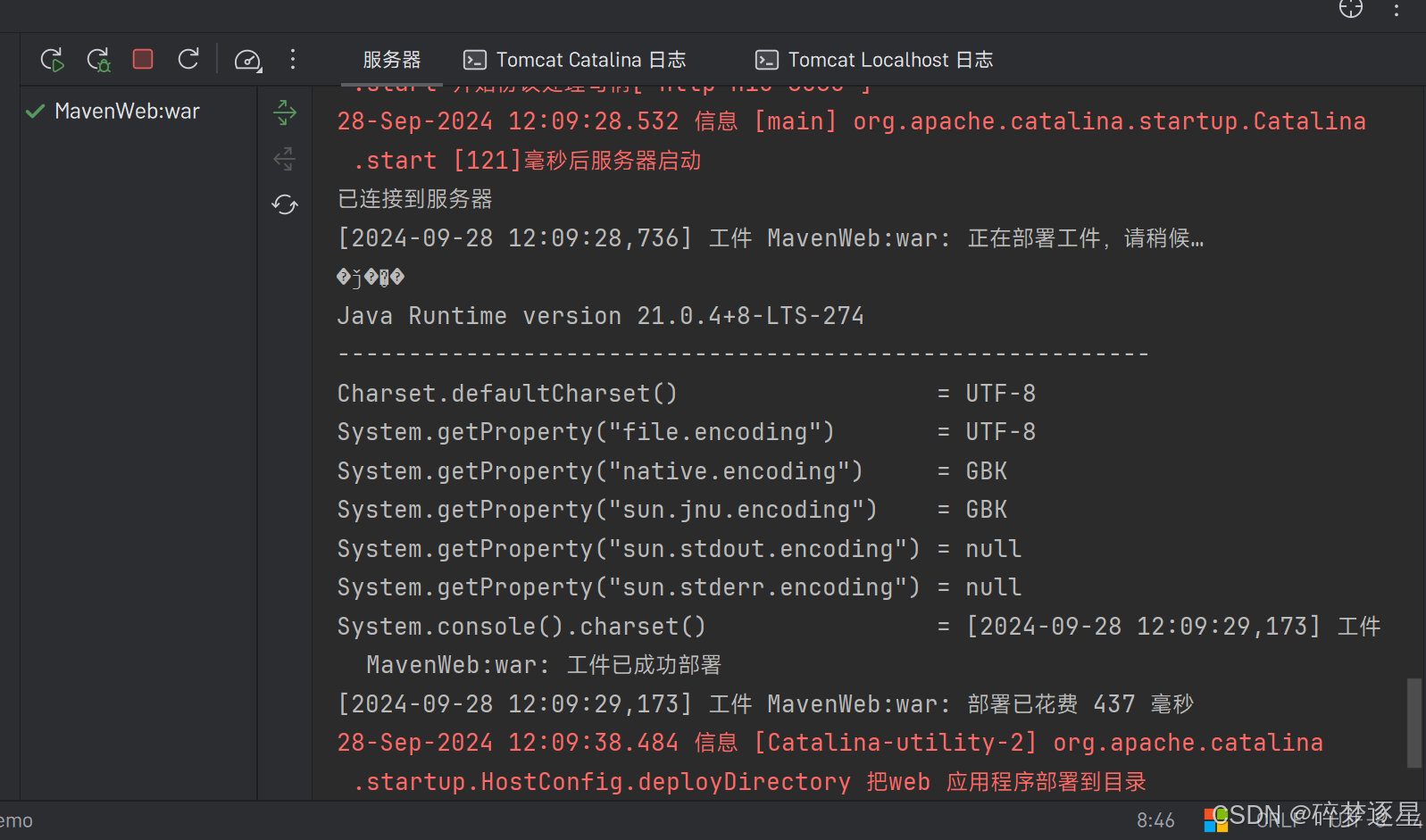
写进servlet,通过tomcat调用,没有加参数,UTF-8控制台
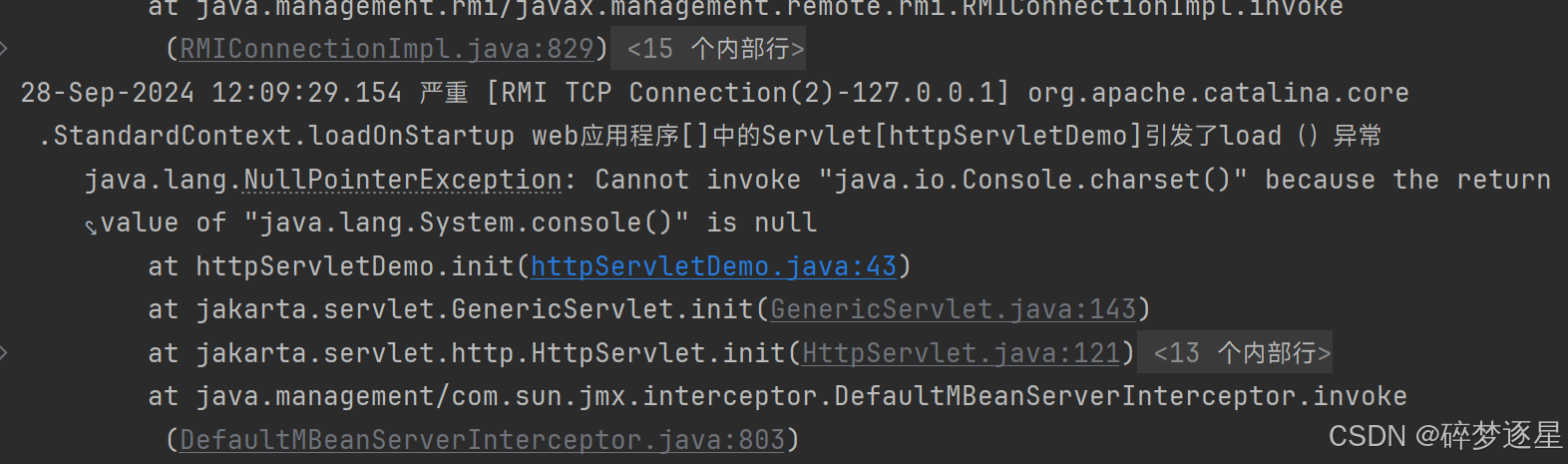
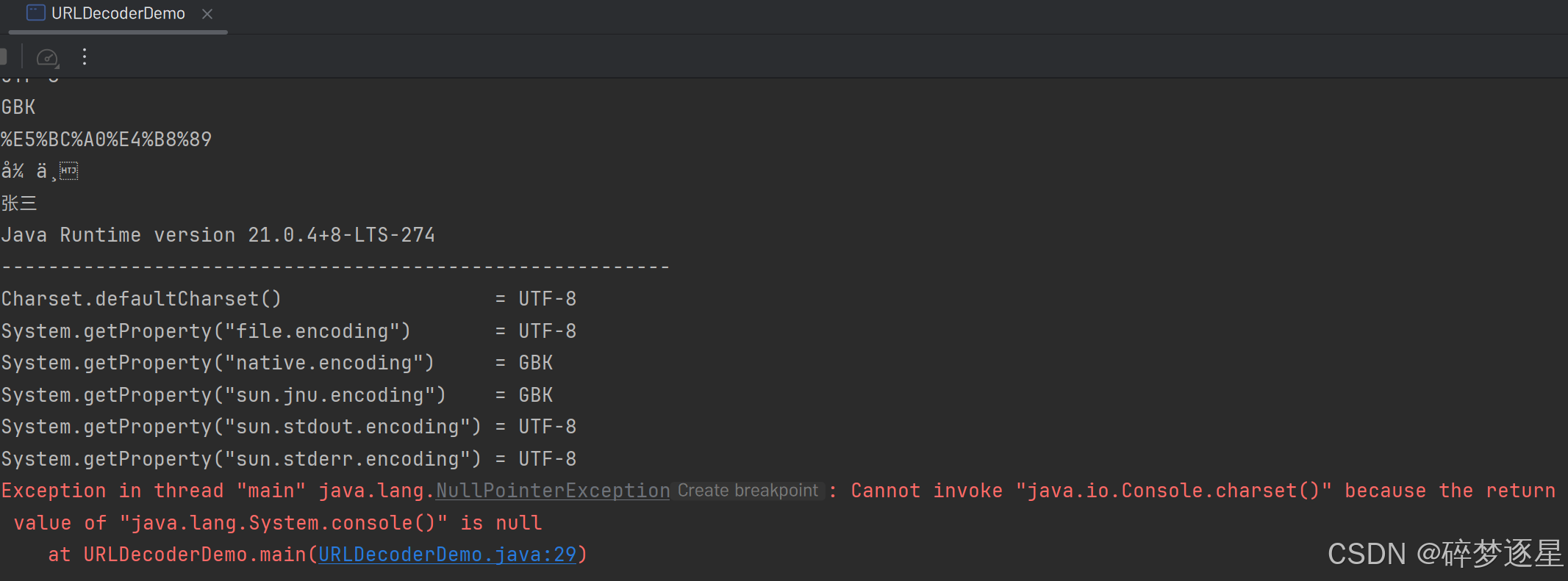
表面上tomcat运行正常,但实际上后台出了一个和本地调用一样的异常
看出来了么? Console.charset() 是没有返回值的, 而 tomcat 又不指定输出流的字符集,这两项参数就是null,最终导致控制台输出流以本地字符集GBK编码。故方法二运行时加上utf8参数的做法也是可行的。
总结
我是来学tomcat的,你们要干什么!
版权归原作者 碎梦逐星 所有, 如有侵权,请联系我们删除。