
Flink 常见问题汇总
0 如何分析日志
0.1作业内部重启异常, 作业正常运行
- 在 Flink UI 的 Exceptions 页面,直接查看 Root Exception
 2. 查看 Flink 的 jobManager 的日志,查看失败的原因 搜索关键字:RUNNING to FAILED 这段关键日志下面就是导致作业失败或者重启的原因(由于 commit 时出现了 io exception 导致)
2. 查看 Flink 的 jobManager 的日志,查看失败的原因 搜索关键字:RUNNING to FAILED 这段关键日志下面就是导致作业失败或者重启的原因(由于 commit 时出现了 io exception 导致)
0.2 作业内部重启, 但作业已经手动 kill 整个 yarn-application
当作业发生了重启,但已经手动操作 kill,这样的情况下,Flink 无法将作业的运行信息写入到 HDFS,则无法通过 HistoryServer 查看。
- 进入 Yarn 的 AppMaster 界面
- 点击查看 jobManager 所在 container 的日志(如下所示,点击 here 展开全量的日志)

tips:
当并发较多时,jobManager 会产生较多的日志文件,此时在浏览器查看会比较卡,可以有两种方式进行查看。
- 可以通过 wget 将整个网页直接下载下来,如下所示,去掉 “&start.time=0&end.time=9223372036854775”,结尾为 start=0
wget “http:///container_e36_1638340655551_0550_01_000001/container_e36_1638340655551_0550_01_000001/h_data_platform/jobmanager.log/?start=0”
- 修改日志 URL 的后缀,然后访问,可以只查看末尾的日志,方便快速查看。
“http:///jobhistory/logs/.bj:22700/container_e36_1638340655551_0550_01_000001/container_e36_1638340655551_0550_01_000001/h_data_platform/jobmanager.log/?start=-1024000”
0.3 作业失败,整个 yarn application 结束运行
- 进入 Yarn 的 AppMaster 界面, 点击 Tracking URL
 2. 通过 HistoryServer 查看 Root Exception HistoryServer 进入可能比较慢, 遇到这种情况可以直接参考上面的日志查看方式。
2. 通过 HistoryServer 查看 Root Exception HistoryServer 进入可能比较慢, 遇到这种情况可以直接参考上面的日志查看方式。
1 Flink 作业积压排查流程及解决思路
1 反压原因
积压产生的原因可能多种多样, 排查作业积压出现的原因,可以参考下面的步骤.
反压其实就是 task 处理不过来,算子的 sub-task 需要处理的数据量 > 能够处理的数据量,比如:
当前某个 sub-task 只能处理 1w qps 的数据,但实际上到来 2w qps 的数据,但是实际只能处理 1w 条,从而反压
常见原因有:
- 数据倾斜:数据分布不均,个别task 处理数据过多
- 算子性能问题:可能某个节点逻辑很复杂,比如sink节点很慢,lookup join 热查询慢
- 流量陡增,比如大促时流量激增,或者使用了数据炸开的函数
2 反压的危害
- 任务处理性能出现瓶颈:以消费 Kafka 为例,大概率会出现消费 Kafka Lag
- Checkpoint 时间长或者失败:因为某些反压会导致 barrier 需要花很长时间才能对齐,任务稳定性差
- 整个任务完全卡住。比如在 TUMBLE 窗口算子的任务中,反压后可能会导致下游算子的 input pool 和上游算子的 output pool 满了,这时候如果下游窗口的 watermark 一直对不齐,窗口触发不了计算的话,下游算子就永远无法触发窗口计算了,整个任务卡住
3. 定位反压节点
查看WebUI
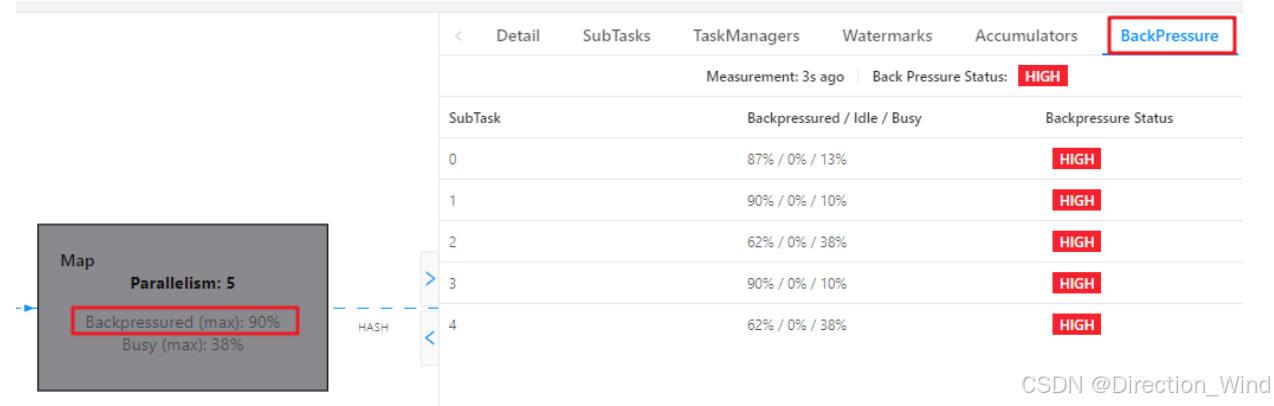
作业图的 UI 展示,会通过不同颜色和数值代表繁忙和反压的程度 ,红色表示busy,灰色表示积压,一般是红色的算子处理能力不足。
作业图的 UI 展示,会通过不同颜色和数值代表繁忙和反压的程度 可以通过BackPressure查看 subtask 反压情况
还可以查看Flink 任务的 Metrics
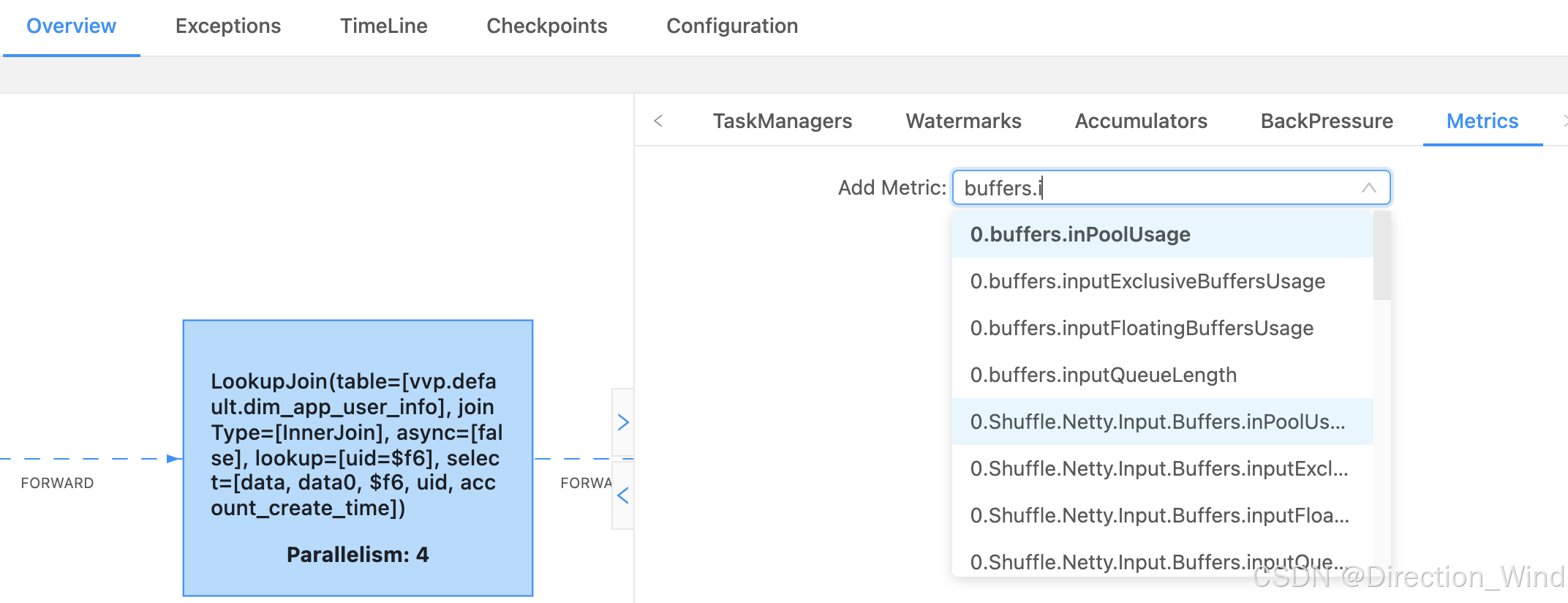
我这个是并行度是 4 ,所以会有 0、1、2、3 代表是哪个 subTask(task 下每个并行task),其中看到的比较多的是这两个,outPutUsage 代表发送端 Buffer 的使用率,inPutusage 代表的接收端 Buffer 的使用率

4. 排查反压原因
我们生产环境中,会遇到负载高峰、CheckPoint、作业重启引起的数据积压而导致反压,这种情况反压如果是暂时的,我们可以忽略它
除了定位反压节点,还需要排查原因
4.1 数据倾斜
我们可以用 Web UI 查看该节点每个 SubTask 的 Record Send 和 Record Received 来看是否数据倾斜,也可以通过 Checkpoint 每个 Subtask 的 state 的 size 大小
4.2 火焰图
在代码提交时设置开启火焰图,然后可以在 Web UI 里面查看,
rest.flamegraph.enabled: true #默认 false
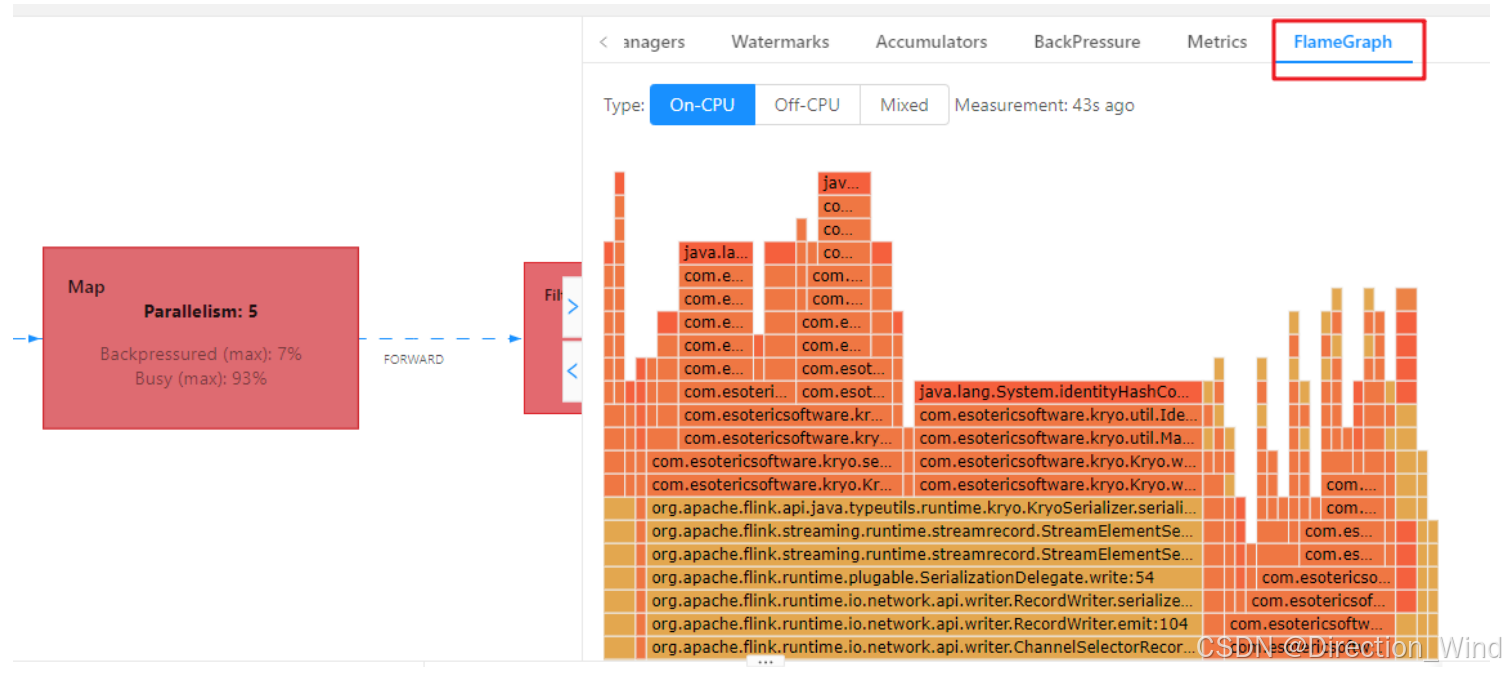
纵向是调用链,从下往上,顶部就是正在执行的函数
不是用颜色代表的,而是横向长度,代表出现次数或者说执行时长,某个函数过宽,出现了平顶,那这个函数可能有性能问题
4.3 分析 GC
也可能是 TaskManager 的内存引起的 GC 问题,也会导致反压,我们一般使用 G1 回收机制,有可能是 TaskManager JVM 各区内存分配不合理导致频繁的 Full GC
我们可以提交任务时设置打印 GC 日志然后查看Web UI GC 情况或者直接看日志
-Denv.java.opts=“-XX:+PrintGCDetails -XX:+PrintGCDateStamps”

4.4 在 Metric 页面,查看 Source 的流入量,可以直观体现作业的处理速度
- 如果处理速度下降,则说明出现性能瓶颈,或其他原因导致速度下降
- 如果处理速度不变或是有上涨,说明上游的数据在持续增长

5. 常见处理方案
5.1 常见原因:
- 是否紧急: 线上作业/测试作业
- 上游是否有增长: 有增长/无增长
- 作业 GC 情况: GC 正常/GC非常频繁/GC一般频繁(类似: 15min GC 5min)
- 是否数据倾斜: 无倾斜/有倾斜/有倾斜但不是核心原因,重点关注空值与空字符串关联
- 作业的反压task和慢 task: 反压task名+满task名/无明显反压或者慢 task
- 慢 Task 对应的执行栈: 有明显的慢的线程栈/无明显的线程栈
- 是否有异常日志: 有异常日志(贴身对应的日志和日志链接)/无异常日志
5.2 常见解决策略
- 很多时候反压就是资源不足导致的,给任务加资源
- 如果是数据倾斜、算子性能问题之类,那就去解决这些问题
- 如果确实是流量过大消费不过来,就调大并行度(如果是kafka,需要同时调大kafka分区数)
- 限制数据源的消费数据速度。比如在事件时间窗口的应用中,可以自己设置在数据源处加一些限流措施,让每个数据源都能够够匀速消费数据,避免出现有的 Source 快,有的 Source 慢,导致窗口 input pool 打满,watermark 对不齐导致任务卡住
- 关闭 Checkpoint。关闭 Checkpoint 可以将 barrier 对齐这一步省略掉,促使任务能够快速回溯数据。然后等数据回溯完成之后,再将 Checkpoint 打开,或开启非对其ck:set execution.checkpointing.unaligned=true;
- 拆分算子链接
SET pipeline.operator-chaining=false;
- 开启mini-batch:
set table.exec.mini-batch.enabled=true;
set table.exec.mini-batch.allow-latency=1000;
set table.exec.mini-batch.size=200;
- 设置合理的ttl和ck设置:
–state ttl机制
set state.retention.time.min=3d;
set state.retention.time.max=4d;
set execution.checkpointing.mode=exactly_once;
set execution.checkpointing.interval=6min;
– 超时时间
set execution.checkpointing.timeout=80min;
set execution.checkpointing.min-pause=0ms;
10.set table.exec.source.cdc-events-duplicate=true;
2 Flink checkpoint失败排查流程
排查作业 checkpoint 失败的原因,可以参考下面的步骤.
- 找到第一次失败的 checkpoint

- 找到未能完成 checkpoint 的 task 以及对应的 subtask 找到未能 100% 完成 checkpoint 的 task
 展开找到未完成的 subtask
展开找到未完成的 subtask 
- 找到对应 task 所在的 TaskManager 在 FlinkUI找到对应的 subtask 所在的 TaskManager
 点 View TaskManager Log 即可跳转至对应的 TaskManager
点 View TaskManager Log 即可跳转至对应的 TaskManager
- 结合执行栈找到相应的卡点
 具体的解决方案与常见原因,可以参考本人的另一篇帖子: 《Flink checkpoint操作流程详解与报错调试方法汇总,增量checkpoint原理及版本更新变化,作业恢复和扩缩容原理与优化》
具体的解决方案与常见原因,可以参考本人的另一篇帖子: 《Flink checkpoint操作流程详解与报错调试方法汇总,增量checkpoint原理及版本更新变化,作业恢复和扩缩容原理与优化》
2. 如何查看各个taskmanager的checkpoint的执行情况?
- 查看JobManger日志,有以下日志代表开始执行checkpoint:
2020-09-1118:56:25.275 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint1 @ 1599821785269for job e1d818d210f40700760e893cdef96f11.
- 查看TaskManager日志,有以下日志代表接收到barrier,开始执行checkpoint
2020-09-1118:56:25.280 INFO org.apache.flink.streaming.runtime.tasks.StreamTask -Startingcheckpoint(1)CHECKPOINTon task Source: Custom Source -> Flat Map (1/2)2020-09-1118:56:25.295 INFO org.apache.flink.streaming.runtime.tasks.StreamTask -Startingcheckpoint(1)CHECKPOINTon task Keyed Aggregation -> Sink: Printto Std.Out(2/2)
- 查看TaskManager日志,有以下日志代表开始执行checkpoint同步阶段,根据statebackend不同,日志稍有不同
2020-09-1118:56:25.303 INFO org.apache.flink.runtime.state.AbstractSnapshotStrategy - DefaultOperatorStateBackend snapshot(In-Memory Stream Factory, asynchronous part)in thread Thread[AsyncOperations-thread-1,5,Flink Task Threads] took 12 ms.// 关键日志2020-09-1118:56:25.571 INFO org.apache.flink.runtime.state.AbstractSnapshotStrategy - Heap backend snapshot(In-Memory Stream Factory, asynchronous part)in thread Thread[AsyncOperations-thread-1,5,Flink Task Threads] took 271 ms.
- 查看JobManager日志,有以下日志代表checkpoint完成
2020-09-1118:56:25.604 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint1for job e1d818d210f40700760e893cdef96f11 (866067 bytes in334 ms).
3. 没有触发 Checkpoint
Flink 的 JobManager 负责 checkpoint 相关工作,因此当出现涉及 Checkpoint 的相关问题时,首先检查 JobManager 的日志,查看相关异常日志。
4. Checkpoint 超时
- 动态调整:作业出现因追数据或流量峰值造成连续 checkpoint 超时,使得长时间无法将数据追平时,可以考虑暂时调长作业 checkpoint 的超时时间,设置方式为:/config/set/{key}/{value} 如示例将某作业超时设置为1小时
- 配置框架参数:execution.checkpointing.timeout=20min
5. 如何设置statebackend
直接在框架参数里面配置:
state.backend=rocksdb(or filesystem)
6. 感觉StateBackend读写访问慢,想要开启监控查看原因
state.backend.latency-track.keyed-state-enabled=true
state.backend.rocksdb.native-metrics-enabled=true
上述第一个配置开启的是KeyedState的延迟监控,属于采样值,监控的是所有KeyedState的访问延迟,不区分StateBackend,默认单位是us(微秒)。第二个配置能开启所有的RocksDB的native监控,只有使用RocksDBStateBackend时才会生效。
3 Flink 窗口计算问题排查
在使用窗口计算时,常常会遇到窗口未触发,计算不准确,以下是一些常见的排查手段以及修复方式.
- 检查 watermark 是否正常
- 未显示正常的 watermark - 检查上游的各个 subtask 是否都能正常产生 watermark- 如果部分subtask 无数据 - Jar 包作业 - 给source 指定的并发小于或等于 talos 的 partition 数- 设置 source idle 的超时 https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/datastream/event-time/generating_watermarks/#%E5%A4%84%E7%90%86%E7%A9%BA%E9%97%B2%E6%95%B0%E6%8D%AE%E6%BA%90- SQL 作业: - 设置 table.exec.source.idle-timeout 参数 https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/config/#table-exec-source-idle-timeout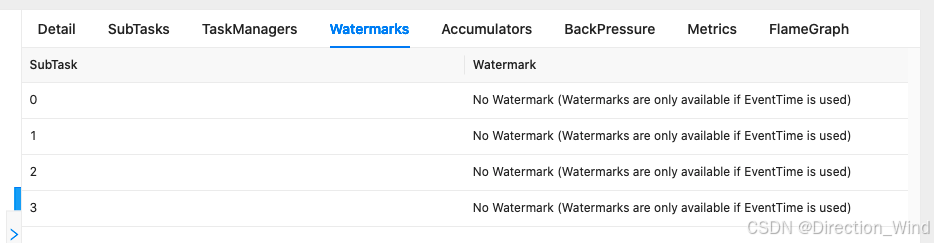
- Watermark 数值不符合预期 - 检查 watermark 对应的生成逻辑是否正常- 是否存在时区问题,导致数值偏移.- 是否存在脏数据,导致watermark数值拉高,造成 Drop 较多数据.
- 检查是否有较多晚到数据被 Drop 掉
- 在 grafana中搜索 Drop 的数据指标. 如果存在较多的 Drop 的数据,则需要考虑 watermark 设置是否合理,以及这份数据是否适合用于时间窗口计算场景.
![[图片]](https://i-blog.csdnimg.cn/direct/61df37118e444315b5f9c856fb19f825.png)
4 flink内存问题
4.1 1. 堆内内存溢出 Heap OutOfMemory
该异常说明 JVM 的堆空间过小。 可以通过增大总内存、TaskManager 的任务堆内存、JobManager 的 JVM 堆内存等方法来增大 JVM 堆空间。
4.2 Container 内存超用 killed by YARN for exceeding physical memory limits
异常日志:
原因:
Container 内存超用
解决方案:
可以调大 taskmanager.memory.jvm-overhead.fraction=0.2(堆外内存使用过多,堆内有富余的情况下可调整;如果堆内内存也使用较多,需要对 Taskmanager 内存进行扩容)
4.3 DirectMemory 内存溢出 DirectMemory OutOfMemory
该异常通常说明 JVM 的直接内存限制过小,或者存在直接内存泄漏(Direct Memory Leak)。 请确认用户代码及外部依赖中是否使用了 JVM 直接内存,以及如果使用了直接内存,是否配置了足够的内存空间。 可以通过调整堆外内存来增大直接内存限制。
Flink 中的 DirectMemory 包含框架对外内存、任务堆外内存、网络内存三部分,一般是由于任务堆外内存导致该异常,可以稍微调大 taskmanager.memory.task.off-heap.size = 256mb。
5 调优
资源的设置与调优
为任务分配合理的资源是Flink调优的第一步。在一定范围内,为作业增加资源(这里的资源主要指作业的并行度、内存、CPU等资源)几乎总是能提升作业的性能,因此只有在实现了作业的最优资源配置后,再去考虑进行下面的性能调优,才能达到事半功倍的效果。
5.1 内存设置
JobManager的内存设置
一般来说,JobManager主要用于资源的申请和作业的调度,因此其内存消耗没有TaskManager大,一般的建议设置是 2~4G ,如果作业的并行度比较大或是有用到大状态的Operator State,可以考虑适当往上进行调整。
TaskManager的内存设置
TaskManager承担着作业的执行功能,并在其内存中保存着作业的状态,其内存消耗比JobManager要大,如果该值过小,可能会导致作业运行内存不足,频繁触发Full GC,增加作业出现Heartbeat timeout的概率,一般情况下建议设置其内存大小为 2~8G .
内存设置调优
以上对内存设置大小的建议值是一个范围值,由于各个作业逻辑不尽相同,有的作业是CPU密集型任务,有的作业是I/O密集型任务,因此它们的内存大小的最优值肯定是不同的,那么如何确定最适合自己作业内存的值呢?
我们可以按以下方法进行一个推断,从而大致计算出最适合自己作业的内存大小。首先,在内存大小的推荐范围内为作业选择建议值,然后将作业提交运行,运行的过程中,会产生GC日志(GC日志与作业运行日志在同一目录下,可通过查看Flink日志找到),将作业的GC日志拷贝到 GC日志分析工具进行分析,重点是看Full GC后老年代空间的剩余大小,假设该值大小是P,则堆内存大小的建议值是34倍P,Flink堆内存默认分成两个部分:Framework Heap和Task Heap,前者默认是128M,后者的值会根据Flink TaskManager的总内存去除堆外内存和overhead预留后计算得出,Flink UI的Metrics页可以非常方便的看到作业当前各区域内存的大小,调整TaskManager的总内存大小,确保堆内存大小为作业Full GC后老年代空间剩余大小的34倍即可。
5.2 CPU设置
目前,CPU默认是1核,也就是不存在并行问题,除非任务对CPU的需要确实很高,否则一般建议不要修改CPU的默认设置。
并行度设置
在作业开发完成后,最好对其进行压测,压测的方法其实很简单,如果是消费Talos的数据,可以先暂停消费一段时间攒一批数据或是在作业尚未消费过数据时设置作业从头开始消费,如果是已经消费过的数据可以删除Checkpoint后设置从最早进行消费。将作业的并行度设置为一个比较小的值,比如10以下,然后测试单个并行度的处理极限值。
再根据公式:并行度 = 总QPS / 单并行度处理能力极限值
当然,由于这样算出来的并行度可能会不太准确。比如,如果作业的逻辑比较简单,不涉及到网络传输,那么其QPS的增加与并行度的增加是线性的;而有些作业逻辑复杂,涉及到网络数据交换等,那么其并行度就不能如此简单的按线性比值进行计算。
建议是根据高峰期的QPS进行压测,并最好预留一定的资源,如并行度*1.2~1.3倍。
5.3 Source端并行度的配置
如果数据源端是Kafka,那么最好设置Source的并行度为消费的对应Topic的分区数,不宜大于,大于会有空闲source task休息,如果在运行过程中发现如此比较浪费,也可以设置为Topic的分区数的可被整除数,确保每个Source的SubTasks分配到的Topic分区数都是相同的,不会出现数据倾斜和负载不均衡现象。如果在运行的过程中发现依然存在积压,且后续处理算子都不是瓶颈,最好的处理方式是增加Source端并行度的同时增加Topic的分区数,并始终保持它俩相等。由于Flink Source的一个并行度可以处理一个或多个Topic分区的数据,因此如果Source端并行度超过Topic的分区数,将会有Source SubTask空闲,没有做到资源的最大化利用。
5.4 Transform算子并行度设置
它的设置可以分成两种情况,一种是keyby之前的算子,一般是做一些数据的filter过滤、map转换或是flatmap打平等操作,逻辑不会特别复杂,处理起来也会比较快,其并行度可以设置得与Source端并行度一致,以减少数据的网络传输损耗;另一种是keyby之后得算子,建议设置为2的整数次幂,之所以这样设置与Flink对Key的分配原理有关,当然如果没有keyby就无须遵循这个原则。如果作业在运行的过程中,网络传输消耗是其性能瓶颈,将所有算子chain在一起将会显著提升其性能。
5.5 Sink端并行度设置
Sink端的并行度设置需要根据数据量和下游服务的写入能力进行综合评估,避免对下游造成太大的压力,甚至是将下游服务打挂,这个时候就需要对并行度的设置做一个权衡。如果是Kafka的话,可以设置为其写入Topic的分区数大小。
如果数据从Source获取到后,进行了数据的打平和细粒度的拆分,导致数据量不断增加,那么Sink端的数据量就会非常之大,此时就需要加大Sink端的并行度;否则,如果在中间处理的过程中根据规则过滤掉了大量的无用数据,就可以适当减小Sink端的并行度。
5.6框架参数设置与调优
State和StateBackend调优
一定要为State设置TTL
在Flink实时计算的过程中,可能会遇到状态数据不断累计,导致状态量越来越大的情况,如定义了超长的时间窗口、在动态表上应用了无限范围的group by、双流join没有时间限制等,对于这些情况就非常容易出现OOM的情况,或者是堆外内存持续增长最终导致超用引发作业频繁崩溃重启,因此为状态设置TTL非常必要。
如果是jar包模式,那么State TTL需要与具体的状态绑定,并不是全局生效的,具体的设置方式可以参考以下例子:
StateTtlConfig ttlConfig =StateTtlConfig.newBuilder(Time.seconds(5*60)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();ValueStateDescriptor<String> stateDescriptor =newValueStateDescriptor<>("StateTtl",String.class);
stateDescriptor.enableTimeToLive(ttlConfig)
上例为名为StateTtl的ValueState设置了5分钟的生命周期,每次创建或写入都会修改其更新时间戳,已过期但尚未清理的State永远不会返回给调用方。
对于SQL作业,无法使用上述的方式,可以在SQL配置中添加以下配置:
set state
不要在大状态时使用Operator State
Operator状态的结构是一个List,由于没有KeyGroup,所以需要对其序列化结果的每个元素存储一个位置偏移,并作为元数据保存到JobManager中,大状态容易造成JobManager的OOM。此外,它在做checkpoint时采用的是深拷贝模式,此时其占用空间会出现翻倍的情况,因此在使用其进行大状态存储时也容易造成TaskManager的OOM。一般仅使用OperatorState存储Talos的消费offset等小规模状态,建议不要对未进行keyby的Operator存储大状态。
StateBackend的选择和调优
Flink支持有状态的处理和Exactly Once语义,如果对于状态后端的选择有疑惑或是在读写状态时发现有性能瓶颈,可以参考这篇文章:Flink StateBackend介绍及调优
注意:从Flink 1.14开始,Flink支持通过Savepoint来切换StateBackend,如果目前使用的StateBackend无法满足使用场景,可以通过StopWithSavepoint进行停止,然后修改state.backend并再次重启即可。
在这里要补充一点,RocksDB采用类似于HBase的LSM树的形式实现,因此其写入性能是强于读取性能的,又由于其读取和写入时需要有序列化和反序列化的开销,因此通过上面介绍的优化参数,一般可以将单并行度的吞吐量(TPS)优化到5000~10000条/s,如果处理性能依然不足,由于每个并行度上的RocksDB都是其一个单独的实例,因此横向扩展其并行度就能提升其性能。
State读写性能瓶颈问题的确定
通过开启RocksDB State访问延迟监控,可以采样监控rocksdb的访问延迟:
state.backend.rocksdb.latency-track-enabled=true
并能通过 falcon监控 查看访问延迟,如果存在延迟升高或较高的情况,可以依照上述StateBackend的调优进行优化。
5.7 Checkpoint的调优
Checkpoint设置
一般建议Checkpoint的周期,也就是两次Checkpoint的时间间隔需要在分钟级别,对于小状态可以设置为35分钟,对于状态比较大的作业由于每次访问HDFS比较耗时,设置为510分钟比较好,此外,还需要调大两次Checkpoint之间的暂停间隔,至少设置为3~8分钟。
如果需要保证数据不丢不重,需要设置Checkpoint语义为EXACTLY_ONCE,此时在多个并发度作业中会存在Checkpoint barrier的对齐耗时,可以通过Flink UI的Checkpoint Tab页查看各阶段的耗时,并依此进行针对性的解决。
Checkpoint小文件调优
Flink可以开启增量Checkpoint来减少每次Checkpoint需要上传的文件大小和数量,但也非常容易因此产生小文件问题。小文件问题不仅会对HDFS NameNode造成比较大的访问压力,也会快速消耗HDFS的quota,可以使用以下框架参数配置开启小文件合并:state.backend.checkpoint.stream-concat-enabled=true
如果效果依然有限,小文件仍然很多,可以先停止任务,然后添加以下框架参数,强制做一次全量的checkpoint,后续根据全量的checkpoint的性能决定是否切换回增量checkpoint,切换的方式很简单,将false改成true即可:
state.backend.incremental=false
任务重启时会自动的将未用到的checkpoint清理,因此也能减少checkpoint文件的数量。
另外,在保证作业的处理性能足够的前提下,减少作业的并发度也能减小每个作业生成的小文件数量。
Checkpoint超时和失败优化
Checkpoint非常容易因为背压、数据倾斜、磁盘瓶颈和故障、瞬时流量高峰造成超时或失败,此时,可以开启DEBUG日志来查看是哪个task的哪个阶段导致的异常和失败:
flink.log.level=debug
对于背压等造成的Checkpoint Expire,可以参看这篇文章(Flink 积压问题分析),也可以考虑开启开启Unaligned Checkpoint:
execution.checkpointing.unaligned=true
execution.checkpointing.aligned-checkpoint-timeout=30s
第二个参数的意思是,作业会首先使用Aligned Checkpoint,只有当作业开始全局Checkpoint的时间和作业在某个subtask的Checkpoint的时间之差超过该timeout时,才会转换为使用Unaligned Checkpoint继续处理。
如果只是短时间的流量高峰导致的Checkpoint超时,那么可以通过动态调整
从1.14开始,Flink引入了缓冲区Debloating来自动采样和控制Flink算子/子任务之间缓冲的 In-flight 数据的数据量,从而缩短 Checkpoint 的时间,且该功能对Aligned Checkpoint和Unalign Checkpoint都生效,但是对Aligned Checkpoint的效果会更加明显。在Unaligned Checkpoint情况下使用缓冲区 Debloating 时,附加的好处是 Checkpoint 大小会更小,并且恢复时间更快 (因为需要保存和恢复的 In-flight 数据会更少)。开启方式是框架参数增加以下配置:
taskmanager.network.memory.buffer-debloat.enabled=true
如果启用这个配置,可以支持适当减小Checkpoint的周期,实现更频繁的Checkpoint。
大状态作业的恢复
当Flink任务出现失败时,可以基于本地的状态信息进行恢复,但这只在作业框架内重启时比较有效,当作业重新启动时,由于其运行节点与上一次的节点基本不会相同,所以在Application ID发生改变时,本地状态恢复几乎失去了意义。
开启方式是在框架参数中增加以下配置:
state.backend.local-recovery=true
5.8 Jar包任务数据倾斜问题的解决
keyby之前的数据倾斜
这可能是由于数据源的数据本身就不均衡,如Talos/Kafka的Topic中某些partition的数据量较大,某些partition的数据量较小,此时除了可以从业务上和数据源上解决该问题,如果不需要维护数据的有序性(同partition的数据是有序的,如果下游继续使用forward、hash等流分区方式,将能维持数据消费的有序性,从而确保不出现乱序问题),那么可以让Flink任务强制shuffle,通过shuffle、reblance或rescale算子即可将数据均匀分配,解决数据倾斜问题。
keyby之后的聚合存在数据倾斜
采用本地预聚合的思想,在keyby上游算子的数据发送之前,在其本地对数据进行聚合之后再发送到下游,从而减少下游接收到的数据,让keyby之后的聚合操作不再是瓶颈。在实现上必须存在一个攒批的过程,只有当上游算子攒够一定的数据量,再聚合发送给下游才会生效,这是由于在没有开窗的情况下,Flink是基于事件驱动来处理的,每来一条数据即处理一条,并向下游发送一条,根本达不到本地聚合的效果。
keyby之后的窗口聚合存在数据倾斜
由于使用了窗口,此时已经将流数据变成了有界数据,由于窗口默认已经完成了攒批操作,因此可以直接使用两阶段聚合的方式处理,第一阶段为key拼接随机前缀或后缀,然后keyby、开窗和聚合;第二阶段去掉随机前缀或后缀,按原来的key和windowEn做keyby和聚合。
5.9 SQL使用和调优的最佳实践
Group Aggregate优化
- 开启MiniBatch提升吞吐 我们知道微批处理几乎总能提高吞吐(当然,是以牺牲部分实效性为代价的),Flink SQL中的MiniBatch的原理是缓存一定的数据量后再触发处理,从而减少对State的访问,提升吞吐的同时减少数据的输出,目前主要是通过在每个Task上注册Timer定时器线程来触发的,所以可能会有一定的线程调度性能的损耗,但根据以往经验,它对于实效性要求不那么高的任务,几乎总能提升其吞吐量。 MiniBatch默认是关闭的,开启方式如下:
set table.exec.mini-batch.enabled=true;
set table.exec.mini-batch.allow-latency=5s;
set table.exec.mini-batch.size=20000;
- 开启LocalGlobal Aggregate解决普通聚合的数据热点问题 用于解决SUM、COUNT、MAX、MIN和AVG等普通聚合的性能,主要思路是将原Aggregate拆分成Local+Global两阶段聚合,第一阶段在上游节点本地攒一批数据进行聚合(Local Aggregate),并输出这个微批的增量值;第二阶段将收到的增量值再进行合并,从而得到最终的结果(Global Aggregate)。本质上来讲,其就是依靠Local Aggregate聚合掉部分倾斜数据,从而降低Global Aggregate的热点,提升性能。 LocalGlobal Aggregate优化默认需要先开启MiniBatch,因此其依赖于上面提到的三个MiniBatch的参数,此外它还有一个额外的参数:
set table.optimizer.agg-phase-strategy=TWO_PHASE
该参数指定聚合策略,默认值是AUTO,表示不强制,此时它会根据Cost来决定使用哪种聚合方式;TWO_PHASE表示强制使用两阶段聚合方式,也就是Local Aggregate和Global Aggregate;ONE_PHASE表示强制使用一阶段提交方式CompleteGlobalAggregate,也就是没有本地于聚合的方式。
如果在最终生成的Topology中包含名为GlobalGroupAggregate或是LocalGroupAggregate的节点则表示生效。
开启Split Distinct来优化Distinct性能
LocalGlobal Aggregate对于count distinct的收效并不明显,因为count distinct在本地预聚合时,去重的效率并不高,因此在Global Aggregate时仍然会存在热点问题。其实现方式是,先对Distinct的key打散求count distinct,然后再在全局对打散去重后的数据进行SUM汇总。
默认也是不开启的,可以通过以下参数开启
set table.optimizer.distinct-agg.split.enabled=true;
set table.optimizer.distinct-agg.split.bucket-num=1024;
如果在最终生成的Topology中包含名为Expand的节点或是原来的一层聚合变成了两层聚合则表示生效。建议在使用count distinct且无法满足当前性能要求时开启。
TopN优化
TopN算子有一个Cache层,它会缓存部分State的内容来减少State的访问,从而提升性能,增大缓存大小能提升缓存命中率,从而使大量的请求命中缓存,大幅提升性能,如果内存充足,建议可以适当增大Top N的Cache Size。
配置方式如下(默认是10000):
set table.exec.topn.cache-size=20000;
当然,目前该参数被标记为@Experimental的,也就是说是实验性质的参数,在性能比较低时可以尝试增大该配置的值。
6 Flink 依赖冲突排查
- Method Not Found
Caused by:java.lang.NoSuchMethodError:org.apache.flink.api.common.functions.RuntimeContext.getMetricGroup()Lorg/apache/flink/metrics/groups/OperatorMetricGroup;
at org.apache.flink.api.common.functions.util.FunctionUtils.openFunction(FunctionUtils.java:34)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.open(AbstractUdfStreamOperator.java:102)
at org.apache.flink.streaming.api.operators.ProcessOperator.open(ProcessOperator.java:56)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:428)
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$2(StreamTask.java:571)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.runThrowing(StreamTaskActionExecutor.java:50)
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:561)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:601)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:758)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:573)
at java.lang.Thread.run(Thread.java:748)
- is not assignable 通常是版本依赖错误,导致依赖冲突。 如下的错误所示: redis/clients/jedis/JedisPoolConfig 正常情况下继承了 org/apache/commons/pool2/impl/GenericObjectPoolConfig ,如果 JedisPoolConfig 所在的包 shade 了 org/apache/commons/pool2/impl/GenericObjectPoolConfig 则会导致这个问题
排查流程:
- 在框架参数增加参数查看加载的类和 jar 的对应关系. 增加参数之后, 作业的 stdout 中会打印 class 是从哪个 jar 引入的
env.java.opts.taskmanager=“-verbose:class”
env.java.opts.jobmanager=“-verbose:class”
- 排查并解决依赖冲突
冲突类来自集群的公共依赖:
- 如果是 Flink 依赖, 确认 Flink 的版本是否一致, 确认 jar 打包的版本和 Flink 集群保持一致
- 如果是其他依赖, 一般可以可以看到依赖的 jar 的版本 - 修改用户 jar 包依赖的版本, 保持和 Flink 集群的版本一致- Shade 用户 jar 包依赖的相关 jar,避免引用到集群的版本
冲突的类来自用户 jar 包
- 确认打包不同依赖之间 jar 版本是否存在冲突
- 使用idea的插件 maven helper ,查看版本不一致的jar包
7 常见报错问题
1. 心跳超时 Heartbeat Timeout
原因:
心跳超时是比较常见的问题,一般是 FullGC 比较频繁导致的心跳超时,少部分是因为网络引起的,如果作业频繁出现心跳超时,则大概率是内存问题导致。
如果需要确认是否因为 GC 导致的异常,通常有两种方式可以查看 GC 的情况。
- 通过 metrics 页面, 查看 taskManager 的 GC 情况。metrics 的查看入口可以参考 查看Flink监控
- 通过 Yarn 日志,查看 taskManager 的 GC log. 解决方案:
- 可以调大内存减少 GC
- 增大心跳超时时间:heartbeat.timeout = xxxxxx (默认200000)
2. Remote task manager was lost
- exit code 143 搜索 Jobmanager 是否存在如下日志:
org.apache.flink.runtime.io.network.netty.exception.RemoteTransportException:Connection unexpectedly closed by remote task manager 'zjy-hadoop-prc-st2998.bj/10.152.163.21:39427'.This might indicate that the remote task manager was lost.[2020-10-2616:20:51.616]Container exited witha non-zero exit code 143.Error file: prelaunch.err.
原因:
container 超过 yarn 内存限制被 kill.
Flink 中部分 direct memory 及 native 由于不受 JVM 控制,有可能会超用,导致超出 container 内存大小,被 yarn kill 掉。
解决方案:
- 1.9 集群作业:增大containerized.heap-cutoff-ratio, 该值默认为0.25
- 1.10 及以上集群作业: 如果 statebackend 是 rocksdb,增大 overhead 内存,调整如下两个参数 (overhead 内存会在 fraction 及 max 中取最小值): taskmanager.memory.jvm-overhead.fraction=0.2(默认 0.1) taskmanager.memory.jvm-overhead.max=2gb(默认 1gb)1. exit code 139 搜索 Jobmanager 是否存在如下日志:
2020-10-2616:20:55.312 INFO org.apache.flink.yarn.YarnResourceManager-ClosingTaskExecutor connection container_e1296_1600936402499_3888764_01_000020 because:[2020-10-2616:20:51.606]container-launch withexit code:139[2020-10-2616:20:51.608]Container exited witha non-zero exit code 139.Error file:prelaunch.err.
Last4096 bytes of prelaunch.err :[2020-10-2616:20:51.616]Container exited witha non-zero exit code 139.Error file:prelaunch.err.
Last4096 bytes of prelaunch.err :
一般为 JNI 调用出现 segmention fault,排查 JNI 调用是否存在问题。
- exit code 134 or 239 搜索 Jobmanager 是否存在如下日志:
2020-11-0214:41:01.067 INFO org.apache.flink.yarn.YarnResourceManager-ClosingTaskExecutor connection container_e1296_1600936402499_4685980_03_000057 because:[2020-11-0214:41:00.613]container-launch withexit code:239[2020-11-0214:41:00.615]Container exited witha non-zero exit code 239.Error file:prelaunch.err.
Last4096 bytes of prelaunch.err :[2020-11-0214:41:00.627]Container exited witha non-zero exit code 239.Error file:prelaunch.err.
Last4096 bytes of prelaunch.err :
如果退出码为 239 或 134,该 container 为 OOM 退出,检查逻辑是否正确。
4. NoResourceAvailableException
队列资源不足,请扩充队列资源。
5. Exit Code: 1
- 可以先检查下 MainClass 是否在 Jar 包中存在
- 检查 Jar 包中是否存在 .SF, .DSA, .RSA 等文件
10. PartitionNotFoundException
2020-09-11 10:04:14
org.apache.flink.runtime.io.network.partition.PartitionNotFoundException: Partition 7613422ba6fffae3952a09198b000211@318bbf7c3c0a151d9fbfdd7f014e0e81 not found.
如果经常出现这个问题可以尝试调大taskmanager.network.request-backoff.max=12000(默认值为10000)
参考:https://ci.apache.org/projects/flink/flink-docs-release-1.9/release-notes/flink-1.9.html#network-stack
11. Flink界面的Byte Received和Bytes Send等监控都为0.

如图所示,这里的Bytes Received 和Bytes Sent都为0。
这是因为这指标是task和task之间的数据传输量,当task只有一个时,它既没有逻辑上的上游也没有逻辑上的下游,所以这里的指标都为0。
如果想查看 operator之间的数据处理速度,可以查看Flink的metric监控页面。
12. Could not forward element to next operator xxxxxx Caused by : Buffer pool is destroyed.
一般来说,出现buffer pool is destroyed的报错出现在作业已经失败的情况, 需要再继续找下该报错之前的日志,找到导致作业失败的真实原因.
回撤流异常情况
set table.exec.sink.drops=DELETE;UPDATE_BEFORE;
case when coalesce(A,‘’) = ‘’ else B 也会导致回撤流异常
版权归原作者 Direction_Wind 所有, 如有侵权,请联系我们删除。