
安装 web driver:
使用 driver 前,需要下载与浏览器版本相对应的 driver。如要在 Chrome 浏览器上操作,就要下载Chrome Driver。
几个常用浏览器的参考和下载地址:
Edge Driver:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Chrome Driver:https://sites.google.com/chromium.org/driver/
https://googlechromelabs.github.io/chrome-for-testing/
Firefox Driver:https://github.com/mozilla/geckodriver/releases
这里使用Chrome浏览器,下载Chrome Driver。
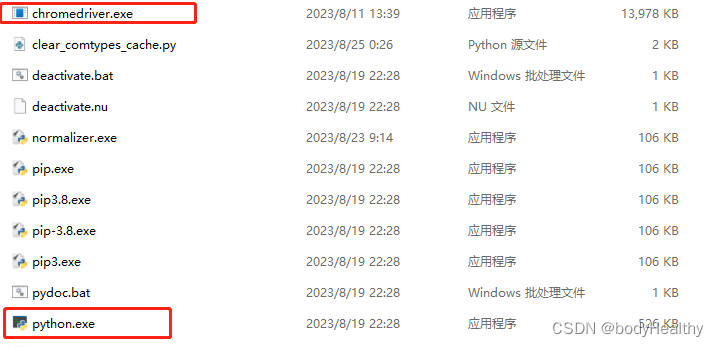
下载并安装完成后,将.exe文件拷贝到 python.exe 同级的目录下。
引入将要使用到的库
from selenium import webdriver
# By 里定义了许多常量,用来标识以何种形式来查找元素,如 By.CLASS_NAME 使用类名来查找
from selenium.webdriver.common.by import By
# 主要用来等待(确保页面加载、更新完成)
import time
初始化驱动器:
driver = webdriver.Chrome()
# 如果没有将driver.exe放到环境变量或python.exe同级目录下,则要参数中指定
# driver = webdriver.Chrome('F:/chromedriver.exe')
打开Chrome浏览器,访问指定的网站:
driver.get('http://www.cwl.gov.cn/fcpz/yxjs/ssq/')
time.sleep(3) # 等待3秒再继续,确保页面加载完成
然后将窗口最大化:
driver.maximize_window()
观察页面和控制台,锁定目标(阳光开奖)的特征。

找到并点击 阳光开奖 链接,继续等待3秒,确保页面加载更新完成:
# find_element 返回的是第一个匹配的元素
# By.XPATH 使用类似 xPath 的语法来定位页面的元素, 第二个参数是对应的 xPath 内容
driver.find_element(by=By.XPATH, value="//div[@data-alias='ygkj']").click()
time.sleep(3)
此时浏览器会打开一个新的标签页,我们需要将 driver 定位到新的标签页中:
# 获取当前打开的几个窗口,返回的是一个列表,每个元素是每个标签页的标识
windows = driver.window_handles
# 切换到最新打开的窗口,保证后面能正常获取页面中的元素
driver.switch_to.window(windows[-1])
结合控制台和页面,找到 往期开奖公告 的特征标识,找到该元素并点击:

# 点击往期开奖公告
# By.PARTIAL_LINK_TEXT 使用链接的文本内容来进行搜索,后面的值是目标元素的innerText
driver.find_element(by=By.PARTIAL_LINK_TEXT, value="往期开奖公告").click()
time.sleep(3)
然后尝试在界面执行一个脚本,滚动到页面底部:
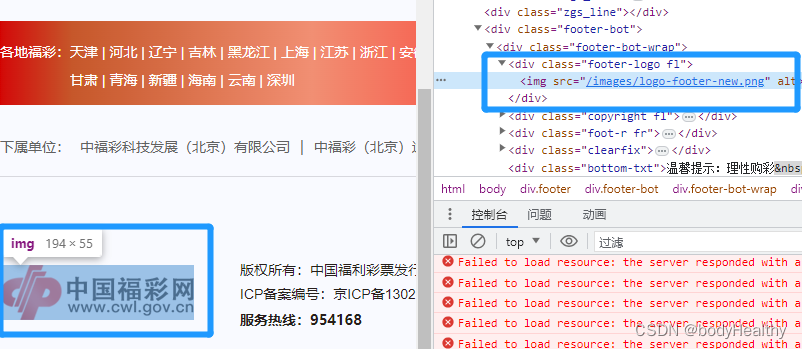
# 滚动到最底部(不是必须)
# By.CLASS_NAME 使用类名来查找底部的图片 第二个参数是对应的类名
target = driver.find_element(by=By.CLASS_NAME, value='footer-logo')
# 对于指定的元素执行脚本 这里的arguments[0]是第二个参数target
driver.execute_script('arguments[0].scrollIntoView({behavior:"smooth"})', target)
time.sleep(2)
然后找到下一页的按钮,并点击进入下一页:

# 下一页
# By.ID 指定使用 id 属性来查找元素,第二个参数是id值
# 这里先试用id来找到祖父节点,顺着该节点再继续往下找
paging = driver.find_element(by=By.ID, value='paging')
paging.find_element(by=By.CLASS_NAME, value='layui-laypage-next').click()
time.sleep(2)
在当前界面的右上角,有搜索功能,尝试自动输入指定内容并搜索:


# 在右上角的输入框中输入内容 使用ID来表示元素
# send_keys 在输入框中键入指定的内容,即输入 2023-5
driver.find_element(By.ID, 'searchInput').send_keys('2023-5')
time.sleep(2)
# 点击搜索按钮 先找父级,在从父级找子元素
btnParent = driver.find_element(By.CLASS_NAME, 'input-group-btn')
btnParent.find_element(By.CLASS_NAME, 'btn-default').click()
time.sleep(2)
点击搜索后,会新创建一个标签页,此时需要更新 driver 到新的标签页面。
# 及时切换窗口
windows = driver.window_handles
driver.switch_to.window(windows[-1])
点击第一个结果:

# 点击第一个结果
items = driver.find_elements(By.CLASS_NAME, 'con-item')
items[0].find_element(By.CLASS_NAME, 'black').click()
点击后,同样会新开一个标签页,此时我们把当前这个搜索结果的标签页关闭,然后跳转到新的标签页中:
# 关闭当前标签页并切换到新的窗口
driver.close()
windows = driver.window_handles
driver.switch_to.window(windows[-1])
time.sleep(2)
如果要返回历史开奖结果页面:
# 返回开奖历史记录
driver.switch_to.window(windows[-2])
如果想给开奖结果截一个图(元素截图):
# 指定元素截图(只截图当前浏览器窗口可见部分)
main = driver.find_element(By.CLASS_NAME, 'main')
main.screenshot('./caipiao_1.png') # 命名并保存
然后可以在当前的目录下查看 caipiao.png 图片:

完整程序代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化驱动器
driver = webdriver.Chrome()
# 如果没有将driver.exe放到环境变量或python.exe同级目录下,则要参数中指定
# driver = webdriver.Chrome('F:/chromedriver.exe')
# 访问指定网站
driver.get('http://www.cwl.gov.cn/fcpz/yxjs/ssq/')
driver.maximize_window() # 最大化窗口
time.sleep(3)
# 点击阳光开奖 使用Xpath来搜索
driver.find_element(by=By.XPATH, value="//div[@data-alias='ygkj']").click()
time.sleep(3)
# 获取当前打开了几个窗口
windows = driver.window_handles
# 会打开新的标签页,因此需要切换到最新打开的窗口,保证后面能正常获取元素
driver.switch_to.window(windows[-1])
# 点击往期开奖公告 使用链接的文本内容来进行搜索
driver.find_element(by=By.PARTIAL_LINK_TEXT, value="往期开奖公告").click()
time.sleep(3)
# 滚动到最底部
target = driver.find_element(by=By.CLASS_NAME, value='footer-logo')
# 对于指定的元素执行脚本 这里的arguments[0]是第二个参数target
driver.execute_script('arguments[0].scrollIntoView({behavior:"smooth"})', target)
time.sleep(2)
# 下一页 先试用id来找到祖父节点,顺着该节点再继续往下找
paging = driver.find_element(by=By.ID, value='paging')
paging.find_element(by=By.CLASS_NAME, value='layui-laypage-next').click()
time.sleep(2)
# 在右上角的输入框中输入内容
driver.find_element(By.ID, 'searchInput').send_keys('2023-5')
time.sleep(2)
# 点击搜索按钮
btnParent = driver.find_element(By.CLASS_NAME, 'input-group-btn')
btnParent.find_element(By.CLASS_NAME, 'btn-default').click()
time.sleep(2)
# 及时切换窗口
windows = driver.window_handles
driver.switch_to.window(windows[-1])
# 点击第一个结果
items = driver.find_elements(By.CLASS_NAME, 'con-item')
items[0].find_element(By.CLASS_NAME, 'black').click()
# 关闭当前标签页并切换到新的窗口
driver.close()
windows = driver.window_handles
driver.switch_to.window(windows[-1])
time.sleep(2)
# 返回开奖历史记录
driver.switch_to.window(windows[-2])
# 指定元素截图(只截图当前浏览器窗口可见部分)
main = driver.find_element(By.CLASS_NAME, 'main')
main.screenshot('./caipiao_1.png')
input('') # 保持程序运行状态,浏览器不会被关闭
获取前三页的彩票中奖号码,并写入到 Excel 中:
'''
需要安装 xlwings 来操作 Excel
pip install xlwings
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import xlwings as xw
driver = webdriver.Chrome()
driver.get('http://www.cwl.gov.cn/ygkj/kjgg/')
sleep(2)
driver.find_element(By.CLASS_NAME, 'ygkj_wqkjgg_nav').click()
sleep(2)
# 保存结果
days = []
qiu_list = []
def get_data(total_pages, current_page, file_name = 'data'):
tbody = driver.find_element(By.TAG_NAME, 'tbody')
trs = tbody.find_elements(By.TAG_NAME, 'tr')
for tr in trs:
tds = tr.find_elements(By.TAG_NAME, 'td')
days.append(tds[1].text)
qiu_items = tr.find_elements(By.CLASS_NAME, 'qiu-item')
nums = []
for item in qiu_items:
nums.append(item.text)
qiu_list.append(nums)
# 递归调用
if current_page < total_pages:
# 下一页
driver.find_element(By.CLASS_NAME, 'layui-laypage-next').click()
get_data(total_pages, current_page + 1)
else:
driver.quit() # 停止驱动器,关闭网页
# 创建一个不显示、不添加新的工作簿的 Excel 应用程序对象
app = xw.App(visible=False, add_book=False)
# 创建了一个新的工作簿对象,并将其赋值给 wb 变量。
wb = app.books.add()
# 获取第一张表格
sheet_1 = wb.sheets['sheet1']
sheet_1["A1"].value = "时间" # 设置A1单元格的内容
for i in range(1, 7): # 设置 B1 ~ H1的内容
sheet_1[f"{chr(ord('A') + i)}1"].value = f"红{i}"
sheet_1[f"{chr(ord('A') + 7)}1"].value = "蓝"
for i in range(len(days)): # 填写内容
sheet_1[f"A{2 + i}"].value = days[i]
sheet_1[f"B{2 + i}:{chr(ord('B') + 7)}{2 + i}"].value = qiu_list[i]
wb.save(f"./{file_name}.xlsx") # 保存xlsx
wb.close() # 关闭该工作簿对象
app.quit() # 关闭应用程序
print('successful.')
if __name__ == '__main__':
get_data(total_pages=3, current_page=1)

** 参考:**
[1] Selenium Python 教程 - 知乎
[2] Python操作Excel的Xlwings教程(一) - 知乎
[3] xlwings,让excel飞起来!
[4] Python 自动化操作 Excel 看这一篇就够了 - 知乎
[5] 定位策略 | Selenium
本文转载自: https://blog.csdn.net/hao_13/article/details/132701205
版权归原作者 bodyHealthy 所有, 如有侵权,请联系我们删除。
版权归原作者 bodyHealthy 所有, 如有侵权,请联系我们删除。