
- [分布式与微服务的区别](#_13)
+ [什么是CAP?为什么不能三者同时拥有](#CAP_32)
+ - [分区容错性](#_40)
- [一致性](#_44)
- [可用性](#_50)
+ [Base理论了解吗](#Base_56)
+ - [基本可用](#_59)
- [软状态](#_69)
- [最终一致性](#_73)
+ [什么是分布式事务](#_78)
+ [分布式事务有哪些常见的实现方案?](#_83)
+ - [2PC(Two Phase Commit)](#2PCTwo_Phase_Commit_85)
- [3PC(Three Phase Commit)](#3PCThree_Phase_Commit_118)
- [TCC(Try Commit Cancel)](#TCCTry_Commit_Cancel_122)
- [2PC、3PC、TCC区别](#2PC3PCTCC_138)
- [2PC存在问题](#2PC_144)
- [TCC存在问题](#TCC_147)
- [TCC的优点](#TCC_152)
- [对比2PC,3PC有什么优点](#2PC3PC_158)
+ [有哪些分布式锁的实现方案?](#_164)
+ - [一、 分布式锁场景](#__165)
- [二、分布式锁特点](#_168)
- [基于缓存实现分布式锁,以Redis为例](#Redis_177)
+ [感谢阅读](#_252)
分布式系统面试全集通第一篇
什么是分布式?和微服务的区别
什么是分布式
- 一个系统各组件分别部署在不同服务器。彼此通过网络通信和协调的系统。
- 也可以指多个不同组件分布在网络上互相协作,比如说电商网站
- 也可以一个组件的多个副本组成集群,互相协作如同一个组件,比如数据存储服务中为了数据不丢失而采取的多个服务备份冗余,当数据修改时也需要通信来复制数据
- 分布式最早出现的目地首先是解决单点问题,避免单点故障,然后解决了性能问题

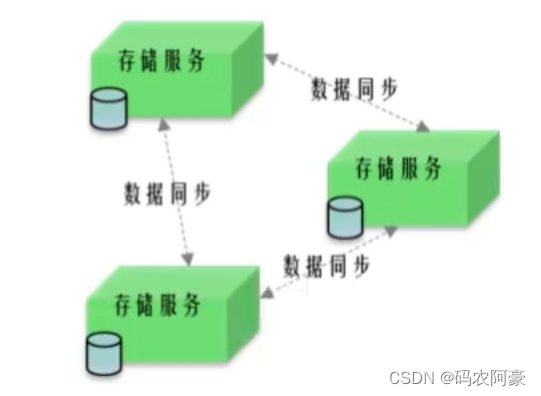
分布式与微服务的区别
分布式和微服的架构很相似,只是部署的方式不一样而已。
- 分布式服务架构与微服务架构概念的区别与联系: - 分布式:分散压力。 不同模块部署在不同服务器上; 作用:分布式解决网站高并发带来问题; 集群:相同的服务; 多台服务器部署相同应用构成一个集群; 作用:通过负载均衡设备共同对外提供服务; 业务系统分解为多个组件,让每个组件都独立提供离散,自治,可复用的服务能力; 通过服务的组合和编排来实现上层的业务流程; 作用:简化维护,降低整体风险,伸缩灵活;- 微服务:分散能力。 微服务[找到服务/微服务网关open API]; 架构设计概念:各服务间隔离(分布式也是隔离),自治(分布式依赖整体组合),其它特性(单一职责,边界,异步通信,独立部署) 是分布式概念更加严格的执行; SOA到微服务架构的演进过程; 作用:各服务可独立应用,组合服务也可系统应用(巨石应用[monolith]的简化实现策略-平台思想).
- 明确一个问题:分布式主要针对是部署方式,微服务则是将应用才分的一种应用架构
什么是CAP?为什么不能三者同时拥有
在设计一个分布式项目的时候会遇到三个特性:
- 一致性(consistency)
- 可用性(Availability)
- 分区容错(partition-tolerance)都需要的情景 输入/唤起更 CAP定律说的是在一个分布式计算机系统中,一致性,可用性和分区容错性这三种保证无法同时得到满足,最多满足两个。
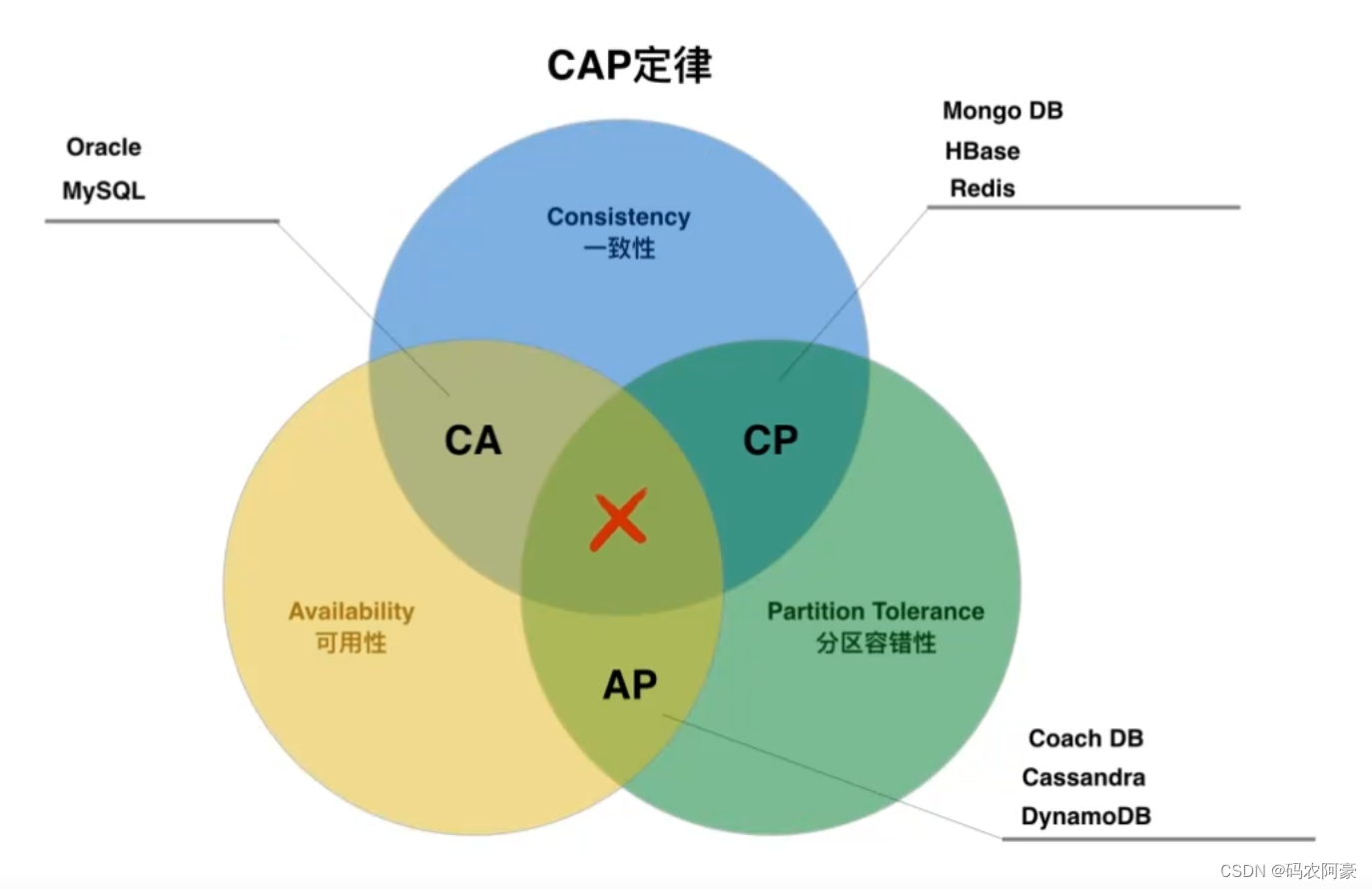
分区容错性
- 分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供服务。
- 分布式系统中,尽管部分节点出现任何消息丢失或者故障,系统应继续运行
- 通常分布式系统的各各结点部署在不同的子网,这就是网络分区,不可避免的会出现由于网络问题而导致结点之间通信失败,此时仍可对外提供服务。
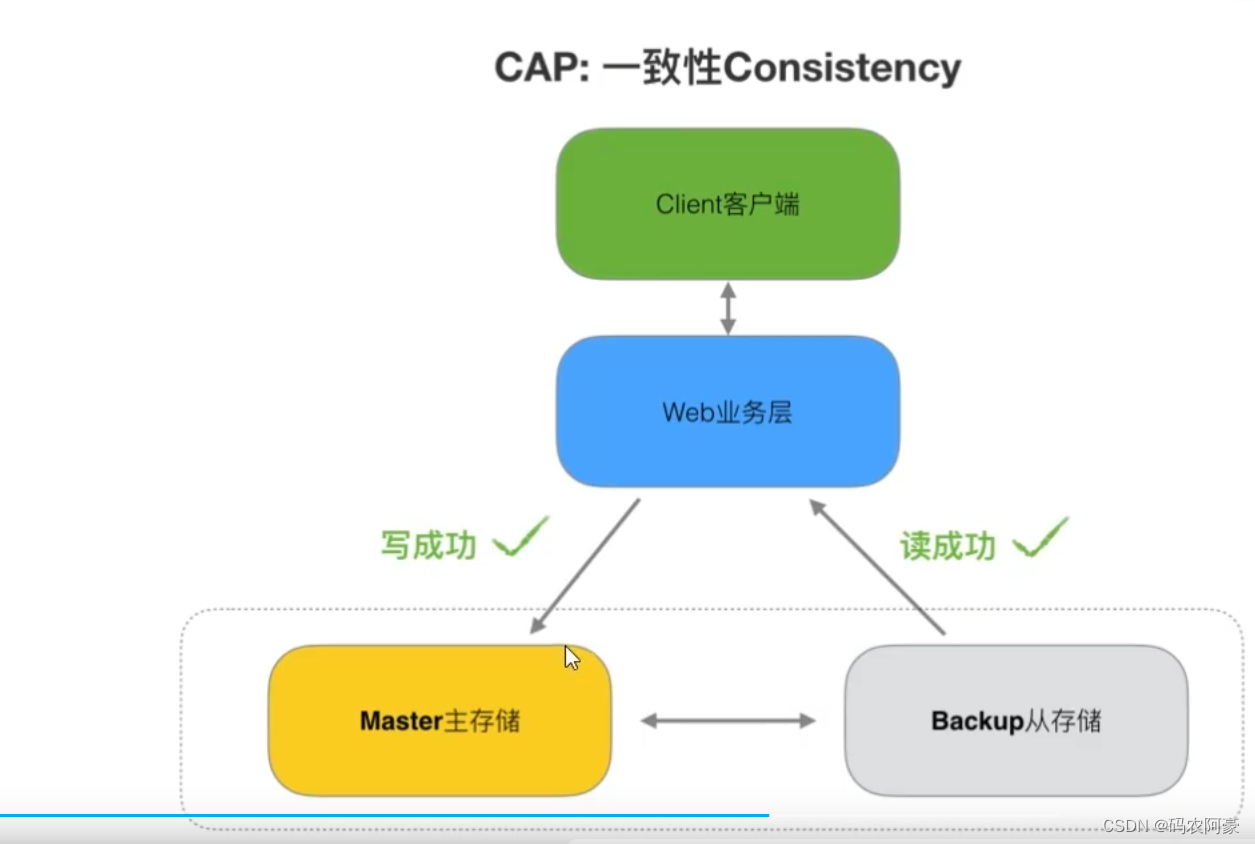
一致性
- 一致性指"all nodes see the same data at the same即更新操作成功并返回客户端time完成后,所有节点在同时间的数据完全一致。
- 一旦数据更新完成并成功返回客户端后,那么分布式系统中所有节点在同一时间的数据完全一致。
- 一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都是最新的状态。
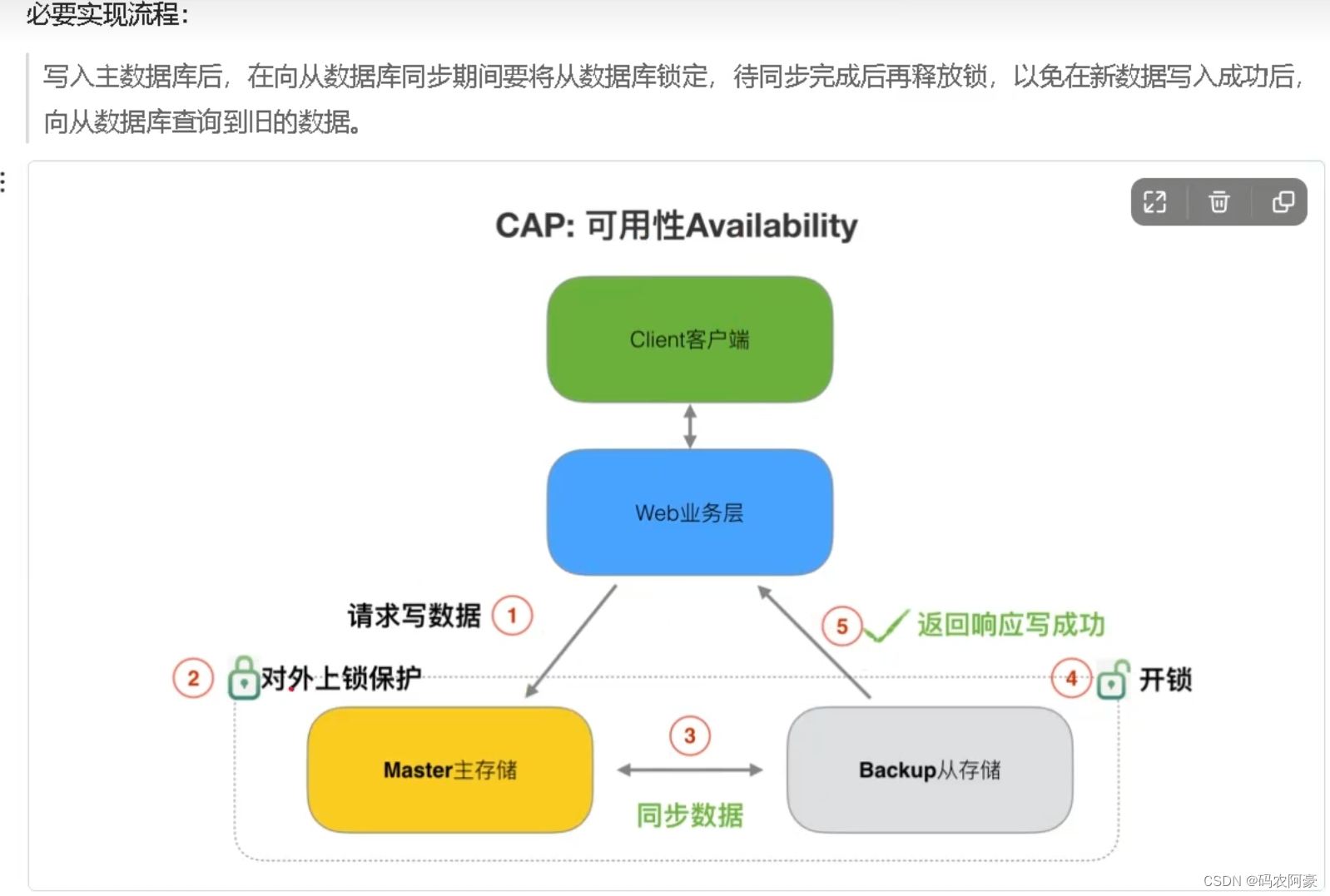
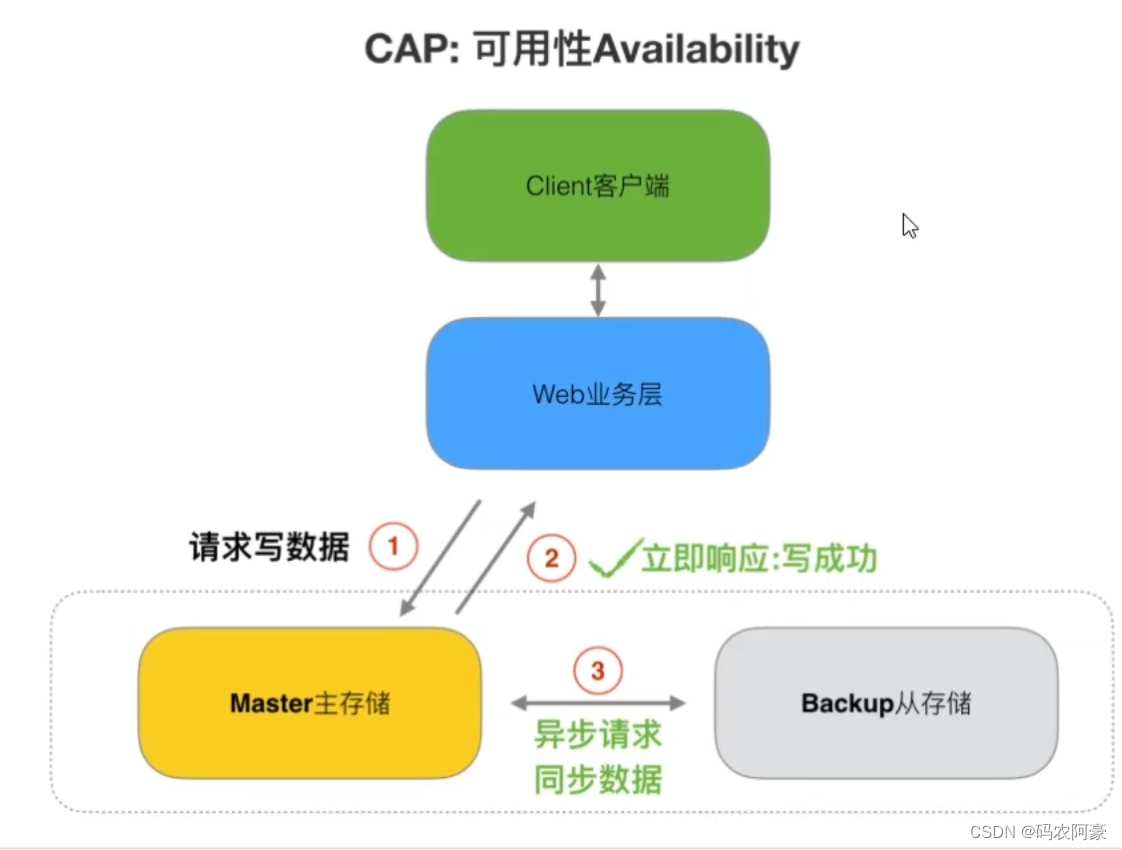
可用性
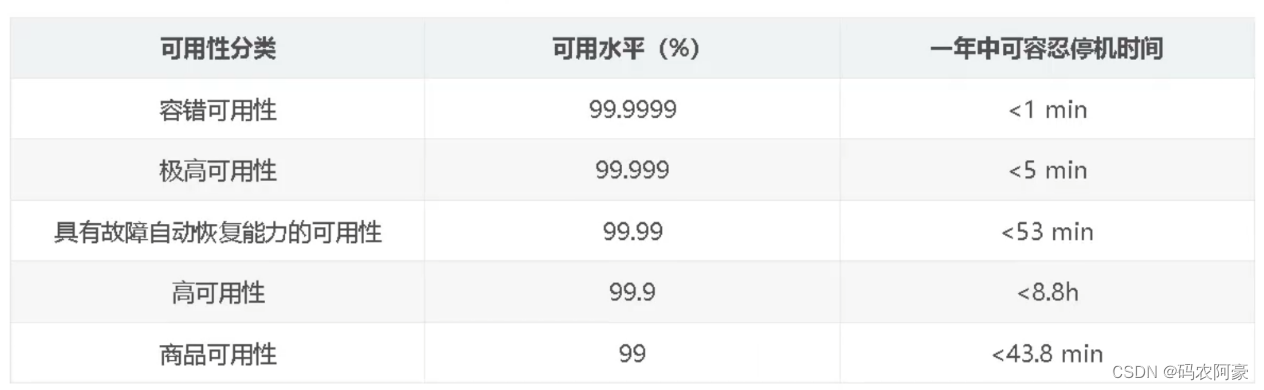
- 可用性指即服务一直可用,而且是正常响应时间。“Reads and writes always succeed” 对于可用性的衡量标准如下:
Base理论了解吗
BASE(Basically Available、Soft state、Eventual consistency)是基于CAP理论逐步演化而来的,核心思想是即便不能达到强一致性(Strong consistency),也可以根据应用特点采用适当的方式来达到最终致性(Eventual consistency)的效果。
基本可用
基本可用本质是一种妥协,也就是出现节点故障或者系统过载时,通过牺牲非核心功能的可用性,保障核心功能的稳定运行。
实现基本可用的几个策略:
- 1、流量削峰(不同地区售票时间错峰出售) 以订票系统设计为例,在春运期间,开始售票前后会出现及其海量的请求峰值。 可以在不同的时间,出售不同区域的票,将访问请求错开,削弱请求峰值。
- 2、延迟响应,异步处理(买票排队,基于队列先收到用户买票请求,排队异步处理,延迟响应)还以订票系统为例。用户提交购票请求后,往往会在队列中排队等待处理,可能几分钟或十几分钟后,系统才开始处理,然后响应处理结果。
- 3、体验降级(看到非实时数据,采用缓存数据提供服务)以互联网系统为例,若出现网络热点事件,产生了海量的突发流量,系统过载,大量图片因为网络超时无法显示那么可以用小图片代替原始图片,降低图片的清晰度和大小,提升系统处理能力。
- 4、过载保护熔断/限流,直接拒绝掉一部分请求,或者当请求队列满了,移除一部分请求,保证整体系统可用)把接收到的请求放在指定的队列中排队处理,如果请求等待时间超时,这时直接拒绝超时请求;如果队列满了之后,就清除队列中一定数量的排队请求,保护系统不过载,实现系统基本可用。
- 5、故障隔离(出现故障,做到故障隔离,避免影响其他服务)
软状态
软状态(弱状态)->允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延迟。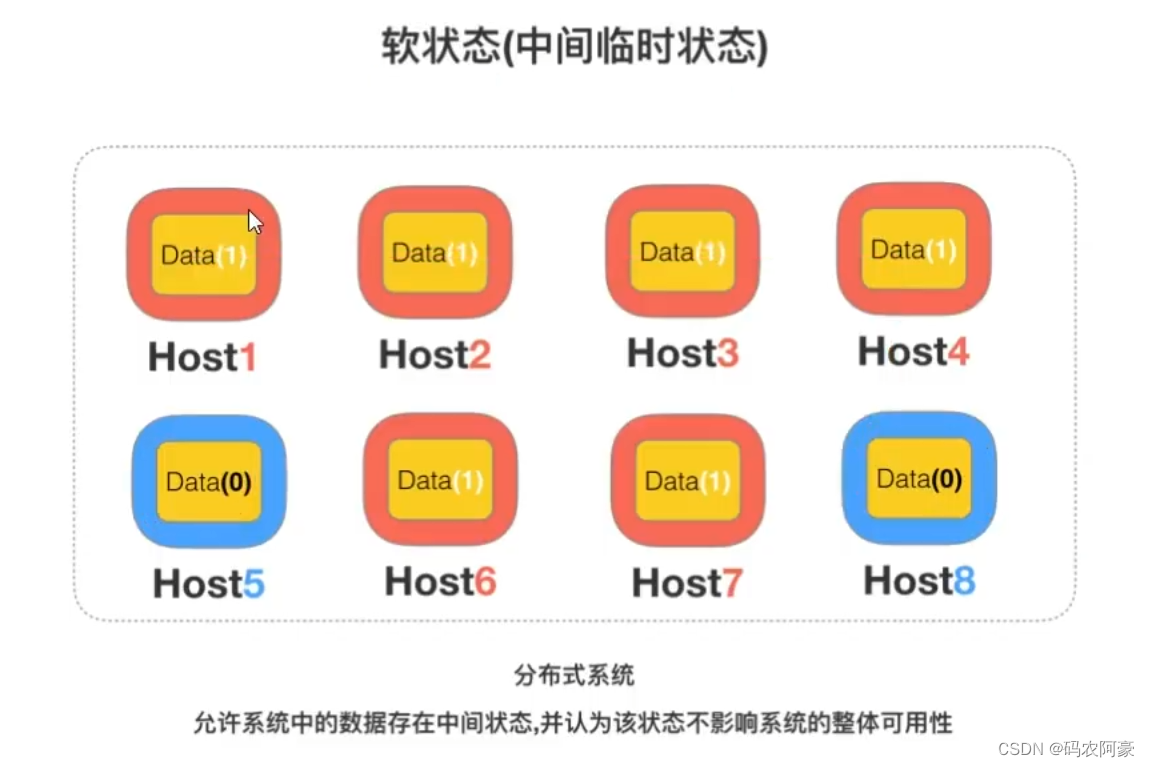
最终一致性
上面说软状态,然后不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性。
从而达到数据的最终一致性。这个时间期限取决于网络延时,系统负载,数据复制方案设计等等因素。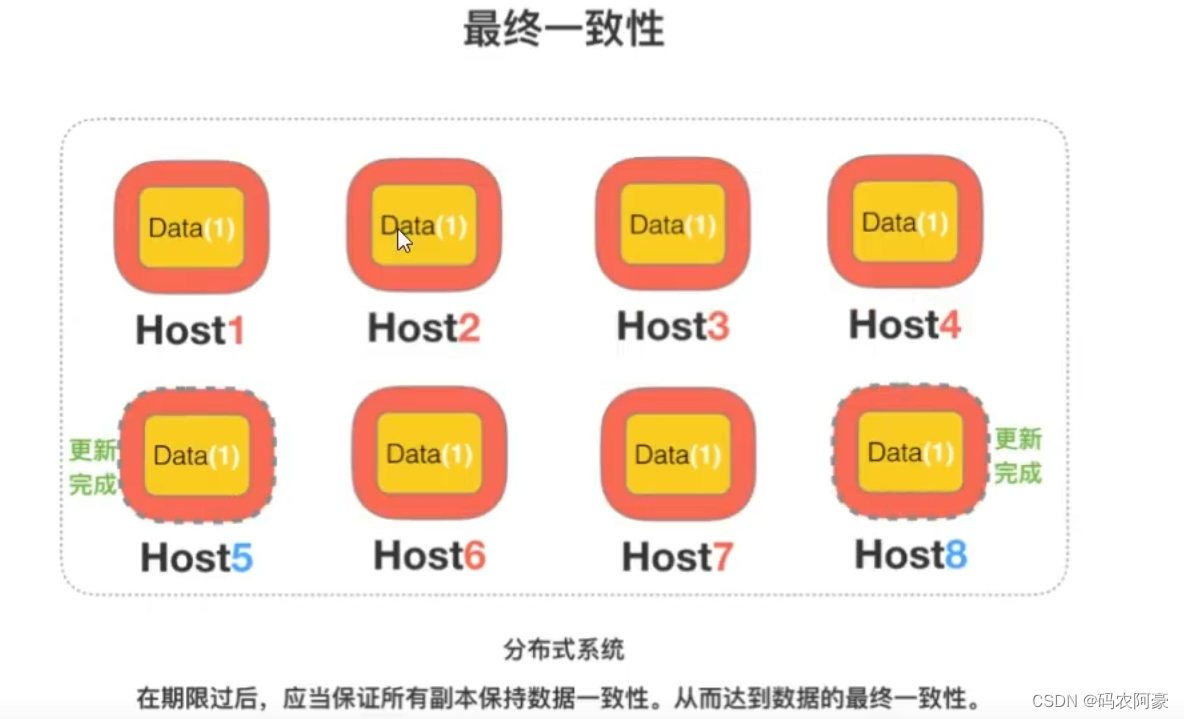
什么是分布式事务
分布式事务是相对本地事务而言的,对于本地事务,利用数据库本身的事务机制,就可以保证事务的ACID
特性。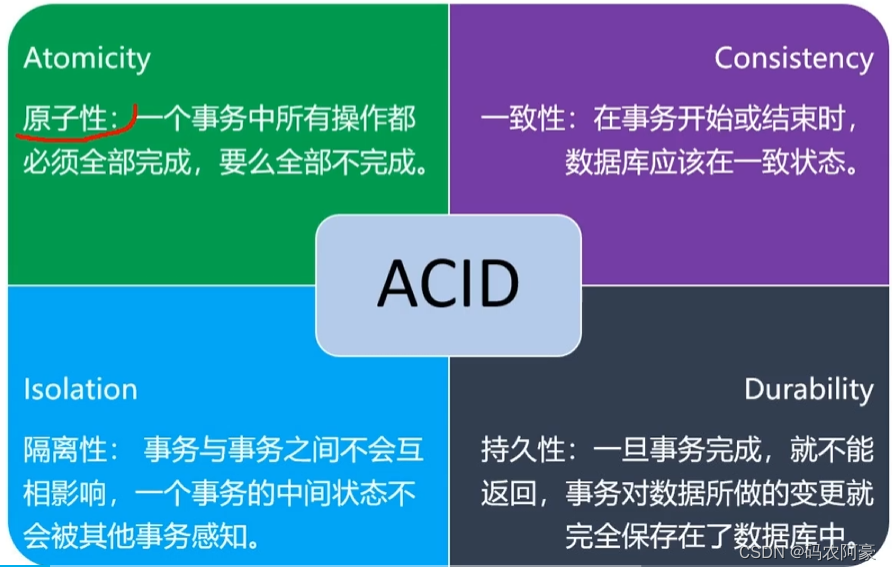
分布式事务有哪些常见的实现方案?
到现在,分布式事务已经有很多的解决方案了,有2PC、3PC、TCC,这一篇博客,我们先来分别讲讲最早的2PC、3PC这两种解决方案的模型及理论基础,以后再丰富其他的分布式事务解决方案。
2PC(Two Phase Commit)
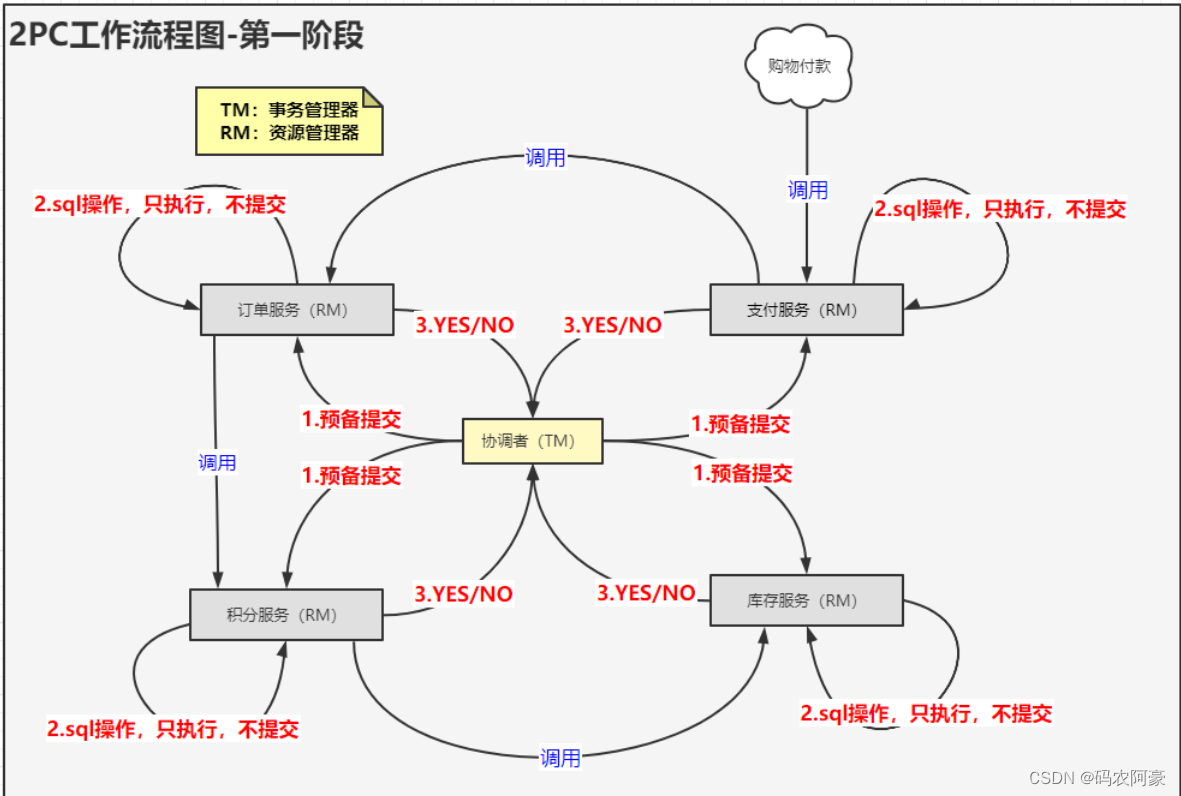
第一阶段:执行事务操作
- 事务询问。 协调者节点向所有参与者节点询问是否可以执行提交操作,并开始等待各参与者节点的响应。
- 执行事务。 参与者节点执行询问发起的所有事务操作,并将Undo信息和Redo信息写入数据库日志。(若操作成功,这里其实每个参与者已经执行了事务操作)
- 各参与者向协调者反馈事务询问的响应。 各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则反馈一个“同意”消息;如果执行失败,则反馈一个“中止”消息。
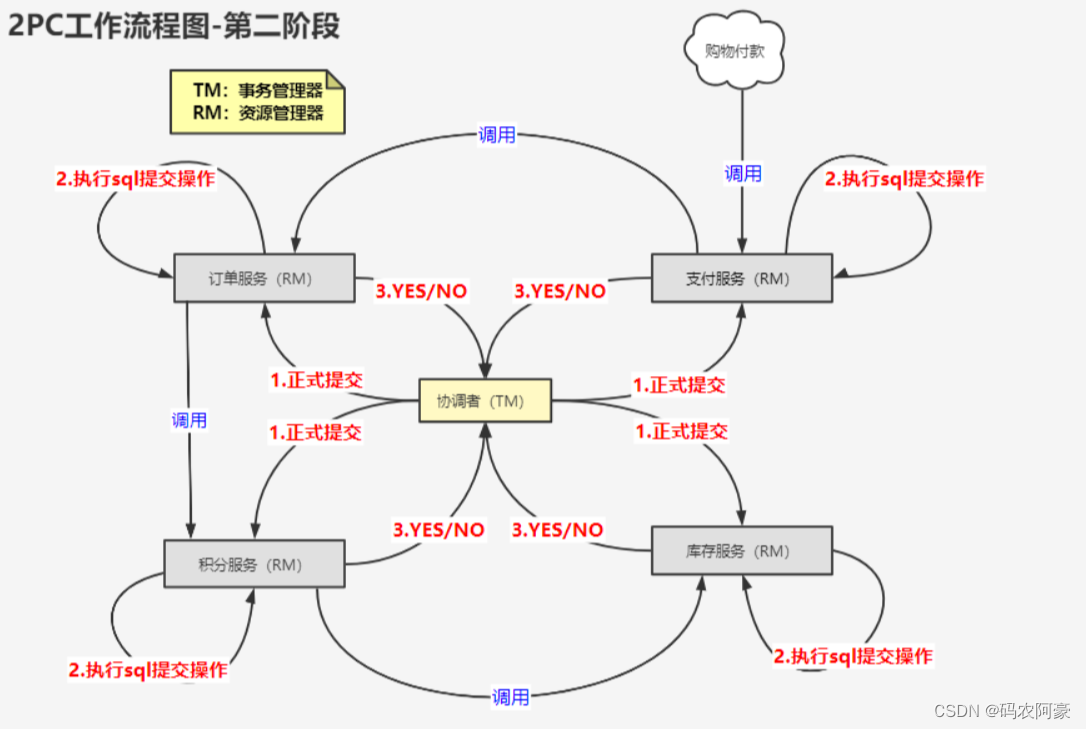 第二阶段:执行事务提交
第二阶段:执行事务提交
当所有参与者节点在第一阶段向协调者节点反馈的消息全都是“同意”时:
- 发送事务提交请求 协调者节点向所有参与者节点发出“正式提交(commit)”请求。
- 事务正式提交 参与者节点正式完成提交操作,并释放在整个事务期间占用的资源。
- 反馈事务提交结果 参与者节点向协调者节点发送“完成”消息。
- 完成事务 协调者节点收到所有参与者节点反馈的“完成”消息后,完成分布式事务。 当任一参与者节点在第一阶段反馈的响应为“中止”,或者协调者在第一阶段接收反馈信息超时:
发送事务回滚请求
协调者节点向所有参与者节点发出“回滚操作(rollback)”请求。
- 事务回滚 各参与者节点收到请求,利用之前写入的Undo信息执行本地事务回滚操作,并释放在整个事务期间占用的资源。
- 反馈事务回滚结果 参与者节点向协调者节点发送“回滚完成”消息。
- 中断事务 协调者节点收到所有参与者节点反馈的“回滚完成”消息后,取消事务。
3PC(Three Phase Commit)
3PC没有解决2PC所有问题,只是降低了灾难的发生概率。只是在2PC基础上,多一个询问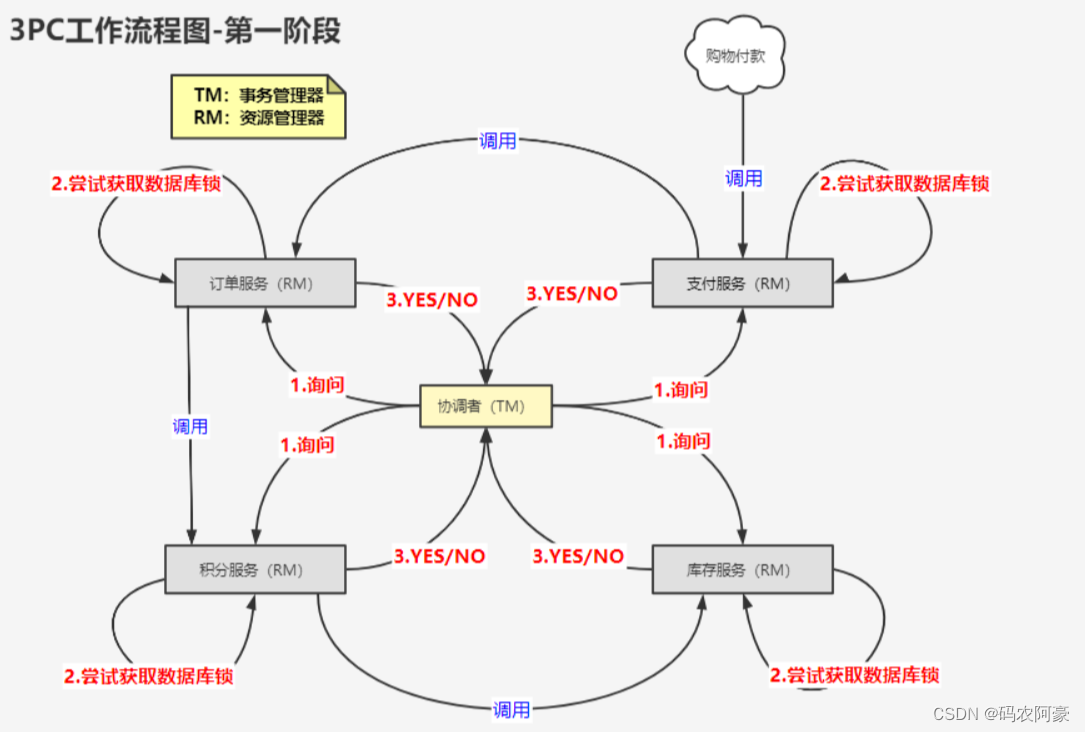
TCC(Try Commit Cancel)
这个模型有两个个阶段,但是与2PC的三个阶段又有所不同。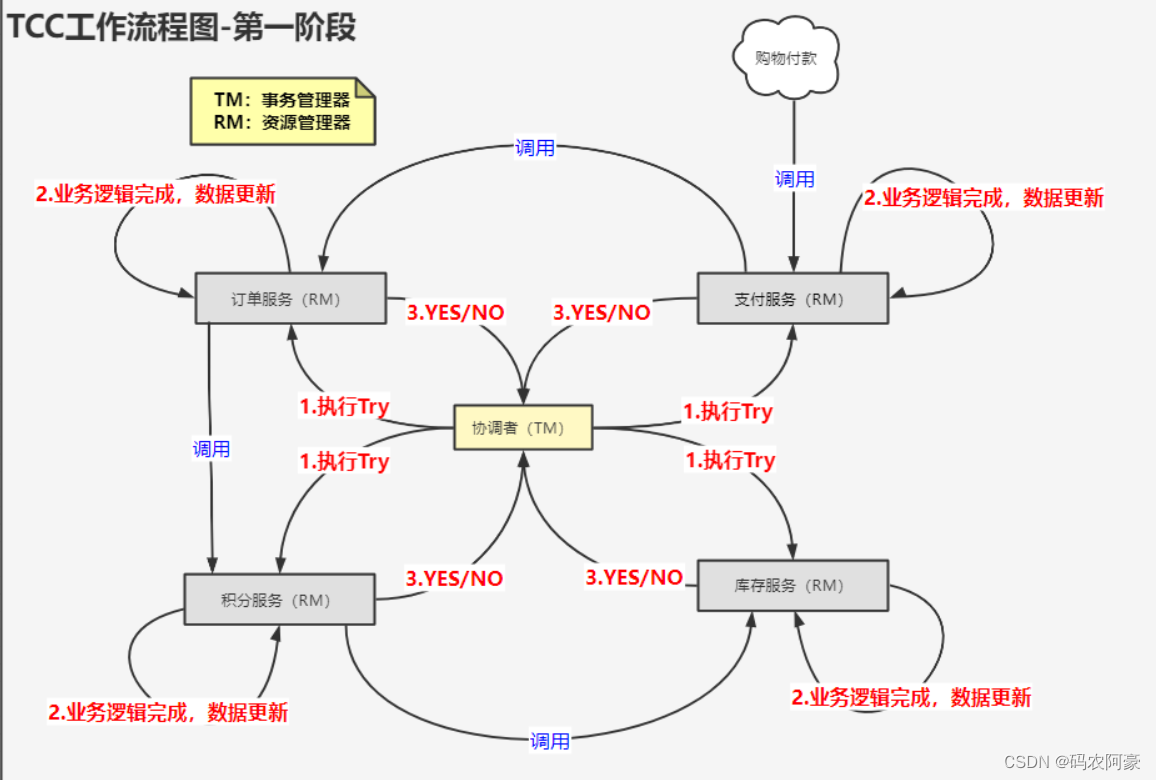
第一阶段:执行Try操作
- 事务发起。 协调者节点向所有参与者节点发起执行业务逻辑包含数据操作的命令,并开始等待各参与者节点的响应。
- 执行数据操作。 直接对数据库的数据执行操作。
- 各参与者向协调者反馈执行操作的响应。 各参与者节点响应协调者节点发起的数据操作。如果参与者节点的数据操作实际执行成功,则反馈一个“同意”消息;如果有一个参与者执行失败,则反馈一个“中止”消息。
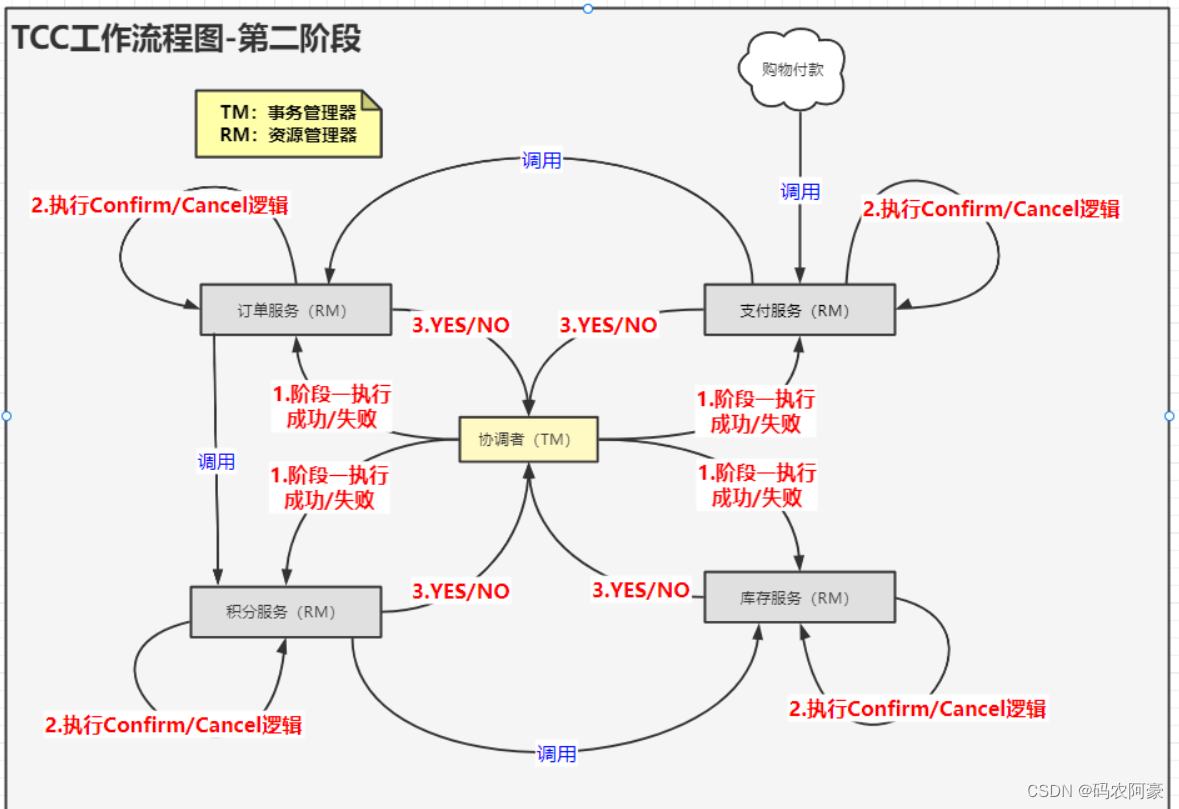 第二阶段:执行Confirm/Cancel操作 根据阶段一各事务参与者的响应,如果所有事务参与者在阶段一执行成功,那就执行Confirm操作,有一个事务参与者在阶段一执行失败,就执行Cancel操作,进行数据库数据恢复。 Confirm 操作用于执行数据操作成功之后的业务逻辑。 Cancel 操作用于恢复阶段一对数据的操作。
第二阶段:执行Confirm/Cancel操作 根据阶段一各事务参与者的响应,如果所有事务参与者在阶段一执行成功,那就执行Confirm操作,有一个事务参与者在阶段一执行失败,就执行Cancel操作,进行数据库数据恢复。 Confirm 操作用于执行数据操作成功之后的业务逻辑。 Cancel 操作用于恢复阶段一对数据的操作。
2PC、3PC、TCC区别
1.在2PC的第一阶段基础之上,3PC新加了一个准备阶段(上图所示),用于询问所有参与者节点是否已经准备好要进行分布式事务操作了,这一阶段没有对资源的占用,只是测试数据库是否能获取锁即可,只是保证所有参与者都有能力参与事务,如果有网络或者其他问题就不用进行第二、三阶段了。
2. 在3PC的所有阶段,都为所有参与者节点和协调者节点添加了超时机制,防止因某一节点宕机造成的资源无法释放问题。
3. 2PC中所有阶段,只对协调者节点添加了超时机制。
4. TCC模型主要是在应用层做的一个分布式事务,2PC和3PC则是在数据库层做的分布式事务。
5。 TCC模型可以用于不支持事务的数据库,但是2PC和3PC要求数据库必须支持事务。
2PC存在问题
2PC只对协调者节点添加了超时机制,如果协调者这一重要角色宕机,所有参与者的资源就会一直得不到释放,降低系统的可用性。
2PC中,当其中任一节点宕机情况出现时,不能保证数据的最终一致性。
TCC存在问题
总目录展示
该笔记共八个节点(由浅入深),分为三大模块。
高性能。 秒杀涉及大量的并发读和并发写,因此支持高并发访问这点非常关键。该笔记将从设计数据的动静分离方案、热点的发现与隔离、请求的削峰与分层过滤、服务端的极致优化这4个方面重点介绍。
一致性。 秒杀中商品减库存的实现方式同样关键。可想而知,有限数量的商品在同一时刻被很多倍的请求同时来减库存,减库存又分为“拍下减库存”“付款减库存”以及预扣等几种,在大并发更新的过程中都要保证数据的准确性,其难度可想而知。因此,将用一个节点来专门讲解如何设计秒杀减库存方案。
高可用。 虽然介绍了很多极致的优化思路,但现实中总难免出现一些我们考虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),麻烦各位转发一下(可以帮助更多的人看到哟!)


由于内容太多,这里只截取部分的内容。
虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),麻烦各位转发一下(可以帮助更多的人看到哟!)
[外链图片转存中…(img-7Pc0XQgx-1725833456428)]
[外链图片转存中…(img-JNLgBJuK-1725833456429)]
由于内容太多,这里只截取部分的内容。
版权归原作者 gan_zi_ge 所有, 如有侵权,请联系我们删除。