
** 环境:centos7.6,腾讯云服务器**
Linux文章都放在了专栏:【Linux】欢迎支持订阅相关文章推荐:
【Linux】冯.诺依曼体系结构与操作系统
【C/进阶】如何对文件进行读写(含二进制)操作?
【Linux】基础IO_文件操作
【Linux】基础IO_文件描述符与重定向
前言
在前文我们所讲的都是已经打开的文件,而没有被打开的文件又存储在哪里呢?又是如何进行管理的呢?事实上,没有被打开的文件存储在磁盘,称之为磁盘文件。磁盘的存在不仅仅是为了存储文件,还有后续能对文件进行快速定位以及读取和写入。而对于磁盘文件的管理,则离不开文件系统,本次文章将对此进行探讨。
磁盘的物理结构
磁盘是什么?
磁盘是一种存储数据的存储器,早期主要计算机使用的磁盘是软磁盘(软盘),而如今则主要使用硬磁盘(硬盘)。而如今市面上的硬盘主要有机械硬盘以及固态硬盘。两者各有优缺点。
- 机械硬盘:容量大、价格便宜、但读取速度非常慢、个头还大(很多公司还在使用,因为成本低)
- 固态硬盘:读取速度快、个头小、但是价格贵,且存储空间有限(当前我们的大多数计算机都是固态硬盘)
 这里我们所讲解的是机械硬盘,顾名思义,机械硬盘是我们计算机上的唯一一个机械设备。
这里我们所讲解的是机械硬盘,顾名思义,机械硬盘是我们计算机上的唯一一个机械设备。
基本结构
机械硬盘的基本结构主要包含以下部分:
- 盘片:一片两面、每一面都可以存储数据、有一摞盘片
- 磁头:盘片每一面各有一个磁头,磁头负责盘面数据的读取
- 传动轴:用来控制磁头的进退
- 主轴:控制盘片的稳定旋转
- ......

存储结构
物理存储结构
机械硬盘的逻辑结构主要分为磁道、扇区和拄面。(部分内容来源于:硬盘结构(机械硬盘和固态硬盘)详解)

- 磁道:每个盘片都在逻辑上有很多的不同半径的同心圆,最外面的同心圆就是 0 磁道。我们将每个同心圆称作磁道(注意,磁道只是逻辑结构,在盘面上并没有真正的同心圆)。
- 扇区:在磁盘上每个同心圆是磁道,从圆心向外呈放射状地产生分割线(扇骨),将每个磁道等分为若干弧段,每个弧段就是一个扇区。每个扇区的大小是固定的,为 512Byte。扇区也是磁盘的最小存储单位。
- 柱面:不同盘片中的相同磁道形成的一个圆柱。
数据的写入与读取:
扇区作为磁盘中存储的基本单元,大小为512byte。(一个文件的数据在存储时可能占用多个扇区)。所以我们在进行数据的写入和读取时,只需要定位到具体的扇区即可。而定位一个扇区,首先要定位该扇区在哪一个盘面上(由磁头定位,每一个面都有一个磁头),接着通过同心圆的半径,确定扇区所在的磁道,最后再通过扇区的编号,确定该扇区的具体位置。这种通过磁头、磁道、扇区编号来定位扇区的放法,称之为CHS定位法。
而磁盘的存储介质为磁性材料,我们知道计算机内的数据都是大量的0和1,而磁头则会将0和1这种电信号转化为磁信号,也就说机械硬盘是通过磁头对南北极的更改,来实现数据的读取与写入。当我们通过CHS定位到具体扇区时:
- 向磁盘中写入数据:**N -> S **(0->1)
- **删除数据:S ->N **(1->0)
- 对数据的写入/删除 与读取的本质:更改基本元素的南北极,读取南北极。
逻辑抽象
如上所说,如果OS能知道任意的CHS地址,就能访问任意一个扇区,但是OS内部并不是直接使用CHS定位法。
这是因为OS是一个用来对软硬件资源做管理的软件,而CHS定位法是磁盘作为硬件来使用的方法。由于硬件可能会随着时代的发展而不断改变,如果此时OS采用CHS,那么OS也要不断随着硬件的更新而更新。耦合度太高,成本太大。因此为了实现与硬件的解耦,OS采用一种新的定位方法---LBA逻辑块地址。
如下图所示:将磁道从最外层铺开,就像扯胶带一样拉开,就会得到一串连续的线性的空间,我们把它想象成一个大数组,如下图所示:

此时计算机的常规访问方式,就变成了某一个数据块的起始地址+偏移量。此时也就完成了CHS到BA的转换。因此,OS对于磁盘的管理,实际上就转化为了对这个大数组的管理。
当然,OS进行IO的基本单位是可以进行调整的,一般都是4KB,即一个数据块的大小,这也是为什么磁盘会被称之为块设备的原因之一。这样也是为了提高IO效率,根据内存对齐原则。
文件系统
分治管理

Windows下的分盘
我们目前所使用的计算机,实际上只有一个盘,那么为什么我们还要将它分成C盘、D盘呢?答案是为了让我们能更好的管理这些资源。同样,Linux操作系统为了更好的管理整个磁盘空间,也会对磁盘进行分区,对OS来说,管理好一个分区,就能管理好所有的分区(每一个分区的管理方法都一样),而为了更好的管理一个分区,又会在该区内进行分组管理,再次细分为一个一个块组。同样,管理好一个块组,即可管理好整个块组,进而管理好整个分区,实现对整个文件系统的管理。

这种管理策略,有点类似于我们国内为了管理好整个国家,设置了各个省,而为了管理好一个省,又设置了各个市。只不过计算机的这种管理方式要更加简单些,因为管理的策略都一样,不像国内各个省市的管理要考虑当地具体情况。
块组内的信息
如上所说,OS只需要管理好一个块组,就能管理好所有的块组,进而管理好一个分区,再进而管理好整个文件系统。那么,一个块组内,都包含些什么呢?如下所示:

上面提到了一个inode节点,我们知道,Linux下一切皆文件,文件=内容+属性,Linux是将文件的内容与属性的数据分离开来,一个inode节点内,保存文件的各种属性信息,比如:文件的读写权限、拥有者、文件大小、对应的inode编号等。而文件的内容数据,则保存在date blocks中对应的一个或多个数据块中。
这里需要注意的是:
- 在文件的inode中,不包含文件名
- 目录也是文件,也有自己的inode编号,其中目录的数据块中存放的则是该目录下的文件名与对应的inode编号的映射关系。两者互为Key值。
- inode编号只在该分组所在的分区内有效。通过inode编号,就可以先确定所在分区,再确定所在分组。
- 一个文件对应一个inode编号。任何文件,都在处于一个目录内。所以可以先通过inode Table找到目录的inode编号,找到inode编号,就找到了inode节点,节点内记载着各种属性,进而找到Block Bitmap的使用情况,根据Block Bitmap再来确定目录所使用的数据块,目录的数据块内包含目录下的文件名与文件的inode编号的映射关系,从而找到目录下的某一个具体文件。
我们通过指令ls -l -i来查看文件的inode编号。

磁盘文件的创建与删除
文件创建
- 对于文件的创建,首先会找到一个空闲的inode节点,将文件属性记录在该节点内,同时将该inode节点对应的inode Bitmap的比特位由0置1
- 寻找空闲的数据块,用来存储文件的相关内容,并将数据块的相关信息填入inode节点中,同时将对应的BlockBitmap由0置1
- 将该文件名添加到当前目录文件的Dateblock中,并将该文件名与对应的inode编号连接起来。
文件删除
- 文件的删除,其实只需要对位图信息进行修改即可
- 首先根据文件所在的目录。目录中的dateBlock记载着该目录下的文件名与inode编号的映射关系,根据映射关系,找到该文件对应的inode
- 根据inode,将对应的BlockBitmap由1置0(删除内容)
- 再根据inode,将对应的inodeBitmap由1置0。(删除属性)
也就是说,假如我们的文件被误删除的话,是有一定希望可以进行恢复,只需要将该文件的inode编号对应的位图信息由0恢复成1即可。当然,这种恢复技术还是由专业人员来进行操作,我们只要保证删除文件的inode编号不被其它文件使用即可。
对于其它的一些补充
补充一、
我们知道,在文件的inode节点中,记载了数据块的相关使用信息,可能是用一个数组来记载,但是此时可能会面临一个问题,就是假如一个文件使用了15个数据块,而一个数据块的大小为4kb,也是不是意味着该文件最多能放入15*4=60kb的内容?
答案是否定的,因为数据块里面有的可能并不是放着文件的内容,而是存放着该文件使用的其它数据块的索引。(有点类似套娃)如下所示:
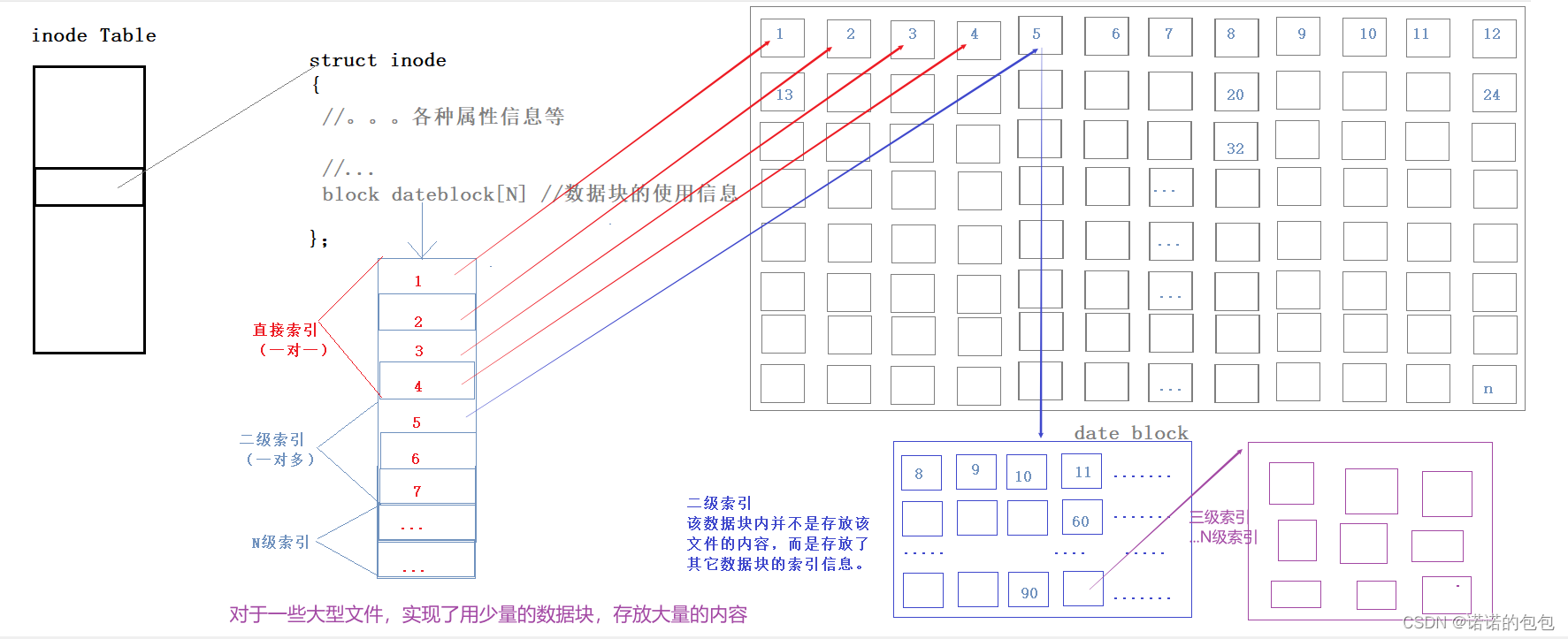
如上所示,一个数据块内,可能存在多级的索引关系,从而实现对大量数据的存储。
补充二、
如上所说,文件的内容采用数据块存储,而一个数据块的大小为4kb,那么就可能会出现文件系统中存在大量的,内容非常少导致实际使用的空间很小(可能才几个字节,甚至更小),此时就会出现大量的空间浪费。
实际上假如出现这种情况,确实会出现空间浪费的情况。但是为什么我们不选择将数据块大小设置为1kb呢?实际上这样做虽然可以处理,但是对于大型文件,就会占用更多的数据块,inode也要记录更多的所使用的数据块情况。此时就可能造成文件系统读写性能不佳,定义成4kb的原因最主要还是由于普适性。并且如今的磁盘空间容量都比较大,所以一般都是采用4kb的大小来定义一个数据块。
end.
生活原本沉闷,但跑起来就会有风!🌹
版权归原作者 诺诺的包包 所有, 如有侵权,请联系我们删除。