
Zookeeper+kafka集群部署
需jdk环境
安装包下载地址:Index of /dist/zookeeper
上传到/usr/local
tar -zxf zookeeper-3.4.5-cdh5.5.4.tar.gz
rm -rf zookeeper-3.4.5-cdh5.5.4.tar.gz
进入到zookeeper的安装目录
cd zookeeper-3.4.5-cdh5.5.4/
新建data和logs文件夹
[root@test zookeeper-3.4.5]# mkdir data
[root@test zookeeper-3.4.5]# mkdir logs
复制zoo_sample.cfg文件
cd conf/
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg文件
[root@test zookeeper-3.4.5]# vim conf/zoo.cfg

注释:
tickTime:心跳时间
initLimit:多少个心跳时间内,允许其他server连接并初始化数据
syncLimit:多少个tickTime内,允许follower节点同步
dataDir:存放内存数据文件目录,根据实际环境修改
dataLogDir:存放日志文件目录,根据实际环境修改
clientPort:监听端口,使用默认2181端口
server.x:配置集群主机信息,[hostname]:[通信端口]:[选举端口],根据自己的主机信息修改
maxClientCnxns:最大并发客户端数,用于防止DOS的,设置为0是不加限制
minSessionTimeout:最小的客户端session超时时间(单位是毫秒)
maxSessionTimeout:最大的客户端session超时时间(单位是毫秒)
将本机安装目录,通过scp全部拷贝至另外2台机器。
scp zoo.cfg root@10.1.50.137://usr/local/zookeeper-3.4.5/conf
scp zoo.cfg root@10.1.50.138://usr/local/zookeeper-3.4.5/conf
在三台服务器的zookeeper安装目录下的data文件夹下面新建文件myid, 分别输入数字1、2、3,对应上面配置文件的server后面的数字
vim myid

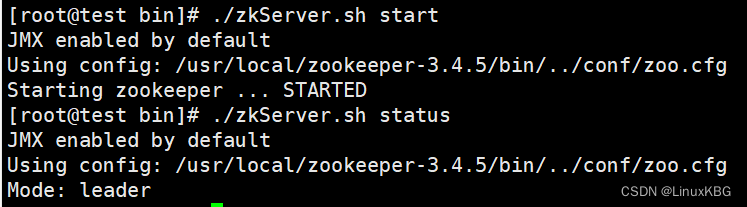
Zookeeper的启动停止 (要三台都启动才行!!!!),分别进入三台服务器的zookeeper安装目录!!!!!!!!!!,输入命令bin/zkServer.sh start 启动Zookeeper服务,查看状态命令:
bin/zkServer.sh start
./zkServer.sh status


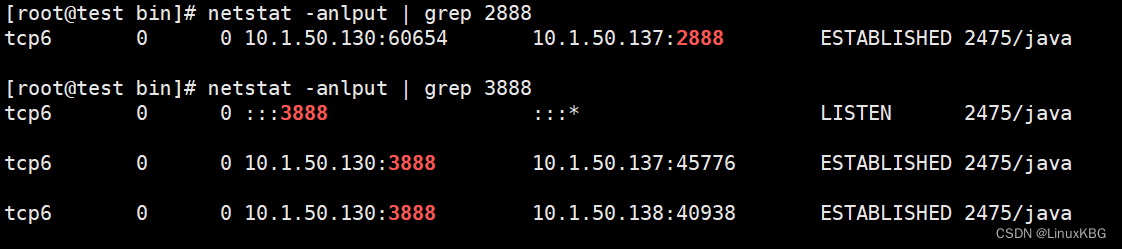
进入节点,执行命令为:
./zkCli.sh -server 10.1.50.130:2181 回车
ls / (查看当前 ZooKeeper 中所包含的内容,输入命令quit 退出Zookeeper服务)
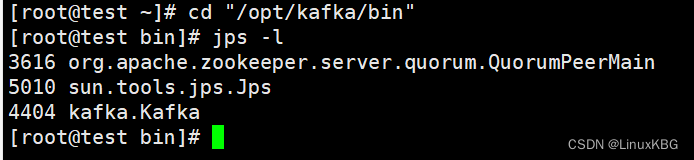
启动zookeeper服务后可以通过jps -l 命令查看zookeeper进程,进程名为QuorumPeerMai
在zookeeper安装目录下输入命令 bin/zkServer.sh status 各个节点的状态
如果需要停止zookeeper服务,则在zookeeper安装目录上输入命令 bin/zkServer.sh stop
部署kafka
下载地址:Apache Kafka
不要下载src包,需编译,直接下载tgz包

长传安装包至node-1节点
解压:
tar -zxvf kafka_2.12-3.2.3.tgz -C /opt
重命名:
mv /opt/kafka_2.12-3.2.3/ /opt/kafka
修改配置文件server.properties
vim /opt/kafka/config/server.properties


可用一下配置覆盖:
当前机器在集群中的唯一标识,和zookeeper的myid性质一样
broker.id=1
套接字服务器监听的地址。如果没有配置,主机名将等于的值
listeners=PLAINTEXT://192.168.1.101:9092
当前kafka对外提供服务的端口默认是9092
port=9092
这个是borker进行网络处理的线程数
num.network.threads=3
这个是borker进行I/O处理的线程数
num.io.threads=8
发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
socket.request.max.bytes=104857600
消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
log.dirs=/opt/kafka/log/kafka-logs
默认的分区数,一个topic默认1个分区数
num.partitions=1
每个数据目录用来日志恢复的线程数目
num.recovery.threads.per.data.dir=1
默认消息的最大持久化时间,168小时,7天
log.retention.hours=168
这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.segment.bytes=1073741824
每隔300000毫秒去检查上面配置的log失效时间
log.retention.check.interval.ms=300000
是否启用log压缩,一般不用启用,启用的话可以提高性能
log.cleaner.enable=false
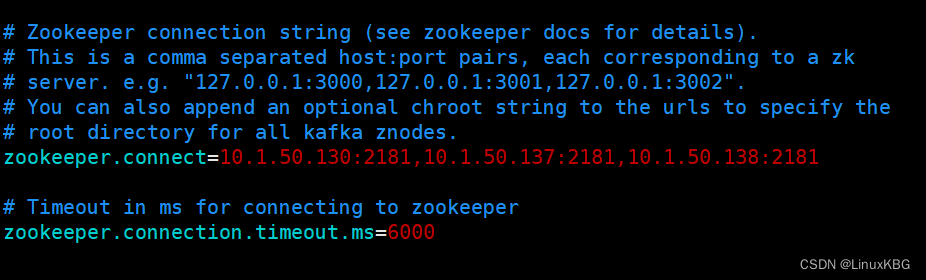
设置zookeeper的连接端口
zookeeper.connect=192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181
设置zookeeper的连接超时时间
zookeeper.connection.timeout.ms=6000
创建server.properties配置文件中的日志存放目录:
mkdir -p /opt/kafka/log
修改producer.properties配置文件
[root@test kafka]# vim /opt/kafka/config/producer.properties
末行加入:
metadata.broker.list=10.1.50.130:2181,10.1.50.137:2181,10.1.50.138:2181

修改consumer.properties配置文件
[root@test kafka]# vim /opt/kafka/config/consumer.properties
末行加入:
zookeeper.connect=10.1.50.130:2181,10.1.50.137:2181,10.1.50.138:2181

各节点添加环境变量:
vim /etc/profile
末行加入:
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$KAFKA_HOME/bin

重载配置文件:
source /etc/profile
分发文件至node002与node001节点
[root@test config]# scp -r /opt/kafka root@10.1.50.137:/opt
[root@test config]# scp -r /opt/kafka root@10.1.50.138:/opt/
修改node002与node003的server.properties配置文件
将node002中server.properties的broker.id修改为2
将node003中server.properties的broker.id修改为3
将node002中server.properties的listeners修改为10.1.50.137:9092
将node003中server.properties的listeners修改为10.1.50.138:9092
各节点启动kafka服务,进入kafka服务/bin目录下执行:
kafka-server-start.sh /opt/kafka/config/server.properties
后台启动:
kafka-server-start.sh -daemon /opt/kafka/config/server.properties
查看:

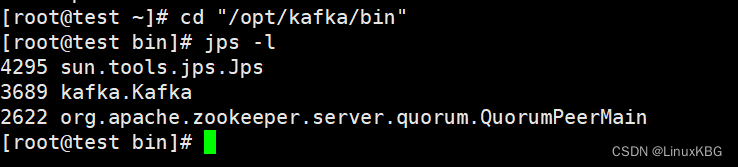

Kafka设置密码
- 停止kafka服务
kafka-server-stop.sh
- 修改kafka配置文件 server.properties
添加如下配置
#使用的认证协议
security.inter.broker.protocol=SASL_PLAINTEXT
#SASL机制
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
#完成身份验证的类
authorizer.class.name=kafka.security.authorizer.AclAuthorizer
#如果没有找到ACL(访问控制列表)配置,则允许任何操作。
allow.everyone.if.no.acl.found=false
#需要开启设置超级管理员,设置admin用户为超级管理员
super.users=User:admin
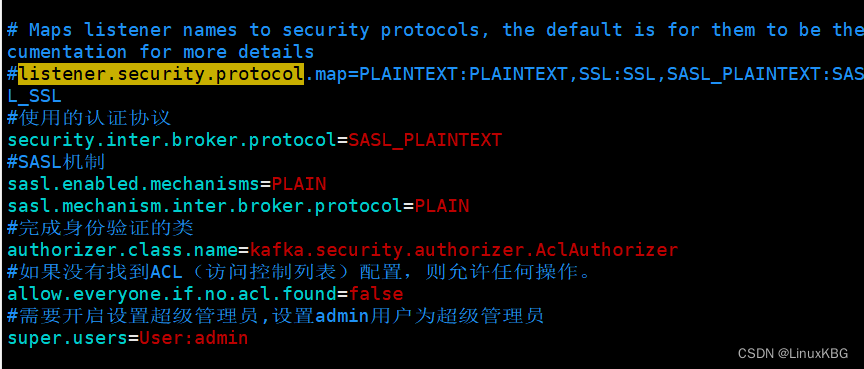
- 添加认证后
此处配置修改添加SASL协议
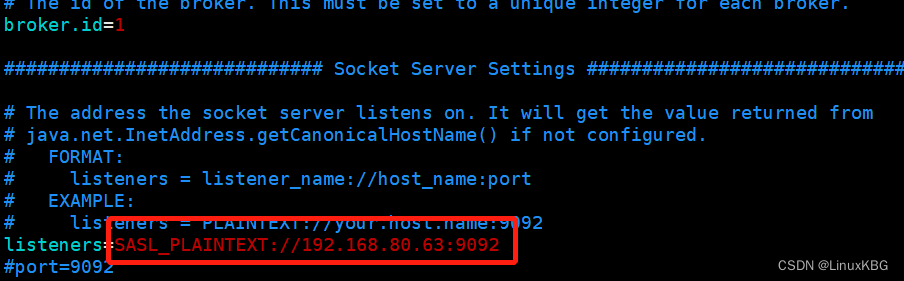
- 添加SASL配置文件
vim config/kafka_server_jaas.conf
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin@123"
user_admin="admin@123";
};
以下为例,测试部署不做客户端操作
#########
客户端若配置登录认证
vim config/kafka_client_jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin@123";
};
说明: 这里配置用户名和密码需要和服务端配置的账号密码保持一致,这里配置了admin这个用户
添加kafka-console-consumer.sh认证文件路径,后面启动消费者测试时使用
vim /opt/kafka/bin/kafka-console-consumer.sh ,找到 “KAFKA_HEAP_OPTS”,添加以下参数:
-Djava.security.auth.login.config=/opt/kafka/kafka_client_jaas.conf

#######
- vim /opt/kafka/bin/kafka-server-start.sh ,找到 export KAFKA_HEAP_OPTS , 添加jvm 参数为kafka_server_jaas.conf文件,加入一行:
-Djava.security.auth.login.config=/opt/kafka/config/kafka_server_jaas.conf

- 启动kafka
各节点启动kafka服务,进入kafka服务/bin目录下执行:
kafka-server-start.sh /opt/kafka/config/server.properties
后台启动:
kafka-server-start.sh -daemon /opt/kafka/config/server.properties
版权归原作者 LinuxKBG 所有, 如有侵权,请联系我们删除。