
Hive环境准备
1、shell脚本执行方式
方式1: sh 脚本 注意: 需要进入脚本所在目录,但脚本有没有执行权限不影响执行
方式2: ./脚本 注意: 需要进入脚本所在目录,且脚本必须有执行权限
方式3: /绝对路径/脚本 注意: 不需要进入脚本所在目录,但必须有执行权限
方式4: 脚本 注意: 需要配置环境变量(大白话就是把脚本所在路径共享,任意位置都能直接访问)
2、配置Hive环境变量
步骤:
注意:下面的步骤,全部在node1上面操作
- vim编辑/etc/profile文件
[root@node1 /]# vim /etc/profile
- 输入i进入编辑模式,在/etc/profile文件末尾添加如下内容
export HIVE_HOME=/export/server/apache-hive-3.1.2-bin export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin
vim小技巧:G快速定位到最后
- 保存退出,让配置生效
[root@node1 /]# source /etc/profile
- 最后建议关机拍摄下快照
3、启动和停止Hive服务
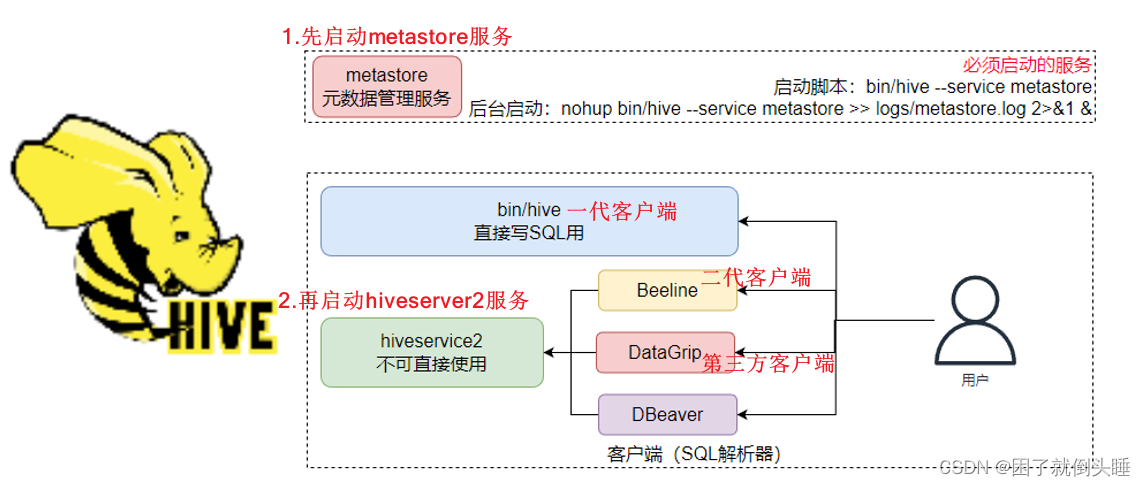
后台启动metastore服务: nohup hive --service metastore &
后台启动hiveserver2服务: nohup hive --service hiveserver2 &
解释:
1- nohup: 程序运行的时候,不输出日志到控制台
2- &: 让程序后台运行
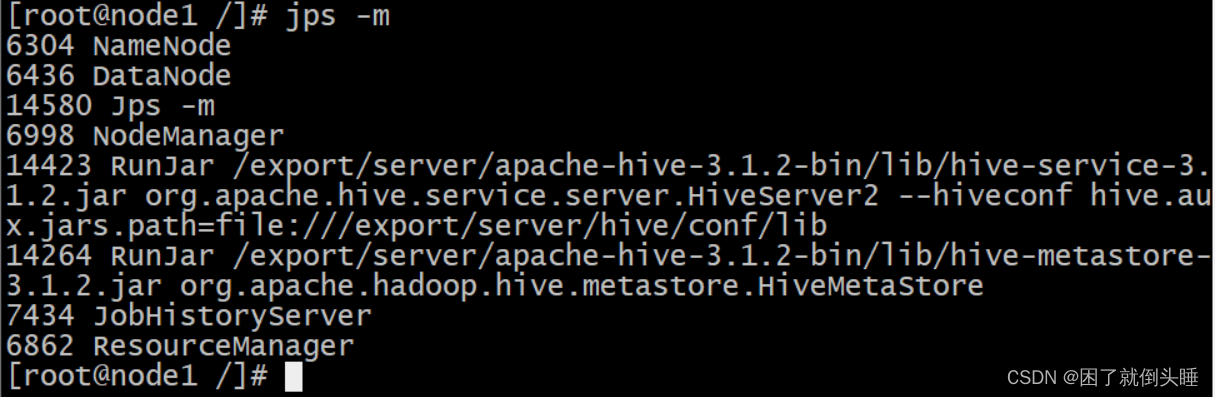
查看metastore和hiveserver2进程是否启动: jps -m
hiveserver2服务启动需要一定时间可以使用lsof查看: lsof -i:10000
注意: hiveserver2服务可能需要几十秒或者1分钟左右才能够成功启动
停止Hive服务: kill -9 进程ID
示例:
[root@node1 bin]# nohup hive --service metastore &
[1] 13490
nohup: 忽略输入并把输出追加到"nohup.out"
回车
[root@node1 bin]# nohup hive --service hiveserver2 &
[2] 13632
nohup: 忽略输入并把输出追加到"nohup.out"
回车
[root@node1 bin]# jps
...
13490 RunJar
13632 RunJar
[root@node1 bin]#
# 注意:10000端口号一般需要等待3分钟左右才会查询到
[root@node1 bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 14423 root 522u IPv6 225303 0t0 TCP *:ndmp (LISTEN)

4、连接Hive服务
一代客户端连接命令: hive
注意: hive直接连接成功,直接可以编写sql语句
二代客户端连接命令: beeline
二代客户端远程连接命令:
注意:
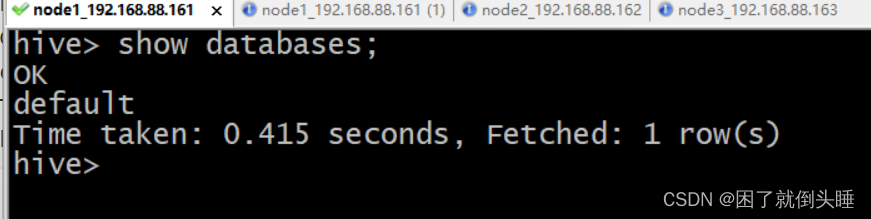
一代客户端示例:
[root@node1 /]# hive
...
hive> show databases;
OK
default
Time taken: 0.5 seconds, Fetched: 1 row(s)
hive> exit;
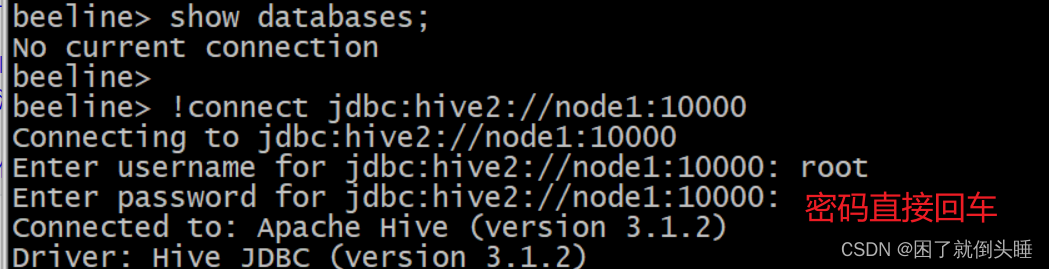
二代客户端示例:
[root@node1 /]# beeline
# 先输入!connect jdbc:hive2://node1:10000连接
beeline> !connect jdbc:hive2://node1:10000
# 再输入用户名root,密码不用输入直接回车即可
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
# 输入show databases;查看表
0: jdbc:hive2://node1:10000> show databases;
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (1.2 seconds)
5、DataGrip连接Hive服务
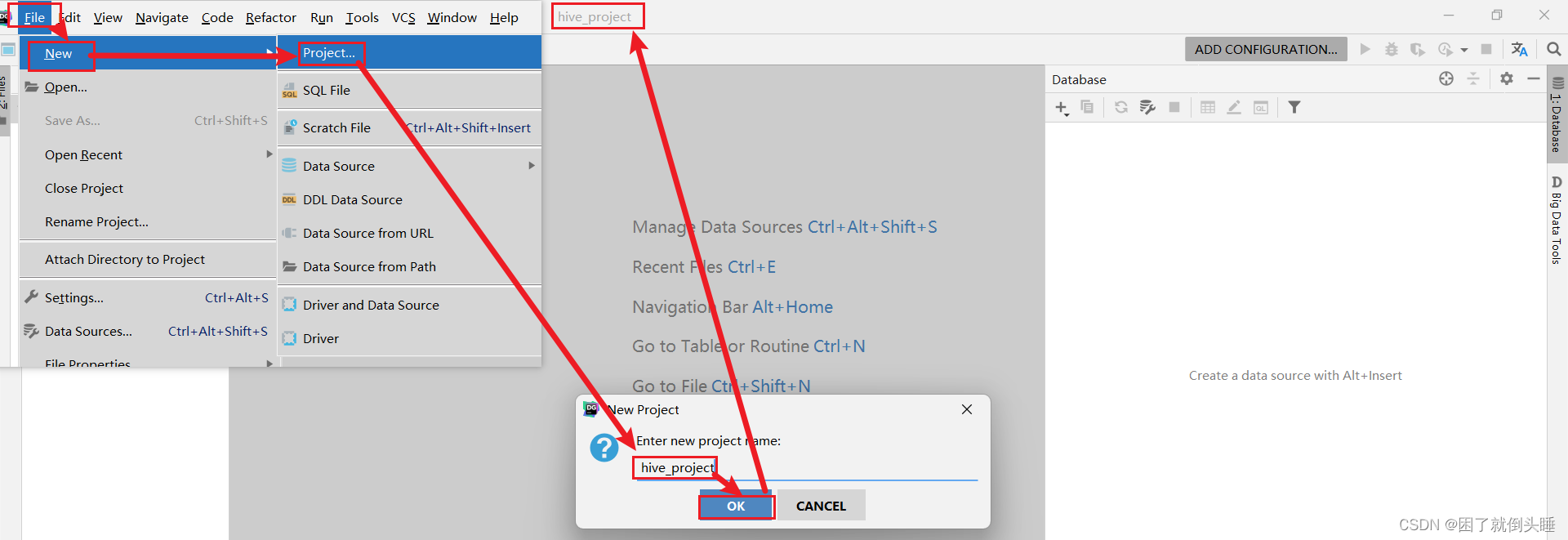
5.1 创建DataGrip项目
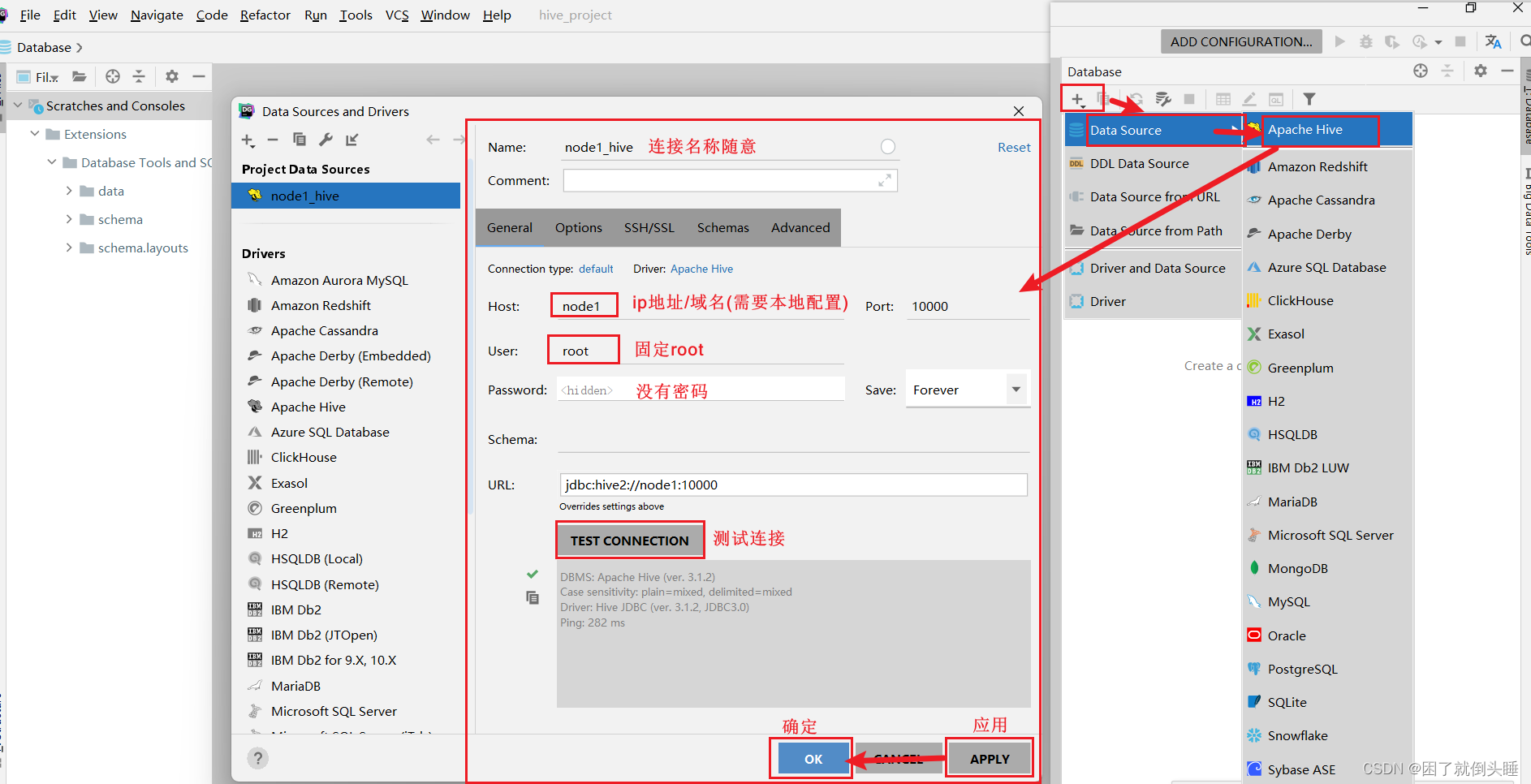
5.2 连接Hive
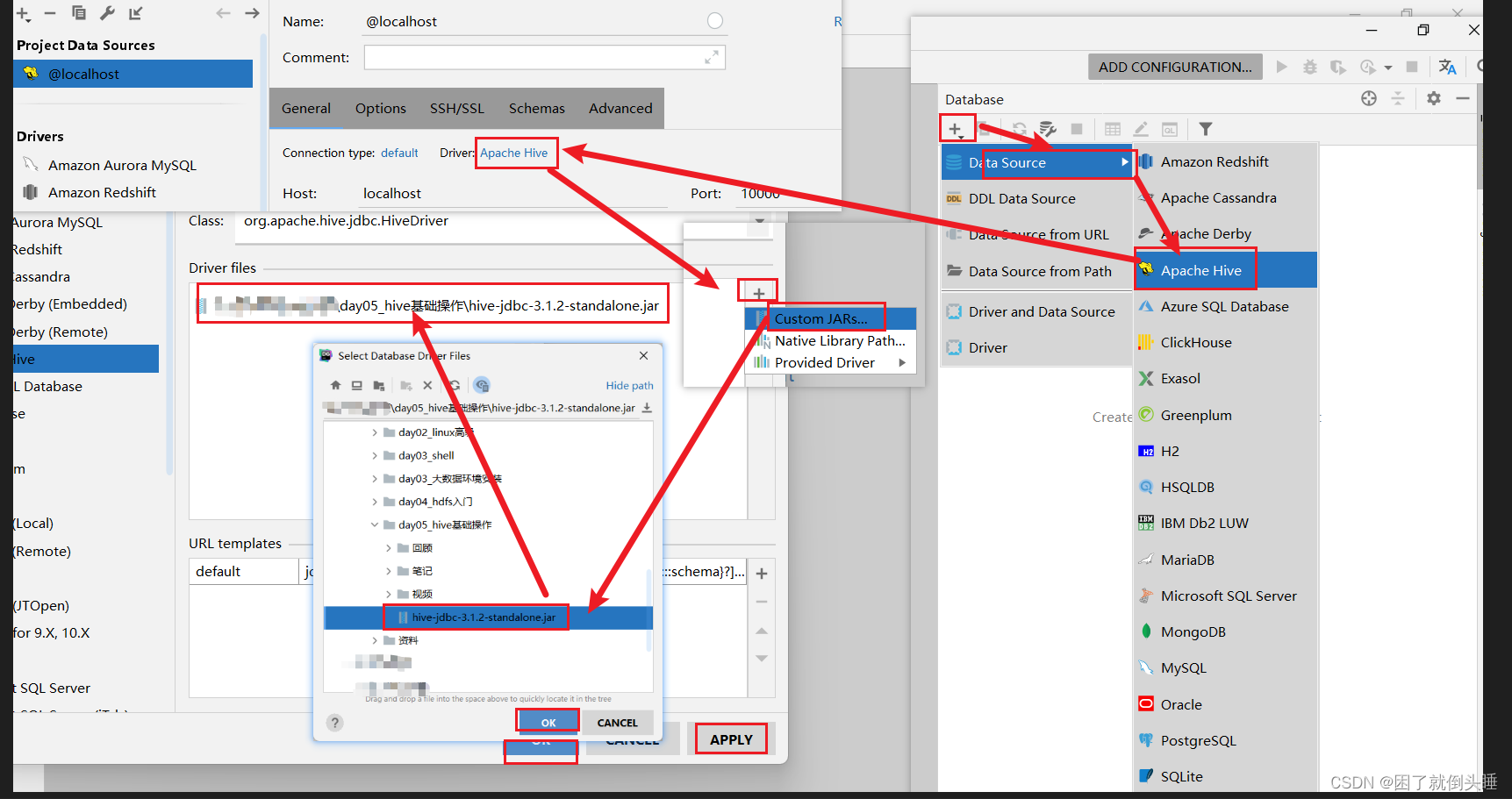
5.3 配置驱动jar包
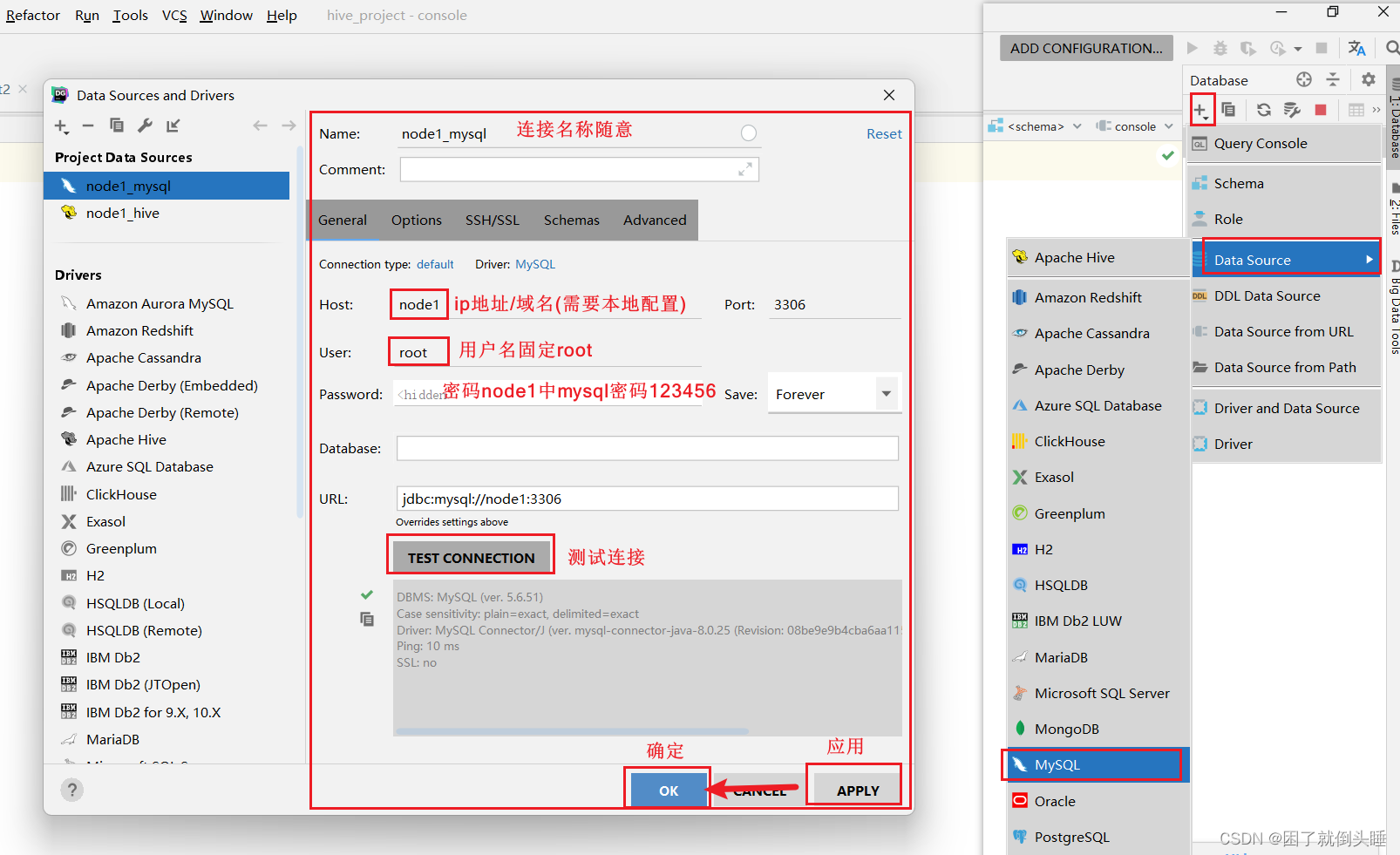
6、DataGrip连接MySQL
本文转载自: https://blog.csdn.net/weixin_65694308/article/details/139102796
版权归原作者 困了就倒头睡 所有, 如有侵权,请联系我们删除。
版权归原作者 困了就倒头睡 所有, 如有侵权,请联系我们删除。