
Chatgpt与机器学习如何影响未来AI发展
chatgpt发布于2022年11月30日,距今已过去一年左右,却对我们的学习与生活产生了很多深刻的影响,以下我将发表我的观点与思考。
量变与质变——gpt的原理与发展
chatgpt本身的基本原理并不是非常复杂,通过海量的数据与深度学习的算法相结合,让模型预测每句话的下一个字的出现的概率,这个思想并非这两年刚有,在2018年6月OPENAI的GPT-1就已经开始了这方面的实现,并且在引爆全网的CHATGPT3.5发布之前就已经有了包括谷歌,百度等大厂的各大模型。但之所以openai能够如此火爆,主要是归功于其惊人的回答专业度与准确性,已经达到了以假乱真的地步。但一个18年就有的技术,为什么到2023年才突然异军突
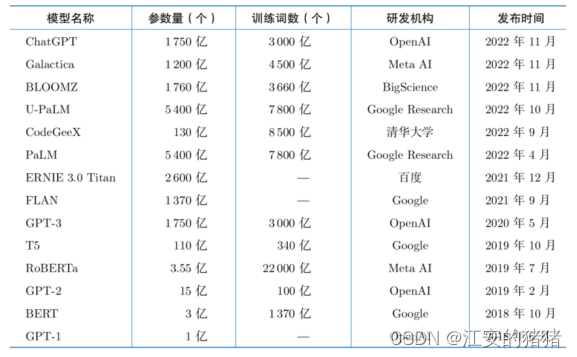
图1-1 chatgpt3.5发布之前大模型时间线
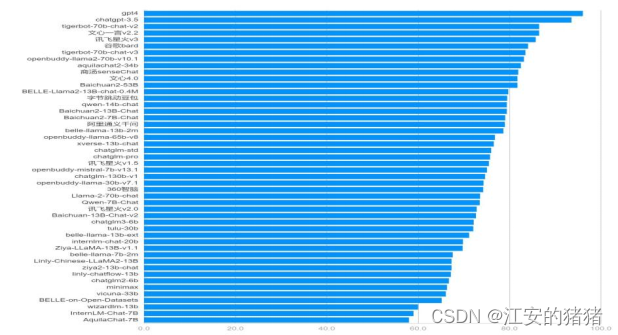
图1-2 各大模型综合能力榜单
起,对我们的生活产生了巨大的变化呢?
第一,大语言模型需要海量的经过整理的数据,这些数据一方面需要人为进行处理,另一方面,需要时间让互联网用户能够产生海量能够进行处理的数据,而这些都需要时间的投入,因此,经过多年的‘养蛊’,最终让gpt得到了令人满意的结果。由图1-3可以看出,
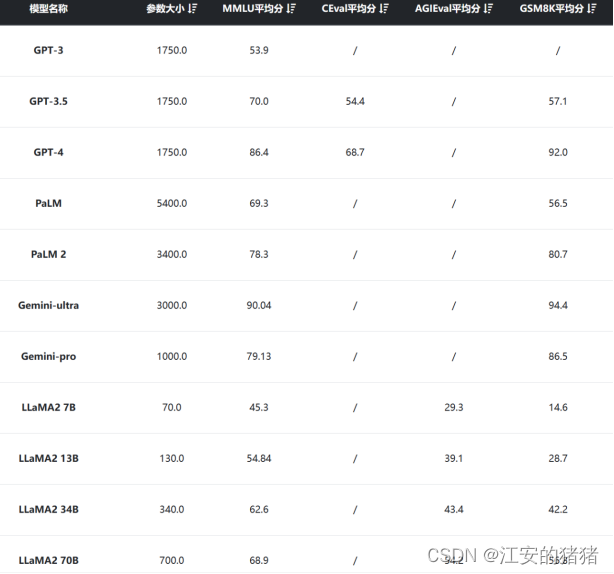
图 1-3目前主流的大模型数据集大小
参数大小是模型准确度高的必要条件,但我也十分佩服openai技术人员的耐心与勇气,因为gpt至今仍然是黑盒,不具有可解释性,因此在结果揭晓之前,谁也不知道质变什么时候会到来,或者是否会到来。
其次,大语言模型的产生需要硬件条件的配合。几个月之前,google开源了llama2模型,我也尝试着在本地和云服务器端对llama2进行部署,最终成功在云服务器进行了成功的部署,但是在本地部署却失败了。经过检查发现,本地部署llama2-7b版本就需要至少28g的内存,而我14000元配置的游戏本都远远不够部署,更不必提技术人员对于大模型的训练所需要的硬件条件了。

图1-4 本地部署llama2的报错信息
最终,在忍痛花费了50元的云服务器上使用A100才正确部署了llama2模型,但很明显,7b相比于gpt3.5 315b的效果还是不尽人意。因此,随着英伟达V100等高性能显卡的发布,才给了gpt发展与成功的坚实土壤。
图1-5 云服务器部署llama2
但是,我们也可以看出,gpt3,gpt3.5,gpt4所用的数据量是一样多的,但是在结果的正确率上却仍然有很大的差距,因此,模型的架构,参数的设置与微调也是大模型取得良好效果的很重要的条件,因此某些厂商吹嘘自己的数据集有几千个亿其实并不是很有说服力。
All in all,我们可以看出,大模型语言在2022年末产生的gpt是量变引起质变,多方面的原因共同铸就的。
一问千金——大预言模型目前的缺陷
虽然大语言模型目前风头正盛,但是仍然面临着很多的问题亟需解决。第一,正如我上文提到的,大模型的训练与运行需要很高的硬件要求

图2-1 部署llama2云服务器配置
并非个人能够承担,因此,大量的训练需要在云服务器进行。这就给相关厂商造成了很高的成本,而目前文心一言等大模型基本都是免费使用,这就需要相关的厂商进行巨量的前期投入抢占蓝海市场。
第二点,我们从gpt的原理可以看出,gpt等都是在已有数据的基础上进行推理与猜测,因此gpt无法给出超出其数据时间的回答,也无法结合当今事物的发展给出回答,gpt的创新能力也因此十分有限,没有可能达到强人工智能的阶段,有多少的“人工”,它就具有多少的智能。
由第二点困难又可以引出的问题是,随着gpt的发展,对数据标注员的要求也越来越高,因为gpt要会的东西。标注员也首先要会。除此之外。虽然随着互联网这么多年的发展以及信息爆炸带来的影响,数据量再多也不是无限,因此,越往后发展,评价模型就越困难,模型的提升也越困难。
最后一点是我国发展大语言模型的困难,我们惊讶的发现,openai团队的核心成员,很大一部分都是华裔科学家,由此也可以看出我国在此方面人员培养方面的缺失,而且在目前的国际竞争中有逐渐恶化的趋势。
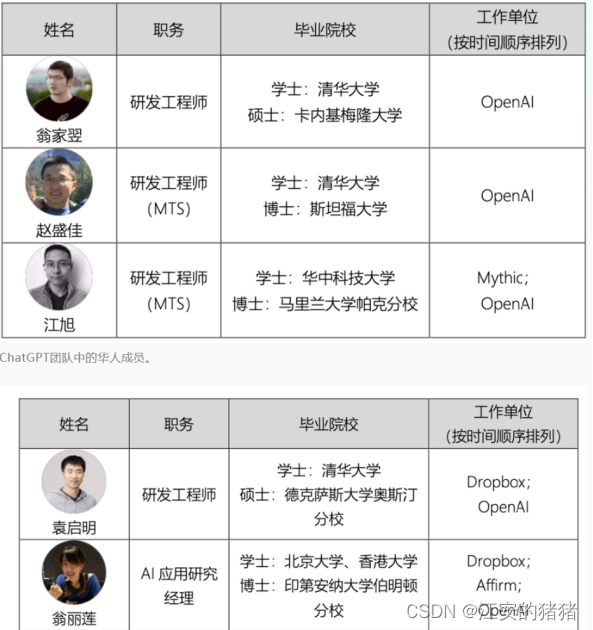
图2-2 openai部分华裔成员名单
此外,随着对于gpt的使用越来越多,人们对于gpt答案的信任也会逐渐加强,倘若有不法的政府或团体希望利用gpt等工具伪造错误答案,影响人们思想,gpt从一个单纯的技术工具或许会变成思想颠覆,洗脑的利剑,我们也需要时刻警惕。值得庆幸的是,目前包括openai在内的公司在相关问题仍然保守这基本的素质,基本都是采取了骑墙策略,谁也不得罪,但是这也不是不值得我们警惕。

图2-3 gpt关于政治敏感问题的回答
应用场景及影响
目前,随着chatgpt版本的不断更新,它已经能够胜任几乎一切重复性的,连篇累牍的重复性工作,例如文书编写,基础程序员的代码编写,等等。虽然目前的语言大模型在逻辑性和正确性方面仍然有待提高,但是我相信这方面能力的修复是必然趋势。毫无疑问的,随着gpt的发展,必然会取代掉一些工作岗位,但是长期来看,我并不认为这一定是一件坏事(呜呜别取代我啊),正如工业革命对于当时手工业者的影响类似,这样反而倒逼人们向更有创造力,更能为社会生产力进步的行业去努力,当然,短期的阵痛肯定是难以避免的,关于这个问题,就不仅仅是学科方面需要解决的了,还需要社会,经济多方面的共同努力,从而将chatgpt这一生产力工具的价值发挥到最大,并且最小化其伤害。
与此同时,对于正处于这个浪潮的我们该怎么做呢?我们最重要需要做的,是改变旧有思想,工业革命与产业革命的例子已经告诉了我们,拒绝跟上历史进程,闭关锁国,结果只能是失败与被超越。我们的思维需要彻底的变革,彻底的转换,我们要做的不是给马车换上最新的汽车发动机,而是要把自己变为汽车,成为大语言模型的掌控者,利用最新的科技工具提高自己的生产力,这样,小从个人,大到国家,才能在一次次的科技浪潮之中永立潮头。
不能光说不干,我们不妨简单利用chatgpt来回答一下这个问题。
Input:
你是一名“大型语言模型替代劳动力评估师”。大型语言模型,是一种用于处理和生成自然语言文本的深度学习模型,最新的大型语言模型能够基于自然语言文本生成、描述创建图像与视频。在这样的背景下,你需要从“该任务是否能够在大语言模型帮助下,在同样时间达成同样产出或者同样效果的前提下,减少人类劳动时间的参与”的角度,给下列每一个任务打分。 评分从0到5分,0代表该任务不能通过大语言模型的帮助减少人类劳动投入,1代表可以减少20%人类劳动投入,2代表可以减少40%的人类劳动投入,3代表可以减少60%的人类劳动投入,4代表可以减少80%的人类劳动投入,5代表可以减少100%的人类劳动投入,即该任务不再需要人类劳动参与。 你的评分,代表着大语言模型可以在每一个任务中节省多少比例的劳动投入,请根据当前大语言模型的进步情况和你认为未来可能的发展状况,谨慎评分。请按照“id,评分”的格式,每一行返回一条任务的评分结果。
Output:

图3-2 chatgpt关于input的回答
为了能够避开chatgpt的防御模式,我并没有采用“替代人类工作”语言,而是强调是“帮助人类减少工作投入”的语言,这也是一种帮助获得理想答案的方法,的我们可以看出,gpt认为可以“帮助人类”的工作大多是重复性的,成长性不高,逻辑性较强的工作。我们也可以看出,为了避免相关的法律争端以及人类敌视,大模型的开发人员将gpt等模型的说话尽可能委婉谦虚,并且足够全面,这也对我们提问方式提出了一定的要求。
未来的发展方向
目前,包括谷歌,百度等大模型语言研发厂商都在努力地将大语言模型与具体的应用相结合,比如谷歌已经将大语言模型与其旗下的word文档,ppt等工具进行了结合,从而能够更好地帮助用户处理相关重复性问题,目前,大语言模型的应用还是一片蓝海,因此世界上各大公司都在日夜不停地改善自己的大语言模型,渴望能抢占一份自己的市场。至于未来大语言模型的发展会何去何从呢,
在短期内,肯定是gpt的数据量不断提高,准确度蒸蒸日上,适应更多的应用场景,至于长期gpt会发展到什么地步,作为大学生的我我也无法做出准确的判断,我只能说,大语言模型在内的工作逐渐深入我们的生活是无法避免的趋势,相比禁止使用它,我们可能需要投入更多的精力去利用这头“猛兽”。不妨,让我用chatgpt的回答来回答这个问题,并结束这个报告吧,希望能有一个更美好的未来!
Input:请问大语言模型未来的发展趋势是怎样的?
Output:

版权归原作者 江安的猪猪 所有, 如有侵权,请联系我们删除。