
selenium学习之路2
参考视频:https://www.bilibili.com/video/BV1NM4y1K73T/?p=66&spm_id_from=pageDriver&vd_source=7963e4096d2b51e52877519dc0202e3e
此为链接
接着selenium学习之路1的基本语法学习
三、 基本语法
(二)元素操作
方法
- clear() 清除文本
- send_keys()模拟输入
- click() 单击元素
信息:
- size 元素大小
- text 元素文本
- get_attribute() 属性值
- is_display() 元素是否可见
- is_enabled() 元素是否可用
示例:
调用元素操作函数
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)#输入
driver.find_element(By.ID,"kw").send_keys("python")
time.sleep(3)#清除
driver.find_element(By.ID,"kw").clear()
time.sleep(3)#输入
driver.find_element(By.ID,"kw").send_keys("美女")#点击
driver.find_element(By.ID,"su").click()
time.sleep(3)#成功关闭浏览器。
driver.quit()
获取元素信息
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)#打印指定元素的大小print(driver.find_element(By.ID,"kw").size)#打印文本print(driver.find_element(By.ID,"kw").text)#打印是否可见print(driver.find_element(By.ID,"kw").is_displayed())#是否可用print(driver.find_element(By.ID,"kw").is_enabled())#打印文本为新闻的元素的href属性值print(driver.find_element(By.XPATH,"//*[text()='新闻']").get_attribute("href"))
time.sleep(3)#成功退出。
driver.quit()#输出结果为:#{'height': 43, 'width': 549}# //是一个输入框,所以没有文字#True#True#http://news.baidu.com/
(三)浏览器
方法:
- maxmize_window() 最大化(最常用)
- set_window_size(width,height) 设置浏览器宽和高
- set_window_position(x,y) 设置浏览器位置
- back() 后退
- forward 前进
- refresh() 刷新
- close() 关闭当前页面
- quit() 关闭浏览器
信息:
- title 页面title(也就是当前页面最最最上面的文字)
- current_url 页面url
示例:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com"#打开百度
driver.get(url)#最大化# driver.maximize_window()#设置浏览器大小
driver.set_window_size(800,600)#设置在显示屏中的位置
driver.set_window_position(200,200)#输入PYTHON
driver.find_element(By.ID,"kw").send_keys("PYTHON")#靠id找到元素
driver.find_element(By.ID,"su").click()#刷新
driver.refresh()#停留
time.sleep(3)#后退
driver.back()#停留
time.sleep(3)#前进
driver.forward()#停留
time.sleep(3)#关闭当前页面
driver.close()#关闭浏览器。
driver.quit()#运行完毕,输出结果为:#PYTHON_百度搜索#https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=PYTHON&fenlei=256&rsv_pq=0x96e4adf0000582db&rsv_t=32016izd2rjN%2FRYR6cc%2BpOFR153eCAhulVkkekfU9FBg2hMIwnkP2V4bl5PX&rqlang=en&rsv_enter=0&rsv_dl=tb&rsv_sug3=6&rsv_btype=i&inputT=199&rsv_sug4=199
(四)等待
作用:翻页必须等待,避免页面还没加载出来,而报错的情况。
(按F12+Fn,出现开发者模式,然后点刷新,看网络时延)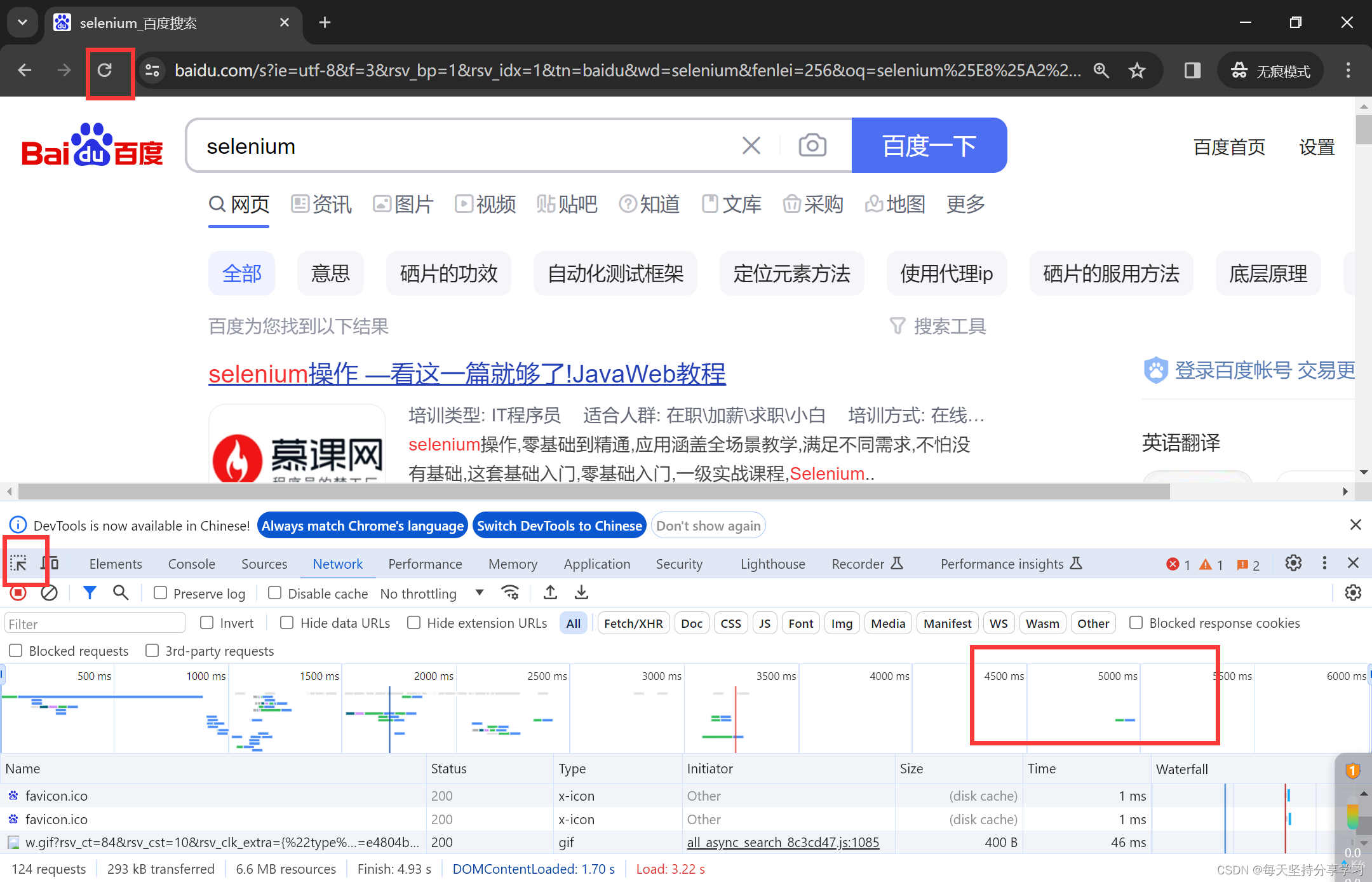
会发现一般网页刷新时间需要3秒或者5秒。
因此,需要页面等待,主要有三种方式:
- 强制等待:如time.sleep(5),简单,但并不是最优解。
- 显式等待:每隔一段时间就去找,找到返回,超过指定时间没找到就报错,但是导的包太多了!
- 隐式等待:implicitly_wait(5)跟强制等待差不多,但是后面跟最多等待的时间,比显示等待简单,不需要导多余的包,也不需要像强制等待一样等那么久(好用)
示例
强制等待
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)#输入美女后点击
driver.find_element(By.ID,"kw").send_keys("美女")
driver.find_element(By.ID,"su").click()#强制等待
time.sleep(3)
driver.find_element(By.XPATH,"//*[@id='1']/div/div[1]/div/div[1]/a[1]").click()#成功退出。
driver.quit()
显示等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
# 期待的条件from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)#输入美女后点击
driver.find_element(By.ID,"kw").send_keys("美女")
driver.find_element(By.ID,"su").click()#显示等待:等待某个元素出现为止,每隔0.5秒检查一次,但最多等五秒,until后面为等待的元素。#下面这行代码有问题,EC.presence_of_element_located里面要求有两个参数,所以需要一个元组,(By.ID,"1")之外还需要一个括号# WebDriverWait(driver,5).until(EC.presence_of_element_located(By.ID,"1"))
WebDriverWait(driver,5).until(EC.presence_of_element_located((By.ID,"1")))
driver.find_element(By.XPATH,"//*[@id='1']/div/div[1]/div/div[1]/a[1]").click()#成功退出。
driver.quit()
隐式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)#输入美女后点击
driver.find_element(By.ID,"kw").send_keys("美女")
driver.find_element(By.ID,"su").click()#隐式等待,最多等五秒。
driver.implicitly_wait(5)
driver.find_element(By.XPATH,"//*[@id='1']/div/div[1]/div/div[1]/a[1]").click()#成功退出。
driver.quit()
(五)鼠标
步骤:
1、创建ActionChains对象
2、使用ActionChains对象的方法,常用的有以下几种:
- context_click() 右击
- double_click() 双击
- drag_and_drop() 拖动
- move_to_element() 悬停
3、必须使用perform()函数执行以上方法。
示例:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
#webdriver获取对象
driver = webdriver.Chrome()
url ="https://www.baidu.com"#拖拽时使用:一个自定义的html。r表示原生字符串# url = r"file:///D:/ship/kc/XXXX/drag.html"
driver.get(url)#鼠标对象
action = ActionChains(driver)#点击右键# action.context_click(driver.find_element(By.ID,"su"))#悬停
action.move_to_element(driver.find_element(By.CLASS_NAME,"soutu-btn"))#拖拽,把div1拖到2上# action.drag_and_drop(driver.find_element(By.id,"div1"),driver.find_element(By.id,"div2"))#双击# action.double_click(driver.find_element(By.ID,"kw"))#长按# action.click_and_hold(driver.find_element(By.ID,"kw"))#点执行
action.perform()# ActionChains.perform()
time.sleep(5)#回收资源,成功退出
driver.quit()
(六)键盘
send_keys()
参数:
- 字符串
- 功能按键:如:CONTROL键复制粘贴用:Keys.CONTROL、退格键 也就是删除键,用:Keys.BACKSPACE
示例:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#导包进来(里面已经封装好了键盘上的功能键)from selenium.webdriver.common.keys import Keys
#webdriver获取对象
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)# 用的多,起个名
el = driver.find_element(By.ID,"kw")#输入框#输入PYTHON
el.send_keys("Python")
time.sleep(2)#删除python,必须先全选,
el.send_keys(Keys.CONTROL,"a")
time.sleep(2)
el.send_keys(Keys.BACKSPACE)#BACK_SPACE也可以。
time.sleep(2)#输入美女
el.send_keys("美女")
time.sleep(2)#复制,必须先全选,
el.send_keys(Keys.CONTROL,"a")
time.sleep(2)
el.send_keys(Keys.CONTROL,"c")
time.sleep(2)#删除
el.send_keys(Keys.BACKSPACE)
time.sleep(2)#粘贴
el.send_keys(Keys.CONTROL,"v")
time.sleep(5)#成功退出
driver.quit()
(七)下拉框
下拉框是HTML中< select >元素,每一个选项都是一个< option >,即元素里面还包含了元素。Select不是Element,但是继承了Element的属性,是一个单独的类别。
步骤:
1、通过select元素创建处Select对象
2、通过Select对象的方法选中选项
- (1)select_by_index 根据索引定位,从0开始
- (2)select_by_value 根据属性value值定位
- (3)select_by_visible_text() 根据文本定位
#下拉框也是元素,包含元素,是单独类别 from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#导select包from selenium.webdriver.support.select import Select
#webdriver获取对象
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)#下拉框,定位元素#本来没有select属性,强转元素为Select类,即定义了Select对象
select = Select(driver.find_element(By.ID,"selectA"))
time.sleep(2)#1
select.select_by_index(3)
time.sleep(2)#2
select.select_by_value("bj")
time.sleep(2)#3
select.select_by_visible_text("A广州")
time.sleep(5)#成功退出
driver.quit()
(八)页面滚动
1、一页太多了,需要滚动才能加载完
2、有些页面加载的条目是固定的,要想更多必须滚动
备注: selenium可以执行js代码!!利用js的方法:
- 绝对滚动window.scrollTo(x,y)
- 相对滚动window.scrollBy(x,y)
备注:滚动条就是最右侧的滚动条,可以上下切换内容
from selenium import webdriver
import time
#from selenium.webdriver.common.by import By#webdriver获取对象
driver = webdriver.Chrome()#访问斗鱼~
url ="https://www.douyu.com/directory/all"
driver.get(url)
driver.maximize_window()
time.sleep(2)## time.sleep(2)# driver.find_element(By.XPATH,"//*[text()='下一页']").click()## time.sleep(2)# driver.find_element(By.XPATH,"//*[text()='下一页']").click()#滚动条,在WebDriver类库中没有直接提供对滚动条操作方法#但提供了可调用JS脚本的方法#可以让浏览器执行js代码driver.execute_script()#绝对滚动window.scrollTo(x,y)绝对路径 和相对滚动window.scrollBy(x,y)#x和y的取值看自己的显示分辨率,#一般x就是不变 为0。如果变y看分辨率,但太麻烦了,因此Y可以写成10000,不会造成溢出,可以直接到页面最下面#定义JS滚动条
js_str ="window.scrollTo(0,10000)"# js_str = window.scrollTo(0,10000) 错的#调用js代码,可以做很多事
driver.execute_script(js_str)
time.sleep(5)#回收资源,成功退出
driver.quit()
(九)警告框
指通过JS中的alert、confirm、prompt方法弹出的框,会阻碍我们对网页的操作
解决方法:
- 1 获取警告框 alert = driver.switch_to.alert
- 2 关闭警告框 alert.dismiss()
- 3 确认 (适用于confirm、prompt) alert.accept()
- 4 输入文字 (prompt) alert.send_keys()
- 5 获取警告框的文字 alert.text
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#先访问一个网址(下面为内部地址)
driver = webdriver.Chrome()
url ="file:///D:/ship/kc/9.selenium/%E8%B5%84%E6%96%99/%E6%B3%A8%E5%86%8CA.html"
driver.get(url)#然后,找到元素,点击(弹出警告框)
driver.find_element(By.ID,"alerta").click()#接着,切换到警告框(即定义警告框对象alert = driver.switch_to.alert),
alert = driver.switch_to.alert
# 再进行如下操作:#查看文本print(alert.text)#取消
alert.dismiss()#确认
alert.accept()
time.sleep(3)#成功退出。
driver.quit()
(十)Frame切换
Frame指一个网页嵌套了一个网页。
要定位iframe里面的元素,需要先切换frame
driver.switch_to.frame()
#先打开无痕模式。from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#打开QQ邮箱
driver = webdriver.Chrome()
url ="https://mail.qq.com/"
driver.get(url)
time.sleep(2)#下面会报错,因为点击的是iframe,是另一个网址,会找不到元素# driver.find_element(By.ID,"u").send_keys("100001")#必须先切换到frame界面!#()里要填参数。因为一个网址有多个网址(frame),跟警告框不一样,#()参数填frame_name、id、driver.find_elements(By.tag_name,"iframe")[0]#切换frame
driver.switch_to.frame("ptlogin_iframe")#ptlogin_iframe是frame_name
time.sleep(2)#输入100001
driver.find_element(By.ID,"u").send_keys("100001")#操作网页其他元素,要切换回原来的网页,原始页面
driver.switch_to.default_content()#获取其他元素的文本print(driver.find_element(By.CLASS_NAME,"login_pictures_title").text)
time.sleep(5)#回收资源
driver.quit()
(十)窗口切换(页面切换)
多窗口:一个浏览器,可以打开多个网页,每个网页就构成了一个标签,有些超链接是_target="blank"的,会在新窗口打开,会出现窗口切换的事情。
因此,可以利用handler进行窗口切换
handler:控制者,窗口的唯一标识,但不是真正地处理对象,在selenium中,通过一个随机生成的字符串(uuid)来唯一标识某一个窗口。
获取handler(句柄)方法:
- 获取所有 driver.window_handles
- 获取单个 driver.current_window_handle
- 切换 driver.switch_to.window(handle)
示例:
#先打开无痕模式。from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#进入百度页面
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)# print(driver.find_element(By.XPATH,"//*[@id='s-top-left']/a[1]").text)#查看标签页全部列表print(driver.window_handles)#['B5202DBDEDB1CF56E52E13D23E028F68']#查看当前标签页print(driver.current_window_handle)#B5202DBDEDB1CF56E52E13D23E028F68#输入美女,搜索
driver.find_element(By.ID,"kw").send_keys("美女")
driver.find_element(By.ID,"su").click()
time.sleep(2)#点开一张图片,会跳转到一个新的页面
driver.find_element(By.XPATH,"//*[@class = 'image-one-line-item_aBS4H imgs-item-tl_Sp2VY ']").click()# driver.find_element(By.XPATH,"//*[@id='1']/div/div[1]/div/div[1]/a[1]").click()
time.sleep(2)#查看标签页全部列表print(driver.window_handles)#['B5202DBDEDB1CF56E52E13D23E028F68', '802A1D86BE874285EABD07C3A825226E']#查看当前标签页print(driver.current_window_handle)#B5202DBDEDB1CF56E52E13D23E028F68#切换回到此页面(新打开的页面在所有handle的最后面,从0开始计算)
driver.switch_to.window(driver.window_handles[1])print(driver.current_window_handle)#802A1D86BE874285EABD07C3A825226E
time.sleep(2)#才可以点击当前页面的图片
driver.find_element(By.XPATH,"//*[@id = 'srcPic']").click()
time.sleep(2)#截图:保存在当前路径下
driver.get_screenshot_as_file("美女.png")
time.sleep(5)#回收资源,成功退出
driver.quit()
(十一)截图
当出现问题,就需要截图。
方法:driver.get_screenshot_as_file(路径)
路径可以直接写".png"名字,代表保存在此路径下。
示例在上面。
(十二)cookie
验证码是防止机器做自动登录,登录时需要。
形式:字母数字、旋转图形、拖动滑块
应对:
去掉验证码:测试环境使用
设置万能验证码:生产环境使用
验证码识别技术(不靠谱)爬虫才喜欢用,Python-tesseract识别图片验证码
使用打码平台:收费
记录cookie:找开发人员给cookie,跳过登录(常用)
cookie的处理:
cookie:浏览器和服务器通过cookie头机制,形成状态保持
方法:
- 1 获取本网站所有本地cookie get_cookies():返回列表套字典,字典的键有domain expiry httpOnly name path secure value
- 2 获取指定的cookie get_cookie(name) 返回的是一个字典,键同上
- 3 添加cookie add_cookie() 参数是一个字典,主要的键有name value
百度的键一般有BDUSS BAIDUID
示例如下:
from selenium import webdriver
import time
#打开百度
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)#输出本网站全部cookieprint(driver.get_cookies())#输出结果:[{'domain': '.baidu.com', 'expiry': 1741246963, 'httpOnly': False, 'name': 'ZFY', 'path': '/', 'sameSite': 'None', 'secure': True, 'value': 'GfEAVehz2id5ysjcuJAMIOui6OwVeOnkJJICEeOx24w:C'}, {'domain': '.baidu.com', 'expiry': 1709797363, 'httpOnly': False, 'name': 'BA_HECTOR', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': '29848l2h8h018kc40k00248150kutt1iug7jj1t'}, {'domain': '.baidu.com', 'expiry': 1741246963, 'httpOnly': False, 'name': 'BAIDUID_BFESS', 'path': '/', 'sameSite': 'None', 'secure': True, 'value': '6CEC38BECFE6FDE3F48A75EB70C78209:FG=1'}, {'domain': '.baidu.com', 'expiry': 1741246962, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': '6CEC38BECFE6FDE3F48A75EB70C78209:FG=1'}, {'domain': 'www.baidu.com', 'expiry': 1710574963, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': '12314753'}, {'domain': '.baidu.com', 'expiry': 1744270962, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': '1709710963'}, {'domain': '.baidu.com', 'expiry': 1744270962, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': '6CEC38BECFE6FDE3F48A75EB70C78209'}]#添加cookie,一般不用自己找,找开发要键值对。
driver.add_cookie({"name":'BAIDUID',"value":'D25EAF38C058CC7164903126DAD4A61A'})
time.sleep(5)#刷新
driver.refresh()
time.sleep(5)#回收资源,成功退出
driver.quit()
版权归原作者 每天坚持分享学习 所有, 如有侵权,请联系我们删除。