
Flink的安装模式
local(本地)
本地单机模式,一般用于测试环境是否搭建成功,很少使用
standalone(独立集群模式)
flink自带集群,开发测试使用
StandAloneHA:独立集群的高可用模式,也是flink自带,用于开发测试环境
on yarn(flink on yarn)
计算资源统一由hadoop yarn管理,生产环境使用
local模式安装
下载安装包
https://pan.baidu.com/s/1xFn7ukWDp4bE0vNZI99AOQ?pwd=1234 提取码:1234
上传服务器
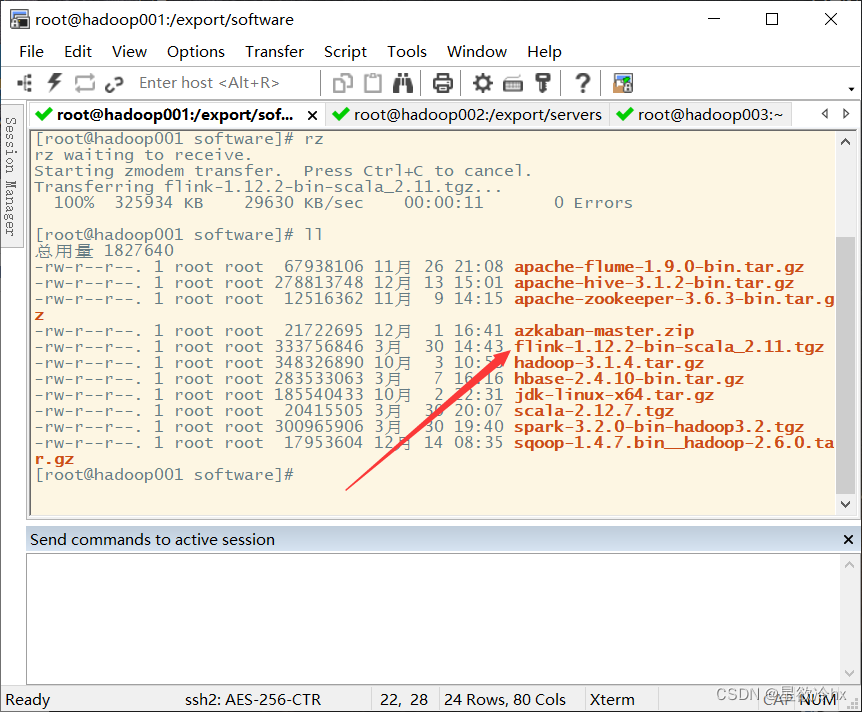
解压

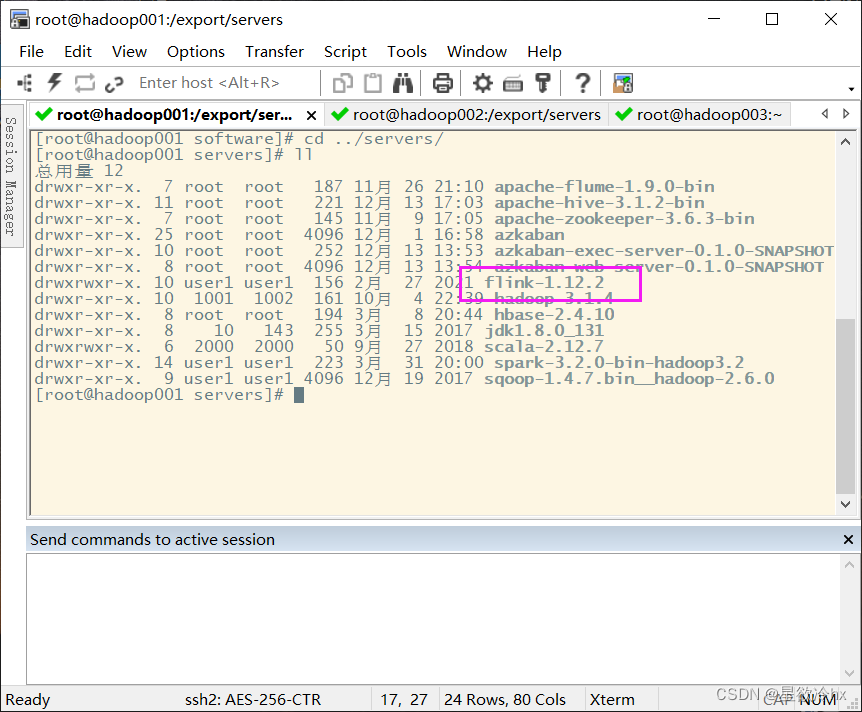

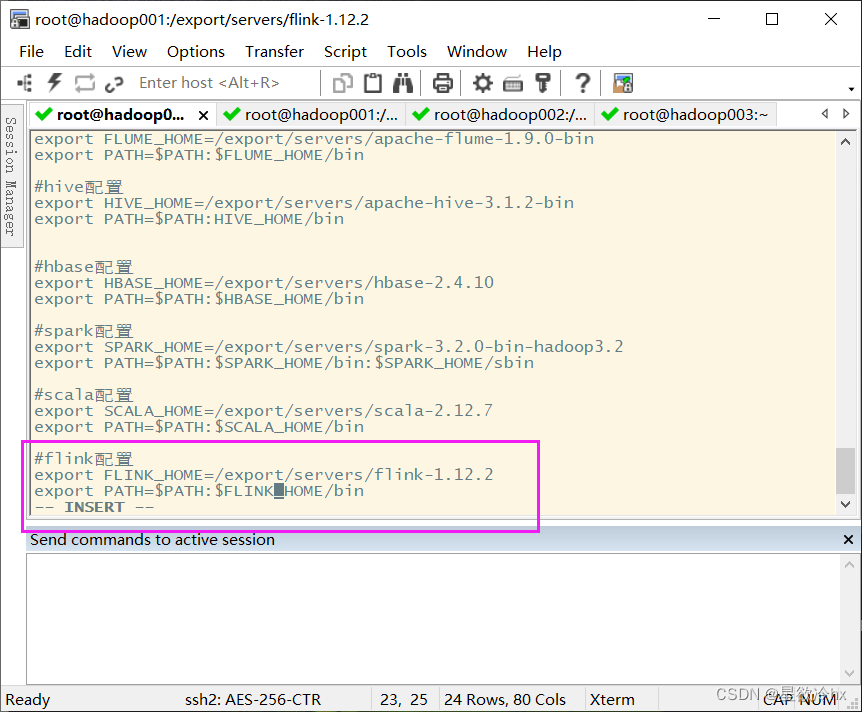
配置环境变量
使环境变量起作用
source /etc/profile
测试
启动Scala shell交互界面
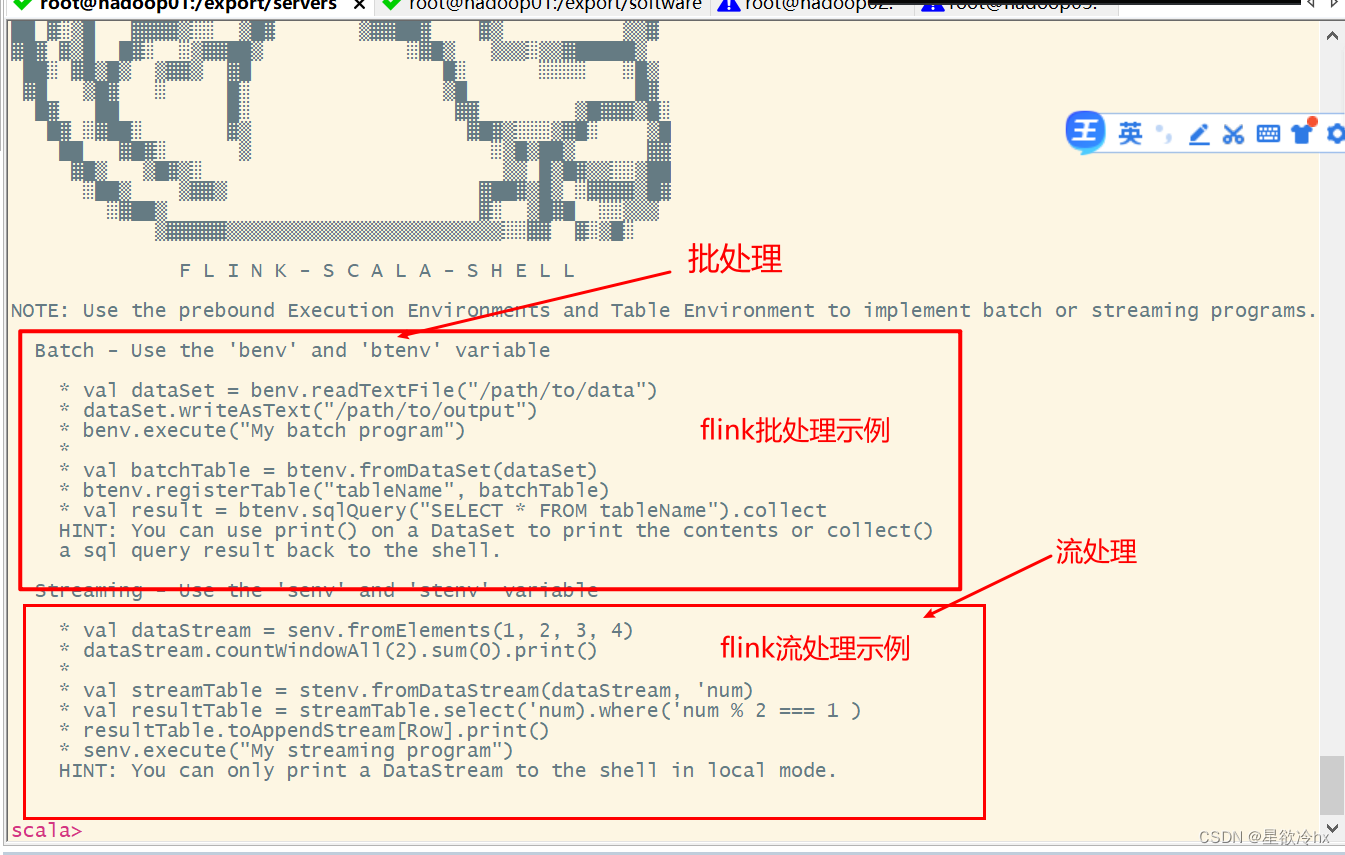
scala命令行示例——单词计数
准备好数据文件,放在/root
执行命令
benv.readTextFile("/root/a.txt").flatMap(.split(" ")).map((,1)).groupBy(0).sum(1).print()
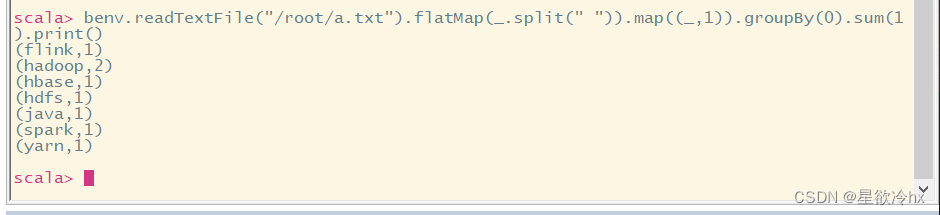
ctrl+d退出交互
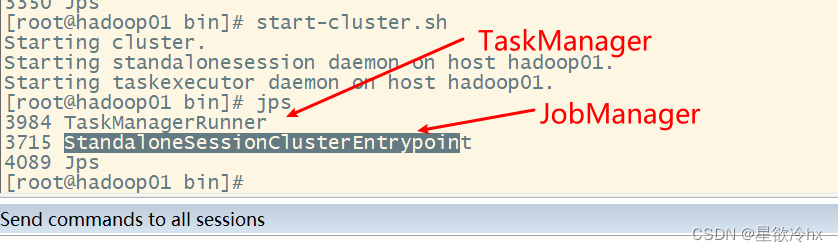
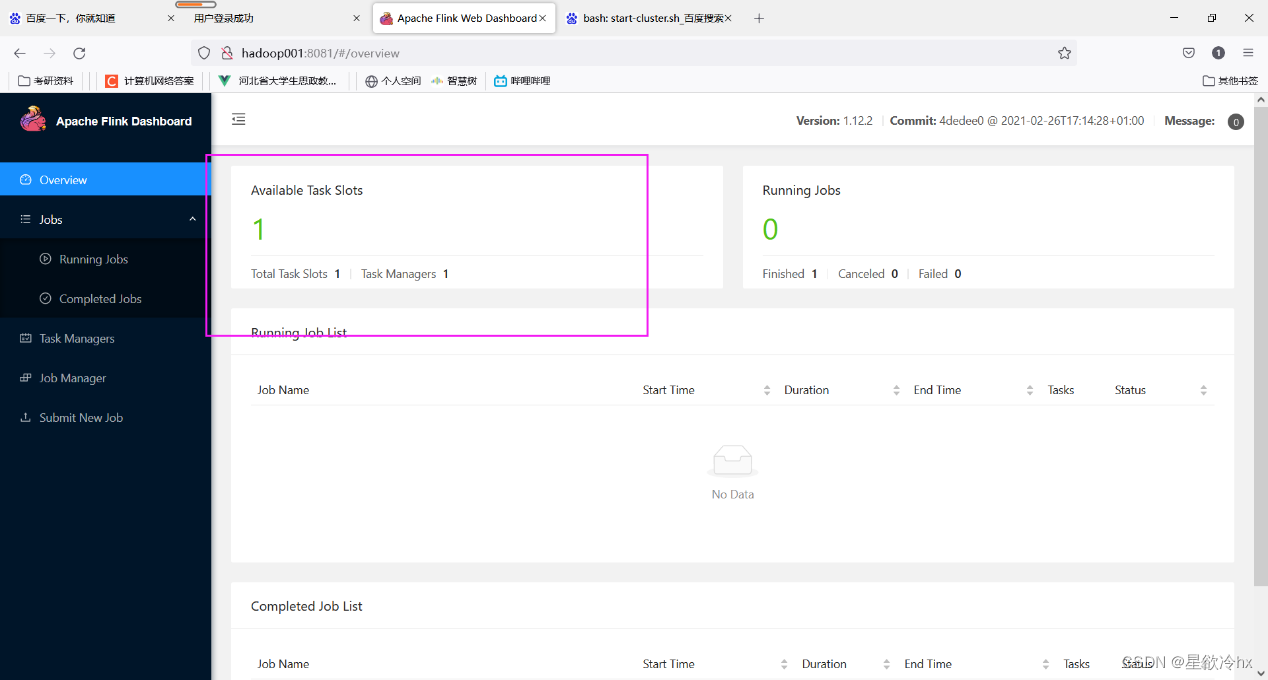
启动Flink的local集群
启动local 模式集群
这里不知道为啥环境变量错了,真是难受
后来知道了,原来是开两个窗口不是互通的,有clone延迟

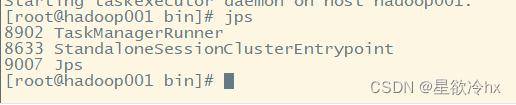
查看flink 的web ui
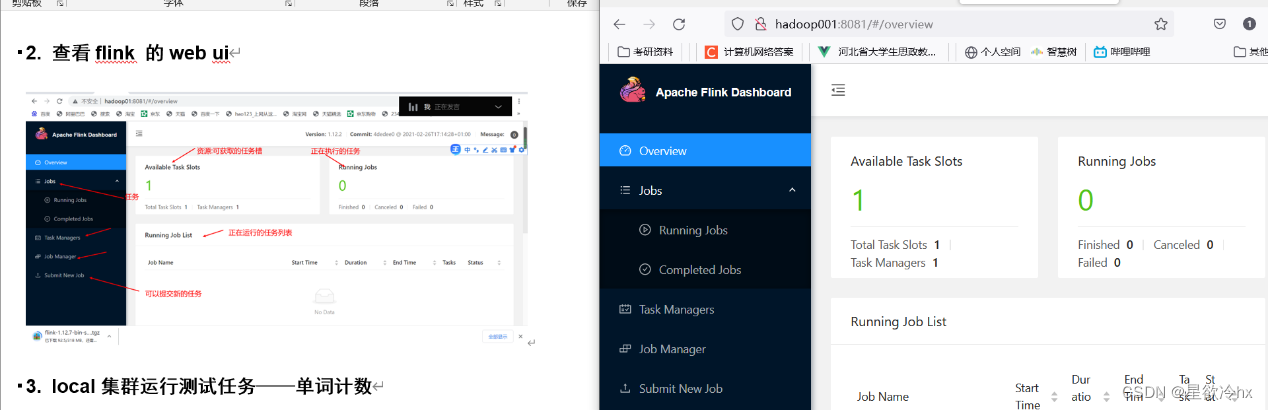
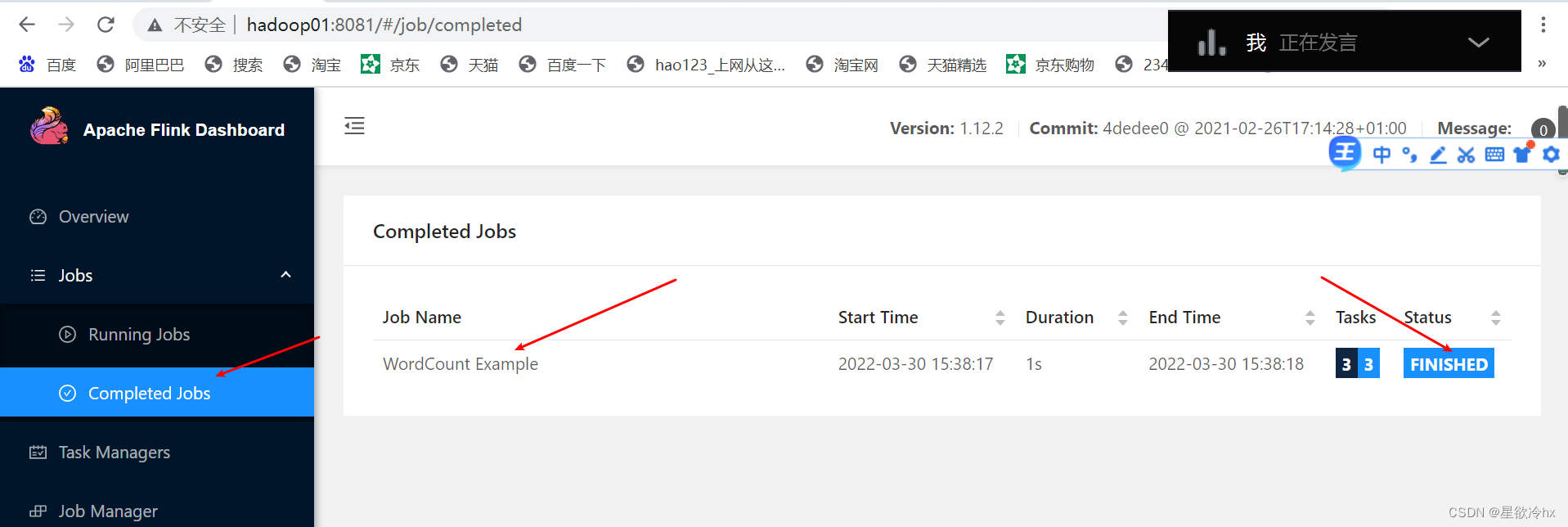
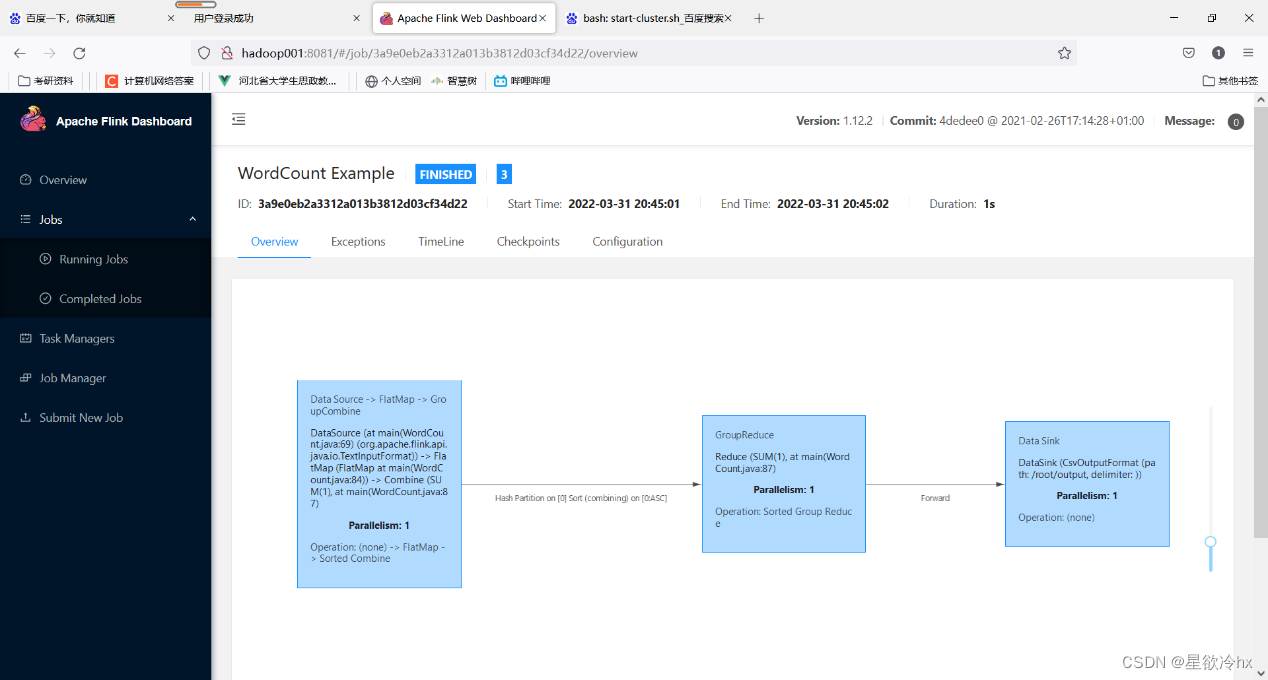
local集群运行测试任务——单词计数
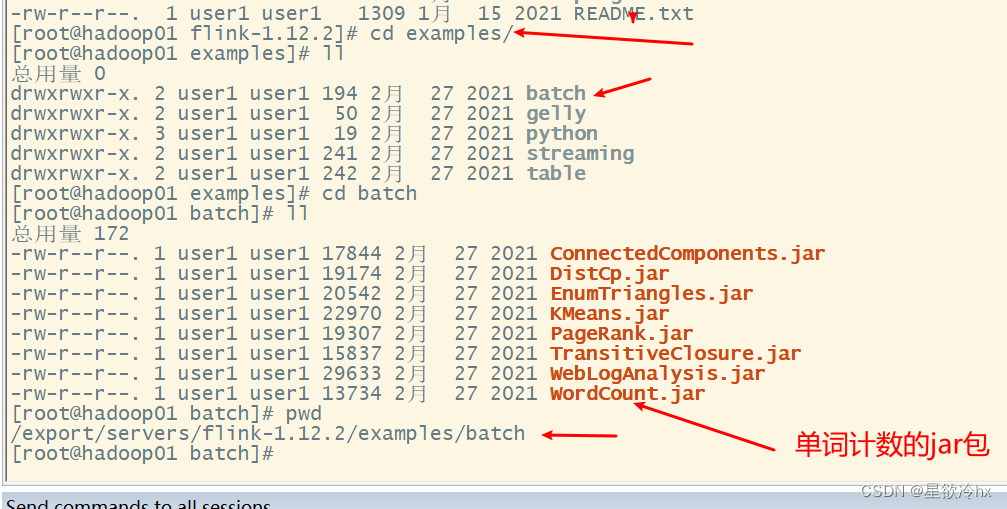
提交任务
flink run examples/batch/WordCount.jar --input /root/a.txt --output /root/output


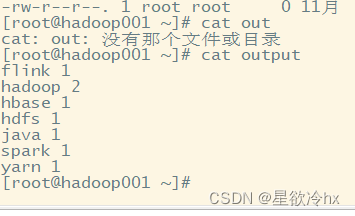
查看结果
Standalone模式安装
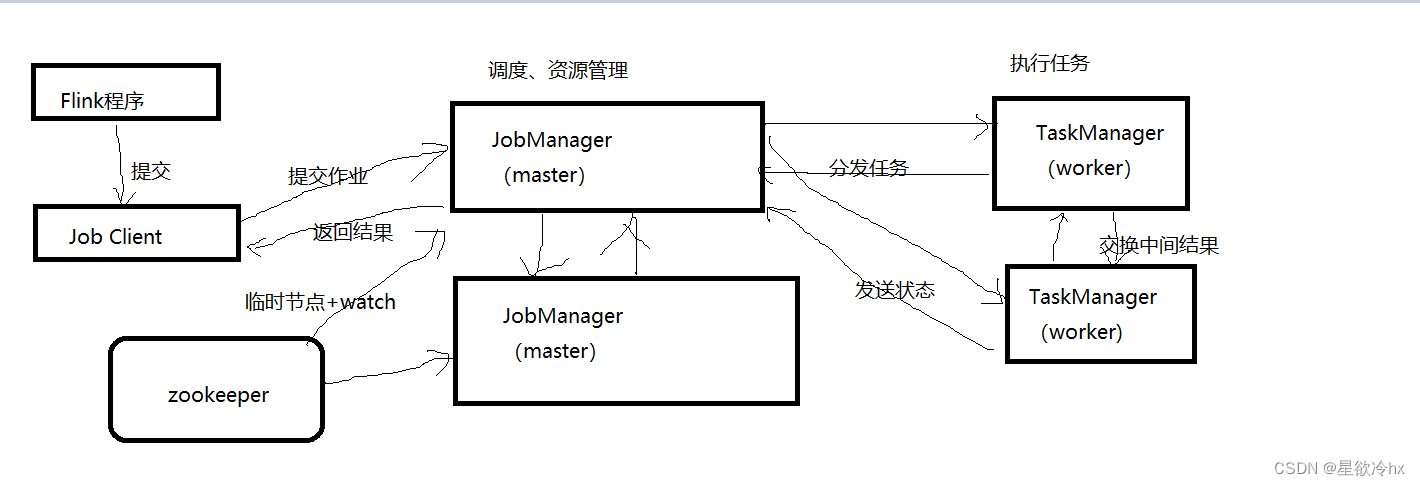
JobManager
TaskManager
hadoop01
y
y
hadoop02
n
y
hadoop03
n
y
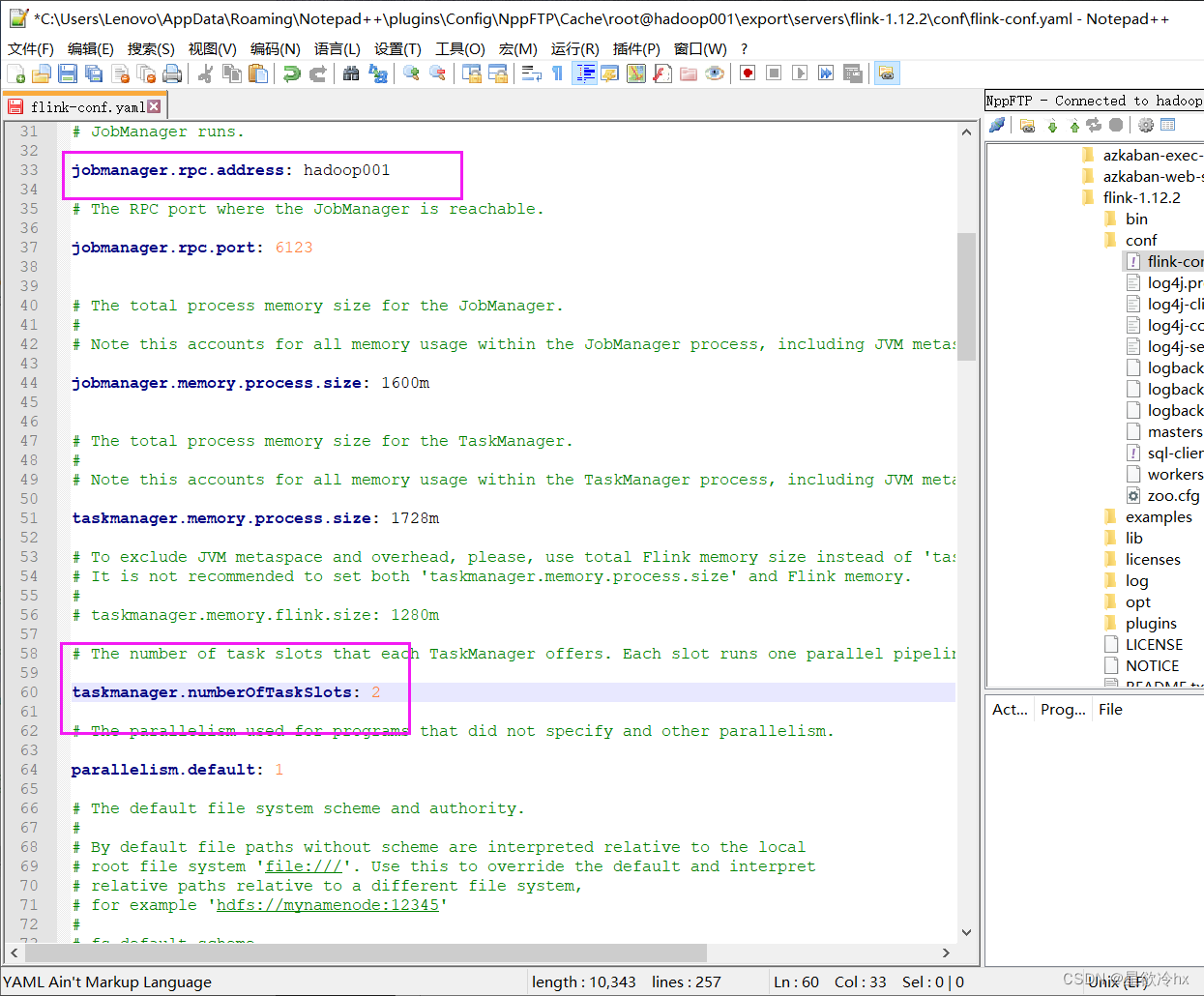
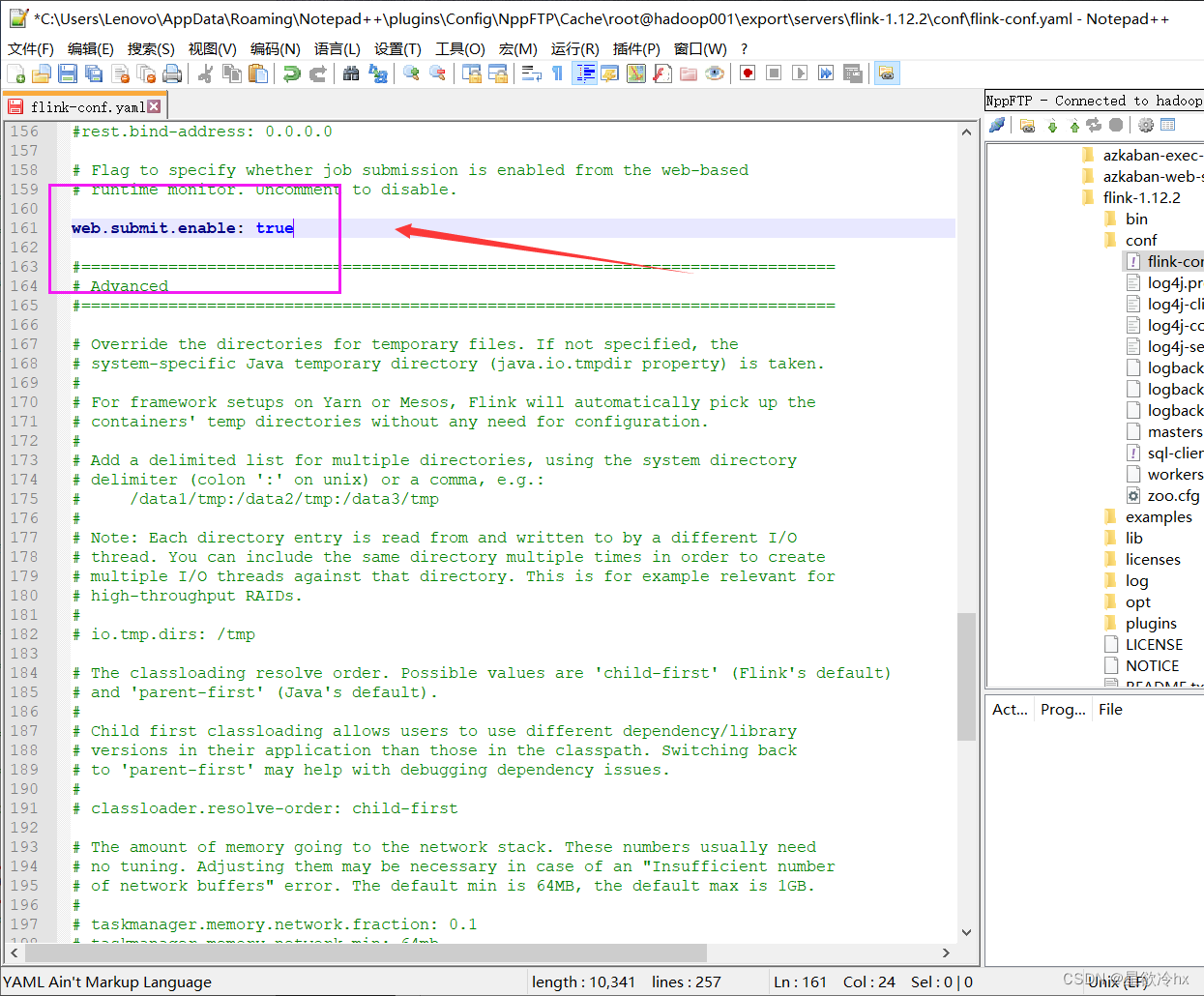
修改Flink的配置文件
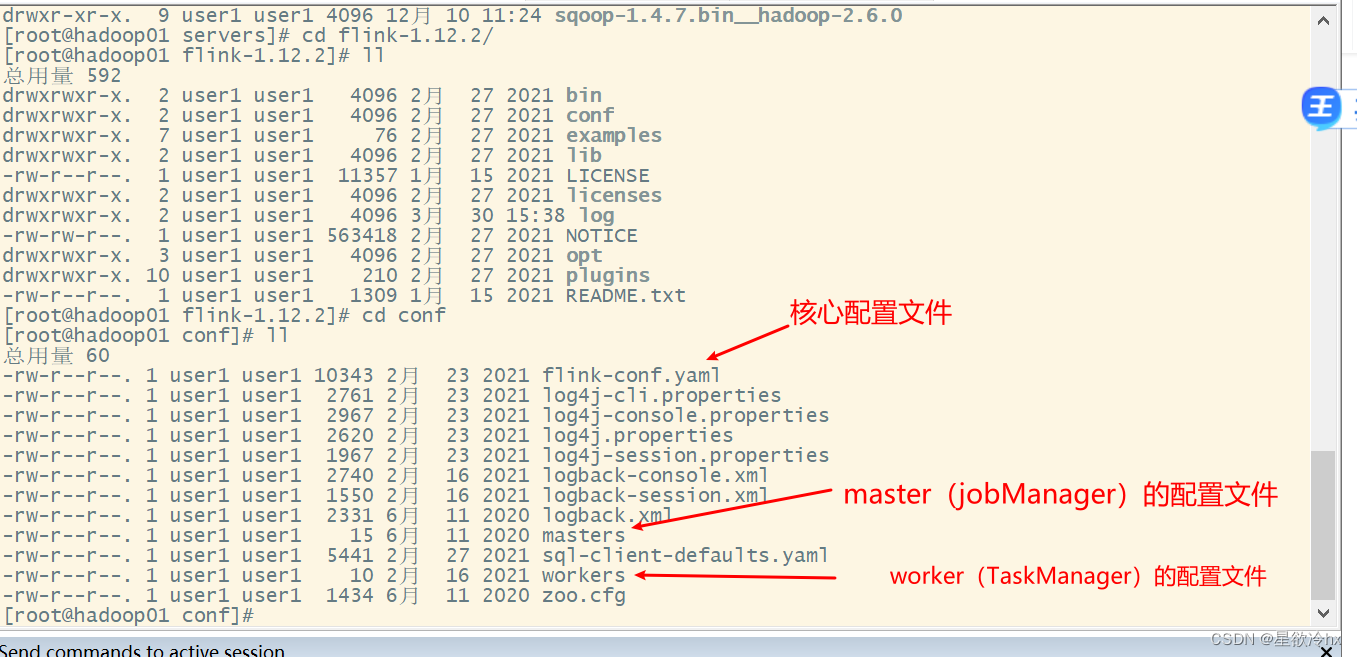
修改fink-conf.yml
注意:修改yml格式的配置文件时,key和value之间必须得有一个空格

masters
workers
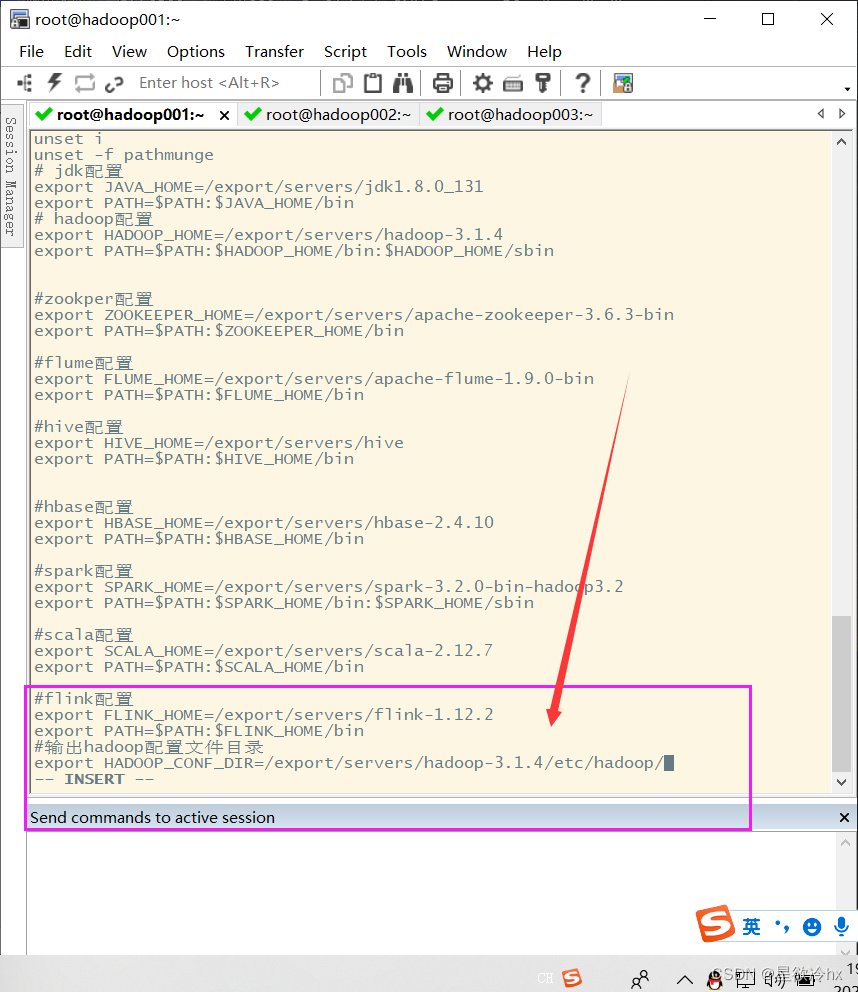
在环境变量配置文件中指定hadoop的配置目录
分发文件
分发****flink
分发环境变量配置文件

使环境变量起作用
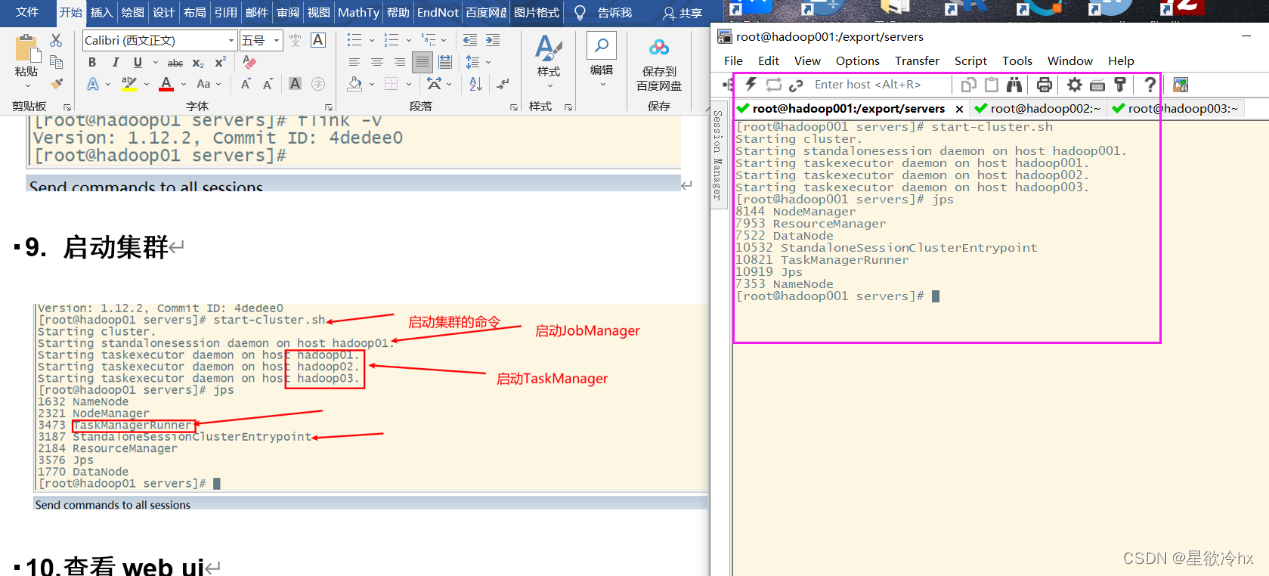
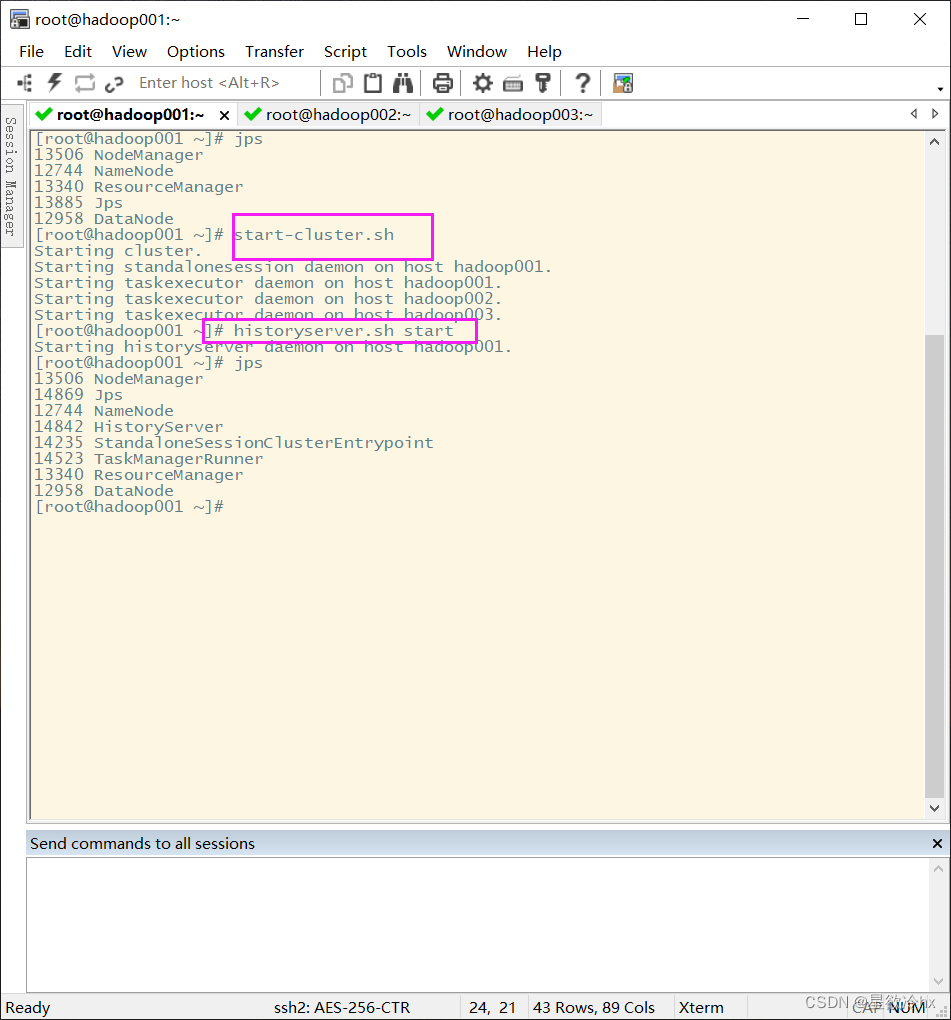
启动集群
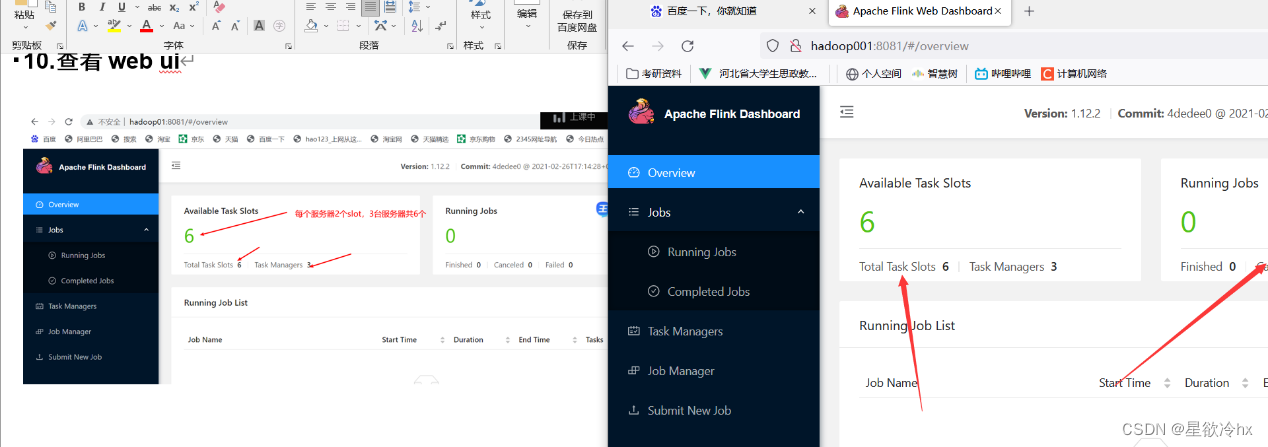
查看web ui
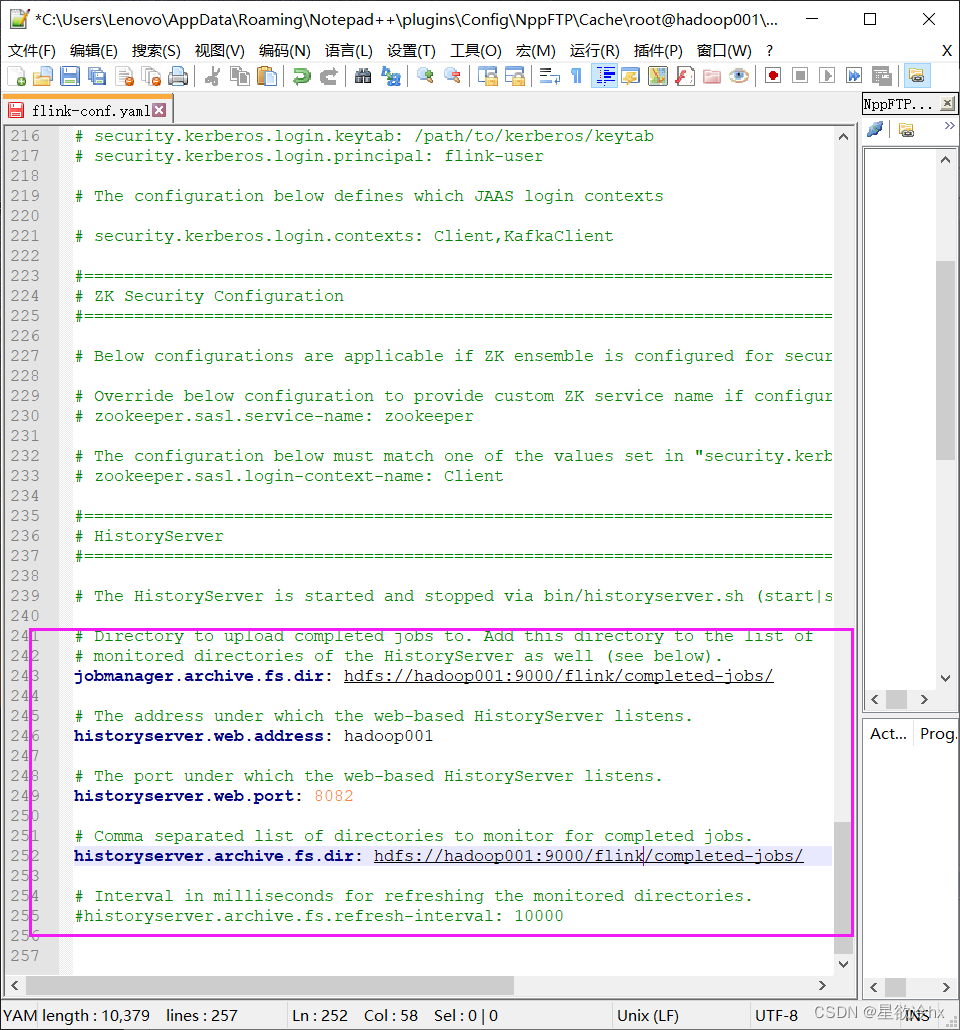
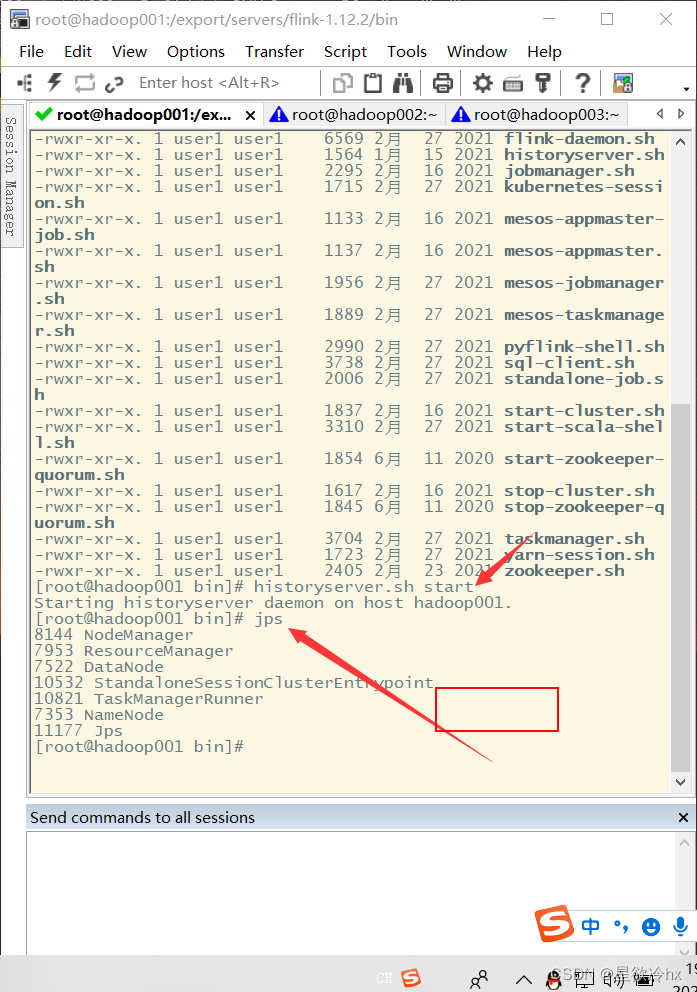
启动历史服务器


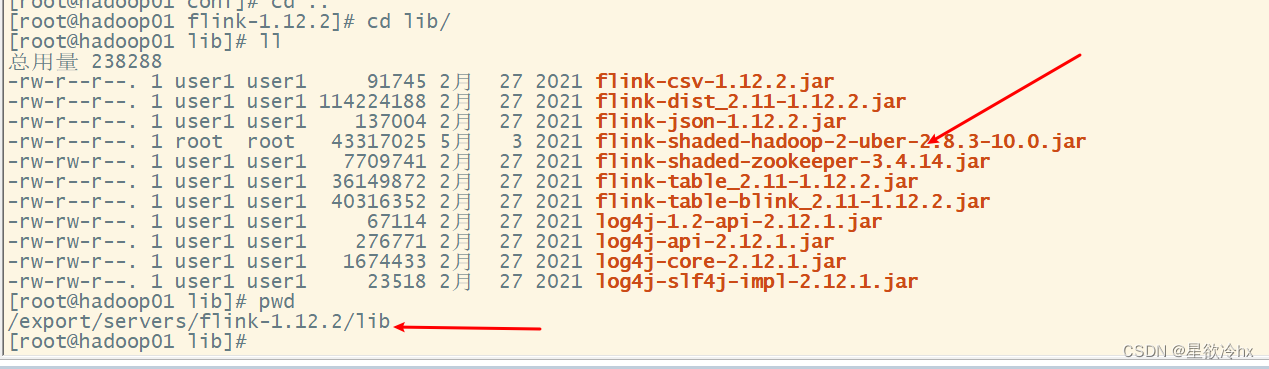
如果出错,则需要再添加一个hadoop 包,详细过程在本文章后面《上面整合jar包详细过程》那个标题
注意:

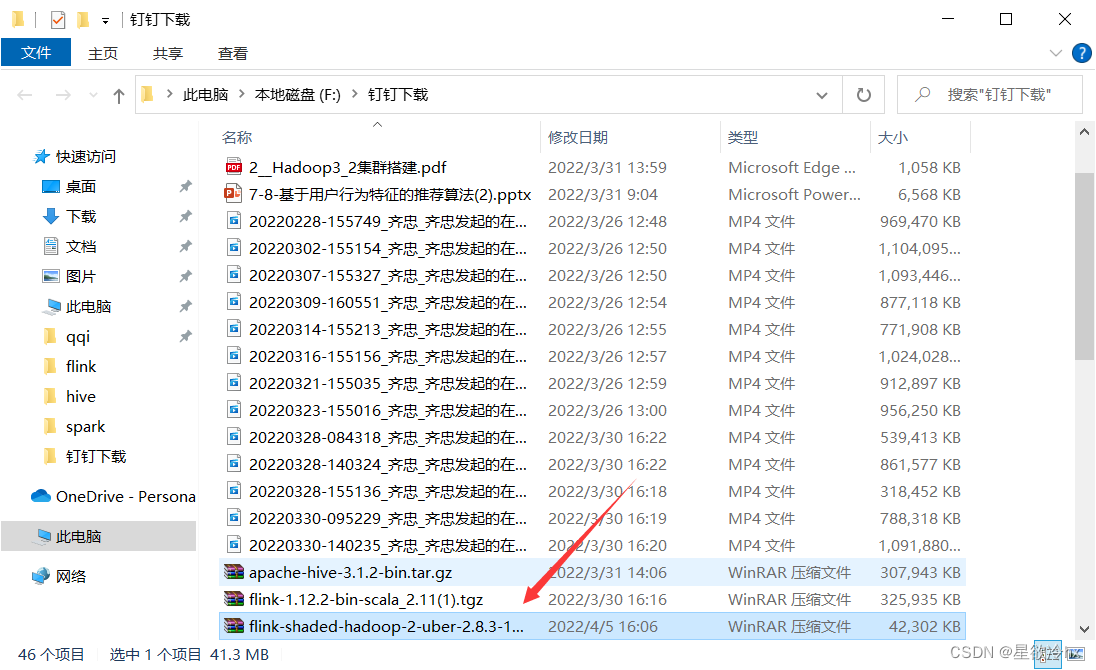
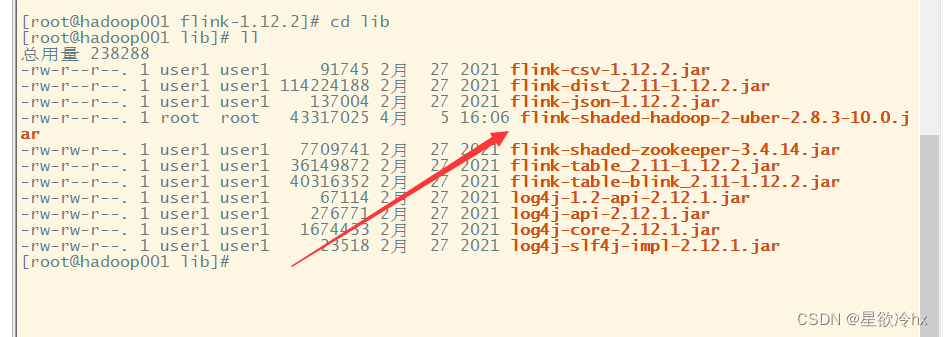
这就是刚才提到的那个,我把链接放这,把这个包放到这个lib目录里面
https://pan.baidu.com/s/1Jvo9n7y90TL2FjJRnDaCsg?pwd=1234 提取码:1234
详细过程在后面的标题《上面整合jar包详细过程》
查看历史服务器的web ui
standalone集群的测试任务——单词计数
flink run examples/batch/WordCount.jar --input hdfs://hadoop001:9000/input/ --output hdfs://hadoop001:9000/output/result.txt
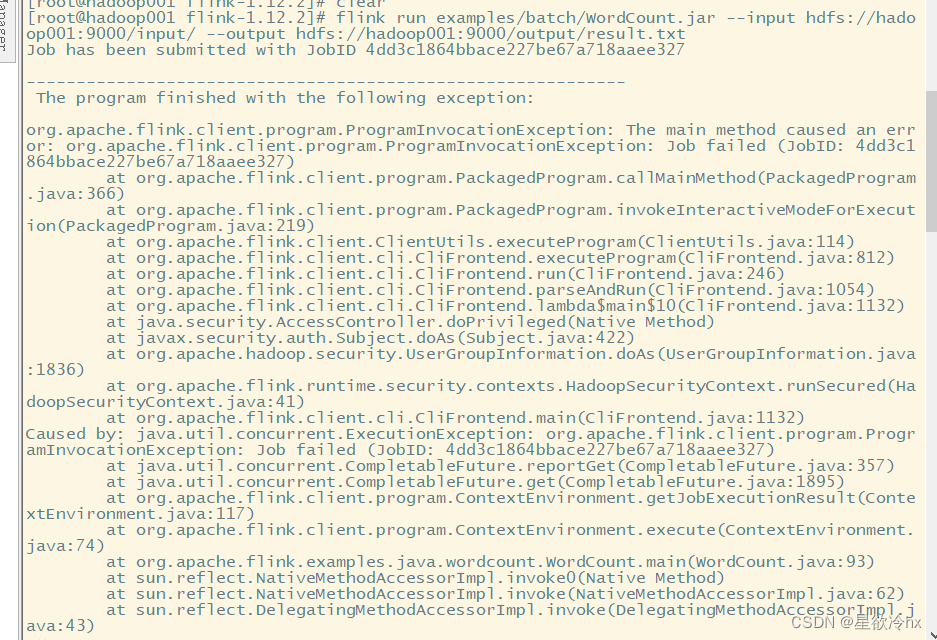
出错了,发现是有out put 文件,必须先删除
一定要先删除output
hdfs dfs -rm -r /output
再重启运行
使用默认的参数执行
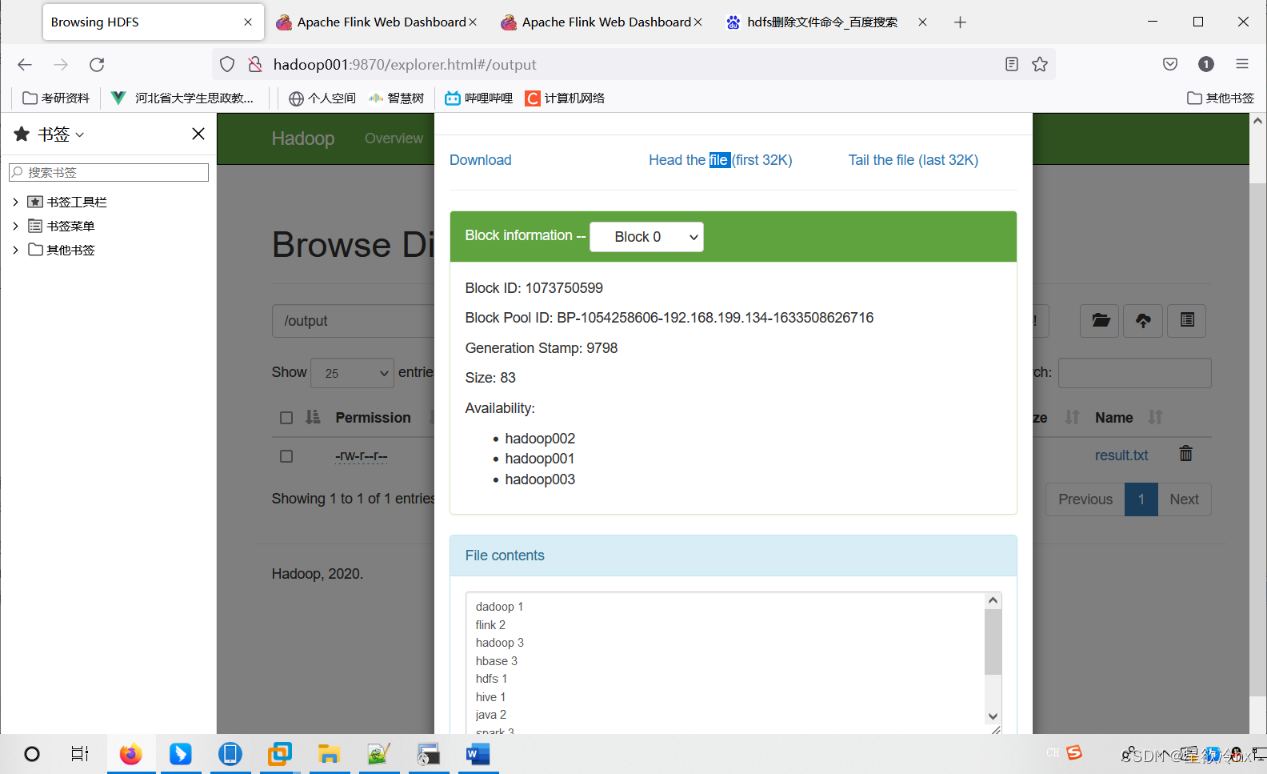
这里需要再删除output
带参数的任务提交
flink run examples/batch/WordCount.jar --input hdfs://hadoop001:9000/input/ --output hdfs://hadoop001:9000/output/result.txt

查看结果
注意:运行过程中会出现问题,需要配置hadoop classpath的环境变量,获取classpath可以通过一下命令:
*** hadoop classpath***
(上边已经改过了)
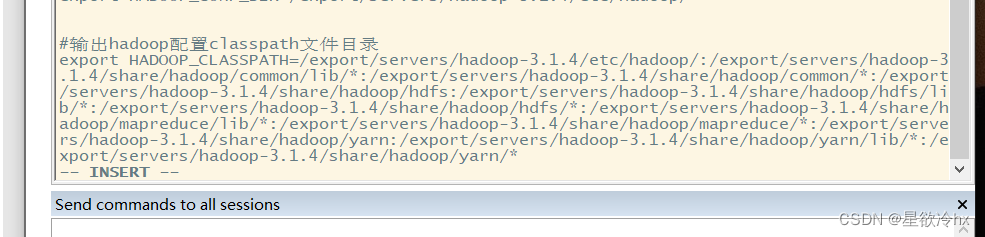
修改/etc/profile,添加HADOOP_CLASSPATH变量,值为前述命令的结果,复制粘贴过来即可
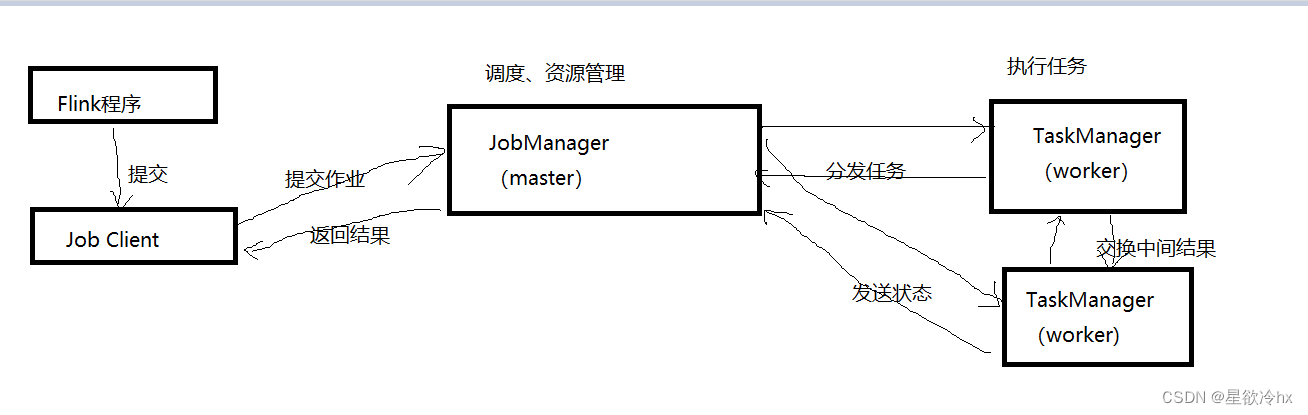
工作原理
Standalone-HA模式安装
集群规划
JobManager
TaskManager
hadoop01
y
y
hadoop02
Y
y
hadoop03
n
y
停止flink集群
stop-cluster.sh
修改flink的配置文件
(笔者在这里出现了bug,改了一下午,发现是第一条高可用zookeeper只要配置ha总会出错,后面重装解决)
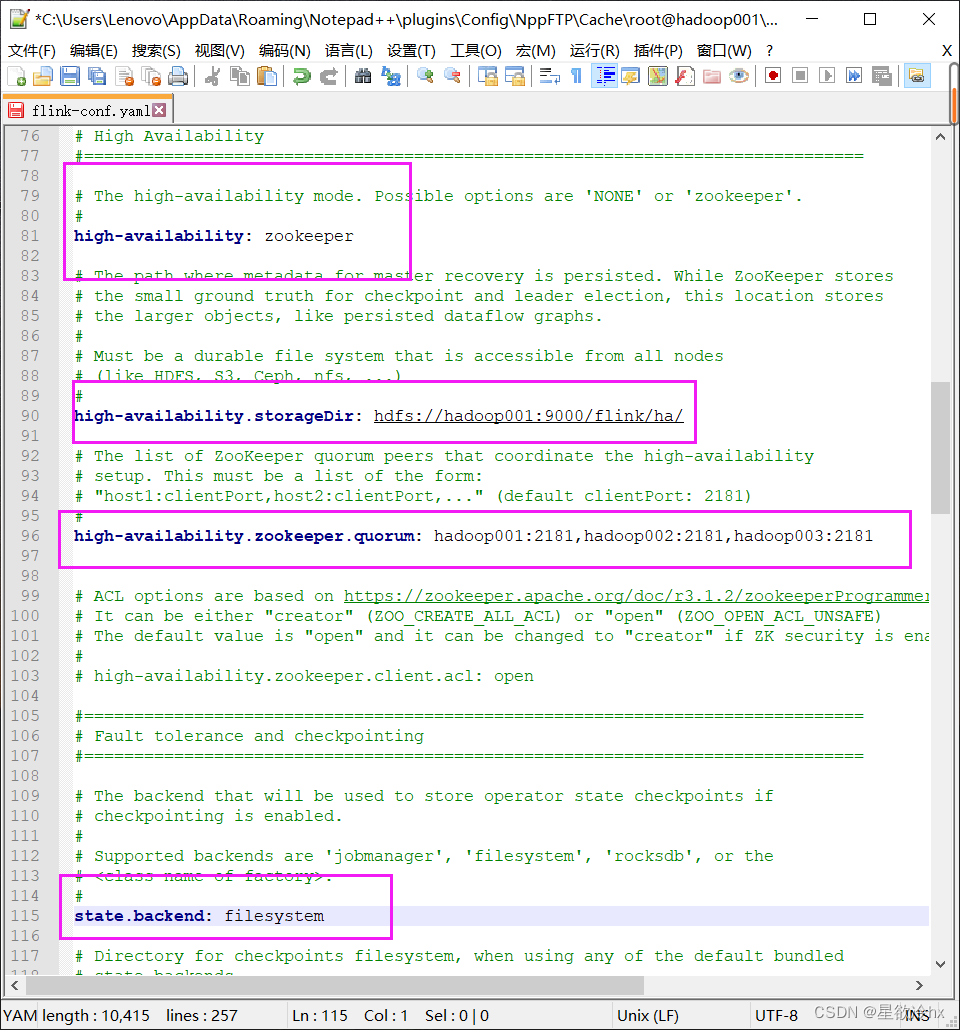
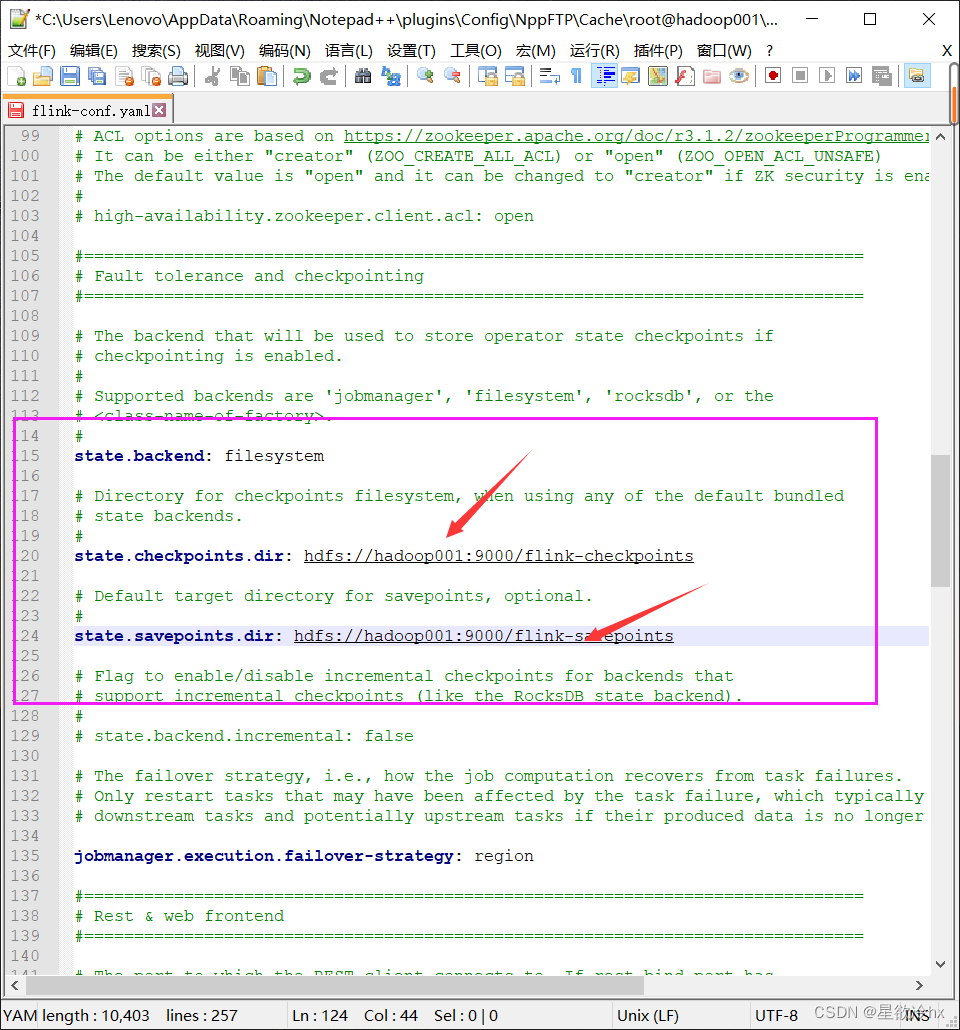
修改masters文件

不用修改workers文件 同步配置文件
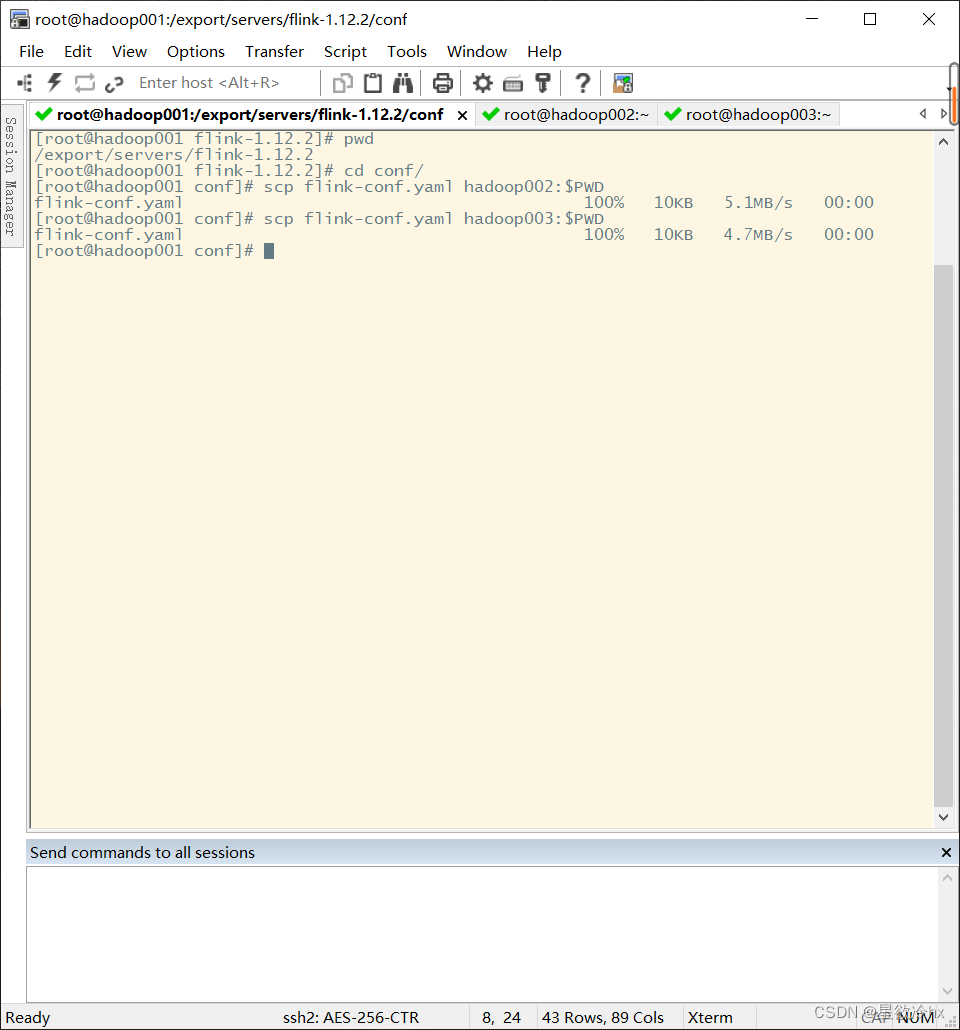
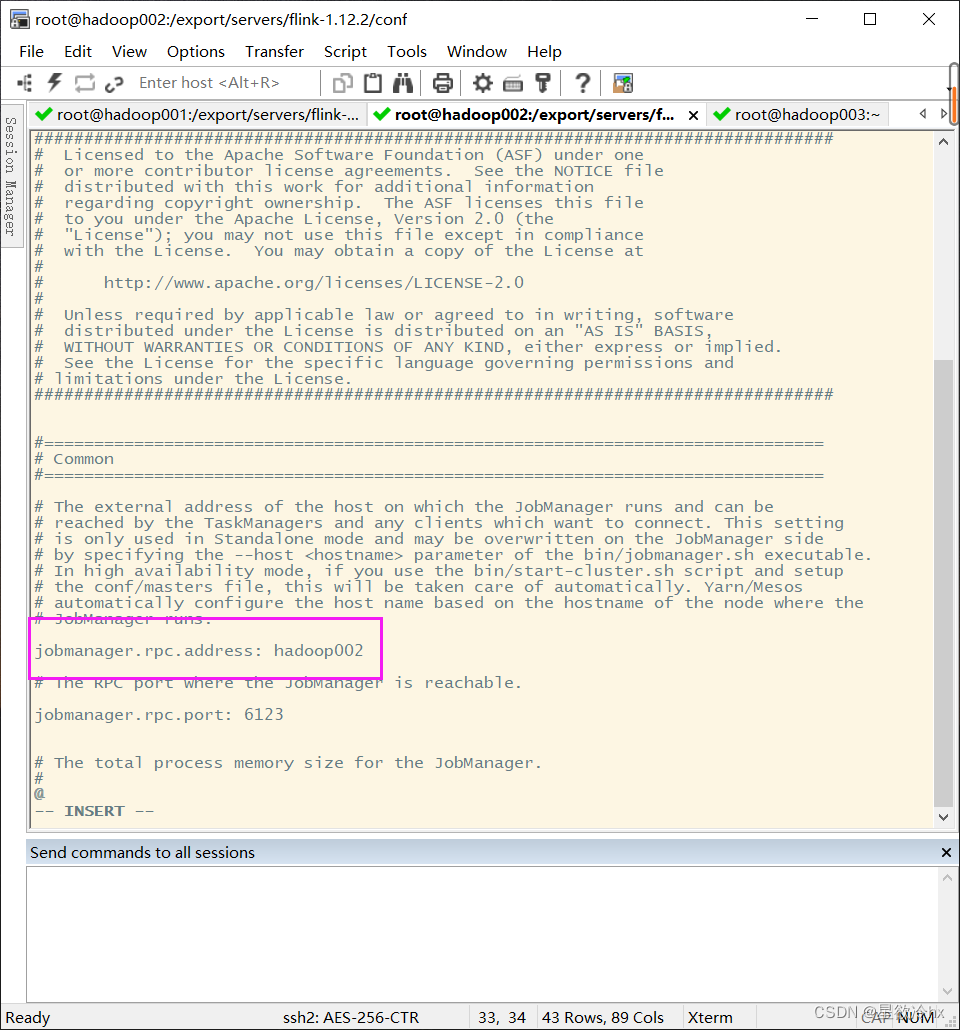
修改hadoop02上的flink配置文件flink-conf.yaml
重新启动flink集群
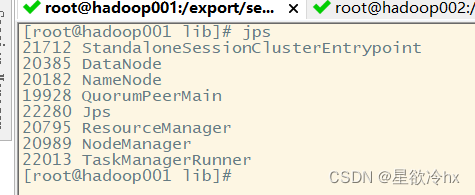
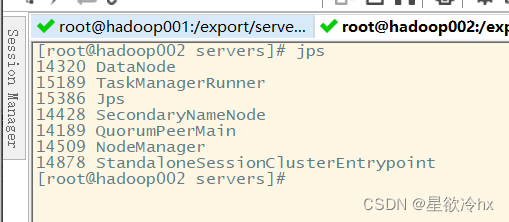
上面整合jar包详细过程
说明:如果发现相关的进程没有启动,是因为缺少flink整合hadoop的jar包,需要从flink官网下载,放入flink的lib目录,并分发至其他节点
Apache Flink: Downloads

flink的webui查看
集群测试——单词计数
杀掉hadoop001的master
重新执行单词计数,查看能否正常执行
要一个输出路径
说明集群能正常工作,高可用起作用

工作原理
Flink On Yarn模式安装
优点
资源可以按需使用,提高集群的资源利用率
任务有优先级,可以根据优先级运行作业
基于yarn调度系统,能够自动化的处理各个角色的容错
集群规划
跟standalone保持一致
JobManager
TaskManager
hadoop01
y
y
hadoop02
Y
y
hadoop03
n
y
修改yarn的配置
修改hadoop的yarn的配置文件yarn-site.xml
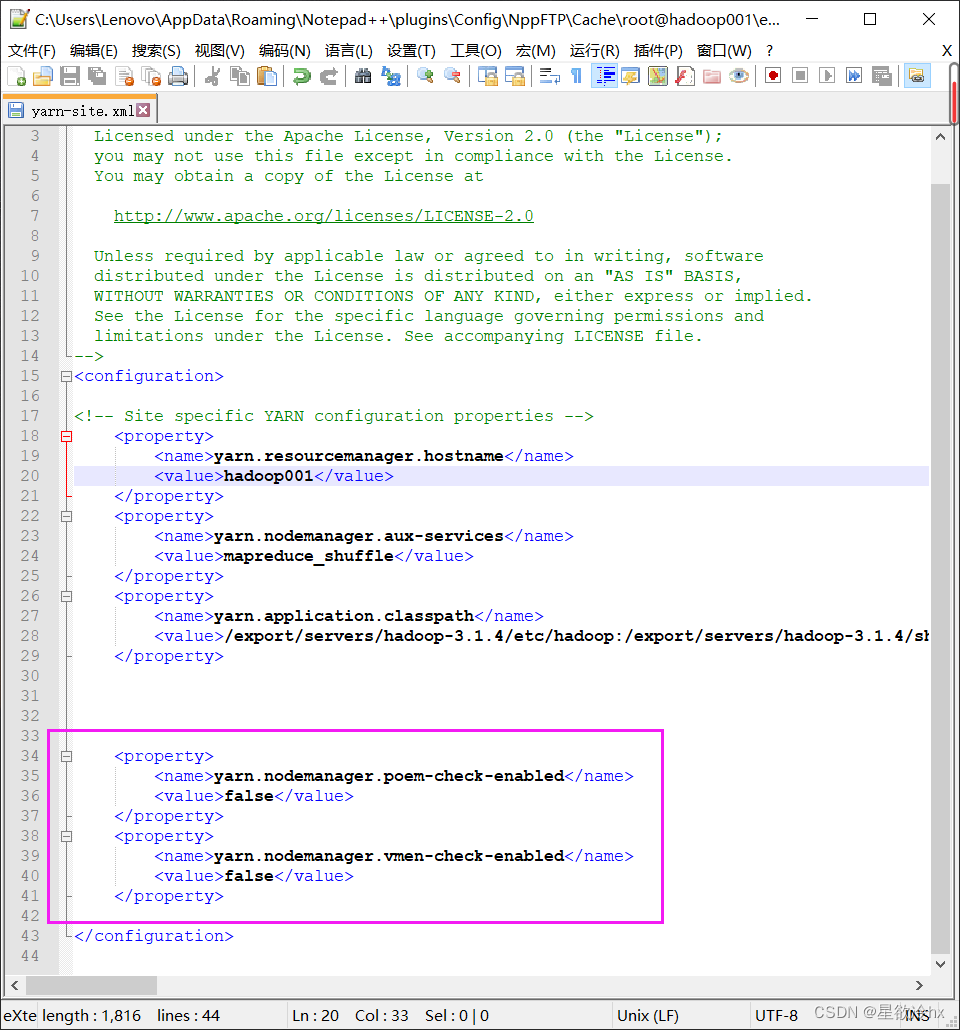
分发到其他节点

启动相关服务
- zookeeper
- dfs
- yarn
- flink
- historyserver
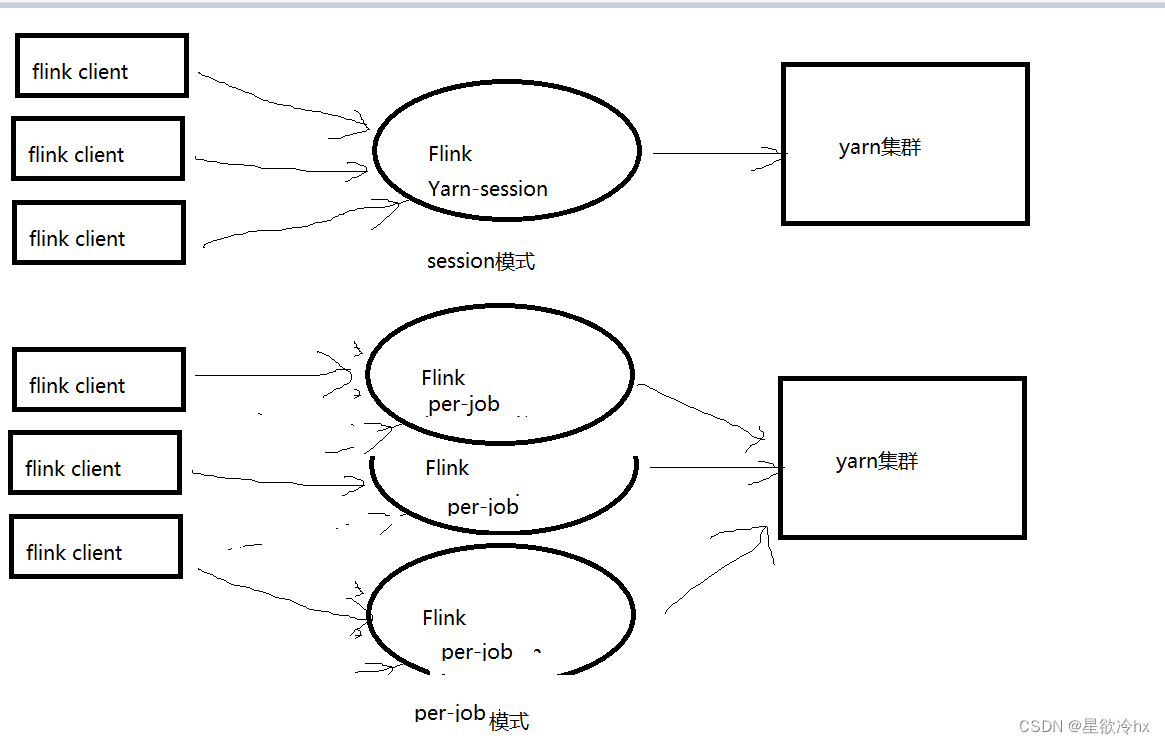
提交任务模式
flink on yarn提交任务模式有两种
session模式:会话模式
per-job模式:每任务模式
Session模式提交任务
开启会话(资源)
语法:
yarn-session.sh -n 2 -tm 800 -s 1 -d
说明:
-n:表示申请的容器,也就是worker的数量,也即cpu的核心数
-tm:表示每个worker(taskManager)的内存大小
-s:表示每个worker的slot的数量
-d:表示后台运行

当前的jps:
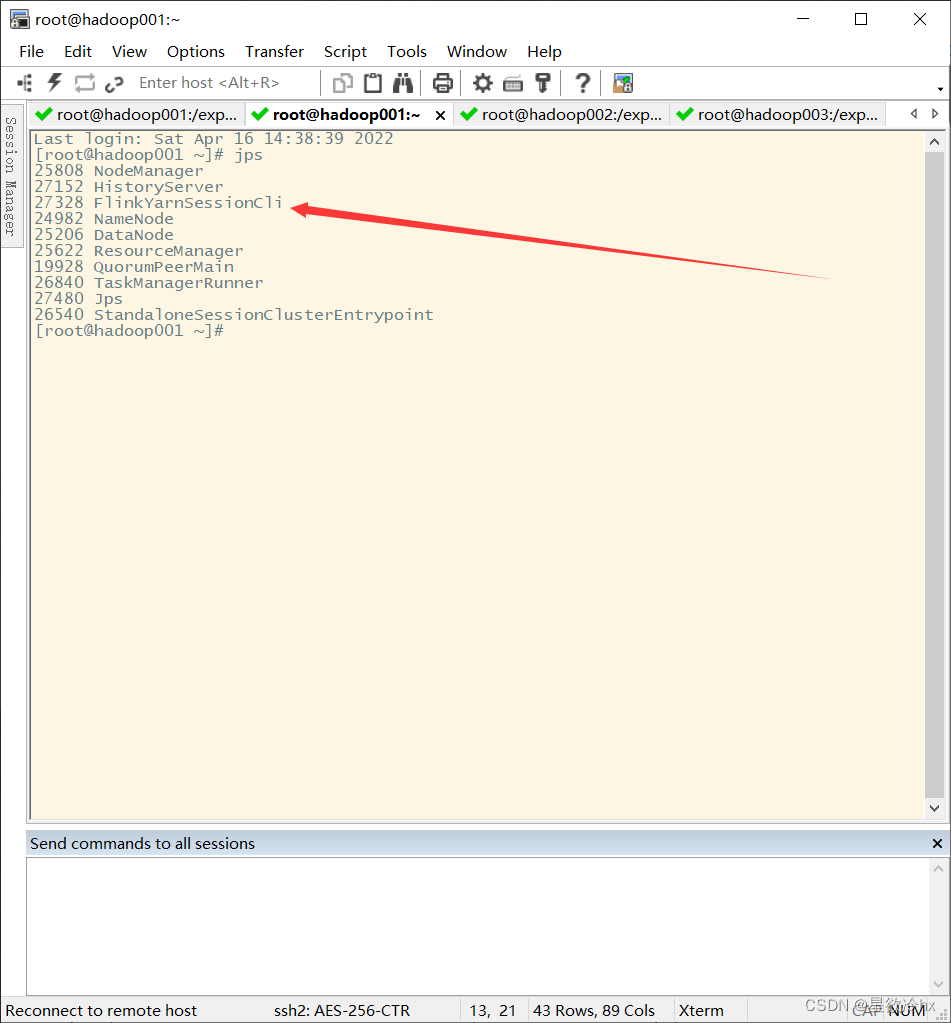
查看yarn的web ui
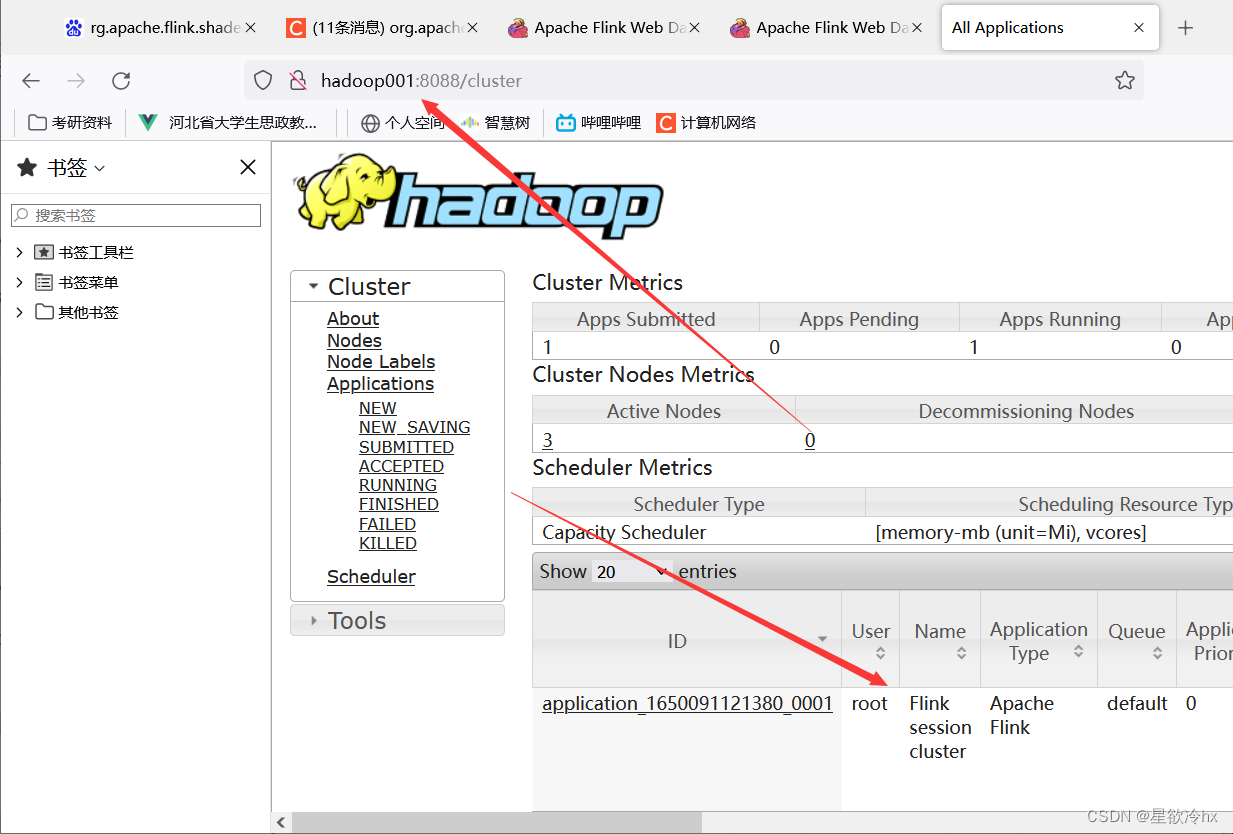
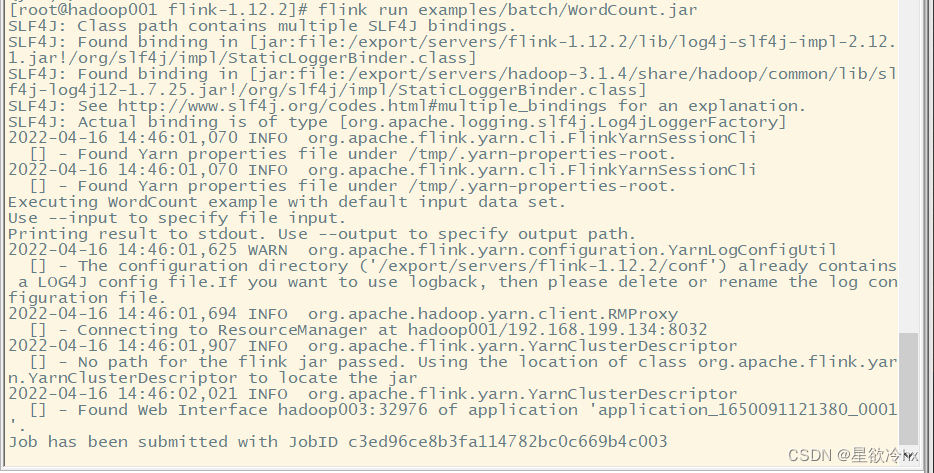
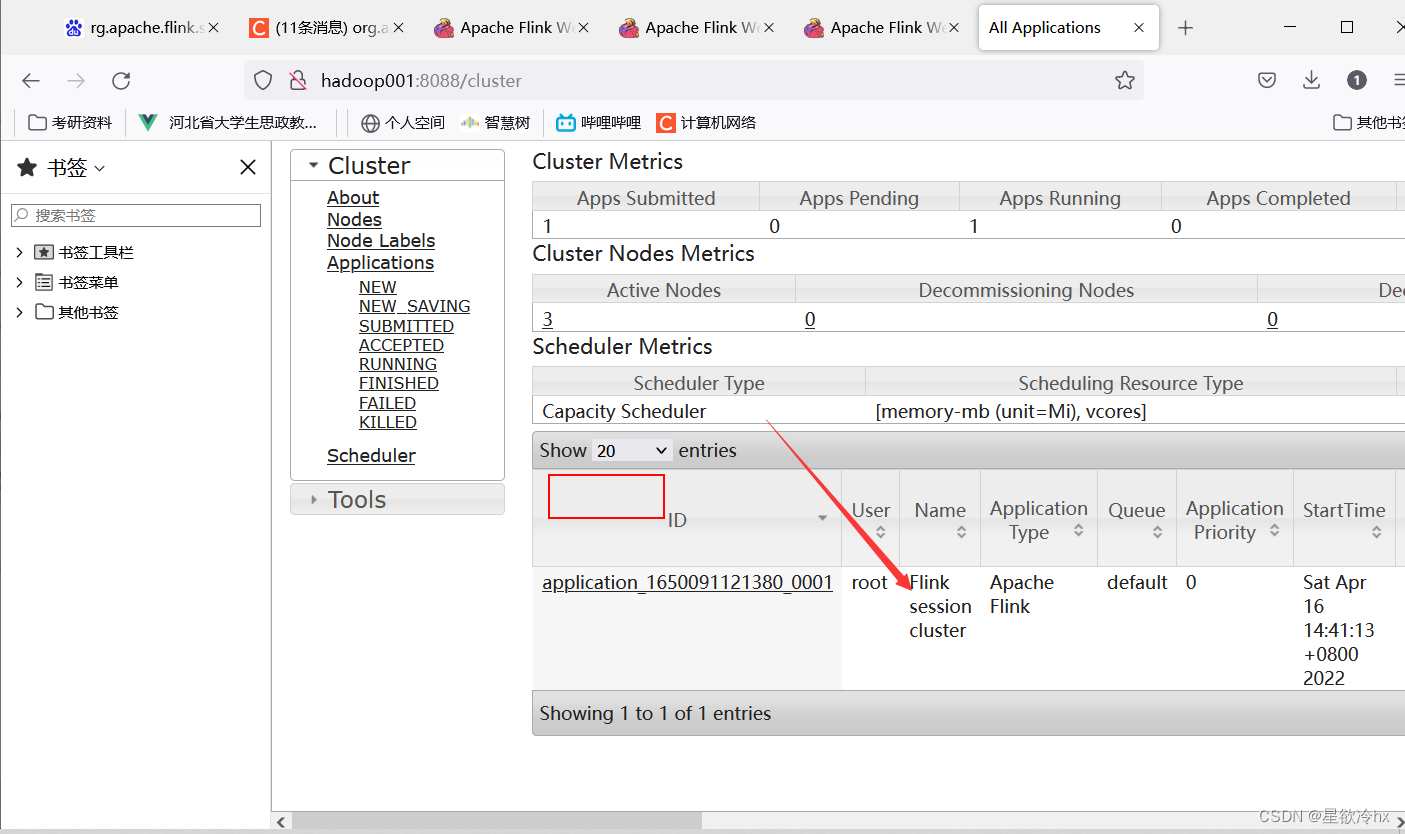
提交任务-单词计数
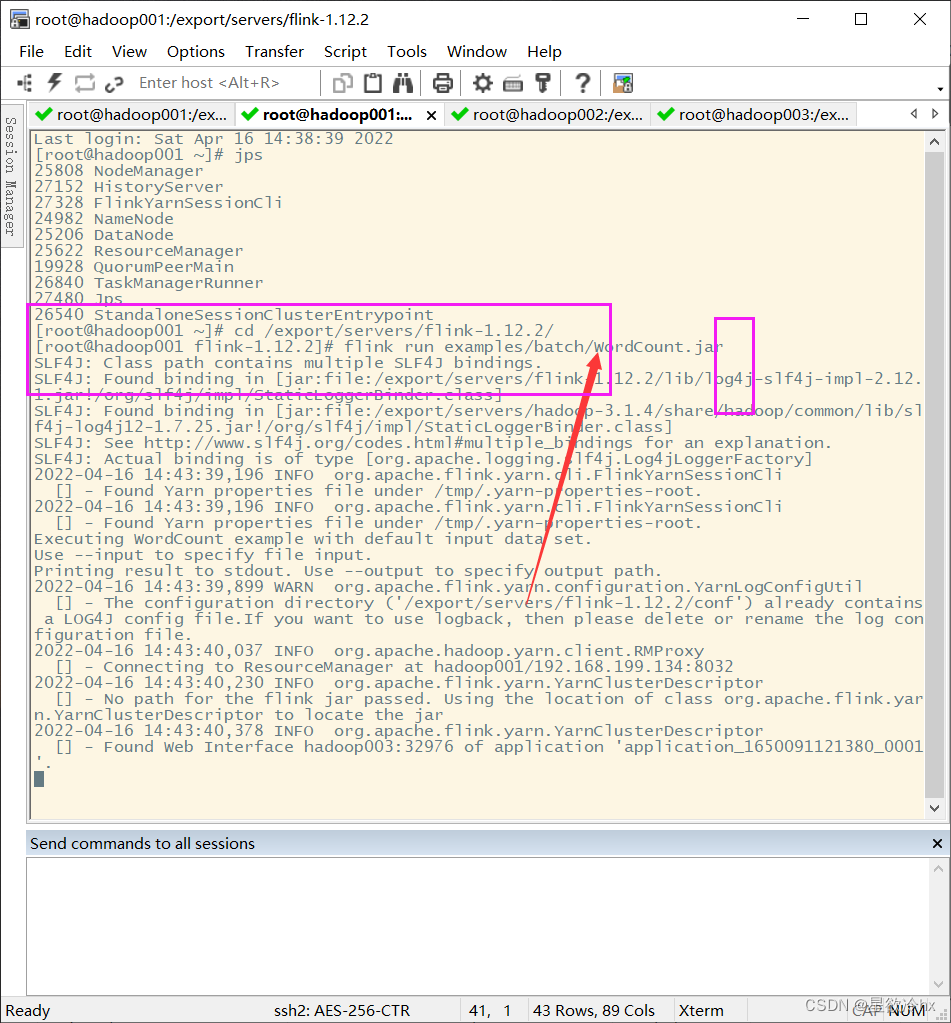
查看yarn的web ui
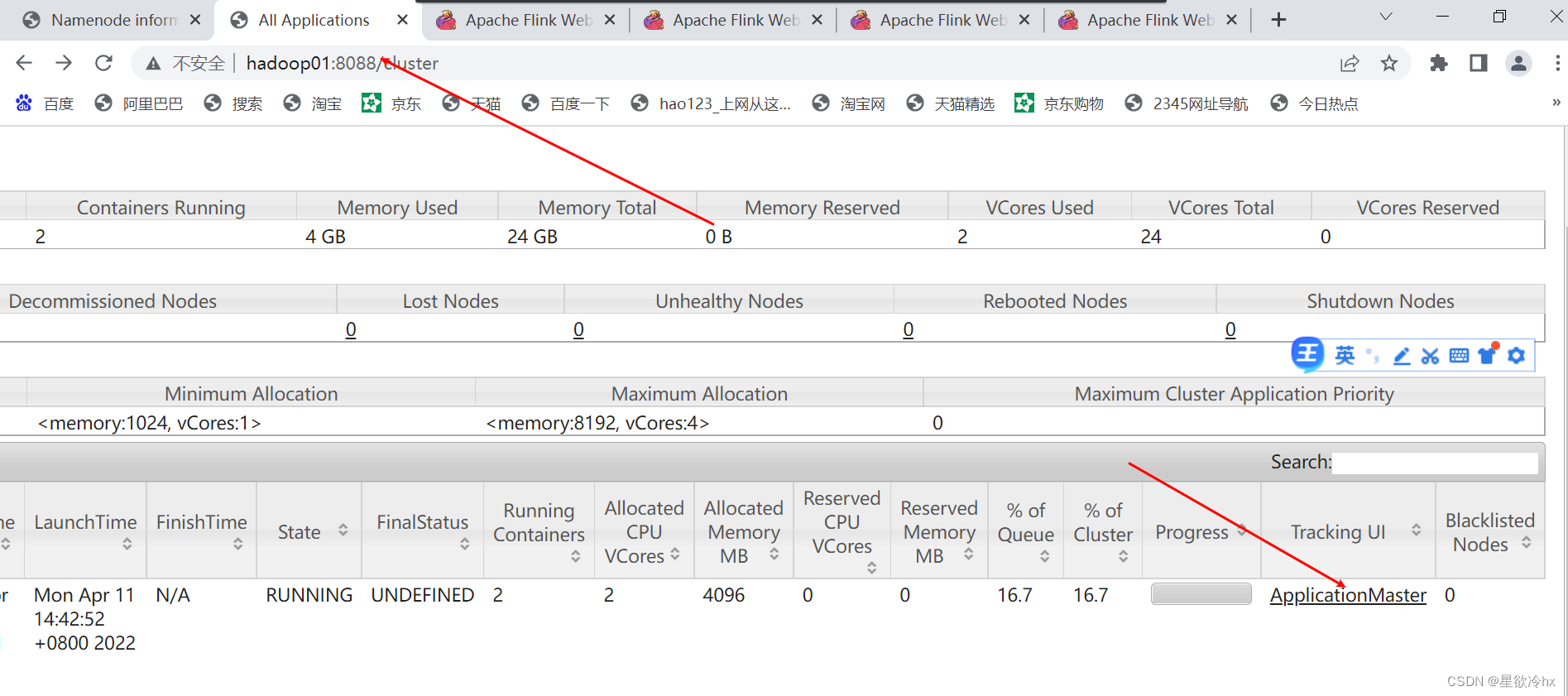
再次提交一个任务
再查看yarn的web ui
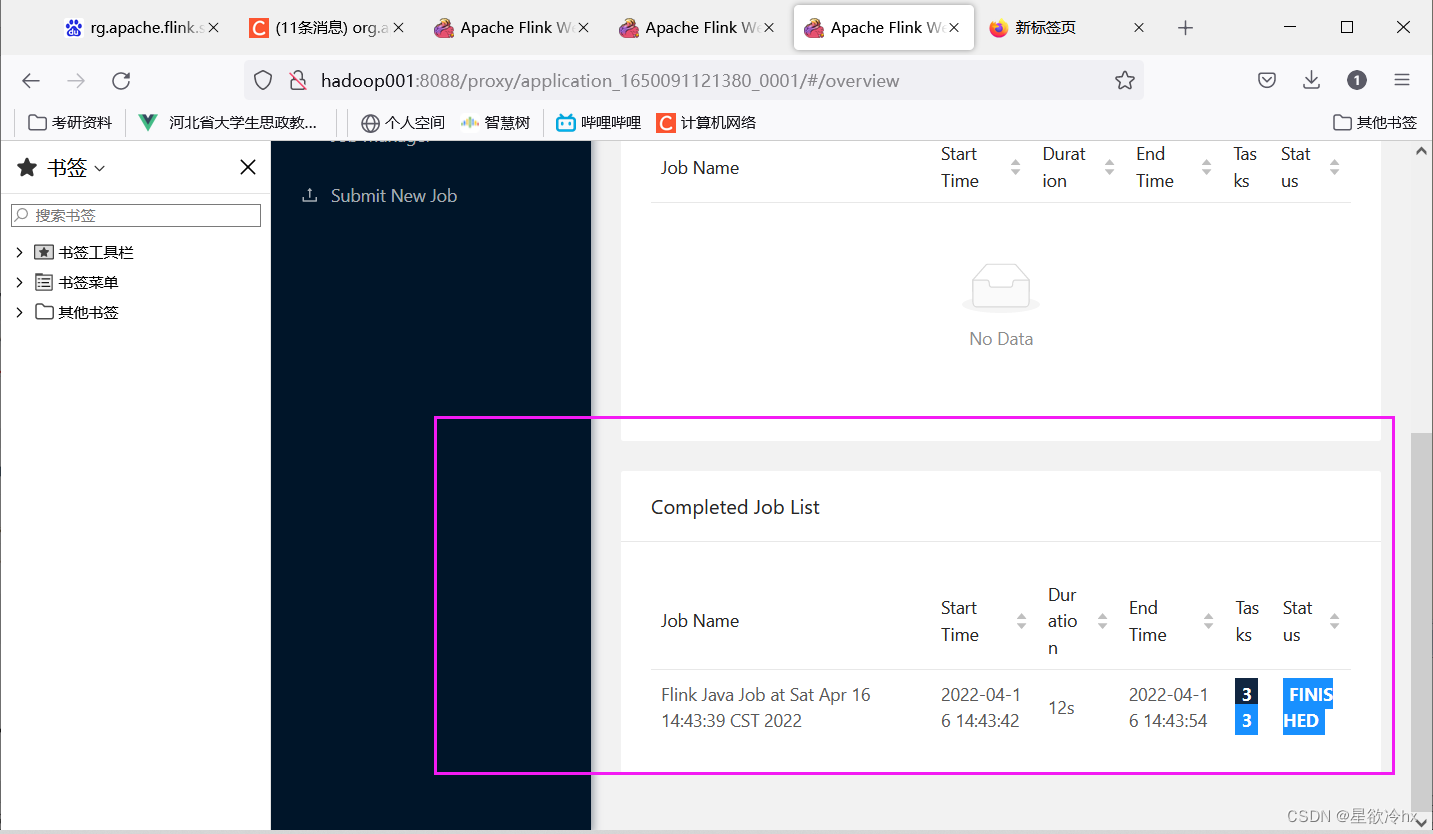
session一直在
查看任务详情
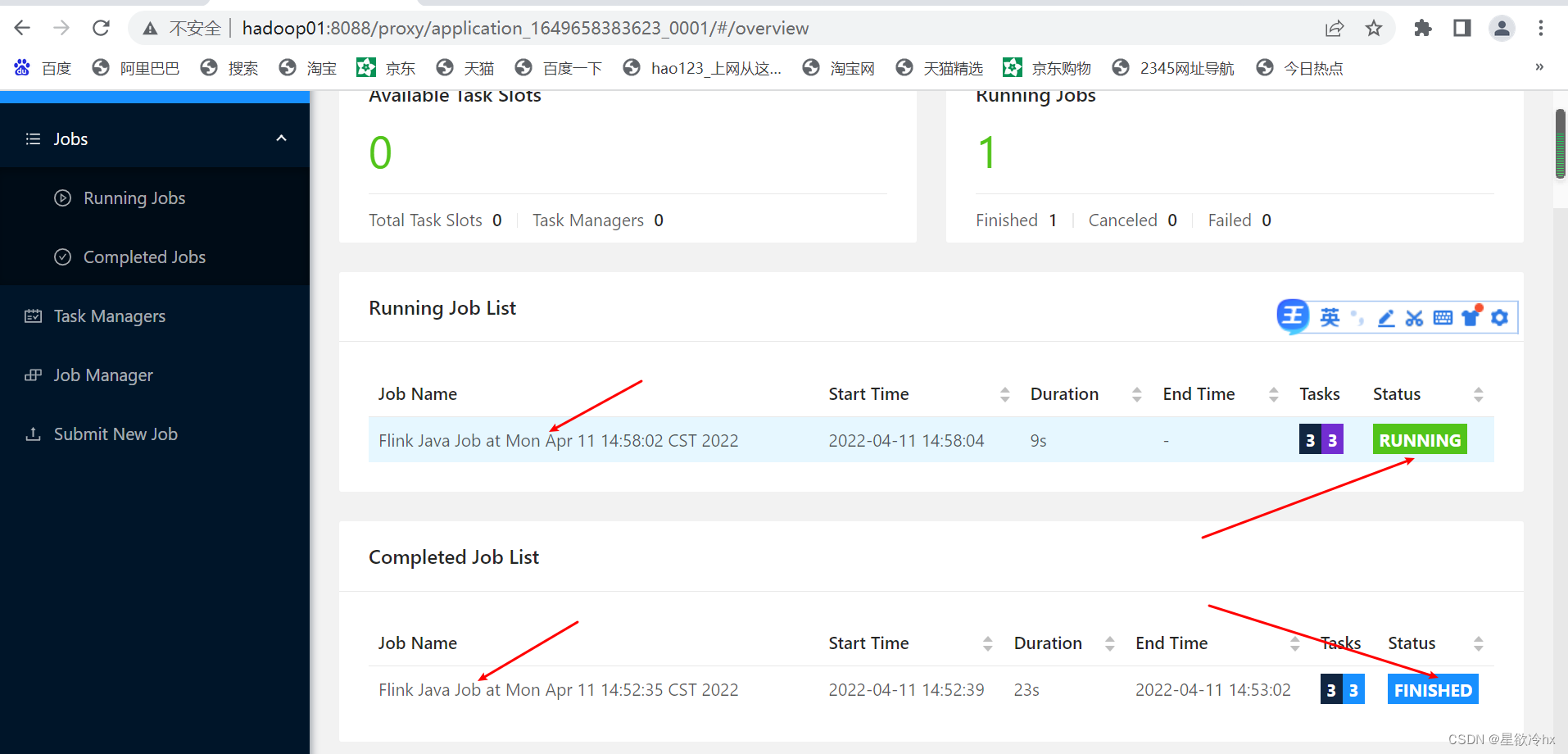
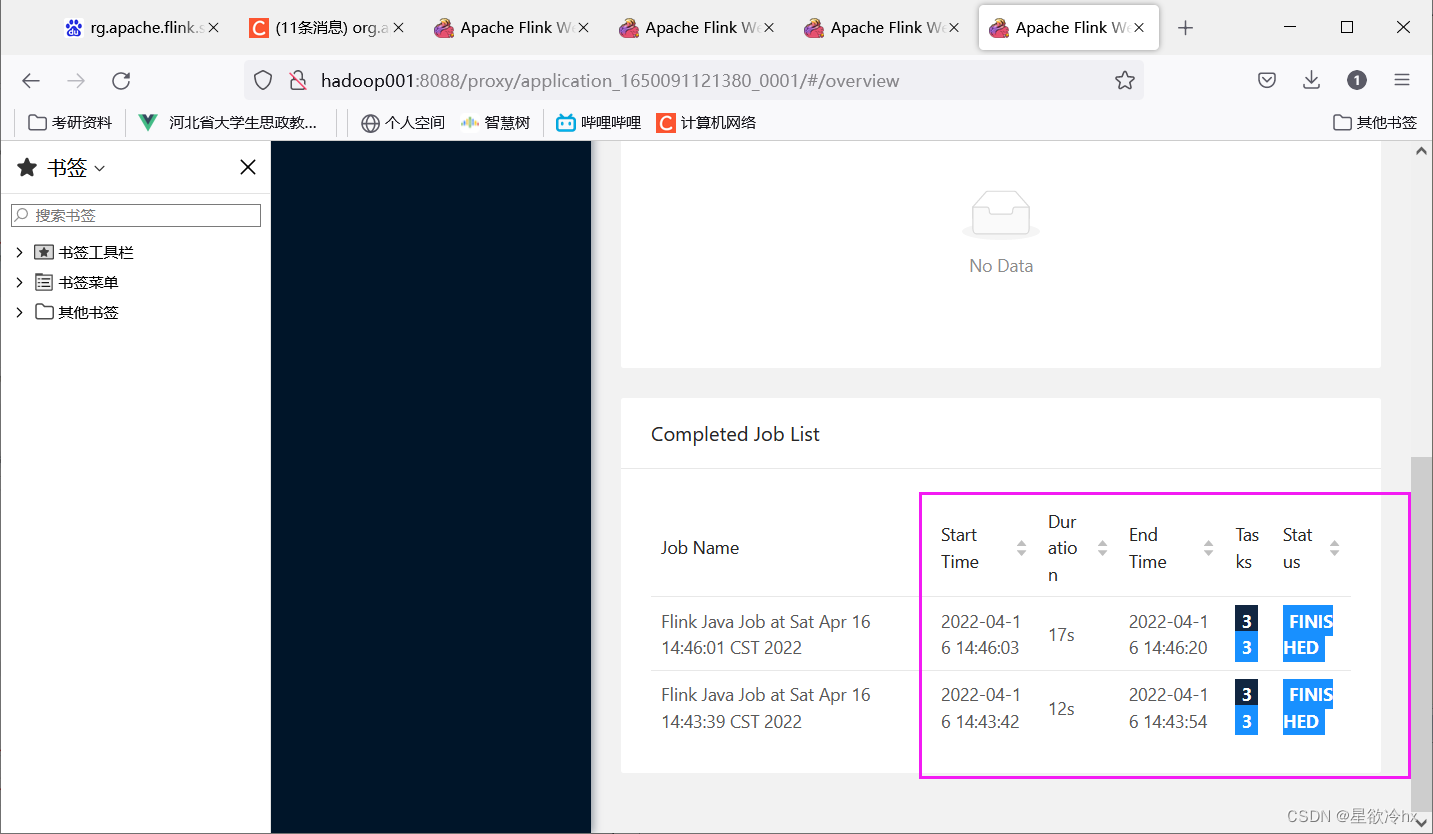
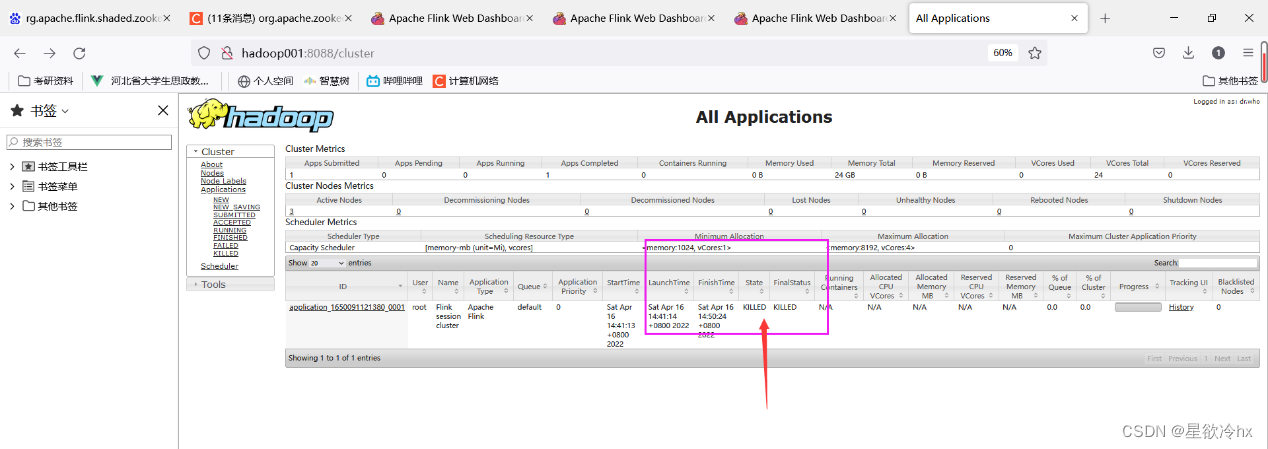
关闭yarn-sesion
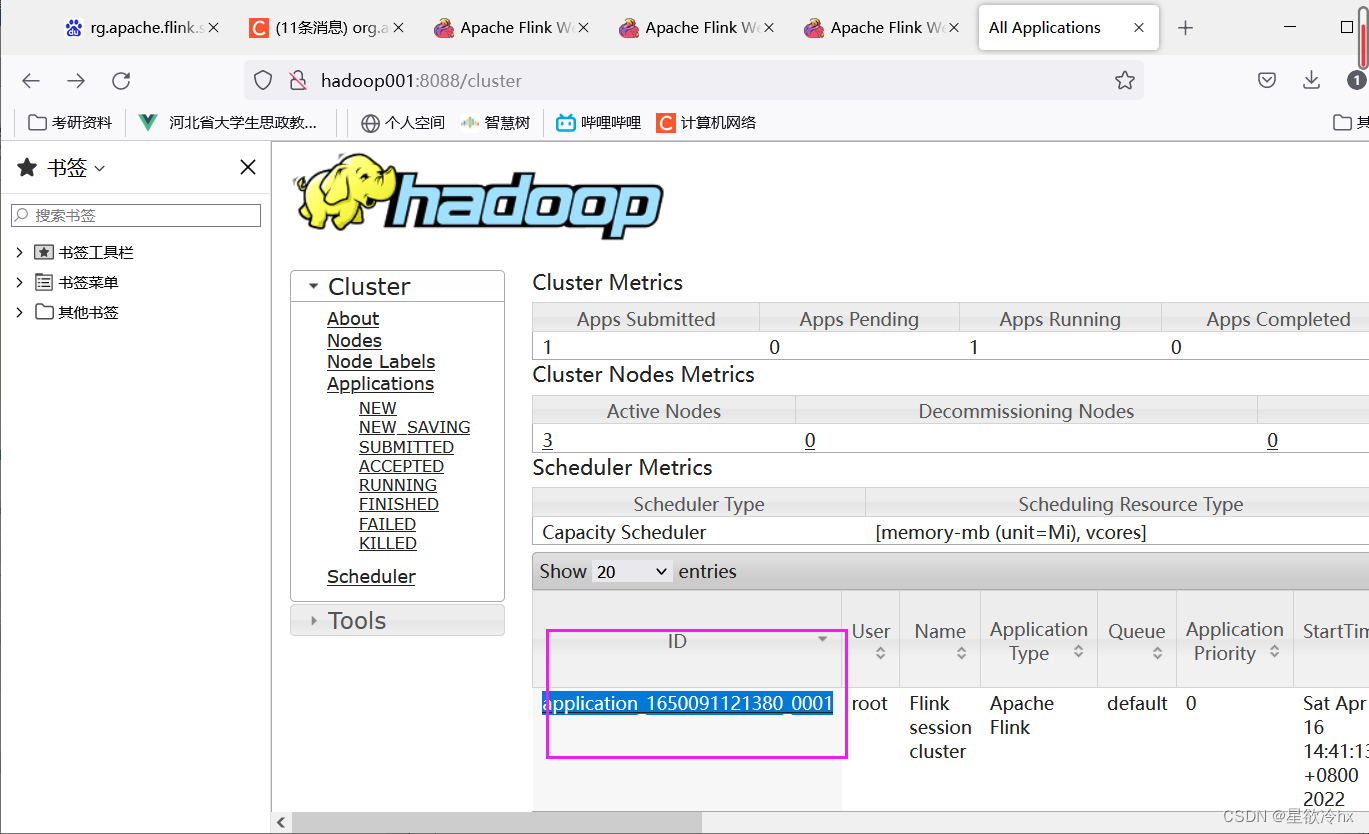
yarn application -kill application_1649658383623_0001

Per-Job模式提交任务
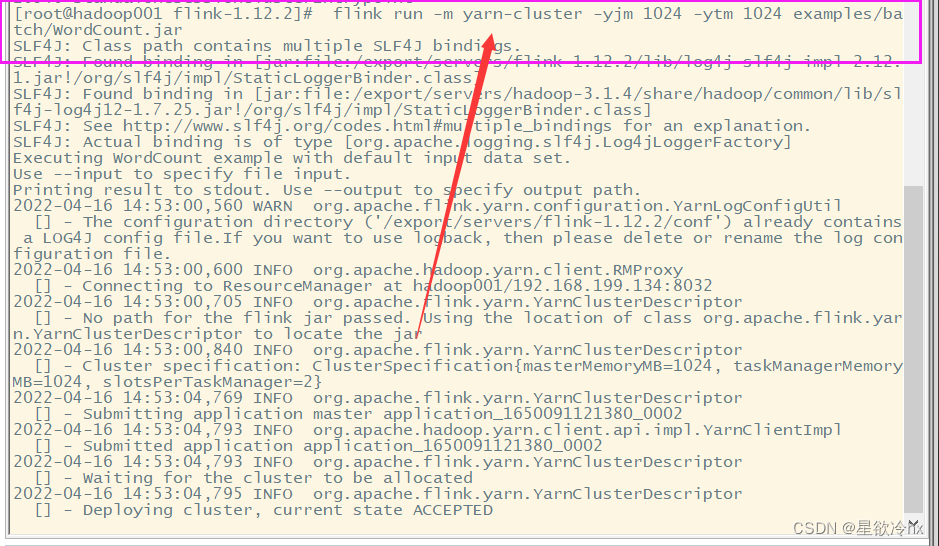
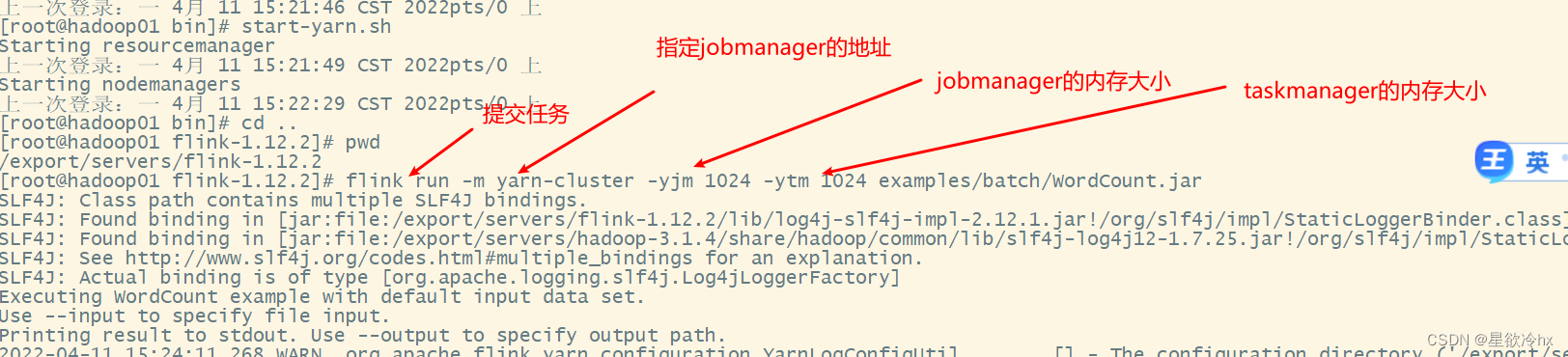
提交任务(job)
flink run -m yarn-cluster -yjm 1024 -ytm 1024 examples/batch/WordCount.jar
-m:jobmanager的地址
-yjm:jobmanager的内存大小
-ytm:taskmanager的内存大小
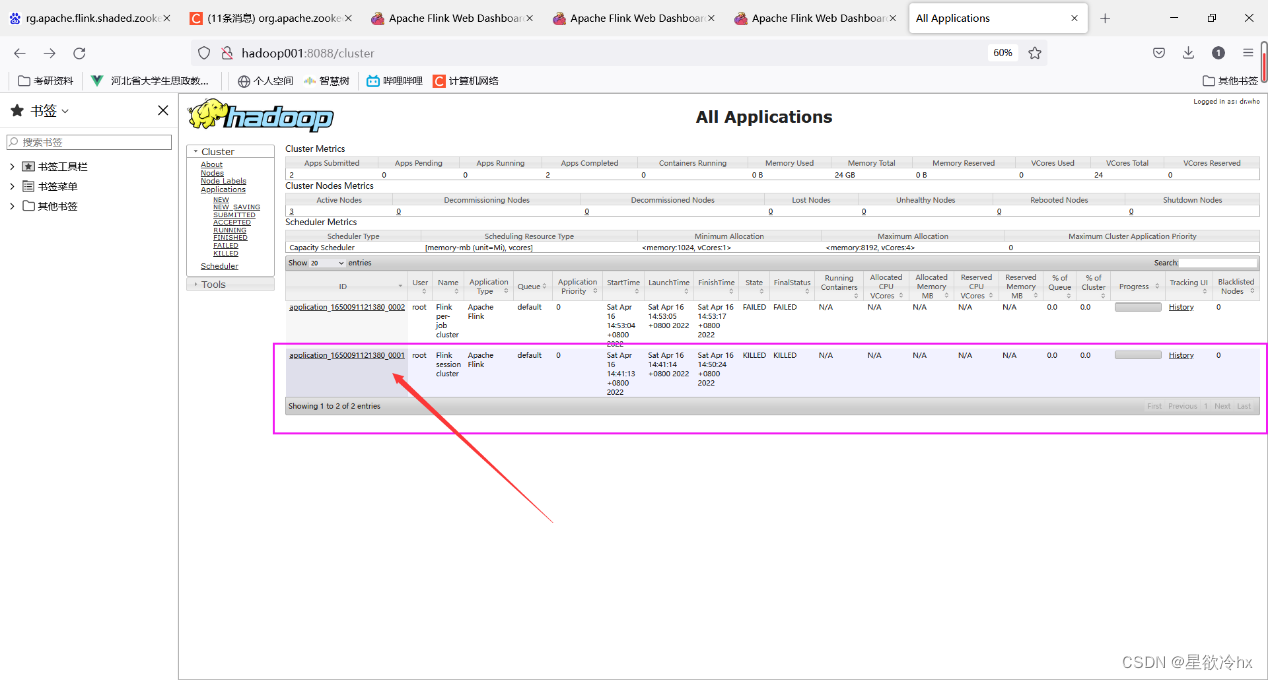
查看yarn的web ui
跟进查看
进程filed了

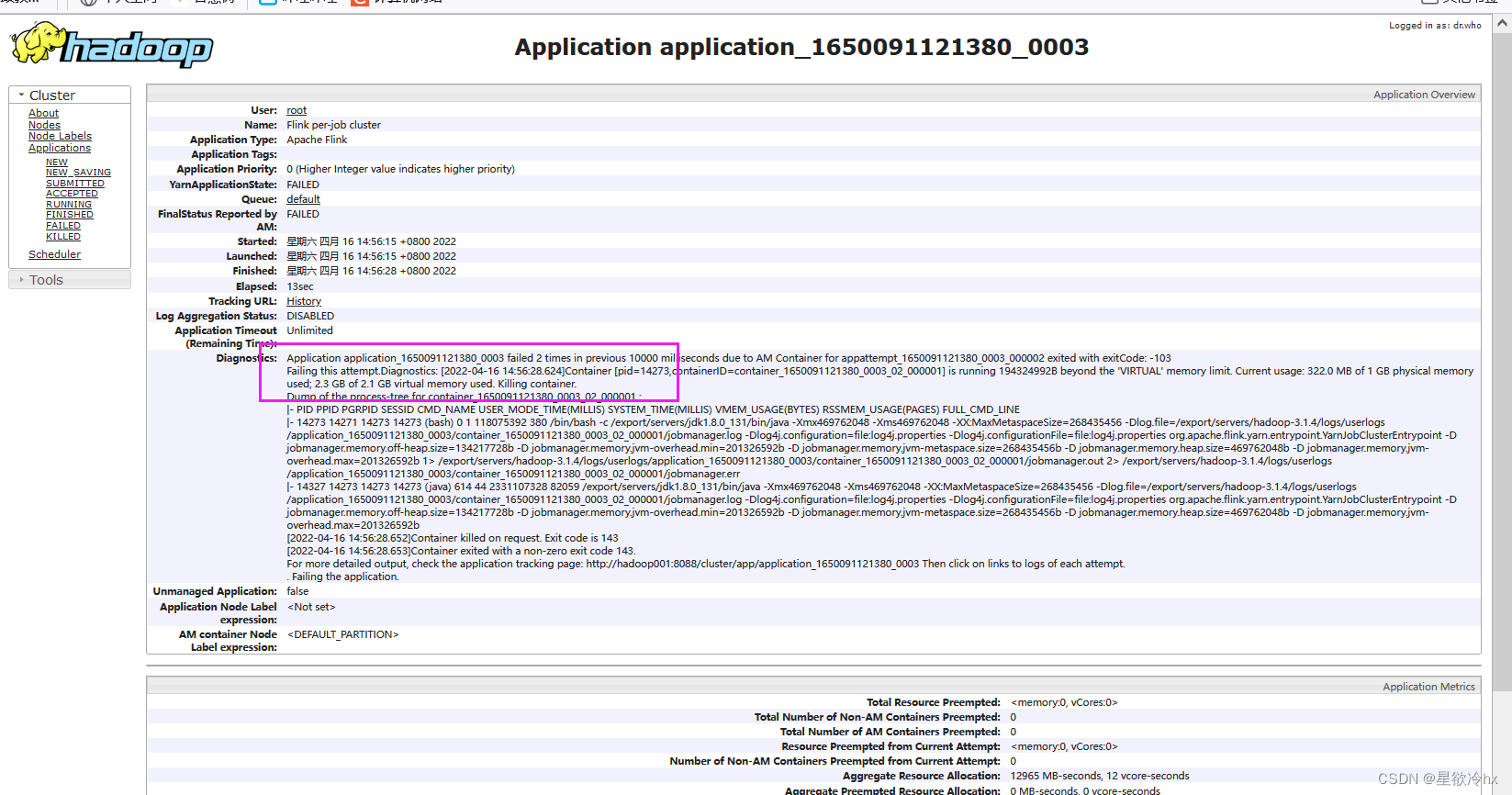
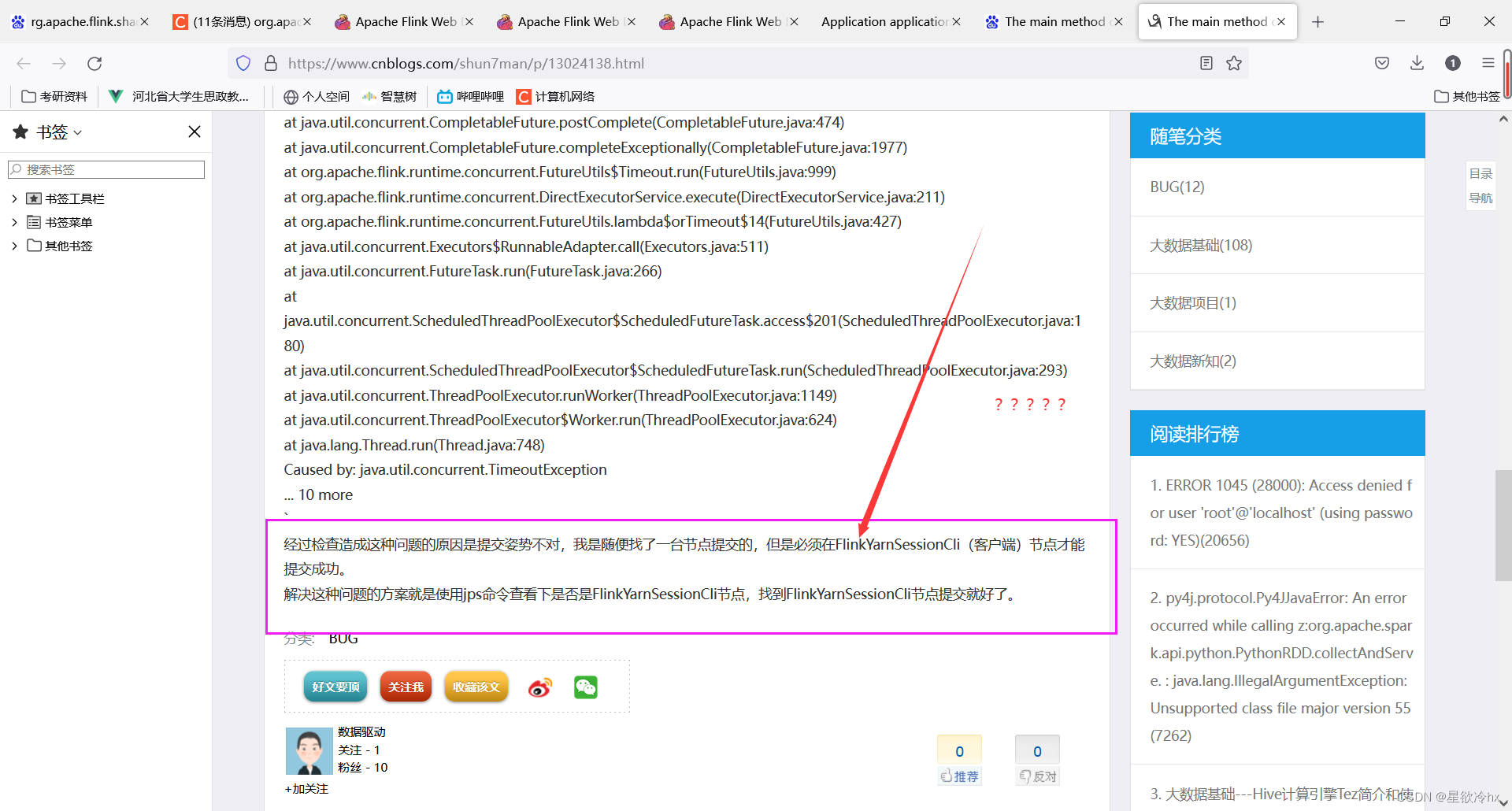
我这才想起来刚才进程已经杀死了
克隆一个起来
这下好了
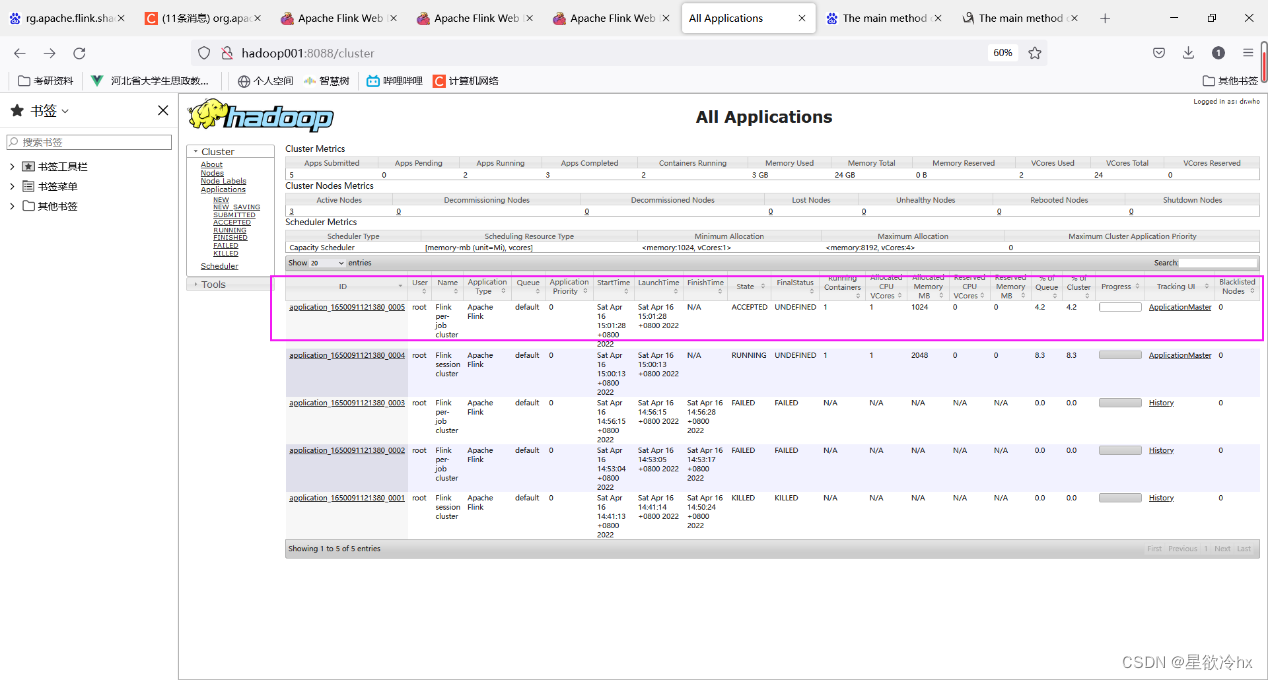
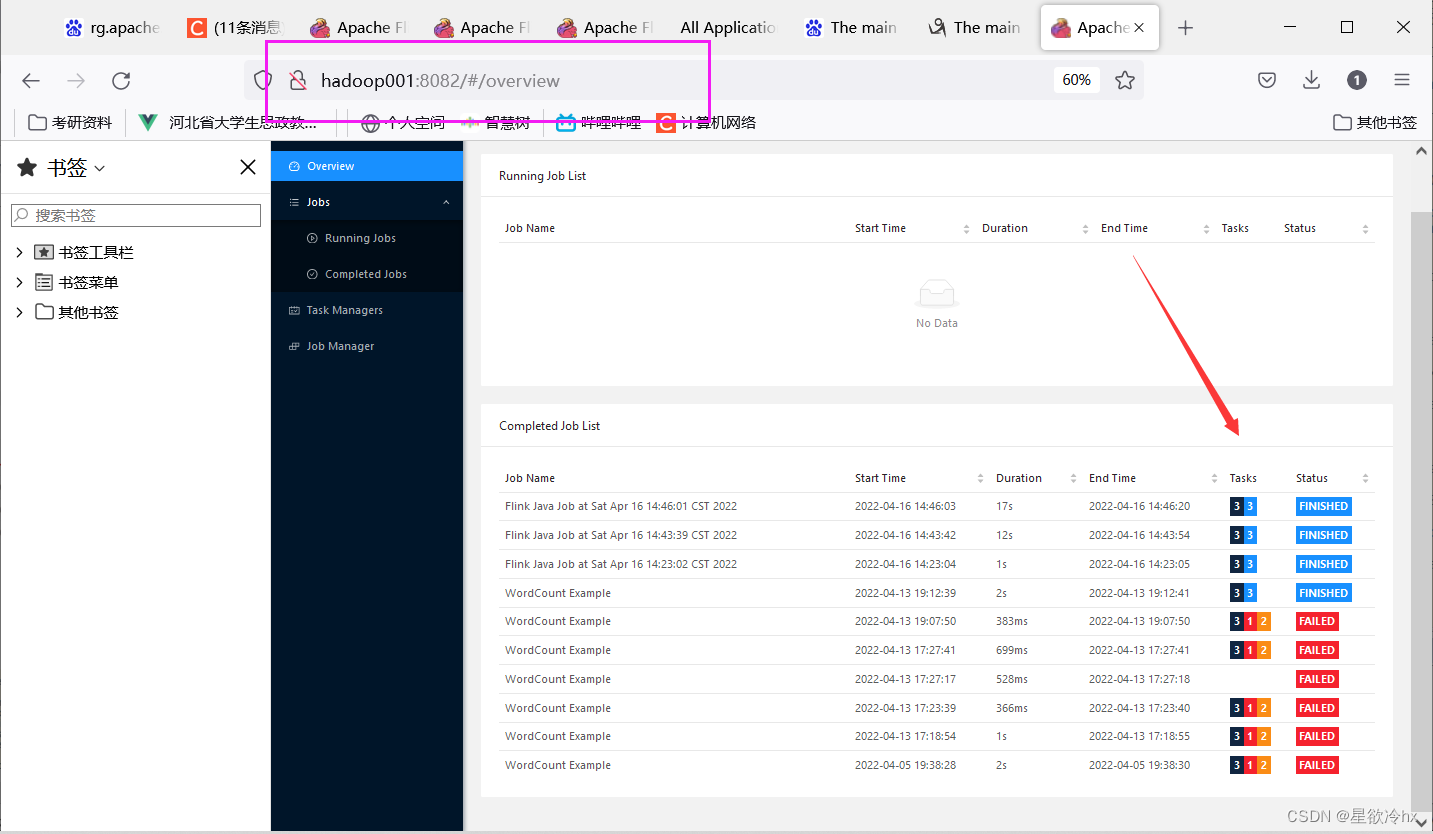
再次提交任务查看yarn的web ui
发现又多了一个任务执行列表
我这里因为错误提交了好几次
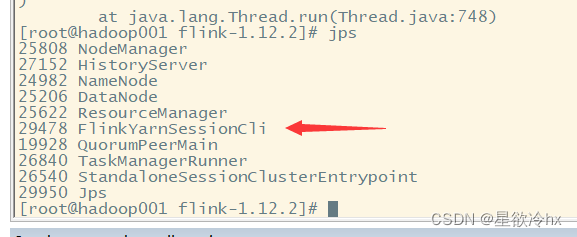
查看jps
发现没有相关的进程,也就是当任务执行完成后,进程自动关闭
有时候有延迟,延迟还很大
flink任务提交参数总结
flink run --help

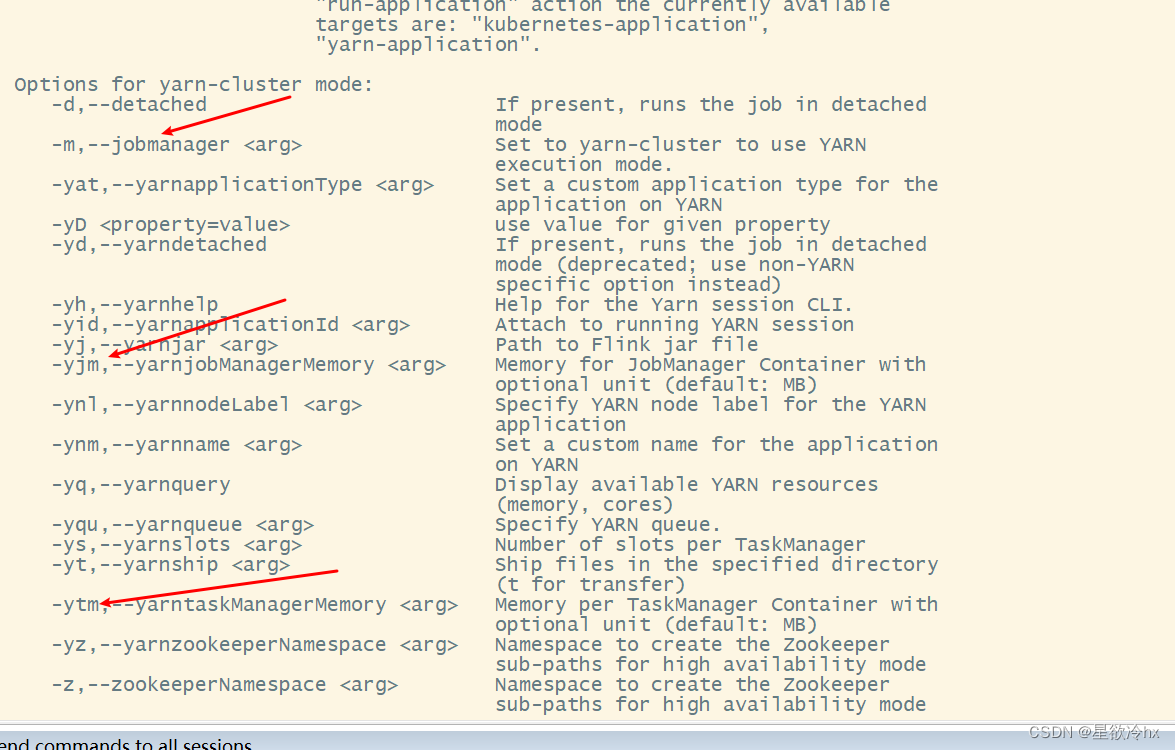
到这里flink的三种模式的安装部署测试与介绍就基本上完成了
flink的环境也搭建起来的,接下来(2)我们要介绍的是flink的入门案例
如遇侵权,请联系删除。
版权归原作者 星欲冷hx 所有, 如有侵权,请联系我们删除。