
前提:已经安装了spark集群,可参考上篇文章搭建:http://t.csdnimg.cn/UXBOp
一、Spark集群配置YARN
1、增加hadoop 配置文件地址
vim spark-env.sh
增加export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.1/etc/hadoop
2、关闭虚拟内存
cd /usr/local/soft/hadoop-3.1.1/etc/hadoop
vim yarn-site.xml
增加以下配置:

3、同步到其他节点
scp -r yarn-site.xml node1:pwd
scp -r yarn-site.xml node2:pwd
4、启动hadoop
start-all.sh
5、yarn与standalone一样,也有两种运行方式,client与cluster
使用spark提供的模版进行测试:
client提交命令:
spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.3.jar 100
cluster提交命令:
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.3.jar 100
注:100给的是task任务的数量,即分区的数量也是100,可以手动指定任意数量,如果不指定,默认是按照文件的分区数算。
二、client与cluster提交流程图解
1、spark yarn client
资源调度图解:

注意:MapReduce的资源调度是每次需要执行任务的时候去申请资源,而spark是提前申请任务所需要的所有资源。MapReduce这种方式叫细粒度执行,spark这种方式叫粗粒度执行。
任务调度图解:
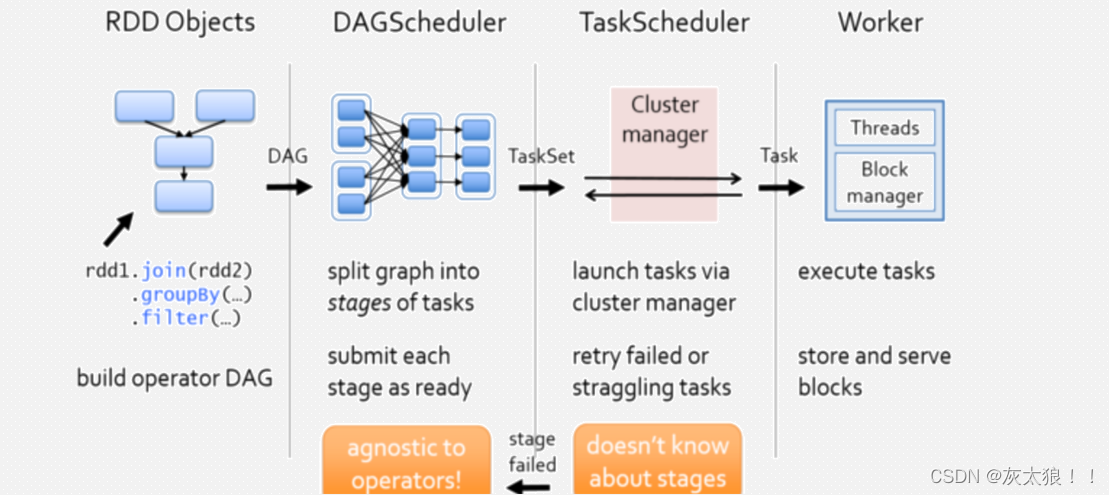
** DAG Scheduler:**
(1)基于Stage构建DAG,决定每个任务的最佳位置
(2)将taskset传给底层调度器TaskScheduler
(3)重新提交shuffle输出丢失的stage。
Task Scheduler:
(1)提交taskset(一组并行task)到集群运行并汇报结果
(2)出现shuffle输出lost要报告fetchfailed错误
(3)碰到straggle任务需要放到别的节点上重试
(4)为每一一个TaskSet维护一一个TaskSetManager(追踪本地性及错误信息)
更易懂的任务调度图解:

**资源调度+任务调度图解: **

2、spark yarn cluster
资源调度:
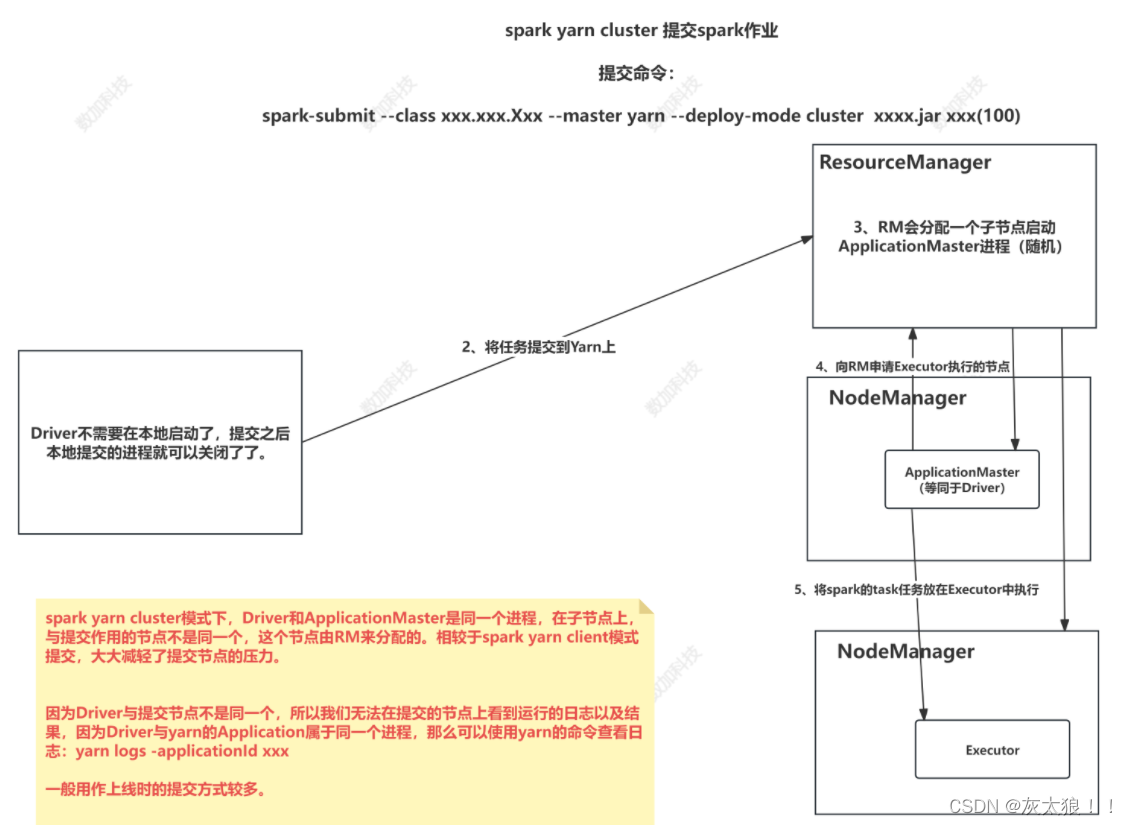
名词解释:
(1) Driver:是一个进程,我们编写的Spark应用程序就运行在Driver上,由Driver进程执行
(2) Executor:是在一个workernode上为某应用用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应用用都有各自自独立的executors
(3)RM:ResourceManager主要作用:
a、处理客户端请求
b、监控NodeManager
c、启动或监控ApplicationMaster
d、资源的分配与调度
(4)AM:ApplicationMaster(MRAppMaster)作用:
a、负责数据的切分
b、为应用程序申请资源并分配内部的任务
c、任务的监控与容错
(5)NM:NodeManager主要作用:
a、管理单个节点上的资源
b、处理来自ResourceManager的命令
c、处理来自ApplicationMaster的命令
三、编写spark程序在yarn上执行
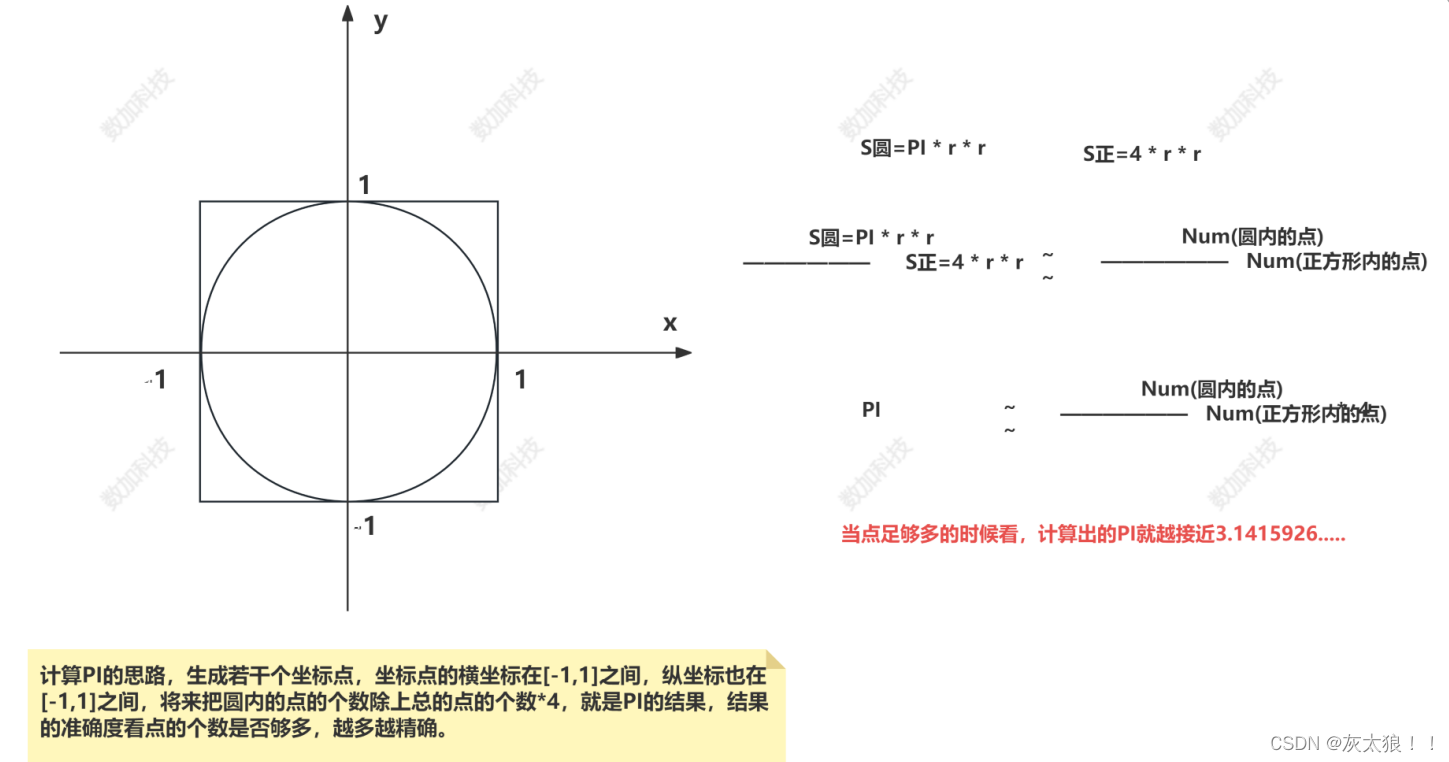
案例:计算PI
1、思路图解:
2、编写spark代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
object Demo19PI {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
/**
* 提交到yarn上运行,这个参数依旧不用设置
*/
// conf.setMaster("local")
conf.setAppName("yarn submit")
val context = new SparkContext(conf)
//设置生成点的个数 10000
val list: Range.Inclusive = 0 to 10000
//将scala的序列集合变成rdd
val rangeRDD: RDD[Int] = context.parallelize(list)
//随机生成正方形内的点
val dianRDD: RDD[(Double, Double)] = rangeRDD.map((i: Int) => {
val x: Double = Random.nextDouble() * 2 - 1
val y: Double = Random.nextDouble() * 2 - 1
(x, y)
})
// println(dianRDD.count())
//取出圆中点的个数
val yuanZuoRDD: RDD[(Double, Double)] = dianRDD.filter {
case (x: Double, y: Double) =>
x * x + y * y < 1
}
// println(yuanZuoRDD.count())
//计算PI
println("="*100)
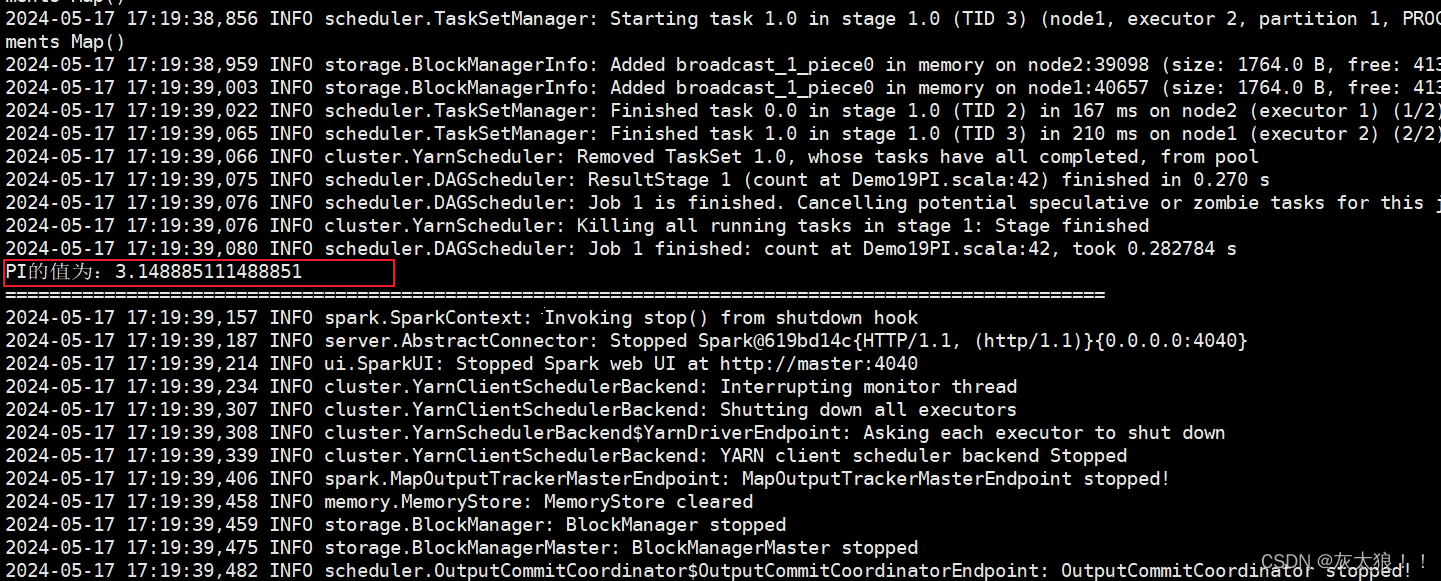
println(s"PI的值为:${(yuanZuoRDD.count().toDouble / dianRDD.count()) * 4}")
println("="*100)
/**
* spark-submit --class com.shujia.core.Demo19PI --master yarn --deploy-mode client spark-1.0-SNAPSHOT.jar
* spark-submit --class com.shujia.core.Demo19PI --master yarn --deploy-mode cluster spark-1.0-SNAPSHOT.jar
*/
}
}
3、提交
流程:将程序打包上传到linux中,使用以下命令在yarn上运行,与stanadalone模式相同,在yarn提交作业的方式也有两种,client模式和cluster模式
client模式:日志在本地端生成,多用于测试环境
spark-submit --class com.shujia.core.Demo19PI --master yarn --deploy-mode client spark-1.0-SNAPSHOT.jar
cluster模式:上线使用,不会再本地打印日志
spark-submit --class com.shujia.core.Demo19PI --master yarn --deploy-mode cluster spark-1.0-SNAPSHOT.jar
3.1使用client模式的命令执行:
3.2使用cluster模式的命令执行:
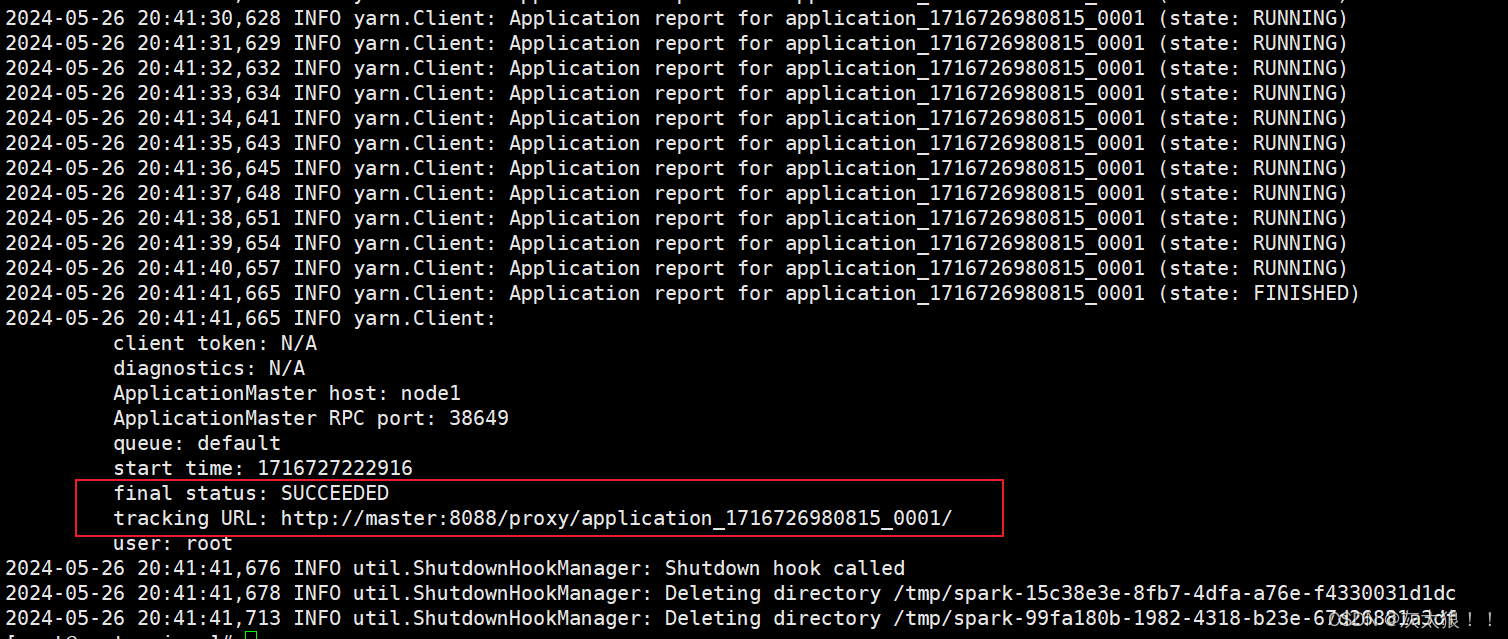
使用cluster模式不会再本地打印日志,我们看不到运行的结果,但是我们可以使用下列命令查看yarn的日志来确定结果:
yarn logs -applicationId application_1716726980815_0001
版权归原作者 灰太狼!! 所有, 如有侵权,请联系我们删除。