
一、GaussDB数据库语法入门
之前我们讲了如何连接数据库实例,那连接数据库后如何使用数据库呢?那么我们今天就带大家了解一下GaussDB,以下简称GaussDB的基本语法。
关于如何连接数据库,请戳这里。
学习本节课程之后,您将可以完成创建数据库、创建表及向表中插入数据和查询表中数据等操作。
1、前提条件
• GaussDB实例正常运行。
• 已通过DAS或gsql连接数据库实例。
2、操作步骤
通过DAS或gsql连接数据库实例。
创建数据库用户。
默认只有创建实例时的管理员用户可以访问初始数据库,您还可以手动创建其他数据库用户帐号。
postgres=# CREATE USER joe WITH PASSWORD "xxxxxxxx";
xxxxxxxx需要替换为指定的密码,当结果显示为如下信息,则表示创建成功。
CREATE ROLE
如上创建了一个用户名为joe,密码为xxxxxxxxx的用户。
如下命令为设置joe用户为系统管理员。
postgres=# GRANT ALL PRIVILEGES TO joe;
使用GRANT命令进行相关权限设置,具体操作请参考GRANT。
** 引申信息:**GaussDB对于用户可以进行灵活的权限控制,想要了解请戳管理用户及权限。
- 创建数据库。
postgres=# CREATE DATABASE db_tpcds;
当结果显示为如下信息,则表示创建成功。
CREATE DATABASE
创建完db_tpcds数据库后,就可以按如下方法退出postgres数据库,使用新用户连接到此数据库执行接下来的创建表等操作。当然,也可以选择继续在默认的postgres数据库下做后续的体验。
postgres=# \q
gsql -d db_tpcds -p 8000 -U joe
Password for user joe:
gsql compiled at 2020-05-08 02:59:43 commit 2143 last mr 131)
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
db_tpcds=>
创建表。
创建一个名称为mytable,只有一列的表。字段名为firstcol,字段类型为integer。
db_tpcds=> CREATE TABLE mytable (firstcol int);
未使用“DISTRIBUTE BY”指定分布列时,系统默认会指定第一列为哈希分布列,且给出提示。系统返回信息以“CREATE TABLE”结束,表示创建表成功。
NOTICE: The 'DISTRIBUTE BY' clause is not specified. Using 'firstcol' as the distribution column by default.
HINT: Please use 'DISTRIBUTE BY' clause to specify suitable data distribution column.
CREATE TABLE
向表中插入数据:
db_tpcds=> INSERT INTO mytable values (100);
当结果显示为如下信息,则表示插入数据成功。
INSERT 0 1
查看表中数据:
db_tpcds=> SELECT * from mytable;
firstcol
----------
100
(1 row)
**引申信息:**
- 默认情况下,新的数据库对象是创建在“$user”模式下的,例如刚刚新建的表。关于模式的更多信息请参考创建和管理schema。
- 关于创建表的更多信息请参见创建和管理表。
- 除了创建的表以外,数据库还包含很多系统表。这些系统表包含集群安装信息以及GaussDB上运行的各种查询和进程的信息。可以通过查询系统表来收集有关数据库的信息。请参见查看系统表。
二、GaussDB数据库gsql入门
gsql是GaussDB提供在命令行下运行的数据库连接工具,可以通过此工具连接服务器并对其进行操作和维护,除了具备操作数据库的基本功能,gsql还提供了若干高级特性,便于用户使用。
1、基本功能
- 连接数据库:可以通过gsql远程连接数据库实例。如何使用gsql连接数据库请参考连接实例。
- 执行SQL语句:支持交互式地键入并执行SQL语句,也可以执行一个文件中指定的SQL语句。
- 执行元命令:元命令可以帮助管理员查看数据库对象的信息、查询缓存区信息、格式化SQL输出结果,以及连接到新的数据库等。
2、使用指导
步骤 1 使用gsql连接到GaussDB实例。
gsql工具使用-d参数指定目标数据库名、-U参数指定数据库用户名、-h参数指定主机名、-p参数指定端口号信息。
若未指定数据库名称,则使用初始化时默认生成的数据库名称;若未指定数据库用户名,则默认使用当前操作系统用户作为数据库用户名;当某个值没有前面的参数(-d、-U等)时,若连接的命令中没有指定数据库名(-d)则该参数会被解释成数据库名;如果已经指定数据库名(-d)而没有指定数据库用户名(-U)时,该参数则会被解释成数据库用户名。
示例,使用jack用户连接到远程主机postgres数据库的8000端口。
gsql -h 10.180.123.163 -d postgres -U jack -p 8000
详细的gsql参数请参见命令参考。
步骤 2 执行SQL语句。
以创建数据库human_staff为例。
CREATE DATABASE human_staff;
CREATE DATABASE
通常,输入的命令行在遇到分号的时候结束。如果输入的命令行没有错误,结果就会输出到屏幕上。
步骤 3 执行gsql元命令。
以列出GaussDB中所有的数据库和描述信息为例。
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
----------------+----------+-----------+---------+-------+-----------------------
human_resource | root | SQL_ASCII | C | C |
postgres | root | SQL_ASCII | C | C |
template0 | root | SQL_ASCII | C | C | =c/root +
| | | | | root=CTc/root
template1 | root | SQL_ASCII | C | C | =c/root +
| | | | | root=CTc/root
human_staff | root | SQL_ASCII | C | C |
(5 rows)
更多gsql元命令请参见元命令参考。
3、示例
以把一个查询分成多行输入为例。注意提示符的变化:
postgres=# CREATE TABLE HR.areaS(
postgres(# area_ID NUMBER,
postgres(# area_NAME VARCHAR2(25)
postgres-# )tablespace EXAMPLE;
CREATE TABLE
查看表的定义:
postgres=# \d HR.areaS
Table "hr.areas"
Column | Type | Modifiers
-----------+-----------------------+-----------
area_id | numeric | not null
area_name | character varying(25) |
向HR.areaS表插入四行数据:
postgres=# INSERT INTO HR.areaS (area_ID, area_NAME) VALUES (1, 'Europe');
INSERT 0 1
postgres=# INSERT INTO HR.areaS (area_ID, area_NAME) VALUES (2, 'Americas');
INSERT 0 1
postgres=# INSERT INTO HR.areaS (area_ID, area_NAME) VALUES (3, 'Asia');
INSERT 0 1
postgres=# INSERT INTO HR.areaS (area_ID, area_NAME) VALUES (4, 'Middle East and Africa');
INSERT 0 1
切换提示符:
postgres=# \set PROMPT1 '%n@%m %~%R%#'
root@[local] postgres=#
查看表:
root@[local] postgres=#SELECT * FROM HR.areaS;
area_id | area_name
---------+------------------------
1 | Europe
4 | Middle East and Africa
2 | Americas
3 | Asia
(4 rows)
可以用\pset命令以不同的方法显示表:
root@[local] postgres=#\pset border 2
Border style is 2.
root@[local] postgres=#SELECT * FROM HR.areaS;
+---------+------------------------+
| area_id | area_name |
+---------+------------------------+
| 1 | Europe |
| 2 | Americas |
| 3 | Asia |
| 4 | Middle East and Africa |
+---------+------------------------+
(4 rows)
root@[local] postgres=#\pset border 0
Border style is 0.
root@[local] postgres=#SELECT * FROM HR.areaS;
area_id area_name
------- ----------------------
1 Europe
2 Americas
3 Asia
4 Middle East and Africa
(4 rows)
使用元命令:
root@[local] postgres=#\a \t \x
Output format is unaligned.
Showing only tuples.
Expanded display is on.
root@[local] postgres=#SELECT * FROM HR.areaS;
area_id|2
area_name|Americas
area_id|1
area_name|Europe
area_id|4
area_name|Middle East and Africa
area_id|3
area_name|Asia
三、总结
云数据库 GaussDB各特性版本的功能发布和对应的文档动态,欢迎体验。

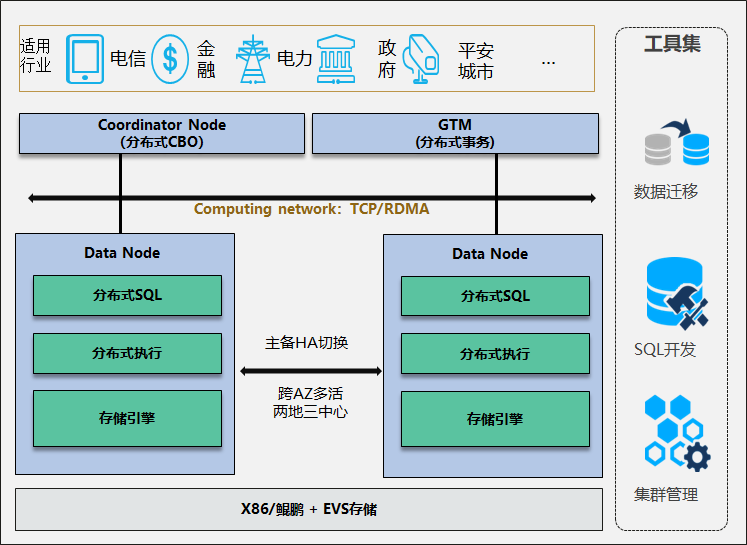
GaussDB是华为公司倾力打造的自研企业级分布式关系型数据库,该产品支持优异的分布式事务,同城跨AZ部署,数据0丢失,支持1000+扩展能力,PB级海量存储等企业级数据库特性。拥有云上高可用,高可靠,高安全,弹性伸缩,一键部署,快速备份恢复,监控告警等关键能力,能为企业提供功能全面,稳定可靠,扩展性强,性能优越的企业级数据库服务。
今天就为大家介绍到这里啦,欢迎交流~
版权归原作者 Gauss松鼠会 所有, 如有侵权,请联系我们删除。