
Abstract
基于机器学习的自动驾驶系统经常面临安全关键场景的挑战,而这些场景在真实世界的数据中较为罕见,从而阻碍了其大规模部署。虽然增加真实世界训练数据的覆盖范围可以解决这个问题,但代价高昂且存在危险。本研究通过轨迹优化,探索通过修改复杂的真实世界常规场景来生成安全关键驾驶场景。我们提出了ReGentS,该方法通过稳定生成的轨迹并引入启发式方法来避免明显的碰撞和优化问题。我们的方法解决了不现实的分离轨迹和不可避免的碰撞场景,这些场景对训练鲁棒的规划器没有用处。我们还扩展了场景生成框架以处理多达32个智能体的真实世界数据。此外,通过使用可微分模拟器,我们简化了涉及模拟器的基于梯度下降的优化过程,为未来的进展铺平了道路。
代码获取:https://github.com/valeoai/ReGentS
欢迎加入自动驾驶实战群
Introduction
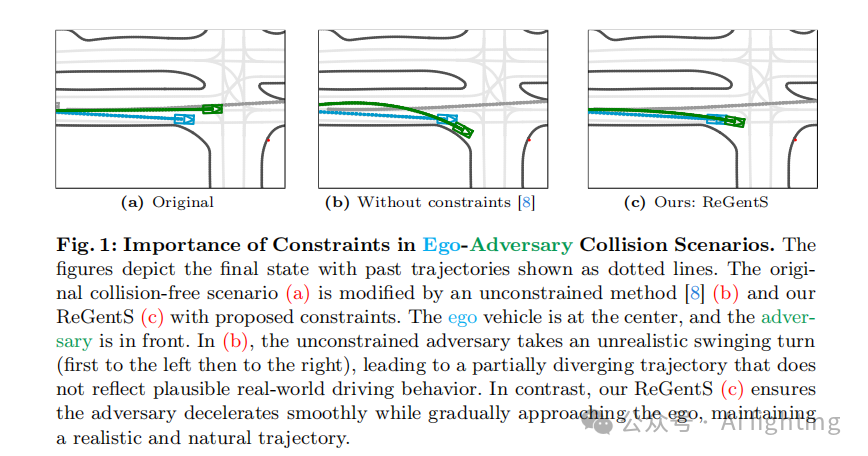
随着机器学习(ML)的快速发展,特别是通过基于神经网络的方法,自动驾驶系统变得越来越精通。然而,其性能在很大程度上依赖于训练数据的覆盖范围,且可能在现实世界数据中很少遇到的安全关键场景下表现不佳。提升分布外场景的泛化能力仍然是ML领域的重要话题。这一挑战阻碍了自动驾驶系统的大规模部署,因为它们必须符合严格的安全标准。一个解决方案是通过收集更多多样化的数据来增强真实世界数据的覆盖范围,例如通过事件数据记录器(EDR)。然而,专门为安全关键场景收集数据是危险的、昂贵的,并且伴随着隐私问题。另一种解决方案是生成这些场景。然而,大多数现有方法基于复杂性有限的合成数据进行基准测试,通常涉及的车辆较少。此外,生成过程往往是无约束的,可能会产生不现实的解决方案(如图1b所示)或对增强基于ML的规划器鲁棒性无用的场景。
在这项工作中,我们介绍了ReGentS,这是一种基于真实世界数据生成更稳定的安全关键驾驶场景的方法。我们研究了现有方法中的一些常见选择,例如引发碰撞的成本。通过专注于KING并在更大规模和更现实的设置下进行重构,结合真实世界数据的模拟器Waymax,我们确定了以下改进领域:(1)可能会生成不现实的摆动轨迹;(2)许多生成的碰撞涉及自车被追尾,而这种碰撞在实际中不可避免,因此对于规划器的训练没有提供有用的边缘案例。我们通过分析的优化过程并添加约束来生成更稳定的轨迹。此外,我们引入了启发式方法以避免明显的碰撞场景。与无约束方法相比,我们的方法在生成的轨迹中体现了更现实的驾驶行为,如图1b和1c所示。
从技术角度看,我们通过单个可微分模拟器实现并简化了设置。这使得可以通过梯度下降直接优化,简化了过程并使其统一且更易扩展。可微分模拟器还避免了可微分代理模拟器与非可微分模拟器(如CARLA)之间的繁重交互,消除了两者之间可能出现的不一致性。
3.Method
3.1 模型假设
每个背景智能体 (i > 0) 的轨迹由一系列动作通过离散化的运动学模型控制:
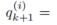
!
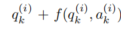
其中 f 是车辆的运动学模型,
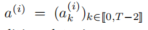
是一个动作序列,持续时间为 T - 1。我们将此动作条件的轨迹表示为
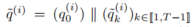
,其中
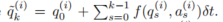
动作条件的轨迹应恢复原始轨迹,即
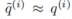
。因此,场景 s 扩展为
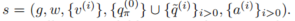
。注意,大多数数据集中通常没有动作序列 ,因此需要根据运动学模型 f 和原始轨迹估计它们。假设自车是一个映射
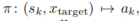
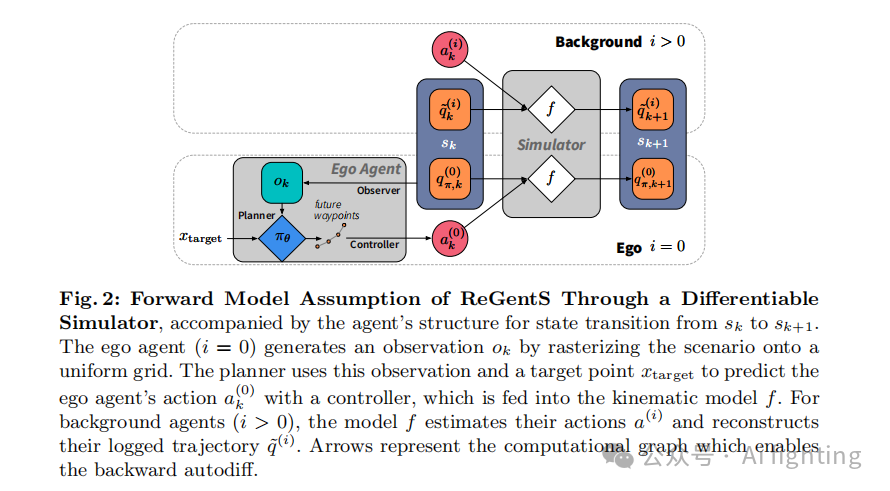
,它可以进一步分解为观察者-规划器-控制器结构(详见第 5.1 节)。图 2 展示了该前向方案。
3.2 前提:KING
我们的方法基于 KING,并通过使用运动学模型和估计的智能体动作修改每个场景 s ∈ D 中背景智能体的轨迹来生成新场景。该方法的核心内容如下。
将场景生成视为优化问题
在 KING 中定义的场景生成问题是通过成本函数 C(s) 解决的,该成本函数旨在促使背景智能体在最初无碰撞的场景中与自车发生碰撞。优化问题的公式如下:
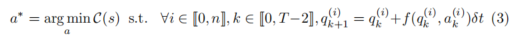
其中 a 表示所有背景智能体的动作序列
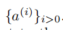
。解决这个问题可以找到最小化成本的动作序列,同时满足物理动力学模型的约束。
成本定义
文献将成本 C 分解为两个部分:(a)碰撞诱导:引入一个成本
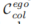
来促使自车与其中一个背景智能体发生碰撞;(b)背景智能体正则化:引入了两个成本
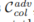
和
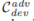
以避免背景智能体之间的碰撞,并防止它们偏离可行驶区域。
成本(a)考虑了所有时间步
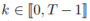
中自车 (i = 0) 与每个背景智能体 (i > 0) 之间的平均距离,以表明诱发碰撞的可能性:
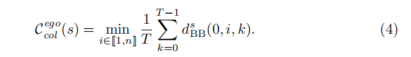
该函数选择最接近自车的背景智能体,以最小化其与自车的距离。正则化(b)旨在避免不希望的解决方案。第一个项通过基于距离的排斥来阻止背景智能体之间的碰撞:
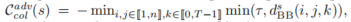
该公式衡量了任何两个背景智能体在整个时间段内的最小距离,且由阈值 τ 限制。第二个项旨在帮助背景智能体保持在可行驶区域内:
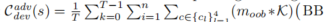
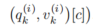
.
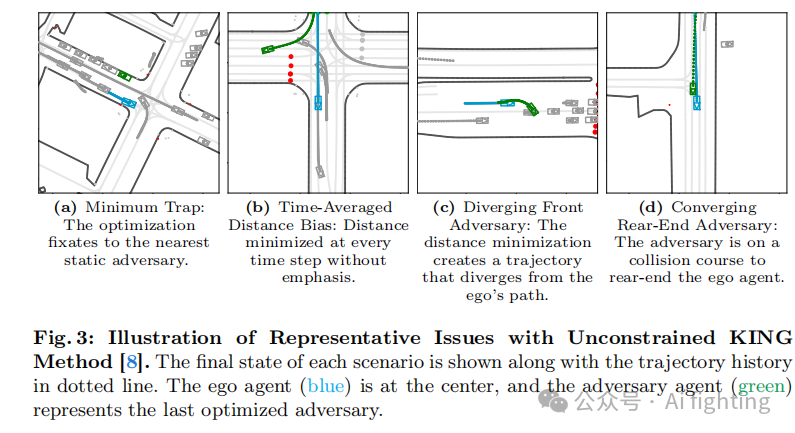
这里,K 是 2D 高斯核,
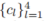
表示智能体边界框的四个角。高斯核位移由每个角的坐标决定,并与二值可行驶区域图 moob 卷积。较高的成本表示背景智能体的边界框距离可行驶区域越远。
使用梯度下降解决优化问题
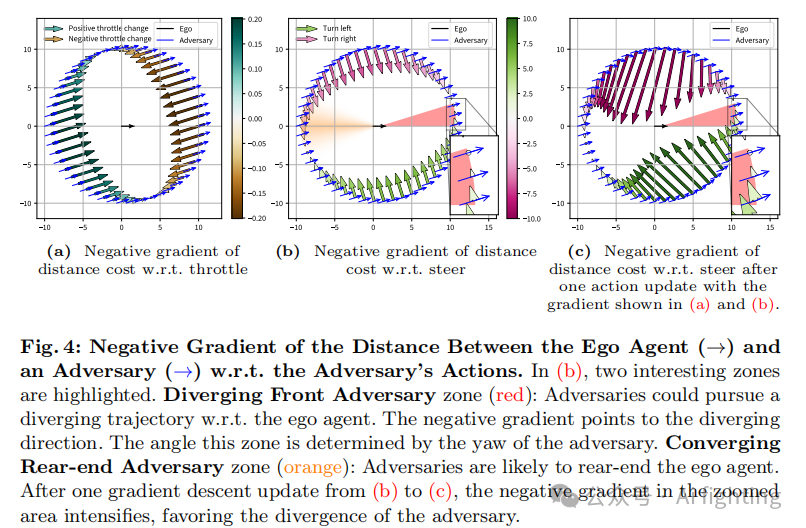
优化问题 Eq. (3) 通过梯度下降方法求解。成本函数的梯度 ∇aC(s) 相对于所有时间步中所有背景智能体的动作序列
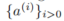
计算,如果运动学模型是可微的,则这是可行的。一旦条件 Eq. (2) 得到满足,优化迭代便停止。
3.3 ReGentS
分析
我们主要研究了碰撞诱导成本函数(Eq. 4)及其优化过程。首先,我们对优化问题、优化算法和主要成本函数的运动学梯度进行了分析。
优化偏差
当前的安全关键场景生成方法基于从 Eq. 2 接受条件推导出的距离损失。然而,通过成本函数 Eq. 4 解决优化问题会引入一些不希望的偏差:
最小陷阱:尽管 Eq. 4 没有明确指定对手,但硬最小操作符可能会使优化过程固定在第一次迭代中选择的对手上。图 3a 所示,碰撞成本固定在一个停止的智能体上,而在十字路口转弯的智能体本可以创造更有趣且可避免的碰撞。
时间平均距离偏差:如图 3b 所示,原本意图右转的绿色对手因为时间平均距离的最小化,被拉回自车附近。一个更简单的解决方案是只优化对手到达十字路口前的轨迹。这展示了在所有时间步最小化距离可能导致无效的解决方案。
对手轨迹多样性有限:选择的对手的动作序列 (ak)k 的优化仅依赖于优化算法及其超参数(例如,学习率或 Adam 的衰减率),这限制了结果的多样性。
运动学梯度偏差
定义基于距离的损失来创建碰撞很方便,但它也可能导致依赖运动学梯度信息的方法表现出不现实的行为,这是由于动作的自由度(DoF)受到限制。我们展示了 KING中的一些问题,该方法严重依赖运动学梯度。值得注意的是,这些问题也可能影响最近的分类器控制扩散模型,它们生成的动作使用运动学模型,并使用相同的梯度引导生成模型诱导碰撞。
为了说明运动学梯度的问题,我们展示了一个简单场景,该场景只涉及自车和一个需要优化的对手智能体。对手在不同位置显示,但与自车的距离相同,如图 4 所示。两个智能体都以恒定速度向右移动,关键区别在于它们的偏航:自车的偏航与 x 轴对齐,而对手的偏航略微偏离。这个场景在使用真实数据时特别有趣,因为即使背景智能体与自车朝向相同,噪声使得它们的偏航不可能完全对齐。图 4 所示的偏航偏移是为了更好地说明和可视化。
在图 4 中,我们展示了对手加速度(图 4a)和转向(图 4b)计算出的梯度下降方向(即负梯度)。如图 4a 所示,加速度的负梯度符合典型驾驶员的直觉:如果对手领先自车,它会减少加速度;如果落后,则会加速更多。然而,转向的负梯度更复杂。我们关注对手的两个特定区域(红色和橙色),这些区域可能发生不希望的情况。这个区域的角度对应自车和对手之间的方向差异。
前方发散的对手:如图 3c 所示,对手本可以通过减速与自车发生碰撞,但它进行了不必要的转向,导致与另一背景智能体发生碰撞。当对手进入图 4b 中的红色区域时,其负梯度建议它应远离自车,导致对手的轨迹与自车发散。随后,使用该负梯度更新动作会放大偏航差异,导致智能体展示出不现实的发散行为,例如在左转和右转之间摆动。
后方追尾的对手:在实际驾驶环境中,追尾碰撞对增强规划器的鲁棒性影响不大。例如,如果自车处于拥堵交通中,几乎不可能避免此类碰撞。然而,优化某些区域的对手注定会导致追尾碰撞。如图 3d 所示,当对手位于自车后方时,即处于图 4b 中的橙色区域,它将被吸引与自车对齐。在这种区域内,对手很难超越自车,因为偏离自车轨迹的趋势将被抵消。因此,优化的对手很可能会追尾自车,导致无趣的情况。
ReGentS 解决方案
受上述分析启发,我们提出了 ReGentS,它包含一些约束规则,旨在解决上述问题。我们的目标是使这些标准尽可能灵活。
阻止前方发散:如第 4.3 节所讨论的,前方发散可能是由于过度依赖转向负梯度造成的。为缓解此问题,我们建立以下规则:如果对手在一定时间步比例内保持(i)领先自车且(ii)其偏航相对于自车偏向相同侧,我们将取消转向动作的更新。
排除追尾和静止的对手:如第 4.3 节所述,追尾碰撞在某些情况下对自车是不可避免的。在 ReGentS 中,我们将橙色区域内的碰撞视为不可操作的,并选择排除在原始场景中大部分时间处于该区域的对手。为了避免优化过程中固定在静止对手上,我们简单地将场景中的所有静止对手排除出优化候选。
4.Experiment
定性结果
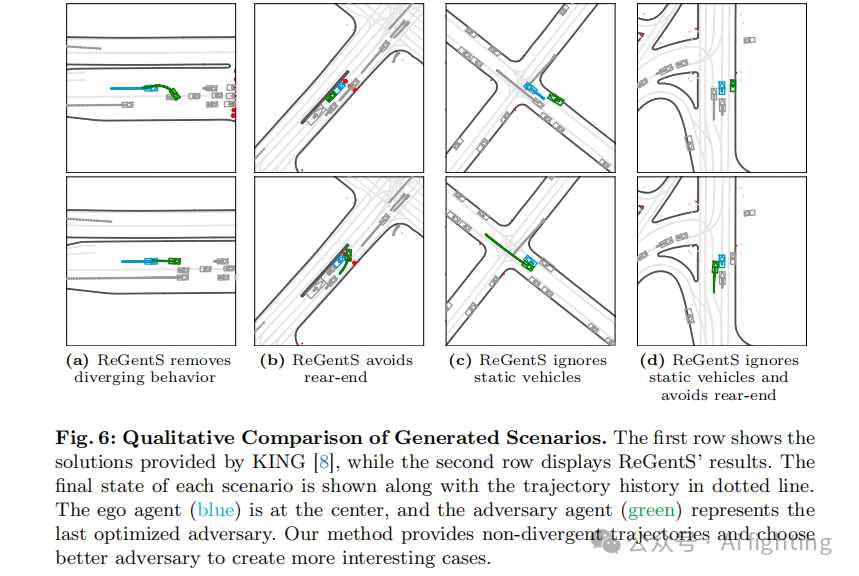
在图 6 中,我们展示了 ReGentS 与 KING 的定性比较。在图 6a 中,使优化后的对手车辆撞上另一个背景车辆,尽管有正则化,而 ReGentS 可以稳步减速对手车辆而不会产生发散轨迹。在图 6b 中,ReGentS 选择了一个背景智能体来引发合并碰撞,而导致了一个不太有趣的追尾碰撞。在图 6c 中,ReGentS 删除了静止的智能体,并与迎面而来的智能体发生正面碰撞,而 KING 则专注于一个停止的车辆并试图让它从停止状态启动。在图 6d 中,ReGentS 忽略了右侧的停止车辆以及另一侧的车辆,从右侧引发了车道合并碰撞。这些定性结果表明,ReGentS 在对手轨迹生成方面更加稳定,并且在对手选择上优于。
定量结果
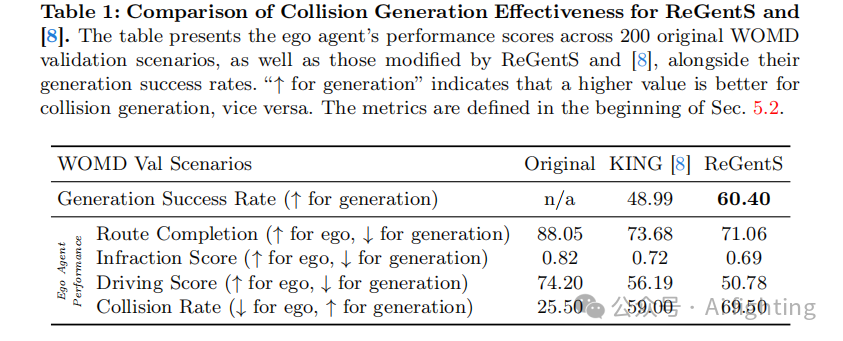
为了展示碰撞生成的有效性,我们报告了生成成功率,即在之前没有碰撞的场景中,相应方法成功创建的碰撞百分比。在表 1 中,我们展示了 ReGentS 修改的场景与原始 KING 生成的场景的对比结果。
我们观察到 KING 的碰撞生成成功率大幅下降,从最初工作中使用合成场景的约 80% 下降到 WOMD 的 49%。这一下降突显了将此方法应用于真实世界场景的挑战。相比之下,ReGentS 将成功率提高到 60%,比 WOMD 增加了 10 个百分点。
此外,ReGentS 和 KING 生成的碰撞都对自车的驾驶性能产生了负面影响。ReGentS 倾向于对自车进行更多惩罚,这可能是由于创建了更多的碰撞导致的。
结论
本文的贡献如下:
- 提出了现有方法中的两个主要问题的解决方案:解决方案的稳定性和对抗车辆的选择。具体而言,我们通过定制分析改进了优化过程的稳定性,并引入了基于背景车辆位置的启发式方法。
- 在大规模、可微分的模拟器上实现了基于轨迹优化的场景生成管道,用于真实场景和数据,方便其在进一步研究中使用。
- 证明了ReGentS在某些情况下选择了更好的对手,并生成了更稳定的轨迹。定量上,它生成了更多的安全关键场景,这对基于ML的规划器的微调非常有用。
文章引用:
ReGentS: Real-World Safety-Critical Driving
Scenario Generation Made Stable
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。
398扫码加入自动驾驶实战知识星球,即可跟学习自动驾驶感知项目:环境配置,算法原理,算法训练,代码理解等。
版权归原作者 自动驾驶实战(AIFighting) 所有, 如有侵权,请联系我们删除。