
Selenium爬取小说
确定url
找到你所需要的网站 然后进行分析检查 。
==注意: 进行搜索元素时 会有一个ctrl+f的操作
看class 或者 id 后面等于的值的时候 match 不一定是1 但是只要 这个标签下id=的这个值是唯一标识的即可 ,因为你搜索的是全部的整个页面下的这个值 但是class[id=xxx]这个会可能是唯一的。
进行分析页面在爬取
可以发现都在dd标签下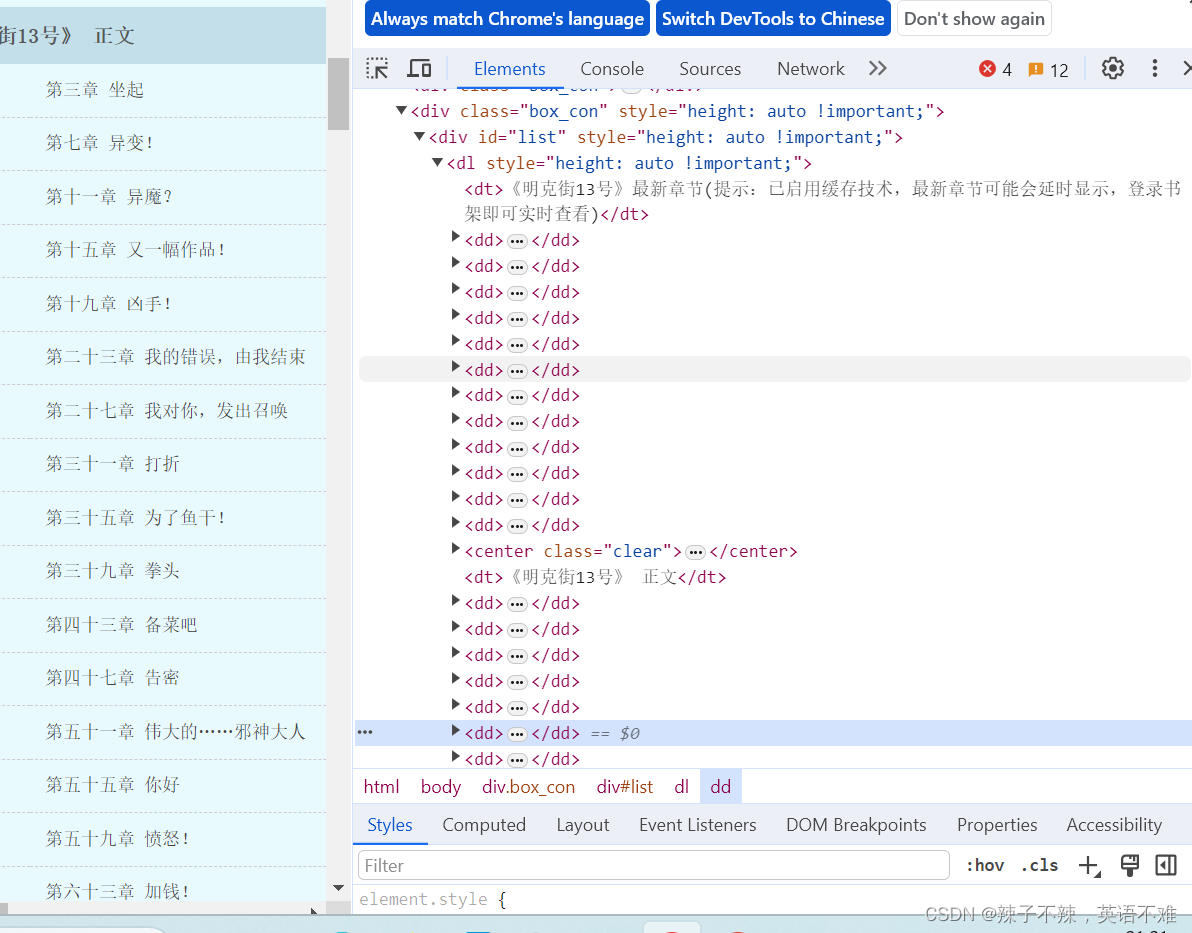
多层爬取 进入这个页面 然后爬取这一章的内容
可以发现内容都在这个标签下
我们打开一个文件接受这个文本即可
爬虫代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
file=open('./output/xxx/明克街13号.txt','a',encoding='utf-8')
driver = webdriver.Firefox()
url ='https://www.xxxxx.bz/book/54529/'
driver.get(url)
dd_list =driver.find_elements(By.XPATH,"//div[@id='list']/dl/dd")print(dd_list)
number =1for i inrange(12,len(dd_list)):print(f'爬取第{number}章')
detail_url = dd_list[i].find_element(By.XPATH,'a').get_attribute('href')print(detail_url)
driver_chmo = webdriver.Chrome()
driver_chmo.get(detail_url)
response = driver_chmo.find_element(By.XPATH,'//div[@id="content"]')print(response.text)file.write(response.text+f'\n 第{number}章 \n')
number = number +1
time.sleep(3)file.close()
爬取的结果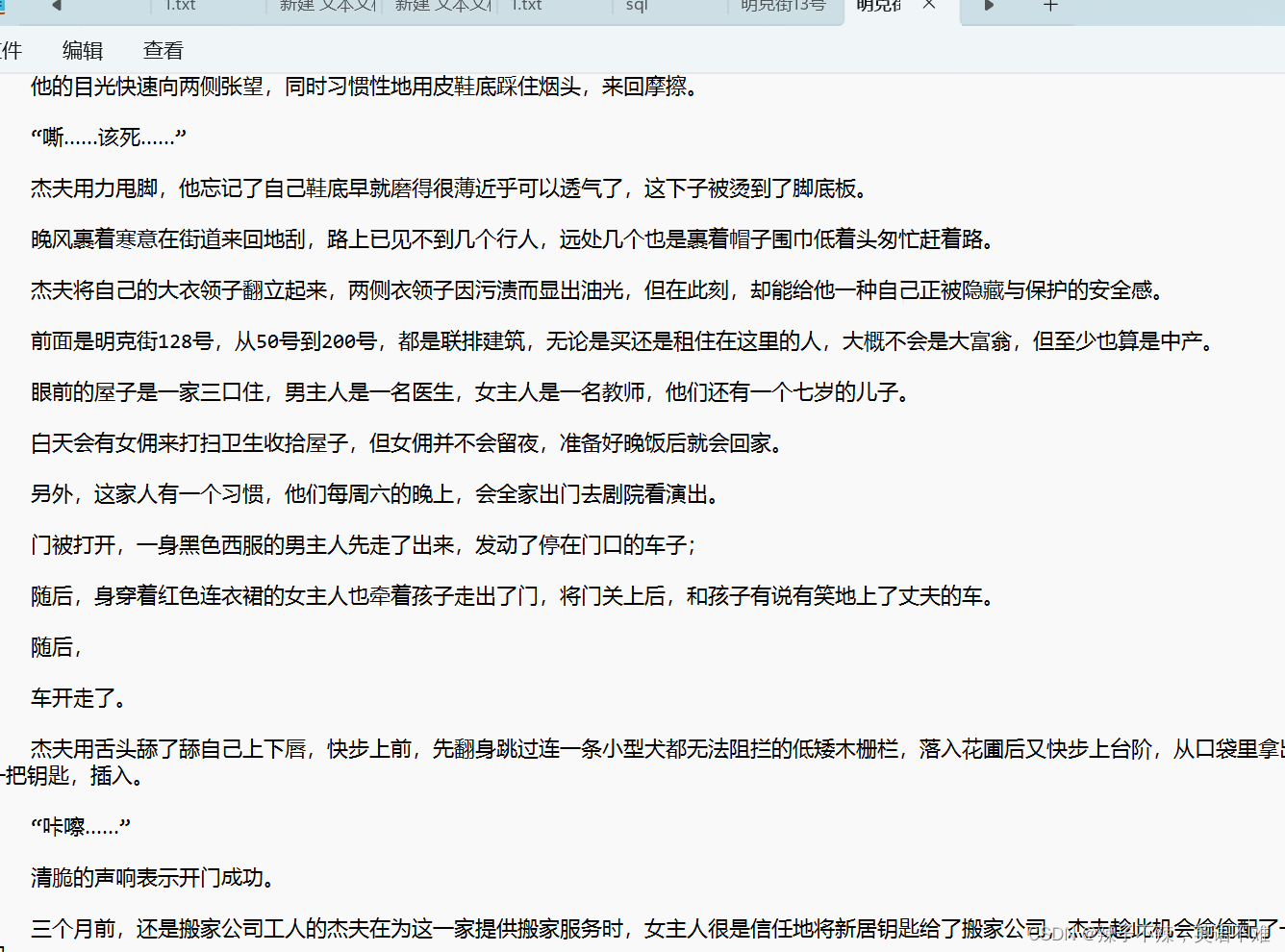
欢迎批评指正
本文转载自: https://blog.csdn.net/qq_50847752/article/details/134770836
版权归原作者 辣子不辣,英语不难 所有, 如有侵权,请联系我们删除。
版权归原作者 辣子不辣,英语不难 所有, 如有侵权,请联系我们删除。