
Linux系统(Centos7)实现hadoop安装
工具:
Linux系统 :Centos7
JDK:JDK1.8
Hadoop:Hadoop-3.3.1
虚拟机:VMware Workstation Pro 16
本机系统:Windows10
一、虚拟机设置
1.设置虚拟机的网络连接方式
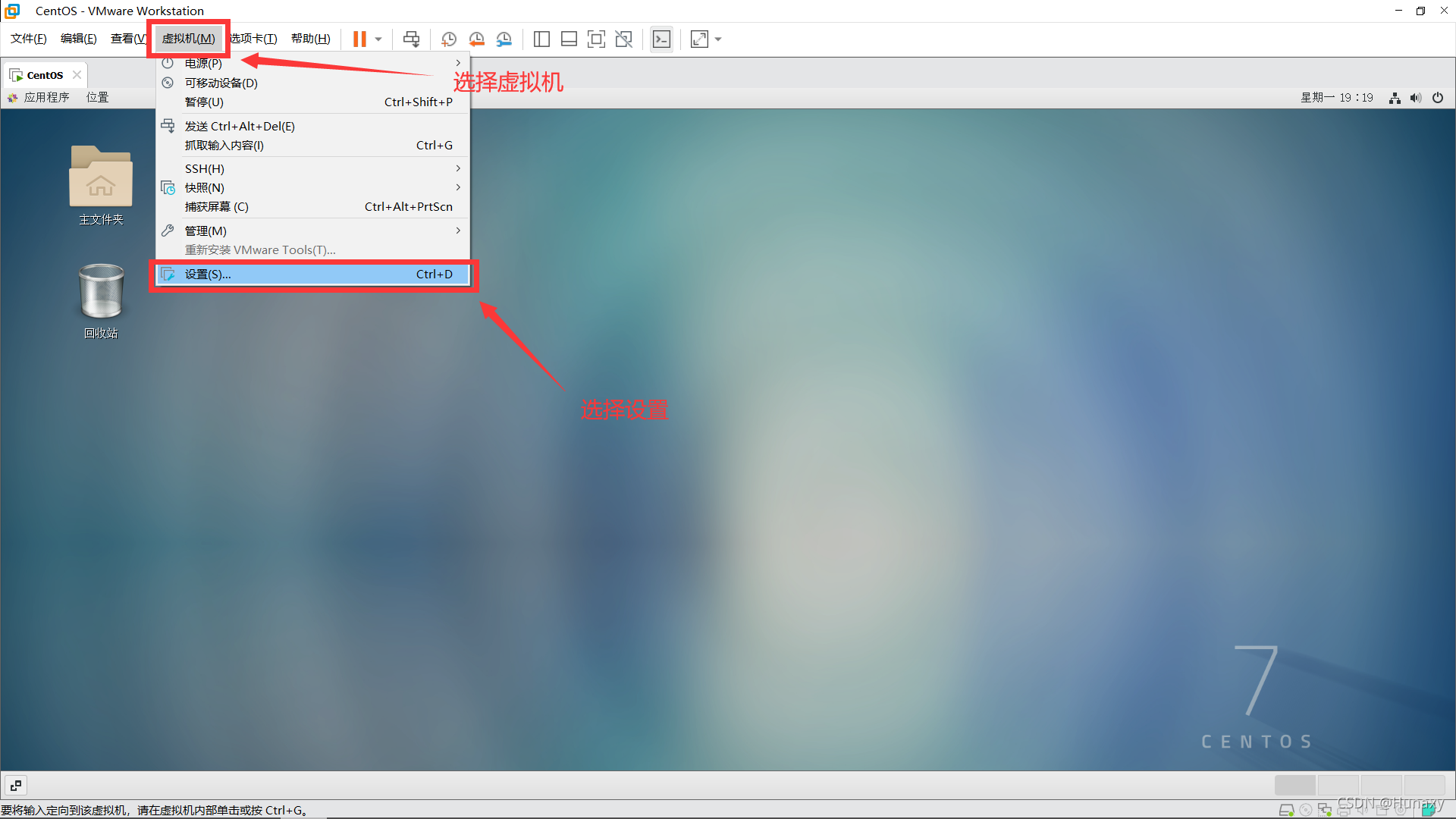

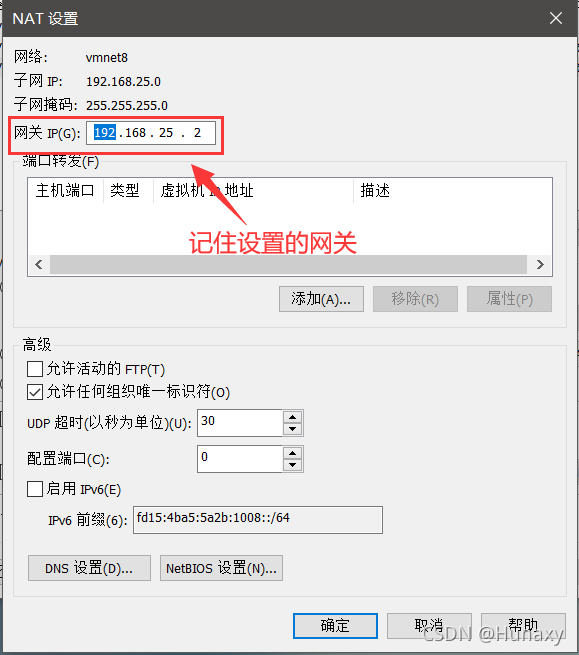
2.设置虚拟机网络配置
说明:修改子网IP设置,可自由设置固定IP;
若设置固定IP为192.168.2.2-255,例如:192.168.2.2,则子网IP为192.168.2.0;
若设置固定IP为192.168.1.2-255,例如:192.168.1.2,则子网IP为192.168.1.0;
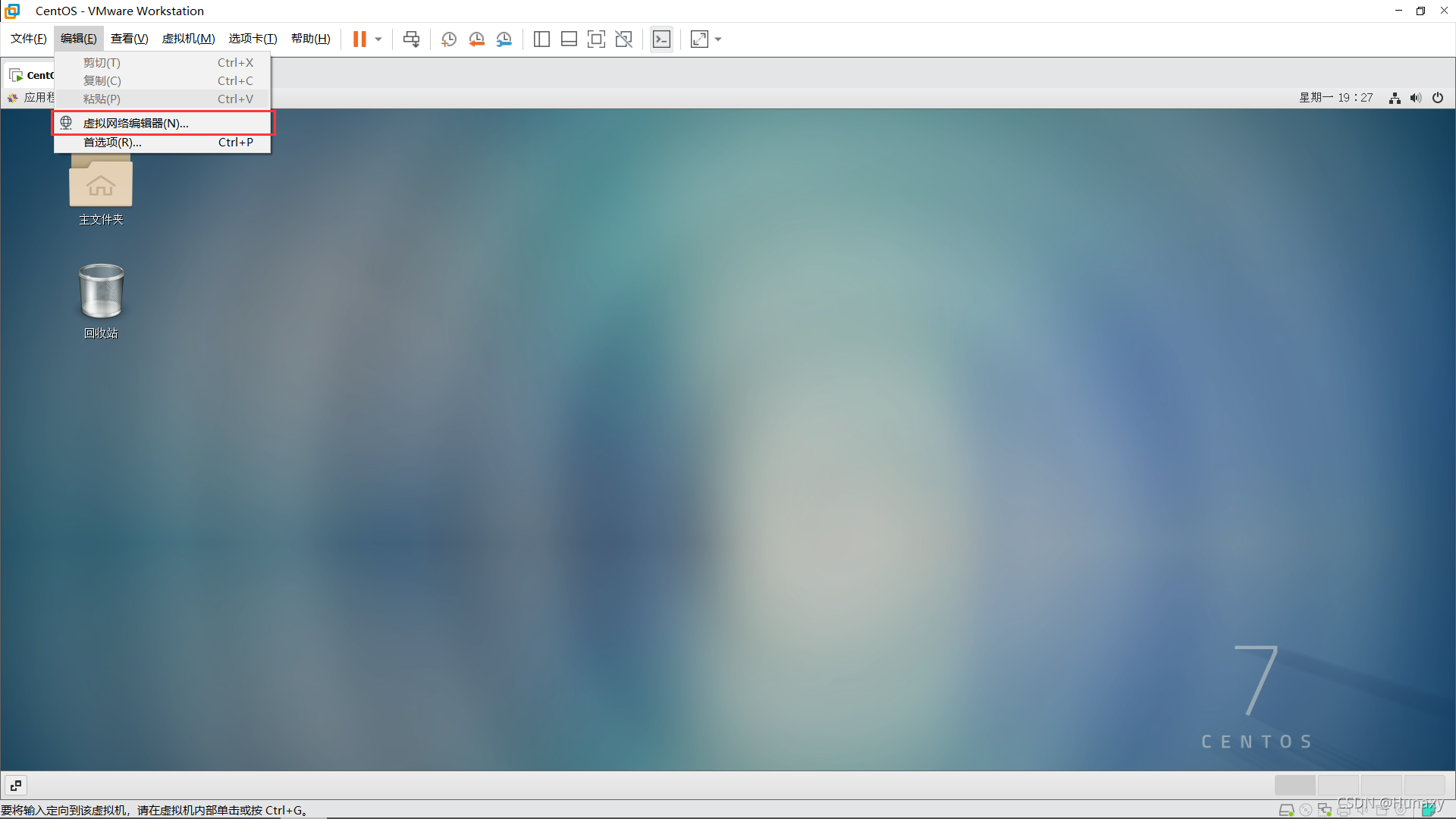
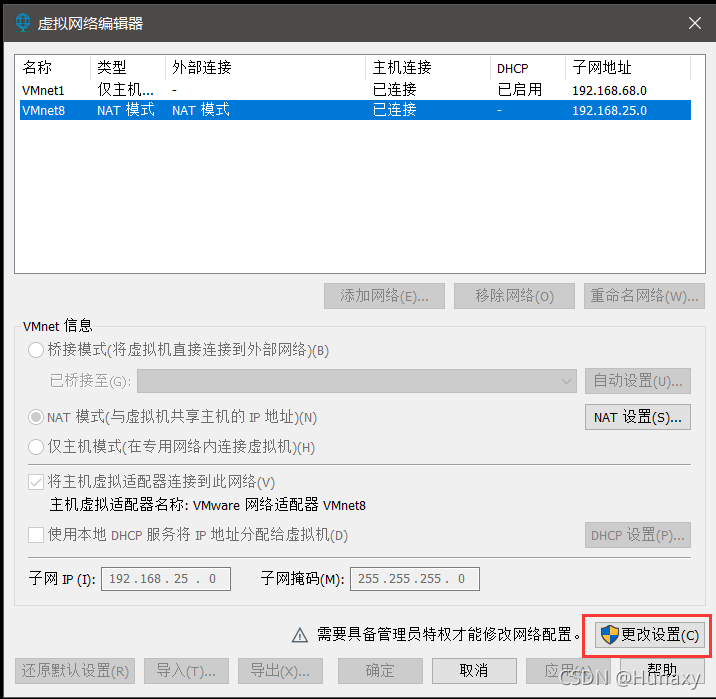
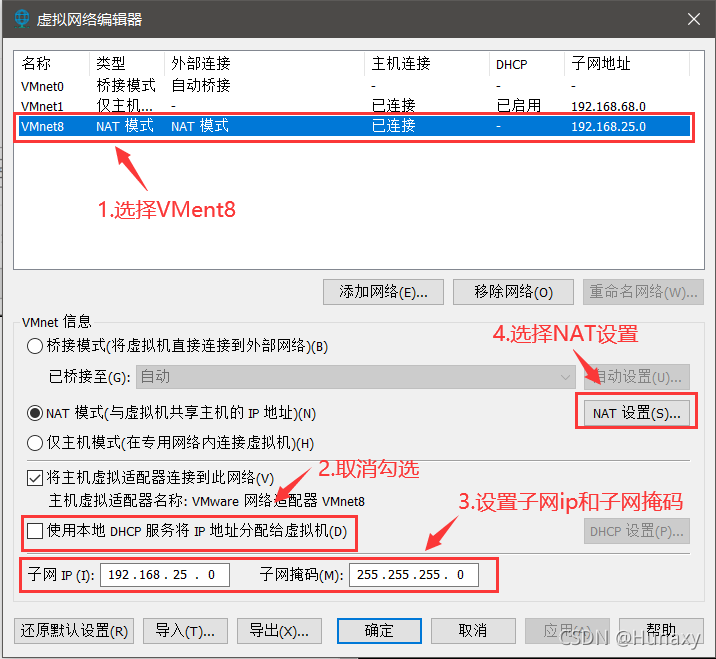
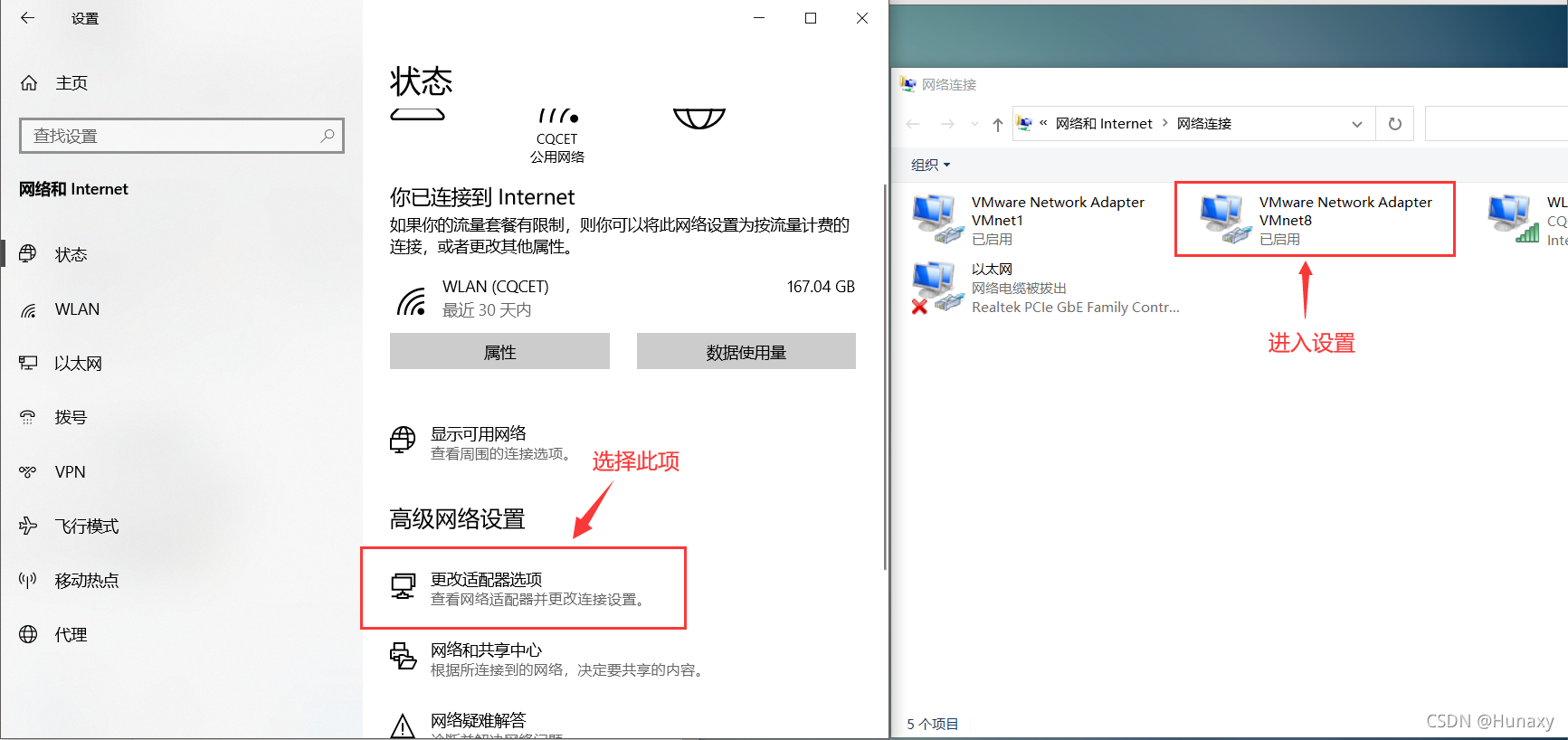
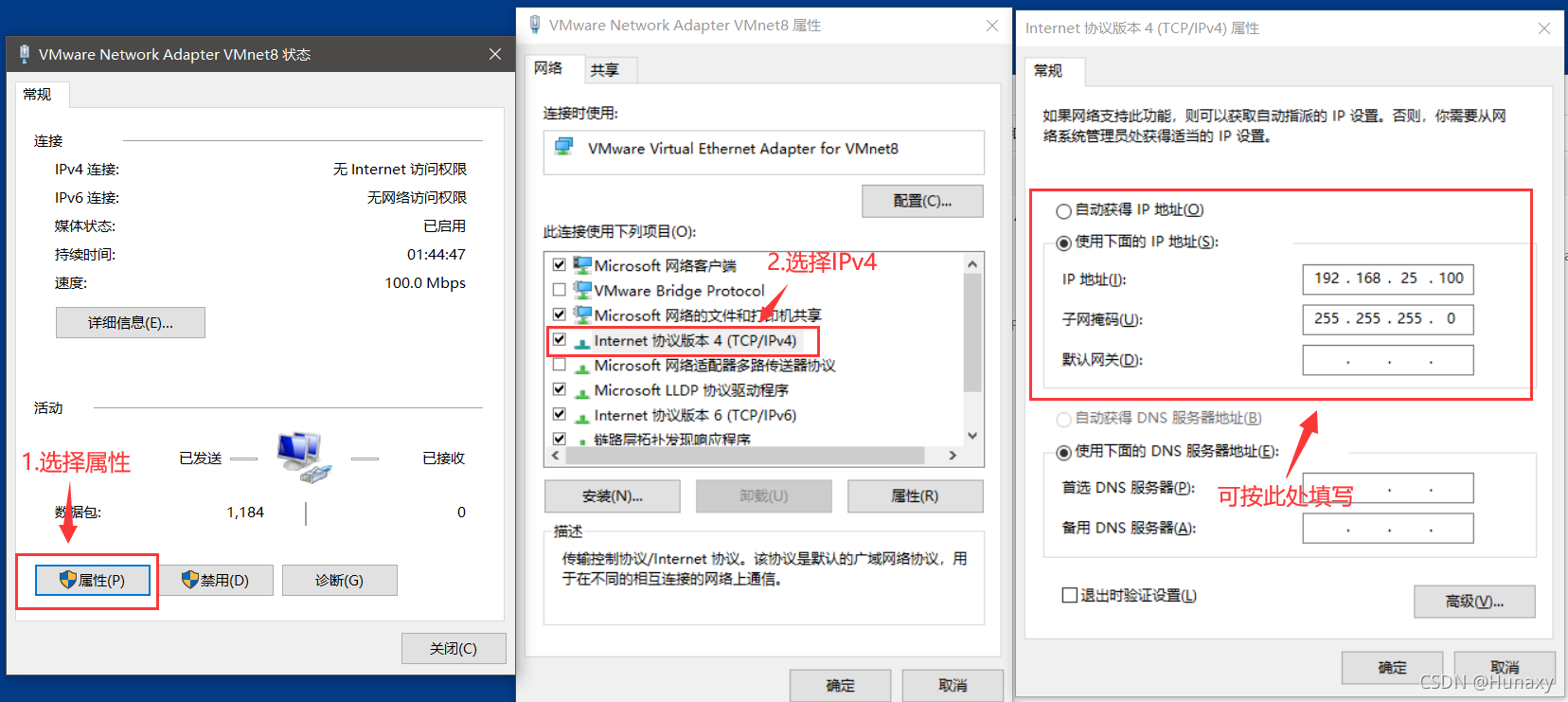
3.配置本机VMent8的本地参数
说明:IPv4中的ip地址可随意设置,但不能和虚拟机的固定ip一样。
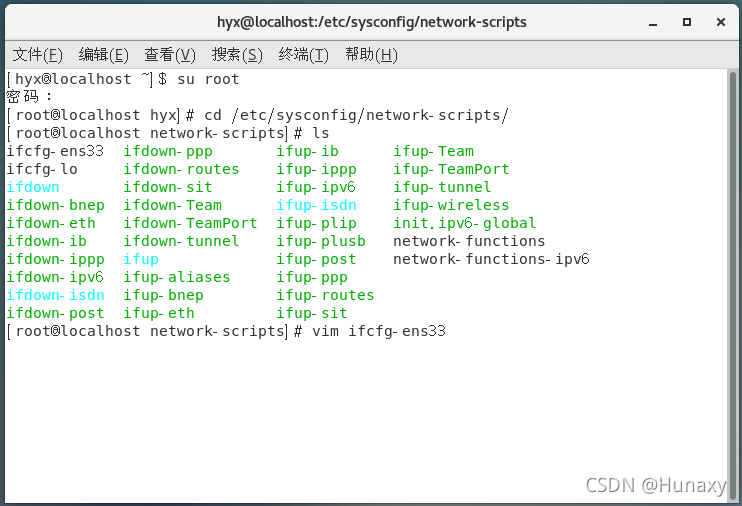
4.修改Centos7的网络配置文件
cd /etc/sysconfig/network-scripts/
ls #查看配置文件名字
vim ifcfg-ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.25.11
PREFIX=24
GATEWAY=192.168.25.2 #网关,这里需和NAT模式具体地址参数中设置的网关IP一致
DNS1=114.114.114.114
我的个人配置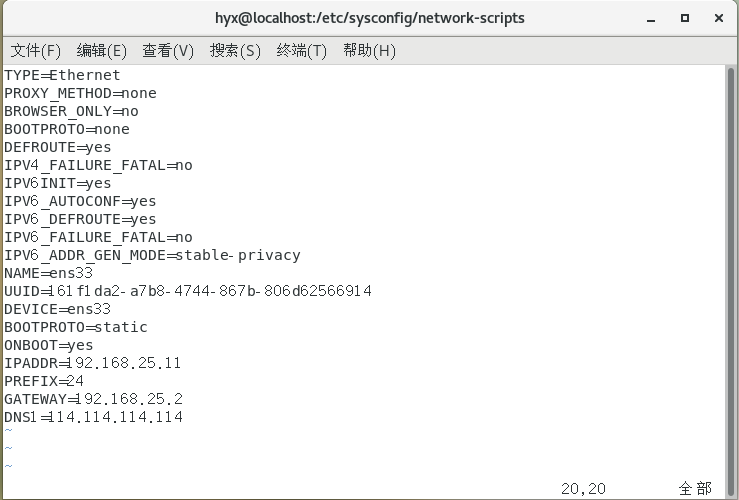
重启网络服务
service network restart
5.检查配置是否成功
(1)IP显示为设置后的IP则成功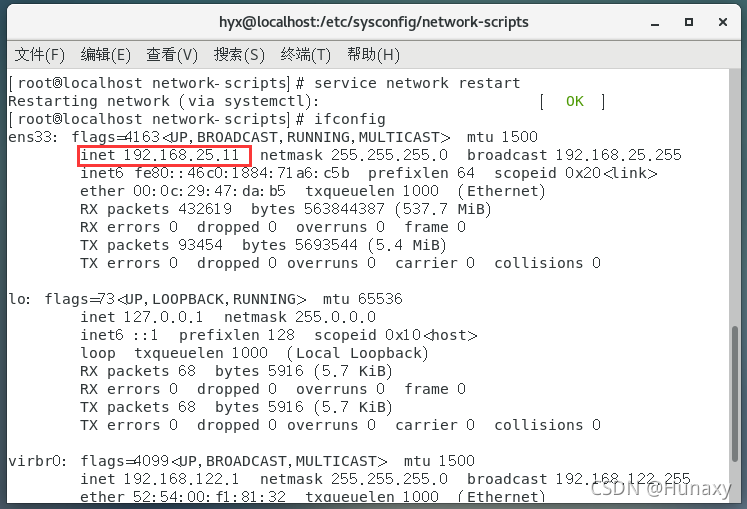
(2)测试是否能连通外网,若有数据返回则成功
ping -c 4 www.baidu.com

若显示未找到服务器,但ping外网ip有数据返回一样表示成功
(3)使用cmd测试本机能否ping通虚拟机IP
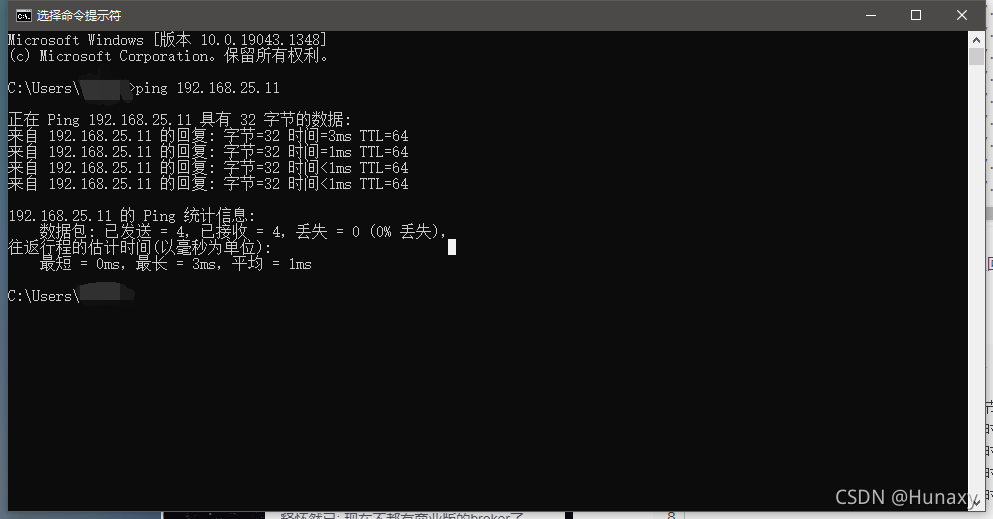
6.修改虚拟机主机名
修改主机名
查看主机名:终端输入hostname
修改主机名:终端输入hostname Master
注意:修改主机名不会立刻在终端上显示,重新打开终端就可看到主机名已更换
二、JDK安装
1.前往官网下载JDK安装包:https://www.oracle.com/java/technologies/downloads/#java8
2.解压文件:使用XFTP等文件传输软件进行压缩包的传输,此链接为免费版XFTP下载链接:https://www.netsarang.com/zh/free-for-home-school/
连接时只需要修改选中的参数,其他保持默认即可
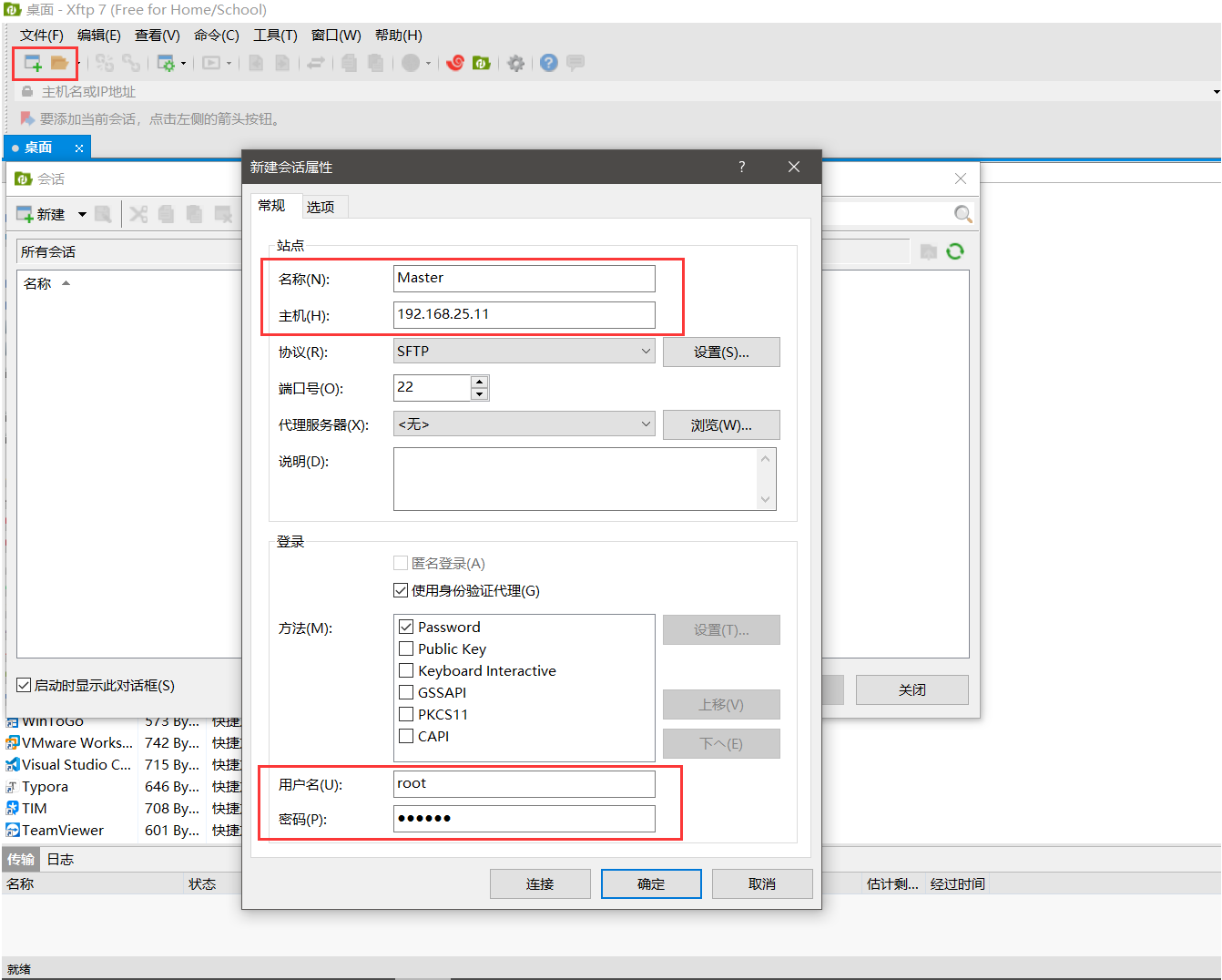
创建java文件夹并将jdk压缩包传入java文件夹中
也可以在终端中使用mkdir命令直接创建
进入jdk压缩包的目录下输入命令进行解压:
tar -zvxf jdk-8u202-linux-x64.tar.gz
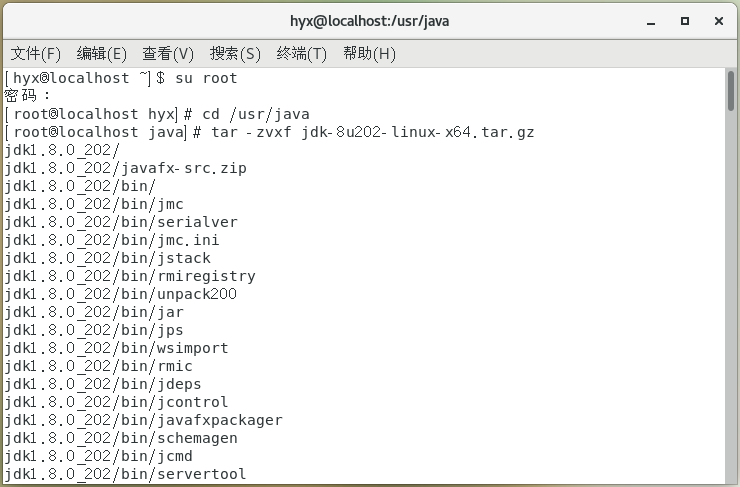
3.配置系统环境,命令:
vim /etc/profile
在文件中添加:
export JAVA_HOME=/usr/java/jdk1.8.0_202 # 此处为自己的jdk版本
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
重启环境并验证jdk是否安装成功
source /etc/profile
java -version

至此JDK安装完成
三、Hadoop安装与配置
1.Hadoop的安装与JDK安装一样,都是在usr文件夹下创建新的hadoop文件夹,使用XFTP将hadoop压缩包传入文件夹中并且解压
tar -zvxf hadoop-3.3.1.tar.gz
2.配置系统环境,与配置jdk时一样,输入命令:
vim /etc/profile
在文件中添加:
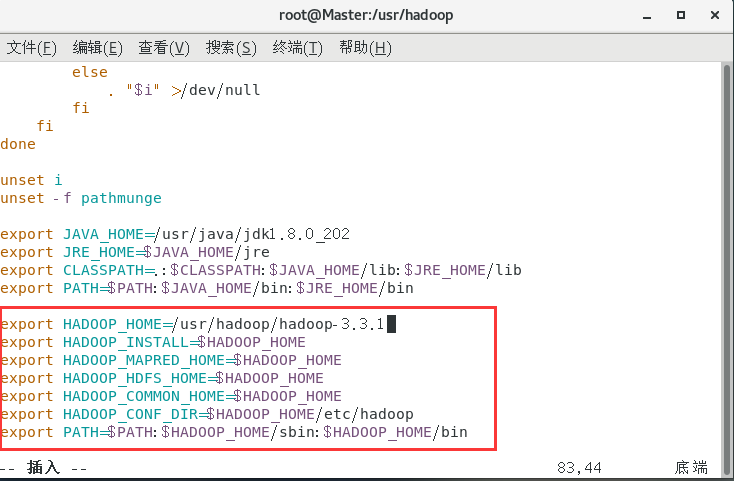
export HADOOP_HOME=/usr/hadoop/hadoop-3.3.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
重启环境并验证hadoop是否安装成功:
source /etc/profile
hadoop version
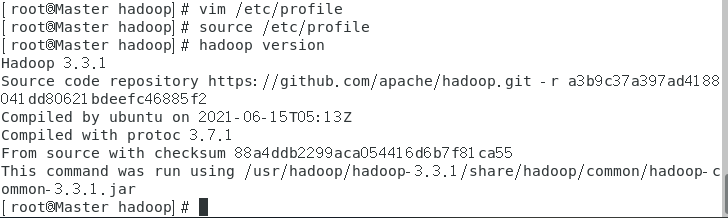
如图显示则表示hadoop安装成功
3.Hadoop完全分布式配置
(1)首先进入hadoop文件夹中创建几个文件夹:
mkdir /usr/hadoop/hadoop-3.3.1/tmp
mkdir /usr/hadoop/hadoop-3.3.1/data
mkdir /usr/hadoop/hadoop-3.3.1/data/namenode
mkdir /usr/hadoop/hadoop-3.3.1/data/datanode
mkdir /usr/hadoop/hadoop-3.3.1/pids
mkdir /usr/hadoop/hadoop-3.3.1/logs
(2)在终端上输入:
cd /usr/hadoop/hadoop-3.3.1/etc/hadoop
进入该文件夹中开始配置Hadoop完全分布式搭建所需的文件:
(注意将以下文件中的主机名和文件名修改为自己设置的主机名和文件名)
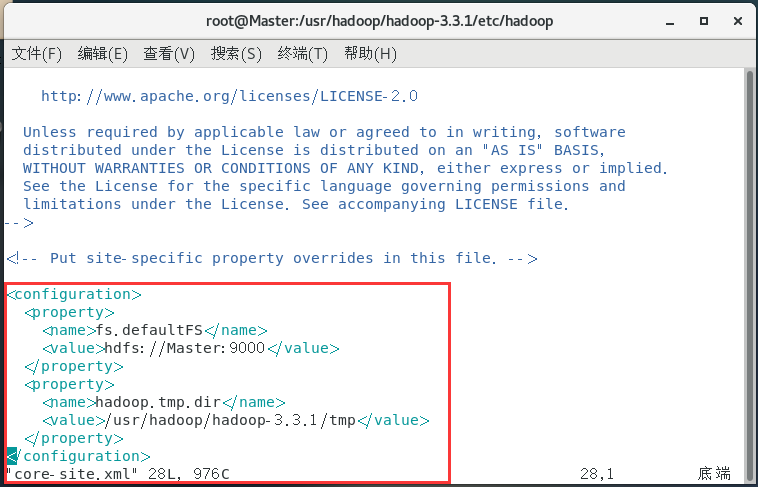
配置core-site.xml:
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-3.3.1/tmp</value>
</property>
</configuration>
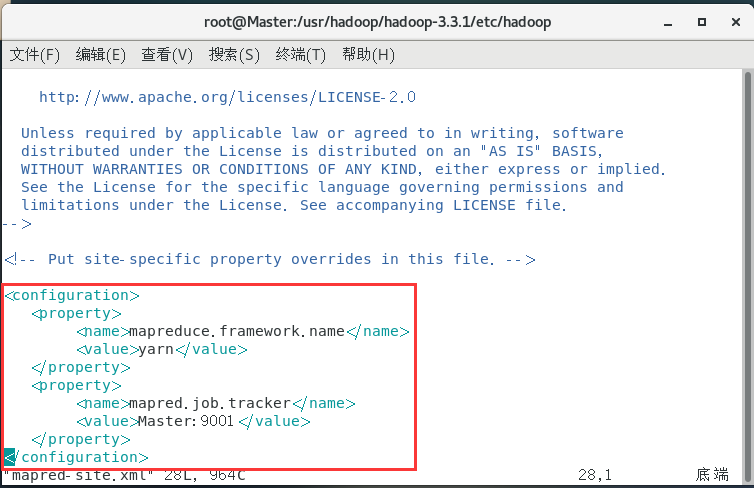
配置mapred-site.xml:
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
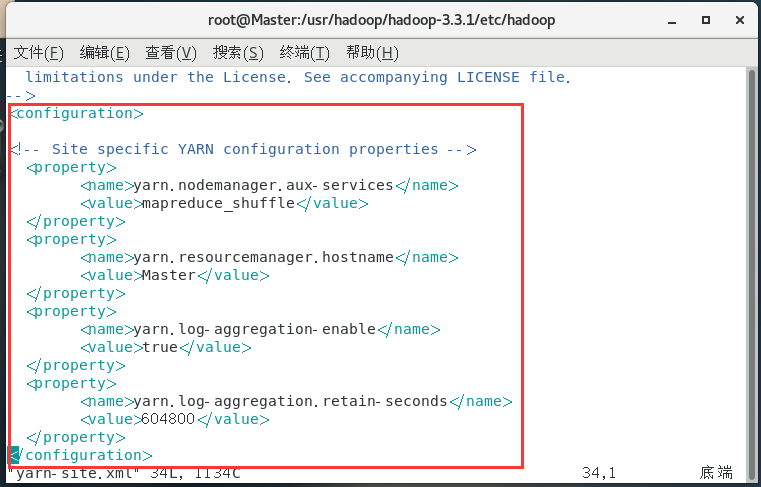
配置yarn-site.xml:
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
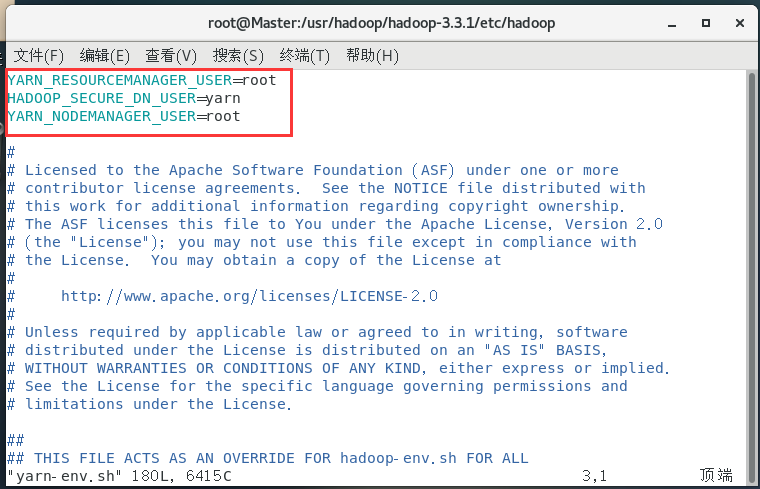
配置yarn-env.sh:
vim yarn-env.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
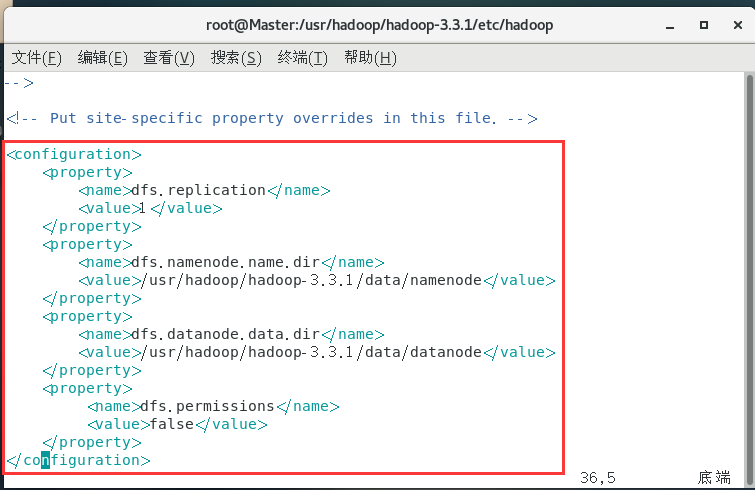
配置hdfs-site.xml:
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop/hadoop-3.3.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop/hadoop-3.3.1/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
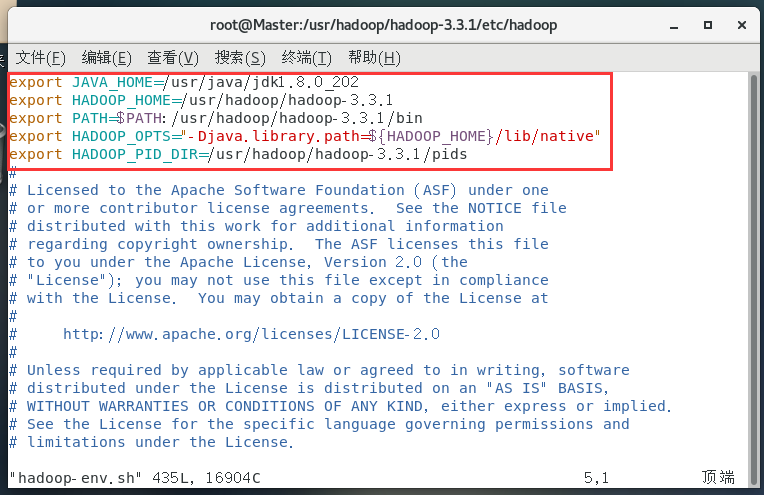
配置hadoop-env.sh:
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_202
export HADOOP_HOME=/usr/hadoop/hadoop-3.3.1
export PATH=$PATH:/usr/hadoop/hadoop-3.3.1/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/usr/hadoop/hadoop-3.3.1/pids
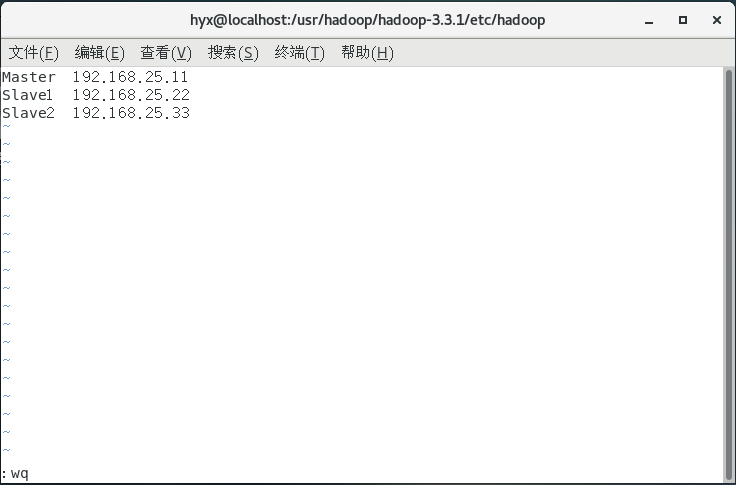
配置workers:
vim workers
打开文件后将文件内的内容替换为你的主机名和IP地址,这里先提前写下另外两台需要克隆的虚拟机名字,之后克隆的两台虚拟机需要按照此时输入的主机名和IP进行修改
在终端输入:
cd /usr/hadoop/hadoop-3.3.1/sbin/
进入新的目录中
配置start-dfs.sh:
vim start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
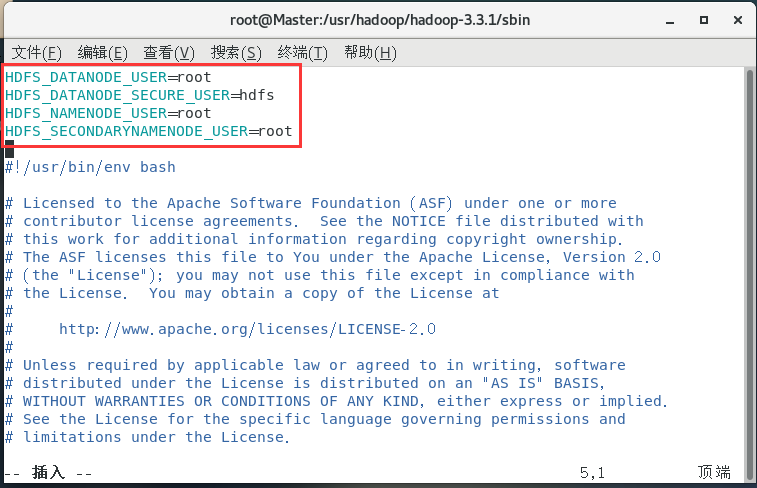
配置stop-dfs.sh:
vim stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
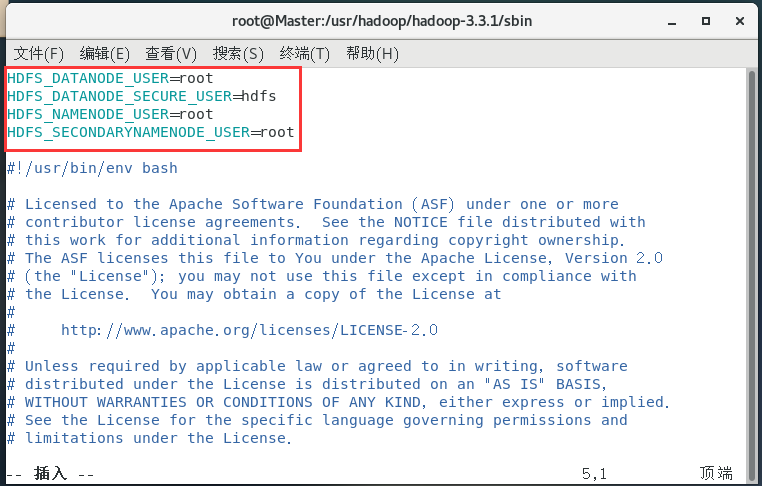
四、克隆虚拟机
1.关闭防火墙:
systemctl stop firewalld.service // 临时关闭防火墙
systemctl disable firewalld.service // 设置为开机不自启
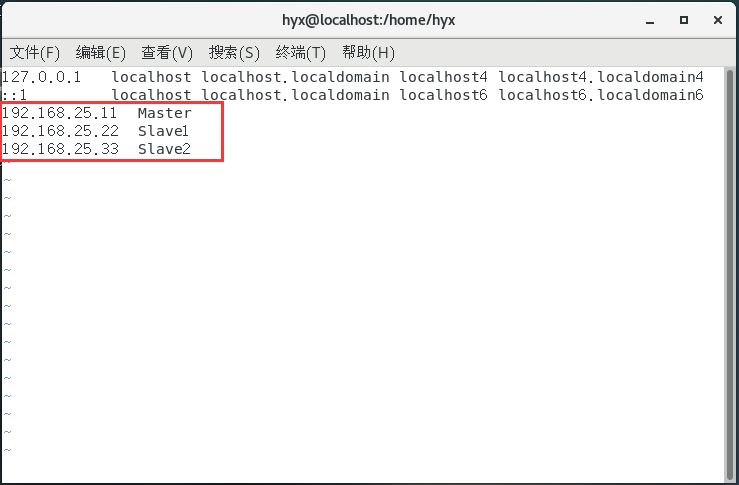
2.添加虚拟机映射
vi /etc/hosts
3.克隆两台虚拟机
关闭当前虚拟机,克隆其余两台虚拟机

4.修改克隆机设置
设置Slave1和Slave2的主机名和IP地址
使用 hostname 主机名 修改
修改IP的方法和文章开始修改Master主机IP一致

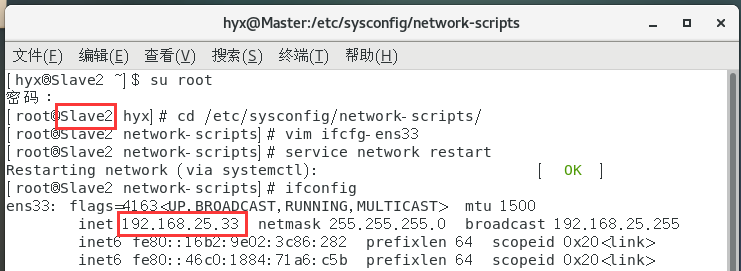
5.设置SSH免密登录
在三台虚拟机上输入:
cd ~/.ssh
ssh-keygen -t rsa
一直按回车直到结束
结束后在三台虚拟机终端中输入:
ssh-copy-id Master
ssh-copy-id Slave1
ssh-copy-id Slave2
再在Master上进行授权:
chmod 0600 authorized_keys
将授权文件发送到其他主机:
scp authorized_keys Slave1:/root/.ssh/
scp authorized_keys Slave2:/root/.ssh/
将密钥发送出去
若在任意一台虚拟机中使用:
ssh 主机名
能进入所输入的虚拟机中则表示免密登录成功
登录之后一定要使用exit退出后再尝试登录其他主机或进行其他操作
五、启动集群
1.三台虚拟机先进行格式化处理:
hdfs namenode -format
2.启动集群
在Master中输入:
start-all.sh
以此来启动集群,若要关闭集群则输入:
stop-all.sh
启动完毕之后输入jps查看状态
Master和Slave应该有如下信息:
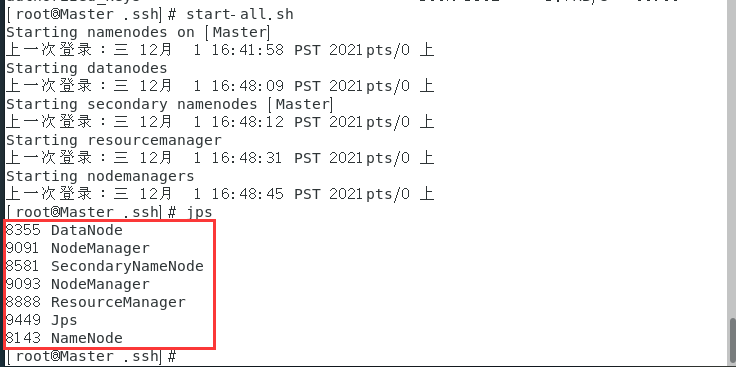
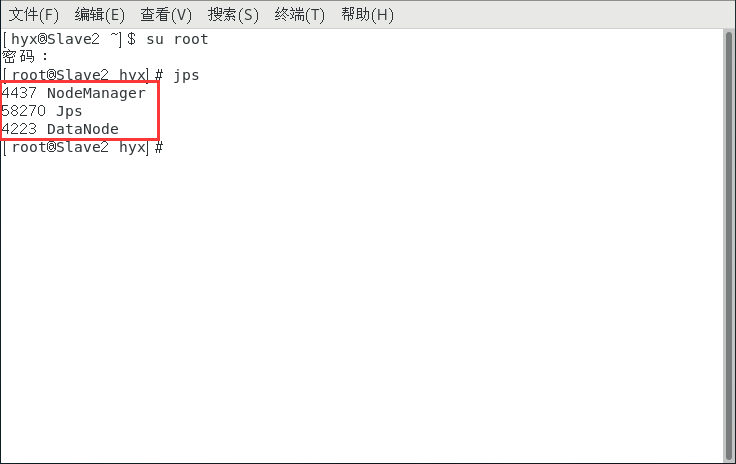
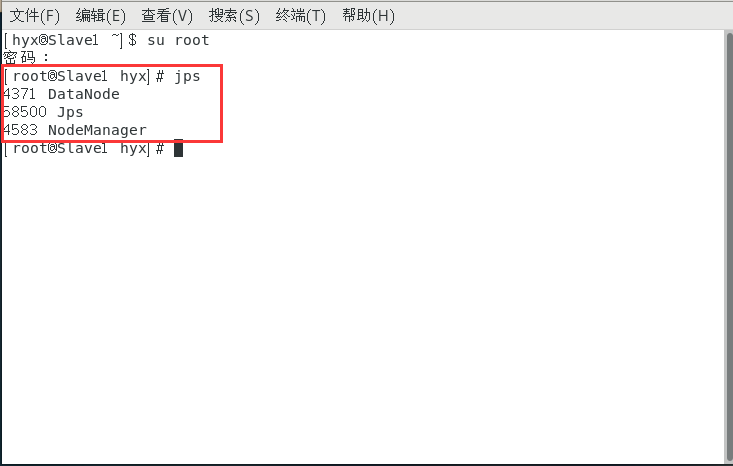
在Master主机上打开浏览器,输入:
Master:9870
Master:8088
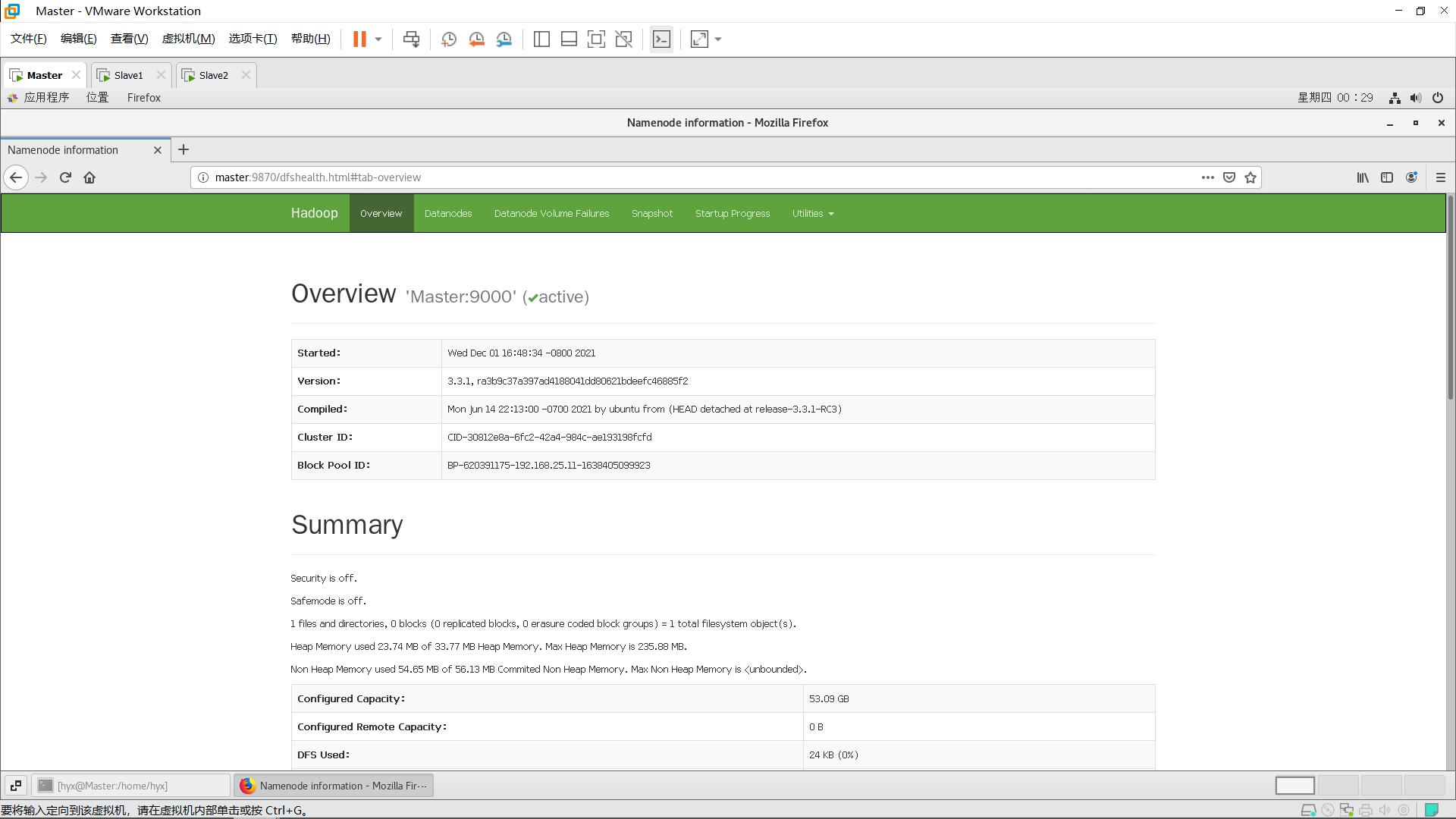
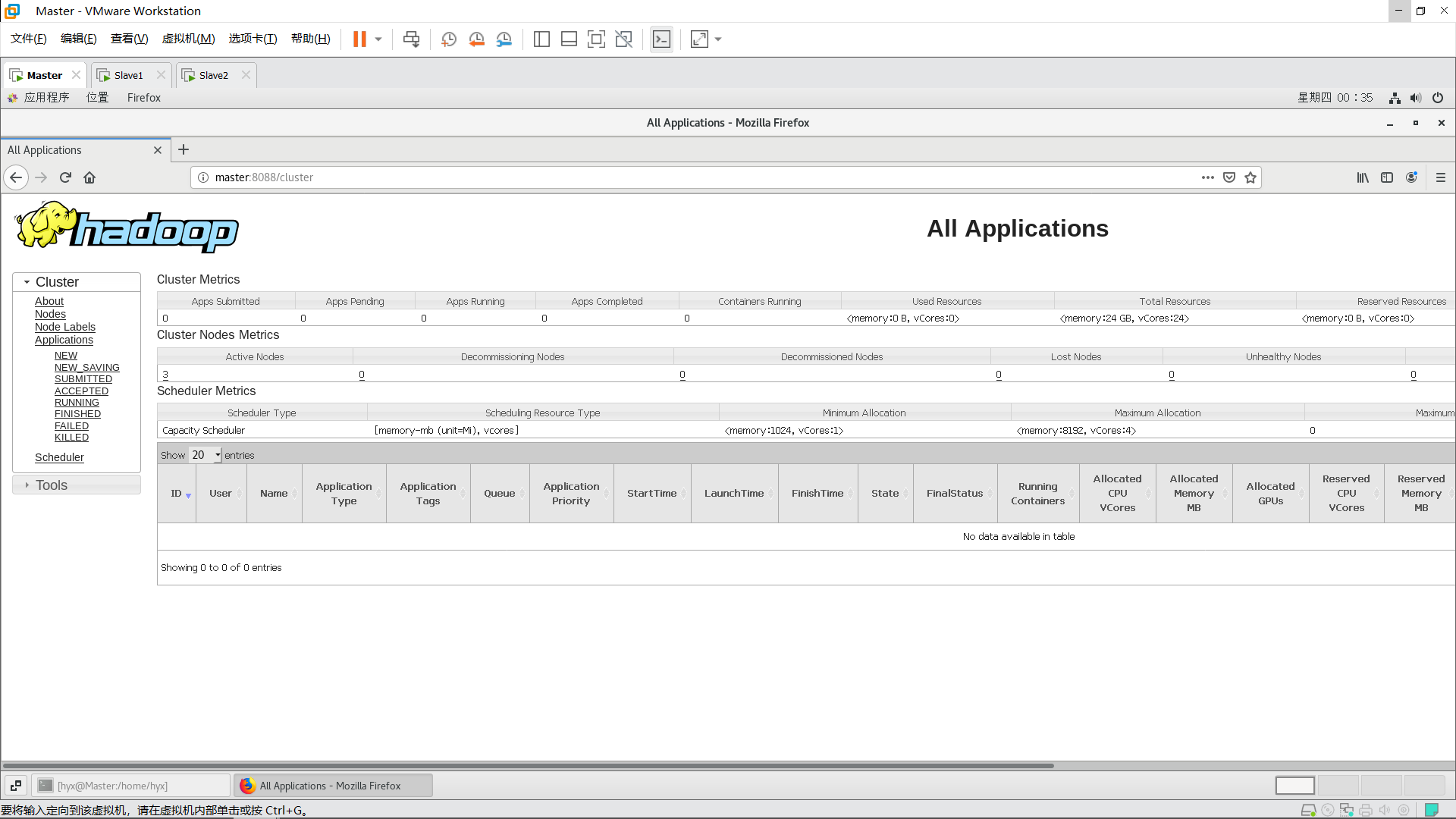
若能访问这两个地址则表示Hadoop完全分布式搭建成功
版权归原作者 Hunaxy 所有, 如有侵权,请联系我们删除。