
9.1概述
1. 排序方法的稳定和不稳定
在排序前后,含相等关键字的记录的**相对位置保持不变**,称这种排序方法是稳定的;
反之,含相等关键字的记录的相对位置有可能改变,则称这种排序方法是不稳定的。
2. 内部排序和外部排序
在排序过程中,只使用**计算机的内存**存放待排序记录,称这种排序为内部排序。
排序期间文件的全部记录不能同时存放在计算机的内存中,要借助**计算机的外存**才能完成排序,称之为“外部排序”。
**内外存之间的数据交换次数**是影响**外部排序速度**的主要因素。
3. 存储结构
#define maxsize 1000//待排顺序表的最大长度
typedef int keytype;//关键字类型为int类型
typedef struct
{
keytype key;//关键字项
infotype otherinfo;// 其他数据项
}RcdType; //记录类型
typedef struct
{
RcdType r[maxsize+1];//r[0]闲置
int length;//长度
}SqList; //顺序表类型
4.效率分析
(1) 时间复杂度:
关键字的比较次数和记录移动次数
(2) 空间复杂度:
执行算法所需的附加存储空间
(3) 稳定算法和不稳定算法。
9.2 插入排序
9.2.1 直接插入排序
直接插入排序从什么位置开始?
从第二个元素开始。一共进行n-1次。
0号单元不存,哨兵。
直接插入排序第i趟后序列有什么特征?
前i+1个记录是有序的。
2. 插入排序的思想
(1)一个记录是有序的;
(2)从第二个记录开始,按关键字的大小将每个记录插入到**已排好序的序列**中;
(3)一直进行到第n个记录。
3. 算法概述
(1)将序列中的**第1个记录**看成是**一个有序的子序列**;
(2)从第2个记录起按关键字大小逐个进行插入,直至整个序列变成按关键字有序序列为止;
整个排序过程需要进行比较、后移记录、插入适当位置。从第二个记录到第n个记录共需n-1趟。
4. 直接插入排序算法
#define maxsize 1000//待排顺序表的最大长度
typedef int keytype;//关键字类型为int类型
typedef struct
{
keytype key;//关键字项
infotype otherinfo;// 其他数据项
}RcdType; //记录类型
typedef struct
{
RcdType r[maxsize+1];//r[0]闲置
int length;//长度
}SqList; //顺序表类型
//直接插入排序
void InsertionSort(SqList &L)
{
int i,j;
for(i=2;i<=L.length ;i++)
{
if(L.r[i].key <L.r[i-1].key )//后一个元素<前一个元素
{
L.r[0]=L.r[i];//哨兵
//从最后一个开始后移
for(j=i-1;L.r[0].key < L.r[j].key ; --j)
{
L.r[j+1]=L.r[j];//后移
}
L.r[j+1]=L.r[0];//正确的位置
}
}
}
**5. ****算法分析 **

**(1)****稳定性 **
** 直接插入排序是稳定的排序方法。 **
**(2)****算法效率 **
** a.时间复杂度 **
** 最好情况:比较****O(n),移动O(1); **
** 最坏情况:比较O(n2 **),移动O(n**2****); **
** 平均O(n2****) **
** b.空间复杂度 **
** O(1)。**哨兵的位置
9.2.2 其它插入排序
折半插入排序
**6. ****折半插入排序思想 **
**(1)在直接插入排序进行第i个元素时,L.r[1], ****L.r[2], …, L.r[i-1] 是一个按关键字有序的序列; **
**(2)可以利用折半查找实现在“L.r[1], L.r[2], …, L.r[i-1]”中查找****r[i]的插入位置; **
**(3)**称这种排序为折半插入排序。
**9. **折半插入排序算法分析
**(1)****稳定性 **
*折半插入排序是稳定的*排序方法。 **
**(2)****算法效率 **
**a.****时间复杂度 **
最好情况**:比较O(n),移动O(1); **
最坏情况**:比较O(log2 n!) ,移动O(n2); **
,移动O(n2); **
平均O(n2**) **
**b.****空间复杂度 **
**O(1)**。
//折半插入排序
void BiInsertionSort(SqList &L)
{
int i,j;
for(i=2;i<=L.length,i++)//从第2到n个元素
{
if(L.r[i].key < L.r[i-1].key )//比较 如果比后面值小 存到哨兵
{
L.r[0]=L.r[i];
}
// 1..i-1中折半查找位置
low=1;
high=i-1;
while(low<=high)
{
mid=(low+high) /2;
if(L.r[0].key < L.r[mid].key )
{
high=mid-1;
}
else
{
low=mid+1;
}
}
//找到插入位置high
for(j=i-1;j>=high+1;--j)
{
L.r[j+1]=L.r[j];//后移
}
L.r[j+1]=L.r[0];//插入
}
}
9.2.3 希尔排序
**1. **希尔排序的思想
**(1)****对待排记录序列先作“宏观”调整, ****再作“微观”调整; **
**(2)****所谓“宏观”调整,指的是,“跳跃 **式” 的插入排序。
**2. **希尔排序概述
**(1)****将记录序列分成若干子序列,分别对每个子序 **
列进行插入排序。
**例如:将 ****n ****个记录分成 ****d ****个子序列: **
**{R[1], R[1+d], R[1+2d], …, R[1+kd]} **
**{R[2], R[2+d], R[2+2d], …, R[2+kd]} **
**…………………………………… **
**{R[d], R[d+d], R[d+2d], …, R[d+kd]} **
**(2)其中,d ****称为增量,它的值在排序过程中从大 **
*到小逐渐缩小,直至最后一趟排序**减为 1。*
**问题? **
在增量为d时,希尔排序从什么位置开始?
*答:从d+1*个记录开始。 **
*希尔排序完成增量为d*的排序后,序列有什 ****么特征? **
**答:子序列 ****L.r[i], L.r[i+d], L.r[i+2d], … , 是有序的,1 ****≤ i ≤ **d
**问 题 : 设 希 尔 排 序 的 增 量 序 列 为 *d1,d2,…,dr, 请问:dr*等于多少? **
*答:等于1*。 **
*问题:当希尔排序的增量为1*时的排序 ****过程是什么排序? **
答:是直接插入排序。
**5. ****希尔排序算法分析 **
**(1)****稳定性 **
*希尔排序是不稳定*的排序方法。 **
**(2)****算法效率 **
**(1)****时间复杂度 **
平均O(n1.3**)到平均O(n1.5) **
**(2)****空间复杂度 **
**O(1)**。
**4. **希尔排序算法
void ShellInsert(SqList &L,int dk)
{
int i,j;
//从dk+1开始
for(i=dk+1 ; i<=L.length;i++)
{
//从当前下标向前 与同一小组的数据进行比较,如果前面数据大,就把前面数据赋值给当前位置
if( LT(L.r[i].key ,L.r[i-dk].key ) )//同一组元素中前一个相比较
{
L.r[0]=R.r[i];//暂存哨兵
for(j=i-dk; j>0 &&(LT(L.r[0].key,L.r[j].key ) ) ; j-=dk )
{
//后移
L.r[j+dk]=L.r[j];
}
//插入位置
L.r[j+dk]=L.r[0];
}
}
}
void ShellSort(SqList &L,int delta[],int t)
{
//1.获取数组长度
int len=L.length;
//2.获取初始的间隔长度
int dk=length/2;
//
while(dk>=1)
{
ShellInsert(L,dk);
dk=dk/2;
}
}
9.3 快速排序 ——交换排序类
*9.3.1***、起泡排序 **
**1. ****实例演示 **
** 问题:冒泡排序一趟后序列有什么特征? **
** 总共需要多少趟排序? **
** 答案:冒泡排序一趟后最大元素沉底,最大 **
** 元素位于它最终的位置上。总共需要n-1趟.**
**2. ****算法思想 **
**(1)从第一个记录开始,两两记录比较,若 L.r[i].key>L.r[i+1].key,则将两个记录交换; **
**(2)第1趟比较结果将序列中关键字最大的记 录放置到最后一个位置,称为“沉底”,而最小 **
**的则上浮一个位置; **
(3)n个记录比较n-1遍(趟)
如果某趟后序列没 有变化,就表示已 经排好了。
**4. **算法分析
(1)稳定性
起泡排序是稳定的排序方法。
(2)时间是复杂性
最好情况:比较O(n), 移动O(1)
最坏情况:比较O(n2), 移动O(n2)
平均情况:O(n2)
(3)空间复杂性
O(1)

**3. **算法
void BubbleSort(SqList &L)
{
int i,j,noswap;
SqList temp;
//int n=L.length;
for(i=1;i<=n-1;i++)
{
noswap=1;
for(j=1;j<=n-i;j++)
{
if(L.r[j].key > L.r[j+1].key )//后面小 交换
{
temp=L.r[j];
L.r[j]=L.r[j+1];
L.r[j+1] =temp;
noswap=0;
}
}
if(noswap==1)break;//如果某趟后序列没有变化,就表示已经排好了。
}
}
while
void BubbleSort(Elem R[],int n)
{
i=n;
while(i>1)
{
lastindex=1;
for(j=1;j<i;j++)
{
if(R[j+1].key < R[j].key )
{
Swap(R[j],R[j+1]);
lastindex=j;//记下进行交换的记录位置
}//if
}
i = lastExchangeIndex; // 本趟进行过交换的
}// while // 最后一个记录的位置
} //表明i之后是有序的
9.3.2****、快速排序
*1. 基本思想—*分治算法
任取待排序对象序列中的某个对象v(枢轴,基准,支点),按照该对象的关键字大小,将整个序列划分为左右两个子序列;
(1)左侧子序列中所有对象的关键字都小于或等于对象v的关键字;
(2)右侧子序列中所有对象的关键字都大于或等于对象v的关键字;
(3)对象v则排在这两个子序列中间(也是它最终的位置)。
目标:找一个记录,以它的关键字作为“枢轴”,
凡其关键字小于枢轴的记录均移动至该记录之前,反
之,凡关键字大于枢轴的记录均移动至该记录之后。
致使一趟排序之后,记录的无序序列R[s..t]将**分割成两 **
部分:R[s..i-1]和R[i+1..t],且
R[j].key≤ R[i].key ≤ R[j].key
**(**s≤j≤i-1) **枢轴 **
(i+1≤j≤t)。
*问题:***快速排序一趟后序列有什么特征? **
**答案:存在一个元素,这个元素左边元素的 **
**关键字不大于它的关键字,它右边元素的关 **
键字不小于它的关键字
**4. **算法分析
**(1)****稳定性 **
*快速排序是不稳定*的排序方法。 **
**(2)****时间复杂度 **
**最坏情况: **
*1,2,3,…,n n,n-1,…2,1***。 **
比较O(n2**)**
**时间复杂性最好情况是每次选择的基准把左 **
**右分成相等两部分: **
**C(n)≤n+2C(n/2) **
≤n+2(n/2+2C(n/4))=2n+22C(n/2**2) **
**…… **
≤kn+2kC(n/2**k) **
*最后组中只有一个元素:n=2k ,k=log2***n, **
*C(n)≤nlog2*n+nC(1) **
*最好情况的时间复杂度为O(nlog2***n) **
平均时间复杂度也是O(nlog2****n)
**(3)****空间复杂度 **
**由于快速排序是一个递归过程,需一个栈的附加空 **
*间,栈的平均深度为O(log2***n)****。 **
假设一次划分所得枢轴位置 i=k,则对
***n ***个记录进行快排所需时间:
其中 Tpass(n)为对 ***n ***个记录进行一次划分
所需时间。
若待排序列中记录的关键字是随机分布
的,则 ***k ***取 1 至 ***n ***中任意一值的可能性相
同

结论**: 快速排序是所有同量级O(nlogn****) **
的排序 方法中,平均性能最好的

int Partition(SqList &L,int low,int high)
{
keytype pivotkey;//基准
L.r[0]=L.r[low];
pivotkey=L.r[low].key;
while(low<high)
{
while(low<high && L.r[high].key>=pivotkey)
{
--high;
}//找到比基准小的key对应的下标high
L.r[low]=L.r[high];//原本low的位置用这个值代替
while(low<high && L.r[low].key<=pivotkey)
{
low++;
}
L.r[high]=L.r[low];//原本high所在位置用此时low的值代替
}
L.r[low]=L.r[0]; // 枢轴记录到位
return low; // 返回枢轴位置
} // Partition
void QSort(SqList &L,int low,int high)//递归
{
int pivotloc;
if(low<high)
{
pivotloc=Partition(L,low,high);// 将L.r[low..high]一分为二
QSort(L,low,pivotloc-1); // 对低子表递归排序,pivotloc是枢轴位置
QSort(L, pivotloc+1, high);// 对高子表递归排序
}
}
**5. **算法改进
**若待排记录的初始状态为按关键字有序时,快速排序 **
将蜕化为起泡排序,其时间复杂度为O(n**2)****。 **
*为避免出现这种情况,***需在进行一次划分之前,进行 “予处理”,即: **
*先对 *R(s).key, R(t).key *和 **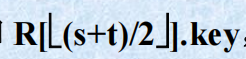 *,进行相互***比较,然后*取*关键字为 “三者之中”的记录为枢轴*记 **
*,进行相互***比较,然后*取*关键字为 “三者之中”的记录为枢轴*记 **
录。
9.4 选择排序
9.4.1 简单选择排序
**1. ****算法思想 **
** (1)第一次从n个关键字中选 择一个最小值,确定第一个; **
** (2)第二次再从剩余元素中选 择一个最小值,确定第二个; **
** (3)共需n-1次选择。**
**2. ****实例演示 **
** 问题:简单选择****排序一趟后序列有什么特征? **
** 答案:**最小元素排在第一位。
**3. ****算法概述 **
*设需要排序的表是***R[n+1]: **
**(1)第一趟排序是在无序区R[1]到A[n]****中选出关 **
*键字最小的记录,将它与***R[1]交换,确定最小值; **
**(2)第二趟排序是在R[2]到r[n]****中选关键字最小 **
*的记录,将它与***R[2]****交换,确定次小值; **
**(3)第i趟排序是在R[i]到R[n]****中选关键字最小的 **
*记录,将它与***R[i]****交换; **
**(4)共n-1**趟排序。
**5. **算法分析
**(1)****稳定性 **
*简单选择排序方法是不稳定*的。 **
**(2)****时间复杂度 **
*比较O(n*2 ****),移动最好O(1),最差O(n) **
**(3)****空间复杂度 **
*为***O(1)**。
对 n 个记录进行简单选择排序,所 需进行的 **关键字间的比较次数 **总计为:
移动记录的次数,最小值为 0, 最大 值为3(n-1) 。 //交换两个值需要三次交换 temp=a a=b b=temp
**4. ****算法 **
算法概要:
void SelectSort (Elem R[], int n )
{
// 对记录序列R[1..n]作简单选择排序。
for (i=1; i<n; ++i) {
// 选择第 i 小的记录,并交换到位
j = SelectMinKey(R, i);
// 在 R[i..n] 中选择关键字最小的记录
if (i!=j) R[i]←→R[j];// 与第 i 个记录交换
}
} // SelectSort
算法:
void Select(SqList &L)
{
int i,j,min;//min存储L.r[i...n]中最小值的下标
for(i=1;i<L.length;i++)
{
min=i;
for(j=i+1;j<=L.length;j++)
{
if(L.r[j].key<L.r[min].key)
min=j;
}
if(min!=i)//如果min较比初值发生变化,则交换
{
L.r[0]=L.r[i];
L.r[i]=L.r[min];
L.r[min]=L.r[0];
}
}
}
**9.4.1 **堆排序
**1. ****引入 **
** 堆排序属于选择排序****:**出发点是
** 利用选择排序已经发生过的比较, **
** 记住比较的结果,减少重复“比较” 的次数**
**2. ****堆的定义 **

在大根堆中,哪个结点关键字最大?
答:根节点的关键字最大。
左右不论 (二叉排序树则是左小于右)
根节点与最后一个节点交换
问题:利用大根堆排序一趟后序 列有什么特点?
答:最大元素在最后。
**3. ****堆排序算法思想 **
**堆排序需解决两个问题: **
**(1) ****由一个无序序列建成一个堆。 **
**(2) ****在输出堆顶元素之后,调整剩余元 **
素成为一个新的堆。
4. 堆排序算法概要(采用大根堆)
**(1) 按关键字建立R[1],R[2],…R[n]的大根堆; **
**(2) 输出堆顶元素,采用堆顶元素R****[1]****与最后 **
一个元素**R[n]****交换,最大元素得到正确的 **
排序位置**; **
**(3) 此时前n-1****个元素不再满足堆的特性,需重 **
建堆**; **
**(4) 循环执行(2),(3)**两步,到排序完成。
**5. ****筛选算法实例演示 **
(1)先建一个完全二叉树:
(2)从最后一个非终端结点 开始建堆;
n个结点,最后一个非终端结点的下标是
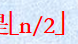
**8. **算法分析
**(1)堆排序是不稳定****的排序。 **
**(2)时间复杂度为O(nlog2n)**。
*最坏情况下时间复杂度为O(nlog2***n)****的算法。 **
**(3)空间复杂度为O(1)**。
**1. ****对深度为 ****k ****的堆,“筛选”所需进行的关键字 **
*比较的次数至多为***2(k-1)****; **
2. **对 *n 个关键字,建成深度为h*(=***log*2n****+1)****的堆, **
*所需进行的关键字比较的次数至多 *4**n**;
**3. ****调整“堆顶” *****n-1 *****次,总共进行的关键 **
**字比较的次数不超过 **
*2 (***log*2 ****(n-1)+ log****2 (n-2)+ …+log22*) < 2n(log*2n***) **
因此,堆排序的时间复杂度为O(nlog***n*****)**。

**6. ****筛选算法 **
**7. ****堆排序算法 **
void HeapAdjust(HeapType &H,int s,int m)
{//从H中调整下标s的位置 一共M个元素
int j;
RedType rc;
rc=H.r[s];//将要移动的元素 暂存
//暂存堆顶r[s]到rc
for(j=2*s ; j<=m; j*=2)//2*s是左孩子
{
//如果左孩子<右孩子
if(j<m && H.r[j].key<H.r[j+1].key )//横比,j初值指向左孩子
{
++j;//就指向右孩子
}//如果右孩子大于左孩子,j指向右孩子,j指示关键字较大位置
if(rc.key>=H.r[j].key)//如果基准值大于等于j的key
break;//纵比,如果…,定位成功
H.r[s]=H.r[j];//指向当前结点的左孩子
s=j;//
//否则,r[j]上移到s,s变为j, 然后j*=2,进入下一层
}
H.r[s]=rc;//插入
// 将调整前的堆顶记录rc到位置s中
}
void HeapSort(HeapType &H)
{
int i;
RcdType temp;
for(i=H.length/2 ;i>0;--i)//建堆
{
HeapAdjust(H,i,H.length);
}
for(i=H.length ;i>1;--i)
{
//交换r[1]和r[i]
temp=H.r[i];
H.r[i]=H.r[1];
H.r[1]=temp;
HeapAdjust(H,1,i-1); //调整,使得1~i-1符合堆的定义
}
}
9.5 归并排序
**1. ****归并的定义 **
** 归并又叫合并,是指把两个或两个以上的有序序列合并成一个有序序列。 **
**2. ****归并实例演示 **
**3. ****归并算法 **
**4. ****归并排序实例 **
**5. ****归并排序思想 **
**6. ****归并排序核心算法 **
**7. ****归并排序算法 **
**8. **算法分析
*将两个长度分别为n,m*的递增有序顺序表归 **
**并成一个有序顺序表,其元素最多的比较次 **
**数是 **
**n **
**m+n **
**MIN(m,n) **
**m+n-1 **
A
问题分析
二路归并排序的思想是:将待排序 的数列分成相等的两个子数列(数量 相差±1),然后,再使用同样的算 法对两个子序列分别进行排序,最 后将两个排好的子序列归并成一个 有序序列。
算法设计与描述 MergeSort( A,p,r )算法分析输入:n个数的无序序列A[p,r] , 1<= p <= r <= n ,(1)输入n,计算规模是n输出:n个数的有序序列A[p,r]
MergeSort (A,p,r)
{
if( p<r )
{
q <- (p+r)/2 ;//中间
MergeSort (A,p,q); //左侧
MergeSort(A,q+1,r) ;//右侧
Merge (A,p,q,r);
}
}
(2)核心操作为 移动盘子
(3)
(4)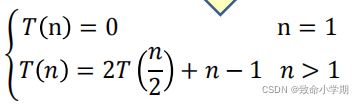

C
算法设计与描述 Merge( A,p,q,r )算法分析输入:n按递增顺序排好的 A[p...q] 和 Aq+1...r 输入n,计算规模是n输出:按照递增顺序排序的A[p,r]
Merge (A,p,q,r)
{
x <- q-p+1 ,y <- r-q;//x,y分别是两个子数组的元素数
A[p...q] -> B[1...x] , A[q+1...r] -> C[1...y] //两个新数组
i <- 1 ,j<- 1 ,k <- p
while i<=x and j <= y do
{
if ( B[i] <= C[ j ] ) //注意是i 和 j
{
A[k] <- B[i];//较小数
i <- i+1;
}
else
{
A[k] <- C[j] ;
j <- j+1;
}
k=k+1;
}
if(i>x) C[j...y] -> A[k..r] //如果还要剩余的元素,就不需要比较,直接赋值回去就行
else B[i..x] -> A[k...r]
}
(2)核心操作为 移动盘子
(3)根据递推公式,。。。【不全】
9.6 基数排序
9.7 内部排序方法的比较
版权归原作者 致命小学期 所有, 如有侵权,请联系我们删除。