
1.图片验证码
import requests
res = requests.get('https://www.gushiwen.cn/RandCode.ashx')withopen("code.png","wb")as f:
f.write(res.content)
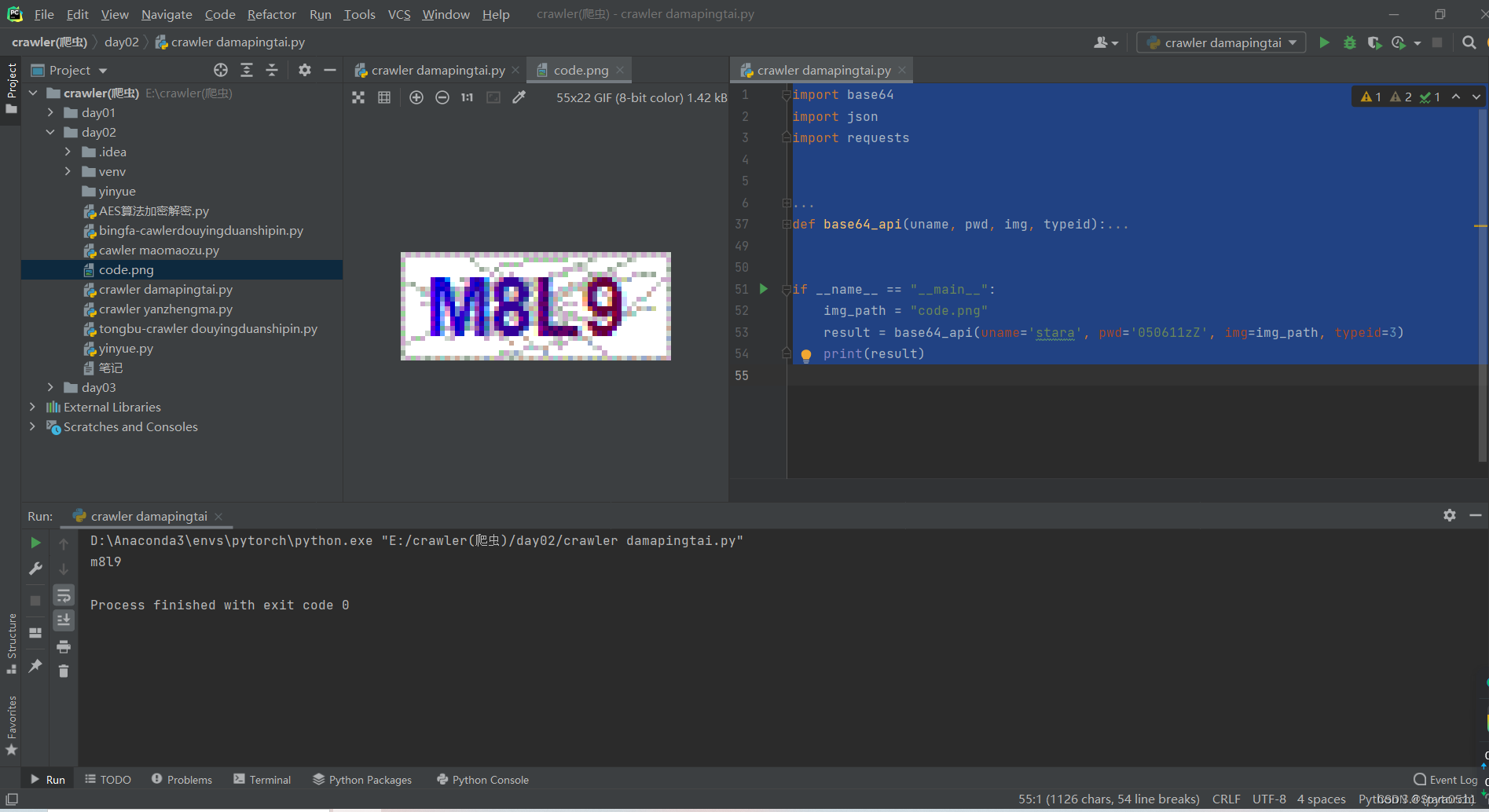
2.打码平台
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):# 1 : 纯数字# 1001:纯数字2# 2 : 纯英文# 1002:纯英文2# 3 : 数英混合# 1003:数英混合2# 4 : 闪动GIF# 7 : 无感学习(独家)# 11 : 计算题# 1005: 快速计算题# 16 : 汉字# 32 : 通用文字识别(证件、单据)# 66: 问答题# 49 :recaptcha图片识别# 二、图片旋转角度类型:# 29 : 旋转类型## 三、图片坐标点选类型:# 19 : 1个坐标# 20 : 3个坐标# 21 : 3 ~ 5个坐标# 22 : 5 ~ 8个坐标# 27 : 1 ~ 4个坐标# 48 : 轨迹类型## 四、缺口识别# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)# 33 : 单缺口识别(返回X轴坐标 只需要1张图)# 五、拼图识别# 53:拼图识别defbase64_api(uname, pwd, img, typeid):withopen(img,'rb')as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data ={"username": uname,"password": pwd,"typeid": typeid,"image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)if result['success']:return result["data"]["result"]else:# !!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别return result["message"]return""if __name__ =="__main__":
img_path ="code.png"
result = base64_api(uname='stara', pwd='050611zZ', img=img_path, typeid=3)print(result)
本文转载自: https://blog.csdn.net/m0_69402477/article/details/136545286
版权归原作者 Stara0511 所有, 如有侵权,请联系我们删除。
版权归原作者 Stara0511 所有, 如有侵权,请联系我们删除。