

Spark高效数据分析04、RDD创建
📋前言📋
💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝
✍本文由在下【红目香薰】原创,首发于CSDN✍
🤗2022年最大愿望:【服务百万技术人次】🤗
💝Spark初始环境地址:【Spark高效数据分析01、idea开发环境搭建】💝
环境需求
环境:win10
开发工具:IntelliJ IDEA 2020.1.3 x64
maven版本:3.0.5
RDD产生背景
RDD产生的目的是为了解决开发人员能在大规模的集群中以一种容错的方式进行内存计算,而当前的很多框架对迭代式算法场景与交互性数据挖掘场景的处理性能非常差, 这个是 RDD 提出的动机
基于 MR 的数据迭代处理流程和基于 Spark 的数据迭代处理流程如图所示
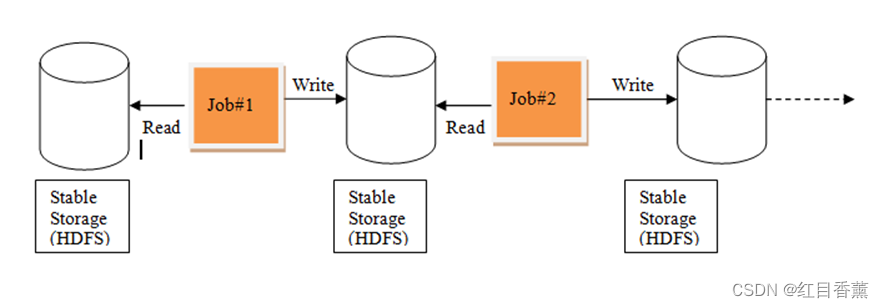
基于MR的数据迭代处理流程

基于Spark的数据迭代处理流程
RDD 的概念
RDD是弹性分布式数据集 ,是Spark的核心所在
RDD是只读的、分区记录的集合,它只能基于在稳定物理存储中的数据和其他已有的RDD执行特定的操作来创建
它是逻辑集中的实体,在集群中的多台机器上进行了数据的分区,通过RDD的依赖关系形成Spark的调度顺序,形成整个Spark行分区
RDD支持两种算子操作
转化操作,转化操作是返回一个新的 RDD 的操作
行动操作,行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作
RDD 的弹性
- 自动进行内存和磁盘数据存储的切换
- 基于系统的高效容错机制
- Task 如果失败会自动进行特定次数的重试
- Stage 如果失败会自动进行特定次数的重试
- Checkpoint 和 Persist 可主动或被动触发
- 数据调度弹性
- 数据分区的高度弹性
Demo-对list进行操作
package com.item.action
import org.apache.spark.{SparkConf, SparkContext}
object Demo7 {
def main(args: Array[String]): Unit = {
var conf =new SparkConf().setAppName("demo").setMaster("local")
var sc =new SparkContext(conf)
val rdd = sc.parallelize(List(2,8,6,3,3,7,9,5))
rdd.distinct().foreach(i=>println(i+"-"))
rdd.sortBy(x=>x,false).foreach(i=>println(i+"-"))
rdd.filter(_>3).foreach(i=>println(i+"-"))
rdd.map(_*2).foreach(i=>println(i+"-"))
}
}
Demo-对单词数量进行分析
分析数据:
id 编号 内容
A B C
AB A B
C A B
AB AB AB
package com.item.action
import org.apache.spark.{SparkConf, SparkContext}
object Demo1 {
def main(args: Array[String]): Unit = {
//直接解压到桌面
val filepath ="C:\\Users\\Administrator\\Desktop\\计应 spark机试考试素材\\计应 spark机试考试素材\\数据/spark1.txt"
//设置配置文件·app名称以及【local本地文件读取】
val sparkConf = new SparkConf().setAppName("demo1").setMaster("local")
//程序的入口
val sc = new SparkContext(sparkConf)
//读取文件
val strfile = sc.textFile(filepath)
//去除首行
var firstRow=sc.textFile(filepath).first()
//将数据进行分割,并筛选出包含有A的数据
val wordes = strfile.filter(!_.equals(firstRow)).flatMap(_.split("\t")).filter(_.contains("A"))
//每个a累计一次
val wordone = wordes.map(a=>(a,1))
// 前面一个下划线表示累加数据,后面一个下划线表示新数据
val result = wordone.reduceByKey(_+_)
//输出位置
result.saveAsTextFile("D://demo/demo1")
}
}
本文转载自: https://blog.csdn.net/feng8403000/article/details/125881550
版权归原作者 红目香薰 所有, 如有侵权,请联系我们删除。
版权归原作者 红目香薰 所有, 如有侵权,请联系我们删除。