
问题:根据指定关键字爬取某网站的回答内容
- 根据指定关键字爬取回答摘要
- 过滤重复数据
- 把数据保存到mongodb
- 部署到服务器上
- 每隔一个小时爬一次
技术选型
在开始之前需要先对网站进行分析,是否需要登录,防爬做的怎么样,如果网站的防爬做的比较好,并且要爬的数据量并不大,那就选择最简单最通用的方式,也就是用selenium做。
爬的数据是不确定的,采用非关系型数据库比较好,这里使用mongodb
爬虫部署可以使用定时任务,也可以使用爬虫管理系统,这里使用爬虫管理系统部署,像下图这样子的功能。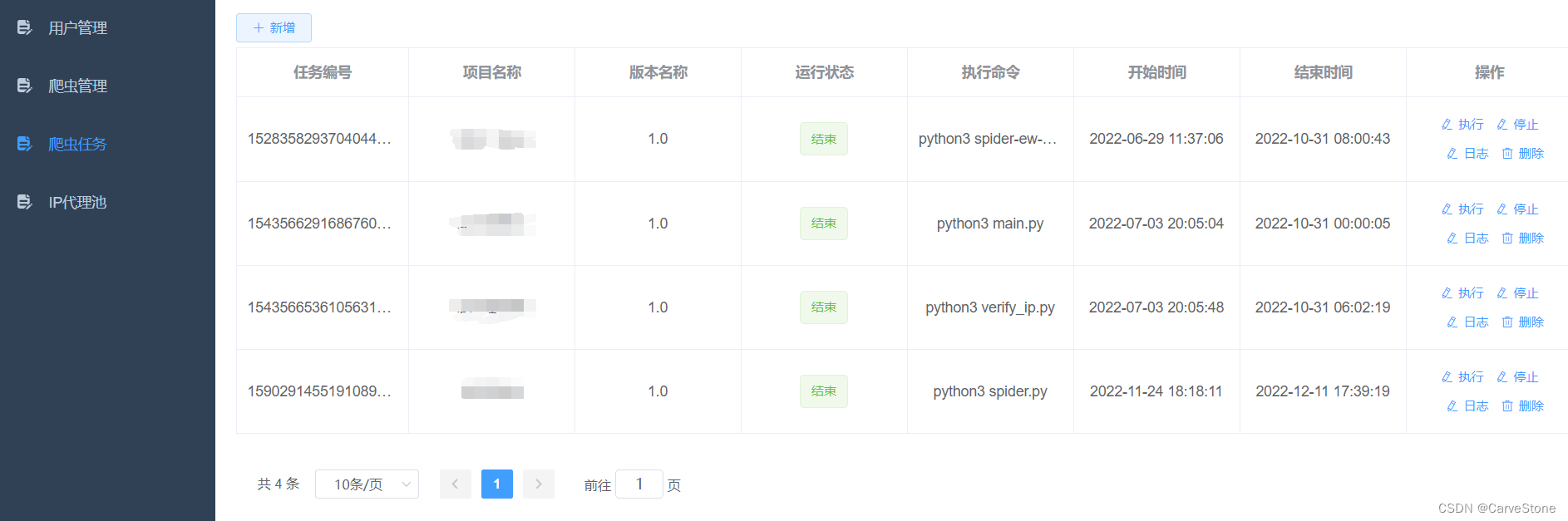
代码实现
考虑到要部署到服务器上,selenium要设置成无界面的,无界面的selenium有很多坑,下面的代码可以拿去参考。
# -*- coding: UTF-8 -*-from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
import os
import time
import csv
import mongoConfig as mongo
classAnswerItem:def__init__(self):
self.href =''
self.question =''
self.excerpt =''
self.create_time =None
self.update_time =Nonedef__str__(self):return"AnswerItem(href="+ self.href +",question="+ self.question + \
",excerpt="+ self.excerpt +")"classSpider:def__init__(self, url):
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')# 这个配置很重要
options.add_argument(f'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36')
self.driver = webdriver.Chrome(chrome_options=options)withopen('./stealth.min.js')as f:
js = f.read()
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{"source": js
})
self.url = url
# 滚动页面到底层defscroll_bottom(self,driver):
temp_height =0whileTrue:# 循环将滚动条下拉
driver.execute_script("window.scrollBy(0,1000)")# sleep一下让滚动条反应一下
time.sleep(0.05)# 获取当前滚动条距离顶部的距离
check_height = driver.execute_script("return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")# 如果两者相等说明到底了if check_height == temp_height:
time.sleep(1)break
temp_height = check_height
time.sleep(5)defclose(self):
self.driver.quit()defparse(self,driver,url):
driver.get(url)
time.sleep(10)# 网站是滚动加载的# 滚动页面1次,爬取20条数据
self.scroll_bottom(driver)
question_list = driver.find_elements_by_xpath('//div[@class="ListShortcut"]/div/div/div')for index, question inenumerate(question_list):try:# 使页面滚动条移动到指定元素element的位置处
driver.execute_script("arguments[0].scrollIntoView();", question)
driver.execute_script("window.scrollBy(0,500)")
time.sleep(0.1)
item = AnswerItem()
href = question.find_element_by_xpath('.//a').get_attribute('href')if'answer'in href:
question_name = question.find_element_by_xpath('.//a/span').text
excerpt = question.find_element_by_xpath('.//div[@class="RichContent-inner"]//span').text
item.href = href
item.question = question_name
item.excerpt = excerpt
print(item)if self.is_exist(item):continue# 保存到数据库
self.save(item.__dict__)except Exception as err:print(err)'''每次保存数据到mongodb
'''defsave(self,item):
item['create_time']= time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
item['update_time']= item['create_time']# 保存数据到mongodb
mongo.save(item)# 判断mongodb数据库中是否存在此链接defis_exist(self,item):return mongo.is_exist_href(item.href)defrun(self):
self.parse(self.driver,self.url)
self.close()defmain():
words =['python','java']for word in words:
url ='/search?q={}&type=content&time_interval=a_day'.format(word)
spider = Spider(url)
spider.run()if __name__ =="__main__":
main()
mongoConfig.py
from pymongo import MongoClient
collection ="test"defget_db():# 下面的配置记得改成自己的
user ='root'
password ='123456'
host ='0.0.0.0/carve'
port =27017
uri ="mongodb://%s:%s@%s"%(user,password,host)
client = MongoClient(host=uri,port=port)
db = client['carve']return db
defsave(obj):
get_db()[collection].insert_one(obj)defis_exist_href(href):
result = get_db()[collection].find({'href':href},{'href':1})for i in result:returnTruereturnFalse
部署爬虫
selenium的环境搭建
在centos7系统里安装谷歌浏览器及驱动
# 配置yum源cd /etc/yum.repos.d/
vim google-chrome.repo
# 写入以下内容[google-chrome]name=google-chrome
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearchenabled=1gpgcheck=1gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub
# 更新yumsudo yum update
# 安装Chrome无头浏览器
yum -yinstall google-chrome-stable --nogpgcheck# 查看安装Chrome版本
google-chrome --version# 安装谷歌驱动
https://registry.npmmirror.com/binary.html?path=chromedriver/
# 解压unzip chromedriver_linux64.zip
# 放到/usr/binmv chromedriver /usr/bin
运行爬虫
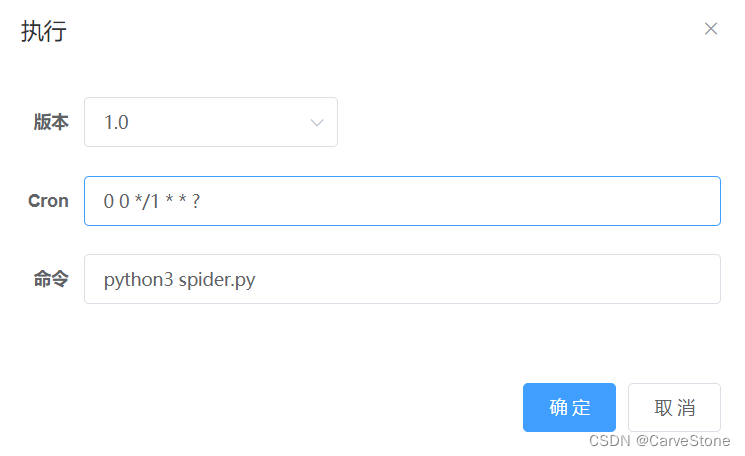
不想用爬虫管理系统的可以用定时任务命令执行爬虫代码
# 执行crontab命令crontab-e# 编写任务00 */1 * * ? python3 spider.py >> log.txt
本文转载自: https://blog.csdn.net/weixin_44018458/article/details/128567008
版权归原作者 CarveStone 所有, 如有侵权,请联系我们删除。
版权归原作者 CarveStone 所有, 如有侵权,请联系我们删除。