
背景
DataX3.0 官方版本里面目前只支持了hdfs的读写,不支持hive的读写,基于原有的hdfsreader和hdfswriter开发了hivereader和hivewriter。
1、修改根目录的pom文件
新增hivereader、hivewriter
<modules>
<module>common</module>
<module>core</module>
<module>transformer</module>
<!-- reader -->
<module>mysqlreader</module>
<module>drdsreader</module>
<module>sqlserverreader</module>
<module>postgresqlreader</module>
<module>kingbaseesreader</module>
<module>oraclereader</module>
<module>odpsreader</module>
<module>otsreader</module>
<module>otsstreamreader</module>
<module>txtfilereader</module>
<module>hdfsreader</module>
<module>streamreader</module>
<module>ossreader</module>
<module>ftpreader</module>
<module>mongodbreader</module>
<module>rdbmsreader</module>
<module>hbase11xreader</module>
<module>hbase094xreader</module>
<module>tsdbreader</module>
<module>opentsdbreader</module>
<module>cassandrareader</module>
<module>gdbreader</module>
<module>oceanbasev10reader</module>
<module>hivereader</module>
<!-- writer -->
<module>mysqlwriter</module>
<module>tdenginewriter</module>
<module>drdswriter</module>
<module>odpswriter</module>
<module>txtfilewriter</module>
<module>ftpwriter</module>
<module>hdfswriter</module>
<module>streamwriter</module>
<module>otswriter</module>
<module>oraclewriter</module>
<module>sqlserverwriter</module>
<module>postgresqlwriter</module>
<module>kingbaseeswriter</module>
<module>osswriter</module>
<module>mongodbwriter</module>
<module>adswriter</module>
<module>ocswriter</module>
<module>rdbmswriter</module>
<module>hbase11xwriter</module>
<module>hbase094xwriter</module>
<module>hbase11xsqlwriter</module>
<module>hbase11xsqlreader</module>
<module>elasticsearchwriter</module>
<module>tsdbwriter</module>
<module>adbpgwriter</module>
<module>gdbwriter</module>
<module>cassandrawriter</module>
<module>clickhousewriter</module>
<module>oscarwriter</module>
<module>oceanbasev10writer</module>
<!-- common support module -->
<module>plugin-rdbms-util</module>
<module>plugin-unstructured-storage-util</module>
<module>hbase20xsqlreader</module>
<module>hbase20xsqlwriter</module>
<module>kuduwriter</module>
<module>tdenginereader</module>
<module>hivewriter</module>
</modules>
2、修改根目录的package.xml
新增hivereader、hivewriter的打包依赖
<fileSet>
<directory>hivereader/target/datax/</directory>
<includes>
<include>**/*.*</include>
</includes>
<outputDirectory>datax</outputDirectory>
</fileSet>
<fileSet>
<directory>hivewriter/target/datax/</directory>
<includes>
<include>**/*.*</include>
</includes>
<outputDirectory>datax</outputDirectory>
</fileSet>
3、新建hivereader模块
项目结构
package.xml
<assembly
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id></id>
<formats>
<format>dir</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>src/main/resources</directory>
<includes>
<include>plugin.json</include>
<include>plugin_job_template.json</include>
</includes>
<outputDirectory>plugin/reader/hivereader</outputDirectory>
</fileSet>
<fileSet>
<directory>target/</directory>
<includes>
<include>hivereader-0.0.1-SNAPSHOT.jar</include>
</includes>
<outputDirectory>plugin/reader/hivereader</outputDirectory>
</fileSet>
<!--<fileSet>-->
<!--<directory>src/main/cpp</directory>-->
<!--<includes>-->
<!--<include>libhadoop.a</include>-->
<!--<include>libhadoop.so</include>-->
<!--<include>libhadoop.so.1.0.0</include>-->
<!--<include>libhadooppipes.a</include>-->
<!--<include>libhadooputils.a</include>-->
<!--<include>libhdfs.a</include>-->
<!--<include>libhdfs.so</include>-->
<!--<include>libhdfs.so.0.0.0</include>-->
<!--</includes>-->
<!--<outputDirectory>plugin/reader/hdfsreader/libs</outputDirectory>-->
<!--</fileSet>-->
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>false</useProjectArtifact>
<outputDirectory>plugin/reader/hivereader/libs</outputDirectory>
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>
Constant.class
package com.alibaba.datax.plugin.reader.hivereader;
public class Constant {
public final static String TEMP_DATABASE_DEFAULT = "default"; // 参考CDH的default库
public static final String TEMP_DATABSE_HDFS_LOCATION_DEFAULT = "/user/{username}/warehouse/";// 参考CDH的default库的路径
public static final String TEMP_TABLE_NAME_PREFIX="tmp_datax_hivereader_";
// public final static String HIVE_CMD_DEFAULT = "hive"; //
public final static String HIVE_SQL_SET_DEFAULT = ""; //
public final static String FIELDDELIMITER_DEFAULT = "\\u0001"; //
public final static String NULL_FORMAT_DEFAULT="\\N" ;
public static final String TEXT = "TEXT";
public static final String ORC = "ORC";
public static final String CSV = "CSV";
public static final String SEQ = "SEQ";
public static final String RC = "RC";
}
DFSUtil.class
package com.alibaba.datax.plugin.reader.hivereader;
import com.alibaba.datax.common.element.*;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordSender;
import com.alibaba.datax.common.plugin.TaskPluginCollector;
import com.alibaba.datax.common.util.Configuration;
import com.alibaba.datax.plugin.unstructuredstorage.reader.ColumnEntry;
import com.alibaba.datax.plugin.unstructuredstorage.reader.UnstructuredStorageReaderErrorCode;
import com.alibaba.datax.plugin.unstructuredstorage.reader.UnstructuredStorageReaderUtil;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.ql.io.RCFile;
import org.apache.hadoop.hive.ql.io.RCFileRecordReader;
import org.apache.hadoop.hive.ql.io.orc.OrcFile;
import org.apache.hadoop.hive.ql.io.orc.OrcInputFormat;
import org.apache.hadoop.hive.ql.io.orc.OrcSerde;
import org.apache.hadoop.hive.ql.io.orc.Reader;
import org.apache.hadoop.hive.serde2.columnar.BytesRefArrayWritable;
import org.apache.hadoop.hive.serde2.columnar.BytesRefWritable;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hadoop.util.ReflectionUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.net.URISyntaxException;
import java.nio.ByteBuffer;
import java.text.SimpleDateFormat;
import java.util.*;
public class DFSUtil {
private static final Logger LOG = LoggerFactory.getLogger(HiveReader.Job.class);
private org.apache.hadoop.conf.Configuration hadoopConf = null;
private String username = null;
private String specifiedFileType = null;
private Boolean haveKerberos = false;
private String kerberosKeytabFilePath;
private String kerberosPrincipal;
private static final int DIRECTORY_SIZE_GUESS = 16 * 1024;
public static final String HDFS_DEFAULTFS_KEY = "fs.defaultFS";
public static final String HADOOP_SECURITY_AUTHENTICATION_KEY = "hadoop.security.authentication";
public DFSUtil(Configuration taskConfig) {
hadoopConf = new org.apache.hadoop.conf.Configuration();
//io.file.buffer.size 性能参数
//http://blog.csdn.net/yangjl38/article/details/7583374
Configuration hadoopSiteParams = taskConfig.getConfiguration(Key.HADOOP_CONFIG);
JSONObject hadoopSiteParamsAsJsonObject = JSON.parseObject(taskConfig.getString(Key.HADOOP_CONFIG));
if (null != hadoopSiteParams) {
Set<String> paramKeys = hadoopSiteParams.getKeys();
for (String each : paramKeys) {
hadoopConf.set(each, hadoopSiteParamsAsJsonObject.getString(each));
}
}
hadoopConf.set(HDFS_DEFAULTFS_KEY, taskConfig.getString(Key.DEFAULT_FS));
this.username = taskConfig.getString(Key.USERNAME);
System.setProperty("HADOOP_USER_NAME", this.username);
//是否有Kerberos认证
this.haveKerberos = taskConfig.getBool(Key.HAVE_KERBEROS, false);
if (haveKerberos) {
this.kerberosKeytabFilePath = taskConfig.getString(Key.KERBEROS_KEYTAB_FILE_PATH);
this.kerberosPrincipal = taskConfig.getString(Key.KERBEROS_PRINCIPAL);
this.hadoopConf.set(HADOOP_SECURITY_AUTHENTICATION_KEY, "kerberos");
}
this.kerberosAuthentication(this.kerberosPrincipal, this.kerberosKeytabFilePath);
LOG.info(String.format("hadoopConfig details:%s", JSON.toJSONString(this.hadoopConf)));
}
private void kerberosAuthentication(String kerberosPrincipal, String kerberosKeytabFilePath) {
if (haveKerberos && StringUtils.isNotBlank(this.kerberosPrincipal) && StringUtils.isNotBlank(this.kerberosKeytabFilePath)) {
UserGroupInformation.setConfiguration(this.hadoopConf);
try {
UserGroupInformation.loginUserFromKeytab(kerberosPrincipal, kerberosKeytabFilePath);
} catch (Exception e) {
String message = String.format("kerberos认证失败,请确定kerberosKeytabFilePath[%s]和kerberosPrincipal[%s]填写正确",
kerberosKeytabFilePath, kerberosPrincipal);
throw DataXException.asDataXException(HiveReaderErrorCode.KERBEROS_LOGIN_ERROR, message, e);
}
}
}
/**
* 获取指定路径列表下符合条件的所有文件的绝对路径
*
* @param srcPaths 路径列表
* @param specifiedFileType 指定文件类型
*/
public HashSet<String> getAllFiles(List<String> srcPaths, String specifiedFileType) {
this.specifiedFileType = specifiedFileType;
if (!srcPaths.isEmpty()) {
for (String eachPath : srcPaths) {
LOG.info(String.format("get HDFS all files in path = [%s]", eachPath));
getHDFSAllFiles(eachPath);
}
}
return sourceHDFSAllFilesList;
}
private HashSet<String> sourceHDFSAllFilesList = new HashSet<String>();
public HashSet<String> getHDFSAllFiles(String hdfsPath) {
try {
FileSystem hdfs = FileSystem.get(new URI(hadoopConf.get(HDFS_DEFAULTFS_KEY)),hadoopConf,username);
//判断hdfsPath是否包含正则符号
if (hdfsPath.contains("*") || hdfsPath.contains("?")) {
Path path = new Path(hdfsPath);
FileStatus stats[] = hdfs.globStatus(path);
for (FileStatus f : stats) {
if (f.isFile()) {
if (f.getLen() == 0) {
String message = String.format("文件[%s]长度为0,将会跳过不作处理!", hdfsPath);
LOG.warn(message);
} else {
addSourceFileByType(f.getPath().toString());
}
} else if (f.isDirectory()) {
getHDFSAllFilesNORegex(f.getPath().toString(), hdfs);
}
}
} else {
getHDFSAllFilesNORegex(hdfsPath, hdfs);
}
return sourceHDFSAllFilesList;
} catch (IOException | InterruptedException | URISyntaxException e) {
String message = String.format("无法读取路径[%s]下的所有文件,请确认您的配置项fs.defaultFS, path的值是否正确," +
"是否有读写权限,网络是否已断开!", hdfsPath);
LOG.error(message);
throw DataXException.asDataXException(HiveReaderErrorCode.PATH_CONFIG_ERROR, e);
}
}
private HashSet<String> getHDFSAllFilesNORegex(String path, FileSystem hdfs) throws IOException {
// 获取要读取的文件的根目录
Path listFiles = new Path(path);
// If the network disconnected, this method will retry 45 times
// each time the retry interval for 20 seconds
// 获取要读取的文件的根目录的所有二级子文件目录
FileStatus stats[] = hdfs.listStatus(listFiles);
for (FileStatus f : stats) {
// 判断是不是目录,如果是目录,递归调用
if (f.isDirectory()) {
LOG.info(String.format("[%s] 是目录, 递归获取该目录下的文件", f.getPath().toString()));
getHDFSAllFilesNORegex(f.getPath().toString(), hdfs);
} else if (f.isFile()) {
addSourceFileByType(f.getPath().toString());
} else {
String message = String.format("该路径[%s]文件类型既不是目录也不是文件,插件自动忽略。",
f.getPath().toString());
LOG.info(message);
}
}
return sourceHDFSAllFilesList;
}
// 根据用户指定的文件类型,将指定的文件类型的路径加入sourceHDFSAllFilesList
private void addSourceFileByType(String filePath) {
// 检查file的类型和用户配置的fileType类型是否一致
boolean isMatchedFileType = checkHdfsFileType(filePath, this.specifiedFileType);
if (isMatchedFileType) {
LOG.info(String.format("[%s]是[%s]类型的文件, 将该文件加入source files列表", filePath, this.specifiedFileType));
sourceHDFSAllFilesList.add(filePath);
} else {
String message = String.format("文件[%s]的类型与用户配置的fileType类型不一致," +
"请确认您配置的目录下面所有文件的类型均为[%s]"
, filePath, this.specifiedFileType);
LOG.error(message);
throw DataXException.asDataXException(
HiveReaderErrorCode.FILE_TYPE_UNSUPPORT, message);
}
}
public InputStream getInputStream(String filepath) {
InputStream inputStream;
Path path = new Path(filepath);
try {
FileSystem fs = FileSystem.get(new URI(hadoopConf.get(HDFS_DEFAULTFS_KEY)),hadoopConf,username);
//If the network disconnected, this method will retry 45 times
//each time the retry interval for 20 seconds
inputStream = fs.open(path);
return inputStream;
} catch (IOException | URISyntaxException | InterruptedException e) {
String message = String.format("读取文件 : [%s] 时出错,请确认文件:[%s]存在且配置的用户有权限读取", filepath, filepath);
throw DataXException.asDataXException(HiveReaderErrorCode.READ_FILE_ERROR, message, e);
}
}
public void sequenceFileStartRead(String sourceSequenceFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read sequence file [%s].", sourceSequenceFilePath));
Path seqFilePath = new Path(sourceSequenceFilePath);
SequenceFile.Reader reader = null;
try {
//获取SequenceFile.Reader实例
reader = new SequenceFile.Reader(this.hadoopConf,
SequenceFile.Reader.file(seqFilePath));
//获取key 与 value
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), this.hadoopConf);
Text value = new Text();
while (reader.next(key, value)) {
if (StringUtils.isNotBlank(value.toString())) {
UnstructuredStorageReaderUtil.transportOneRecord(recordSender,
readerSliceConfig, taskPluginCollector, value.toString());
}
}
} catch (Exception e) {
String message = String.format("SequenceFile.Reader读取文件[%s]时出错", sourceSequenceFilePath);
LOG.error(message);
throw DataXException.asDataXException(HiveReaderErrorCode.READ_SEQUENCEFILE_ERROR, message, e);
} finally {
IOUtils.closeStream(reader);
LOG.info("Finally, Close stream SequenceFile.Reader.");
}
}
public void rcFileStartRead(String sourceRcFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read rcfile [%s].", sourceRcFilePath));
List<ColumnEntry> column = UnstructuredStorageReaderUtil
.getListColumnEntry(readerSliceConfig, com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN);
// warn: no default value '\N'
String nullFormat = readerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.NULL_FORMAT);
Path rcFilePath = new Path(sourceRcFilePath);
FileSystem fs = null;
RCFileRecordReader recordReader = null;
try {
fs = FileSystem.get(rcFilePath.toUri(), hadoopConf,username);
long fileLen = fs.getFileStatus(rcFilePath).getLen();
FileSplit split = new FileSplit(rcFilePath, 0, fileLen, (String[]) null);
recordReader = new RCFileRecordReader(hadoopConf, split);
LongWritable key = new LongWritable();
BytesRefArrayWritable value = new BytesRefArrayWritable();
Text txt = new Text();
while (recordReader.next(key, value)) {
String[] sourceLine = new String[value.size()];
txt.clear();
for (int i = 0; i < value.size(); i++) {
BytesRefWritable v = value.get(i);
txt.set(v.getData(), v.getStart(), v.getLength());
sourceLine[i] = txt.toString();
}
UnstructuredStorageReaderUtil.transportOneRecord(recordSender,
column, sourceLine, nullFormat, taskPluginCollector);
}
} catch (IOException | InterruptedException e) {
String message = String.format("读取文件[%s]时出错", sourceRcFilePath);
LOG.error(message);
throw DataXException.asDataXException(HiveReaderErrorCode.READ_RCFILE_ERROR, message, e);
} finally {
try {
if (recordReader != null) {
recordReader.close();
LOG.info("Finally, Close RCFileRecordReader.");
}
} catch (IOException e) {
LOG.warn(String.format("finally: 关闭RCFileRecordReader失败, %s", e.getMessage()));
}
}
}
public void orcFileStartRead(String sourceOrcFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read orcfile [%s].", sourceOrcFilePath));
List<ColumnEntry> column = UnstructuredStorageReaderUtil
.getListColumnEntry(readerSliceConfig, com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN);
String nullFormat = readerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.NULL_FORMAT);
StringBuilder allColumns = new StringBuilder();
StringBuilder allColumnTypes = new StringBuilder();
boolean isReadAllColumns = false;
int columnIndexMax = -1;
// 判断是否读取所有列
if (null == column || column.size() == 0) {
int allColumnsCount = getAllColumnsCount(sourceOrcFilePath);
columnIndexMax = allColumnsCount - 1;
isReadAllColumns = true;
} else {
columnIndexMax = getMaxIndex(column);
}
for (int i = 0; i <= columnIndexMax; i++) {
allColumns.append("col");
allColumnTypes.append("string");
if (i != columnIndexMax) {
allColumns.append(",");
allColumnTypes.append(":");
}
}
if (columnIndexMax >= 0) {
JobConf conf = new JobConf(hadoopConf);
Path orcFilePath = new Path(sourceOrcFilePath);
Properties p = new Properties();
p.setProperty("columns", allColumns.toString());
p.setProperty("columns.types", allColumnTypes.toString());
try {
OrcSerde serde = new OrcSerde();
serde.initialize(conf, p);
StructObjectInspector inspector = (StructObjectInspector) serde.getObjectInspector();
InputFormat<?, ?> in = new OrcInputFormat();
FileInputFormat.setInputPaths(conf, orcFilePath.toString());
//If the network disconnected, will retry 45 times, each time the retry interval for 20 seconds
//Each file as a split
//TODO multy threads
InputSplit[] splits = in.getSplits(conf, 1);
RecordReader reader = in.getRecordReader(splits[0], conf, Reporter.NULL);//获取reader
Object key = reader.createKey();
Object value = reader.createValue();// OrcStruct
// 获取列信息
List<? extends StructField> fields = inspector.getAllStructFieldRefs();
List<Object> recordFields;
while (reader.next(key, value)) {//next 读取数据到 value(OrcStruct)
recordFields = new ArrayList<Object>();
for (int i = 0; i <= columnIndexMax; i++) {
Object field = inspector.getStructFieldData(value, fields.get(i));//从 OrcStruct 数组中 返回对应列 数据
recordFields.add(field);
}
transportOneRecord(column, recordFields, recordSender,
taskPluginCollector, isReadAllColumns, nullFormat);
}
reader.close();
} catch (Exception e) {
String message = String.format("从orcfile文件路径[%s]中读取数据发生异常,请联系系统管理员。"
, sourceOrcFilePath);
LOG.error(message);
throw DataXException.asDataXException(HiveReaderErrorCode.READ_FILE_ERROR, message);
}
} else {
String message = String.format("请确认您所读取的列配置正确!columnIndexMax 小于0,column:%s", JSON.toJSONString(column));
throw DataXException.asDataXException(HiveReaderErrorCode.BAD_CONFIG_VALUE, message);
}
}
private Record transportOneRecord(List<ColumnEntry> columnConfigs, List<Object> recordFields
, RecordSender recordSender, TaskPluginCollector taskPluginCollector, boolean isReadAllColumns, String nullFormat) {
Record record = recordSender.createRecord();
Column columnGenerated;
try {
if (isReadAllColumns) {
// 读取所有列,创建都为String类型的column
for (Object recordField : recordFields) {
String columnValue = null;
if (recordField != null) {
columnValue = recordField.toString();
}
columnGenerated = new StringColumn(columnValue);
record.addColumn(columnGenerated);
}
} else {
for (ColumnEntry columnConfig : columnConfigs) {
String columnType = columnConfig.getType();
Integer columnIndex = columnConfig.getIndex();
String columnConst = columnConfig.getValue();
String columnValue = null;
if (null != columnIndex) {
if (null != recordFields.get(columnIndex))
columnValue = recordFields.get(columnIndex).toString();
} else {
columnValue = columnConst;
}
Type type = Type.valueOf(columnType.toUpperCase());
// it's all ok if nullFormat is null
if (StringUtils.equals(columnValue, nullFormat)) {
columnValue = null;
}
switch (type) {
case STRING:
columnGenerated = new StringColumn(columnValue);
break;
case LONG:
try {
columnGenerated = new LongColumn(columnValue);
} catch (Exception e) {
throw new IllegalArgumentException(String.format(
"类型转换错误, 无法将[%s] 转换为[%s]", columnValue,
"LONG"));
}
break;
case DOUBLE:
try {
columnGenerated = new DoubleColumn(columnValue);
} catch (Exception e) {
throw new IllegalArgumentException(String.format(
"类型转换错误, 无法将[%s] 转换为[%s]", columnValue,
"DOUBLE"));
}
break;
case BOOLEAN:
try {
columnGenerated = new BoolColumn(columnValue);
} catch (Exception e) {
throw new IllegalArgumentException(String.format(
"类型转换错误, 无法将[%s] 转换为[%s]", columnValue,
"BOOLEAN"));
}
break;
case DATE:
try {
if (columnValue == null) {
columnGenerated = new DateColumn((Date) null);
} else {
String formatString = columnConfig.getFormat();
if (StringUtils.isNotBlank(formatString)) {
// 用户自己配置的格式转换
SimpleDateFormat format = new SimpleDateFormat(
formatString);
columnGenerated = new DateColumn(
format.parse(columnValue));
} else {
// 框架尝试转换
columnGenerated = new DateColumn(
new StringColumn(columnValue)
.asDate());
}
}
} catch (Exception e) {
throw new IllegalArgumentException(String.format(
"类型转换错误, 无法将[%s] 转换为[%s]", columnValue,
"DATE"));
}
break;
default:
String errorMessage = String.format(
"您配置的列类型暂不支持 : [%s]", columnType);
LOG.error(errorMessage);
throw DataXException
.asDataXException(
UnstructuredStorageReaderErrorCode.NOT_SUPPORT_TYPE,
errorMessage);
}
record.addColumn(columnGenerated);
}
}
recordSender.sendToWriter(record);
} catch (IllegalArgumentException iae) {
taskPluginCollector
.collectDirtyRecord(record, iae.getMessage());
} catch (IndexOutOfBoundsException ioe) {
taskPluginCollector
.collectDirtyRecord(record, ioe.getMessage());
} catch (Exception e) {
if (e instanceof DataXException) {
throw (DataXException) e;
}
// 每一种转换失败都是脏数据处理,包括数字格式 & 日期格式
taskPluginCollector.collectDirtyRecord(record, e.getMessage());
}
return record;
}
private int getAllColumnsCount(String filePath) {
Path path = new Path(filePath);
try {
Reader reader = OrcFile.createReader(path, OrcFile.readerOptions(hadoopConf));
return reader.getTypes().get(0).getSubtypesCount();
} catch (IOException e) {
String message = "读取orcfile column列数失败,请联系系统管理员";
throw DataXException.asDataXException(HiveReaderErrorCode.READ_FILE_ERROR, message);
}
}
private int getMaxIndex(List<ColumnEntry> columnConfigs) {
int maxIndex = -1;
for (ColumnEntry columnConfig : columnConfigs) {
Integer columnIndex = columnConfig.getIndex();
if (columnIndex != null && columnIndex < 0) {
String message = String.format("您column中配置的index不能小于0,请修改为正确的index,column配置:%s",
JSON.toJSONString(columnConfigs));
LOG.error(message);
throw DataXException.asDataXException(HiveReaderErrorCode.CONFIG_INVALID_EXCEPTION, message);
} else if (columnIndex != null && columnIndex > maxIndex) {
maxIndex = columnIndex;
}
}
return maxIndex;
}
private enum Type {
STRING, LONG, BOOLEAN, DOUBLE, DATE,
}
public boolean checkHdfsFileType(String filepath, String specifiedFileType) {
Path file = new Path(filepath);
try {
FileSystem fs = FileSystem.get(new URI(hadoopConf.get(HDFS_DEFAULTFS_KEY)),hadoopConf,username);
FSDataInputStream in = fs.open(file);
if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.CSV)
|| StringUtils.equalsIgnoreCase(specifiedFileType, Constant.TEXT)) {
boolean isORC = isORCFile(file, fs, in);// 判断是否是 ORC File
if (isORC) {
return false;
}
boolean isRC = isRCFile(filepath, in);// 判断是否是 RC File
if (isRC) {
return false;
}
boolean isSEQ = isSequenceFile(filepath, in);// 判断是否是 Sequence File
if (isSEQ) {
return false;
}
// 如果不是ORC,RC和SEQ,则默认为是TEXT或CSV类型
return !isORC && !isRC && !isSEQ;
} else if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.ORC)) {
return isORCFile(file, fs, in);
} else if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.RC)) {
return isRCFile(filepath, in);
} else if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.SEQ)) {
return isSequenceFile(filepath, in);
}
} catch (Exception e) {
String message = String.format("检查文件[%s]类型失败,目前支持ORC,SEQUENCE,RCFile,TEXT,CSV五种格式的文件," +
"请检查您文件类型和文件是否正确。", filepath);
LOG.error(message);
throw DataXException.asDataXException(HiveReaderErrorCode.READ_FILE_ERROR, message, e);
}
return false;
}
// 判断file是否是ORC File
private boolean isORCFile(Path file, FileSystem fs, FSDataInputStream in) {
try {
// figure out the size of the file using the option or filesystem
long size = fs.getFileStatus(file).getLen();
//read last bytes into buffer to get PostScript
int readSize = (int) Math.min(size, DIRECTORY_SIZE_GUESS);
in.seek(size - readSize);
ByteBuffer buffer = ByteBuffer.allocate(readSize);
in.readFully(buffer.array(), buffer.arrayOffset() + buffer.position(),
buffer.remaining());
//read the PostScript
//get length of PostScript
int psLen = buffer.get(readSize - 1) & 0xff;
int len = OrcFile.MAGIC.length();
if (psLen < len + 1) {
return false;
}
int offset = buffer.arrayOffset() + buffer.position() + buffer.limit() - 1
- len;
byte[] array = buffer.array();
// now look for the magic string at the end of the postscript.
if (Text.decode(array, offset, len).equals(OrcFile.MAGIC)) {
return true;
} else {
// If it isn't there, this may be the 0.11.0 version of ORC.
// Read the first 3 bytes of the file to check for the header
in.seek(0);
byte[] header = new byte[len];
in.readFully(header, 0, len);
// if it isn't there, this isn't an ORC file
if (Text.decode(header, 0, len).equals(OrcFile.MAGIC)) {
return true;
}
}
} catch (IOException e) {
LOG.info(String.format("检查文件类型: [%s] 不是ORC File.", file.toString()));
}
return false;
}
// 判断file是否是RC file
private boolean isRCFile(String filepath, FSDataInputStream in) {
// The first version of RCFile used the sequence file header.
final byte[] ORIGINAL_MAGIC = new byte[]{(byte) 'S', (byte) 'E', (byte) 'Q'};
// The 'magic' bytes at the beginning of the RCFile
final byte[] RC_MAGIC = new byte[]{(byte) 'R', (byte) 'C', (byte) 'F'};
// the version that was included with the original magic, which is mapped
// into ORIGINAL_VERSION
final byte ORIGINAL_MAGIC_VERSION_WITH_METADATA = 6;
// All of the versions should be place in this list.
final int ORIGINAL_VERSION = 0; // version with SEQ
final int NEW_MAGIC_VERSION = 1; // version with RCF
final int CURRENT_VERSION = NEW_MAGIC_VERSION;
byte version;
byte[] magic = new byte[RC_MAGIC.length];
try {
in.seek(0);
in.readFully(magic);
if (Arrays.equals(magic, ORIGINAL_MAGIC)) {
byte vers = in.readByte();
if (vers != ORIGINAL_MAGIC_VERSION_WITH_METADATA) {
return false;
}
version = ORIGINAL_VERSION;
} else {
if (!Arrays.equals(magic, RC_MAGIC)) {
return false;
}
// Set 'version'
version = in.readByte();
if (version > CURRENT_VERSION) {
return false;
}
}
if (version == ORIGINAL_VERSION) {
try {
Class<?> keyCls = hadoopConf.getClassByName(Text.readString(in));
Class<?> valCls = hadoopConf.getClassByName(Text.readString(in));
if (!keyCls.equals(RCFile.KeyBuffer.class)
|| !valCls.equals(RCFile.ValueBuffer.class)) {
return false;
}
} catch (ClassNotFoundException e) {
return false;
}
}
boolean decompress = in.readBoolean(); // is compressed?
if (version == ORIGINAL_VERSION) {
// is block-compressed? it should be always false.
boolean blkCompressed = in.readBoolean();
if (blkCompressed) {
return false;
}
}
return true;
} catch (IOException e) {
LOG.info(String.format("检查文件类型: [%s] 不是RC File.", filepath));
}
return false;
}
// 判断file是否是Sequence file
private boolean isSequenceFile(String filepath, FSDataInputStream in) {
byte[] SEQ_MAGIC = new byte[]{(byte) 'S', (byte) 'E', (byte) 'Q'};
byte[] magic = new byte[SEQ_MAGIC.length];
try {
in.seek(0);
in.readFully(magic);
if (Arrays.equals(magic, SEQ_MAGIC)) {
return true;
} else {
return false;
}
} catch (IOException e) {
LOG.info(String.format("检查文件类型: [%s] 不是Sequence File.", filepath));
}
return false;
}
}
HiveReader.class
package com.alibaba.datax.plugin.reader.hivereader;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordSender;
import com.alibaba.datax.common.spi.Reader;
import com.alibaba.datax.common.util.Configuration;
import com.alibaba.datax.plugin.unstructuredstorage.reader.UnstructuredStorageReaderUtil;
import org.apache.commons.lang.StringEscapeUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashSet;
import java.util.List;
public class HiveReader extends Reader {
/**
* Job 中的方法仅执行一次,Task 中方法会由框架启动多个 Task 线程并行执行。
* <p/>
* 整个 Reader 执行流程是:
* <pre>
* Job类init-->prepare-->split
*
* Task类init-->prepare-->startRead-->post-->destroy
* Task类init-->prepare-->startRead-->post-->destroy
*
* Job类post-->destroy
* </pre>
*/
public static class Job extends Reader.Job {
private static final Logger LOG = LoggerFactory.getLogger(Job.class);
private Configuration readerOriginConfig = null;
@Override
public void init() {
LOG.info("init() begin...");
this.readerOriginConfig = super.getPluginJobConf();//获取配置文件信息{parameter 里面的参数}
this.validate();
LOG.info("init() ok and end...");
LOG.info("HiveReader流程说明[1:Reader的HiveQL导入临时表(TextFile无压缩的HDFS) ;2:临时表的HDFS到目标Writer;3:删除临时表]");
}
private void validate() {
this.readerOriginConfig.getNecessaryValue(Key.DEFAULT_FS,
HiveReaderErrorCode.DEFAULT_FS_NOT_FIND_ERROR);
List<String> sqls = this.readerOriginConfig.getList(Key.HIVE_SQL, String.class);
if (null == sqls || sqls.size() == 0) {
throw DataXException.asDataXException(
HiveReaderErrorCode.SQL_NOT_FIND_ERROR,
"您未配置hive sql");
}
//check Kerberos
Boolean haveKerberos = this.readerOriginConfig.getBool(Key.HAVE_KERBEROS, false);
if (haveKerberos) {
this.readerOriginConfig.getNecessaryValue(Key.KERBEROS_KEYTAB_FILE_PATH, HiveReaderErrorCode.REQUIRED_VALUE);
this.readerOriginConfig.getNecessaryValue(Key.KERBEROS_PRINCIPAL, HiveReaderErrorCode.REQUIRED_VALUE);
}
}
@Override
public List<Configuration> split(int adviceNumber) {
//按照Hive sql的个数 获取配置文件的个数
LOG.info("split() begin...");
List<String> sqls = this.readerOriginConfig.getList(Key.HIVE_SQL, String.class);
List<Configuration> readerSplitConfigs = new ArrayList<Configuration>();
Configuration splitedConfig = null;
for (String querySql : sqls) {
splitedConfig = this.readerOriginConfig.clone();
splitedConfig.set(Key.HIVE_SQL, querySql);
readerSplitConfigs.add(splitedConfig);
}
return readerSplitConfigs;
}
//全局post
@Override
public void post() {
LOG.info("任务执行完毕,hive reader post");
}
@Override
public void destroy() {
}
}
public static class Task extends Reader.Task {
private static final Logger LOG = LoggerFactory.getLogger(Task.class);
private Configuration taskConfig;
private String hiveSql;
private String hiveJdbcUrl;
private String username;
private String password;
private String tmpPath;
private String tableName;
private String tempDatabase;
private String tempHdfsLocation;
// private String hive_cmd;
private String hive_sql_set;
private String fieldDelimiter;
private String nullFormat;
private String hive_fieldDelimiter;
private DFSUtil dfsUtil = null;
private HashSet<String> sourceFiles;
@Override
public void init() {
this.tableName = hiveTableName();
//获取配置
this.taskConfig = super.getPluginJobConf();//获取job 分割后的每一个任务单独的配置文件
this.hiveSql = taskConfig.getString(Key.HIVE_SQL);//获取hive sql
this.hiveJdbcUrl = taskConfig.getString(Key.HIVE_JDBC_URL);//获取hive jdbcUrl
this.username = taskConfig.getString(Key.USERNAME);//获取hive 用户名
this.password = taskConfig.getString(Key.PASSWORD);//获取hive 密码
this.tempDatabase = taskConfig.getString(Key.TEMP_DATABASE, Constant.TEMP_DATABASE_DEFAULT);// 临时表的数据库
this.tempHdfsLocation = taskConfig.getString(Key.TEMP_DATABASE_HDFS_LOCATION,
Constant.TEMP_DATABSE_HDFS_LOCATION_DEFAULT.replace("{username}", this.username));// 临时表的数据库路径
// this.hive_cmd = taskConfig.getString(Key.HIVE_CMD, Constant.HIVE_CMD_DEFAULT);
this.hive_sql_set = taskConfig.getString(Key.HIVE_SQL_SET, Constant.HIVE_SQL_SET_DEFAULT);
//判断set语句的结尾是否是分号,不是给加一个
if (!this.hive_sql_set.trim().endsWith(";")) {
this.hive_sql_set = this.hive_sql_set + ";";
}
this.fieldDelimiter = taskConfig.getString(Key.FIELDDELIMITER, Constant.FIELDDELIMITER_DEFAULT);
this.hive_fieldDelimiter = this.fieldDelimiter;
this.fieldDelimiter = StringEscapeUtils.unescapeJava(this.fieldDelimiter);
this.taskConfig.set(Key.FIELDDELIMITER, this.fieldDelimiter);//设置hive 存储文件 hdfs默认的分隔符,传输时候会分隔
this.nullFormat = taskConfig.getString(Key.NULL_FORMAT, Constant.NULL_FORMAT_DEFAULT);
this.taskConfig.set(Key.NULL_FORMAT, this.nullFormat);
//判断set语句的结尾是否是分号,不是给加一个
if (!this.tempHdfsLocation.trim().endsWith("/")) {
this.tempHdfsLocation = this.tempHdfsLocation + "/";
}
this.tmpPath = this.tempHdfsLocation + this.tableName;//创建临时Hive表 存储地址
LOG.info("配置分隔符后:" + this.taskConfig.toJSON());
this.dfsUtil = new DFSUtil(this.taskConfig);//初始化工具类
}
@Override
public void prepare() {
//创建临时Hive表,指定存储地址
String hiveQueryCmd = this.hive_sql_set + " use " + this.tempDatabase + "; create table "
+ this.tableName + " ROW FORMAT DELIMITED FIELDS TERMINATED BY '" + this.hive_fieldDelimiter
+ "' STORED AS TEXTFILE "
+ " as " + this.hiveSql;
LOG.info("hiveCmd ----> :" + hiveQueryCmd);
// String[] cmd = new String[]{this.hive_cmd, "-e", "\"" + hiveQueryCmd + " \""};
// LOG.info(cmd.toString());
//执行脚本,创建临时表
if (!HiveServer2ConnectUtil.execHiveSql(this.username, this.password, hiveQueryCmd, this.hiveJdbcUrl)) {
throw DataXException.asDataXException(
HiveReaderErrorCode.SHELL_ERROR,
"创建hive临时表脚本执行失败");
}
// if (!ShellUtil.exec(new String[]{this.hive_cmd, " -e", "\"" + hiveQueryCmd + " \""})) {
// throw DataXException.asDataXException(
// HiveReaderErrorCode.SHELL_ERROR,
// "创建hive临时表脚本执行失败");
// }
LOG.info("创建hive 临时表结束 end!!!");
LOG.info("prepare(), start to getAllFiles...");
List<String> path = new ArrayList<String>();
path.add(tmpPath);
this.sourceFiles = dfsUtil.getAllFiles(path, Constant.TEXT);
LOG.info(String.format("您即将读取的文件数为: [%s], 列表为: [%s]",
this.sourceFiles.size(),
StringUtils.join(this.sourceFiles, ",")));
}
@Override
public void startRead(RecordSender recordSender) {
//读取临时hive表的hdfs文件
LOG.info("read start");
for (String sourceFile : this.sourceFiles) {
LOG.info(String.format("reading file : [%s]", sourceFile));
//默认读取的是TEXT文件格式
InputStream inputStream = dfsUtil.getInputStream(sourceFile);
UnstructuredStorageReaderUtil.readFromStream(inputStream, sourceFile, this.taskConfig,
recordSender, this.getTaskPluginCollector());
if (recordSender != null) {
recordSender.flush();
}
}
LOG.info("end read source files...");
}
//只是局部post 属于每个task
@Override
public void post() {
LOG.info("one task hive read post...");
deleteTmpTable();
}
private void deleteTmpTable() {
String hiveCmd = this.hive_sql_set + " use " + this.tempDatabase + "; drop table if exists " + this.tableName;
LOG.info("清空数据:hiveCmd ----> :" + hiveCmd);
//执行脚本,删除临时表
if (!HiveServer2ConnectUtil.execHiveSql(this.username, this.password, hiveCmd, this.hiveJdbcUrl)) {
throw DataXException.asDataXException(
HiveReaderErrorCode.SHELL_ERROR,
"删除hive临时表脚本执行失败");
}
// if (!ShellUtil.exec(new String[]{this.hive_cmd, "-e", "\"" + hiveCmd + "\""})) {
// throw DataXException.asDataXException(
// HiveReaderErrorCode.SHELL_ERROR,
// "删除hive临时表脚本执行失败");
// }
}
@Override
public void destroy() {
LOG.info("hive read destroy...");
}
//创建hive临时表名称
private String hiveTableName() {
StringBuilder str = new StringBuilder();
FastDateFormat fdf = FastDateFormat.getInstance("yyyyMMdd");
str.append(Constant.TEMP_TABLE_NAME_PREFIX)
.append(fdf.format(new Date()))
.append("_")
.append(System.currentTimeMillis());
// .append("_").append(KeyUtil.genUniqueKey());
return str.toString().toLowerCase();
}
}
}
HiveReaderErrorCode.class
package com.alibaba.datax.plugin.reader.hivereader;
import com.alibaba.datax.common.spi.ErrorCode;
public enum HiveReaderErrorCode implements ErrorCode {
BAD_CONFIG_VALUE("HiveReader-00", "您配置的值不合法."),
SQL_NOT_FIND_ERROR("HiveReader-01", "您未配置hive sql"),
DEFAULT_FS_NOT_FIND_ERROR("HiveReader-02", "您未配置defaultFS值"),
ILLEGAL_VALUE("HiveReader-03", "值错误"),
CONFIG_INVALID_EXCEPTION("HiveReader-04", "参数配置错误"),
REQUIRED_VALUE("HiveReader-05", "您缺失了必须填写的参数值."),
SHELL_ERROR("HiveReader-06", "hive 脚本执行失败."),
PATH_CONFIG_ERROR("HdfsReader-09", "您配置的path格式有误"),
READ_FILE_ERROR("HdfsReader-10", "读取文件出错"),
FILE_TYPE_UNSUPPORT("HdfsReader-12", "文件类型目前不支持"),
KERBEROS_LOGIN_ERROR("HdfsReader-13", "KERBEROS认证失败"),
READ_SEQUENCEFILE_ERROR("HdfsReader-14", "读取SequenceFile文件出错"),
READ_RCFILE_ERROR("HdfsReader-15", "读取RCFile文件出错"),;
;
private final String code;
private final String description;
private HiveReaderErrorCode(String code, String description) {
this.code = code;
this.description = description;
}
@Override
public String getCode() {
return this.code;
}
@Override
public String getDescription() {
return this.description;
}
@Override
public String toString() {
return String.format("Code:[%s], Description:[%s]. ", this.code,
this.description);
}
}
HiveServer2ConnectUtil.class
package com.alibaba.datax.plugin.reader.hivereader;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class HiveServer2ConnectUtil {
private static final Logger LOG = LoggerFactory.getLogger(HiveServer2ConnectUtil.class);
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) {
execHiveSql("hive", null,
"; use default; create table tmp_datax_hivereader_20220808_1659953092709 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\u0001' STORED AS TEXTFILE as select id,username,password from default.t_user;",
"jdbc:hive2://10.252.92.4:10000");
}
/**
* hive执行多个sql
*
* @param username
* @param password
* @param hiveSql
* @param hiveJdbcUrl
* @return
*/
public static boolean execHiveSql(String username, String password, String hiveSql, String hiveJdbcUrl) {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
try {
LOG.info("hiveJdbcUrl:{}", hiveJdbcUrl);
LOG.info("username:{}", username);
LOG.info("password:{}", password);
Connection conn = DriverManager.getConnection(hiveJdbcUrl, username, password);
Statement stmt = conn.createStatement();
String[] hiveSqls = hiveSql.split(";");
for (int i = 0; i < hiveSqls.length; i++) {
if (StringUtils.isNotEmpty(hiveSqls[i])) {
stmt.execute(hiveSqls[i]);
}
}
return true;
} catch (SQLException sqlException) {
LOG.error(sqlException.getMessage(), sqlException);
return false;
}
}
}
Key.class
package com.alibaba.datax.plugin.reader.hivereader;
public class Key {
/**
* 1.必选:hiveSql,defaultFS
* 2.可选(有缺省值):
* tempDatabase(default)
* tempHdfsLocation(/tmp/hive/)
* hive_cmd(hive)
* fieldDelimiter(\u0001)
* 3.可选(无缺省值):hive_sql_set
*/
public final static String DEFAULT_FS = "defaultFS";
// reader执行的hiveSql语句
public final static String HIVE_SQL = "hiveSql";
// hive的Jdbc链接
public final static String HIVE_JDBC_URL = "hiveJdbcUrl";
// hive的用户名
public final static String USERNAME = "username";
// hive的密码
public final static String PASSWORD = "password";
// 临时表所在的数据库名称
public final static String TEMP_DATABASE = "tempDatabase";
// 临时标存放的HDFS目录
public final static String TEMP_DATABASE_HDFS_LOCATION = "tempDatabasePath";
// hive -e命令
public final static String HIVE_CMD = "hive_cmd";
public final static String HIVE_SQL_SET = "hive_sql_set";
// 存储文件 hdfs默认的分隔符
public final static String FIELDDELIMITER = "fieldDelimiter";
public static final String NULL_FORMAT = "nullFormat";
public static final String HADOOP_CONFIG = "hadoopConfig";
public static final String HAVE_KERBEROS = "haveKerberos";
public static final String KERBEROS_KEYTAB_FILE_PATH = "kerberosKeytabFilePath";
public static final String KERBEROS_PRINCIPAL = "kerberosPrincipal";
}
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>datax-all</artifactId>
<groupId>com.alibaba.datax</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>hivereader</artifactId>
<properties>
<hive.version>2.1.1</hive.version>
<hadoop.version>2.7.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>datax-common</artifactId>
<version>${datax-project-version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-serde</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive.hcatalog</groupId>
<artifactId>hive-hcatalog-core</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>plugin-unstructured-storage-util</artifactId>
<version>${datax-project-version}</version>
</dependency>
<!--<!– https://mvnrepository.com/artifact/org.pentaho/pentaho-aggdesigner-algorithm –>-->
<!--<dependency>-->
<!--<groupId>org.pentaho</groupId>-->
<!--<artifactId>pentaho-aggdesigner-algorithm</artifactId>-->
<!--<version>5.1.5-jhyde</version>-->
<!--<!–<scope>test</scope>–>-->
<!--</dependency>-->
<!--<!– https://mvnrepository.com/artifact/eigenbase/eigenbase-properties –>-->
<!--<dependency>-->
<!--<groupId>com.grgbanking.eigenbase</groupId>-->
<!--<artifactId>eigenbase</artifactId>-->
<!--<version>1.1.7</version>-->
<!--</dependency>-->
</dependencies>
<build>
<plugins>
<!-- compiler plugin -->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>${project-sourceEncoding}</encoding>
</configuration>
</plugin>
<!-- assembly plugin -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/main/assembly/package.xml</descriptor>
</descriptors>
<finalName>datax</finalName>
</configuration>
<executions>
<execution>
<id>dwzip</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
plugin_job_template.json
{
"name": "hivereader",
"parameter": {
"defaultFS": "hdfs://:",
"hiveJdbcUrl": "jdbc:hive2://",
"username": "hive",
"hiveSql": [
"select id,username,password from default.t_user;"
]
}
}
4、新建hivewriter模块
项目结构
package.xml
<assembly
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id></id>
<formats>
<format>dir</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>src/main/resources</directory>
<includes>
<include>plugin.json</include>
</includes>
<outputDirectory>plugin/writer/hivewriter</outputDirectory>
</fileSet>
<fileSet>
<directory>target/</directory>
<includes>
<include>hivewriter-0.0.1-SNAPSHOT.jar</include>
</includes>
<outputDirectory>plugin/writer/hivewriter</outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>false</useProjectArtifact>
<outputDirectory>plugin/writer/hivewriter/libs</outputDirectory>
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>
Constans.class
package com.alibaba.datax.plugin.writer.hivewriter;
public class Constants {
public static final String TEMP_TABLE_NAME_PREFIX_DEFAULT="tmp_datax_hivewriter_";
public final static String HIVE_CMD_DEFAULT = "hive";
public final static String HIVE_SQL_SET_DEFAULT = "";
public final static String HIVE_TARGET_TABLE_COMPRESS_SQL= "";
public static final String WRITE_MODE_DEFAULT="insert";
public final static String HIVE_PRESQL_DEFAULT = "";
public final static String HIVE_POSTSQL_DEFAULT = "";
public static final String INSERT_PRE_SQL="SET hive.exec.dynamic.partition=true;"
+"SET hive.exec.dynamic.partition.mode=nonstrict;"
+"SET hive.exec.max.dynamic.partitions.pernode=100000;"
+"SET hive.exec.max.dynamic.partitions=100000;";
public final static String FIELDDELIMITER_DEFAULT = "\\u0001";
public final static String COMPRESS_DEFAULT="gzip";
// 此默认值,暂无使用
public static final String DEFAULT_NULL_FORMAT = "\\N";
}
HdfsHelper.class
package com.alibaba.datax.plugin.writer.hivewriter;
import com.alibaba.datax.common.element.Column;
import com.alibaba.datax.common.element.Record;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordReceiver;
import com.alibaba.datax.common.plugin.TaskPluginCollector;
import com.alibaba.datax.common.util.Configuration;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.google.common.collect.Lists;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.tuple.MutablePair;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat;
import org.apache.hadoop.hive.ql.io.orc.OrcSerde;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.security.UserGroupInformation;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.text.SimpleDateFormat;
import java.util.*;
public class HdfsHelper {
public static final Logger LOG = LoggerFactory.getLogger(HiveWriter.Job.class);
public FileSystem fileSystem = null;
public JobConf conf = null;
public org.apache.hadoop.conf.Configuration hadoopConf = null;
public static final String HADOOP_SECURITY_AUTHENTICATION_KEY = "hadoop.security.authentication";
public static final String HDFS_DEFAULTFS_KEY = "fs.defaultFS";
private String username = null;
// Kerberos
private Boolean haveKerberos = false;
private String kerberosKeytabFilePath;
private String kerberosPrincipal;
public void getFileSystem(String defaultFS, Configuration taskConfig) {
hadoopConf = new org.apache.hadoop.conf.Configuration();
Configuration hadoopSiteParams = taskConfig.getConfiguration(Key.HADOOP_CONFIG);
JSONObject hadoopSiteParamsAsJsonObject = JSON.parseObject(taskConfig.getString(Key.HADOOP_CONFIG));
if (null != hadoopSiteParams) {
Set<String> paramKeys = hadoopSiteParams.getKeys();
for (String each : paramKeys) {
hadoopConf.set(each, hadoopSiteParamsAsJsonObject.getString(each));
}
}
hadoopConf.set(HDFS_DEFAULTFS_KEY, defaultFS);
this.username = taskConfig.getString(Key.USERNAME);
System.setProperty("HADOOP_USER_NAME", this.username);
//是否有Kerberos认证
this.haveKerberos = taskConfig.getBool(Key.HAVE_KERBEROS, false);
if (haveKerberos) {
this.kerberosKeytabFilePath = taskConfig.getString(Key.KERBEROS_KEYTAB_FILE_PATH);
this.kerberosPrincipal = taskConfig.getString(Key.KERBEROS_PRINCIPAL);
hadoopConf.set(HADOOP_SECURITY_AUTHENTICATION_KEY, "kerberos");
}
this.kerberosAuthentication(this.kerberosPrincipal, this.kerberosKeytabFilePath);
conf = new JobConf(hadoopConf);
conf.setUser(this.username);
try {
LOG.info("defaultFS:{},user:{}", defaultFS, this.username);
fileSystem = FileSystem.get(new URI(hadoopConf.get(HDFS_DEFAULTFS_KEY)), conf, this.username);
} catch (IOException e) {
String message = String.format("获取FileSystem时发生网络IO异常,请检查您的网络是否正常!HDFS地址:[%s]",
"message:defaultFS =" + defaultFS);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
} catch (Exception e) {
String message = String.format("获取FileSystem失败,请检查HDFS地址是否正确: [%s]",
"message:defaultFS =" + defaultFS);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
if (null == fileSystem || null == conf) {
String message = String.format("获取FileSystem失败,请检查HDFS地址是否正确: [%s]",
"message:defaultFS =" + defaultFS);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, message);
}
}
private void kerberosAuthentication(String kerberosPrincipal, String kerberosKeytabFilePath) {
if (haveKerberos && StringUtils.isNotBlank(this.kerberosPrincipal) && StringUtils.isNotBlank(this.kerberosKeytabFilePath)) {
UserGroupInformation.setConfiguration(this.hadoopConf);
try {
UserGroupInformation.loginUserFromKeytab(kerberosPrincipal, kerberosKeytabFilePath);
} catch (Exception e) {
String message = String.format("kerberos认证失败,请确定kerberosKeytabFilePath[%s]和kerberosPrincipal[%s]填写正确",
kerberosKeytabFilePath, kerberosPrincipal);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.KERBEROS_LOGIN_ERROR, e);
}
}
}
/**
* 获取指定目录先的文件列表
*
* @param dir
* @return 拿到的是文件全路径,
*/
public String[] hdfsDirList(String dir) {
Path path = new Path(dir);
String[] files = null;
try {
FileStatus[] status = fileSystem.listStatus(path);
files = new String[status.length];
for(int i=0;i<status.length;i++){
files[i] = status[i].getPath().toString();
}
} catch (IOException e) {
String message = String.format("获取目录[%s]文件列表时发生网络IO异常,请检查您的网络是否正常!", dir);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
return files;
}
/**
* 获取以fileName__ 开头的文件列表
*
* @param dir
* @param fileName
* @return
*/
public Path[] hdfsDirList(String dir, String fileName) {
Path path = new Path(dir);
Path[] files = null;
String filterFileName = fileName + "__*";
try {
PathFilter pathFilter = new GlobFilter(filterFileName);
FileStatus[] status = fileSystem.listStatus(path,pathFilter);
files = new Path[status.length];
for(int i=0;i<status.length;i++){
files[i] = status[i].getPath();
}
} catch (IOException e) {
String message = String.format("获取目录[%s]下文件名以[%s]开头的文件列表时发生网络IO异常,请检查您的网络是否正常!",
dir,fileName);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
return files;
}
public boolean isPathexists(String filePath) {
Path path = new Path(filePath);
boolean exist = false;
try {
exist = fileSystem.exists(path);
} catch (IOException e) {
String message = String.format("判断文件路径[%s]是否存在时发生网络IO异常,请检查您的网络是否正常!",
"message:filePath =" + filePath);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
return exist;
}
public boolean isPathDir(String filePath) {
Path path = new Path(filePath);
boolean isDir = false;
try {
isDir = fileSystem.isDirectory(path);
} catch (IOException e) {
String message = String.format("判断路径[%s]是否是目录时发生网络IO异常,请检查您的网络是否正常!", filePath);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
return isDir;
}
public void deleteFiles(Path[] paths){
for(int i=0;i<paths.length;i++){
LOG.info(String.format("delete file [%s].", paths[i].toString()));
try {
fileSystem.delete(paths[i],true);
} catch (IOException e) {
String message = String.format("删除文件[%s]时发生IO异常,请检查您的网络是否正常!",
paths[i].toString());
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
}
}
public void deleteDir(Path path){
LOG.info(String.format("start delete tmp dir [%s] .",path.toString()));
try {
if(isPathexists(path.toString())) {
fileSystem.delete(path, true);
}
} catch (Exception e) {
String message = String.format("删除临时目录[%s]时发生IO异常,请检查您的网络是否正常!", path.toString());
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
LOG.info(String.format("finish delete tmp dir [%s] .",path.toString()));
}
public void renameFile(HashSet<String> tmpFiles, HashSet<String> endFiles) {
Path tmpFilesParent = null;
if (tmpFiles.size() != endFiles.size()) {
String message = String.format("临时目录下文件名个数与目标文件名个数不一致!");
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.HDFS_RENAME_FILE_ERROR, message);
} else {
try {
for (Iterator it1 = tmpFiles.iterator(), it2 = endFiles.iterator(); it1.hasNext() && it2.hasNext(); ) {
String srcFile = it1.next().toString();
String dstFile = it2.next().toString();
Path srcFilePah = new Path(srcFile);
Path dstFilePah = new Path(dstFile);
if (tmpFilesParent == null) {
tmpFilesParent = srcFilePah.getParent();
}
LOG.info(String.format("start rename file [%s] to file [%s].", srcFile, dstFile));
boolean renameTag = false;
long fileLen = fileSystem.getFileStatus(srcFilePah).getLen();
if (fileLen > 0) {
renameTag = fileSystem.rename(srcFilePah, dstFilePah);
if (!renameTag) {
String message = String.format("重命名文件[%s]失败,请检查您的网络是否正常!", srcFile);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.HDFS_RENAME_FILE_ERROR, message);
}
LOG.info(String.format("finish rename file [%s] to file [%s].", srcFile, dstFile));
} else {
LOG.info(String.format("文件[%s]内容为空,请检查写入是否正常!", srcFile));
}
}
} catch (Exception e) {
String message = String.format("重命名文件时发生异常,请检查您的网络是否正常!");
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
} finally {
deleteDir(tmpFilesParent);
}
}
}
//关闭FileSystem
public void closeFileSystem(){
try {
fileSystem.close();
} catch (IOException e) {
String message = String.format("关闭FileSystem时发生IO异常,请检查您的网络是否正常!");
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.CONNECT_HDFS_IO_ERROR, e);
}
}
//textfile格式文件
public FSDataOutputStream getOutputStream(String path){
Path storePath = new Path(path);
FSDataOutputStream fSDataOutputStream = null;
try {
fSDataOutputStream = fileSystem.create(storePath);
} catch (IOException e) {
String message = String.format("Create an FSDataOutputStream at the indicated Path[%s] failed: [%s]",
"message:path =" + path);
LOG.error(message);
throw DataXException.asDataXException(HiveWriterErrorCode.Write_FILE_IO_ERROR, e);
}
return fSDataOutputStream;
}
/**
* 写textfile类型文件
*
* @param lineReceiver
* @param config
* @param fileName
* @param taskPluginCollector
*/
public void textFileStartWrite(RecordReceiver lineReceiver, Configuration config, String fileName,
TaskPluginCollector taskPluginCollector) {
char fieldDelimiter = config.getChar(Key.FIELD_DELIMITER);
List<Configuration> columns = config.getListConfiguration(Key.COLUMN);
String compress = config.getString(Key.COMPRESS, null);
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMMddHHmm");
String attempt = "attempt_" + dateFormat.format(new Date()) + "_0001_m_000000_0";
Path outputPath = new Path(fileName);
//todo 需要进一步确定TASK_ATTEMPT_ID
conf.set(JobContext.TASK_ATTEMPT_ID, attempt);
FileOutputFormat outFormat = new TextOutputFormat();
outFormat.setOutputPath(conf, outputPath);
outFormat.setWorkOutputPath(conf, outputPath);
if (null != compress) {
Class<? extends CompressionCodec> codecClass = getCompressCodec(compress);
if (null != codecClass) {
outFormat.setOutputCompressorClass(conf, codecClass);
}
}
try {
RecordWriter writer = outFormat.getRecordWriter(fileSystem, conf, outputPath.toString(), Reporter.NULL);
Record record = null;
while ((record = lineReceiver.getFromReader()) != null) {
MutablePair<Text, Boolean> transportResult = transportOneRecord(record, fieldDelimiter, columns, taskPluginCollector,config);
if (!transportResult.getRight()) {
writer.write(NullWritable.get(),transportResult.getLeft());
}
}
writer.close(Reporter.NULL);
} catch (Exception e) {
String message = String.format("写文件文件[%s]时发生IO异常,请检查您的网络是否正常!", fileName);
LOG.error(message);
Path path = new Path(fileName);
deleteDir(path.getParent());
throw DataXException.asDataXException(HiveWriterErrorCode.Write_FILE_IO_ERROR, e);
}
}
public static MutablePair<Text, Boolean> transportOneRecord(
Record record, char fieldDelimiter, List<Configuration> columnsConfiguration, TaskPluginCollector taskPluginCollector, Configuration config) {
MutablePair<List<Object>, Boolean> transportResultList = transportOneRecord(record, columnsConfiguration, taskPluginCollector, config);
//保存<转换后的数据,是否是脏数据>
MutablePair<Text, Boolean> transportResult = new MutablePair<Text, Boolean>();
transportResult.setRight(false);
if (null != transportResultList) {
Text recordResult = new Text(StringUtils.join(transportResultList.getLeft(), fieldDelimiter));
transportResult.setRight(transportResultList.getRight());
transportResult.setLeft(recordResult);
}
return transportResult;
}
public Class<? extends CompressionCodec> getCompressCodec(String compress) {
Class<? extends CompressionCodec> codecClass = null;
if (null == compress) {
codecClass = null;
} else if ("GZIP".equalsIgnoreCase(compress)) {
codecClass = org.apache.hadoop.io.compress.GzipCodec.class;
} else if ("BZIP2".equalsIgnoreCase(compress)) {
codecClass = org.apache.hadoop.io.compress.BZip2Codec.class;
} else if ("SNAPPY".equalsIgnoreCase(compress)) {
//todo 等需求明确后支持 需要用户安装SnappyCodec
codecClass = org.apache.hadoop.io.compress.SnappyCodec.class;
// org.apache.hadoop.hive.ql.io.orc.ZlibCodec.class not public
//codecClass = org.apache.hadoop.hive.ql.io.orc.ZlibCodec.class;
} else {
throw DataXException.asDataXException(HiveWriterErrorCode.ILLEGAL_VALUE,
String.format("目前不支持您配置的 compress 模式 : [%s]", compress));
}
return codecClass;
}
/**
* 写orcfile类型文件
*
* @param lineReceiver
* @param config
* @param fileName
* @param taskPluginCollector
*/
public void orcFileStartWrite(RecordReceiver lineReceiver, Configuration config, String fileName,
TaskPluginCollector taskPluginCollector) {
List<Configuration> columns = config.getListConfiguration(Key.COLUMN);
String compress = config.getString(Key.COMPRESS, null);
List<String> columnNames = getColumnNames(columns);
List<ObjectInspector> columnTypeInspectors = getColumnTypeInspectors(columns);
StructObjectInspector inspector = (StructObjectInspector) ObjectInspectorFactory
.getStandardStructObjectInspector(columnNames, columnTypeInspectors);
OrcSerde orcSerde = new OrcSerde();
FileOutputFormat outFormat = new OrcOutputFormat();
if (!"NONE".equalsIgnoreCase(compress) && null != compress) {
Class<? extends CompressionCodec> codecClass = getCompressCodec(compress);
if (null != codecClass) {
outFormat.setOutputCompressorClass(conf, codecClass);
}
}
try {
RecordWriter writer = outFormat.getRecordWriter(fileSystem, conf, fileName, Reporter.NULL);
Record record = null;
while ((record = lineReceiver.getFromReader()) != null) {
MutablePair<List<Object>, Boolean> transportResult = transportOneRecord(record, columns, taskPluginCollector, config);
if (!transportResult.getRight()) {
writer.write(NullWritable.get(), orcSerde.serialize(transportResult.getLeft(), inspector));
}
}
writer.close(Reporter.NULL);
} catch (Exception e) {
String message = String.format("写文件文件[%s]时发生IO异常,请检查您的网络是否正常!", fileName);
LOG.error(message);
Path path = new Path(fileName);
deleteDir(path.getParent());
throw DataXException.asDataXException(HiveWriterErrorCode.Write_FILE_IO_ERROR, e);
}
}
public List<String> getColumnNames(List<Configuration> columns) {
List<String> columnNames = Lists.newArrayList();
for (Configuration eachColumnConf : columns) {
columnNames.add(eachColumnConf.getString(Key.NAME));
}
return columnNames;
}
/**
* id int,
* username string,
* telephone string,
* mail string,
* day string
*/
public String getColumnInfo(List<Configuration> columns) {
StringBuilder str = new StringBuilder();
List<String> columnNames = Lists.newArrayList();
for (int i = 0; i < columns.size(); i++) {
Configuration eachColumnConf = columns.get(i);
String name = eachColumnConf.getString(Key.NAME);//列名称
String type = eachColumnConf.getString(Key.TYPE);//列类型
str.append(name).append(" ").append(type);
if (i != (columns.size() - 1)) {
str.append(",");
}
}
return str.toString();
}
/**
* By LingZhy on 2021/4/29 16:58
*
* @return java.lang.String
* @description
* @params * @param columns
*/
public String getColumnName(List<Configuration> columns) {
StringBuilder str = new StringBuilder();
List<String> list = Lists.newArrayList();
for (int i = 0; i < columns.size(); i++) {
Configuration eachColumnConf = columns.get(i);
String name = eachColumnConf.getString(Key.NAME).toLowerCase();
list.add(name);
}
return String.join(",", list);
}
/**
* 根据writer配置的字段类型,构建inspector
*
* @param columns
* @return
*/
public List<ObjectInspector> getColumnTypeInspectors(List<Configuration> columns) {
List<ObjectInspector> columnTypeInspectors = Lists.newArrayList();
for (Configuration eachColumnConf : columns) {
SupportHiveDataType columnType = SupportHiveDataType.valueOf(eachColumnConf.getString(Key.TYPE).toUpperCase());
ObjectInspector objectInspector = null;
switch (columnType) {
case TINYINT:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(Byte.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case SMALLINT:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(Short.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case INT:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case BIGINT:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(Long.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case FLOAT:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(Float.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case DOUBLE:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(Double.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case TIMESTAMP:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(java.sql.Timestamp.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case DATE:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(java.sql.Date.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case STRING:
case VARCHAR:
case CHAR:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(String.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
case BOOLEAN:
objectInspector = ObjectInspectorFactory.getReflectionObjectInspector(Boolean.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
break;
default:
throw DataXException
.asDataXException(
HiveWriterErrorCode.ILLEGAL_VALUE,
String.format(
"您的配置文件中的列配置信息有误. 因为DataX 不支持数据库写入这种字段类型. 字段名:[%s], 字段类型:[%d]. 请修改表中该字段的类型或者不同步该字段.",
eachColumnConf.getString(Key.NAME),
eachColumnConf.getString(Key.TYPE)));
}
columnTypeInspectors.add(objectInspector);
}
return columnTypeInspectors;
}
public OrcSerde getOrcSerde(Configuration config) {
String fieldDelimiter = config.getString(Key.FIELD_DELIMITER);
String compress = config.getString(Key.COMPRESS);
String encoding = config.getString(Key.ENCODING);
OrcSerde orcSerde = new OrcSerde();
Properties properties = new Properties();
properties.setProperty("orc.bloom.filter.columns", fieldDelimiter);
properties.setProperty("orc.compress", compress);
properties.setProperty("orc.encoding.strategy", encoding);
orcSerde.initialize(conf, properties);
return orcSerde;
}
public static MutablePair<List<Object>, Boolean> transportOneRecord(
Record record, List<Configuration> columnsConfiguration,
TaskPluginCollector taskPluginCollector, Configuration config) {
MutablePair<List<Object>, Boolean> transportResult = new MutablePair<List<Object>, Boolean>();
transportResult.setRight(false);
List<Object> recordList = Lists.newArrayList();
int recordLength = record.getColumnNumber();
if (0 != recordLength) {
Column column;
for (int i = 0; i < recordLength; i++) {
column = record.getColumn(i);
//todo as method
if (null != column.getRawData()) {
String rowData = column.getRawData().toString();
SupportHiveDataType columnType = SupportHiveDataType.valueOf(
columnsConfiguration.get(i).getString(Key.TYPE).toUpperCase());
//根据writer端类型配置做类型转换
try {
switch (columnType) {
case TINYINT:
recordList.add(Byte.valueOf(rowData));
break;
case SMALLINT:
recordList.add(Short.valueOf(rowData));
break;
case INT:
recordList.add(Integer.valueOf(rowData));
break;
case BIGINT:
recordList.add(column.asLong());
break;
case FLOAT:
recordList.add(Float.valueOf(rowData));
break;
case DOUBLE:
recordList.add(column.asDouble());
break;
case STRING:
case VARCHAR:
case CHAR:
recordList.add(column.asString());
break;
case BOOLEAN:
recordList.add(column.asBoolean());
break;
case DATE:
recordList.add(new java.sql.Date(column.asDate().getTime()));
break;
case TIMESTAMP:
recordList.add(new java.sql.Timestamp(column.asDate().getTime()));
break;
default:
throw DataXException
.asDataXException(
HiveWriterErrorCode.ILLEGAL_VALUE,
String.format(
"您的配置文件中的列配置信息有误. 因为DataX 不支持数据库写入这种字段类型. 字段名:[%s], 字段类型:[%d]. 请修改表中该字段的类型或者不同步该字段.",
columnsConfiguration.get(i).getString(Key.NAME),
columnsConfiguration.get(i).getString(Key.TYPE)));
}
} catch (Exception e) {
// warn: 此处认为脏数据
String message = String.format(
"字段类型转换错误:你目标字段为[%s]类型,实际字段值为[%s].",
columnsConfiguration.get(i).getString(Key.TYPE), column.getRawData().toString());
taskPluginCollector.collectDirtyRecord(record, message);
transportResult.setRight(true);
break;
}
} else {
// warn: it's all ok if nullFormat is null
//recordList.add(null);
// fix 写入hdfs的text格式时,需要指定NULL为\N
String nullFormat = config.getString(Key.NULL_FORMAT);
if (nullFormat == null) {
recordList.add(null);
} else {
recordList.add(nullFormat);
}
}
}
}
transportResult.setLeft(recordList);
return transportResult;
}
}
HiveServer2ConnectUtil.class
package com.alibaba.datax.plugin.writer.hivewriter;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class HiveServer2ConnectUtil {
private static final Logger LOG = LoggerFactory.getLogger(HiveServer2ConnectUtil.class);
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) {
execHiveSql("hive", null,
"; use default; create table tmp_datax_hivereader_20220808_1659953092709 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\u0001' STORED AS TEXTFILE as select id,username,password from default.t_user;",
"jdbc:hive2://10.252.92.4:10000");
}
/**
* hive执行多个sql
*
* @param username
* @param password
* @param hiveSql
* @param hiveJdbcUrl
* @return
*/
public static boolean execHiveSql(String username, String password, String hiveSql, String hiveJdbcUrl) {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
try {
LOG.info("hiveJdbcUrl:{}", hiveJdbcUrl);
LOG.info("username:{}", username);
LOG.info("password:{}", password);
Connection conn = DriverManager.getConnection(hiveJdbcUrl, username, password);
Statement stmt = conn.createStatement();
String[] hiveSqls = hiveSql.split(";");
for (int i = 0; i < hiveSqls.length; i++) {
if (StringUtils.isNotEmpty(hiveSqls[i])) {
stmt.execute(hiveSqls[i]);
}
}
return true;
} catch (SQLException sqlException) {
LOG.error(sqlException.getMessage(), sqlException);
return false;
}
}
}
HiveWriter.class
package com.alibaba.datax.plugin.writer.hivewriter;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordReceiver;
import com.alibaba.datax.common.spi.Writer;
import com.alibaba.datax.common.util.Configuration;
import org.apache.commons.lang.StringEscapeUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
//import java.util.UUID;
//import com.alibaba.datax.common.util.KeyUtil;
//import com.alibaba.datax.common.util.ShellUtil;
public class HiveWriter extends Writer {
public static class Job extends Writer.Job {
private static final Logger log = LoggerFactory.getLogger(Job.class);
private Configuration conf = null;
private String defaultFS;
private String tmpPath;
private String tmpTableName;
private String tempHdfsLocation;
@Override
public void init() {
this.conf = super.getPluginJobConf();//获取配置文件信息{parameter 里面的参数}
log.info("hive writer params:{}", conf.toJSON());
//校验 参数配置
log.info("HiveWriter流程说明[1:创建hive临时表 ;2:Reader的数据导入到临时表HDFS路径(无分区);3:临时表数据插入到目标表;4:删除临时表]");
this.validateParameter();
}
private void validateParameter() {
this.conf.getNecessaryValue(Key.DATABASE_NAME, HiveWriterErrorCode.REQUIRED_VALUE);
this.conf.getNecessaryValue(Key.TABLE_NAME, HiveWriterErrorCode.REQUIRED_VALUE);
this.conf.getNecessaryValue(Key.DEFAULT_FS, HiveWriterErrorCode.REQUIRED_VALUE);
this.conf.getNecessaryValue(Key.HIVE_DATABASE_TMP_LOCATION, HiveWriterErrorCode.REQUIRED_VALUE);
//Kerberos check
Boolean haveKerberos = this.conf.getBool(Key.HAVE_KERBEROS, false);
if (haveKerberos) {
this.conf.getNecessaryValue(Key.KERBEROS_KEYTAB_FILE_PATH, HiveWriterErrorCode.REQUIRED_VALUE);
this.conf.getNecessaryValue(Key.KERBEROS_PRINCIPAL, HiveWriterErrorCode.REQUIRED_VALUE);
}
}
@Override
public void prepare() {
this.tempHdfsLocation = this.conf.getString(Key.HIVE_DATABASE_TMP_LOCATION);
}
@Override
public List<Configuration> split(int mandatoryNumber) {
this.defaultFS = this.conf.getString(Key.DEFAULT_FS);
//按照reader 切分的情况来组织相同个数的writer配置文件 (reader channel writer)
List<Configuration> configurations = new ArrayList<Configuration>(mandatoryNumber);
for (int i = 0; i < mandatoryNumber; i++) {
Configuration splitedTaskConfig = this.conf.clone();
this.tmpTableName = hiveTableName();
//判断set语句的结尾是否是/,不是给加一个
if (!this.tempHdfsLocation.trim().endsWith("/")) {
this.tempHdfsLocation = this.tempHdfsLocation + "/";
}
//创建临时Hive表,指定hive表在hdfs上的存储路径
this.tmpPath = this.tempHdfsLocation + this.tmpTableName.toLowerCase();
//后面需要指定写入的文件名称
// String fileSuffix = UUID.randomUUID().toString().replace('-', '_');
String fullFileName = String.format("%s%s/%s", defaultFS, this.tmpPath, this.tmpTableName);// 临时存储的文件路径
splitedTaskConfig.set(Key.HIVE_DATABASE_TMP_LOCATION, tmpPath);
splitedTaskConfig.set(Key.TMP_FULL_NAME, fullFileName);
splitedTaskConfig.set(Key.TEMP_TABLE_NAME_PREFIX, this.tmpTableName);
//分区字段解析 "dt","type"
List<String> partitions = this.conf.getList(Key.PARTITION, String.class);
String partitionInfo = StringUtils.join(partitions, ",");
splitedTaskConfig.set(Key.PARTITION, partitionInfo);
configurations.add(splitedTaskConfig);
}
return configurations;
}
@Override
public void post() {
}
@Override
public void destroy() {
}
private String hiveTableName() {
StringBuilder str = new StringBuilder();
FastDateFormat fdf = FastDateFormat.getInstance("yyyyMMdd");
str.append(Constants.TEMP_TABLE_NAME_PREFIX_DEFAULT).append(fdf.format(new Date()))
// .append("_").append(KeyUtil.genUniqueKey());
.append("_").append(System.currentTimeMillis());
return str.toString();
}
}
public static class Task extends Writer.Task {
//写入hive步骤 (1)创建临时表 (2)读取数据写入临时表 (3) 从临时表写出数据
private static final Logger LOG = LoggerFactory.getLogger(Task.class);
private Configuration conf;
private String defaultFS;
private String username;
private String password;
private String hiveJdbcUrl;
private String databaseName;
private String tableName;//目标表名称
private String writeMode;
private String partition;
private String tmpDataBase;
private String tmpTableName;
private boolean alreadyDel = false;
private String hive_cmd;
private String hive_sql_set;
private HdfsHelper hdfsHelper = null;//工具类
private String fieldDelimiter;
private String hive_fieldDelimiter;
private String compress;
private String hive_target_table_compress_sql;
private String hive_preSql;
private String hive_postSql;
@Override
public void init() {
this.conf = super.getPluginJobConf();
//初始化每个task参数
this.defaultFS = this.conf.getString(Key.DEFAULT_FS);
this.username = this.conf.getString(Key.USERNAME);
this.password = this.conf.getString(Key.PASSWORD);
this.hiveJdbcUrl = this.conf.getString(Key.HIVE_JDBC_URL);
this.databaseName = this.conf.getString(Key.DATABASE_NAME);
this.tableName = this.conf.getString(Key.TABLE_NAME);
this.partition = this.conf.getString(Key.PARTITION);
this.writeMode = this.conf.getString(Key.WRITE_MODE, Constants.WRITE_MODE_DEFAULT);
this.tmpDataBase = this.conf.getString(Key.HIVE_TMP_DATABASE, this.databaseName);
this.tmpTableName = this.conf.getString(Key.TEMP_TABLE_NAME_PREFIX);
this.hive_cmd = this.conf.getString(Key.HIVE_CMD, Constants.HIVE_CMD_DEFAULT);
this.hive_sql_set = this.conf.getString(Key.HIVE_SQL_SET, Constants.HIVE_SQL_SET_DEFAULT);
this.fieldDelimiter = this.conf.getString(Key.FIELD_DELIMITER, Constants.FIELDDELIMITER_DEFAULT);
this.compress = this.conf.getString(Key.COMPRESS, Constants.COMPRESS_DEFAULT);
this.hive_preSql = this.conf.getString(Key.HIVE_PRESQL, Constants.HIVE_PRESQL_DEFAULT);
this.hive_postSql = this.conf.getString(Key.HIVE_POSTSQL, Constants.HIVE_POSTSQL_DEFAULT);
this.hive_fieldDelimiter = this.fieldDelimiter;
this.fieldDelimiter = StringEscapeUtils.unescapeJava(this.fieldDelimiter);
this.conf.set(Key.FIELD_DELIMITER, this.fieldDelimiter);//设置hive 存储文件 hdfs默认的分隔符,传输时候会分隔
this.conf.set(Key.COMPRESS, this.compress);
this.hive_target_table_compress_sql = this.conf.getString(Key.HIVE_TARGET_TABLE_COMPRESS_SQL, Constants.HIVE_TARGET_TABLE_COMPRESS_SQL);
//判断set语句的结尾是否是分号,不是给加一个
if (!this.hive_sql_set.trim().endsWith(";")) {
this.hive_sql_set = this.hive_sql_set + ";";
}
if (!this.hive_preSql.trim().endsWith(";")) {
this.hive_preSql = this.hive_preSql + ";";
}
if (!this.hive_postSql.trim().endsWith(";")) {
this.hive_postSql = this.hive_postSql + ";";
}
hdfsHelper = new HdfsHelper();
hdfsHelper.getFileSystem(defaultFS, conf);
}
@Override
public void prepare() {
//创建临时表
List<Configuration> columns = this.conf.getListConfiguration(Key.COLUMN);
String columnsInfo = hdfsHelper.getColumnInfo(columns);
String hive_presql_str = "";
if (this.hive_preSql.equals("select 1;")) {
hive_presql_str = "";
} else if (StringUtils.isNotBlank(this.hive_preSql)) {
String hivepresql_Info = this.hive_preSql;
hive_presql_str = hivepresql_Info;
}
String hiveCmd = this.hive_sql_set + hive_presql_str + " use " + this.tmpDataBase + "; " +
"create table " + this.tmpTableName + "(" + columnsInfo + ") " +
" ROW FORMAT DELIMITED FIELDS TERMINATED BY '" + this.hive_fieldDelimiter + "' stored as TEXTFILE ";
LOG.info("创建hive临时表 ----> :" + hiveCmd);
//执行脚本,创建临时表
if (!HiveServer2ConnectUtil.execHiveSql(this.username, this.password, hiveCmd, this.hiveJdbcUrl)) {
throw DataXException.asDataXException(
HiveWriterErrorCode.SHELL_ERROR,
"创建hive临时表脚本执行失败");
}
// if (!ShellUtil.exec(new String[]{this.hive_cmd, "-e", "\"" + hiveCmd + "\""})) {
// throw DataXException.asDataXException(
// HiveWriterErrorCode.SHELL_ERROR,
// "创建hive临时表脚本执行失败");
// }
addHook();
LOG.info("创建hive 临时表结束 end!!!");
}
@Override
public void startWrite(RecordReceiver lineReceiver) {
List<Configuration> columns = this.conf.getListConfiguration(Key.COLUMN);
String columnsStr = hdfsHelper.getColumnName(columns);
// String columnsInfo=hdfsHelper.getColumnInfo(columns);
// String[] columnsInfoStr = columnsInfo.split(",");
// List<String> list = new ArrayList<>();
//
// for (String c:columnsInfoStr){
// list.add(c.split(" ")[0]);
// }
// String columnsStr = String.join(",",list);
//(2)读取数据写入临时表,默认创建的临时表是textfile格式
LOG.info("begin do write...");
String fullFileName = this.conf.getString(Key.TMP_FULL_NAME);// 临时存储的文件路径
LOG.info(String.format("write to file : [%s]", fullFileName));
//写TEXT FILE
hdfsHelper.textFileStartWrite(lineReceiver, this.conf, fullFileName, this.getTaskPluginCollector());
LOG.info("end do write tmp text table");
LOG.info("columnsStr:" + columnsStr);
String writeModeSql = null;
if (this.writeMode.equals("overwrite")) {
writeModeSql = "overwrite";
} else {
writeModeSql = "into";
}
String partition_str = "";
if (StringUtils.isNotBlank(this.partition)) {
//获取分区字段
String partitionInfo = this.partition;
partition_str = " partition(" + partitionInfo + ") ";
}
//从临时表写入到目标表
String insertCmd = this.hive_sql_set + " use " + this.databaseName + ";" +
Constants.INSERT_PRE_SQL + this.hive_target_table_compress_sql +
" insert " + writeModeSql + " table " + this.tableName + partition_str +
" (" + columnsStr + ")" +
" select " + columnsStr + " from " + this.tmpDataBase + "." + this.tmpTableName + ";";
LOG.info("insertCmd ----> :" + insertCmd);
//执行脚本,导入数据到目标hive表
if (!HiveServer2ConnectUtil.execHiveSql(this.username, this.password, insertCmd, this.hiveJdbcUrl)) {
throw DataXException.asDataXException(
HiveWriterErrorCode.SHELL_ERROR,
"导入数据到目标hive表失败");
}
// if (!ShellUtil.exec(new String[]{this.hive_cmd, "-e", "\"" + insertCmd + "\""})) {
// throw DataXException.asDataXException(
// HiveWriterErrorCode.SHELL_ERROR,
// "导入数据到目标hive表失败");
// }
LOG.info("end do write");
}
@Override
public void post() {
LOG.info("one task hive write post...end");
deleteTmpTable();
}
@Override
public void destroy() {
}
private void addHook() {
if (!alreadyDel) {
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
deleteTmpTable();
}
}));
}
}
private void deleteTmpTable() {
String hive_postsql_str = "";
if (this.hive_postSql.equals("select 1;")) {
hive_postsql_str = "";
} else if (StringUtils.isNotBlank(this.hive_postSql)) {
//获取分区字段
String hivepostsql_Info = this.hive_postSql;
hive_postsql_str = hivepostsql_Info;
}
String hiveCmd = this.hive_sql_set + " use " + this.tmpDataBase + ";" +
"drop table if exists " + tmpTableName + ";" + hive_postsql_str;//注意要删除的是临时表
LOG.info("hiveCmd ----> :" + hiveCmd);
//执行脚本,删除hive临时表
if (!HiveServer2ConnectUtil.execHiveSql(this.username, this.password, hiveCmd, this.hiveJdbcUrl)) {
throw DataXException.asDataXException(
HiveWriterErrorCode.SHELL_ERROR,
"删除hive临时表脚本执行失败");
}
// if (!ShellUtil.exec(new String[]{this.hive_cmd, "-e", "\"" + hiveCmd + "\""})) {
// throw DataXException.asDataXException(
// HiveWriterErrorCode.SHELL_ERROR,
// "删除hive临时表脚本执行失败");
// }
alreadyDel = true;
}
}
}
HiveWriterErrorCode.class
package com.alibaba.datax.plugin.writer.hivewriter;
import com.alibaba.datax.common.spi.ErrorCode;
public enum HiveWriterErrorCode implements ErrorCode {
REQUIRED_VALUE("HiveWriter-00", "您缺失了必须填写的参数值."),
SHELL_ERROR("HiveReader-06", "hive 脚本执行失败."),
CONFIG_INVALID_EXCEPTION("HdfsWriter-00", "您的参数配置错误."),
ILLEGAL_VALUE("HdfsWriter-02", "您填写的参数值不合法."),
WRITER_FILE_WITH_CHARSET_ERROR("HdfsWriter-03", "您配置的编码未能正常写入."),
Write_FILE_IO_ERROR("HdfsWriter-04", "您配置的文件在写入时出现IO异常."),
WRITER_RUNTIME_EXCEPTION("HdfsWriter-05", "出现运行时异常, 请联系我们."),
CONNECT_HDFS_IO_ERROR("HdfsWriter-06", "与HDFS建立连接时出现IO异常."),
COLUMN_REQUIRED_VALUE("HdfsWriter-07", "您column配置中缺失了必须填写的参数值."),
HDFS_RENAME_FILE_ERROR("HdfsWriter-08", "将文件移动到配置路径失败."),
KERBEROS_LOGIN_ERROR("HdfsWriter-09", "KERBEROS认证失败");
;
private final String code;
private final String description;
private HiveWriterErrorCode(String code, String description) {
this.code = code;
this.description = description;
}
@Override
public String getCode() {
return this.code;
}
@Override
public String getDescription() {
return this.description;
}
@Override
public String toString() {
return String.format("Code:[%s], Description:[%s].", this.code,
this.description);
}
}
Key.class
package com.alibaba.datax.plugin.writer.hivewriter;
public class Key {
/**
* 1.必选:defaultFS,databaseName,tableName,column,tmpDatabasePath,tmpDatabase
* 2.可选(有缺省值):
* writeMode(insert)
* hive_cmd(hive)
* fieldDelimiter(\u0001)
* compress(gzip)
* tmpTableName(tmp_datax_hivewriter_)
* 3.可选(无缺省值):partition,fullFileName,encoding
* */
public final static String DEFAULT_FS = "defaultFS";
public final static String USERNAME = "username";
public final static String PASSWORD = "password";
public final static String HIVE_JDBC_URL = "hiveJdbcUrl";
public final static String DATABASE_NAME = "databaseName";//目标数据库名
public final static String TABLE_NAME = "tableName";//目标表名
public static final String WRITE_MODE = "writeMode";//表的写入方式insert、overwrite
public static final String COLUMN = "column";//目标表的列
public static final String NAME = "name";//目标表的字段名
public static final String TYPE = "type";//目标表的字段类型
public static final String PARTITION="partition";//分区字段
public static final String HIVE_DATABASE_TMP_LOCATION="tmpDatabasePath";//临时hive表所在数据库的location路径
public static final String HIVE_TMP_DATABASE="tmpDatabase";//临时HIVE表所在的数据库
public static final String TEMP_TABLE_NAME_PREFIX="tmpTableName";//临时HIVE表名前缀
public static final String TMP_FULL_NAME="fullFileName";//临时hive表 HDFS文件名称
public static final String HIVE_CMD = "hive_cmd"; //hive
public final static String HIVE_SQL_SET = "hive_sql_set";
public static final String HIVE_PRESQL = "hive_preSql";
public final static String HIVE_POSTSQL = "hive_postSql";
public final static String HIVE_TARGET_TABLE_COMPRESS_SQL="hive_target_table_compress_sql";
public static final String COMPRESS = "compress";//临时表压缩格式
public static final String ENCODING="encoding";
public static final String FIELD_DELIMITER="fieldDelimiter";
public static final String NULL_FORMAT = "nullFormat";
public static final String HAVE_KERBEROS = "haveKerberos";
public static final String KERBEROS_KEYTAB_FILE_PATH = "kerberosKeytabFilePath";
public static final String KERBEROS_PRINCIPAL = "kerberosPrincipal";
public static final String HADOOP_CONFIG = "hadoopConfig";
}
SupportHiveDataType.class
package com.alibaba.datax.plugin.writer.hivewriter;
public enum SupportHiveDataType {
TINYINT,
SMALLINT,
INT,
BIGINT,
FLOAT,
DOUBLE,
TIMESTAMP,
DATE,
STRING,
VARCHAR,
CHAR,
BOOLEAN
}
plugin_job.template.json
{
"name": "hivewriter",
"parameter": {
"print":true,
"username": "hive",
"defaultFS": "hdfs://",
"hiveJdbcUrl": "jdbc:hive2://",
"databaseName": "default",
"tableName": "t_user",
"writeMode": "insert",
"tmpDatabase":"tmp",
"tmpDatabasePath":"/user/hive/warehouse/tmp.db/",
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "username",
"type": "STRING"
},
{
"name": "password",
"type": "STRING"
}
]
}
}
问题处理:
1、ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: Cannot run program "hive": error=2, No such file or directory
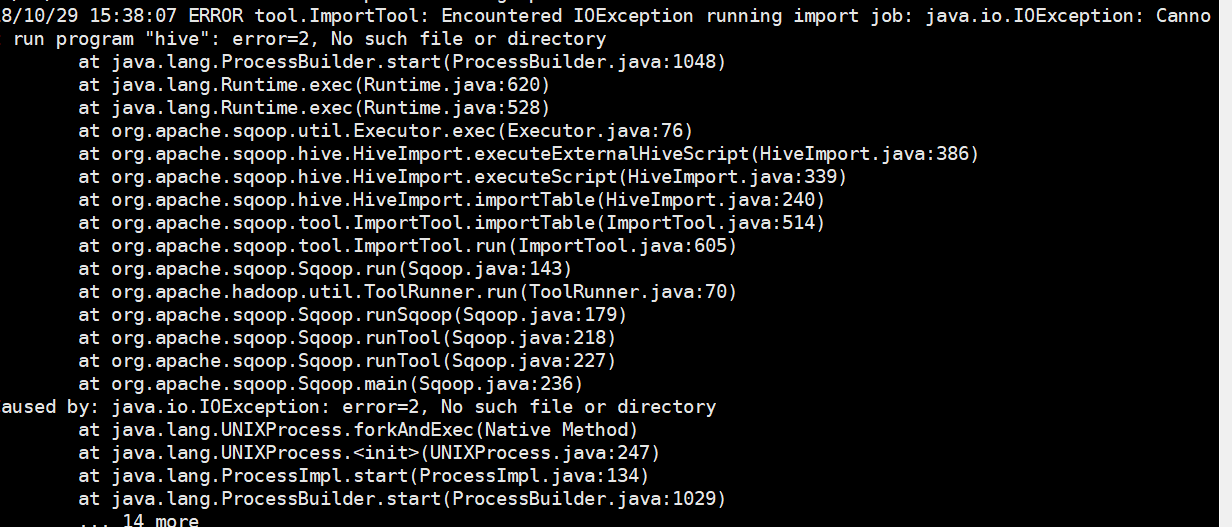
原因是hive没有设置环境变量,根据你自己的路径配置环境变量
解决办法:
1、如果你是在Hadoop集群的虚拟机上部署DataX,你可以改变DataX部署的用户为hive的用户,不过这种比较局限,只能当个用户,而且要和hadoop环境依赖耦合。
vim /etc/profile (切换root用户)
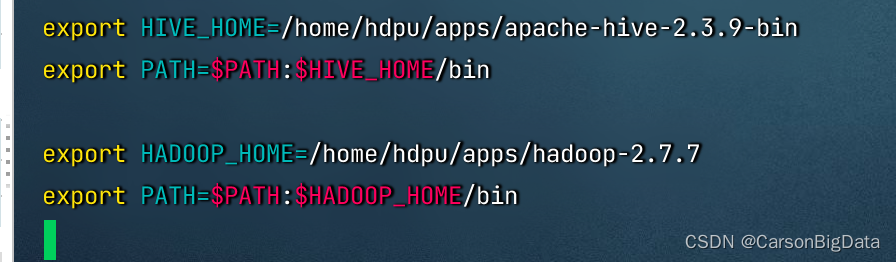
source /etc/profile
2、在DFSUtil类初始化时,修改HADOOP_USER_NAME为模版传入的用户,目前用户未开启认证,所以修改用户名称即可
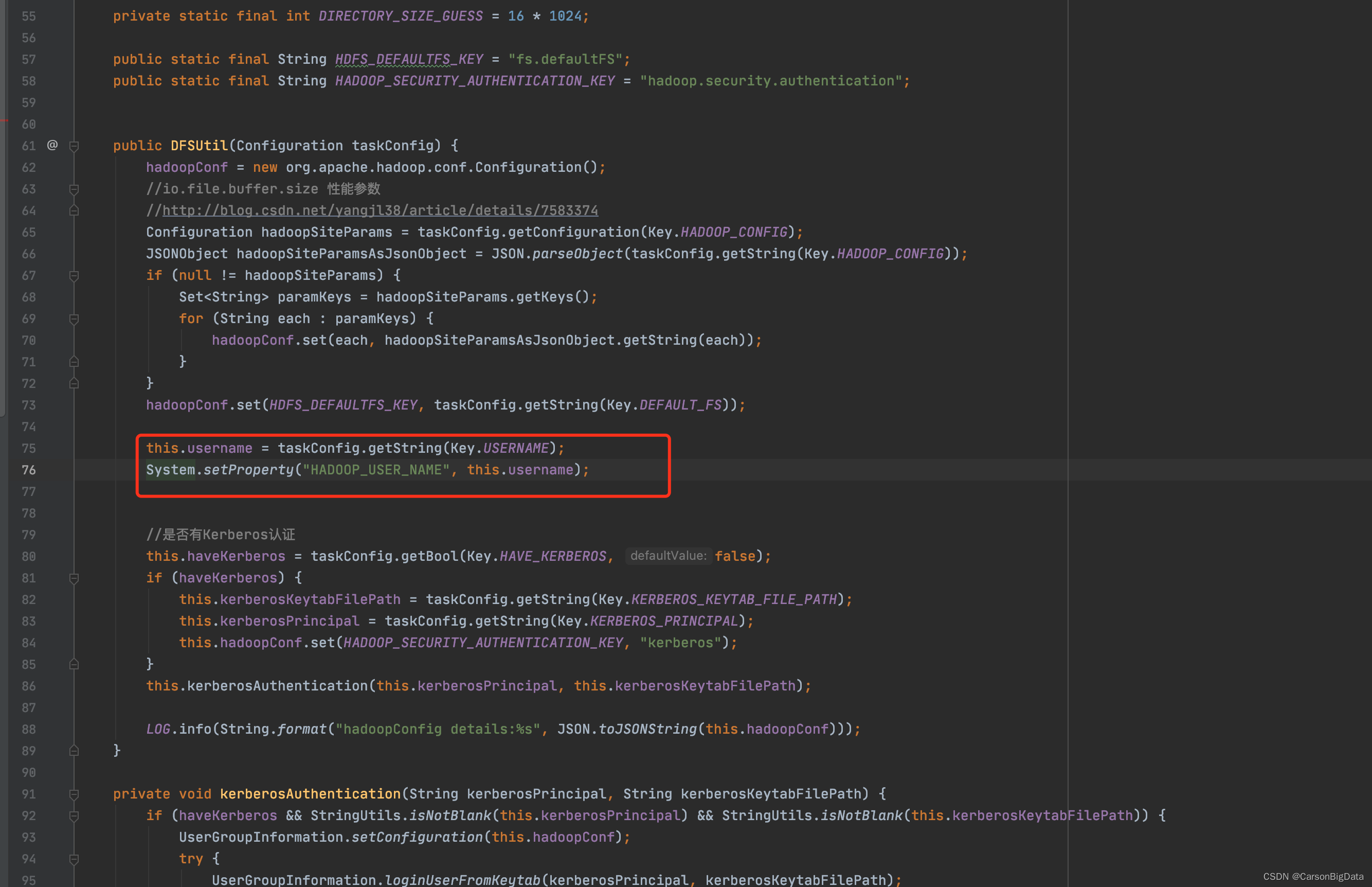
补充:
package com.alibaba.datax.plugin.reader.hivereader;
import com.alibaba.datax.common.util.RetryUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class ShellUtil {
private static final int SUCCESS = 0;
private static final Logger LOG = LoggerFactory.getLogger(RetryUtil.class);
public static boolean exec(String[] command) {
try {
Process process = Runtime.getRuntime().exec(command);
read(process.getInputStream());
StringBuilder errMsg = read(process.getErrorStream());
// 等待程序执行结束并输出状态
int exitCode = process.waitFor();
if (exitCode == SUCCESS) {
LOG.info("脚本执行成功");
return true;
} else {
LOG.info("脚本执行失败[ERROR]:" + errMsg.toString());
return false;
}
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
private static StringBuilder read(InputStream inputStream) {
StringBuilder resultMsg = new StringBuilder();
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
resultMsg.append(line);
resultMsg.append("\r\n");
}
return resultMsg;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
参考博客:
datax同步hive到mongo_文大侠的博客-CSDN博客_datax hivereader
https://github.com/deanxiao/DataX-HiveReader
第3.6章:DataX访问Hive2拉取数据(拓展篇)_流木随风的博客-CSDN博客_datax连接hive
【HDFS】mkdir: Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x - 灰信网(软件开发博客聚合)
GitHub - deanxiao/DataX-HiveWriter: HiveWriter for alibaba DataX
版权归原作者 CarsonBigData 所有, 如有侵权,请联系我们删除。