
题目:请编写一个爬虫程序,访问https://www,taobao.com/页面,在搜索框中输入“python”,点击“搜索”按钮,爬取页面中所有书名和价格等数据。
先下载python 模块!
python自己的Selenium模块
pip install selenium
网速慢的可以用清华的源
清华大学开源软件镜像站:使用清华大学的源,可以通过以下命令安装Selenium:
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
1.首先咋们要用python(selenium)自动化需要浏览器 安装浏览器驱动。
安装浏览器驱动
安装浏览器驱动时注意版本保持一致。
查看浏览器版本: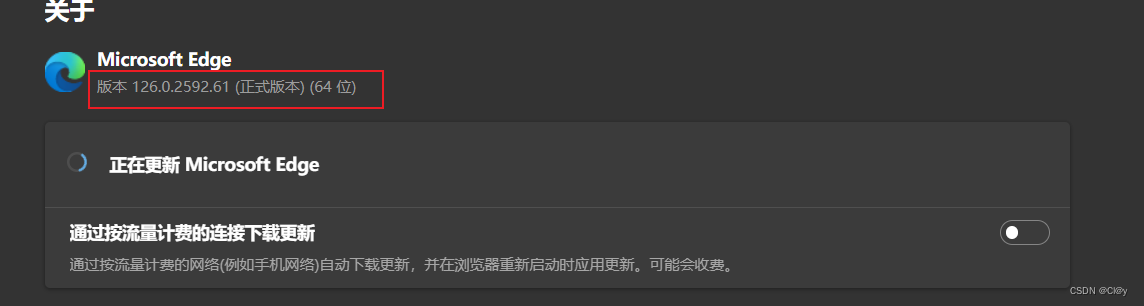
标题
上图中看到我的Edge版本是 126.0.2592.61。
进入网站下载驱动。
在这个网站上下载驱动:Microsoft Edge WebDriver |Microsoft Edge 开发人员https://developer.microsoft.com/zh-cn/microsoft-edge/tools/webdriver/
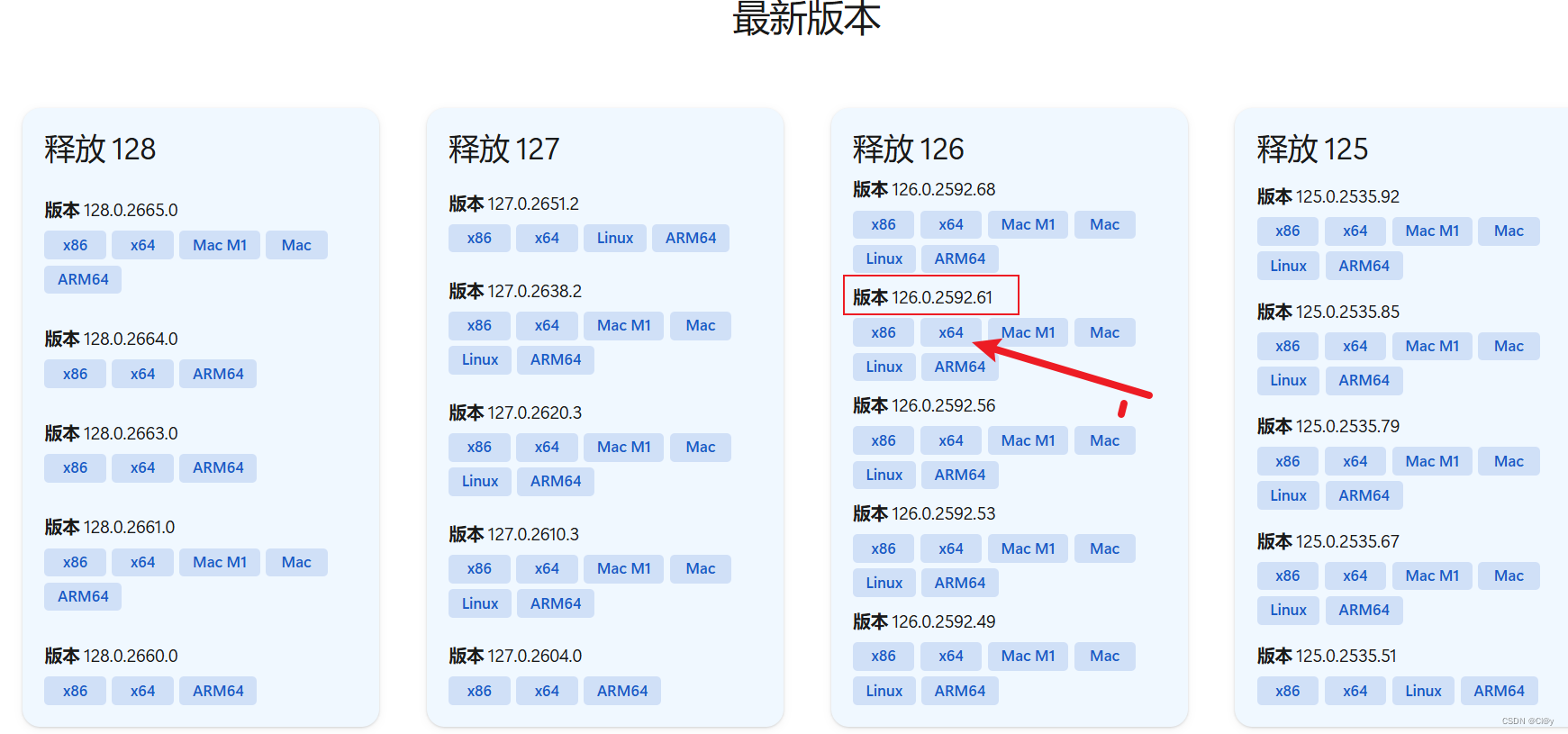
根据自己的浏览器匹配下载
下载之后会是这个样子的里面有个msedgedriver.exe文件 把文件复制到python解释器目录下并且改名为**MicrosoftWebDriver.exe **
如果你不知道python解释器目录在哪里咋们可以直接win+cmd查找解释器目录。
#win+R 输入cmd
where python
# 或者,如果默认的Python版本是Python 3,你可能需要输入:
where python3
如图这就是解释器目录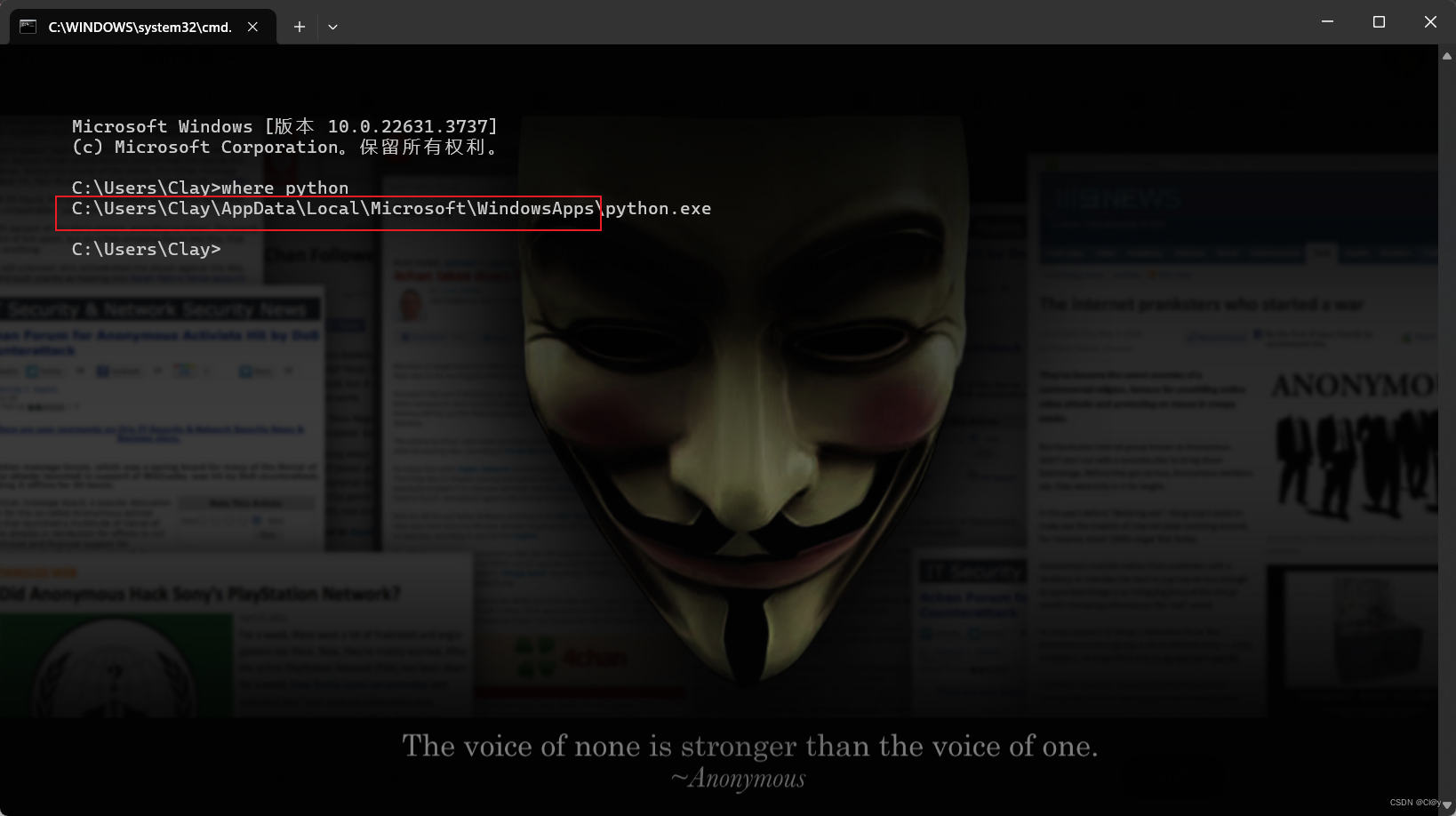
** 记得给浏览器驱动改个名字**
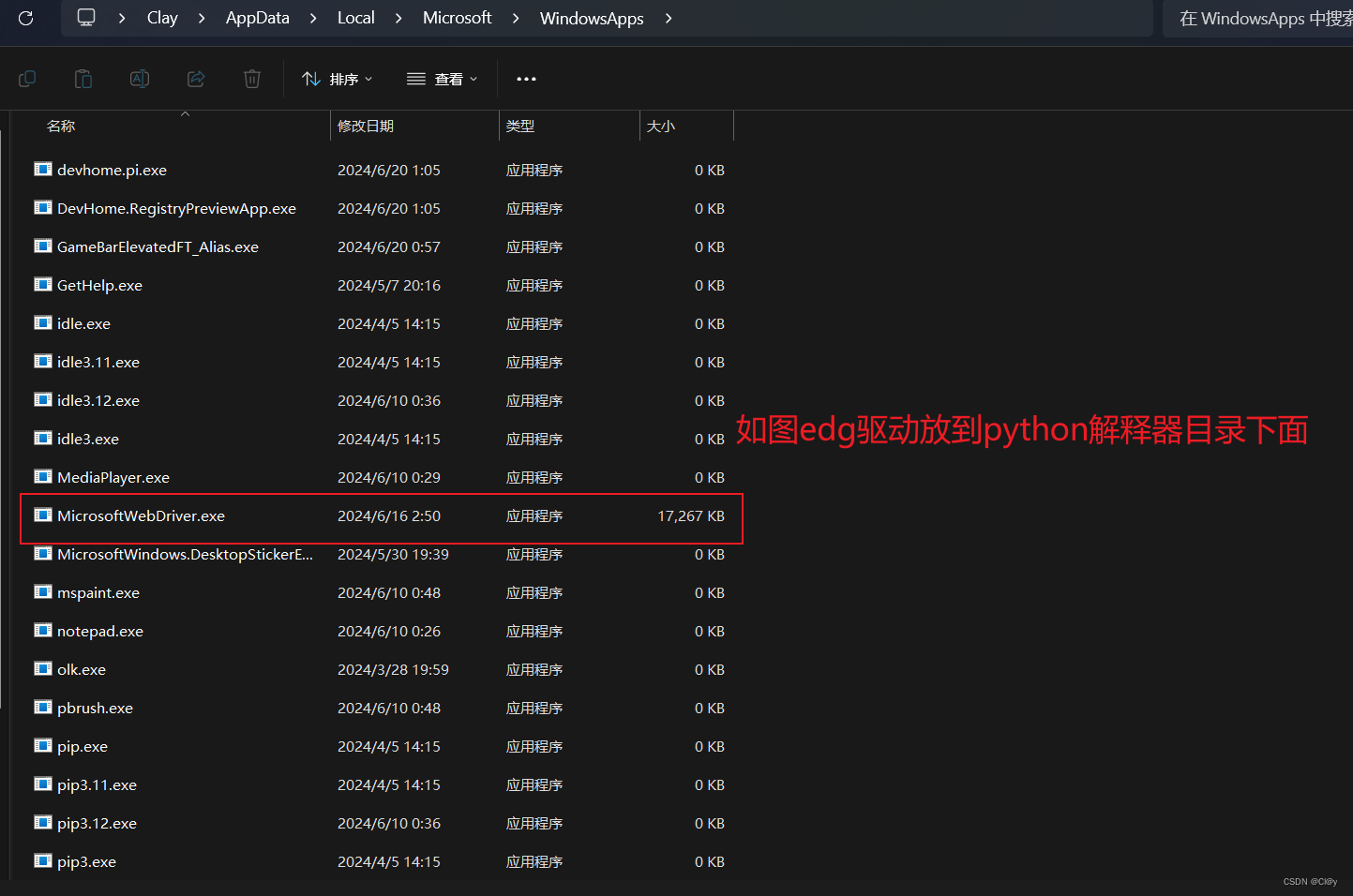
下载配置完了浏览器驱动就可以使用python自动化selenium
该Python函数使用Selenium库实现了一个简单的自动化浏览器操作,具体功能如下:
- 使用Edge浏览器的WebDriver打开淘宝网站。
- 等待搜索框加载完成,并在搜索框中输入关键词"python"后提交搜索。
- 等待页面加载完成。
- 定位搜索结果页面中的所有商品项,并遍历每个商品项。
- 提取并打印每个商品的名称、价格、付款人数和地区信息。
- 如果页面加载超时或元素未找到,则打印错误信息。
- 最后关闭浏览器。
该函数通过Selenium库实现了自动化浏览器操作,能够自动打开淘宝网站、搜索商品并提取相关信息,方便进行数据分析或自动化测试等任务。
上python代码注释里写的很清楚一看便知,不懂评论区讨论
# 导入Selenium WebDriver模块及相关类,用于自动化网页操作
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import time
# 初始化Edge浏览器驱动,用于后续网页访问
# 初始化WebDriver,这里使用的是Edge浏览器,确保已经安装了对应的WebDriver
browser = webdriver.Edge()
# 打开淘宝网站主页
# 打开淘宝网站
browser.get('https://www.taobao.com')
# 创建一个等待对象,设置最长等待时间为15秒
# 等待搜索框加载完成,增加等待时间至20秒
wait = WebDriverWait(browser, 15)
# 等待搜索框出现,并在搜索框中输入“python”,然后按下回车键
# 定位搜索框并输入搜索内容
search_box = wait.until(EC.presence_of_element_located((By.ID, "q")))
search_box.send_keys('python')
search_box.send_keys(Keys.RETURN) # 使用回车键提交搜索
# 暂停10秒,等待搜索结果页面加载
# 等待15秒,让页面有足够时间加载搜索结果
time.sleep(10)
try:
# 等待搜索结果项全部加载完成
# 定位所有商品项
product_items = wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME, "Card--doubleCard--wznk5U4")))
# 遍历所有搜索结果项,提取并打印商品名称、价格、销量和地区信息
for item in product_items:
# 商品名称
product_name = item.find_element(By.CLASS_NAME, "Title--title--jCOPvpf").text
print(f"商品名称: {product_name}")
# 商品价格
price_int = item.find_element(By.CLASS_NAME, "Price--priceInt--ZlsSi_M").text
price_float = item.find_element(By.CLASS_NAME, "Price--priceFloat--h2RR0RK").text
print(f"商品价格: {price_int}.{price_float}元")
# 付款人数
sales_count = item.find_element(By.CLASS_NAME, "Price--realSales--FhTZc7U").text
print(f"付款人数: {sales_count}")
# 地区信息
region = item.find_element(By.XPATH, ".//div[@class='Price--procity--_7Vt3mX']/span").text
print(f"地区: {region}")
print("-" * 50) #分割线
except TimeoutException as e:
# 如果等待超时,打印错误信息
print("页面加载超时或元素未找到:", e)
# 关闭浏览器
# 完成操作后,关闭浏览器
browser.quit()
演示图:

本文转载自: https://blog.csdn.net/m0_64000952/article/details/139871672
版权归原作者 Cl@y 所有, 如有侵权,请联系我们删除。
版权归原作者 Cl@y 所有, 如有侵权,请联系我们删除。