
Hive的安装和基本操作实验
一、实验目的
了解Hive的安装和基本操作
二、实验原理
Hive定义了一套自己的SQL,简称HQL,它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。
- DDL操作(数据定义语言)包括:Create、Alter、Show、Drop等。
(1)create database- 创建新数据库
(2)alter database - 修改数据库
(3)drop database - 删除数据库
(4)create table - 创建新表
(5)alter table - 变更(改变)数据库表
(6)drop table - 删除表
(7)create index - 创建索引(搜索键)
(8)drop index - 删除索引
(9)show table - 查看表
- DML操作(数据操作语言)包括:Load 、Insert、Update、Delete、Merge。
(1)load data - 加载数据
①insert into - 插入数据
②insert overwrite - 覆盖数据(insert ... values从Hive 0.14开始可用。)
(2)update table - 更新表(update在Hive 0.14开始可用,并且只能在支持ACID的表上执行)
(3)delete from table where id = 1; - 删除表中ID等于1的数据(delete在Hive 0.14开始可用,并且只能在支持ACID的表上执行)
(4)merge - 合并(MERGE在Hive 2.2开始可用,并且只能在支持ACID的表上执行)
注意:频繁的update和delete操作已经违背了Hive的初衷。不到万不得已的情况,还是使用增量添加的方式最好。
三、Hive的安装****
1、实验环境(请补充各软件版本号)****
Ubuntu
22.04.3
Jdk
1.8.0_341
Hadoop
3.2.3
Hive
3.1.2
MySQL
8.0.3
2、Hive的安装
Hive的安装和配置主要过程、出现的问题及解决方法(截图)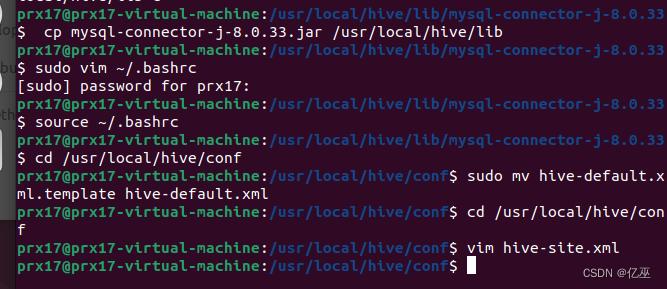
未出现问题
四、Hive实验操作内容(以下各步截图)****
1.数据库的创建与删除
2.表的创建、修改、删除
3.表中数据的导入导出
4.词频统计(本地、HDFS)
(一)****实验环境准备
1.首先在Linux本地新建/data/hivetest目录。
sudo mkdir -p /data/hivetest

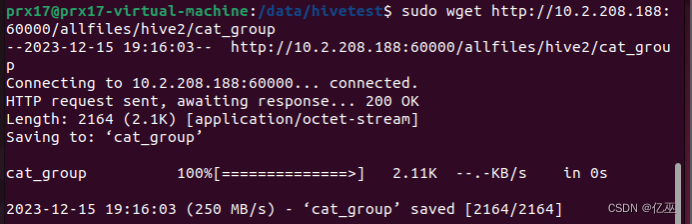
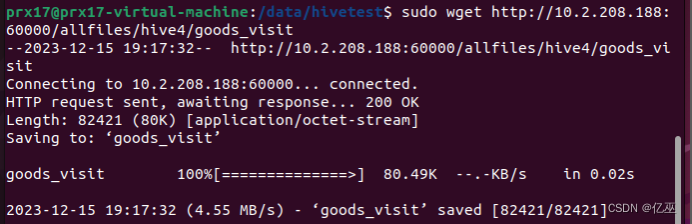
2.切换到/data/hivetest目录下,使用wget命令,下载http://10.2.208.188:60000/allfiles/hive2中的cat_group文件
http://10.2.208.188:60000/allfiles/hive4中的goods_visit文件
cd /data/hivetest
sudo wget http://10.2.208.188:60000/allfiles/hive2/cat_group
sudo wget http://10.2.208.188:60000/allfiles/hive4/goods_visit

sudo wget http://10.2.208.188:60000/allfiles/hive2/cat_group
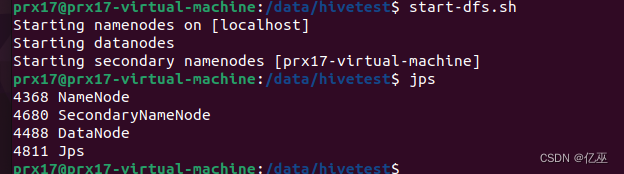
3.输入jps检查Hadoop相关进程,是否已经启动。若未启动,切换到/usr/local/hadoop/sbin目录下,启动Hadoop。
jps
cd /usr/local/hadoop/sbin
./start-all.sh
4.开启Hive,首先,需要保证Mysql启动。执行以下命令,查看Mysql的运行状态。
sudo service mysql status
此语句发生报错

使用sudo systemctl status mysql
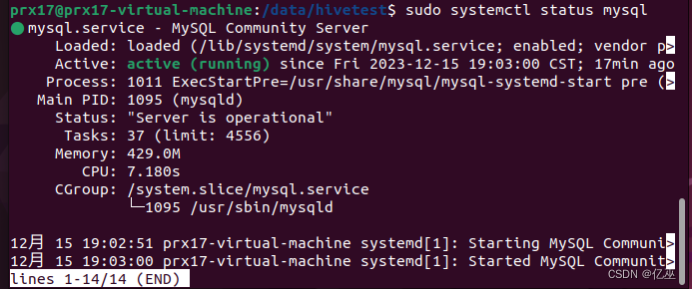
输出显示Mysql未启动。执行以下启动命令。
sudo service mysql start

sudo service mysql start
然后切换到/usr/local/hive/bin目录下,开启Hive。
cd /usr/local/hive/bin
./hive

(二)****Hive数据仓库的操作
1.在Hive中创建一个数据仓库,名为DB。
create database DB;
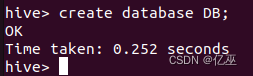
2.以上简单创建了一个DB库,但是这条sql可以更进一步的优化,我们可以加上if not exists。
create database if not exists DB;

解析:在创建库时,应避免新建的库名与已有库名重复,如果库名重复将会报出以下错误(我在已有DB库的前提下,再次创建了DB库)。

错误提示数据仓库DB已经存在, 那么加入的if not exists就起了作用,如下(在已有DB库的前提下,再次创建DB库,提示成功不会报错)

加入if not exists的意思是如果没有DB库就创建,如果已有就不再创建。
3.查看数据仓库DB的信息及路径。
Describe database DB;
describe database pp;

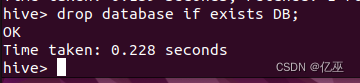
4.删除名为DB的数据仓库。
Drop database if exists DB;
(三)****Hive数据表的操作
Hive的数据表分为两种:内部表和外部表。
Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据,生产中常使用外部表。
下面详细介绍对表操作的命令及使用方法:
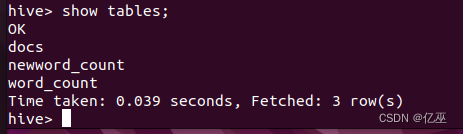
即将创建的表,表名不能和已有表名重复,否则会报错,现在我们show tables一下,查看已存在的表。
Show tables;
1.创建一个名为cat的内部表,有两个字段为cat_id和cat_name,字符类型为string。
Create table cat(cat_id string,cat_name string);

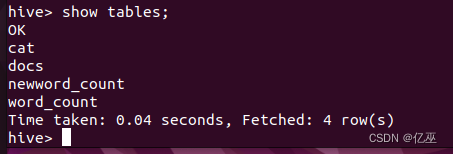
查看是否创建成功。
show tables;
下面我们再次创建一个与刚才表名相同的表,看一下报错。
create table cat(cat_id string,cat_name string);

提示错误,该表已经存在!说明表与库一样,名称不能重复,解决方法是加入if not exists。
2.创建一个外部表,表名为cat2,有两个字段为cat_id和cat_name,字符类型为string。
create external table if not exists cat2(cat_id string,cat_name string);
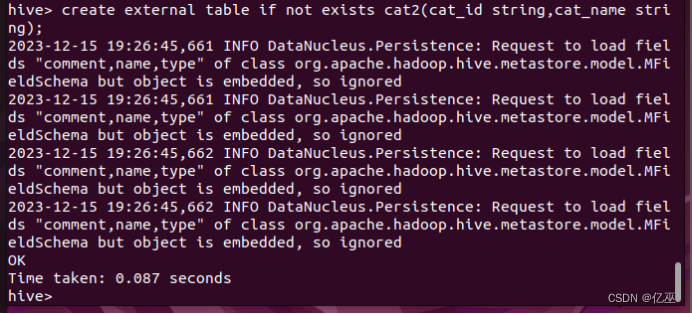
查看是否创建成功。
show tables;
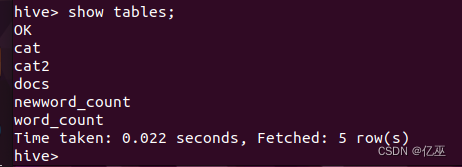
外部表较内部表而言,只是在create后加了一个external。
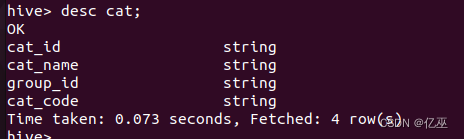
3.修改cat表的表结构。对cat表添加两个字段group_id和cat_code。
alter table cat add columns(group_id string,cat_code string);

使用desc命令查看一下加完字段后的cat表结构 。
desc cat;
4.修改cat2表的表名。把cat2表重命名为cat3 。
alter table cat2 rename to cat3;

这个命令可以让用户为表更名,数据所在的位置和分区名并不改变。
5.删除名为cat3的表并查看。
drop table cat3;
show tables;
6.创建与已知表相同结构的表,创建一个与cat表结构相同的表,名为cat4,这里要用到like关键字。
create table cat4 like cat;
创建完成并查看结果。
show tables;
(四)****Hive中数据的导入导出
以下介绍四种常见的数据导入方式:
1.从本地文件系统中导入数据到Hive表。
首先,在Hive中创建一个cat_group表,包含group_id和group_name两个字段,字符类型为string,以“\t”为分隔符,并查看结果。
Create table cat_group(group_id string,group_name string) row format delimited fields terminated by '\t' stored as textfile;
show tables;
[row format delimited]关键字,是用来设置创建的表在加载数据的时候,支持的列分隔符。
[stored as textfile]关键字,是用来设置加载数据的数据类型,默认是TEXTFILE,如果文件数据是纯文本,就是使用 [stored as textfile],然后从本地直接拷贝到HDFS上,Hive直接可以识别数据。
create table cat_group(group_id string,group_name string) row format delimited fields terminated by '\t' stored as textfile;
然后,将Linux本地/data/hivetest目录下的cat_group文件导入到Hive中的cat_group表中。
load data local inpath '/home/prx17/Desktop/cat_group' into table cat_group;

通过select语句查看cat_group表中是否成功导入数据,由于数据量大,使用limit关键字限制输出10条记录。
select * from cat_group limit 10;
Select * from cat_group limit 10;
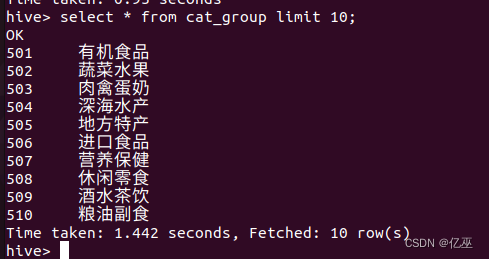
导入成功。
2.将HDFS上的数据导入到Hive中。
首先,另外开启一个操作窗口,在HDFS上创建/myhivetest目录。
Hdfs fs -mkdir /myhivetest

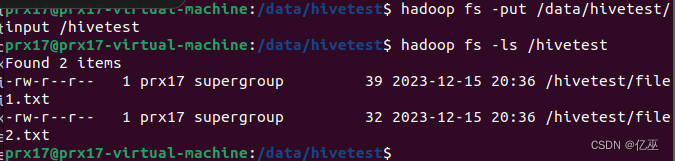
然后,将本地/data/hivetest/下的cat_group表上传到HDFS的/myhivetest上,并查看是否创建成功。
hadoop fs -put /data/hivetest/cat_group /myhivetest
hadoop fs -ls /myhivetest

接着,在Hive中创建名为cat_group1的表,创表语句如下。
create table cat_group1(group_id string,group_name string)
row format delimited fields terminated by '\t' stored as textfile;

最后,将HDFS下/myhivetest中的表cat_group导入到Hive中的cat_group1表中 ,并查看结果。
load data inpath '/myhivetest/cat_group' into table cat_group1;
select * from cat_group1 limit 10;
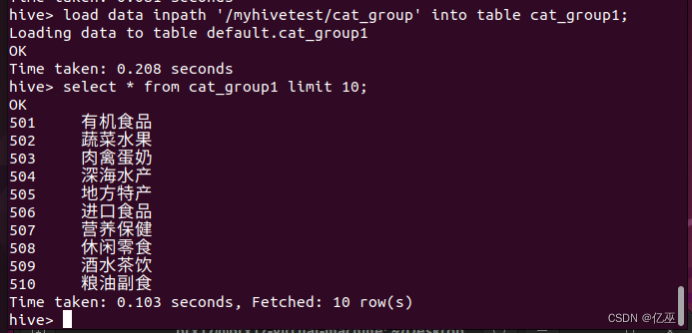
导入成功。
提示:HDFS中数据导入到Hive中与本地数据导入到hive中的区别是load data后少了local。
3.从别的表中查询出相应的数据并导入到Hive中。
首先在Hive中创建一个名为cat_group2的表。
create table cat_group2(group_id string,group_name string)
row format delimited fields terminated by '\t' stored as textfile;

用下面两种方式将cat_group1表中的数据导入到cat_group2表中。
insert into table cat_group2 select * from cat_group1;
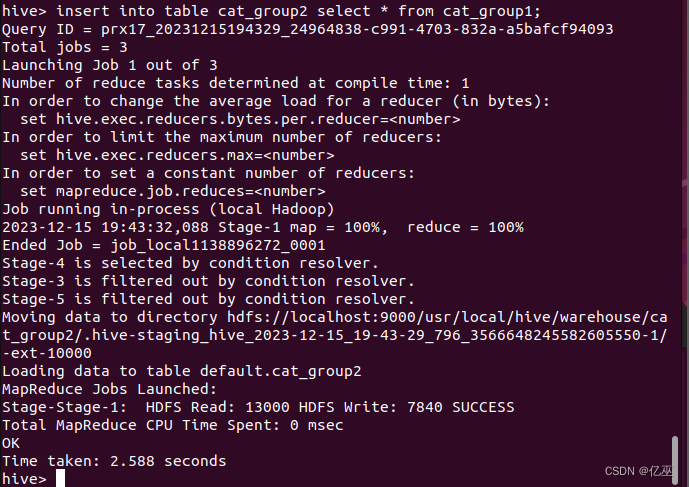
或 insert overwrite table cat_group2 select * from cat_group1;
(insert overwrite 会覆盖数据)。
导入完成后,用select语句查询cat_group2表。
select * from cat_group2 limit 10;

4.在创建表的时候从别的表中查询出相应数据并插入到所创建的表中。
Hive中创建表cat_group3并直接从cat_group2中获得数据。
create table cat_group3 as select * from cat_group2;
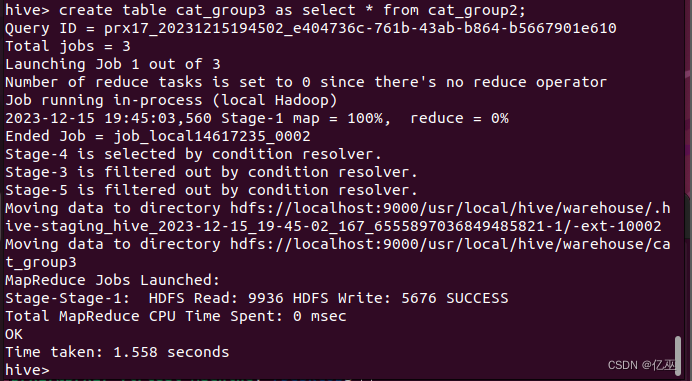
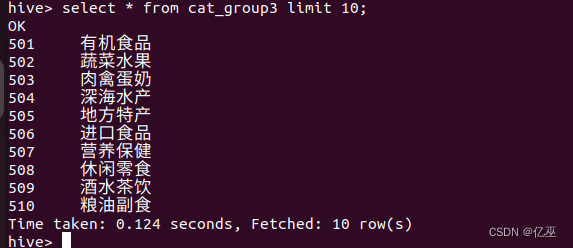
创建并导入完成,用select语句查询实验结果。
select * from cat_group3 limit 10;
(五)Hive的排序(Order** **by)
Hive中的Order by和传统Sql中的Order by一样,对查询结果做全局排序,会新启动一个Job进行排序,会把所有数据放到同一个Reduce中进行处理,不管数据多少,不管文件多少,都启用一个Reduce进行处理。如果指定了hive.mapred.mode=strict(默认值是nonstrict),这时就必须指定limit来限制输出条数,原因是:所有的数据都会在同一个Reducer端进行,数据量大的情况下可能不出结果,那么在这样的严格模式下,必须指定输出的条数。
- 在Hive中创建一个goods_visit表,有goods_id和click_num两个字段,字符类型分别为string和int,以‘\t’为分隔符。

- 创建完成,查询是否创建该表(show),并查看表视图(describe)。

视图

- 将Linux本地/data/hivetest目录下的goods_visit文件导入到Hive中的goods_visit表中。

- 使用‘Order** by’对商品点击次数从大到小排序,并通过‘l******imit****’取出前20条数据。
select * from cat_group order by group_name desc limit 10;
正序就不加desc

(六)****三种常见的数据导出方式
1.导出到本地文件系统。
首先,在Linux本地新建/data/hivetest/out目录。
mkdir -p /data/hivetest/out

并将Hive中的cat_group表导出到本地文件系统/data/hivetest/out中。
注意:方法和导入数据到Hive不一样,不能用insert into来将数据导出。
(注意:应先修改文件夹访问权限,否则无法将数据写入本地文件系统
$ sudo chown -R hadoop:hadoop /data/hivetest )

insert overwrite local directory '/data/hivetest/out' select * from cat_group;
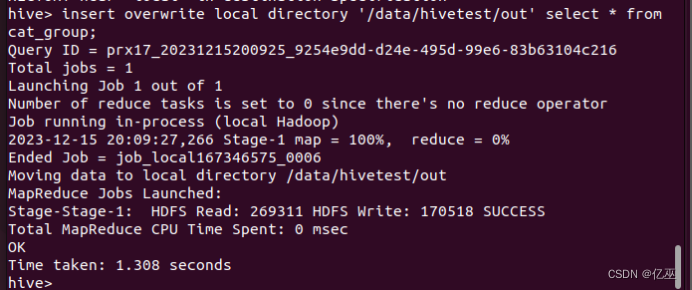
导出完成后,在Linux本地切换到/data/hive2/out目录,通过cat命令查询导出文件的内容。
cd /data/hivetest/out
ls
cat 000000_0
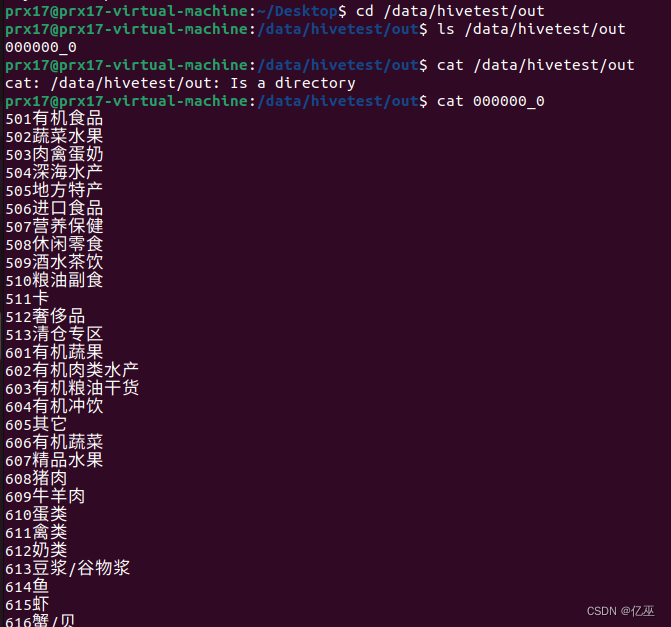
可以看到导出的数据,字段之间没有分割开,所以我们使用下面的方式,将输出字段以“\t”键分割。
insert overwrite local directory '/data/hivetest/out' select group_id,concat('\t',group_name) from cat_group;
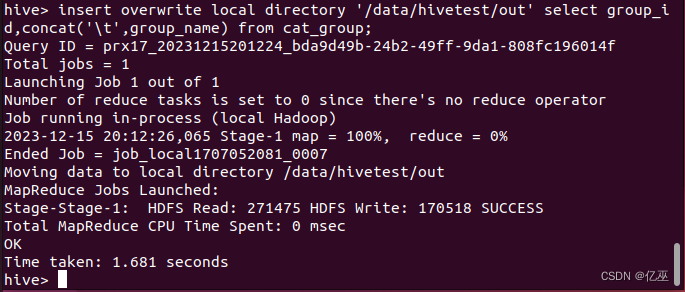
通过cat命令查询/data/hivetest/out目录下的导出文件。
cd /data/hivetest/out/
cat 000000_0

2.Hive中数据导出到HDFS中
在HDFS上创建/myhivetest/out目录。
hadoop fs -mkdir -p /myhivetest/out

将Hive中的表cat_group中的数据导入到HDFS的/myhivetest/out目录里。
insert overwrite directory '/myhivetest/out' select group_id,concat('\t',group_name) from cat_group;
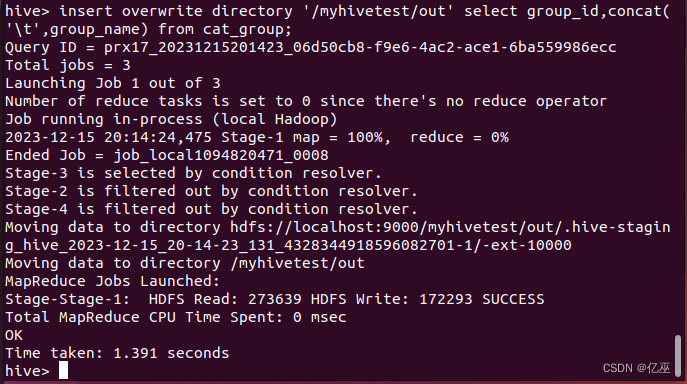
导入完成后,在HDFS上的/myhivetest/out目录下查看结果。
hadoop fs -ls /myhivetest/out

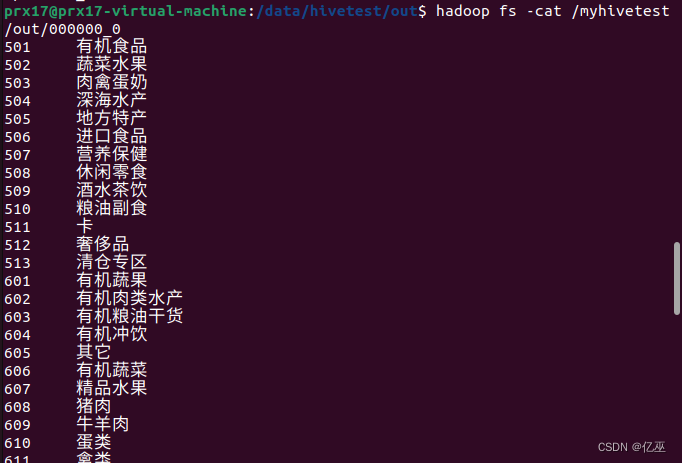
3.导出到Hive的另一个表中。
将Hive中表cat_group中的数据导入到cat_group4中(两表字段及字符类型相同)。
首先在Hive中创建一个表cat_group4,有group_id和group_name两个字段,字符类型为string,以‘\t’为分隔符。
create table cat_group4(group_id string,group_name string)
row format delimited fields terminated by '\t' stored as textfile;

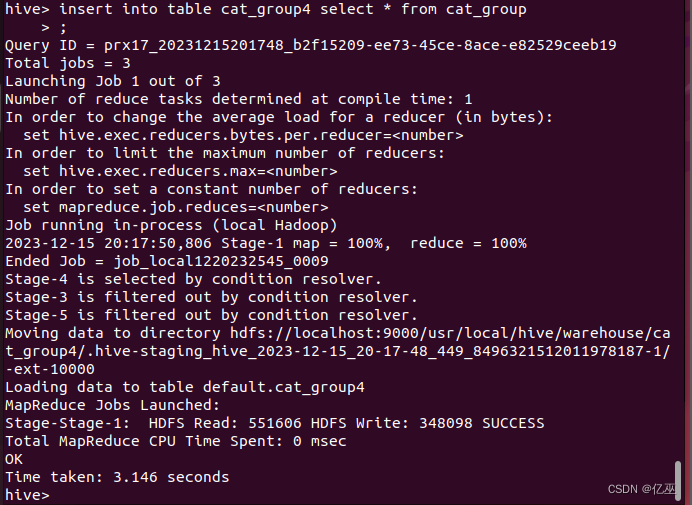
然后将cat_group中的数据导入到cat_group4中。
insert into table cat_group4 select * from cat_group;
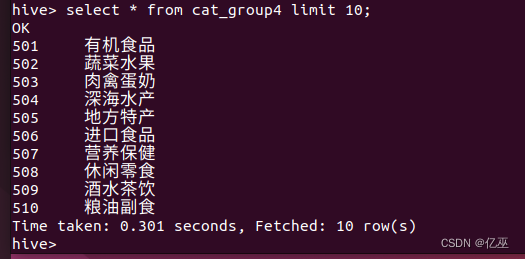
导入完成后,查看cat_group4表中数据。
select * from cat_group4 limit 10;
(七)使用Hive进行词频统计
首先,需要创建一个需要分析的输入数据文件,然后编写HiveQL语句实现WordCount算法,在Ubuntu中实现步骤如下:
1.对本地文件进行词频统计
(1)创建input目录,其中input为输入目录。命令如下:
$ cd /data/hivetest
$ mkdir input

- 在input文件夹中创建两个测试文件file1.txt和file2.txt,输入任意行文本

- 进入hive命令行界面,编写HiveQL语句实现WordCount算法

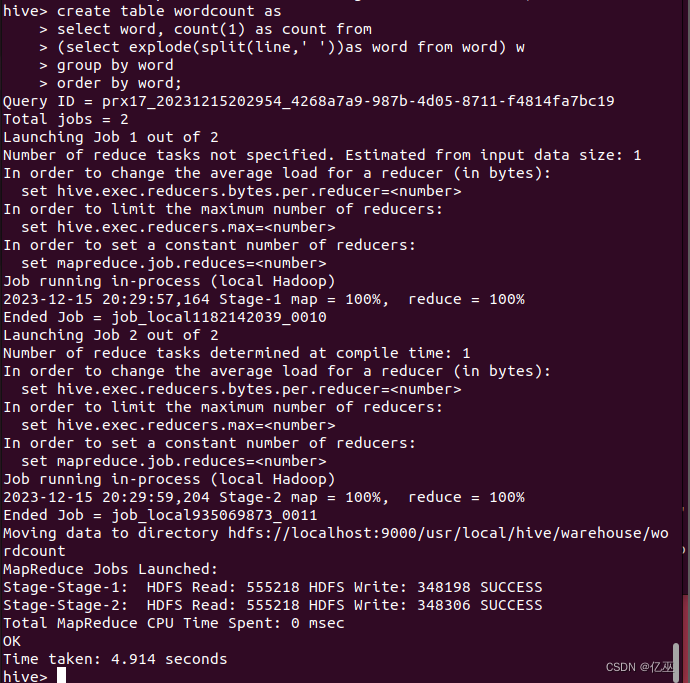
- 执行完成后,用select语句查看运行结果
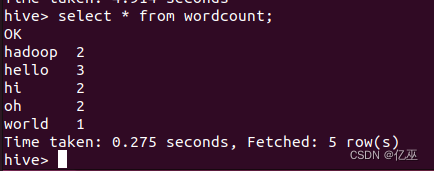
- 对HDFS中的文件进行词频统计。修改上述两个file文件内容,上传至HDFS中myhivetest/input中,使用Hive对HDFS中的这两个文件进行词频统计。
修改文件内容


上传到hdfs
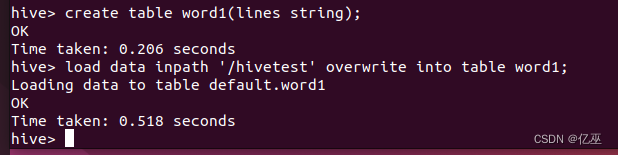
数据加载进word1中
词频统计语句
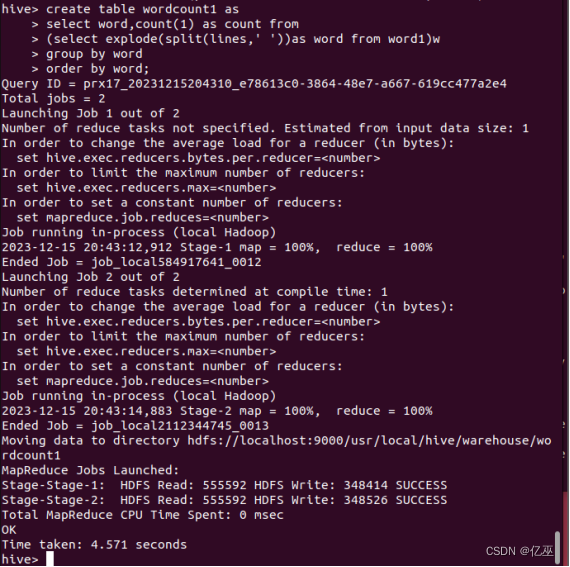
结果
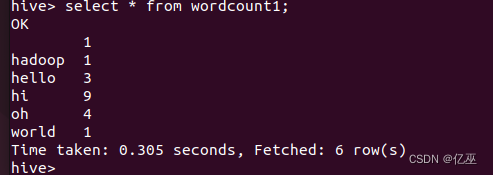
遇到的问题和解决办法(有一些是第一次操作的报错)
问题1:alter table usr rename to user;报错
FAILED: ParseException line 1:26 cannot recognize input near 'rename' 'to' 'user' in alter table statement
根据常见的数据库系统,"usr"和"user"都是保留字或关键字,不能直接用作表名或列名。
使用了反引号()将表名括起来,以确保不与关键字冲突。  ****问题2****:ALTER TABLE usersCHANGE COLUMNusername` after age;报错,因为username和age的类型不同
建立新列为同类型
再次置于后成功
问题3:
词频统计时统计结果为字母而不是我需要的词,发现是语句有个错误,split(lines,’ ’)在’’之间需要有一个空格。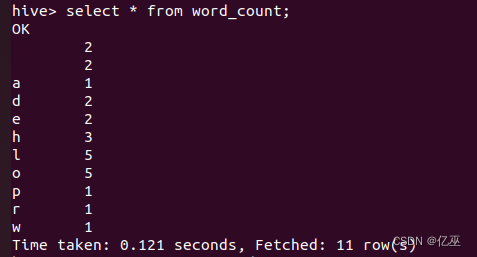
添加空格之后,才是按空格分开,不然是按照字母切分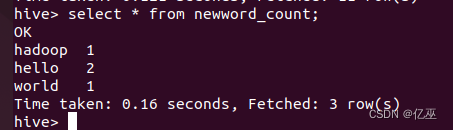
问题4:
如果数据库非空的话删除会出现错误。
版权归原作者 亿巫 所有, 如有侵权,请联系我们删除。