
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
个人主页:beixi@
本文章收录于专栏(点击传送):【大数据学习】
💓💓持续更新中,感谢各位前辈朋友们支持学习~💓💓
文章目录
1.HBase集群环境介绍
HBase集群由多个RegionServer节点和一个或多个HMaster节点组成。HMaster节点负责管理元数据(例如表的位置、分区等),并协调集群中的各个节点。RegionServer节点负责存储和处理数据,并与HMaster节点通信以获取元数据信息。
HBase集群的主要特点包括:
- 可靠性:HBase采用数据副本和RegionServer读写分离等机制来实现容错和恢复能力,即使部分节点出现故障,集群仍然可用。
- 高性能:HBase通过将表分割成不同的Region来进行水平扩展,可以处理海量数据并具有很高的读写性能。
- 数据模型:HBase提供类似于Google的Bigtable的列族存储模型,可以灵活定义列族和列,支持动态添加或删除列族和列。
- 多版本控制:HBase支持存储多个版本的数据,可以回滚到先前的状态,也可以查询以前的历史值。

2.搭建环境准备
本次用到的环境有:
Oracle Linux 7.4
Zookeeper3.4.6集群环境
Hadoop2.7.4集群环境
注:HBase依赖于ZooKeeper来进行分布式协调和管理,因此在搭建启用HBASE之前,需要提前搭建并启动好zookeeper集群环境,zookeeper的搭建和启动可以参考我的上一篇文章:ZooKeeper集群环境搭建
3.搭建步骤
1.启动zookeeper集群环境,zookeeper的搭建和启动可以参考我的上一篇文章:ZooKeeper集群环境搭建
2.解压HBase压缩文件至/opt目录。
tar-zxvf /root/experiment/file/hbase-1.2.6-bin.tar.gz -C /opt

3.修改解压后文件夹的名字为hbase。
cd /opt
mv /opt/hbase-1.2.6 /opt/hbase

4.查找Java安装路径
echo$JAVA_HOME

5.配置hbase-env.sh文件
vim /opt/hbase/conf/hbase-env.sh

6.按键:set nu回车设置行号,部分截图如下
7.按键27gg,光标定位到27行,部分截图如下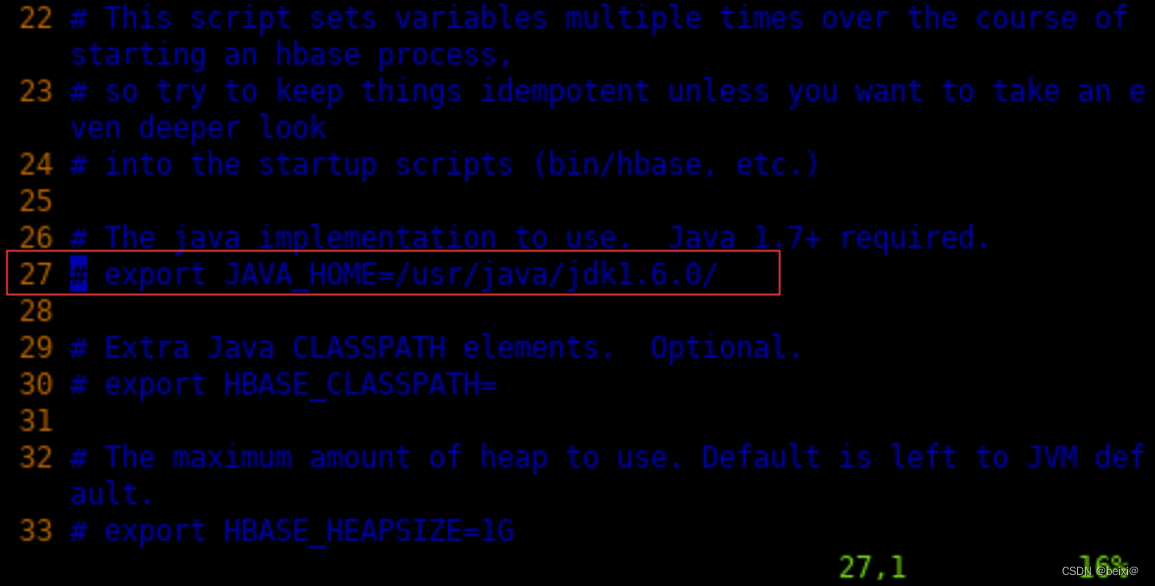
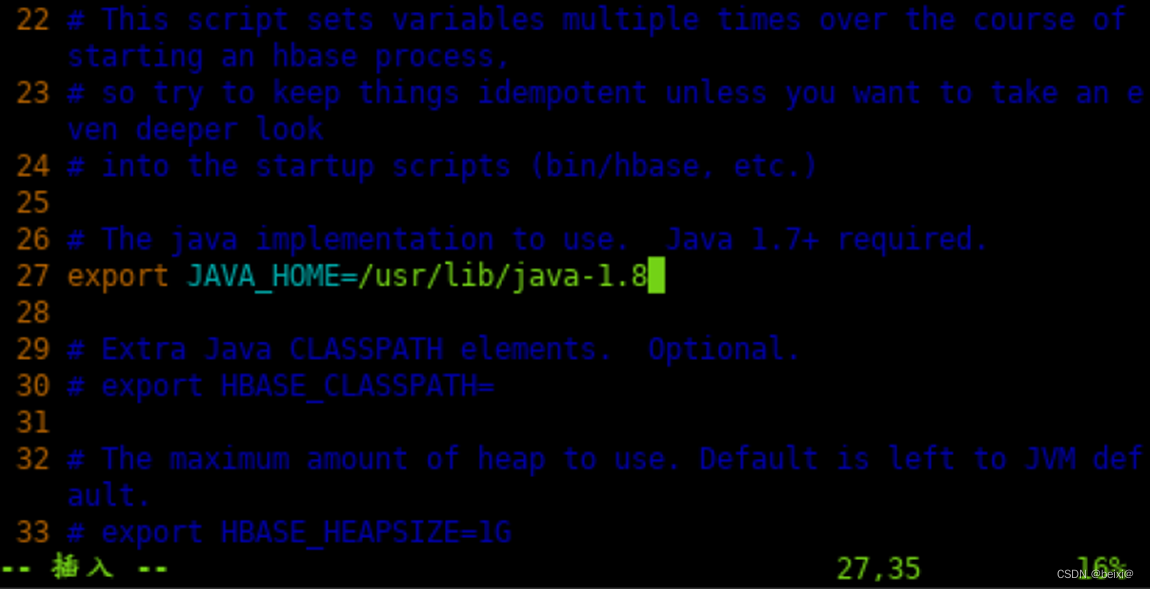
8.按键 i ,更改代码如下:
exportJAVA_HOME=/usr/lib/java-1.8
9.按键Esc,按键128gg,光标定位到128行,部分截图如下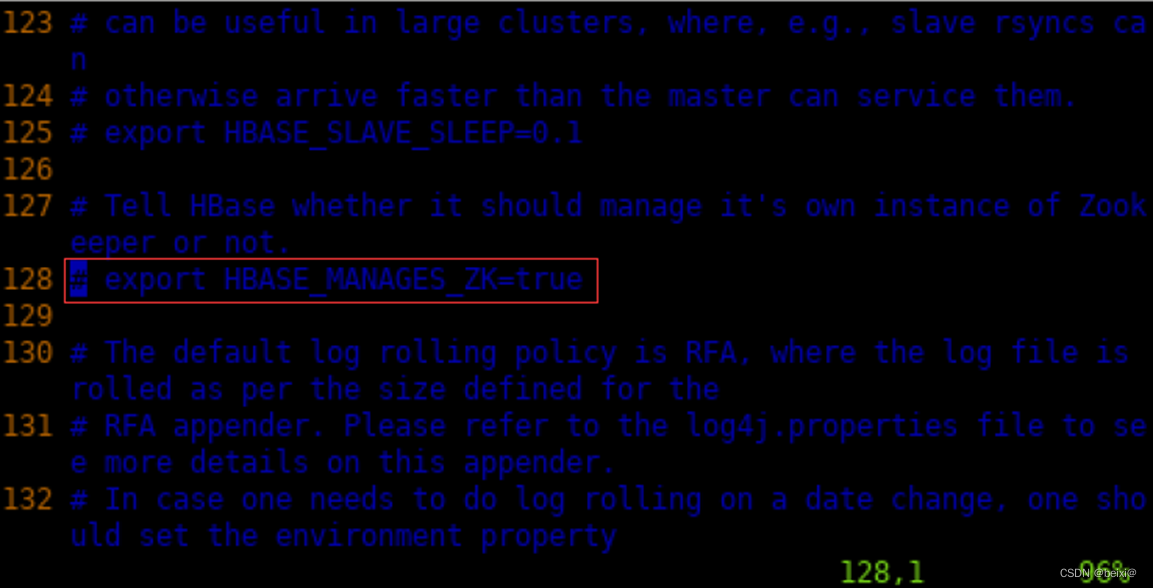
10.按键 i ,设置HBase使用外部独立Zookeeper集群,更改代码如下:
exportHBASE_MANAGES_ZK=false

11.按键Esc,按键”:wq!”保存退出。
12.配置hbase-site.xml文件
vim /opt/hbase/conf/hbase-site.xml
13.按键:set nu回车设置行号,部分截图如下
14.按键24gg,光标定位到24行,部分截图如下
15.按键 i ,在标签之间填加代码如下:
<property><name>hbase.zookeeper.quorum</name><value>master,slave1,slave2</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/root/hbase</value></property><property><name>dfs.datanode.max.transfer.threads</name><value>4096</value></property><property><name>hbase.rootdir</name><value>hdfs://master:8020/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property>
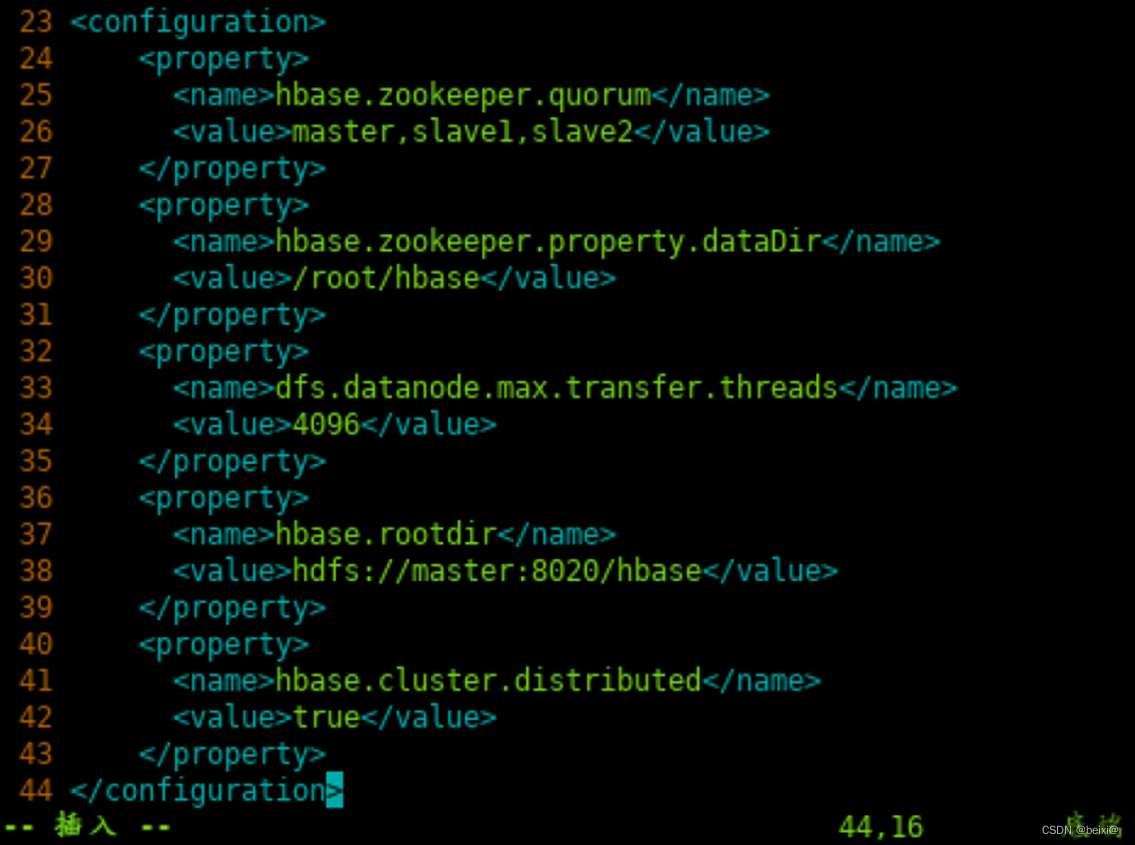
16.按键Esc,按键”:wq!”保存退出。
17.配置regionservers文件
vim /opt/hbase/conf/regionservers

18.按键dd,删除第一行“localhost”,截图如下
19.按键 i ,填加代码如下:
slave1
slave2

按键Esc,按键”:wq!”保存退出。
20.配置hbase环境变量
vim ~/.bashrc
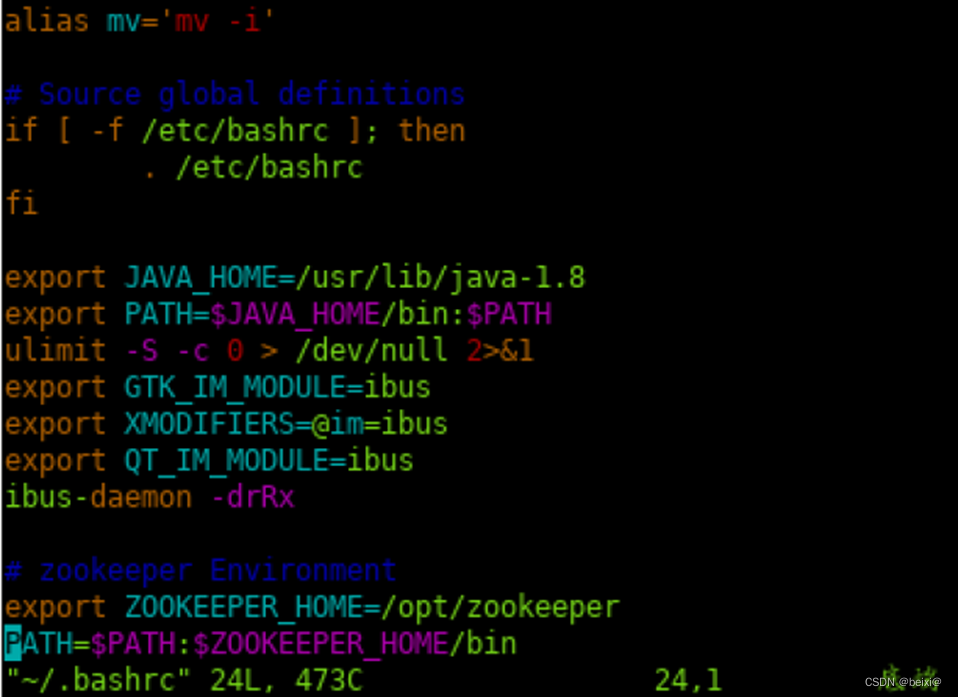
21.按键“shift+g”组合键,达到页面底部。
22.按键 i ,填加代码如下:
exportHBASE_HOME=/opt/hbase
exportPATH=$PATH:$HBASE_HOME/bin
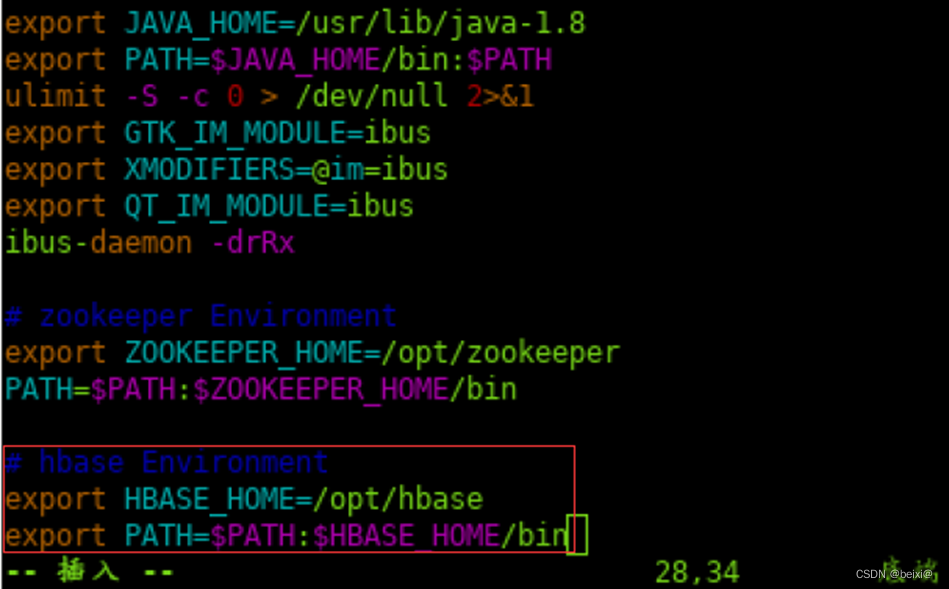
23.按键Esc,按键”:wq!”保存退出。
24.刷新配置文件,使新加Hbase环境变量生效。
source ~/.bashrc

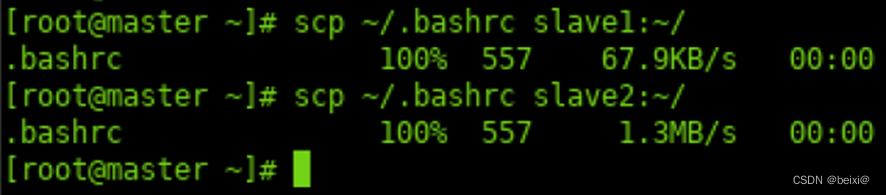
25.拷贝master主机“.bashrc”文件到slave1、slave2从机“~”下。
scp ~/.bashrc slave1:~/
scp ~/.bashrc slave2:~/
26.拷贝配置好的hbase文件夹到slave1、slave2从机“/opt”下。
scp-r /opt/hbase slave1:/opt

scp-r /opt/hbase slave2:/opt

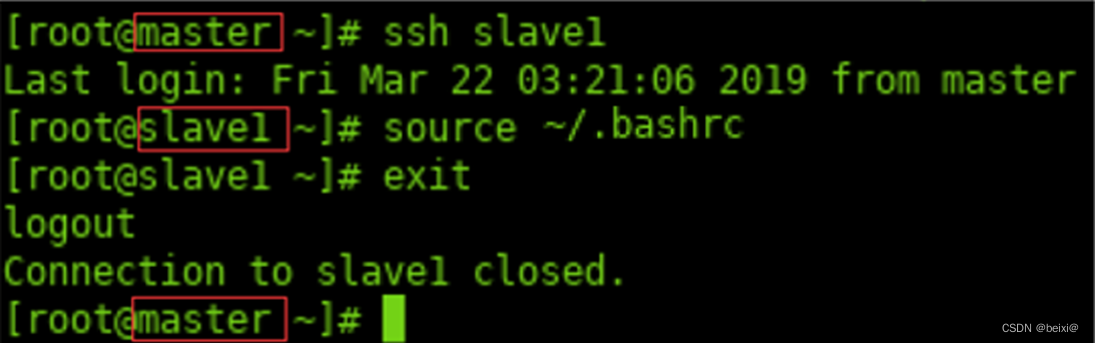
27.切换至“从节点1”机器,双击桌面“Xfce终端”图标打开命令窗口。刷新配置文件,使新加Hbase环境变量生效,退回master主机。
ssh slave1
source ~/.bashrc
exit
28.切换至“从节点2”机器,双击桌面“Xfce终端”图标打开命令窗口。刷新配置文件,使新加Hbase环境变量生效,退回master主机。
ssh slave2
source ~/.bashrc
exit
4.HBase集群环境启动、验证和停止
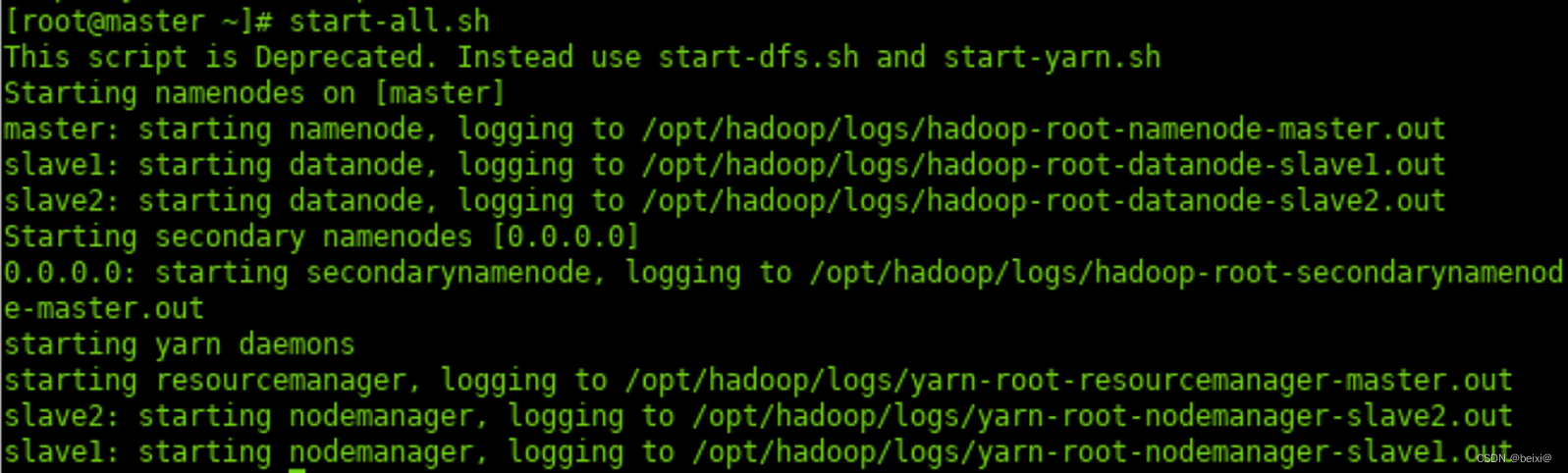
1.切换至“主节点”,双击桌面“Xfce终端”图标打开命令窗口,启动Hadoop。
start-all.sh
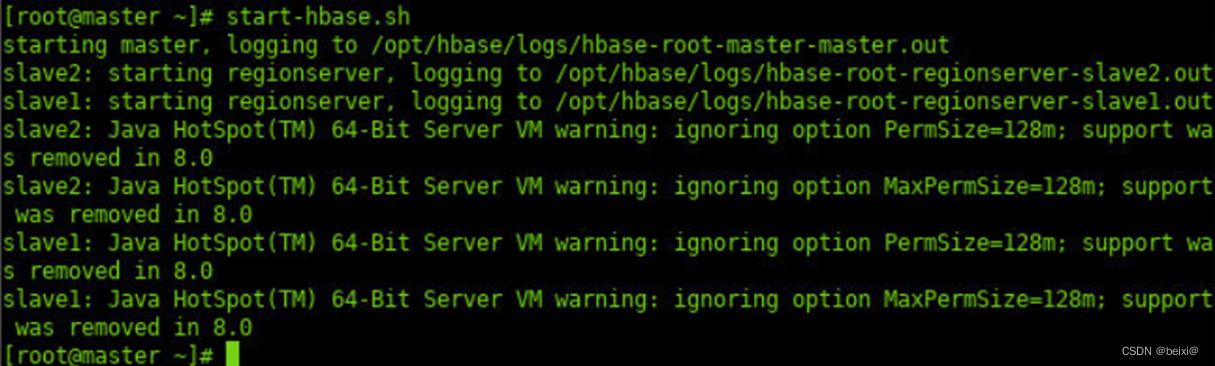
2.启动HBase。
start-hbase.sh
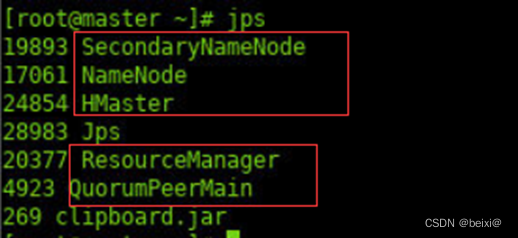
3.查看守护进程。其中HMaster为HBase的守护进程。
jps
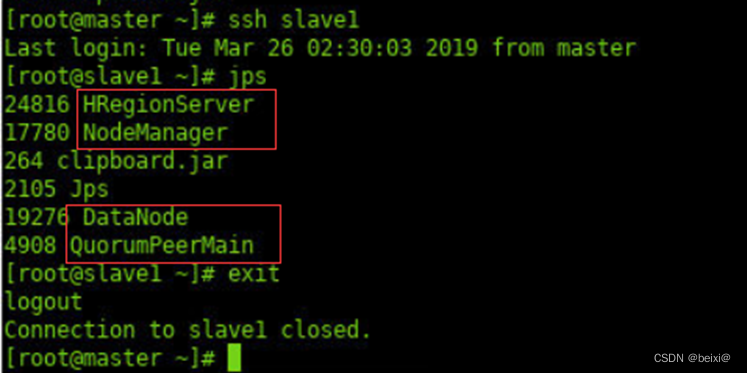
4.切换至“从节点1”,查看守护进程。其中HRegionServer为HBase的守护进程。
ssh slave1
jps
exit
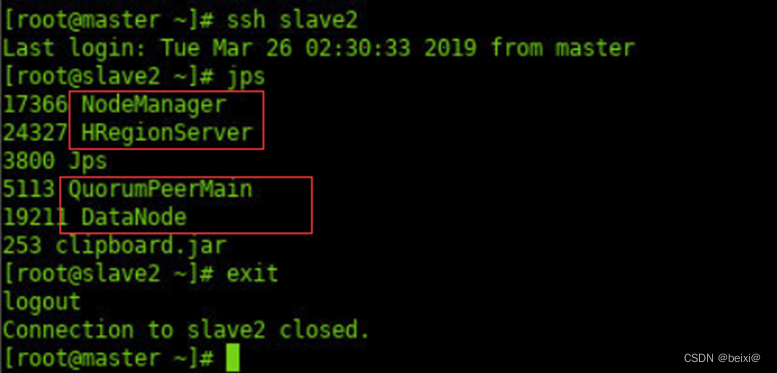
5.切换至“从节点2”,查看守护进程。其中HRegionServer为HBase的守护进程。
ssh slave2
jps
exit
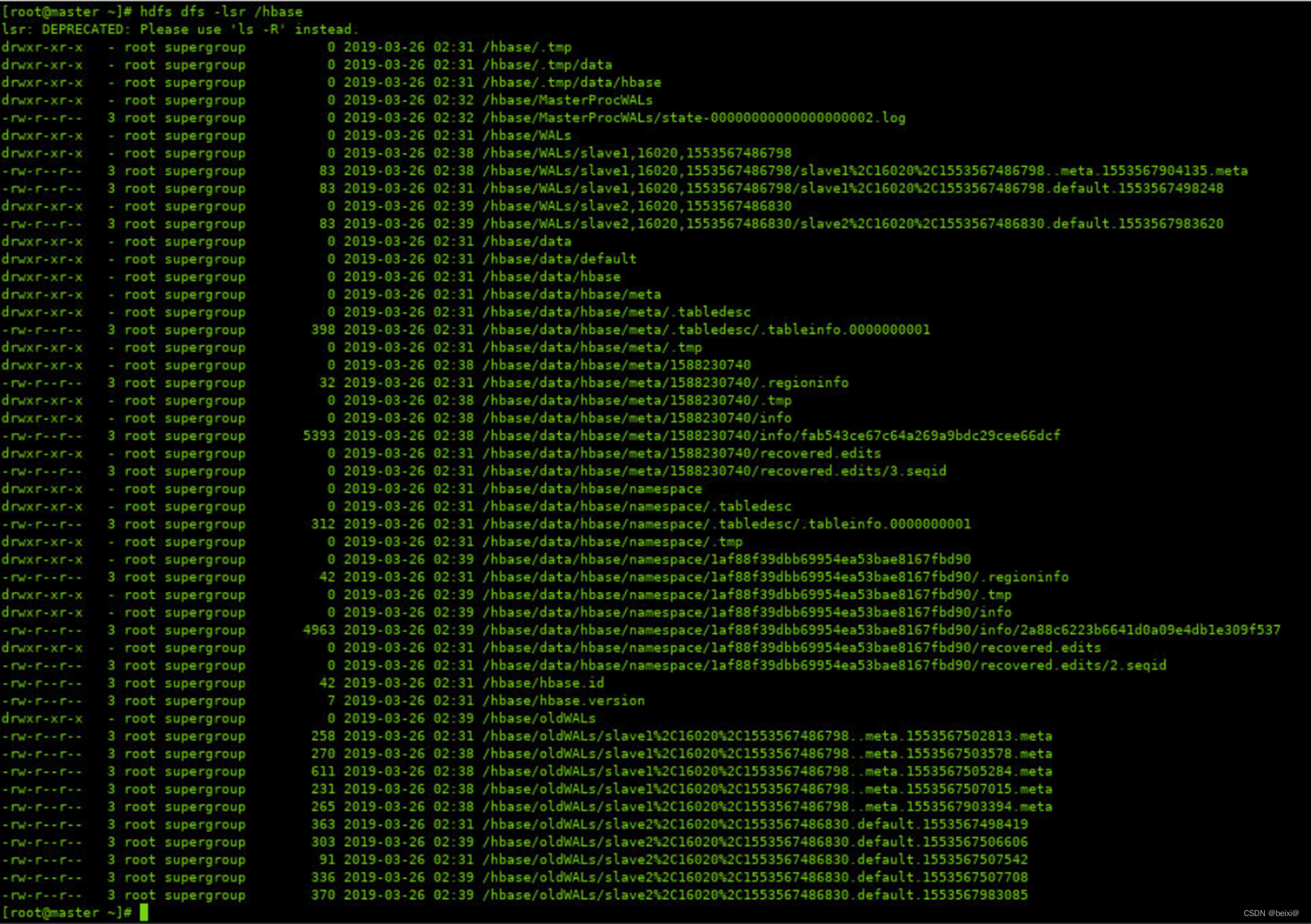
6.切换至“主节点”,查看HDFS平台上Hbase。
hdfs dfs -lsr /hbase
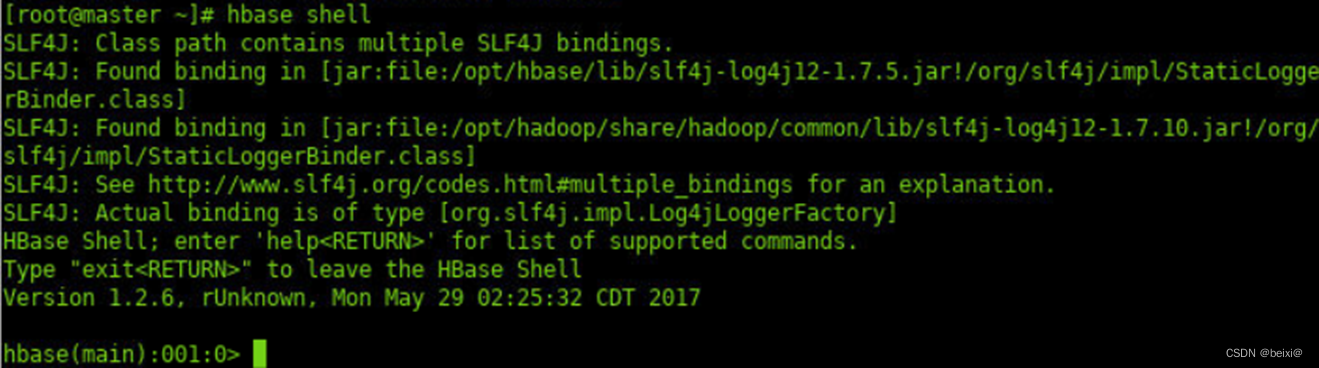
7.启动HBase-shell。
hbase shell
8.HBase下建立带有一个列族family1的表table1。
create 'table1','family1'
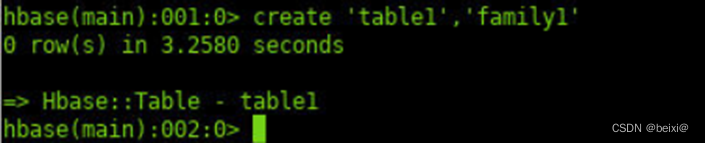
9.向表table1中列族family1下建立列为column1,并向列中播入数据value-1。
put 'table1','myrow-1','family1:column1','value-1'

10.查询表table1中内容。
scan 'table1'

11.删除表。
disable 'table1'
drop 'table1'
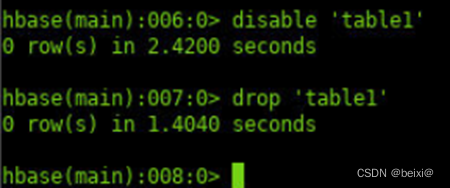
12.退出HBase shell。
quit

13.停止Hbase进程。注意:这里速度有点慢,可能需要稍等几分钟。
stop-hbase.sh

14.停止Hadoop进程。
stop-all.sh
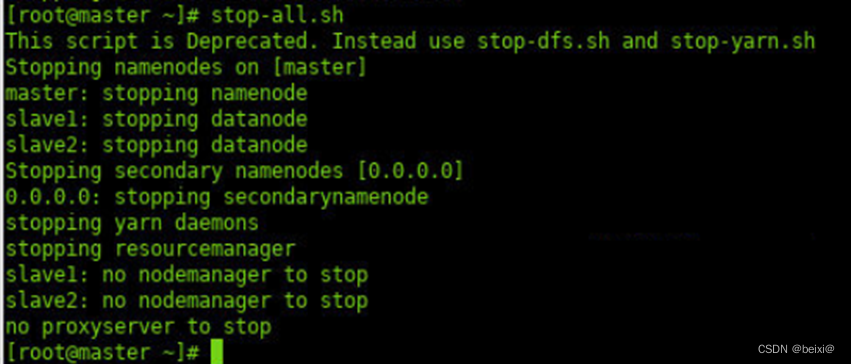
15.停止“主节点”,即master机上的zookeeper进程。
zkServer.sh stop

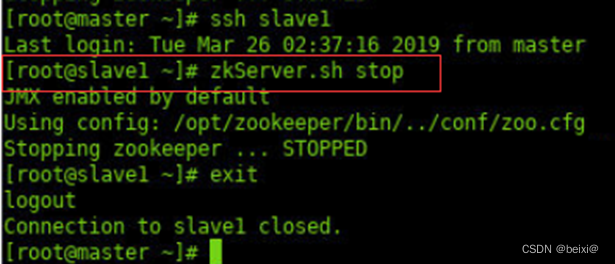
16.停止“从节点1”,即slave1机上的zookeeper进程。
ssh slave1
zkServer.sh stop
exit
17.停止“从节点2”,即slave2机上的zookeeper进程。
ssh slave2

zkServer.sh stop
版权归原作者 beixi@ 所有, 如有侵权,请联系我们删除。