
前言

前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z
ChatGPT体验地址
文章目录
OpenAI体验通道
ChatGPT体验地址
OpenAI Sora文生视频(图像看作单帧视频)一放出就炸翻整个AI 圈,也是ChatGPT掀起GenAI热潮时隔一年后,OpenAI再次史诗级的更新。OpenAI 随后公布的技术综述,难掩其勃勃雄心:视频生成模型作为世界模拟器。
笔者春节前原计划整理一下对Google Lumiere文生视频的认知,多个因素遗憾推迟。对比看两者大的技术方向均选择了扩散模型,却也有许多关键细节不同。恰好可以借着 OpenAI技术综述来提纲挈领,一起梳理一下,为什么笔者觉得这是又一史诗级的更新。
sora官网:https://openai.com/sora
Spacetime Latent Patches 潜变量时空碎片, 建构视觉语言系统
在“ChatGPT是第一个真正意义的人工通用智能”中,笔者总结过大语言模型借助Embedding将人类的语言 “编码”成自己的语言,然后通过注意力Attention从中提取各种丰富的知识和结构,加权积累与关联生成自己的语言,然后“编码”回人类的语言。
与ChatGPT首先引入Token Embedding 思路一致,针对视觉数据的建模方法则作为构建Sora最重要的第一步。碎片Patch已经被证明是一个有效的视觉数据表征模型,且高度可扩展表征不同类型的视频和图像。将视频压缩到一个低维的潜变量空间,然后将其拆解为时空碎片Spacetime Latent Patches。笔者觉得时空碎片是时空建模的关键,统一了时空分割的"语言"。
有了时空碎片这一统一的语言,Sora 自然解锁了多种技能:1. 自然语言理解,采用DALLE3 生成视频文本描述,用GPT丰富文本prompts ,作为合成数据训练Sora, 架起了GPT 与 Sora语言空间的更精确关联,等于在Token与Patch 之间统一了“文字”;2. 图像视频作为prompts,用户提供的图像或视频可以自然的编码为时空碎片Patch,用于各种图像和视频编辑任务 – 静态图动画、扩展生成视频、视频连接或编辑等。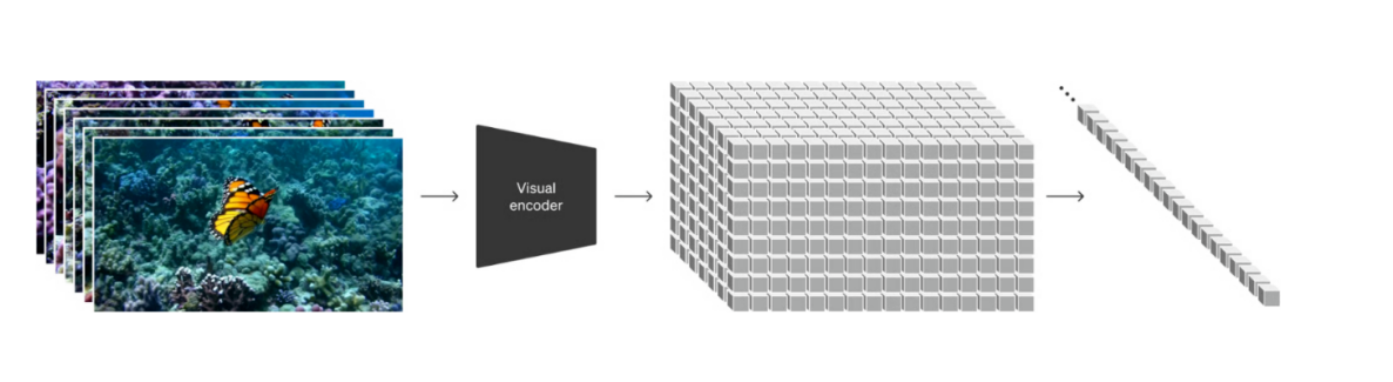
扩散模型与Diffusion Transformer,组合成强大的信息提取器
OpenAI 讲Sora 是一个Diffusion Transformer,这来自伯克利学者的工作Diffusion Transformer (DiT):“采用Transformer的可扩展扩散模型 Scalable diffusion models with transformers”
DiT应用于潜变量时空碎片,学习获得海量视频中时空碎片的动态关联
与“LLM在其高维语言空间中通过Transformer提取人类语言中无数的结构与关联信息”类似,Sora是个基于扩散模型的Transformer,被用于从高维的时空碎片张成的空间中,观察并提取丰富的时空碎片之间的关联与演化的动态过程。如果把前者对应人类读书,后者就是人类的视觉观察。
遗憾的是OpenAI的技术综述没有提供技术细节,不过笔者觉得大家可以参照Google Lumiere的技术原理来大胆推演一下。视频其实是记录了时空信息的载体: 时空碎片patch可以看作是三维空间的点集(x,y,z)的运动(t)或者说其实是个四维时空模型(x,y,z,t)。Sora和Lumiere之类的生成模型的第一步都是如何从中提取出相应的关键信息。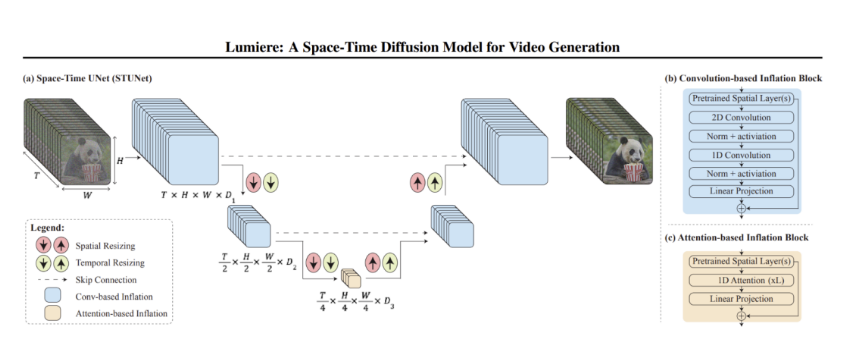
Sora 或Lumiere 视频学习与生成的技术背后蕴含的原理分析
SSM整体思维模型:

- 态空间对事物的表征和刻画:状态空间的高维度,某时刻的信息,即某时刻的事物的能量的概率分布,是众多维度的联合概率分布,各维度都可能具有连续性和非线性,如何用线性系统近似,并最大努力消除非线性的影响非常关键;不同层次的潜变量空间,对信息的提取,和粗颗粒度逐层抽象,都需要类似重整化群 RG中的反复归一化,以消除“近似非线性处理”对整体概率为 1 的偏离。
- 状态空间的动态性:即从时间的维度,研究整个状态空间的变迁。这个变迁是状态空间的大量非时间维度的信息逐层提取,叠加时间这一特殊维度的(状态-时间)序列sequence。不管是高维度低层次的细颗粒度的概率分布的时间变化,还是低维度高层次的粗颗粒度概率分布的时间变化,都是非线性时变系统,用线性时不变(LTI)的模型都是无法很好刻画的。
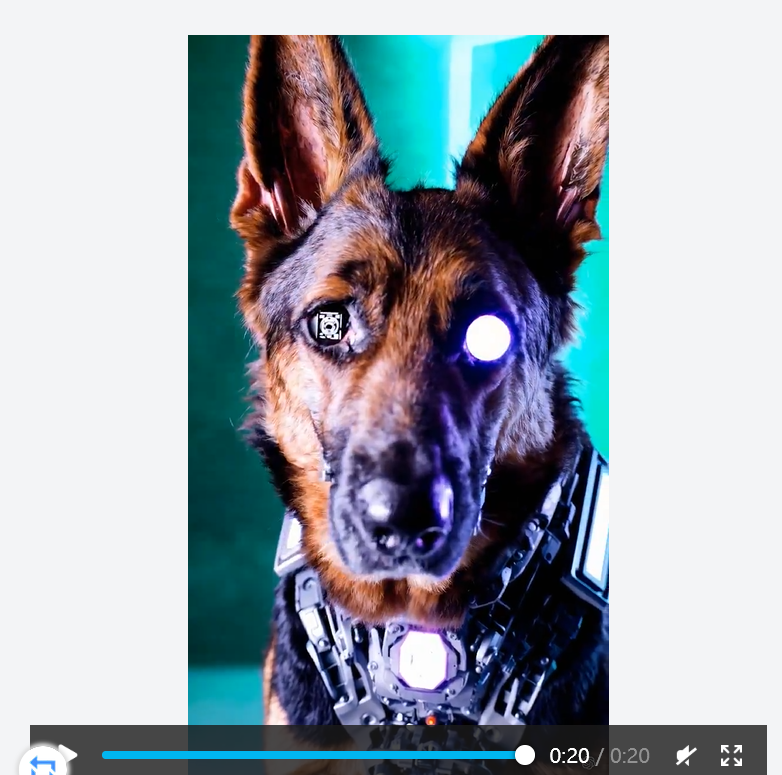
sora最新关键词效果预览
- minecraft with the most gorgeous high res 8k texture pack ever

- this close-up shot of a futuristic cybernetic german shepherd showcases its striking brown and black fur…
- pov footage of an ant navigating the inside of an ant nest

- a golden retriever and samoyed should walk through NYC, then a taxi should stop to let the dogs pass a crosswalk, then they should walk past a pretzel and hot dog stand, and finally they should end up looking at Broadway signs.

最快更新体验通道
Sora体验地址
自媒体运营从入门到精通
从Sora的即将问世,人人做up的时代真正来袭,抓住这个历史性时刻,从运营入手,实现弯道超车!!!
- 🎁本次送书1~3本【取决于阅读量,阅读量越多,送的越多】👈
- ⌛️活动时间:截止到2024-2月27号
- ✳️参与方式:关注博主+三连(点赞、收藏、评论)

版权归原作者 雪碧有白泡泡 所有, 如有侵权,请联系我们删除。