
1.R-CNN论文背景
2. R-CNN算法流程
3. R-CNN创新点
一、R-CNN论文背景
论文网址https://openaccess.thecvf.com/content_cvpr_2014/papers/Girshick_Rich_Feature_Hierarchies_2014_CVPR_paper.pdf
RCNN(Region-based Convolutional Neural Networks)是一篇由Ross Girshick等人于2014年发表的论文,题为《Rich feature hierarchies for accurate object detection and semantic segmentation》(准确的物体检测和语义分割的丰富特征层级)。该论文提出了一种基于深度学习的目标检测算法,该算法在当时取得了显著的突破,为目标检测领域的研究带来了重要的影响。
在RCNN之前,目标检测通常基于手工设计的特征和传统的机器学习算法,如SVM(支持向量机)和随机森林。这些方法在复杂的场景中往往无法提供准确的检测结果。RCNN通过引入深度学习的卷积神经网络(CNN),利用其强大的特征学习能力,极大地改进了目标检测的准确性和性能。
RCNN的创新之处在于将深度学习引入目标检测的各个阶段。通过使用CNN提取特征,RCNN能够学习到更具有判别性的特征表示,从而提高了目标检测的准确性。此外,RCNN还引入了候选区域的生成机制,避免了对整个图像进行密集的滑动窗口搜索,从而大大提高了算法的效率。
RCNN的成功标志着深度学习在目标检测领域的广泛应用。自此之后,研究人员提出了一系列基于RCNN的改进算法,如Fast R-CNN、Faster R-CNN和Mask R-CNN等,进一步提升了目标检测的性能,并推动了计算机视觉领域的发展。
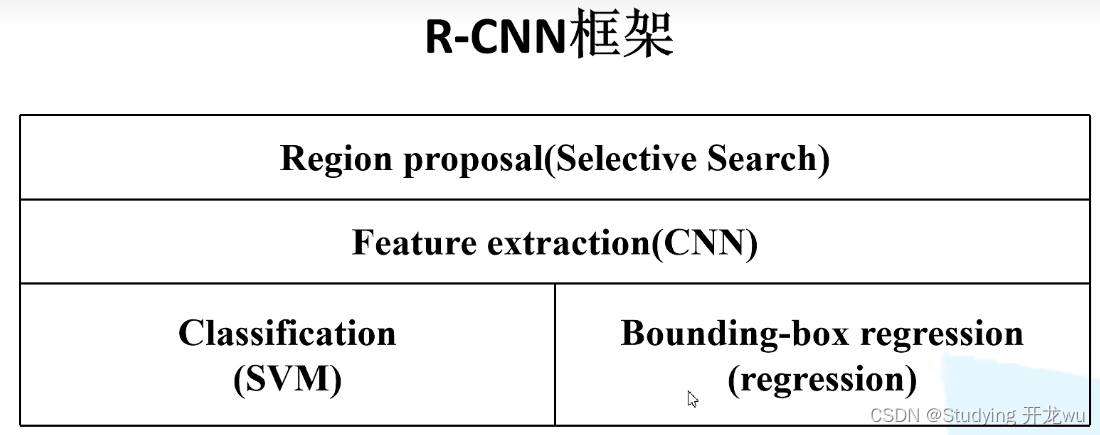
二、R-CNN算法流程
RCNN的核心思想是将目标检测问题转化为一系列的候选区域(region proposal)的分类问题。首先,它使用一个基于选择性搜索(Selective Search)的方法生成一组可能包含目标的候选区域。然后,对每个候选区域,RCNN通过在该区域上进行前向传播来提取固定长度的特征向量。这些特征向量随后被输入到一个独立的SVM分类器中,以判断该区域是否包含目标,同时还有一个边界框回归器用于精确定位目标的位置。
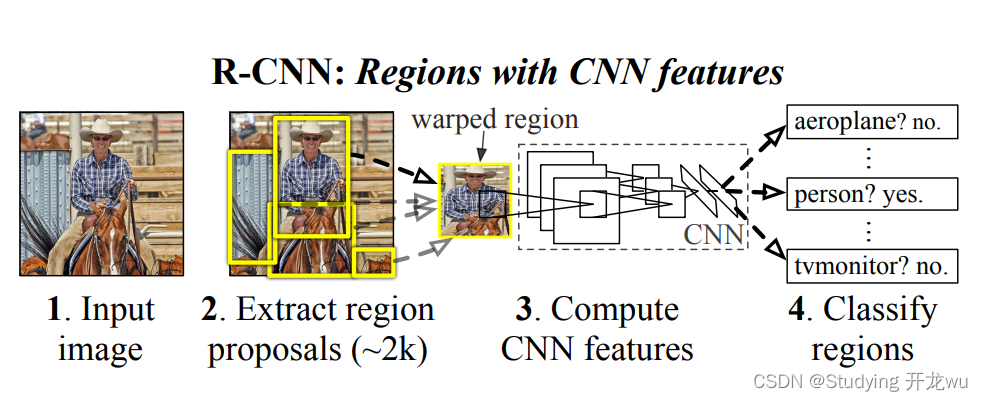
RCNN算法分为4个步骤:
(1)获取候选区域:对于一张输入的图像,首先使用selective search算法获取2000个左右的候选区域,由于selective search生成的候选区域是大小不一致的区域,而后续的卷积神经网络中的全连接层需要保证固定大小的输入,因此在输入卷积网络之后将其缩放至固定大小的图像;
(2)获取图像特征:将图像输入到卷积神经网络中获取图像特征,这一部分可以采用常用的图像卷积神经网络如VGGNet,AlexNet等。
(3)获取区域类别:在初步获得目标的位置之后,需要获取目标的类别,这一步采用SVM分类器来判断当前区域属于哪个类别。
(4)微调区域位置:尽管候选区域已经初步目标的位置,但是这个区域比较粗糙,因此使用回归器对区域位置进行微调
1.候选区域生成:获取候选区域
1.使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
2.查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
3.输出所有曾经存在过的区域,所谓候选区域
其中合并规则如下: 优先合并以下四种区域:
颜色(颜色直方图)相近的
纹理(梯度直方图)相近的
合并后总面积小的: 保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域 (例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh)
合并后,总面积在其BBOX中所占比例大的: 保证合并后形状规则。
首先目标检测问题很重要的一个因素是:一张图像中可能存在多个物体需要分别定位和分类。显然,在训练分类器之前,需要使用一些方法将图像划分为小的区域,这些方法统称为Region Proposal Algorithms。一张图像中包含的信息非常丰富,图像中的物体有不同的形状、尺寸、颜色、纹理,而且物体间还有层次(hierarchical)关系。因此不能通过单一的策略来区分不同的物体,需要充分考虑图像物体的多样性(diversity),除此之外,在图像中物体间的布局还有一定的层次关系。这个时候,作者就给了几种区域提议方法。
(1)传统方法:
Exhaustive Search
一开始是穷举法,遍历图像的每一个像素,但导致搜索的范围很大,计算量也很大,改进的穷举法产生100000多个提议区域,这对后面的区域特征提取和分类器训练带来不小的压力,所以不合适使用复杂的特征提取算法和分类器,一般使用HOG+SVM。
Segmentation
使用分割算法做Region Proposal的内容。比如:通过生成多个前景/背景,通过一定标准预测前景分割区域是一个完整对象区域的可能性大小(预测一个可能性大小),根据这个可能性大小对分割进行排序,可以精确地描绘出图像中的物体。
(2)本论文方法:
Selective Search
优势: 捕捉不同尺度(Capture All Scales)、多样化(Diversification)、快速计算(Fast to Compute)总结为:选择性搜索是用于目标检测的区域提议算法,它计算速度快,具有很高的召回率,基于颜色,纹理,大小和形状兼容计算相似区域的分层分组。Selective Search算法主要包含两个内容:Hierarchical Grouping Algorithm、Diversification Strategies。
Hierarchical Grouping Algorithm
图像中区域特征比像素更具代表性,作者使用Felzenszwalb and Huttenlocher的方法产生图像初始区域,使用贪心算法对区域进行迭代分组:
计算所有邻近区域之间的相似性;
两个最相似的区域被组合在一起;
计算合并区域和相邻区域的相似度;
重复2、3过程,直到整个图像变为一个地区。


Diversification Strategies
这个部分讲述作者提到的多样性的一些策略,使得抽样多样化,主要有下面三个不同方面:
(1)利用各种不同不变性的色彩空间;
(2)采用不同的相似性度量;
(3)通过改变起始区域。此部分比较简单,不详细介绍,作者对比了一些初始化区域的方法,发现方法效果最好。
2.获取图像特征:对每个候选区,使用深度网络提取特征
由于卷积神经网络中包含了全连接层,因此在输入后续卷积神经网络之前需要先将候选区域缩放到统一大小,论文中采用的是227×227。
至于候选区域的缩放方法,论文的补充材料部分中一共讨论了若干种缩放方法:
(1)各向异性缩放:不管图像形状尺寸,直接将图像缩放至指定大小。
(2)各向同性缩放:将候选区域进行扩充至正方形,随后进行缩放裁剪,如果扩充至图像边缘,直接用均值进行填充;直接裁剪候选区域之后用均值将其填充至指定大小。
将2000候选区域缩放到227x227pixel,接着将候选区域输入事先训练好的AlexNet CNN网络获取4096维的特征得到2000×4096维矩阵,注意这里CNN最后一层是全连接层,这里使用把他去掉,得到一个向量是2000×4096维矩阵。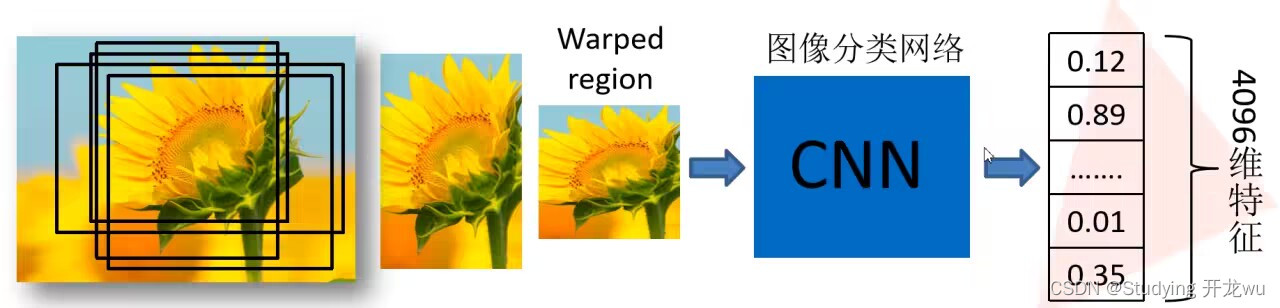
3.获取区域类别:特征送人每一类的SVM分类器,判定类别
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘,获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
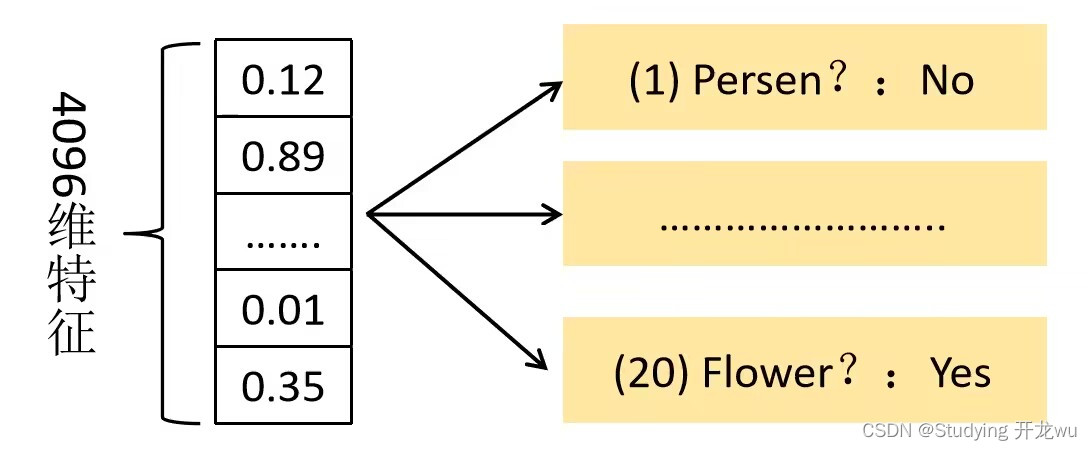
2000×20维矩阵表示每个建议框是某个目标类别的得分:
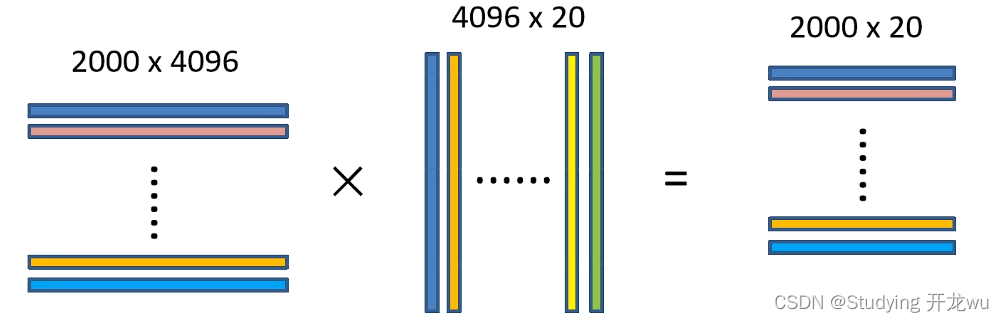
左边:横向量为一个候选框通过CNN网络得到的特征向量,因为有2000个候选框
中间:纵向量为所需检测比如第一个为猫特征向量,第二个为狗
将2000×4096的特征矩阵与20个SVM组成的权值矩阵4096×20相乘,获得2000×20的概率矩阵,每一行代表一个建议框归于每个目标类别的概率。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
非极大值抑制剔除重叠建议框:
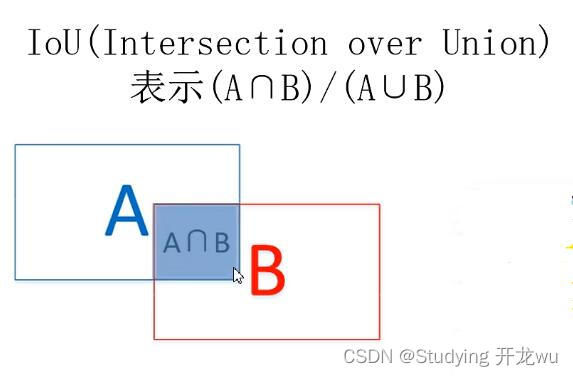
重叠度(IOU):
物体检测需要定位出物体的bounding box,在图片中,我们不仅要定位出被检测物体的bounding box 我们还要识别出bounding box 里面的物体就是类别。
对于bounding box的定位精度,有一个很重要的概念: 因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。 它定义了两个bounding box的重叠度,如下图所示
4.微调区域位置:使用回归器精细修正候选框位置
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
尽管Selective search方法会生成2000个左右的候选区域,但是也很难保证这些候选区域与真值完全一致,为此在此基础上进一步微调是非常有必要的。
RCNN使用线性回归器对位置进行微调微调,得到更加准确的边界框。
对NMS处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
三、 R-CNN相比传统目标检测的创新点和优缺点
1.相比传统目标检测的创新点
创新点主要有以下几个方面:
1.引入深度学习:RCNN首次将深度学习应用于目标检测领域。传统目标检测方法通常使用手工设计的特征和传统的机器学习算法,如SVM和随机森林。而RCNN使用卷积神经网络(CNN)来提取图像特征,能够自动学习更具判别性的特征表示,从而提高了目标检测的准确性。
2.候选区域的生成:RCNN引入了选择性搜索(Selective Search)算法来生成候选区域。传统方法通常采用滑动窗口的方式对整个图像进行密集的搜索,计算量较大。RCNN通过选择性搜索算法,能够快速生成大量可能包含目标的候选区域,减少了计算开销。
3.区域级别的分类与定位:RCNN将目标检测问题转化为对候选区域的分类问题。对于每个候选区域,RCNN使用CNN提取其特征表示,并通过独立的支持向量机(SVM)分类器进行目标的分类判断。此外,RCNN还引入了边界框回归器,能够精确定位目标的位置。
4.端到端的训练:RCNN采用端到端的训练方式,可以同时学习特征提取和目标分类器的参数。这使得RCNN能够端到端地优化整个目标检测系统,提高了检测性能。
2.优缺点
1.优点
1.准确性:RCNN在目标检测任务中表现出很高的准确性。通过使用深度学习模型(卷积神经网络)提取图像特征,RCNN能够学习到更具判别性的特征表示,从而提高了目标检测的准确性。
2.候选区域生成:RCNN采用选择性搜索(Selective Search)算法来生成候选区域。相比传统方法的密集滑动窗口搜索,选择性搜索能够快速生成大量可能包含目标的候选区域,减少了计算开销。
3.端到端训练:RCNN采用端到端的训练方式,能够同时学习特征提取和目标分类器的参数。这使得RCNN能够端到端地优化整个目标检测系统,提高了检测性能。
4.可扩展性:RCNN框架具有良好的可扩展性,可以方便地应用于不同的目标检测任务和数据集。通过改变网络结构和训练数据,RCNN可以适应不同的目标类别和场景。
2.缺点:
1.低速:RCNN算法的一个主要缺点是计算速度较慢。在目标检测过程中,需要为每个候选区域进行特征提取和分类,这导致了大量的计算量和时间消耗。
2.复杂性:RCNN算法的实现相对复杂。它包含了多个组件,包括候选区域生成、特征提取、分类器训练等。这使得算法的实现和调优相对困难。
3.内存消耗大:RCNN算法需要在内存中存储大量的候选区域和特征表示,导致内存消耗较大。
4.训练时间长:由于RCNN的复杂性和计算需求,训练RCNN模型需要大量的时间和计算资源。
R-CNN存在的问题详细:
1.测试速度慢:
测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。
⒉.训练速度慢:
过程及其繁琐
3.训练所需空间大:
对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOCO7训练集上的5k图像上提取的特征需要数百GB的存储空间。
版权归原作者 Studying 开龙wu 所有, 如有侵权,请联系我们删除。