
前端文件流、切片下载和上传技术在提升文件传输效率和优化用户体验方面发挥着关键作用。这些技术不仅可以帮助解决大文件传输过程中可能遇到的问题,如网络超时、内存溢出等,还能通过并行传输和断点续传等功能,提高传输速度和稳定性。
一、前端文件流技术
前端文件流技术主要用于实现文件的流式传输,即数据以流的形式进行发送和接收。通过文件流技术,前端可以按需读取和发送文件数据,而不是一次性加载整个文件,从而降低了内存占用和网络带宽的压力。同时,文件流技术还支持边读取边传输,进一步提高了文件传输的效率。
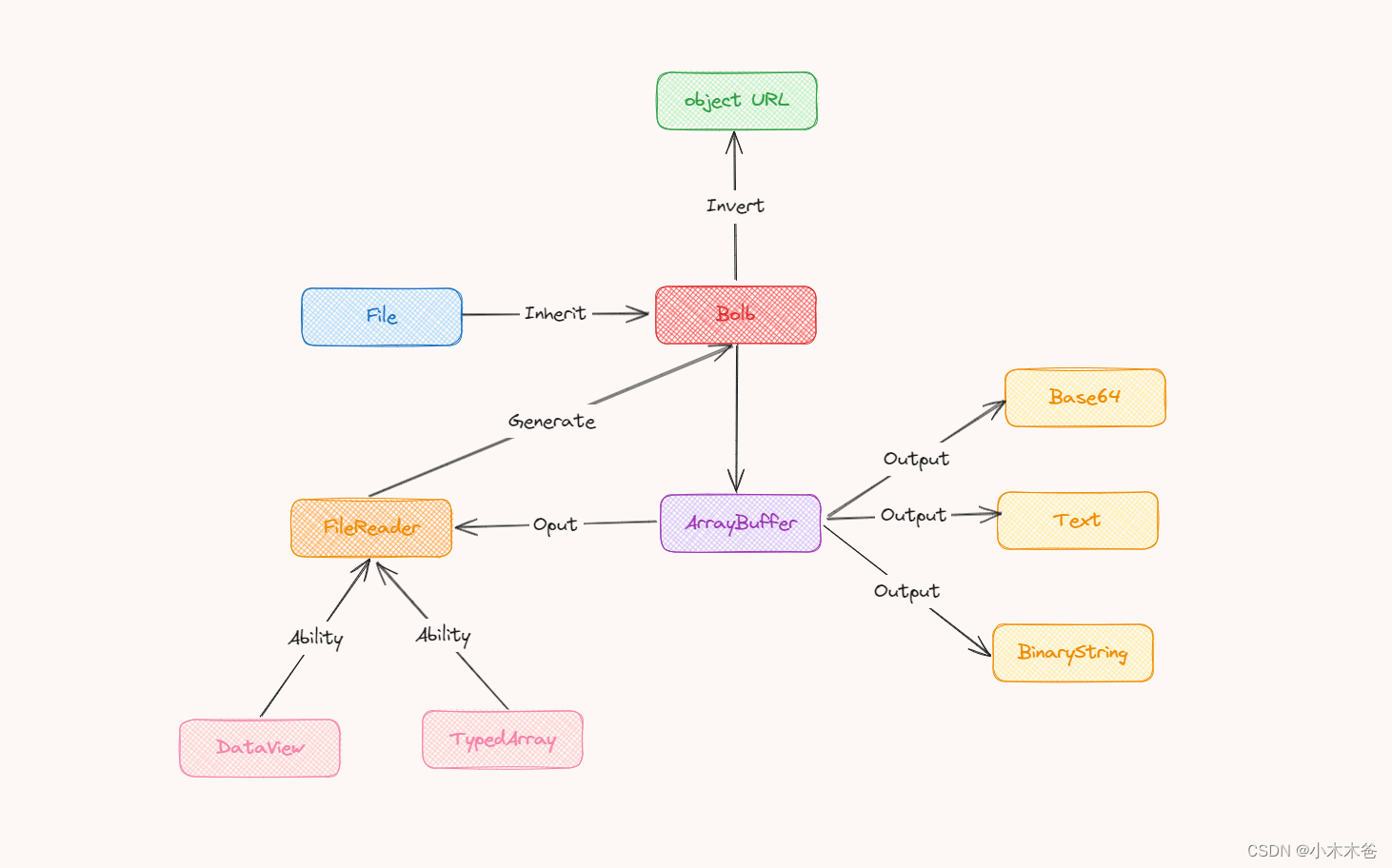
Blob(Binary Large Object)对象和ArrayBuffer是JavaScript中用于处理二进制数据的两种主要方式。它们在处理文件、图像、视频等二进制数据时非常有用,允许我们直接在前端进行高效的数据操作。
Blob对象
Blob对象表示一个不可变的原始数据的类文件对象。Blob表示的数据可以被分割成字节进行读取,它通常用于表示文件的内容。Blob对象常用于处理文件上传、下载以及创建URL引用等场景。
创建Blob对象可以使用Blob构造函数,该构造函数接受两个参数:一个包含数组元素的数组,这些数组元素是ArrayBuffer、ArrayBufferView、Blob、DOMString等类型的对象;以及一个包含对应元素的MIME类型的字符串数组。
例如:
const blob = new Blob(['Hello, world!'], { type: 'text/plain' });
Blob对象有一个非常有用的方法,
slice()
,它用于创建Blob对象的一个副本,包含源Blob中指定范围内的数据。
此外,我们还可以使用
URL.createObjectURL()
方法来创建一个指向Blob对象的URL,这个URL可以用于在
<img>
、
<a>
、
<video>
等标签中引用Blob对象。
ArrayBuffer对象
ArrayBuffer对象用来表示一个通用的、固定长度的原始二进制数据缓冲区。你不能直接操作ArrayBuffer的内容,而是需要通过类型数组对象或DataView对象来读写。ArrayBuffer常用于在网络通信中传输二进制数据,或者用于在Web Workers中共享数据。
创建ArrayBuffer对象很简单,只需要指定所需的字节长度即可:
一旦你有了ArrayBuffer,你可以使用
Int8Array
、
Uint8Array
、
Float32Array
等类型数组对象或者
DataView
对象来读写数据。这些对象提供了以不同格式(如8位整数、32位浮点数等)访问ArrayBuffer内容的方法。
例如:
const buffer = new ArrayBuffer(16);
在这个例子中,我们创建了一个Int32Array视图来访问和修改ArrayBuffer的内容。
总结
Blob对象和ArrayBuffer都是处理二进制数据的重要工具,但它们的使用场景和方式有所不同。Blob对象主要用于表示不可变的文件或二进制数据块,而ArrayBuffer则提供了一个原始二进制数据缓冲区,你可以通过类型数组或DataView对象来读写这个缓冲区的内容。在选择使用哪个工具时,应该根据你的具体需求来决定。
二、切片下载技术
传统文件下载的性能问题
主要体现在以下几个方面:
- 下载速度受限:传统的文件下载方法往往受到网络带宽、服务器性能以及文件大小等因素的限制。在大文件下载时,如果网络带宽不足或服务器处理能力有限,下载速度可能会非常慢,导致用户等待时间过长。
- 资源占用高:传统的文件下载方式在下载过程中会占用大量的系统资源,包括内存、CPU和磁盘空间等。特别是在下载大文件时,这些资源的占用会更加明显,可能会影响其他应用程序的正常运行。
- 断点续传功能不足:传统的文件下载方式通常不支持断点续传功能,一旦下载过程中网络中断或其他原因导致下载失败,用户需要重新开始下载整个文件,这不仅浪费了时间,还可能增加了网络负担。
- 并行处理能力有限:传统的文件下载方式往往无法充分利用现代计算机的多核处理器和网络并行传输能力,导致下载效率低下。特别是在多文件同时下载时,传统方法可能无法有效管理并优化下载过程。
为了解决这些问题,现代的文件下载技术已经发展出了多种优化策略,如分片下载、断点续传、多线程下载等。这些技术可以有效提高文件下载的速度和稳定性,减少资源占用,提升用户体验。同时,随着云计算和分布式存储技术的发展,文件下载的性能问题也得到了进一步的改善。
利用文件切片提升下载效率
利用文件切片来提升下载效率是一种非常有效的策略,尤其是在处理大文件下载时。这种方法通过将大文件切割成多个小文件片段(即切片),然后并行下载这些切片,可以显著提高下载速度和效率。
以下是利用文件切片提升下载效率的主要优势:
- 并行下载:通过将文件切割成多个切片,可以同时下载多个切片,充分利用网络带宽和计算机的多核处理器能力。这样,下载过程不再受到单一连接或线程的限制,可以显著提高下载速度。
- 断点续传:切片下载方式天然支持断点续传功能。如果在下载过程中网络中断或其他原因导致某个切片下载失败,只需要重新下载失败的切片,而不需要重新下载整个文件。这大大减少了用户的等待时间和网络负担。
- 负载均衡:当从多个服务器或不同的网络路径下载切片时,可以实现负载均衡,避免单一服务器或网络路径的拥堵。这有助于确保下载的稳定性和可靠性。
- 灵活性和可扩展性:切片下载策略可以根据网络条件、服务器性能和文件大小等因素进行灵活调整。例如,可以根据网络带宽和服务器负载动态调整切片的大小和并行下载的线程数。
实现文件切片下载通常需要使用专门的下载工具或库,这些工具或库可以处理切片的切割、并行下载、切片合并以及错误处理等过程。同时,为了确保切片下载的效率和稳定性,还需要考虑一些关键因素,如切片大小的选择、并发线程数的控制以及错误重试机制的设计等。
总之,利用文件切片提升下载效率是一种非常实用的技术,尤其适用于处理大文件下载和在网络环境不稳定的情况下进行下载的场景。
const [selectedFile, setSelectedFile] = useState(null);
const [progress, setProgress] = useState(0);
// 处理文件选择事件
function handleFileChange(event) {
setSelectedFile(event.target.files[0]);
}
// 处理文件上传事件
function handleFileUpload() {
if (selectedFile) {
// 计算切片数量和每个切片的大小
const fileSize = selectedFile.size;
const chunkSize = 1024 * 1024; // 设置切片大小为1MB
const totalChunks = Math.ceil(fileSize / chunkSize);
// 创建FormData对象,并添加文件信息
const formData = new FormData();
formData.append('file', selectedFile);
formData.append('totalChunks', totalChunks);
// 循环上传切片
for (let chunkNumber = 0; chunkNumber < totalChunks; chunkNumber++) {
const start = chunkNumber * chunkSize;
const end = Math.min(start + chunkSize, fileSize);
const chunk = selectedFile.slice(start, end);
formData.append(`chunk-${chunkNumber}`, chunk, selectedFile.name);
}
// 发起文件上传请求
axios.post('/upload', formData, {
onUploadProgress: progressEvent => {
const progress = Math.round((progressEvent.loaded / progressEvent.total) * 100);
setProgress(progress);
}
})
.then(response => {
console.log('文件上传成功:', response.data);
})
.catch(error => {
console.error('文件上传失败:', error);
});
}
}
实现客户端切片下载的方案
实现客户端切片下载的方案通常涉及以下几个关键步骤:
- 文件切片: - 在服务器端,将待下载的大文件切割成多个小文件切片(chunks)。切片的大小可以根据实际情况进行调整,通常要考虑文件总大小、网络带宽、以及服务器性能等因素。- 生成切片时,可以为每个切片生成唯一的标识符,以便于在下载过程中追踪和管理。
- 切片信息获取: - 客户端首先向服务器发送请求,获取文件的切片信息,包括切片数量、每个切片的大小、切片对应的URL或下载地址等。- 客户端可以根据这些信息制定下载策略,比如确定并发下载的切片数量。
- 并发下载: - 客户端根据获取到的切片信息,创建多个下载任务,每个任务负责下载一个切片。- 可以使用多线程、异步请求或其他并行处理机制来实现切片的并发下载。- 在下载过程中,可以实时更新已下载切片的进度,并显示给用户。
- 切片合并: - 当所有切片下载完成后,客户端需要将这些切片按照正确的顺序合并成一个完整的文件。- 合并过程中要确保数据的完整性和正确性,避免出现数据损坏或丢失的情况。
- 错误处理和重试机制: - 在下载过程中,如果某个切片下载失败,客户端应该能够捕获到这个错误,并尝试重新下载该切片。- 可以设置重试次数和重试间隔,以应对网络不稳定或服务器故障等情况。
- 进度和状态展示: - 客户端应该能够实时展示每个切片的下载进度,以及整个文件的下载状态。- 这有助于用户了解下载进度和剩余时间,提供更好的用户体验。
在实现切片下载方案时,还需要考虑以下因素:
- 安全性:确保切片下载过程中的数据传输是安全的,可以使用HTTPS协议进行加密传输。
- 性能优化:根据网络条件和服务器性能调整切片大小和并发下载数量,以优化下载速度和资源利用率。
- 兼容性:确保切片下载方案在不同浏览器和客户端平台上的兼容性。
具体的实现方式可以根据所使用的编程语言、框架和库来灵活选择和设计。例如,在JavaScript中,可以使用Fetch API、XMLHttpRequest或第三方库(如axios)来实现切片下载和并发请求。在服务器端,可以根据具体的服务器架构和编程语言提供相应的切片生成和下载接口。
function downloadFile() {
// 发起文件下载请求
fetch('/download', {
method: 'GET',
headers: {
'Content-Type': 'application/json',
},
})
.then(response => response.json())
.then(data => {
const totalSize = data.totalSize;
const totalChunks = data.totalChunks;
let downloadedChunks = 0;
let chunks = [];
// 下载每个切片
for (let chunkNumber = 0; chunkNumber < totalChunks; chunkNumber++) {
fetch(`/download/${chunkNumber}`, {
method: 'GET',
})
.then(response => response.blob())
.then(chunk => {
downloadedChunks++;
chunks.push(chunk);
// 当所有切片都下载完成时
if (downloadedChunks === totalChunks) {
// 合并切片
const mergedBlob = new Blob(chunks);
// 创建对象 URL,生成下载链接
const downloadUrl = window.URL.createObjectURL(mergedBlob);
// 创建 <a> 元素并设置属性
const link = document.createElement('a');
link.href = downloadUrl;
link.setAttribute('download', 'file.txt');
// 模拟点击下载
link.click();
// 释放资源
window.URL.revokeObjectURL(downloadUrl);
}
});
}
})
.catch(error => {
console.error('文件下载失败:', error);
});
}
三、切片上传技术
切片上传技术同样将大文件切割成多个小文件(切片),然后并行上传这些切片。这种方式不仅降低了单次上传的数据量,减少了网络超时和内存溢出的风险,还可以通过并发上传提高整体上传速度。同时,切片上传还支持断点续传和秒传功能。断点续传可以在网络中断后从上次中断的位置继续上传,避免了重复上传已完成的部分;秒传则是在检测到服务器已存在相同文件时,直接完成上传任务,无需再次上传文件内容。
四、优化策略与用户体验
传统的文件上传方式存在的问题
主要体现在以下几个方面:
容错性差:传统的文件上传方式通常将文件直接保存到项目服务器中。一旦服务器出现故障或遭受攻击,上传的文件就可能丢失,从而导致数据损失。此外,如果服务器遇到大量并发上传请求,也容易出现性能下降或崩溃的情况。
占用服务器资源:随着上传文件的数量和体积增加,服务器需要消耗更多的存储空间和计算资源来处理这些文件。这可能导致服务器性能下降,影响其他应用的正常运行。
不适应集群环境:在集群环境中,文件上传与下载可能不在同一个服务器上,这增加了文件管理的复杂性。此外,传统的文件上传方式通常没有考虑负载均衡和容错机制,使得整个系统更加脆弱。
安全性不足:传统的文件上传方式往往缺乏对上传内容的监管和审批功能,这可能导致不合规或恶意文件的上传。同时,传输过程中也可能存在数据泄露或被篡改的风险。
追溯功能弱:对于上传的文件,传统的文件上传方式往往无法提供有效的追溯功能。例如,无法记录谁上传了哪个文件、上传时间、上传的文件内容等信息,这使得在出现问题时难以进行排查和追责。
传输效率低下:对于大文件的上传,传统的文件上传方式可能面临传输速度慢的问题。此外,如果网络不稳定或存在其他干扰因素,还可能导致上传失败或传输中断。
操作繁琐:传统的文件上传方式通常需要用户手动进行一系列操作,如选择文件、点击上传按钮等。这增加了用户的操作负担,降低了工作效率。
综上所述,传统的文件上传方式在容错性、服务器资源占用、集群环境适应性、安全性、追溯功能、传输效率以及操作便捷性等方面都存在明显的问题。为了解决这些问题,现代的文件上传技术已经发展出了多种优化策略,如使用分布式文件系统、加密传输、自动化策略等,以提高文件上传的效率、安全性和用户体验。
为了进一步优化文件传输效率和用户体验,可以采取以下策略:
- 合理设置切片大小:切片大小应根据文件大小、网络带宽和服务器性能等因素进行合理设置。过小的切片可能导致过多的网络请求和开销,而过大的切片则可能降低并行传输的效果。
- 并发控制:根据网络环境和服务器性能,合理控制并发上传或下载的切片数量,以避免网络拥堵和服务器过载。
- 进度反馈与可视化:通过进度条、百分比等形式实时反馈文件传输的进度,让用户了解当前传输状态。同时,对于大型文件的传输,可以提供预计完成时间等更详细的信息。
- 异常处理与提示:在文件传输过程中,对于可能出现的网络中断、文件损坏等异常情况,应提供明确的提示和解决方案,帮助用户快速恢复传输任务。
综上所述,前端文件流、切片下载和上传技术在提升文件传输效率和优化用户体验方面具有重要意义。通过合理应用这些技术,并结合具体的业务场景和需求,可以为用户提供更加高效、稳定、便捷的文件传输体验。
版权归原作者 小木木爸 所有, 如有侵权,请联系我们删除。