
实现
1.引入maven依赖
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.9</version><relativePath/><!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>kafka-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka-demo</name><description>kafka-demo</description><properties><java.version>8</java.version></properties><dependencies><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><image><builder>paketobuildpacks/builder-jammy-base:latest</builder></image></configuration></plugin></plugins></build></project>
2.修改application.properties配置
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.bootstrap-servers=10.20.37.85:9092
spring.kafka.consumer.group-id=demo
通过spring.kafka.consumer.auto-offset-reset配置可以指定Kafka消费者的行为,当遇到没有初始偏移量或当前偏移量不再服务器上存在的情况时的处理策略。这个配置有以下三个可选值:
- earliest:当消费者组中没有存储的偏移量,或者偏移量超出了可用范围时,从最早的可用消息开始消费。
- latest(默认):当消费者组中没有存储的偏移量,或者偏移量超出了可用范围时,从最新的可用消息开始消费。
- none:当服务器上找不到消费者的偏移量时,抛出异常。
通过spring.kafka.bootstrap-servers配置可以指定Kafka的地址。这个配置的值应该是一个或多个Kafka服务器的地址,用逗号分隔。
通过spring.kafka.consumer.group-id配置可以指定Kafka消费者的组ID。这个配置的值应该是一个字符串,用于标识消费者所属的组。
定义Configuer引入kafka Bean
@ComponentpublicclassMyConfiguer{@BeanpublicNewTopictopic(){returnTopicBuilder.name("topic1").partitions(10).replicas(1).build();}}
使用了@Bean注解,表示该方法将返回一个Spring管理的bean对象。在这个方法中,通过调用TopicBuilder类的name方法指定了主题的名称为"topic1",然后使用partitions方法设置了主题的分区数为10,使用replicas方法设置了主题的副本数为1。最后,调用build方法构建并返回了一个NewTopic对象。
定义生产者
@ComponentpublicclassKafkaProducer{@BeanpublicApplicationRunnerrunner(KafkaTemplate<String,String> template){return args ->{
template.send("topic1","test");};}}
ApplicationRunner接口是Spring Boot提供的一个回调接口,用于在应用程序启动后执行一些操作。这段代码的作用是在应用程序启动后自动发送一条消息到Kafka的"topic1"主题,消息内容为"test"。
定义消费者
@ComponentpublicclassKafkaConsumer{@KafkaListener(id ="myId", topics ="topic1")publicvoidlisten(String in){System.out.println(in);}}
@KafkaListener注解用于标记方法作为Kafka消息的消费者。这段代码的作用是创建一个Kafka消费者,监听名为"topic1"的主题,并将接收到的消息内容打印到控制台。
总结
生产者
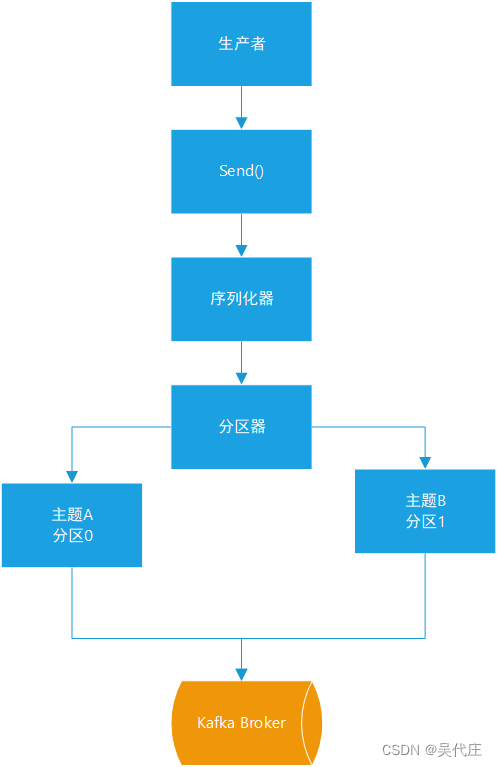
Kafka生产者发送消息的流程如下:
- 创建ProducerRecord:首先,生产者需要创建一个ProducerRecord对象,该对象包含目标主题和要发送的内容。如果需要,还可以指定消息的键(key)或分区(partition)。
- 序列化:生产者将ProducerRecord对象中的键和值进行序列化,转换为字节数组,以便能够在网络上传输。
- 拦截器链:消息会通过一个由一个或多个拦截器组成的链。这些拦截器可以对消息进行预处理,例如添加头信息或实施自定义的逻辑。
- 元数据加载:生产者在发送消息之前,需要加载Kafka集群的元数据,以确定各个主题的分区和副本分布情况。
- 计算分区号:根据ProducerRecord中的键和分区策略(如果有的话),生产者会计算出消息应该发送到哪个分区。
- 累加器缓存:消息被缓存到RecordAccumulator累加器中,这是一个按照批次处理消息的组件。
- Sender线程发送:Sender线程负责将符合条件的消息批次发送给Kafka broker。除了发送消息外,Sender线程也负责更新元数据。
- 等待确认:生产者可以选择等待broker的确认,以确保消息已经被成功接收并写入日志。
- 处理响应:生产者处理来自broker的响应,包括错误处理和重试逻辑。
- 完成发送:一旦消息被成功发送并且确认,生产者会继续发送下一批消息或者结束发送过程。
消费者
Kafka消费者接收消息的流程涉及到多个关键步骤,确保了消息能够从broker高效地传送到消费者手中。以下是该过程的详细描述:
- 创建消费者实例:需要创建一个Kafka消费者实例,这通常涉及到指定一些关键参数,如Kafka集群的地址、消费者组ID、反序列化器等。
- 订阅主题:消费者需要订阅一个或多个感兴趣的主题。这意味着消费者希望从这些主题接收消息。
- 协调消费者组:在ConsumerCoordinator的poll方法中,会有一个ensureActiveGroup的过程,消费者通过这个过程向Coordinator发送加入消费者组的请求,并等待Coordinator的响应。
- 拉取消息:一旦加入了消费者组,消费者开始从订阅的主题中拉取(pull)消息。Kafka采用pull模式而不是push模式,这意味着消费者需要主动去服务器拉取消息。
- 处理消息:消费者获取消息后,会进行相应的处理。这个处理过程可能包括数据转换、存储或者其他业务逻辑。
- 提交消费位移:消费者在处理完消息后,需要提交消费位移。这是告诉Kafka它已经消费到了哪个位置,以便下次从正确的位置开始消费。位移的提交是由消费者自己管理的,Kafka提供了接口来更新这些位移。
- 控制消费速率:消费者可以通过各种方式控制消息的消费速率,例如通过限制拉取操作的频率或者调整消费者的线程数。
- 错误处理和重试:在消费过程中可能会遇到错误,比如网络问题或者消息格式错误。消费者需要有相应的错误处理机制来处理这些情况,并在必要时进行重试。
- 关闭消费者:完成消息消费后,应当关闭消费者实例,释放资源。
本文转载自: https://blog.csdn.net/Luck_gun/article/details/136270060
版权归原作者 吴代庄 所有, 如有侵权,请联系我们删除。
版权归原作者 吴代庄 所有, 如有侵权,请联系我们删除。