
文章目录
零、IDEA的scala环境配置
【IDEA的scala环境配置】
安装scala 插件
打开菜单 [File] → [Settings] → [Plugins],搜索scala,点击[install]
给项目添加scala模块
右键 [项目] → [Add Frameworks Support] → [Scala] → [Create],选择scala的sdk
在源文件目录创建scala目录
右键 [src源目录] → [New] → [Directory],新建scala目录
将scala目录转换成源目录
右键 [scala目录] → [Mark Directory as] → [Sources Root]
简单说:
(1)新建项目,选择scala项目,并且选择对应的java JDK和scala SDK
(2)新建scala文件,scala类是以
object
区分的,所以新建类时要建立object类型
测试下:
object HelloScala {def main(args: Array[String]):Unit={
println("Hello Scala")}}
结果如下: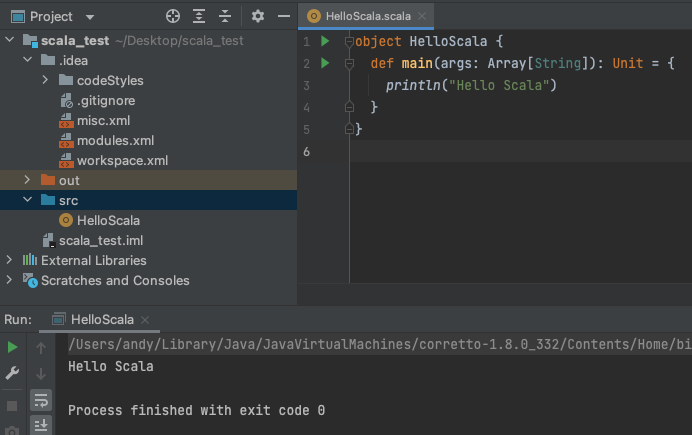
0.1 spark和scala之间的关系
- Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
- Spark本身就是使用Scala语言开发的,spark和flink的底层通讯都是基于的高并发架构akka开发,然而akka是用scala开发的,Scala与Spark可以实现无缝结合,因此Scala顺理成章地成为了开发Spark应用的首选语言
- 在IDEA中开发Spark,可以使用两种方式环境方式: - 一是使用本地Scala库,建立Scala项目,导入Spark jar包。- 一种是通过Maven引入Scala、Spark依赖。我们本次使用Maven的方式,符合Java开发者的习惯于行业规范。
先简单了解下scala的语言特性和项目建立:
- Scala源文件以 “.scala" 为扩展名。
- Scala程序的执行入口是main()函数。
- Scala语言严格区分大小写。
- Scala方法由一条条语句构成,每个语句后不需要分号(Scala语言会在每行后自动加分号),这也体现出Scala的简洁性。
- 如果在同一行有多条语句,除了最后一条语句不需要分号,其它语句需要分号
0.2 编写项目
(0)创建项目
(1)通过maven创建项目:File->New->Project,选择Maven
(2)输入项目的名字,设置想要的GroupId,当然也可以不设置,然后Finish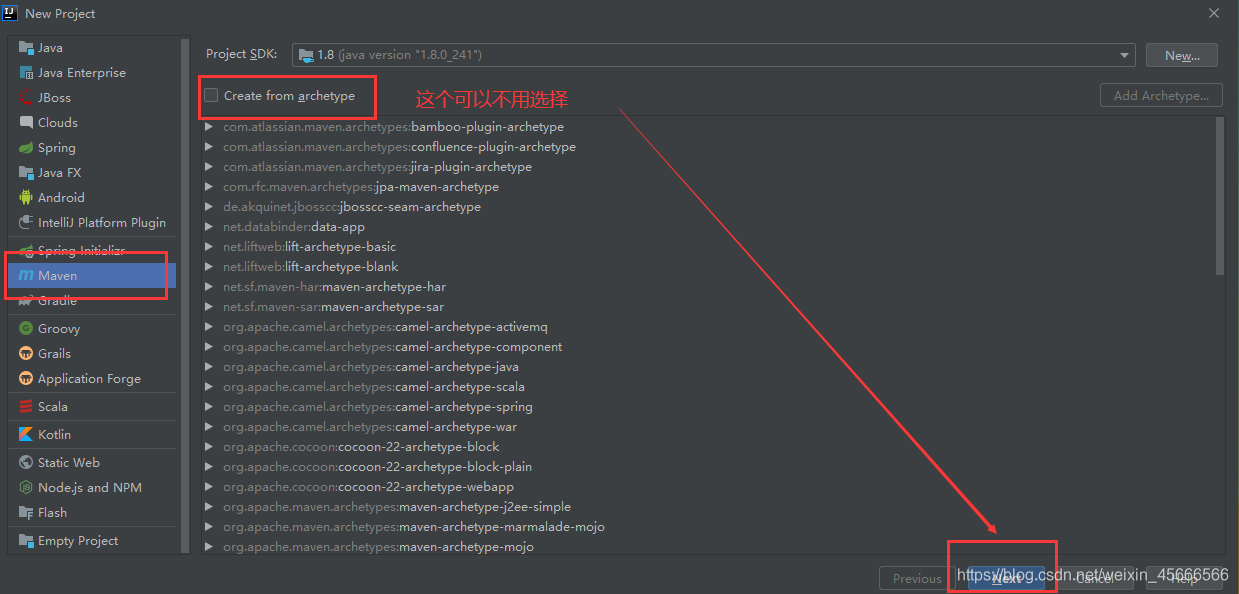
创建完出来是这样的: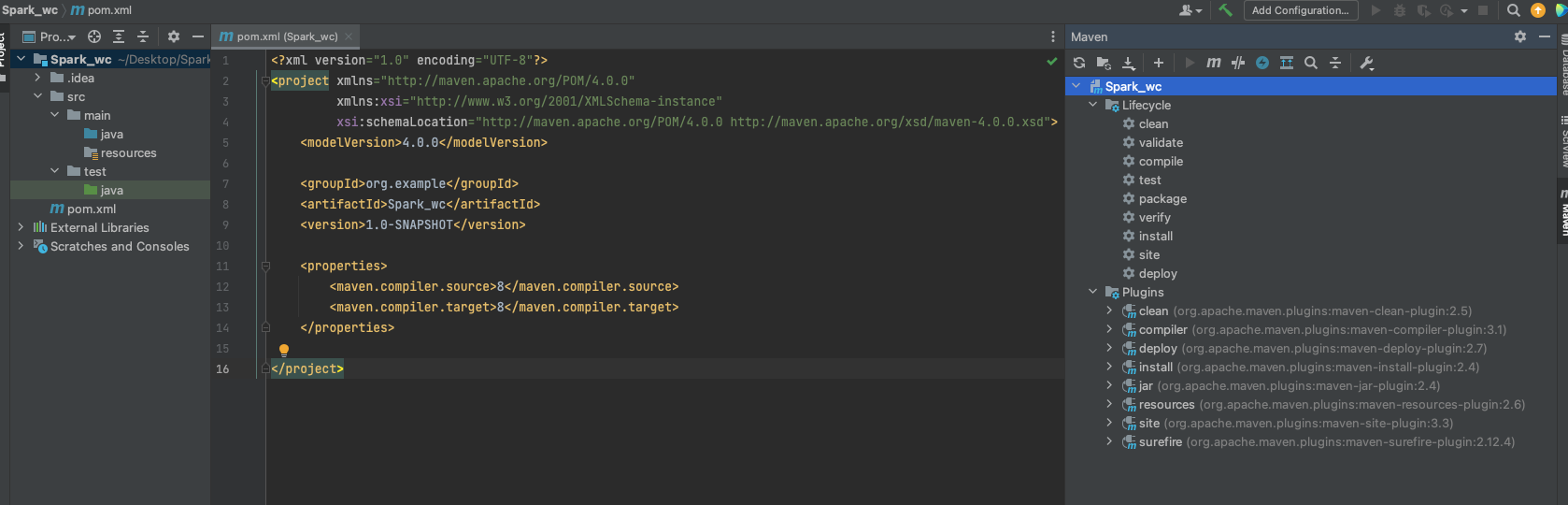
默认的pom.xml文件内容:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>Spark_wc</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties></project>
(3)设置Maven配置指向: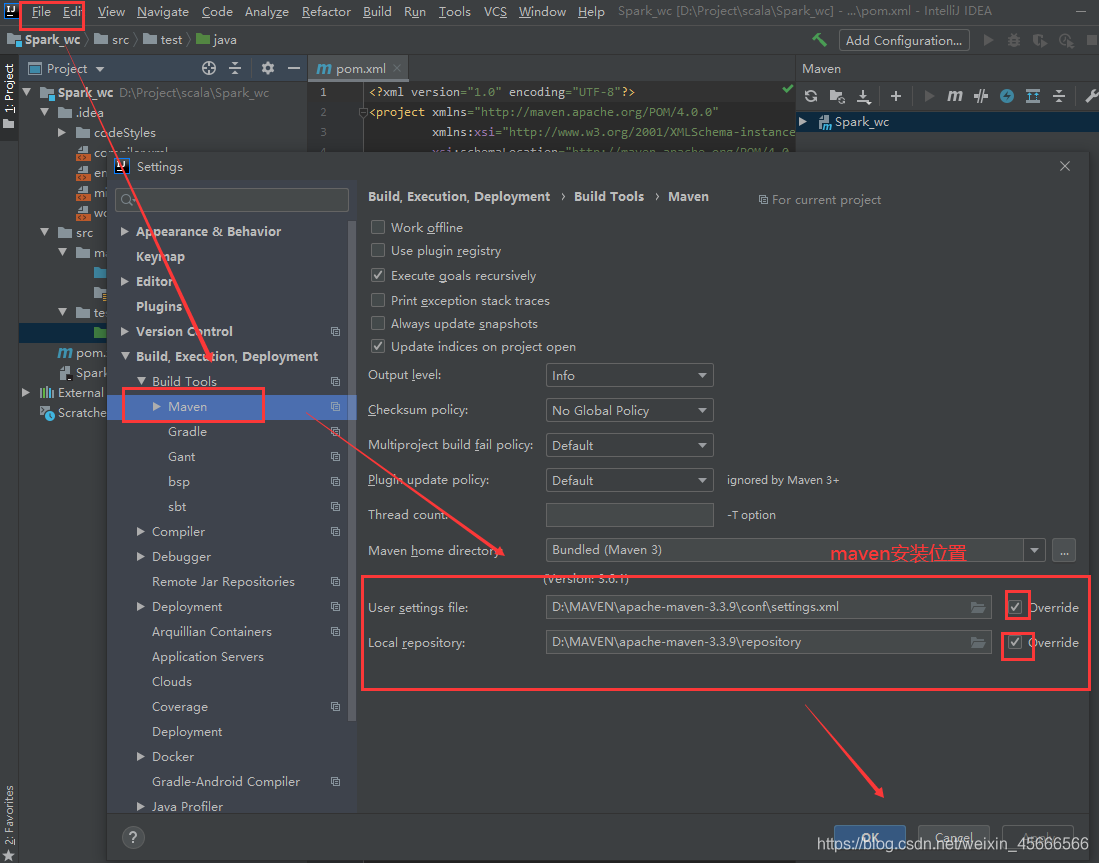
(4)Global Libaries 添加Scala SDK:File->Project Structure->Global Libaries,添加Scala-sdk。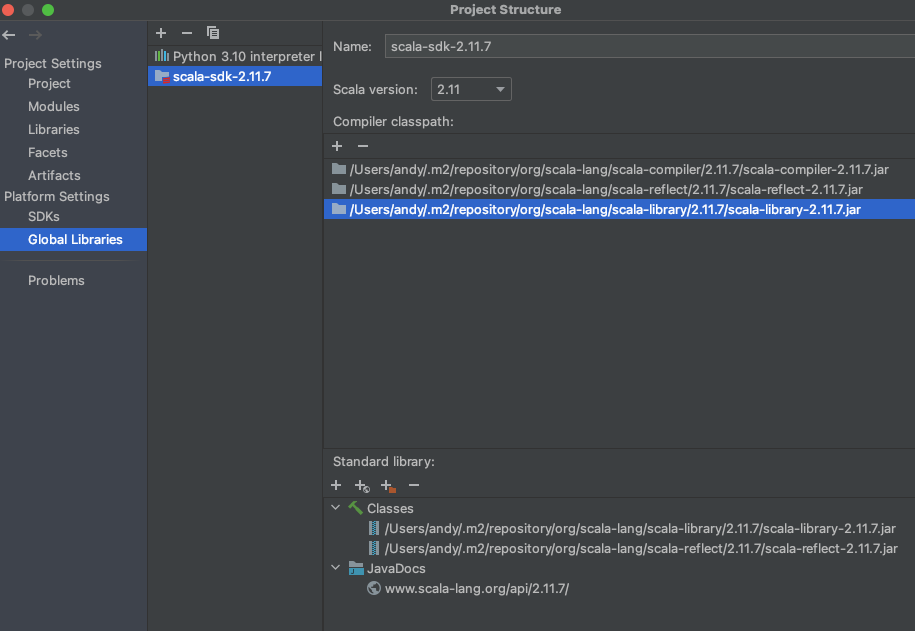
(5)Libaries添加Scala SDK:为了支持scala编程。最简单的方法:右键项目,在弹出的菜单中,选择Add Framework Surport ,在左侧有一排可勾选项,找到scala,勾选即可。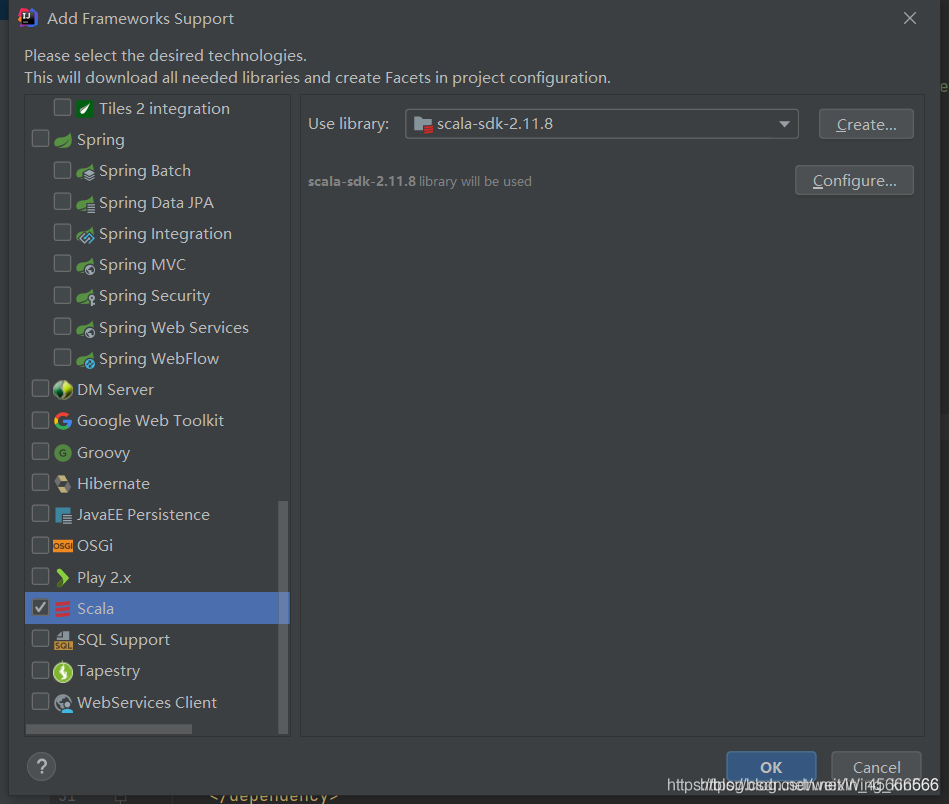
(1)配置pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>spark-demo</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.4</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.4.4</version></dependency></dependencies></project>
(2)配置对应环境
在刚才创建项目时已经有加入java的JDK了(注意JDK的版本):
可以在project structure中查看global libraries选择scala SDK:
(3)测试代码
在main文件夹里新建一个java目录文件: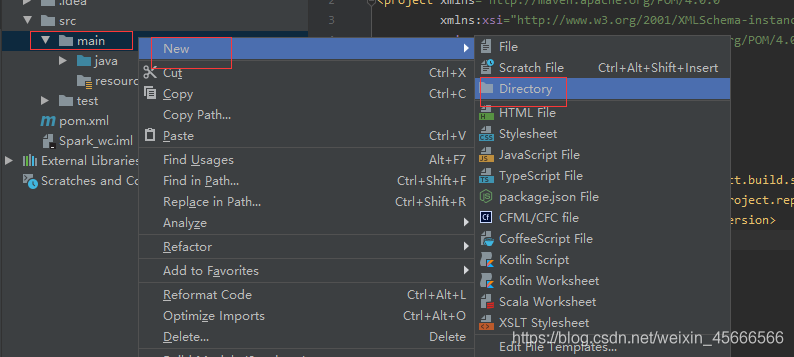

这里展示一个经典的统计词频代码:
packagecom.sparkimportorg.apache.spark.rdd.RDD
importorg.apache.spark.{SparkConf, SparkContext}object Demo_0703 {def main(args: Array[String]):Unit={val sc =new SparkContext(new SparkConf().setMaster("local[*]").setAppName("wc"))val rdd: RDD[String]= sc.makeRDD(List("spark hello","hive","hadoop hbase","spark hadoop","hbase"))// reduceBykeydef wordCount1(rdd: RDD[String]):Unit={// 扁平化操作,拆分出数据val value: RDD[String]= rdd.flatMap(_.split(" "))// map转换为(key,1)val mapRDD: RDD[(String,Int)]= value.map((_,1))// reduceByKey根据key进行聚合val result: RDD[(String,Int)]= mapRDD.reduceByKey(_ + _)
result.collect().foreach(println)}
wordCount1(rdd)
sc.stop()}}
(4)控制台出去日志信息
为了在(3)运行后控制台不出现这么多红色的
INFO
日志信息,可以在项目中的
resources
目录中创建
log4j.properties
,添加日志配置信息:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss}%p %c{1}:%m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the# log level for this class is used to overwrite the root logger's log level, so that# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
(5)注意事项
ps:正运行环境的代码应该都是在resource里面。
mark directory为sources root的作用:
- 源根(或源文件夹):通过为此类别分配文件夹,您可以告诉IDE编译器此文件夹及其子文件夹包含应作为构建过程的一部分进行编译的源代码。
- 测试源根(或测试源文件夹;显示为rootTest):这些根类似于源根,但是用于测试的代码(例如用于单元测试)。 - 通过测试源文件夹,可以将与测试相关的代码与生产代码分开。- 通常,源和测试源的编译结果放在不同的文件夹中。
- 资源根源 - 适用于您的应用程序中使用的资源文件(图像,各种配置XML和属性文件等)。- 在构建过程中,资源文件夹的所有内容将按原样复制到输出文件夹。- 与源类似,可以指定生成资源。还可以指定应将资源复制到的输出文件夹中的哪个文件夹加入。- 通过加入Sources Root,整个文件夹就编译为项目文件,子级就可以直接导入父级中的py文件
0.3 IDEA中切换python环境
既然谈到IDEA,如果要像pycharm切换python的虚拟环境,则需要在project structure中进行更改: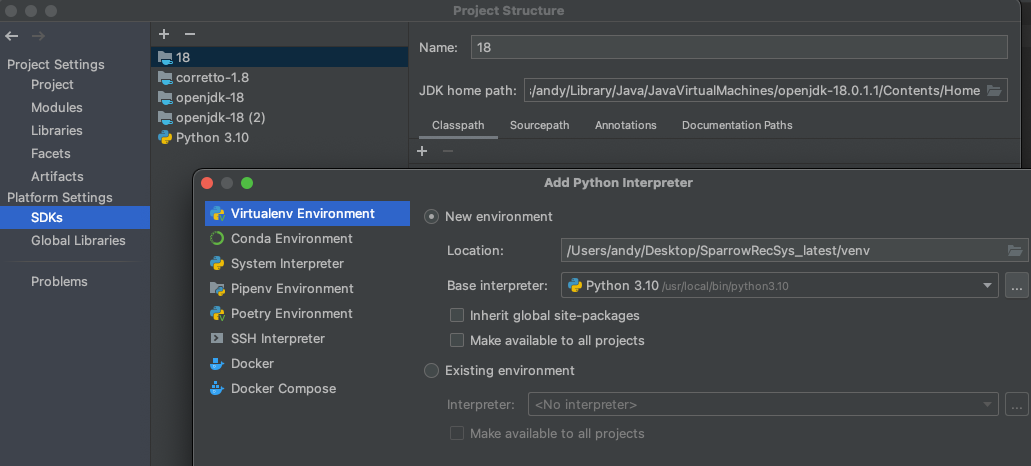
一、scala特点
Spark支持使用Scala、Java、Python和R语言进行编程。由于Spark采用Scala语言进行开发,因此,建议采用Scala语言进行Spark应用程序的编写。Scala是一门现代的多范式编程语言,平滑地集成了面向对象和函数式语言的特性,旨在以简练、优雅的方式来表达常用编程模式。Scala语言的名称来自于“可伸展的语言”,从写个小脚本到建立个大系统的编程任务均可胜任。Scala运行于Java平台(JVM,Java 虚拟机)上,并兼容现有的Java程序。
1.1 面向对象特性
Scala是一种纯面向对象的语言,每个值都是对象。对象的数据类型以及行为由类和特质描述。
类抽象机制的扩展有两种途径(能避免多重继承的种种问题):一种途径是子类继承,另一种途径是灵活的混入机制。
1.2 函数式编程
Scala也是一种函数式语言,其函数也能当成值来使用。Scala提供了轻量级的语法用以定义匿名函数,支持高阶函数,允许嵌套多层函数,并支持柯里化。Scala的case class及其内置的模式匹配相当于函数式编程语言中常用的代数类型。
可以利用Scala的模式匹配,编写类似正则表达式的代码处理XML数据。
1.3 静态类型
Scala具备类型系统,通过编译时检查,保证代码的安全性和一致性。类型系统具体支持以下特性:
- 泛型类
- 协变和逆变
- 标注
- 类型参数的上下限约束
- 把类别和抽象类型作为对象成员
- 复合类型
- 引用自己时显式指定类型视图
- 多态方法
1.4 代码简单测试栗子
右键 [scala目录] → [New] → [Scala Class],新建文件xxx.scala:
/**
* object 单例对象中不可以传参,
* 如果在创建Object时传入参数,那么会自动根据参数的个数去Object中寻找相应的apply方法
*/
object Lesson_ObjectWithParam{// object相当于java的工具类
def apply(s:String)={println("name is "+s)}
def apply(s:String,age:Int)={println("name is "+s+",age = "+age)}
def main(args:Array[String]):Unit={Lesson_ObjectWithParam("zhangsang")Lesson_ObjectWithParam("lisi",18)}}//name is zhangsang//name is lisi,age = 18
二、scala基础语法1
Scala 与 Java 的最大区别是:Scala 语句末尾的分号 ; 是可选的。
scala程序时对象的集合,通过调用彼此的方法来实现消息传递。
字段:每个对象都有它唯一的实例变量集合,即字段。对象的属性通过给字段赋值来创建。
2.1 基本语法
(1)基本规范
- 区分大小写 - Scala是大小写敏感的,这意味着标识Hello 和 hello在Scala中会有不同的含义。
- 类名 - 对于所有的类名的第一个字母要大写。 如果需要使用几个单词来构成一个类的名称,每个单词的第一个字母要大写。 示例:class MyFirstScalaClass
- 方法名称 - 所有的方法名称的第一个字母用小写。 如果若干单词被用于构成方法的名称,则每个单词的第一个字母应大写。
示例:def myMethodName()
- 程序文件名 - 程序文件的名称应该与对象名称完全匹配(新版本不需要了,但建议保留这种习惯)。 保存文件时,应该保存它使用的对象名称(记住Scala是区分大小写),并追加".scala"为文件扩展名。 (如果文件名和对象名称不匹配,程序将无法编译)。 示例: 假设"HelloWorld"是对象的名称。那么该文件应保存为’HelloWorld.scala"
def main(args: Array[String])- Scala程序从main()方法开始处理,这是每一个Scala程序的强制程序入口部分。
(2)scala的数据类型:
数据类型描述Byte8位有符号补码整数。数值区间为 -128 到 127Short16位有符号补码整数。数值区间为 -32768 到 32767Int32位有符号补码整数。数值区间为 -2147483648 到 2147483647Long64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807Float32 位, IEEE 754 标准的单精度浮点数Double64 位 IEEE 754 标准的双精度浮点数Char16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFFString字符序列Booleantrue或falseUnit表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。Nullnull 或空引用NothingNothing类型在Scala的类层级的最底端;它是任何其他类型的子类型。AnyAny是所有其他类的超类AnyRefAnyRef类是Scala里所有引用类(reference class)的基类
PS:使用
var
声明变量,使用
val
声明常量。
(3)scala访问修饰符
(1)private私有成员:如下的第二种
f()
不再类
Inner
中,错误。但是java中允许这两种访问(java允许外部类访问内部类的私有成员)。
class Outer{class Inner{privatedef f(){
println("f")}class InnerMost{
f()// 正确}}(new Inner).f()//错误}
(2)protected保护成员:
- scala对protected成员的访问比java更严格,只允许保护成员在定义了该成员的类的子类中访问;
- 在java中,除了定义了该成员的类的子类可以访问,同一个包里的其他类也可以访问。
packagep{class Super {protecteddef f(){println("f")}}class Sub extends Super {
f()}class Other {(new Super).f()//错误}}
(3)public公共成员:
scala中没有指定修饰符时默认是public,即该成员在任何地方都能被访问。
class Outer {class Inner {def f(){ println("f")}class InnerMost {
f()// 正确}}(new Inner).f()// 正确因为 f() 是 public}
2.2 scala包
(1)包的定义
方法一:和java一样在文件的开头定义包名:
方法二:类似C#:
packagecom.test{class HelloWorld
}
(2)引用
importjava.awt.Color// 引入Colorimportjava.awt._ // 引入包内所有成员
def handler(evt:event.ActionEvent){// java.awt.event.ActionEvent...// 因为引入了java.awt,所以可以省去前面的部分}//如果想引入包中的几个成员,可以使用selector选取器importjava.awt.{Color,Font}// 重命名成员importjava.util.{HashMap=>JavaHashMap}// 隐藏成员importjava.util.{HashMap=> _, _}// 引入了util包的所有成员,但是HashMap被隐藏了
2.3 方法与函数
scala的方法和java类似,方法是类的一部分;而scala的函数则是一个完整的对象,该函数继承了
Trait
的类的对象。一个很简单的加法栗子:
packagecom.spark.wordcountobject Add {def main(args: Array[String]):Unit={
println("Returned value: ", addInt(12,13))}def addInt(a:Int, b:Int):Int={var sum:Int=0
sum = a + b
return sum
}}//(Returned value: ,25)
2.4 其他
(1)字符串的定义:
var greeting:String = "Hello World!";
。
(2)数组,如多维数组,以二维数组举例子:
import Array._
object Test {def main(args: Array[String]){val myMatrix = Array.ofDim[Int](3,3)// 创建矩阵for(i <-0 to 2){for( j <-0 to 2){
myMatrix(i)(j)= j;}}// 打印二维阵列for(i <-0 to 2){for( j <-0 to 2){
print(" "+ myMatrix(i)(j));}
println();}}}//0 1 2//0 1 2//0 1 2
三、scala基础语法2
3.1 scala trait(特征)
trait类似java的接口,但是和接口不同的是,trait还能定义属性和方法的实现。- 一般情况下Scala的类只能够继承单一父类,如果是
trait就可以实现多重继承。 - 下面的栗子是trait特征由
isEqual和isNotEqual方法组成(前者没有定义具体的方法实现,后者有),类似java的抽象类。
trait Equal{
def isEqual(x:Any):Boolean
def isNotEqual(x:Any):Boolean=!isEqual(x)}classPoint(xc:Int, yc:Int)extendsEqual{var x:Int= xc
var y:Int= yc
def isEqual(obj:Any)=
obj.isInstanceOf[Point]&&
obj.asInstanceOf[Point].x == x
}
object Test{
def main(args:Array[String]){
val p1 =newPoint(2,3)
val p2 =newPoint(2,4)
val p3 =newPoint(3,3)println(p1.isNotEqual(p2))println(p1.isNotEqual(p3))println(p1.isNotEqual(2))}}/* false true true */
更多:Scala中trait相关知识和应用
3.2 case class和class区别
- 1、初始化的时候可以不用new,当然也可以加上,普通类一定需要加new
- 默认实现了equals 和hashCode
- 默认是可以序列化的,也就是实现了Serializable
- 自动从scala.Product中继承一些函数
- case class构造函数的参数是public级别的,我们可以直接访问
- 支持模式匹配
3.3 闭包
闭包:访问一个函数里面局部变量的另一个函数。
object Test {def main(args: Array[String]){
println("muliplier(1) value = "+ multiplier(1))
println("muliplier(2) value = "+ multiplier(2))}var factor =3val multiplier =(i:Int)=> i * factor
}//muliplier(1) value = 3 //muliplier(2) value = 6
分析:引入一个自由变量 factor,这个变量定义在函数外面。这样定义的函数变量 multiplier 成为一个"闭包",因为它引用到函数外面定义的变量,定义这个函数的过程是将这个自由变量捕获而构成一个封闭的函数。
3.4 scala集合
- List:特征是其元素以线性方式存储,集合中可以存放重复对象。
- Set
- Map
- Scala元素:不同类型的值的集合
- Option:Option[T] 表示有可能包含值的容器,也可能不包含值。
- Iterator:迭代器
// 定义整型 Listval x = List(1,2,3,4)// 定义 Setval x = Set(1,3,5,7)// 定义 Mapval x = Map("one"->1,"two"->2,"three"->3)// 创建两个不同类型元素的元组val x =(10,"Runoob")// 定义 Optionval x:Option[Int]= Some(5)
Scala 程序使用 Option 非常频繁,在 Java 中使用 null 来表示空值,代码中很多地方都要添加 null 关键字检测,不然很容易出现 NullPointException。因此 Java 程序需要关心那些变量可能是 null,而这些变量出现 null 的可能性很低,但一但出现,很难查出为什么出现 NullPointerException。
Scala 的 Option 类型可以避免这种情况,因此 Scala 应用推荐使用 Option 类型来代表一些可选值。使用 Option 类型,读者一眼就可以看出这种类型的值可能为 None。
附:常见问题
(1)IDEA安装完插件Scala后 通过add frameworks support找到不到scala插件
IDEA安装完插件Scala后 通过add frameworks support找到不到scala插件,不过可能也解决不了。
(2)快速导入头文件
光标移动到需要添加头文件的代码部分,按Alt + enter。
(3)Intellij compile failures: “is already defined as”
可以参考Stack Overflow的问答。
Reference
[1] https://docs.scala-lang.org/getting-started/index.html
[2] scala基础教程
[3] https://www.runoob.com/scala/scala-traits.html
[4] Spark-Mac上IDEA配置Spark开发环境
[5] Idea配置和运行scala
[6] IDEA配置JDK的几种方式
[7] scala——关键字trait的使用
[8] 厦大大数据之Spark入门教程(Scala版)
[9] spark编程00——IDEA创建spark项目
[10] jdk版本的选择(推荐1.8)
[11] 某硅谷spark大数据教学课程
[12] class与case class的区别
[13] 使用集群模式运行Spark程序
[14] scala官方文档:https://docs.scala-lang.org/overviews/scala-book/traits-interfaces.html#extending-a-trait
版权归原作者 山顶夕景 所有, 如有侵权,请联系我们删除。