
在本文中我将介绍强化学习的基本方面,即马尔可夫决策过程。我们将从马尔可夫过程开始,马尔可夫奖励过程,最后是马尔可夫决策过程。

目录
马尔可夫过程
马尔可夫奖励过程
马尔可夫决策过程
马尔可夫过程
马尔可夫决策过程(MDP)代表了一种强化学习的环境。我们假设环境是完全可见的。这意味着我们拥有了当前状态下做出决定所需的所有信息。然而,在我们讨论MDP是什么之前,我们需要知道马尔科夫性质的含义。
马尔可夫性质指出,未来是独立于过去的现在。它意味着当前状态从历史记录中捕获所有相关信息。例如,如果我现在口渴了,我想马上喝一杯。当我决定喝水的时候,这与我昨天或一周前口渴无关(过去的状态)。现在是我做出决定的唯一关键时刻。
鉴于现在,未来独立于过去
除了马尔可夫性质外,我们还建立了一个状态转移矩阵,它存储了从每个当前状态到每个继承状态的所有概率。假设我在工作时有两种状态:工作(实际工作)和观看视频。当我工作时,我有70%的机会继续工作,30%的机会看视频。然而,如果我在工作中看视频,我可能有90%的机会继续看视频,10%的机会回到实际工作中。也就是说,状态转移矩阵定义了从所有状态(工作,观看视频)到所有继承状态(工作,观看视频)的转移概率。
了解了马尔可夫性质和状态转移矩阵之后,让我们继续讨论马尔可夫过程或马尔可夫链。马尔可夫过程是一个无记忆的随机过程,如具有马尔可夫性质的状态序列。
我们可以在下图中看到马尔科夫过程学生活动的一个例子。有几种状态,从class 1到最终状态Sleep。每个圆中的数字表示转移概率。
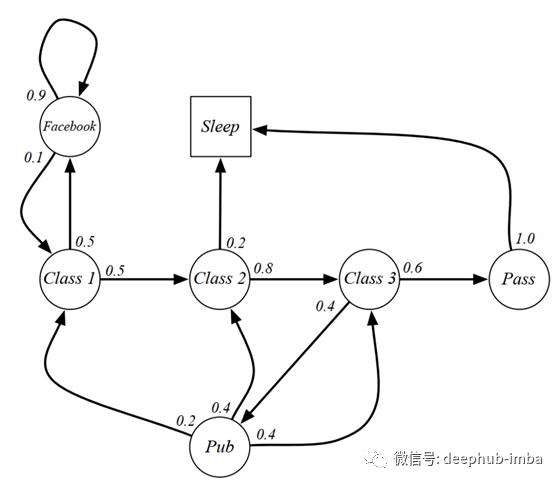
我们可以从class 1到sleep这一过程中获取一些例子:
C1 C2 C3 Pass Sleep,
C1 FB FB C1 C2 Sleep,
C1 C2 C3 Pub C2 C3 Pass Sleep, and so on.
它们三个从相同的状态(class 1)开始,并以睡眠结束。然而,他们经历了不同的路径来达到最终状态。每一次经历都是我们所说的马尔科夫过程。
具有马尔可夫性质的随机状态序列是一个马尔可夫过程
马尔可夫奖励过程
至此,我们终于理解了什么是马尔可夫过程。马尔可夫奖励过程(MRP)是一个有奖励的马尔可夫过程。这很简单,对吧?它由状态、状态转移概率矩阵加上奖励函数和一个折现因子组成。我们现在可以将之前的学生马尔科夫过程更改为学生MRP,并添加奖励,如下图所示。
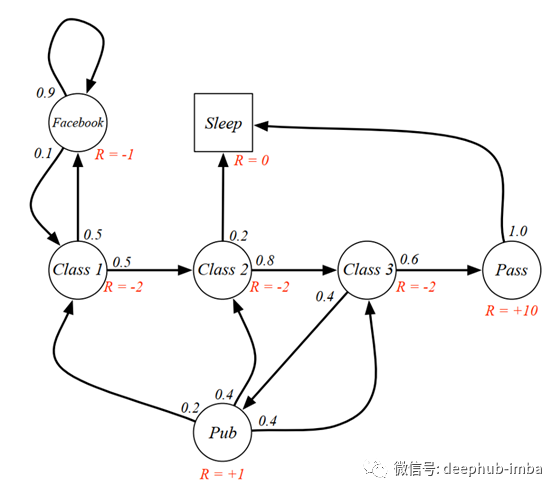
要理解MRP,我们必须了解收益和价值函数。
回报是从现在起的总折扣奖励。折扣因子是未来奖励的现值,其值在0到1之间。当折扣因子接近0时,它倾向于立即奖励而不是延迟奖励。当它接近1时,它将延迟奖励的价值高于立即奖励。
但是,您可能会问“为什么我们要增加折扣系数?”。好吧,出于几个原因需要它。首先,我们希望通过将折扣系数设置为小于1来避免无限的回报。其次,立即获得的回报实际上可能更有价值。第三,人类行为表现出对立即获得奖励的偏好,例如选择现在购物而不是为将来储蓄。
收益(G)可以使用奖励(R)和折扣因子(γ)如下计算。
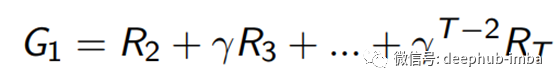
从MRP中,我们可以得到一个从class 1开始的折现系数为0.5的示例收益。样本剧本是[C1 C2 C3 Pass],其收益等于-2 -2 * 0.5 -2 * 0.25 + 10 * 0.125 = -2.25。
除了return之外,我们还有一个value函数,它是一个状态的预期收益。值函数确定状态的值,该值指示状态的可取性。使用Bellman方程,我们可以仅使用当前奖励和下一个状态值来计算当前状态值。
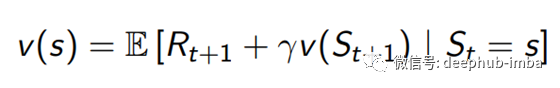
这意味着我们只需要下一个状态即可计算一个状态的总值。换句话说,我们可以拥有一个递归函数,直到处理结束。
让我们再次看一下Gamma等于1的 MRP。下图表示每个状态下都有一个值的MRP。以前已经计算过该值,现在我们要用等式验证3类(红色圆圈)中的值。
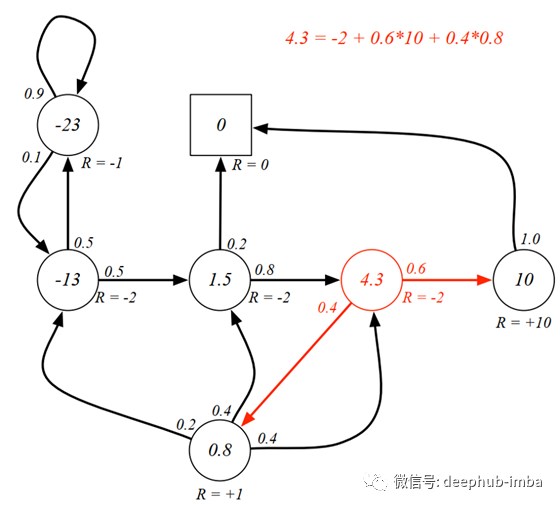
从class3 中我们可以看到,该值是通过将立即回报(-2)与下两个状态的期望值相加来计算的。为了计算下一状态的期望值,我们可以将转移概率与状态的 值相乘。因此,我们得到-2 +0.6* 10 +0.4*0.8等于4.3。
马尔可夫奖励过程是一个具有奖励和价值的马尔可夫过程
马尔可夫决策过程
到目前为止,我们已经了解了马尔可夫奖赏过程。但是,当前状态和下一个状态之间可能没有动作。马尔可夫决策过程(MDP)是具有决策的MRP。现在,我们可以选择几个动作以在状态之间进行转换。
让我们在下图中查看MDP。这里的主要区别在于,在采取行动后会立即获得奖励。在执行MRP时,状态变更后会立即获得奖励。这里的另一个区别是动作也可以导致学生进入不同的状态。根据学生的MDP,如果学生采取Pub动作,则他可以进入class1,class2或class3。
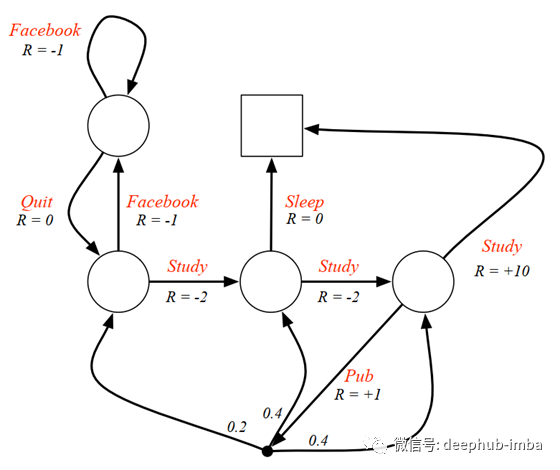
给定这些动作,我们现在有了一个策略,该策略将状态映射到动作。它定义了代理人(在这种情况下是学生)的行为。策略是固定的(与时间无关),它们取决于操作和状态而不是时间步长。
基于策略,我们有一个状态值函数和一个动作值函数。状态值函数是从当前状态开始然后遵循策略的预期收益。另一方面,操作值函数是从当前状态开始,然后执行操作,然后遵循策略的预期收益。
通过使用Bellman方程,我们可以具有状态值函数(v)和动作值函数(q)的递归形式,如下所示。
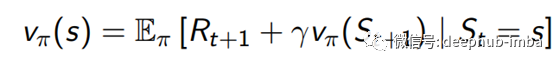
状态值函数
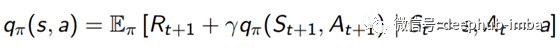
动作值函数
为了使情况更清楚,我们可以在下图中再次查看带有gamma 0.1的 MDP。假设在class3(红色圆圈)中,学生有50:50的政策。这意味着该学生有50%的机会Study或Pub。我们可以通过将每个动作之后的每个预期收益相加来计算状态值。
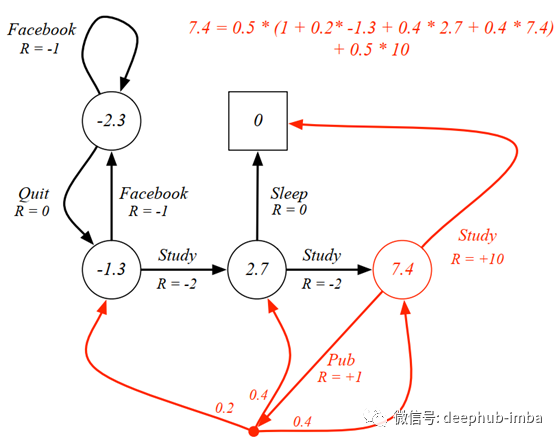
通过将动作概率与下一个状态的期望值(0.5 * 10)相乘,可以计算出Study的期望值。相反,Pub操作具有多个导致不同状态的分支。因此,我们可以通过将动作概率(0.5)乘以动作值,从Pub中计算出期望值。可以通过将即时奖励与来自所有可能状态的期望值相加来计算操作值。可以通过1 + 0.2 * -1.3 + 0.4 * 2.7 + 0.4 * 7.4进行计算。
代理人的目标是最大化其价值。因此,我们必须找到导致最大值的最优值函数。在前面的示例中,我们通过对所有可能的操作的所有期望值求和来计算值。现在,我们只关心提供最大值的动作。在了解了最优值函数之后,我们有了最优策略并求解了MDP。下图显示了针对每个状态的最优值和策略的MDP。
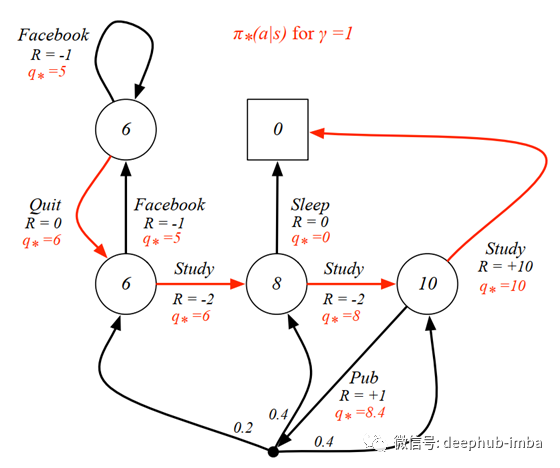
具有最佳政策的学生MDP
结论
总而言之,马尔可夫决策过程是具有动作的马尔可夫奖励过程,在此过程中,代理必须根据最佳价值和政策做出决策。
作者 Alif Ilham Madani
deephub翻译组