
云计算与大数据——部署Kubernetes集群+完成nginx部署(超级详细!)
部署 Kubernetes 集群的基本思路如下:
- 准备环境:- 选择适合的操作系统:根据需求选择适合的 Linux 发行版作为操作系统,并确保在所有节点上进行相同的选择。- 安装 Docker:在所有节点上安装 Docker,它将用于容器化应用程序和组件。- 安装 Kubernetes 工具:安装
kubectl、kubeadm和kubelet工具,这些工具将用于集群的管理和配置。 - 设置主节点 (Master Node):- 选择一个节点作为主节点:通常是从节点中选择一台作为主节点,可以是任意一台具备足够资源的机器。- 初始化主节点:使用
kubeadm init命令初始化主节点,并获取生成的加入令牌 (join token)。- 设置网络插件:选择并安装适当的网络插件,例如 Flannel、Calico 或 Weave,以便节点之间能够进行网络通信。 - 添加从节点 (Worker Nodes):- 在每个从节点上运行加入命令:使用之前生成的加入令牌,在每个从节点上运行
kubeadm join命令,将其加入到集群中。- 确认节点加入:在主节点上运行kubectl get nodes命令,确保所有节点都成功加入集群。 - 部署网络插件:- 根据选定的网络插件,按照其特定的部署和配置方式进行操作。这将确保各节点之间可以进行网络通信,并提供 Kubernetes 集群的网络功能。
- 部署其他组件和应用程序:- 部署其他所需的核心组件,如 kube-proxy 和 kube-dns/coredns。- 部署您的应用程序或服务,可以使用 Kubernetes 的 Deployment、Service 或其他资源类型来管理它们。
- 验证集群状态:- 运行
kubectl get nodes和其他kubectl命令,以确保集群中的节点和组件正常工作。- 测试应用程序:在集群中部署的应用程序上运行测试,确保它们能够正常运行并与其他组件交互。
以上是部署 Kubernetes 集群的基本思路。具体的步骤和细节可能会因环境和需求而有所不同,但这个简要说明可以帮助您了解部署过程的大致流程。
接下来我们进行实操部署kubernetes集群和完成nginx服务。
开始部署Kubernetes集群
以下以root登录运行命令:
一、在所有节点安装和配置docker
1.安装docker所需的工具
yum install-y yum-utils device-mapper-persistent-data lvm2

2.配置阿里云的docker源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo

3.安装docker-ce、docker-ce-cli、containerd.io
yum install-y docker-ce docker-ce-cli containerd.io
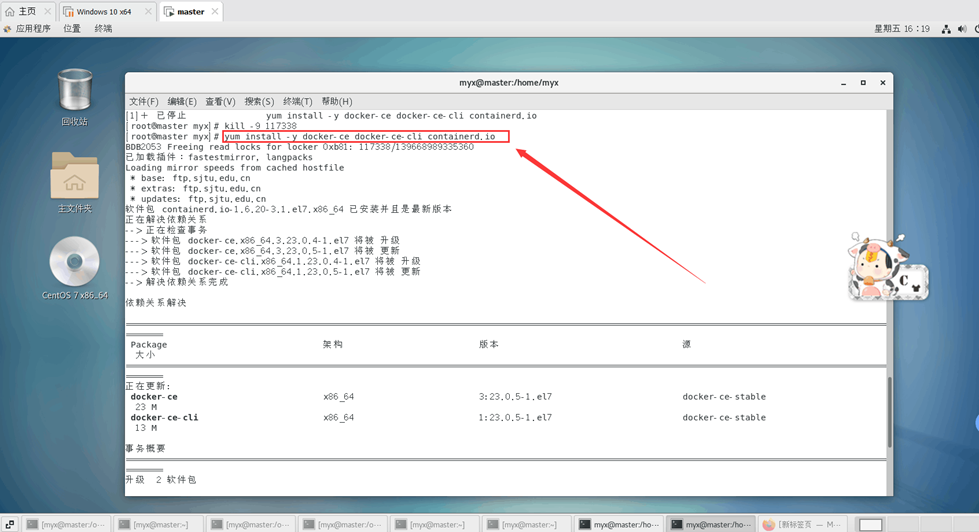
4.启动docker
systemctl enabledocker#设置开机自启
systemctl start docker#启动docker
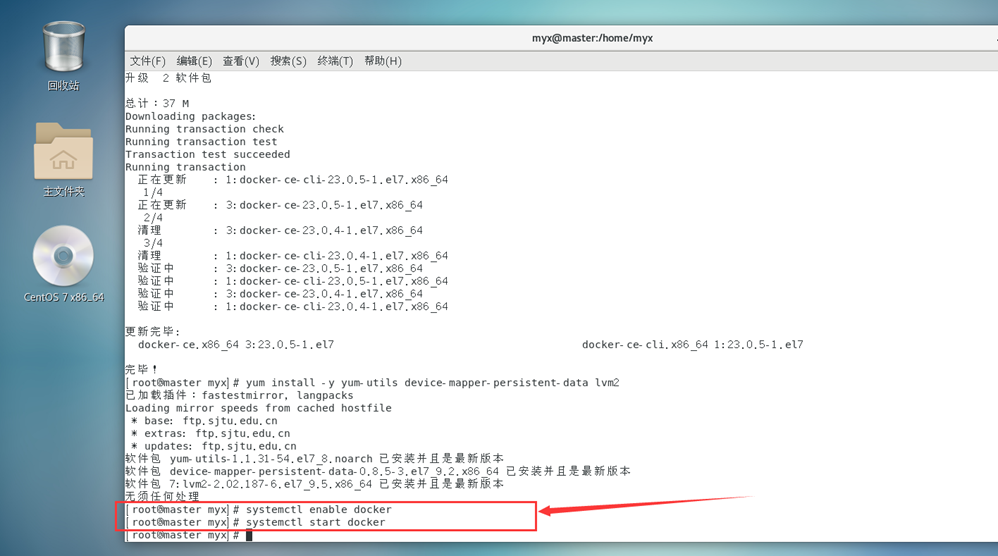
5. 设置镜像加速器
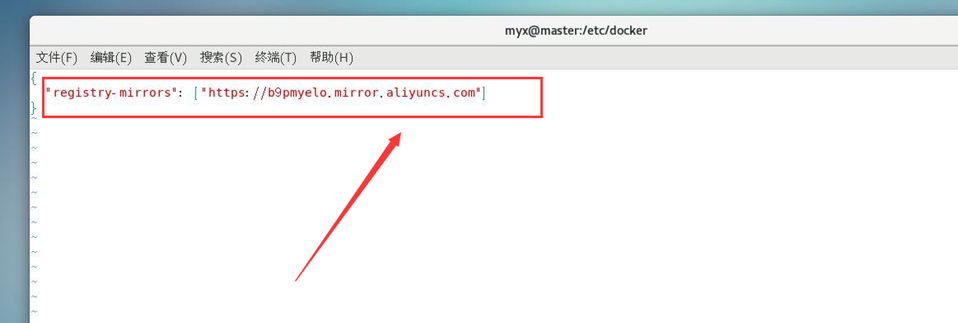
#设置镜像加速器,新建daemon.json文件(参考文献1)
cat<<EOF > /etc/docker/daemon.json
{"registry-mirrors":["https://b9pmyelo.mirror.aliyuncs.com"]}
6.生成并修改containerd 的默认配置文件/etc/containerd/config.toml(参考文献2)
containerd config default > /etc/containerd/config.toml


将sandbox_image = “registry.k8s.io/pause:3.6”
修改为sandbox_image = “k8simage/pause:3.6”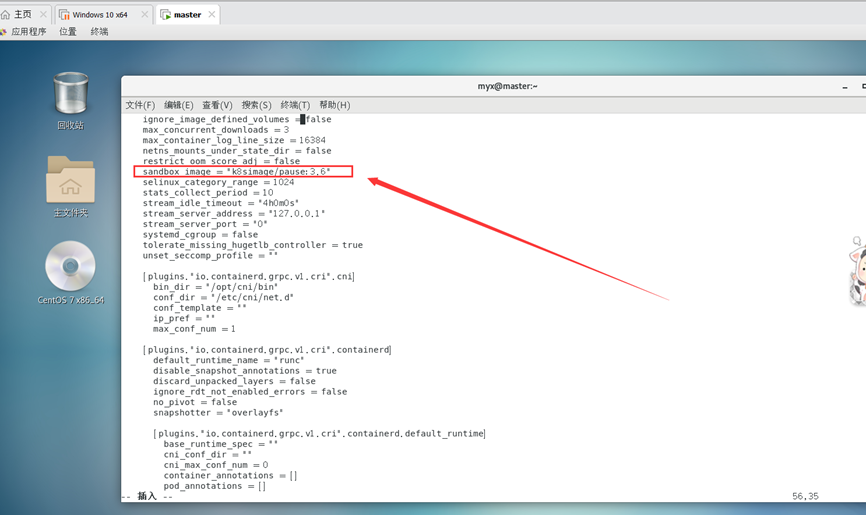

重启 containerd 服务
systemctl daemon-reload
systemctl restart containerd.service

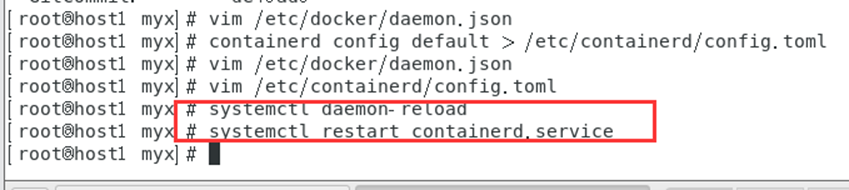
注:此步骤可以解决failed to pull image \“registry.k8s.io/pause:3.6\”; Failed to create sandbox for pod :拉取 registry.k8s.io/pause:3.6 镜像等问题(具体错误问题可以通过运行以下命令查看日志:journalctl -xeu kubelet)
7.关闭防火墙
systemctl disable firewalld
systemctl stop firewalld


8.关闭selinux
#临时禁用selinux
setenforce 0
#或永久关闭,修改/etc/sysconfig/selinux文件设置
sed-i's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux

sed -i ‘s/SELINUX=enforcing/SELINUX=disabled/g’ /etc/selinux/config
9.禁用交换分区
swapoff -a
#或永久禁用,注释掉/etc/fstab文件swap那一行
sed-i ‘s/.*swap.*/#&/’ /etc/fstab


10.修改内核参数
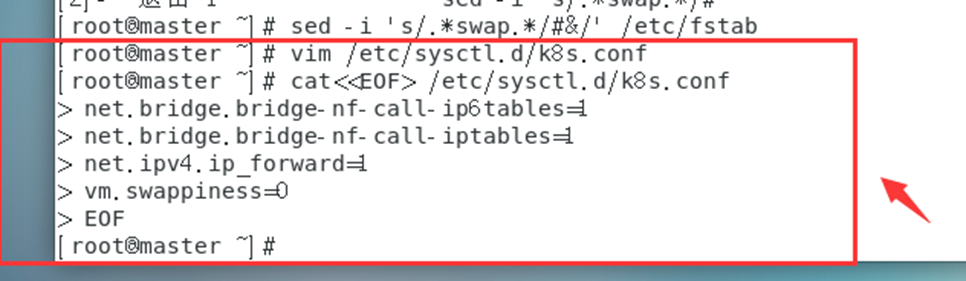
将桥接的IPv4流量传递到iptables的链(有一些ipv4的流量不能走iptables链,因为linux内核的一个过滤器,每个流量都会经过他,然后再匹配是否可进入当前应用进程去处理,所以会导致流量丢失),配置k8s.conf文件(k8s.conf文件原来不存在,需要自己创建的)
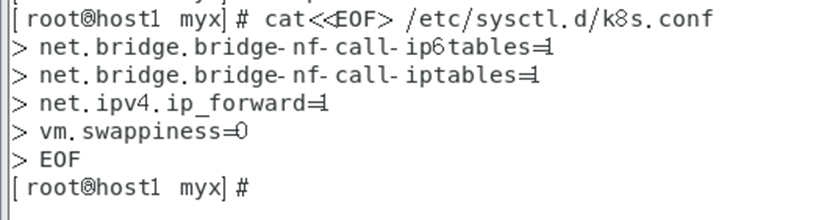
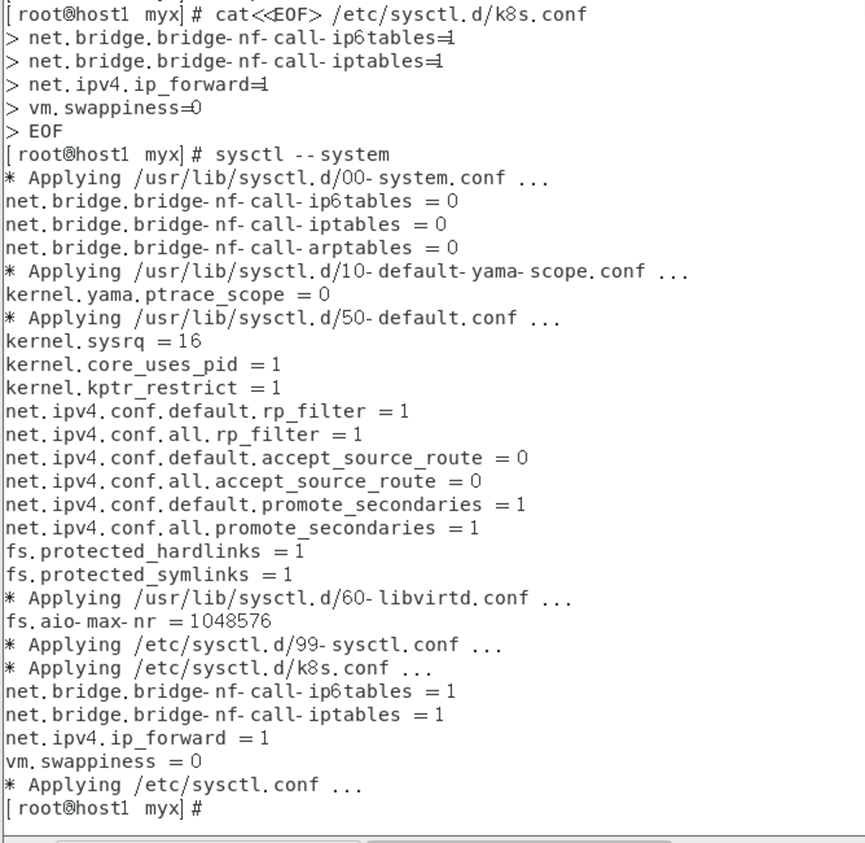
cat<<EOF> /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1net.ipv4.ip_forward=1vm.swappiness=0
EOF
sysctl--system
#重新加载系统全部参数,或者使用sysctl -p亦可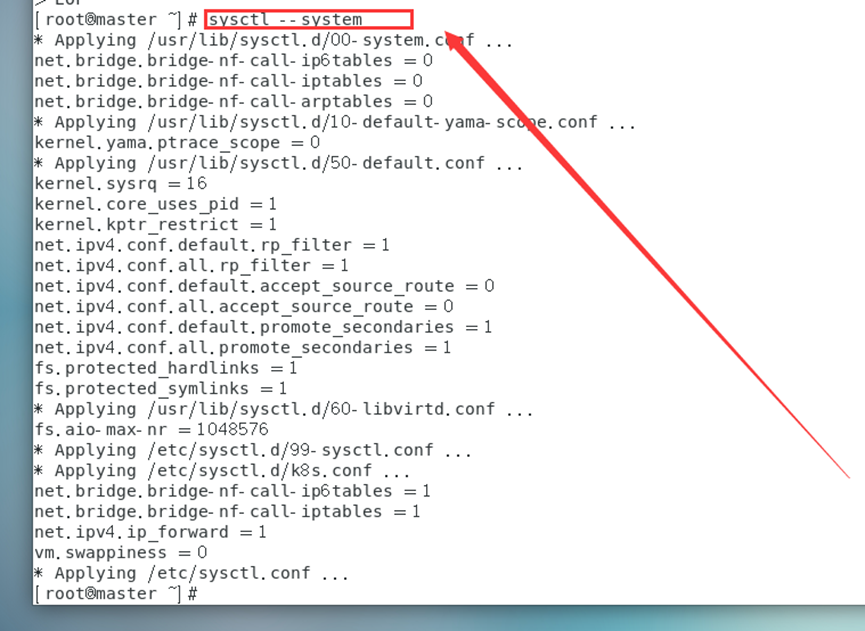
文献1:https://yebd1h.smartapps.cn/pages/blog/index?blogId=123605246&_swebfr=1&_swebFromHost=bdlite
二、在全部节点(个别单独说明的除外)上安装配置Kubernetes
1.配置Kubernetes阿里云源
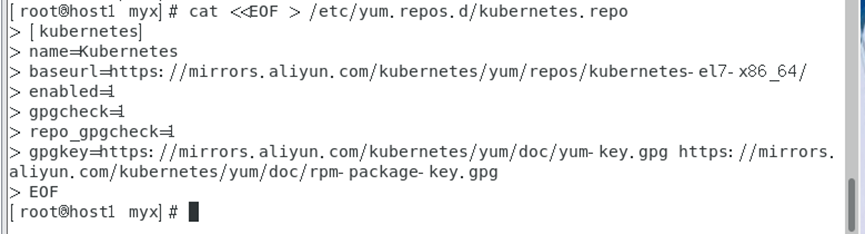
cat<<EOF> /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF

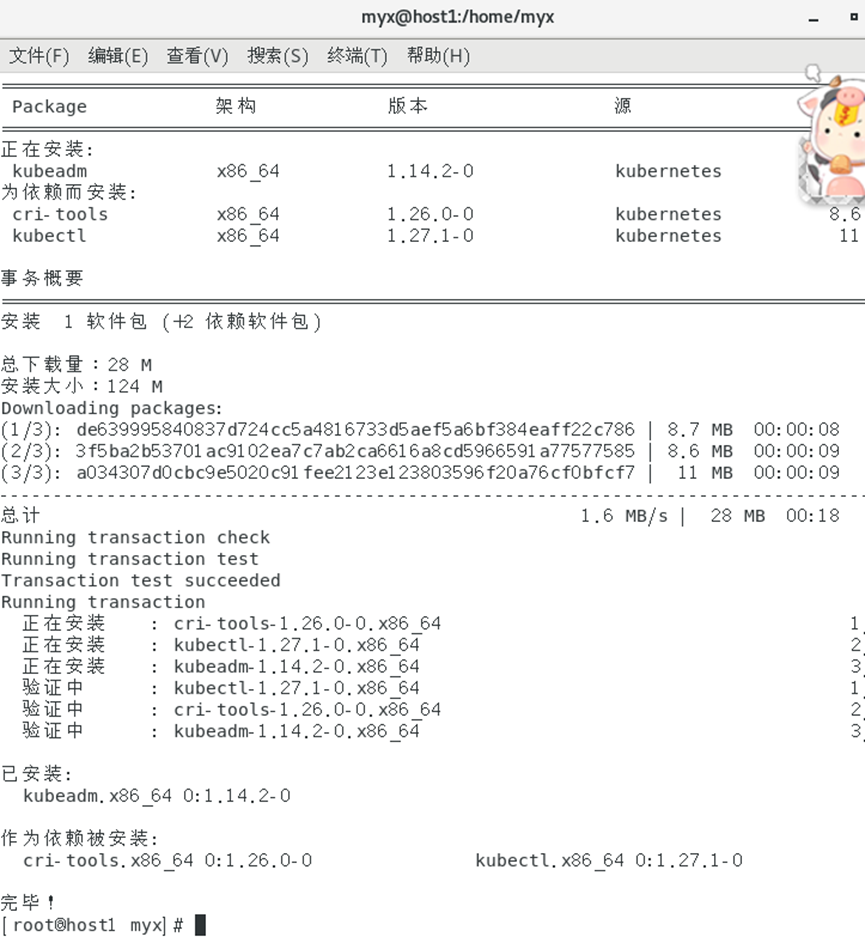
2.安装kubeadm、kubectl、kubelet(kubeadm和kubectl都是工具,kubelet才是系统服务,参考文献1)
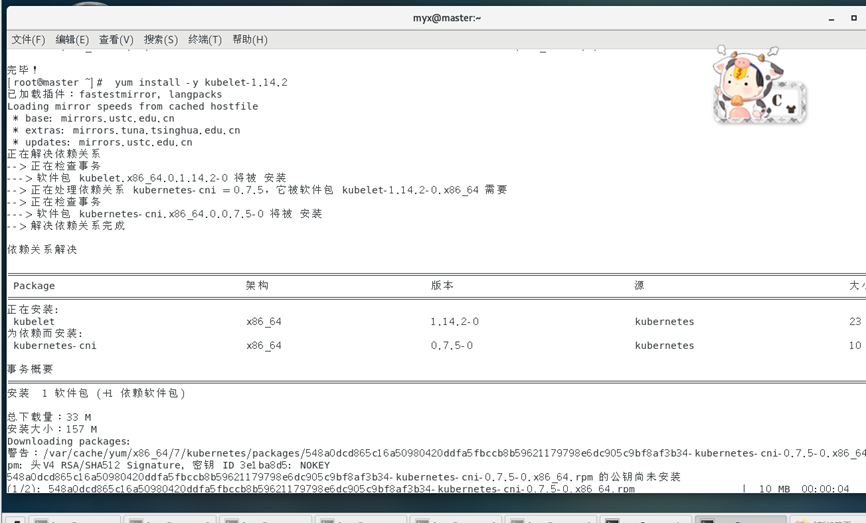
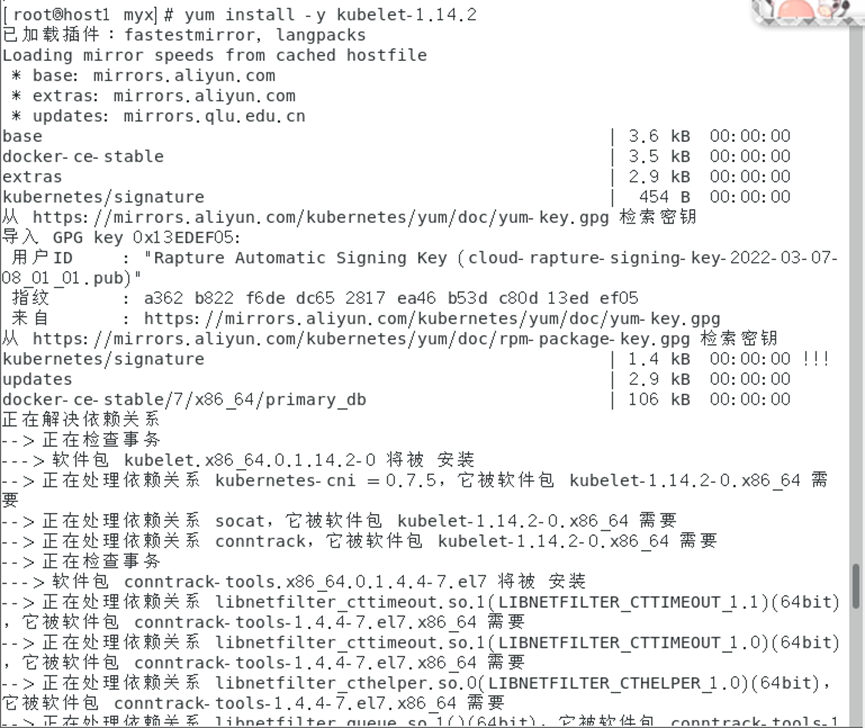
yum install-y kubelet-1.14.2
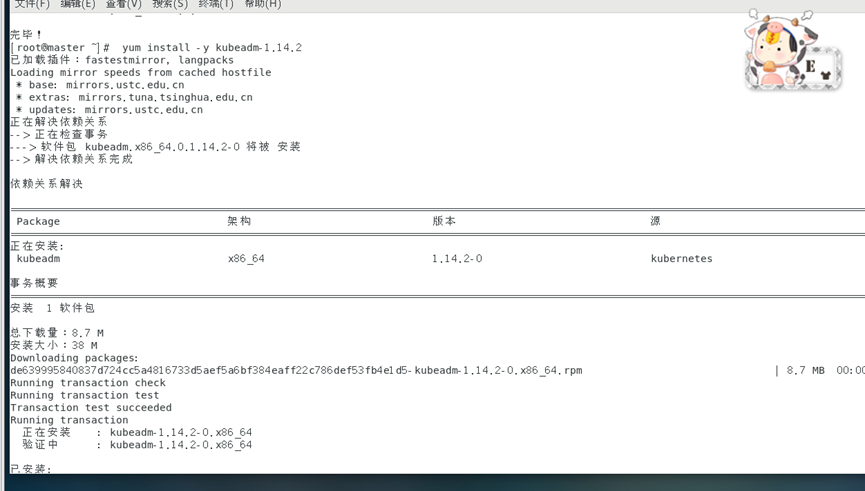
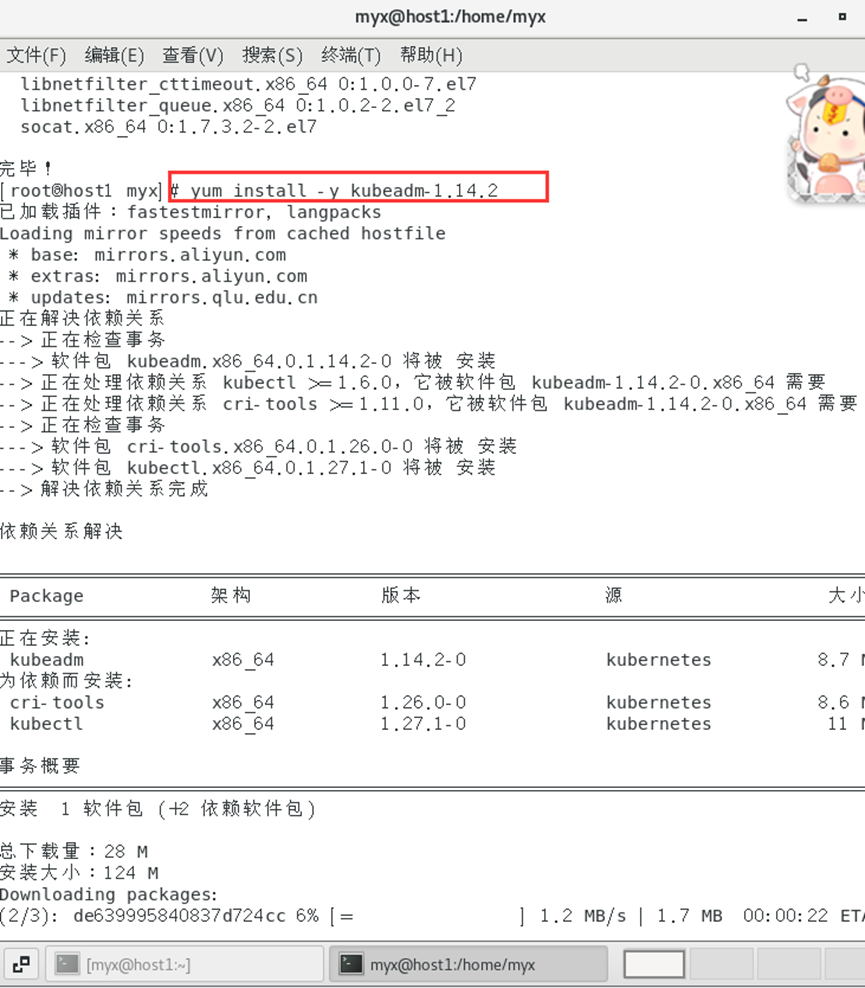
yum install-y kubeadm-1.14.2
3.启动kubelet服务
systemctl enable kubelet && systemctl start kubelet


4. 生成当前版本的初始化配置文件到 /etc/kubernetes 目录下
kubeadm config print init-defaults > /etc/kubernetes/init-default.yaml

1)指定kube-apiserver广播给其他组件的IP地址
这个参数需要设置为主节点的IP地址,以确保其他节点可以访问到kube-apiserver
即:advertiseAddress: 1.2.3.4 -> advertiseAddress: [宿主机ip(内网)]
此项根据自己主节点的IP地址具体设定,本机设置的是:
advertiseAddress:192.168.95.20
2)指定安装镜像的仓库源
建议使用国内镜像如阿里云:
imageRepository: registry.aliyuncs.com/google_containers
注:我们开始会遇到以下初始化问题:
failed to pull image registry.k8s.io/kube-apiserver:v1.26.3
此设置结合kubeadm init命令的以下参数可以解决该问题:
--image-repository=registry.aliyuncs.com/google_containers
即初始化时:kubeadm init --image-repository=registry.aliyuncs.com/google_containers
初始化在后面
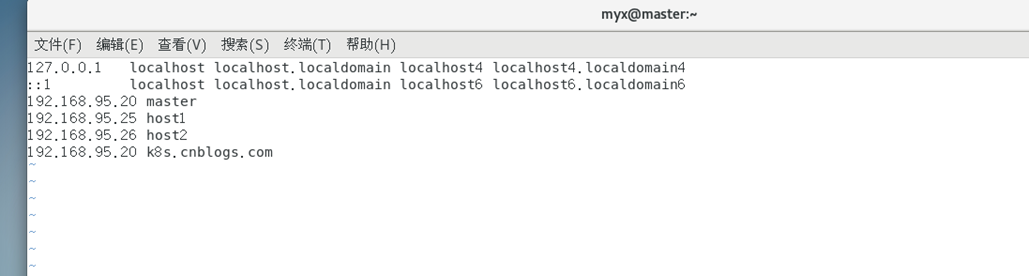
3)编辑/etc/hosts,添加一行:
192.168.95.20 k8s.cnblogs.com #需根据自己主机的IP地址进行修改
总体上第4步可以解决[kubelet-check] Initial timeout of 40s passed.这个复杂问题。
参考文献2:
https://blog.csdn.net/weixin_52156647/article/details/129765134
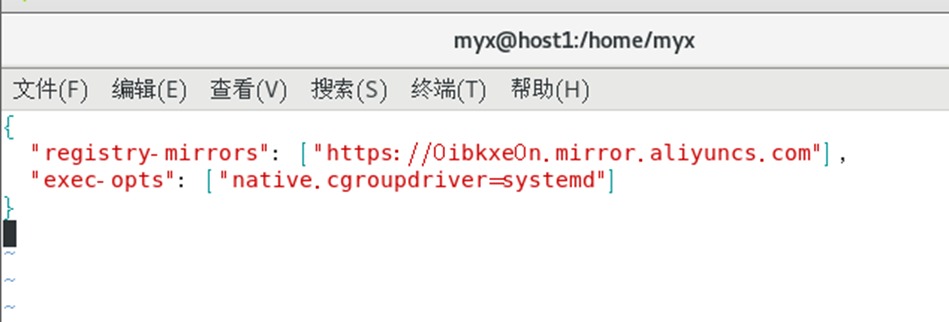
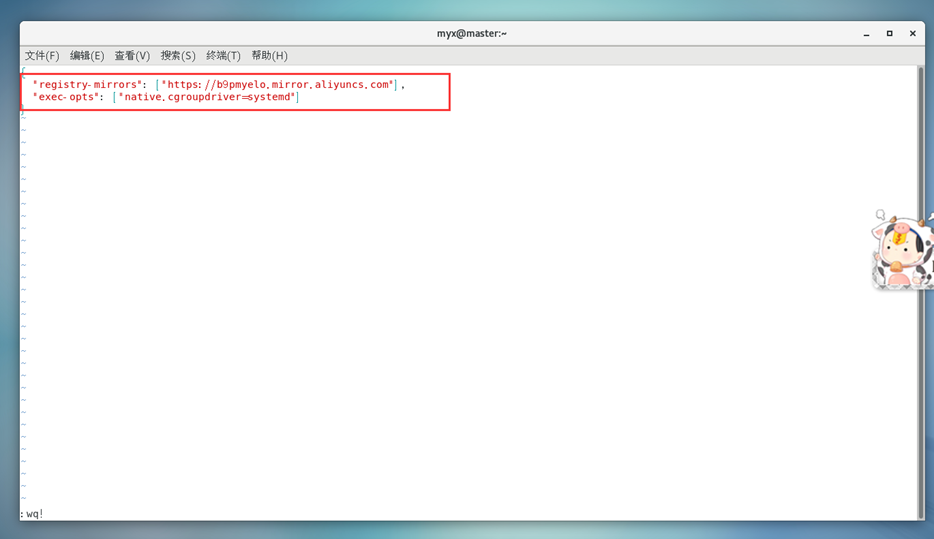
4)统一Kubernetes和docker的Cgroup Driver为systemd
修改/etc/docker/daemon.json 文件,添加如下参数:
vim /etc/docker/daemon.json
#为了保持所有节点docker配置一致,所以其它节点的docker也改了
{"registry-mirrors":["https://b9pmyelo.mirror.aliyuncs.com"],
"exec-opts":["native.cgroupdriver=systemd"]}
重新加载 Docker
systemctl daemon-reload
systemctl restart docker
5.在主节点上初始化Kubernetes
初始化之前先运行:
systemctl restart docker

kubelet命令补全
echo"source <(kubectl completion bash)">> ~/.bash_profile
source .bash_profile


拉取镜像
列出Kubernetes集群启动所需的镜像列表。这些镜像包括控制平面组件(如kube-apiserver、kube-controller-manager和kube-scheduler)以及其他一些必要的组件(如etcd、CoreDNS等)
,并修改tag与所需版本保持一致。
kubeadm config images list

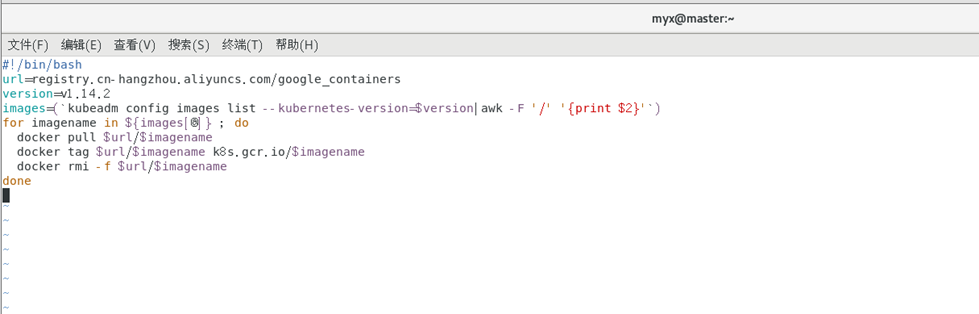
设置镜像源和脚本程序
vim image.sh
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.14.2
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
运行脚本
chmod u+x image.sh
./image.sh
docker images
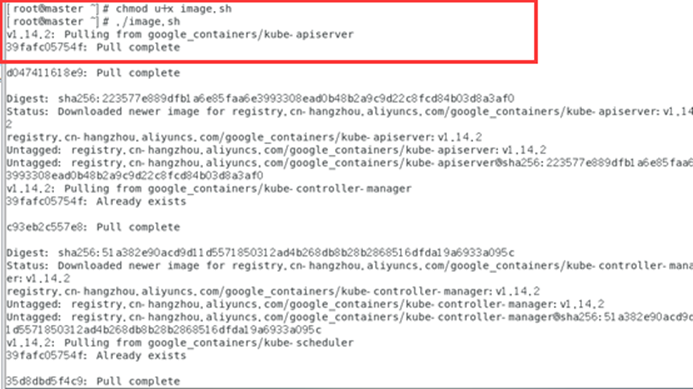
docker images查看docker仓库中的镜像,发现所有的镜像都是以registry.aliyuncs.com/google_containers/开头,有的与kubeadm config images list中要求的镜像名称不一样。我们要修改镜像名称,即对镜像重新打个tag
docker images
显示结果:
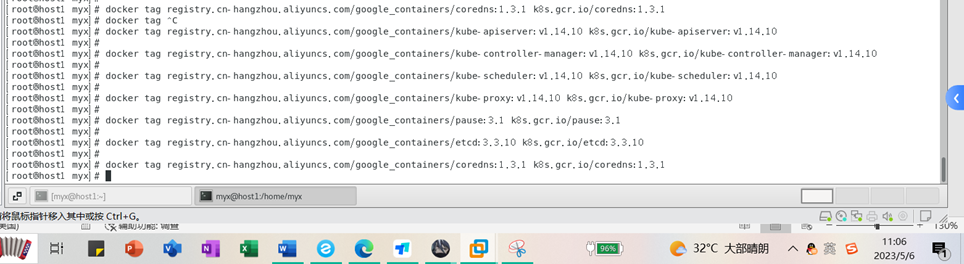
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.14.10 k8s.gcr.io/kube-apiserver:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.14.10 k8s.gcr.io/kube-controller-manager:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.14.10 k8s.gcr.io/kube-scheduler:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.14.10 k8s.gcr.io/kube-proxy:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
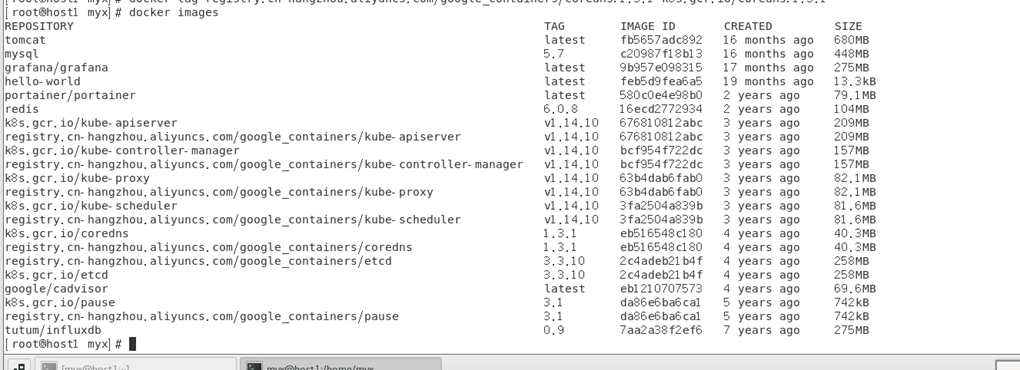
修改完tag后再次查看发现镜像名和版本号与"kubeadm config images list"命令列出的Kubernetes集群启动所需的镜像列表保持一致了。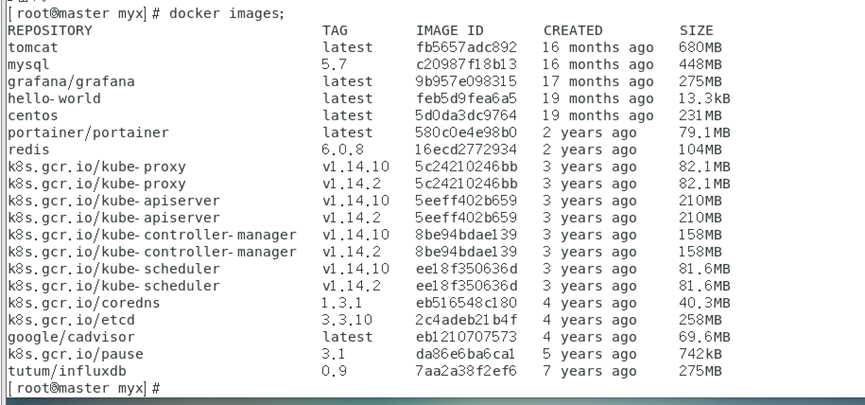
另一种方法我们也可以一个一个拉取镜像
kubeadm config images list

docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1

再次查看docker镜像:
docker images
进行重置k8s集群
kubeadm reset
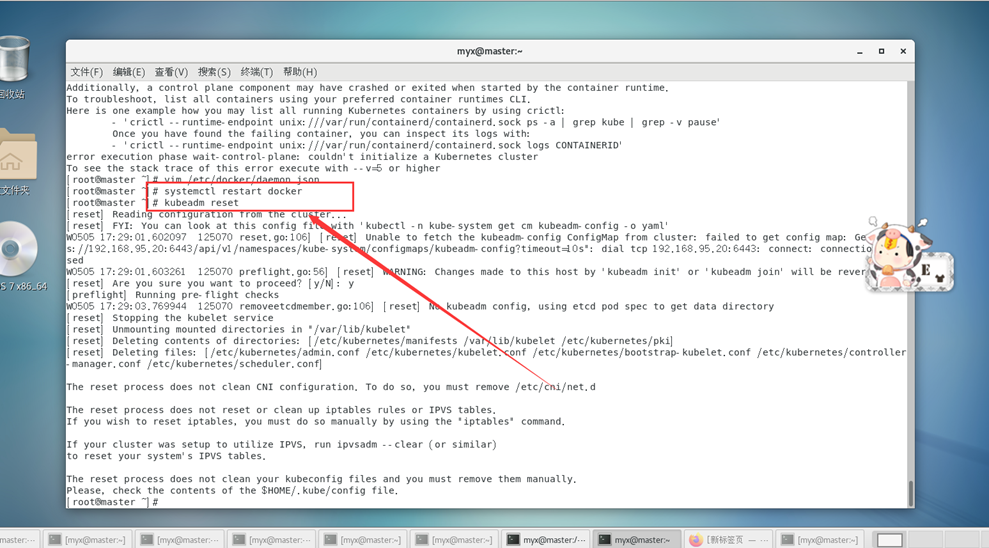
以解除端口占用,删除之前初始化时生成的配置文件等。
然后开始正式执行集群初始化:
kubeadm init --apiserver-advertise-address 192.168.95.20 --pod-network-cidr=10.244.0.0/16
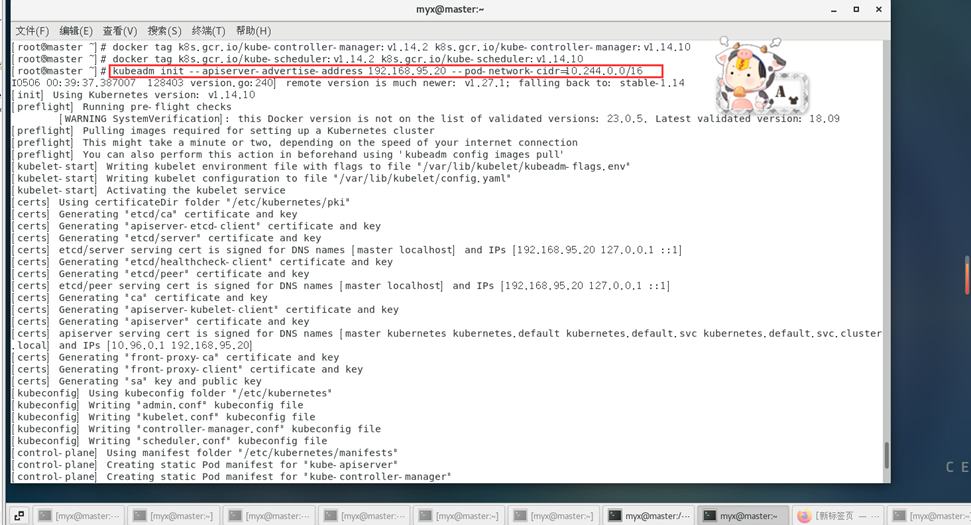
执行信息出现:
Your Kubernetes control-plane has initialized successfully!
成功完成集群初始化。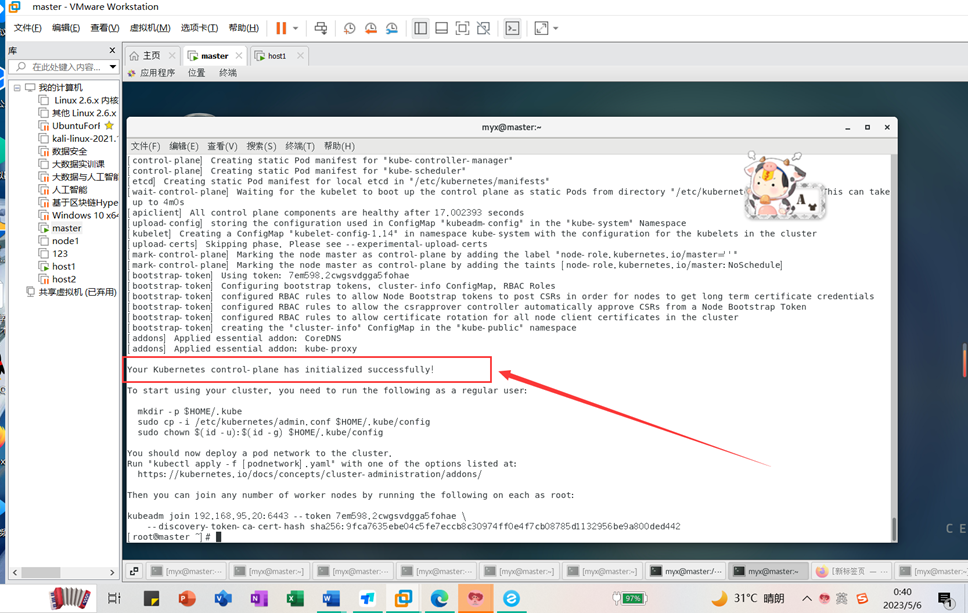

6. 配置节点
以下3条命令使用普通用户:
mkdir-p$HOME/.kube
sudocp-i /etc/kubernetes/admin.conf $HOME/.kube/config
sudochown$(id-u):$(id-g)$HOME/.kube/config
7.注意从节点加入时的命令和秘钥
kubeadm join192.168.95.20:6443 --token 7em598.2cwgsvdgga5fohae \
--discovery-token-ca-cert-hash sha256:9fca7635ebe04c5fe7eccb8c30974ff0e4f7cb08785d1132956be9a800ded442
妥善保存此秘钥。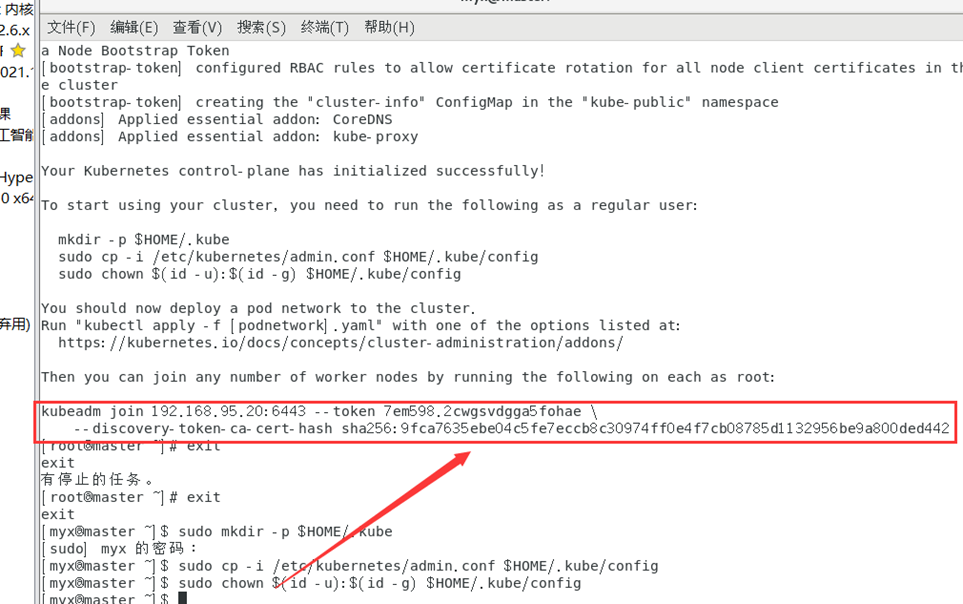
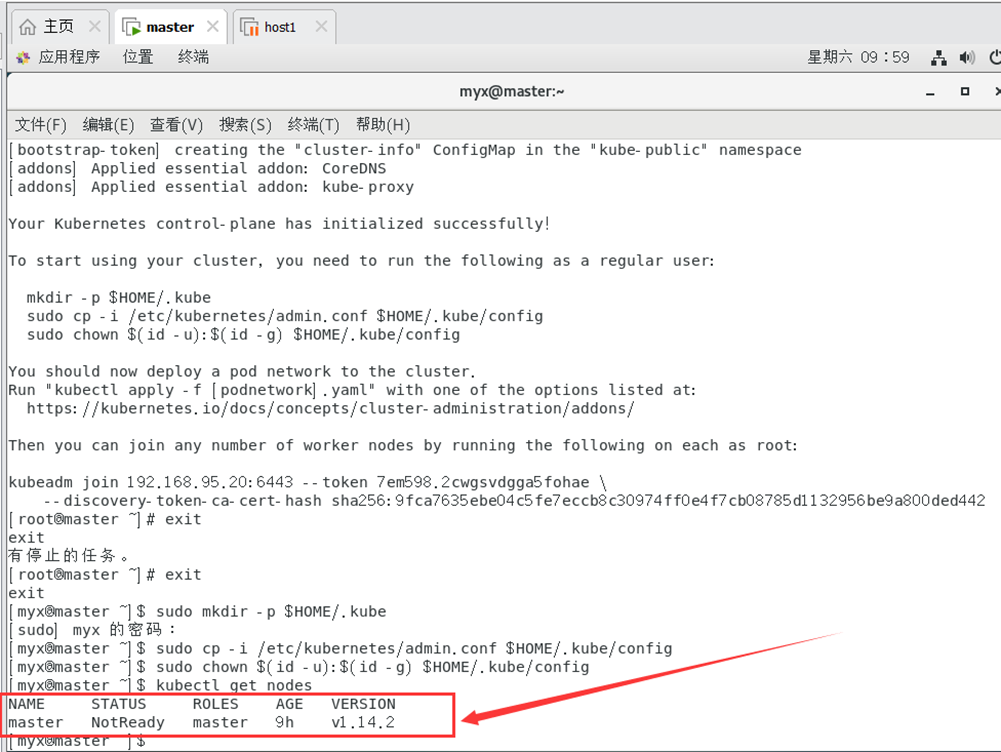
8.查看节点运行情况(NotReady状态)
kubectl get nodes
三、安装配置从节点Kubernetes
1.根据以上第一、二的相关步骤安装从节点软件及进行配置。
host1基本配置: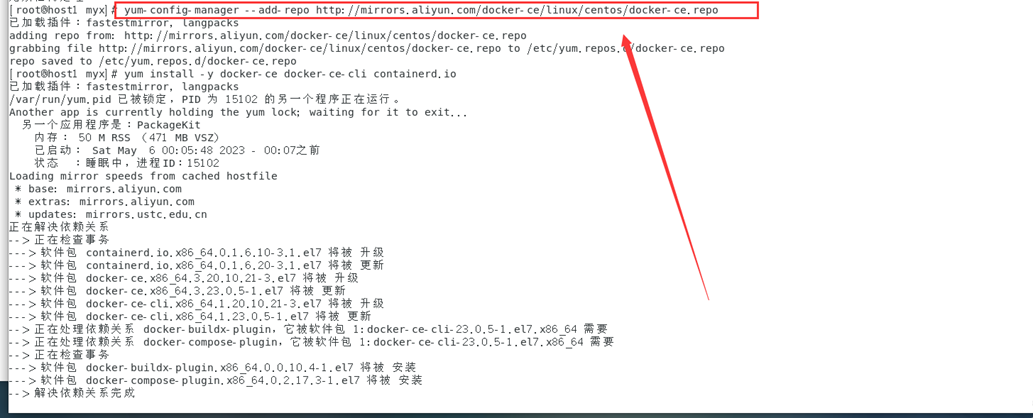
docker version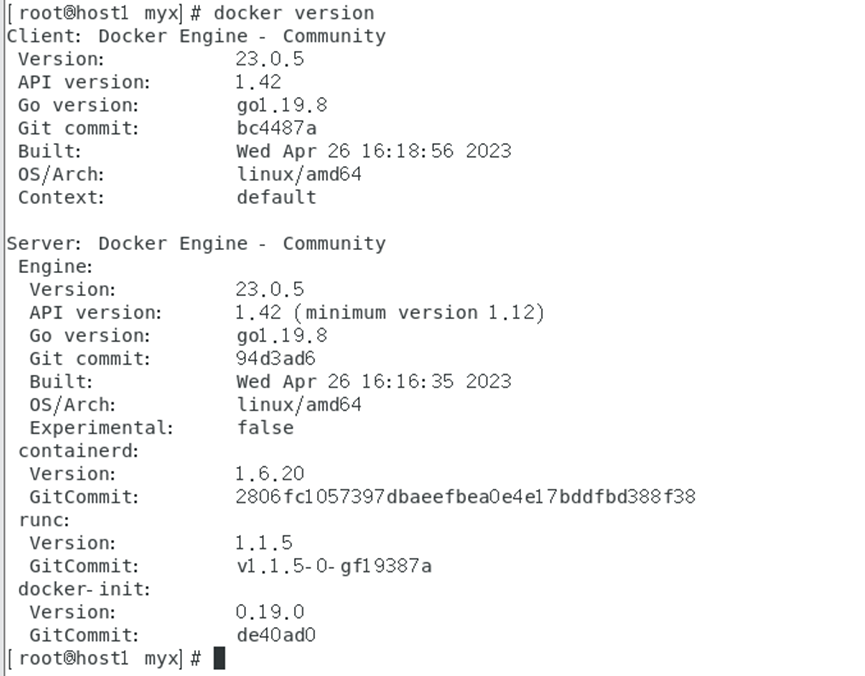
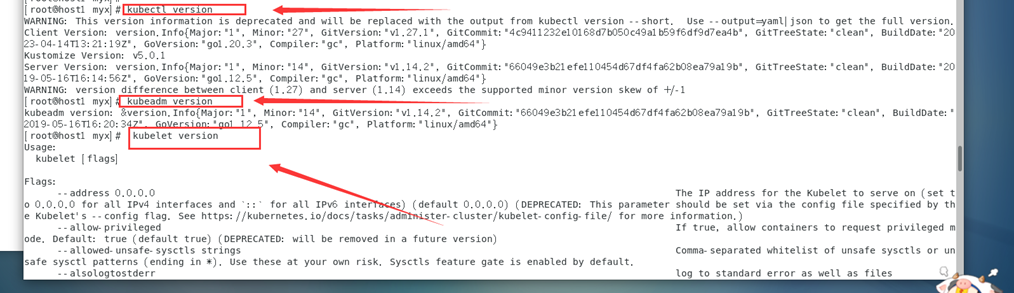
Kubectl version
kubeadm version
kubelet version
2.从节点加入集群(使用root用户)
kubeadm join192.168.95.20:6443 --token 7em598.2cwgsvdgga5fohae \
--discovery-token-ca-cert-hash sha256:9fca7635ebe04c5fe7eccb8c30974ff0e4f7cb08785d1132956be9a800ded442
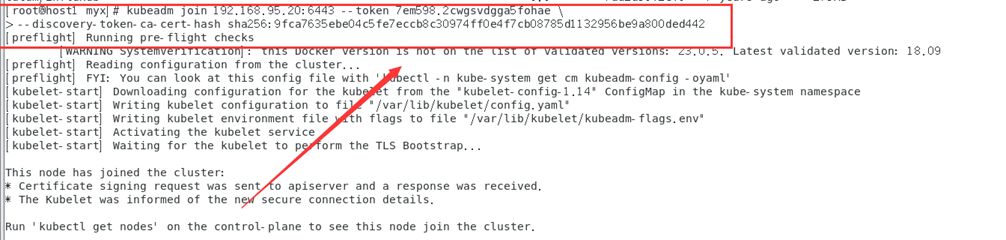
注:此步骤一般会遇到以下问题:
[ERROR CRI]: container runtime is not running:
这是因为用安转包安装的containerd,会默认禁用它作为容器运行时: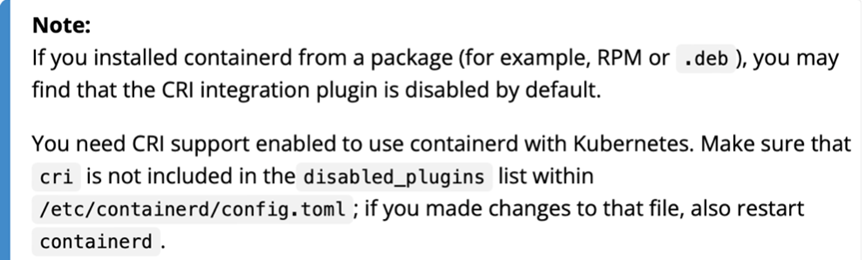
解决:
1)使用
systemctl status containerd
查看状态
Active: active (running) 表示容器运行时正常运行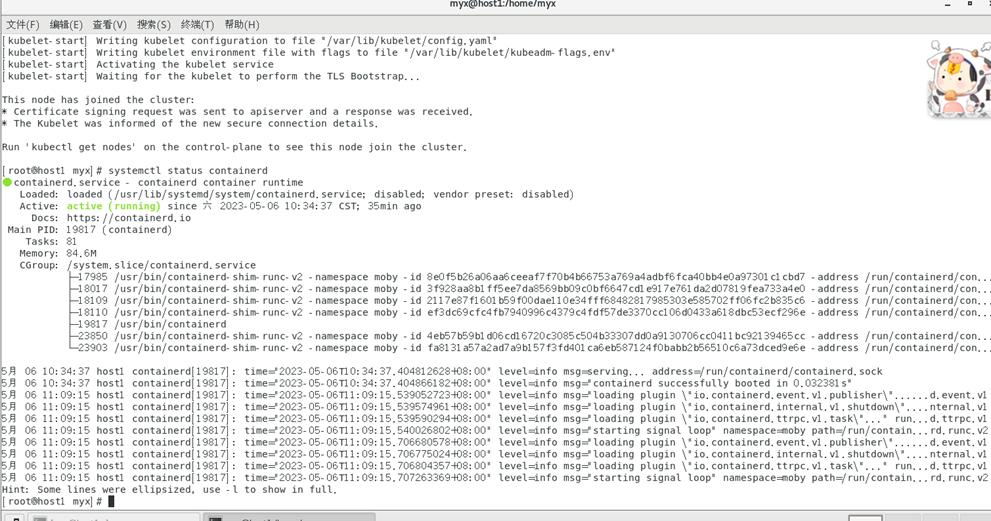
2)查看 /etc/containerd/config.toml文件,这个是容器运行时的配置文件
3)
vim /etc/containerd/config.toml
如果看到了这行
:disabled_plugins : ["cri"]
,
将这行用#注释或者将"cri"删除:
#disabled_plugins : [“cri”]或者
disabled_plugins : []
4)重启容器运行时
systemctl restart containerd
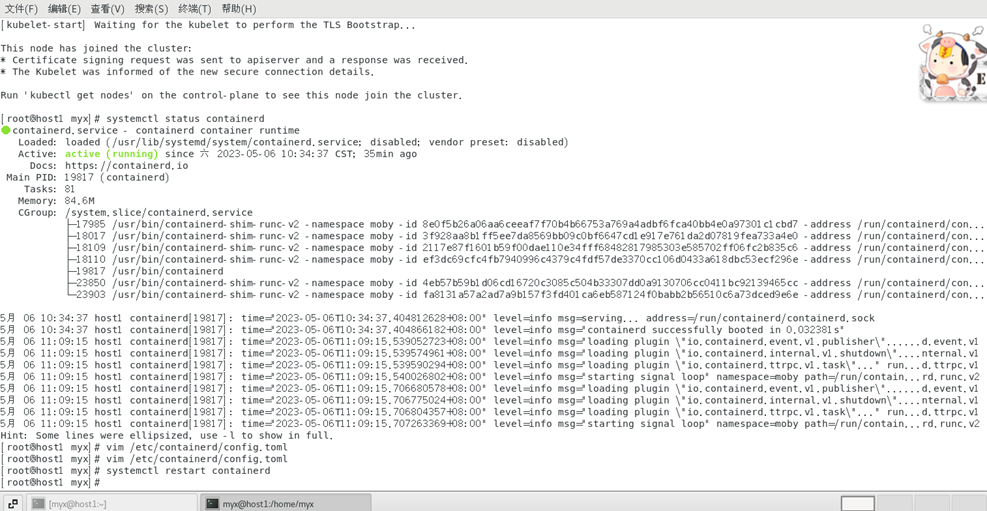
参考文献3:https://blog.csdn.net/weixin_52156647/article/details/129758753
四、在主节点上查看加入的从节点并解决随后的问题
kubectl get nodes

1.此时STATUS显示NotReady
解决:
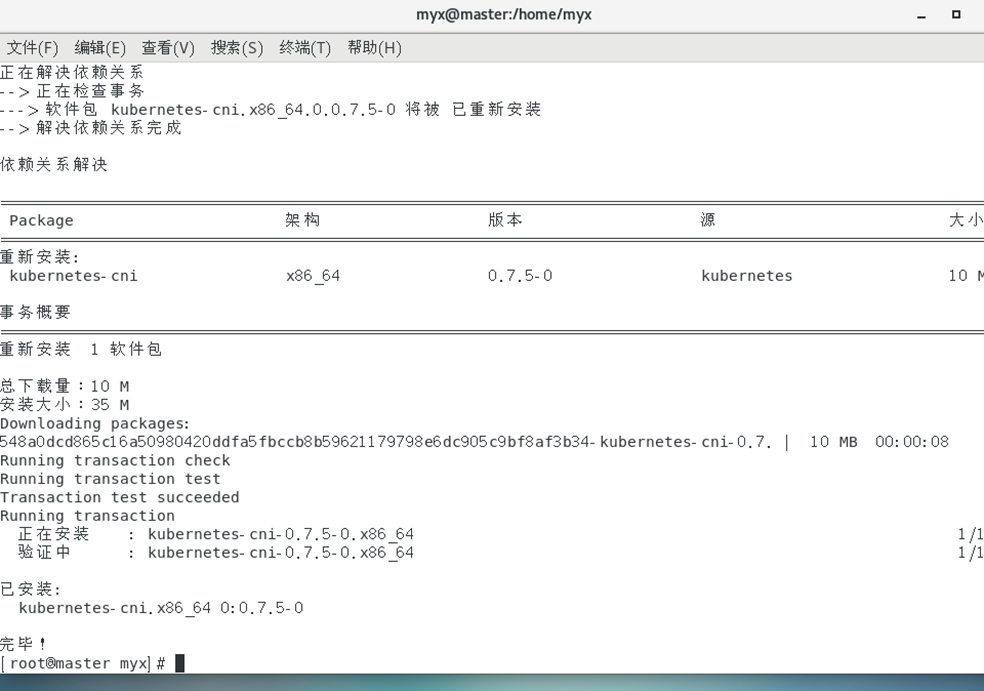
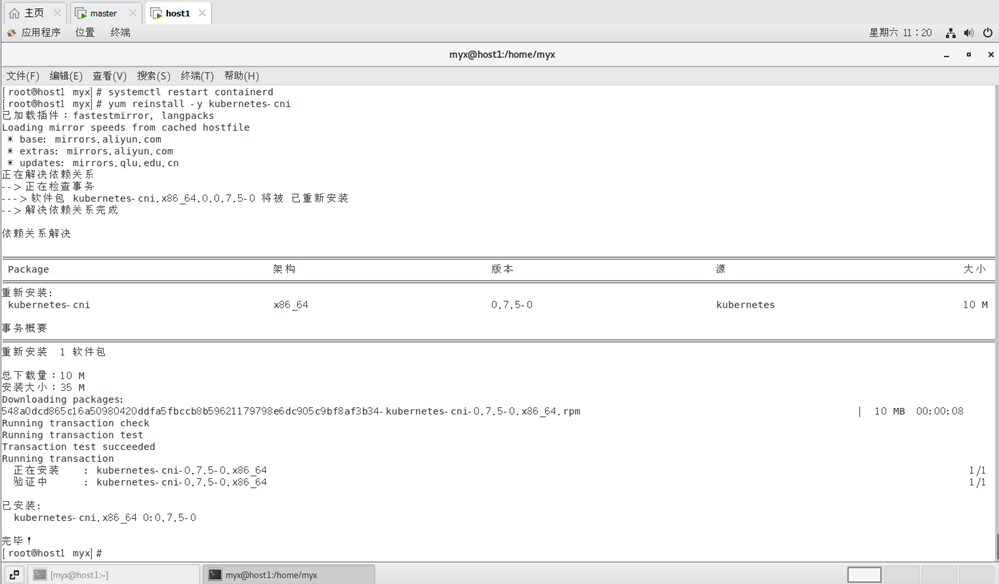
1)所有集群的节点进行重装kubernetes-cni:
yum reinstall -y kubernetes-cni
2)在主节点上安装网络:
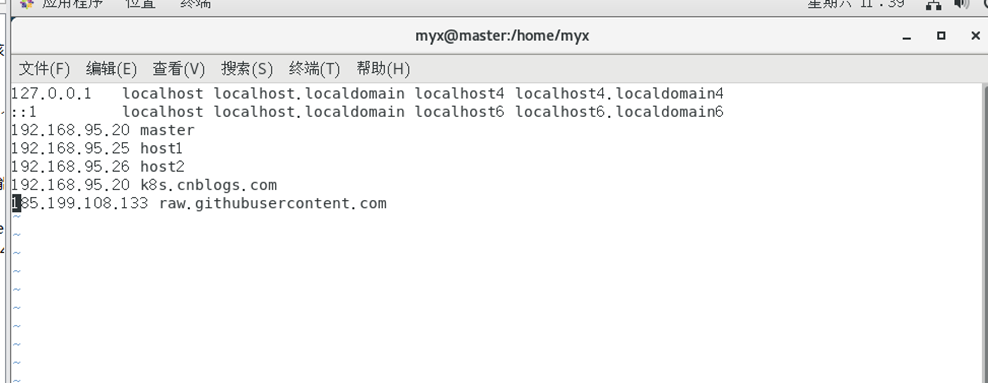
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml,其中要将185.199.108.133 raw.githubusercontent.com加入etc/hosts
(参考文献五:https://www.cnblogs.com/sinferwu/p/12726833.html)
3. 运行kubectl get nodes时出现的问题
1)couldn’t get current server API group list:
解决:
不能用root运行该命令。
2)kubernetes-admin问题
K8S输入 kubectl get nodes显示The connection to the server localhost:8080 was refused - did you specify the right host or port?
出现这个问题的原因是 kubectl 命令需要使用 kubernetes-admin 来运行。可能是系统环境不干净导致,例如重装 k8s 前未完全清空配置等。
解决方法:
(1)将主节点初始化后生成的/etc/kubernetes/admin.conf文件复制到从节点相应目录。
scp /etc/kubernetes/admin.conf host1:/etc/kubernetes/

(2)在所有节点上设置环境变量并更新
echo"export KUBECONFIG=/etc/kubernetes/admin.conf">> ~/.bash_profile
source ~/.bash_profile


在https://www.ipaddress.com/查询raw.githubusercontent.com的真实IP。
再次运行
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
安装flannel成功!
再次通过kubectl get nodes命令获取集群节点列表时候发现host1集群状态一直处于NotReady状态,通过查看日志发现报错:
journalctl -f-u kubelet
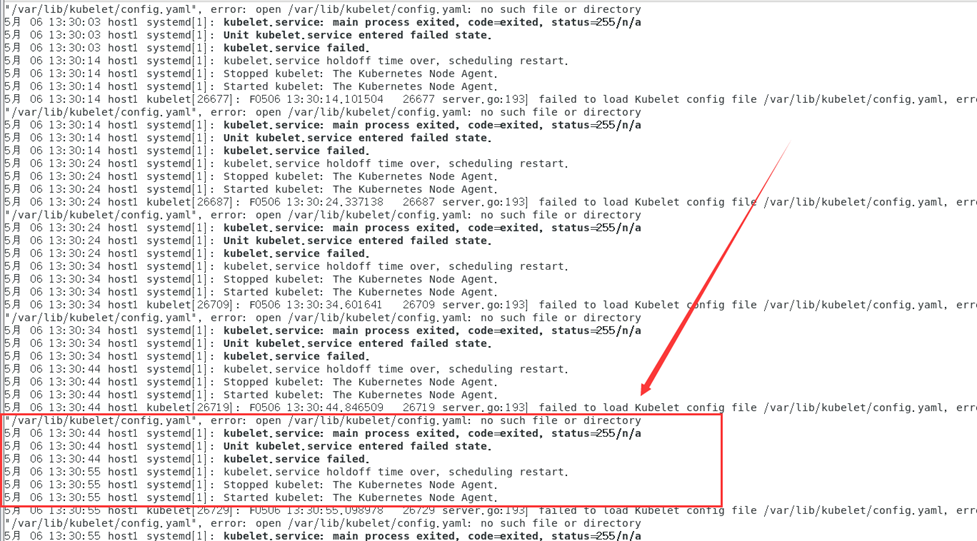
由日志信息可知,报错原因是不能从/var/llib/kubelet/config.yaml下载到kubelet的配置。
错误原因估计是我之前没有做 kubeadm init就运行了
systemctl start kubelet
。
我们可以尝试将token更新,重新生成token,代码如下:
kubeadm token create --print-join-command
在主节点g更新token
复制输出的内容,在hsot1中运行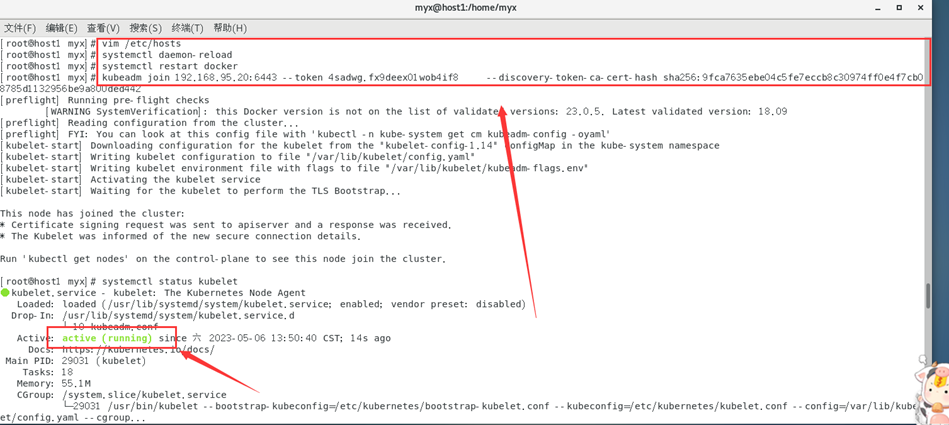
成功解决问题!
集群都是Ready状态!
参考文献六:https://www.cnblogs.com/eastwood001/p/16318644.html
五、测试Kubernetes
1.在主节点上运行:
kubectl create deployment nginx --image=nginx #创建一个httpd服务测试

kubectl expose deployment nginx --port=80--type=NodePort #端口就写80,如果你写其他的可能防火墙拦截了

kubectl get svc,pod #对外暴露端口

2.使用主节点IP地址加保留的端口访问Nginx主页:
比如:
192.168.95.20:21729
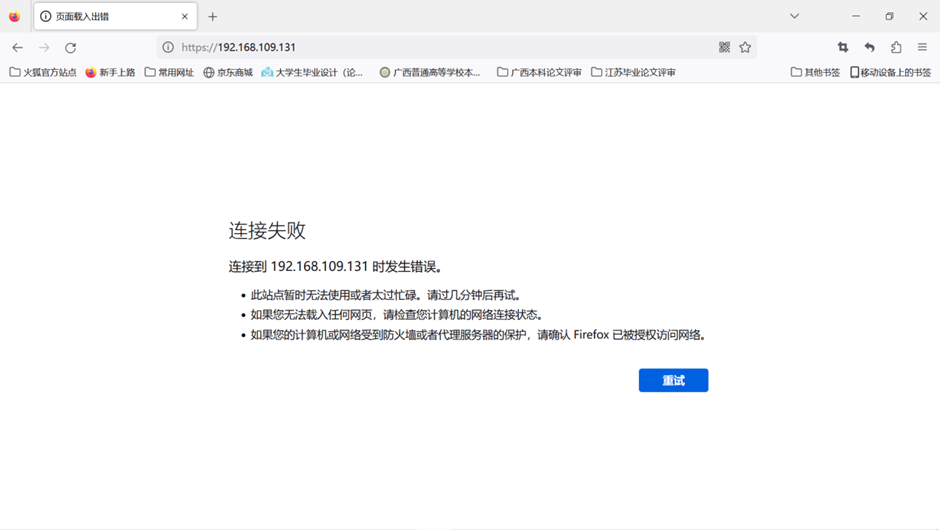
显示连接失败
使用命令
kubectl describe pod nginx-77b4fdf86c-krqtk
显示结果:
open /run/flannel/subnet.env: no such file or directory
发现我缺少相关cni网络配置文件。
我们要仔细检查查看各个节点,包括主节点是否有
/run/flannel/subnet.env
,内容应该是类似如下:
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450FLANNEL_IPMASQ=true
通过检查报错日志发现我缺少相关cni网络配置文件。
创建cni网络相关配置文件:
mkdir-p /etc/cni/net.d/
cat<<EOF> /etc/cni/net.d/10-flannel.conf
{"name":"cbr0","type":"flannel","delegate":{"isDefaultGateway": true}}
EOF
这里我们使用 cat 命令和重定向操作符 (<<),将 {“name”:“cbr0”,“type”:“flannel”,“delegate”: {“isDefaultGateway”: true}} 内容写入到 /etc/cni/net.d/10-flannel.conf 文件中。
mkdir /usr/share/oci-umount/oci-umount.d -pmkdir /run/flannel/
cat<<EOF> /run/flannel/subnet.env
FLANNEL_NETWORK=10.199.0.0/16
FLANNEL_SUBNET=10.199.1.0/24
FLANNEL_MTU=1450FLANNEL_IPMASQ=true
EOF
这里在 <<EOF 和 EOF 之间,有多行文本,每行都包含一个环境变量的定义。具体来说:
FLANNEL_NETWORK=10.199.0.0/16 定义了名为 FLANNEL_NETWORK 的环境变量,并将其设置为 10.199.0.0/16。
FLANNEL_SUBNET=10.199.1.0/24 定义了名为 FLANNEL_SUBNET 的环境变量,并将其设置为 10.199.1.0/24。
FLANNEL_MTU=1450 定义了名为 FLANNEL_MTU 的环境变量,并将其设置为 1450。
FLANNEL_IPMASQ=true 定义了名为 FLANNEL_IPMASQ 的环境变量,并将其设置为 true。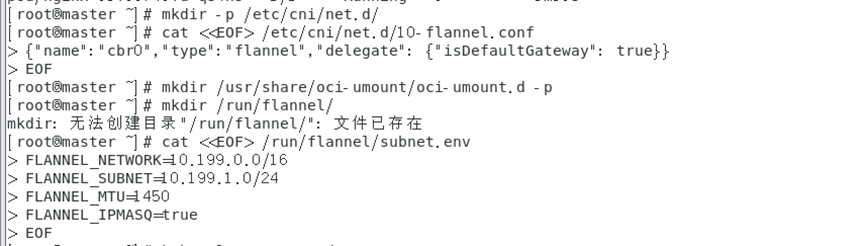
若哪个节点没有该文件那就拷贝一份,再次进行部署,应该就不会报这个错了。
我们在host1节点检查一下:
cat /run/flannel/subnet.env
cat /etc/cni/net.d/10-flannel.conf

通过命令查看到从节点已经有了相关cni网络相关配置文件。
如果缺少这些重要配置文件也会在集群日志中报错:
cni config uninitialized
5月 06 12:44:06 master kubelet[48391]: W0506 12:44:06.599700 48391 cni.go:213] Unable to update cni config: No networks found in /etc/cni/net.d
5月 06 12:44:07 master kubelet[48391]: E0506 12:44:07.068343 48391 kubelet.go:2170] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready

上面配置都没问题的话,
最后也是成功显示nginx
Kubectl get nodes
这里的kubectl get nodes 命令将返回一个表格,其中包含了集群中所有节点的相关信息,如节点名称、状态、角色(master/worker)等。
浏览器网址输入
192.168.95.25:30722

或者输入CLUSTER-IP:
10.100.184.180

这样我们就成功部署Kubernetes集群,完成nginx部署了!
这些都是亲测过的,按照上面正常操作都可以成功部署,祝各位一切顺利。
最后暑假祝各位一切顺利,学的扎实通透,玩得开心。
版权归原作者 星川皆无恙 所有, 如有侵权,请联系我们删除。