
1.简单了解
ConcurrentHashMap是线程安全的HashMap
ConcurrentHashMap在JDK1.8中是以
CAS + synchronized
实现的线程安全
CAS:在没有hash冲突时(Node要放在数组上时)
synchronized:在出现hash冲突时(Node存放的位置已经有数据了)
2.存储
2.1存储结构
数组+链表+红黑树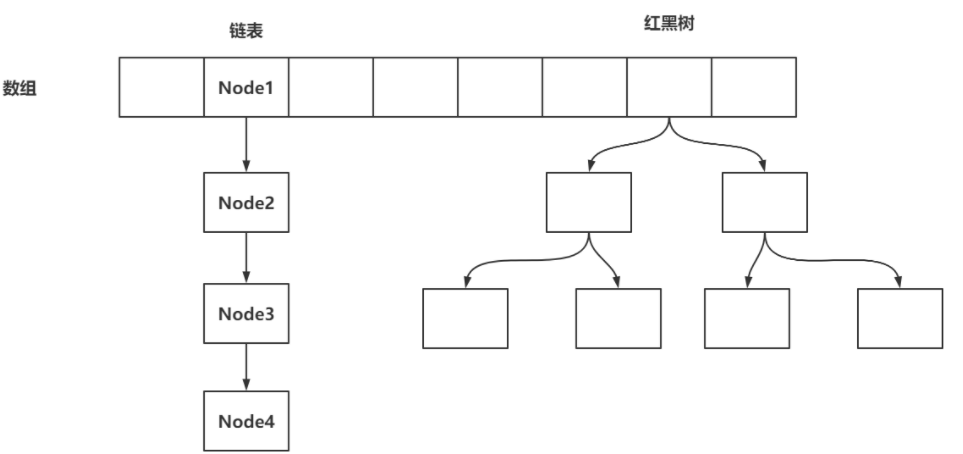
2.2存储操作
2.2.1put方法
publicVput(K key,V value){returnputVal(key, value,false);}
ConcurrentHashMap的数据是以键值对的形式存在的,所以参数是键值对的形式,
里面调了putVal方法,第三个参数默认fasle什么意思呢,false代表key一致时,直接覆盖数据,true代表key一致时,什么都不操作。
publicVputIfAbsent(K key,V value){returnputVal(key, value,true);}
如果你想在key存在添加数据想不被覆盖的情况下可以调用putVal方法。
2.2.2putVal方法
这个方法内容有点多拆解成多个部分看
2.2.2.1 前置校验和散列算法
从校验可以看出key和value都不能为空,而HashMap的key和value都可以为空
finalVputVal(K key,V value,boolean onlyIfAbsent){if(key ==null|| value ==null)thrownewNullPointerException();int hash =spread(key.hashCode());int binCount =0;// 省略。。。}// 计算当前Node的hash值的方法staticfinalintspread(int h){// ^异或运算 相同为0 不同为1 &与运算 都为1时才为1// HASH_BITS: 01111111 11111111 11111111 11111111// 假设h: 00001101 00001101 00101111 10001111// h >>> 16: 00000000 00000000 00001101 00001101// ^: 00001101 00001101 00100010 10000010// &: 00001101 00001101 00100010 10000010return(h ^(h >>>16))&HASH_BITS;}
2.2.2.2 添加数据到数组&&数组初始化
finalVputVal(K key,V value,boolean onlyIfAbsent){// 省略。。。for(Node<K,V>[] tab = table;;){// f: 当前数组i索引位置的Node对象// n: 数组长度// i: 当前Node需要存放的索引位置// fh: 当前数组i索引位置上数据的hash值Node<K,V> f;int n, i, fh;// 判断数据是否为空if(tab ==null||(n = tab.length)==0)// 为空初始化数组长度
tab =initTable();// 基于tabAt获取到i位置的数据elseif((f =tabAt(tab, i =(n -1)& hash))==null){// i位置数据为空 CAS将数据放到i位置上if(casTabAt(tab, i,null,newNode<K,V>(hash, key, value,null)))break;}/**
* static final int MOVED = -1; // 代表当前hash位置的数据正在扩容!
* static final int TREEBIN = -2; // 代表当前hash位置下挂载的是一个红黑树
* static final int RESERVED = -3; // 预留当前索引位置
*/elseif((fh = f.hash)==MOVED)// 帮助数组扩容
tab =helpTransfer(tab, f);// 省略。。。}}/**
* sizeCtl: 数组初始化和扩容操作时的一个变量
* -1 当前数组正在初始化
* 0 当前数组还没初始化
* <-1 低16位代表当前数组正在扩容线程个数(-2代表1个 -3 2个)
* > 0 当前数组的扩容阈值,或者数组的初始化容量
**/privatefinalNode<K,V>[]initTable(){Node<K,V>[] tab;int sc;// 再次判断数组有无初始化while((tab = table)==null|| tab.length ==0){// 说明数组要么没有初始化 要么就是在扩容 总之就是数组还没准备好if((sc = sizeCtl)<0)Thread.yield();// lost initialization race; just spin// 尝试初始化数组,如果修改成功代表数组没有初始化elseif(U.compareAndSwapInt(this,SIZECTL, sc,-1)){try{// 再次判断数组有无初始化if((tab = table)==null|| tab.length ==0){// 如果sc大于0 数组容量就是sc 不是默认容量16int n =(sc >0)? sc :DEFAULT_CAPACITY;@SuppressWarnings("unchecked")Node<K,V>[] nt =(Node<K,V>[])newNode<?,?>[n];// 将初始化的数组赋值给tab和table
table = tab = nt;// 设置阈值 假设数组长度16 16 - 16 >>> 2 (10000 -> 00100) 16-4 12 阈值 12/16 75%
sc = n -(n >>>2);}}finally{// 将赋值好的sc,设置给sizeCtl
sizeCtl = sc;}break;}}return tab;}
为什么长度为2的次幂?
因为要计算数据存放的索引位置 i = (n - 1) & hash
如果数组长度2的3次幂,-1之后变成0111,&之后得到的数,就会完整的得到原hashcode 值的低位值,不会受到与运算对数据的变化影响。
如果数组长度为7,-1之后变成0110 无论怎么与哈希值,就会发现下标为1,3,5,7的位置一直存不上去数据,就会导致数组分散不均匀。
2.2.2.3 添加数据到链表
finalVputVal(K key,V value,boolean onlyIfAbsent){// 省略部分代码…………int binCount =0;for(Node<K,V>[] tab = table;;){// n: 数组长度// i: 当前Node需要存放的索引位置// f: 当前数组i索引位置的Node对象// fh:当前数组i索引位置上数据的hash值Node<K,V> f;int n, i, fh;// 省略部分代码…………else{V oldVal =null;// 基于当前索引位置的Node,作为锁对象……synchronized(f){// 判断当前位置的数据还是之前的f么……(避免并发操作的安全问题)if(tabAt(tab, i)== f){// 再次判断hash值是否大于0(不是树)if(fh >=0){// binCount设置为1(在链表情况下,记录链表长度的一个标识)
binCount =1;// 死循环,每循环一次,对binCount进行+1for(Node<K,V> e = f;;++binCount){K ek;// 当前i索引位置的数据,是否和当前put的key的hash值一致if(e.hash == hash &&// 如果当前i索引位置数据的key和put的key == 返回为true// 或者equals相等((ek = e.key)== key ||(ek !=null&& key.equals(ek)))){// key一致,可能需要覆盖数据!// 当前i索引位置数据的value复制给oldVal
oldVal = e.val;// 如果传入的是false,代表key一致,覆盖value// 如果传入的是true,代表key一致,什么都不做!if(!onlyIfAbsent)// 覆盖value
e.val = value;break;}// 拿到当前指定的Node对象Node<K,V> pred = e;// 将e指向下一个Node对象,如果next指向的是一个null,可以挂在当前Node下面if((e = e.next)==null){// 将hash,key,value封装为Node对象,挂在pred的next上
pred.next =newNode<K,V>(hash, key,
value,null);break;}}}// 省略部分代码…………}}// binCount长度不为0if(binCount !=0){// binCount是否大于8(链表长度是否 >= 8)if(binCount >=TREEIFY_THRESHOLD)// 尝试转为红黑树或者扩容// 基于treeifyBin方法和上面的if判断,可以得知链表想要转为红黑树,必须保证数组长度大于等于64,并且链表长度大于等于8// 如果数组长度没有达到64的话,会首先将数组扩容treeifyBin(tab, i);// 如果出现了数据覆盖的情况,if(oldVal !=null)// 返回之前的值return oldVal;break;}}}// 省略部分代码…………}// 为什么链表长度为8转换为红黑树,不是能其他数值嘛?// 因为布松分布The main disadvantage of per-bin locks is that other update
* operations on other nodes in a bin list protected by the same
* lock can stall,for example when user equals() or mapping
* functions take a longtime. However, statistically, under
* random hash codes,this is not a common problem. Ideally, the
* frequency of nodes in bins follows a Poisson distribution
*(http://en.wikipedia.org/wiki/Poisson_distribution)witha* parameter of about 0.5 on average, given the resizing threshold
* of 0.75, although witha large variance because of resizing
*granularity. Ignoring variance, the expected occurrences of
* list size k are (exp(-0.5)*pow(0.5, k)/factorial(k)).The* first values are:**0:0.60653066*1:0.30326533*2:0.07581633*3:0.01263606*4:0.00157952*5:0.00015795*6:0.00001316*7:0.00000094*8:0.00000006* more: less than 1 in ten million
2.3 扩容操作
// 在链表长度大于等于8时,尝试将链表转为红黑树privatefinalvoidtreeifyBin(Node<K,V>[] tab,int index){Node<K,V> b;int n, sc;// 数组不能为空if(tab !=null){// 数组的长度n,是否小于64if((n = tab.length)<MIN_TREEIFY_CAPACITY)// 如果数组长度小于64,不能将链表转为红黑树,先尝试扩容操作tryPresize(n <<1);// 省略部分代码……}}
2.3.1 扩容操作tryPresize初始化
// size是将之前的数组长度 左移 1位得到的结果privatefinalvoidtryPresize(int size){// 如果扩容的长度达到了最大值,就使用最大值// 否则需要保证数组的长度为2的n次幂// 这块的操作,是为了初始化操作准备的,因为调用putAll方法时,也会触发tryPresize方法// 如果刚刚new的ConcurrentHashMap直接调用了putAll方法的话,会通过tryPresize方法进行初始化int c =(size >=(MAXIMUM_CAPACITY>>>1))?MAXIMUM_CAPACITY:tableSizeFor(size +(size >>>1)+1);// 这些代码和initTable一模一样// 声明scint sc;// 将sizeCtl的值赋值给sc,并判断是否大于0,这里代表没有初始化操作,也没有扩容操作while((sc = sizeCtl)>=0){// 将ConcurrentHashMap的table赋值给tab,并声明数组长度nNode<K,V>[] tab = table;int n;// 数组是否需要初始化if(tab ==null||(n = tab.length)==0){// 进来执行初始化// sc是初始化长度,初始化长度如果比计算出来的c要大的话,直接使用sc,如果没有sc大,// 说明sc无法容纳下putAll中传入的map,使用更大的数组长度
n =(sc > c)? sc : c;// 设置sizeCtl为-1,代表初始化操作if(U.compareAndSwapInt(this,SIZECTL, sc,-1)){try{// 再次判断数组的引用有没有变化if(table == tab){// 初始化数组Node<K,V>[] nt =(Node<K,V>[])newNode<?,?>[n];// 数组赋值
table = nt;// 计算扩容阈值
sc = n -(n >>>2);}}finally{// 最终赋值给sizeCtl
sizeCtl = sc;}}}// 如果计算出来的长度c如果小于等于sc,直接退出循环结束方法// 数组长度大于等于最大长度了,直接退出循环结束方法elseif(c <= sc || n >=MAXIMUM_CAPACITY)break;// 省略部分代码}}// 将c这个长度设置到最近的2的n次幂的值, 15 - 16 17 - 32// c == size + (size >>> 1) + 1// size = 1700000000000000000000000000010001+00000000000000000000000000001000+00000000000000000000000000000001// c = 2600000000000000000000000000011010privatestaticfinalinttableSizeFor(int c){// 00000000 00000000 00000000 00011001int n = c -1;// 00000000 00000000 00000000 00011001// 00000000 00000000 00000000 00001100// 00000000 00000000 00000000 00011101
n |= n >>>1;// 00000000 00000000 00000000 00011101// 00000000 00000000 00000000 00000111// 00000000 00000000 00000000 00011111
n |= n >>>2;// 00000000 00000000 00000000 00011111// 00000000 00000000 00000000 00000001// 00000000 00000000 00000000 00011111
n |= n >>>4;// 00000000 00000000 00000000 00011111// 00000000 00000000 00000000 00000000// 00000000 00000000 00000000 00011111
n |= n >>>8;// 00000000 00000000 00000000 00011111
n |= n >>>16;// 00000000 00000000 00000000 00100000return(n <0)?1:(n >=MAXIMUM_CAPACITY)?MAXIMUM_CAPACITY: n +1;}
2.3.2 tryPreSize方法-计算扩容戳并且查看BUG
privatefinalvoidtryPresize(int size){// n:数组长度while((sc = sizeCtl)>=0){// 判断当前的tab是否和table一致,elseif(tab == table){// 计算扩容表示戳,根据当前数组的长度计算一个16位的扩容戳// 第一个作用是为了保证后面的sizeCtl赋值时,保证sizeCtl为小于-1的负数// 第二个作用用来记录当前是从什么长度开始扩容的int rs =resizeStamp(n);// BUG --- sc < 0,永远进不去~// 如果sc小于0,代表有线程正在扩容。if(sc <0){// 省略部分代码……协助扩容的代码(进不来~~~~)}// 代表没有线程正在扩容,我是第一个扩容的。elseif(U.compareAndSwapInt(this,SIZECTL, sc,(rs <<RESIZE_STAMP_SHIFT)+2))// 省略部分代码……第一个扩容的线程……}}}// 计算扩容表示戳// 32 = 00000000 00000000 00000000 00100000// Integer.numberOfLeadingZeros(32) = 26// 1 << (RESIZE_STAMP_BITS - 1) // 00000000 00000000 10000000 00000000// 00000000 00000000 00000000 00011010// 00000000 00000000 10000000 00011010staticfinalintresizeStamp(int n){returnInteger.numberOfLeadingZeros(n)|(1<<(RESIZE_STAMP_BITS-1));}
2.3.3 tryPreSize方法-对sizeCtl的修改以及条件判断的BUG
privatefinalvoidtryPresize(int size){// sc默认为sizeCtlwhile((sc = sizeCtl)>=0){elseif(tab == table){// rs:扩容戳 00000000 00000000 10000000 00011010int rs =resizeStamp(n);if(sc <0){// 说明有线程正在扩容,过来帮助扩容Node<K,V>[] nt;// 依然有BUG// 当前线程扩容时,老数组长度是否和我当前线程扩容时的老数组长度一致// 00000000 00000000 10000000 00011010if((sc >>>RESIZE_STAMP_SHIFT)!= rs
// 10000000 00011010 00000000 00000010 // 00000000 00000000 10000000 00011010// 这两个判断都是有问题的,核心问题就应该先将rs左移16位,再追加当前值。// 这两个判断是BUG// 判断当前扩容是否已经即将结束|| sc == rs +1// sc == rs << 16 + 1 BUG// 判断当前扩容的线程是否达到了最大限度|| sc == rs +MAX_RESIZERS// sc == rs << 16 + MAX_RESIZERS BUG// 扩容已经结束了。||(nt = nextTable)==null// 记录迁移的索引位置,从高位往低位迁移,也代表扩容即将结束。|| transferIndex <=0)break;// 如果线程需要协助扩容,首先就是对sizeCtl进行+1操作,代表当前要进来一个线程协助扩容if(U.compareAndSwapInt(this,SIZECTL, sc, sc +1))// 上面的判断没进去的话,nt就代表新数组transfer(tab, nt);}// 是第一个来扩容的线程// 基于CAS将sizeCtl修改为 10000000 00011010 00000000 00000010 // 将扩容戳左移16位之后,符号位是1,就代码这个值为负数// 低16位在表示当前正在扩容的线程有多少个,// 为什么低位值为2时,代表有一个线程正在扩容// 每一个线程扩容完毕后,会对低16位进行-1操作,当最后一个线程扩容完毕后,减1的结果还是-1,// 当值为-1时,要对老数组进行一波扫描,查看是否有遗漏的数据没有迁移到新数组elseif(U.compareAndSwapInt(this,SIZECTL, sc,(rs <<RESIZE_STAMP_SHIFT)+2))// 调用transfer方法,并且将第二个参数设置为null,就代表是第一次来扩容!transfer(tab,null);}}}
2.3.4 transfer方法-计算每个线程迁移的长度
// 开始扩容 tab=oldTableprivatefinalvoidtransfer(Node<K,V>[] tab,Node<K,V>[] nextTab){// n = 数组长度// stride = 每个线程一次性迁移多少数据到新数组int n = tab.length, stride;// 基于CPU的内核数量来计算,每个线程一次性迁移多少长度的数据最合理// NCPU = 4// 举个栗子:数组长度为1024 - 512 - 256 - 128 / 4 = 32// MIN_TRANSFER_STRIDE = 16,为每个线程迁移数据的最小长度if((stride =(NCPU>1)?(n >>>3)/NCPU: n)<MIN_TRANSFER_STRIDE)
stride =MIN_TRANSFER_STRIDE;// 根据CPU计算每个线程一次迁移多长的数据到新数组,如果结果大于16,使用计算结果。 如果结果小于16,就使用最小长度16}
2.3.5 transfer方法-构建新数组并查看标识属性
// 以32长度数组扩容到64位例子privatefinalvoidtransfer(Node<K,V>[] tab,Node<K,V>[] nextTab){// n = 老数组长度 32// stride = 步长 16// 第一个进来扩容的线程需要把新数组构建出来if(nextTab ==null){try{// 将原数组长度左移一位,构建新数组长度Node<K,V>[] nt =(Node<K,V>[])newNode<?,?>[n <<1];// 赋值操作
nextTab = nt;}catch(Throwable ex){// 到这说明已经达到数组长度的最大取值范围
sizeCtl =Integer.MAX_VALUE;// 设置sizeCtl后直接结束return;}// 将成员变量的新数组赋值
nextTable = nextTab;// 迁移数据时,用到的标识,默认值为老数组长度
transferIndex = n;// 32}// 新数组长度int nextn = nextTab.length;// 64// 在老数组迁移完数据后,做的标识ForwardingNode<K,V> fwd =newForwardingNode<K,V>(nextTab);// 迁移数据时,需要用到的标识boolean advance =true;boolean finishing =false;// 省略部分代码}
2.3.6 transfer方法-线程领取迁移任务
// 以32长度扩容到64位为例子privatefinalvoidtransfer(Node<K,V>[] tab,Node<K,V>[] nextTab){// n:32// stride:16int n = tab.length, stride;if(nextTab ==null){// 省略部分代码…………// nextTable:新数组
nextTable = nextTab;// transferIndex:0
transferIndex = n;}// nextn:64int nextn = nextTab.length;ForwardingNode<K,V> fwd =newForwardingNode<K,V>(nextTab);// advance:true,代表当前线程需要接收任务,然后再执行迁移, 如果为false,代表已经接收完任务boolean advance =true;// finishing:false,是否迁移结束!boolean finishing =false;// 循环……// i = 15 代表当前线程迁移数据的索引值!!// bound = 0for(int i =0, bound =0;;){// f = null// fh = 0Node<K,V> f;int fh;// 当前线程要接收任务while(advance){// nextIndex = 16// nextBound = 16int nextIndex, nextBound;// 第一次进来,这两个判断肯定进不去。// 对i进行--,并且判断当前任务是否处理完毕!if(--i >= bound || finishing)
advance =false;// 判断transferIndex是否小于等于0,代表没有任务可领取,结束了。// 在线程领取任务会,会对transferIndex进行修改,修改为transferIndex - stride// 在任务都领取完之后,transferIndex肯定是小于等于0的,代表没有迁移数据的任务可以领取elseif((nextIndex = transferIndex)<=0){
i =-1;
advance =false;}// 当前线程尝试领取任务elseif(U.compareAndSwapInt
(this,TRANSFERINDEX, nextIndex,
nextBound =(nextIndex > stride ? nextIndex - stride :0))){// 对bound赋值
bound = nextBound;// 对i赋值
i = nextIndex -1;// 设置advance设置为false,代表当前线程领取到任务了。
advance =false;}}// 开始迁移数据,并且在迁移完毕后,会将advance设置为true}}
2.3.7 transfer方法-迁移结束操作
// 以32长度扩容到64位为例子privatefinalvoidtransfer(Node<K,V>[] tab,Node<K,V>[] nextTab){for(int i =0, bound =0;;){while(advance){// 判断扩容是否已经结束!// i < 0:当前线程没有接收到任务!// i >= n: 迁移的索引位置,不可能大于数组的长度,不会成立// i + n >= nextn:因为i最大值就是数组索引的最大值,不会成立if(i <0|| i >= n || i + n >= nextn){// 如果进来,代表当前线程没有接收到任务int sc;// finishing为true,代表扩容结束if(finishing){// 将nextTable新数组设置为null
nextTable =null;// 将当前数组的引用指向了新数组~
table = nextTab;// 重新计算扩容阈值 64 - 16 = 48
sizeCtl =(n <<1)-(n >>>1);// 结束扩容return;}// 当前线程没有接收到任务,让当前线程结束扩容操作。// 采用CAS的方式,将sizeCtl - 1,代表当前并发扩容的线程数 - 1if(U.compareAndSwapInt(this,SIZECTL, sc = sizeCtl, sc -1)){// sizeCtl的高16位是基于数组长度计算的扩容戳,低16位是当前正在扩容的线程个数if((sc -2)!=resizeStamp(n)<<RESIZE_STAMP_SHIFT)// 代表当前线程并不是最后一个退出扩容的线程,直接结束当前线程扩容return;// 如果是最后一个退出扩容的线程,将finishing和advance设置为true
finishing = advance =true;// 将i设置为老数组长度,让最后一个线程再从尾到头再次检查一下,是否数据全部迁移完毕。
i = n;}}// 开始迁移数据,并且在迁移完毕后,会将advance设置为true }}
2.3.8 transfer方法-迁移数据(链表)
// 以32长度扩容到64位为例子privatefinalvoidtransfer(Node<K,V>[] tab,Node<K,V>[] nextTab){// 省略部分代码…………for(int i =0, bound =0;;){// 省略部分代码…………if(i <0|| i >= n || i + n >= nextn){// 省略部分代码…………}// 开始迁移数据,并且在迁移完毕后,会将advance设置为true // 获取指定i位置的Node对象,并且判断是否为nullelseif((f =tabAt(tab, i))==null)// 当前桶位置没有数据,无需迁移,直接将当前桶位置设置为fwd
advance =casTabAt(tab, i,null, fwd);// 拿到当前i位置的hash值,如果为MOVED,证明数据已经迁移过了。elseif((fh = f.hash)==MOVED)// 一般是给最后扫描时,使用的判断,如果迁移完毕,直接跳过当前位置。
advance =true;// already processedelse{// 当前桶位置有数据,先锁住当前桶位置。synchronized(f){// 判断之前取出的数据是否为当前的数据。if(tabAt(tab, i)== f){// ln:null - lowNode// hn:null - highNodeNode<K,V> ln, hn;// hash大于0,代表当前Node属于正常情况,不是红黑树,使用链表方式迁移数据if(fh >=0){// lastRun机制// 000000000010000// 这种运算结果只有两种,要么是0,要么是nint runBit = fh & n;// 将f赋值给lastRunNode<K,V> lastRun = f;// 循环的目的就是为了得到链表下经过hash & n结算,结果一致的最后一些数据// 在迁移数据时,值需要迁移到lastRun即可,剩下的指针不需要变换。for(Node<K,V> p = f.next; p !=null; p = p.next){int b = p.hash & n;if(b != runBit){
runBit = b;
lastRun = p;}}// runBit == 0,赋值给lnif(runBit ==0){
ln = lastRun;
hn =null;}// rubBit == n,赋值给hnelse{
hn = lastRun;
ln =null;}// 循环到lastRun指向的数据即可,后续不需要再遍历for(Node<K,V> p = f; p != lastRun; p = p.next){// 获取当前Node的hash值,key值,value值。int ph = p.hash;K pk = p.key;V pv = p.val;// 如果hash&n为0,挂到lowNode上if((ph & n)==0)
ln =newNode<K,V>(ph, pk, pv, ln);// 如果hash&n为n,挂到highNode上else
hn =newNode<K,V>(ph, pk, pv, hn);}// 采用CAS的方式,将ln挂到新数组的原位置setTabAt(nextTab, i, ln);// 采用CAS的方式,将hn挂到新数组的原位置 + 老数组长度setTabAt(nextTab, i + n, hn);// 采用CAS的方式,将当前桶位置设置为fwdsetTabAt(tab, i, fwd);// advance设置为true,保证可以进入到while循环,对i进行--操作
advance =true;}// 省略迁移红黑树的操作}}}}}
2.3.9 helpTransfer方法-协助扩容
// 在添加数据时,如果插入节点的位置的数据,hash值为-1,代表当前索引位置数据已经被迁移到了新数组// tab:老数组// f:数组上的Node节点finalNode<K,V>[]helpTransfer(Node<K,V>[] tab,Node<K,V> f){// nextTab:新数组// sc:给sizeCtl做临时变量Node<K,V>[] nextTab;int sc;// 第一个判断:老数组不为null// 第二个判断:新数组不为null (将新数组赋值给nextTab)if(tab !=null&&(f instanceofForwardingNode)&&(nextTab =((ForwardingNode<K,V>)f).nextTable)!=null){// ConcurrentHashMap正在扩容// 基于老数组长度计算扩容戳int rs =resizeStamp(tab.length);// 第一个判断:fwd中的新数组,和当前正在扩容的新数组是否相等。 相等:可以协助扩容。不相等:要么扩容结束,要么开启了新的扩容// 第二个判断:老数组是否改变了。 相等:可以协助扩容。不相等:扩容结束了// 第三个判断:如果正在扩容,sizeCtl肯定为负数,并且给sc赋值while(nextTab == nextTable && table == tab &&(sc = sizeCtl)<0){// 第一个判断:将sc右移16位,判断是否与扩容戳一致。 如果不一致,说明扩容长度不一样,退出协助扩容// 第二个、三个判断是BUG:/*
sc == rs << 16 + 1 || 如果+1和当前sc一致,说明扩容已经到了最后检查的阶段
sc == rs << 16 + MAX_RESIZERS || 判断协助扩容的线程是否已经达到了最大值
*/// 第四个判断:transferIndex是从高索引位置到低索引位置领取数据的一个核心属性,如果满足 小于等于0,说明任务被领光了。if((sc >>>RESIZE_STAMP_SHIFT)!= rs ||
sc == rs +1||
sc == rs +MAX_RESIZERS||
transferIndex <=0)// 不需要协助扩容break;// 将sizeCtl + 1,进来协助扩容if(U.compareAndSwapInt(this,SIZECTL, sc, sc +1)){// 协助扩容transfer(tab, nextTab);break;}}return nextTab;}return table;}
标签:
java
本文转载自: https://blog.csdn.net/qq_52791485/article/details/137957164
版权归原作者 沈情 所有, 如有侵权,请联系我们删除。
版权归原作者 沈情 所有, 如有侵权,请联系我们删除。