
1. 基本原理
1.1 requests 模块
requests 是 Python 中一个非常流行的 HTTP 客户端库,用于发送所有的 HTTP 请求类型。它基于 urllib,但比 urllib 更易用。
中文文档地址:Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档
(1)requests.get(url, **kwargs)
requests.get() 函数是 requests 库中用于发送 HTTP GET 请求的主要函数。GET 请求通常用于从服务器请求数据,而不发送任何数据到服务器(尽管可以通过查询参数发送少量数据)。下面我将介绍 requests.get 函数的参数、用法,并给出一个简短的例子。
参数:
**url ****(str): 请求的 URL。这是 requests.get 必须的参数,想要请求的网页或资源的地址**。
**params ****(dict, optional): **一个字典或字节序列,作为查询参数增加到 url 中。例如,params={'key1': 'value1', 'key2': 'value2'} 将会以 key1=value1&key2=value2 的形式附加到 URL 上。
headers** (dict, optional): **自定义 HTTP 头。例如,可以通过 headers={'User-Agent': 'my-app/0.0.1'} 来设置用户代理。
cookies** (dict, optional): **字典或 CookieJar,包含要发送的 cookie。
timeout** (float or tuple, optional): **以秒为单位的请求超时时间。可以是单个浮点数(连接超时和读取超时相同),或者是一个元组,分别指定连接超时和读取超时。
allow_redirects** (bool, optional): **是否允许重定向。默认为 True。
**proxies ****(dict, optional): **字典映射协议或协议和主机名到 URL。
**verify ****(bool or str, optional): **是否验证 SSL 证书。默认为 True。可以提供一个 CA_BUNDLE 文件的路径。
**stream ****(bool, optional): **是否立即下载响应内容。默认为 False。如果想逐渐下载大型响应,可以设置为 True。
返回值:
requests.get 函数返回一个 Response 对象,该对象包含服务器响应的所有信息,如状态码、响应头、响应体等。
例子:
import requests
# 定义请求的 URL
url = 'http://www.umeituku.com/bizhitupian/fengjingbizhi/'
# 发送 GET 请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 读取响应内容
data = response.text
print("请求成功,响应内容为:")
print(data)
else:
# 请求失败,打印错误信息
print(f"请求失败,状态码:{response.status_code}")
print(response.text)
# 你也可以直接使用 response.json() 方法解析 JSON 响应
if response.headers.get('content-type') == 'application/json':
data = response.json()
print("解析 JSON 响应成功:")
print(data)
**(2)requests.post(url, data=None, json=None, kwargs)
requests.post() 函数是 requests 库中用于发送 HTTP POST 请求的函数。POST 请求通常用于向服务器提交数据,例如提交表单或上传文件。与 GET 请求不同,POST 请求会将数据包含在请求体中发送给服务器。下面我将详细介绍 requests.post 函数的参数、用法,并给出一个简短的例子。
参数:
url** (str): 请求的 URL。这是 requests.post 函数必须的参数**,代表你想要发送 POST 请求的网页或资源的地址。
data** (dict, bytes, or file-like object, optional): **要发送的表单数据。如果是字典,它将被转换为表单编码格式。
json** (dict, optional): **要发送的 JSON 数据。如果提供此参数,content-type 头将自动设置为 application/json。
headers** (dict, optional): **自定义 HTTP 头。
**cookies ****(dict, optional): **字典或 CookieJar,包含要发送的 cookie。
**files ****(dict, optional): **要上传的文件。字典中的键是表单字段名,值是文件元组 (filename, fileobj, content_type, content_encoding)。
**auth ****(tuple, optional): **用于身份验证的元组,如 ('user', 'pass')。
timeout** (float or tuple, optional): **以秒为单位的请求超时时间。
**proxies ****(dict, optional): **字典映射协议或协议和主机名到 URL。
**verify ****(bool or str, optional): **是否验证 SSL 证书。
**stream ****(bool, optional): **是否立即下载响应内容。
**cert ****(tuple, optional):** 客户端证书和其密钥的元组。
返回值:
requests.post 函数返回一个 Response 对象,与 requests.get 函数的返回值类似,该对象包含服务器响应的所有信息,如状态码、响应头、响应体等。
例子:
import requests
# 定义请求的 URL
url = 'http://www.umeituku.com/bizhitupian/fengjingbizhi/'
# 准备要发送的数据
data = {
'username': 'my_username',
'password': 'my_password'
}
# 发送 POST 请求
response = requests.post(url, data=data)
# 检查请求是否成功
if response.status_code == 200:
# 读取响应内容
print("登录成功,响应内容为:")
print(response.text)
else:
# 请求失败,打印错误信息
print(f"登录失败,状态码:{response.status_code}")
print(response.text)
**(2)requests.put(url, data=None, kwargs)
requests.put() 函数是 requests 库中用于发送 HTTP PUT 请求的函数。PUT 请求通常用于更新服务器上的资源。与 POST 请求不同,PUT 请求的意图是替换服务器上指定资源的内容。下面我将详细介绍 requests.put 函数的参数、用法,并给出一个简短的例子。
参数:
url** (str):** 请求的 URL。这是 requests.put 函数必须的参数,代表你想要发送 PUT 请求的资源的地址。
data** (dict, bytes, or file-like object, optional):** 要发送的数据。如果是字典,它将被转换为表单编码格式。这通常用于更新资源的内容。
json** (dict, optional): **要发送的 JSON 数据。如果提供此参数,content-type 头将自动设置为 application/json。
headers** (dict, optional): **自定义 HTTP 头。
cookies** (dict, optional): **字典或 CookieJar,包含要发送的 cookie。
**auth ****(tuple, optional): **用于身份验证的元组,如 ('user', 'pass')。
timeout** (float or tuple, optional): **以秒为单位的请求超时时间。
proxies** (dict, optional):** 字典映射协议或协议和主机名到 URL。
verify** (bool or str, optional): **是否验证 SSL 证书。
**stream ****(bool, optional): **是否立即下载响应内容。
**cert ****(tuple, optional): **客户端证书和其密钥的元组。
返回值:
requests.put 函数返回一个 Response 对象,与 requests.get 和 requests.post 函数的返回值类似。这个对象包含了服务器的响应信息,比如状态码、响应头、响应体等。
例子:
import requests
import json
# 定义请求的 URL
url = 'http://www.umeituku.com/bizhitupian/fengjingbizhi/'
# 准备要更新的数据
data = {
'name': 'Updated Name',
'description': 'This resource has been updated.'
}
# 将数据转换为 JSON 格式
data_json = json.dumps(data)
# 发送 PUT 请求
response = requests.put(url, data=data_json, headers={'Content-Type': 'application/json'})
# 检查请求是否成功
if response.status_code == 200:
# 读取响应内容
print("资源更新成功,响应内容为:")
print(response.text)
else:
# 请求失败,打印错误信息
print(f"资源更新失败,状态码:{response.status_code}")
print(response.text)
2. 图片爬取案例
2.1 案例介绍
这个案例通过发送HTTP请求、解析HTML页面、提取图片链接、下载图片并保存到本地等步骤,实现从指定网页爬取图片的功能。
案例使用的爬取网址:http://www.umeituku.com/bizhitupian/fengjingbizhi/
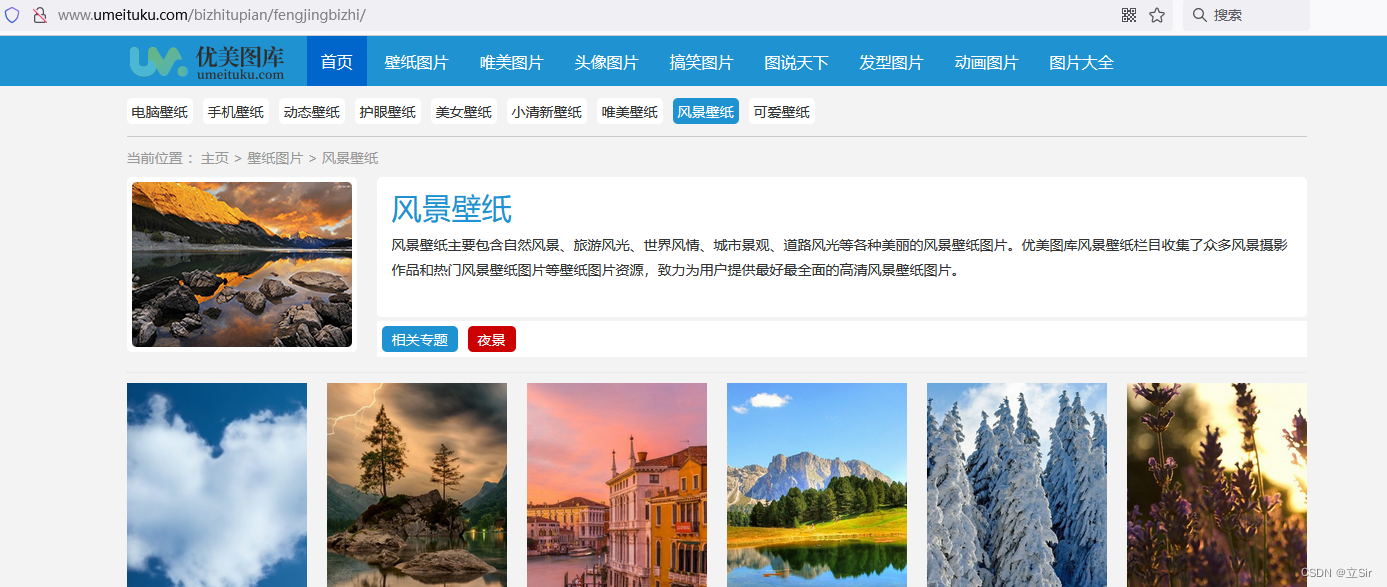
2.2 Python代码
代码如下:
import requests # 发送请求,从服务器获取数据
from bs4 import BeautifulSoup # 解析页面的源代码
n = 1 # 保存图片的计数器
# 发送请求到服务器
url = 'http://www.umeituku.com/bizhitupian/fengjingbizhi/' # 图片网站地址
resp = requests.get(url) # 从服务器拿到网址, 返回响应
resp.encoding = 'utf-8' # 重新编码utf-8
# 解析html--返回页面
main_page = BeautifulSoup(resp.text, 'html.parser')
# 在页面中找标签'div'的TypeList属性
typelist = main_page.find('div', attrs={'class':'TypeList'})
alst = typelist.find_all('a', attrs={'class':'TypeBigPics'}) # 所有的图片链接
# 从标签中获取每张图片的链接
for a in alst:
href = a.get('href') # 发送请求到子页面,进入图片页面
resp1 = requests.get(href) # 从服务器拿到网址
resp1.encoding = 'utf-8' # 重新编码utf-8
child_page = BeautifulSoup(resp1.text, 'html.parser') # 源代码解析,获取子页面
# 获取所有图片路径
src_att = child_page.find('div', attrs={'class':'ImageBody'}) # 找到子页面中图片属性
src = src_att.find('img').get('src') # 子页面中找到src图片路径
# 创建文件
f = open('tu%s.jpg'%n, mode='wb') # 写入文件,内容是非文本文件,保存的文件名
# 发送请求到服务器,把图片保存到本地
f.write(requests.get(src).content)
print('完成一次')
n += 1 # 图片计数器
版权归原作者 立Sir 所有, 如有侵权,请联系我们删除。