
最近换了台电脑,之前就电脑上的hadoop集群也用不了了,正好借此机会重新安装一下hadoop。
VMWare安装CentOS7的教程前面发过,可以参考:
VMWare Workstation中安装CentOS7
本节用到的版本如下:
Hadoop:hadoop-3.3.6
JDK:jdk-8u151-linux-x64,
可以去下面网址下载:JDK下载
MySQL:MySQL-server-5.5.48-1.el6.x86_64
目录如下
一、安装JDK和MySQL
1.1 服务器配置
安装JDK之前,需要先对第一台服务器进行设置,一般来讲,部署Hadoop集群会有奇数台,本节用到了3台,并且命名为:
centos1、centos2、centos3
三台服务器,接下来先对第一台服务器进行设置:
1.1.1 修改主机名
我这里是默认的主机名: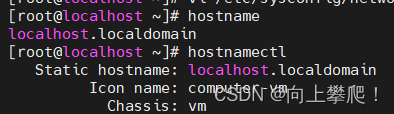
输入命令:
vi /etc/hostname
将本机主机名修改为centos1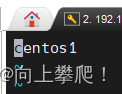
再次查看主机名,发现会改变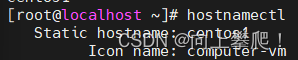
1.1.2 配置IP地址
输入命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
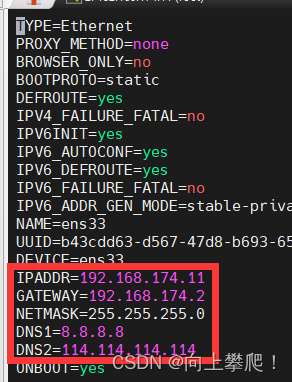
注:这里的IP地址请使用自己的服务器的地址。
然后重启网络服务:
service network restart
1.1.3 关闭网络防火墙
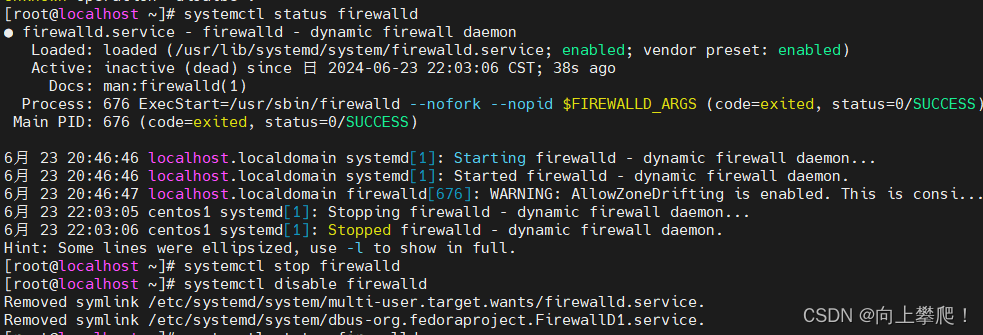
查看当前防火墙状态:
systemctl status firewalld
关闭防火墙:
systemctl stop firewalld
开机自动关闭防火墙:
systemctl disable firewalld
然后重启网络服务:
systemctl restart network
1.1.4 添加内网域名映射
输入命令:
vi /etc/hosts
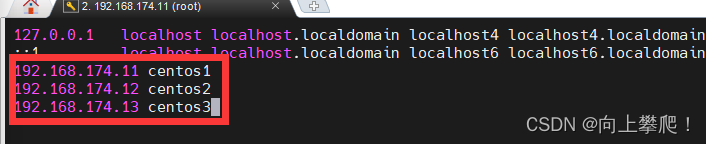
三个地址分别对应自己的三台服务器地址及主机名
1.1.5 同步网络时间
输入命令:
ntpdate cn.pool.ntp.org
发现提示 未找到命令
解决办法:输入命令
yum install ntp
这里可能会提示访问不到外网,具体设置可以参考一下文章:
centos7无法访问外网解决办法
1.2 安装JDK
1.2.1 下载好 jdk-8u151-linux-x64.tar.gz 后,放到服务器上,这里我放的位置是:
/export/software/
目录自己掌握,然后解压
tar-zxvf jdk-8u151-linux-x64.tar.gz -C /export/server
1.2.2 配置环境变量
输入命令:
vi /etc/profile
然后将光标移动到最下面,按i键,进入编辑模式,将以下内容复制到最后面:
注意自己的jdk版本
#set java environment JAVA_HOME=/export/server/jdk1.8.0_151
CLASSPATH=.:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATHexport JAVA_HOME CLASSPATH PATH
然后保存退出
让环境变量生效:
source /etc/profile
检查JDK是否配置完成:
java-version
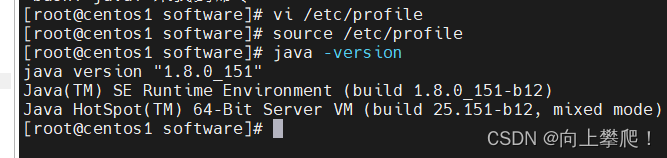
至此,JDK就安装完成了
1.3安装MySQL
1.3.1 先卸载centos7自带的mariadb
先查看mariadb版本:
rpm -qa|grep mariadb
删除对应版本:
rpm-e mariadb-libs-5.5.68-1.el7.x86_64 --nodeps
检查一下是否删除完毕:
rpm -qa|grep mariadb

1.3.2 先创建一个目录:
mkdir /export/software/mysql
1.3.3 下载mysql
MySQL下载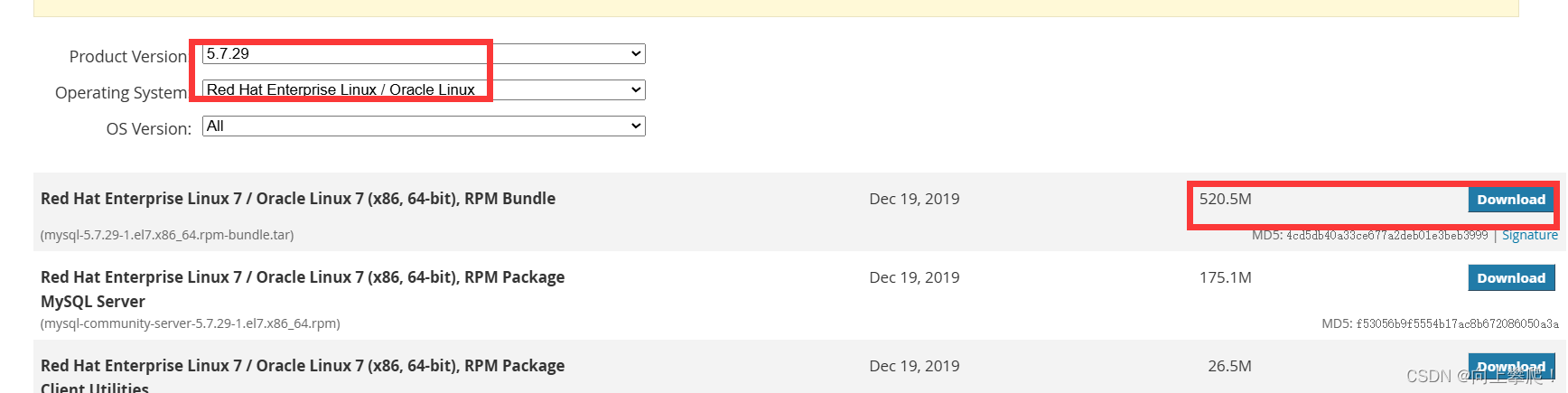
先下载到本地,然后再上传到服务器上
1.3.4 将下载后的mysql上传到
/export/software/mysql
,解压
tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
检查一下依赖:
yum search libaio
yum search perl
yum search net-tools
那个没有就 yun install 它。
然后依次安装下面的:
rpm-ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm
rpm-ivh mysql-community-libs-5.7.29-1.el7.x86_64.rpm
rpm-ivh mysql-community-client-5.7.29-1.el7.x86_64.rpm
rpm-ivh mysql-community-server-5.7.29-1.el7.x86_64.rpm
1.3.5 初始化
mysqld --initialize
1.3.6 更改所属组
chown mysql:mysql /var/lib/mysql -R
1.3.7 启动mysql
systemctl start mysqld.service
注意:如果先启动的话,会报错,需要先更改所属组
1.3.8 修改密码
(1)查看临时生成的密码 :
cat /var/log/mysqld.log
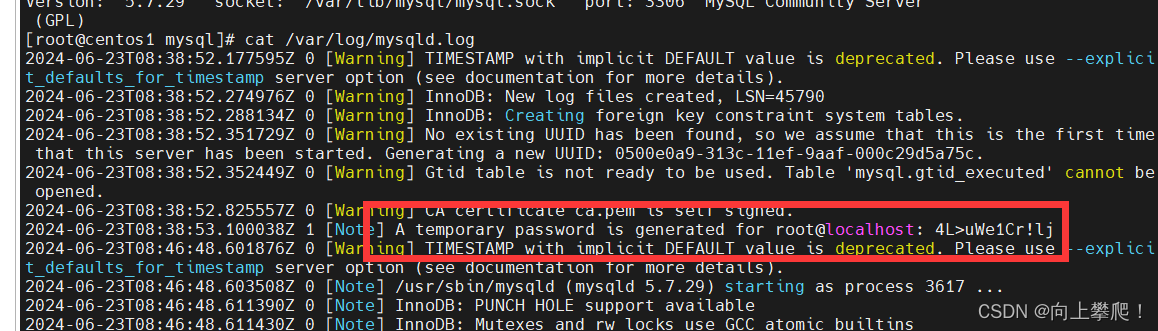
登录:
mysql -u root -p
更改密码:
alter user user() identified by "123456";

授权:
use mysql;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; --开启远程连接
FLUSH PRIVILEGES;exit
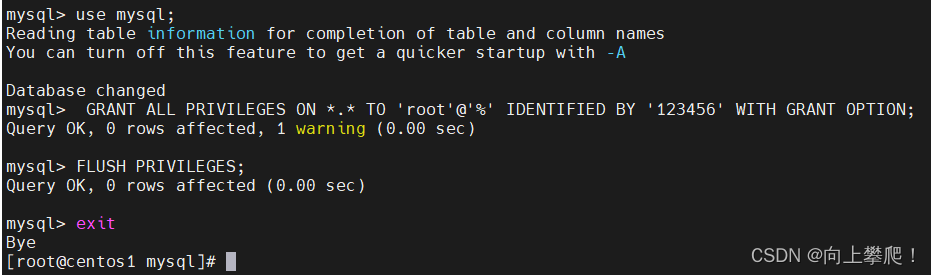
1.3.9 mysql常用的几个命令
systemctl stop mysqld --关闭
systemctl status mysqld --状态
systemctl start mysqld --启动
1.3.10 设置开机自启动
systemctl enable mysqld
systemctl list-unit-files |grep mysqld

至此,服务器上已成功安装了mysql。
二、克隆虚拟机
2.1 克隆虚拟机
这里我们将centos1虚拟机克隆两份,需要先将虚拟机关机,右键单击虚拟机名称 centos1,找到 管理,再选择 克隆
然周直接点下一步

修改虚拟机名称以及存放位置

需要克隆两台虚拟机。
2.2 虚拟机配置
修改centos2和centos3虚拟机的主机名、ip地址等
2.2.1 修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
将IPADDR修改为192.168.174.12
同理,centos3也需要修改为192.168.174.13,
然后重启网络服务:
systemctl restart network
2.2.2 修改主机名
vi /etc/hostname
分别修改主机名为:centos2 centos3
2.3 配置免密登录
2.3.1 分别在三台服务器输入以下命令,连续按回车即可:
ssh-keygen -t rsa

2.3.2 配置免密
# 在centos1输入下面两条命令,输入yes即可
ssh-copy-id centos2
ssh-copy-id centos3
# 同理,需要在另外两台服务器分别配置
2.3.4 验证免密登录
分别在centos1中执行以下命令
ssh centos2
ssh centos3

至此,ssh免密登录配置完成。
三、安装Hadoop
为了后续安装的方便,防止出现问题等,切换一个新的用户
adduser hadoop1
passwd hadoop1
我这里切换了一个新的用户,名字为hadoop1
3.1 安装Hadoop
3.1.1 下载
我这里下载的是3.3.6版本:
Hadoop3.3.6下载
3.1.2
在/目录下新建一个目录,名字为:hadoops,将上面下载好的hadoop压缩包上传到该目录下
并解压
tar-zxvf hadoop-3.3.6-aarch64.tar.gz /hadoops
3.2 配置文件以及环境变量
(1) 配置环境变量 hadoop-env.sh
vi /hadoops/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
只需要将JDK的路径配置进去即可:
exportJAVA_HOME=/export/server/jdk1.8.0_151
然后再最后加上:
exportHDFS_NAMENODE_USER=root
exportHDFS_DATANODE_USER=root
exportHDFS_SECONDARYNAMENODE_USER=root
exportYARN_RESOURCEMANAGER_USER=root
exportYARN_NODEMANAGER_USER=root
(2)配置核心组件 core-site.xml
vi /hadoops/hadoop-3.3.6/etc/hadoop/core-site.xml
找到,将下面代码添加进去:
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --><property><name>fs.defaultFS</name><value>hdfs://centos1:9000</value></property><!-- 设置Hadoop本地保存数据路径 --><property><name>hadoop.tmp.dir</name><value>/export/data/hadoop-3.3.6</value></property><!-- 设置HDFS web UI用户身份 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 整合hive 用户代理设置 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>

(3)配置文件系统hdfs-site.xml
vi /hadoops/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
找到,将下面代码添加进去:
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>/home/hadoop1/hadoopData/name</value></property><property><name>dfs.datanode.data.dir</name><value>/home/hadoop1/hadoopData/data</value></property></configuration>

(4)配置计算框架 mapred-site.xml
vi /hadoops/hadoop-3.3.6/etc/hadoop/mapred-site.xml
找到,将下面代码添加进去:
<property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- MR程序历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>centos1:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>centos1:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>

(5)配置文件系统 yarn-site.xml
vi /hadoops/hadoop-3.3.6/etc/hadoop/yarn-site.xml
找到,将下面代码添加进去:
<property><name>yarn.resourcemanager.hostname</name><value>centos1</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>

(6)配置workers文件
添加(修改)内容为:
centos1
centos2
centos3
这是最一开始配置的三台服务器的名称
(7) 配置环境变量路径
vi /hadoops/hadoop-3.3.6/etc/profile
配置你的JDK路径以及hadoop路径
exportJAVA_HOME=/export/server/jdk1.8.0_151
exportHADOOP_HOME=/hadoops/hadoop-3.3.6
exportPATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin

然后将profile文件分别拷贝到另外两台服务器,并且执行source生效
(8)将centos1编辑好的配置文件都拷贝到另外两台服务器
scp-r /hadoops/hadoop-3.3.6/etc/hadoop/ hadoop@centos2:/hadoops/hadoop-3.3.6/etc/
scp-r /hadoops/hadoop-3.3.6/etc/hadoop/ hadoop@centos3:/hadoops/hadoop-3.3.6/etc/
四、启动Hadoop集群
4.1 集群初始化
hadoop namenode -format


4.2 启动hadoop集群
进入目录:
/hadoops/hadoop-3.3.6/sbin/
4.2.1 启动yarn
start-yarn.sh

4.2.2 启动HDFS
start-dfs.sh

4.3 验证
分别在三台服务器输入命令:
jps
centos1:
centos2:
centos3:
至此 hadoop集群已成功启动。
4.4 在本地windows浏览器查看管理页面
管理页面网址一般是 http://+你的节点的网址+:8088,
例如我的就是:
http://192.168.19.11:8088

4.5 关闭集群
4.5.1 关闭集群服务需要在主节点上进行,也就是centos1
**注意:需要先关闭hdfs,再关闭yarn
(1)关闭hdfs:
stop-dfs.sh
(2)关闭yarn:
stop-yarn.sh

此时可以看到jps后其他服务都消失了,证明集群服务已成功关闭。
五、安装Hive
5.1 安装Hive
hive版本用的是3.1,下载地址:hive3.1.3
选择第一个即可,下载到本地
在目录
/export/software/
下面放进hive压缩包,解压
cd /export/software/
tar-zxvf apache-hive-3.1.3-bin.tar.gz
```### 5.2 配置文件以及环境变量(1) 配置 hive-env.sh文件
```bash
cd /export/software/apache-hive-3.1.3-bin/conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
添加以下内容:
exportHADOOP_HOME=/hadoops/hadoop-3.3.6
exportHIVE_CONF_DIR=/export/software/apache-hive-3.1.3-bin/conf
exportHIVE_AUX_JARS_PATH=/export/software/apache-hive-3.1.3-bin/lib

(2)配置 hive-site.xml 文件
没有这个文件就创建
vim hive-site.xml
添加以下内容:
<configuration><!-- 存储元数据mysql相关配置 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://centos1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- H2S运行绑定host --><property><name>hive.server2.thrift.bind.host</name><value>centos1</value></property><!-- 远程模式部署metastore metastore地址 --><property><name>hive.metastore.uris</name><value>thrift://centos1:9083</value></property><!-- 关闭元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property></configuration>

(4)将mysql的驱动包上传到hive安装目录lib下面
下载网址: mysql-connector-java
(5)配置环境变量
vim ~/.bashrc
添加下面内容:
exportHIVE_HOME=/export/software/apache-hive-3.1.3-bin
exportPATH=$PATH:$HIVE_HOME/bin
让配置文件生效:
source ~/.bashrc
5.3 元数据库初始化
进入目录:
/export/software/apache-hive-3.1.3-bin/bin/
执行命令:
schematool -dbType mysql -initSchema

验证hive:
hive--help

至此,hive3.1.3安装成功。
5.4 启动hive
5.4.1 启动 metastore服务
进入目录:
/export/software/apache-hive-3.1.3-bin/bin/
执行命令:
hive --service metastore

**注意,启动后,这个页面就会保持不动,这时候要新开一个链接页面去操作
5.4.2 启动 hiveserver2 服务
进入目录:
/export/software/apache-hive-3.1.3-bin/bin/
执行命令:
hive --service hiveserver2 &

**注意,hiveserver2启动时间比较长,不要立即beeline连接,很可能会失败。
5.4.3 检查一下是否成功启动
执行命令
jps

5.4.4 启动beeline
进入目录:
/export/software/apache-hive-3.1.3-bin/bin/
执行命令:
beeline

输入:
! connect jdbc:hive2://centos1:10000
继续输入用户名,也就是安装hive的用户名:centos1
回车
六、DBeaver连接hive
6.1 安装dbeaver
下载网址
6.2 连接hive


注意,主机这里要写你的主节点的ip地址,端口的话需要看你hive-site.xml里配置的是哪个就写那个,我这里写的是20000,然后用户名密码就是你当前主机的用户名和密码
然后点击测试链接,连接成功,就可,接下来就可以操作hive了。
版权归原作者 清徐柳 所有, 如有侵权,请联系我们删除。