
目标与背景
本案例的目标是客户价值识别,通过航空公司客户数据识别不同价值的客户。航空公司通常会将客户划分成几种客户,如:重要保持客户、重要发展客户、重要挽留客户、一般客户和低价值客户,识别客户价值应用最广泛的RFM模型是通过3个指标来进行客户细分,识别出高价值的客户(最近一次消费时间间隔(Recency)、
消费频率(Frequency)、消费金额(Monetary))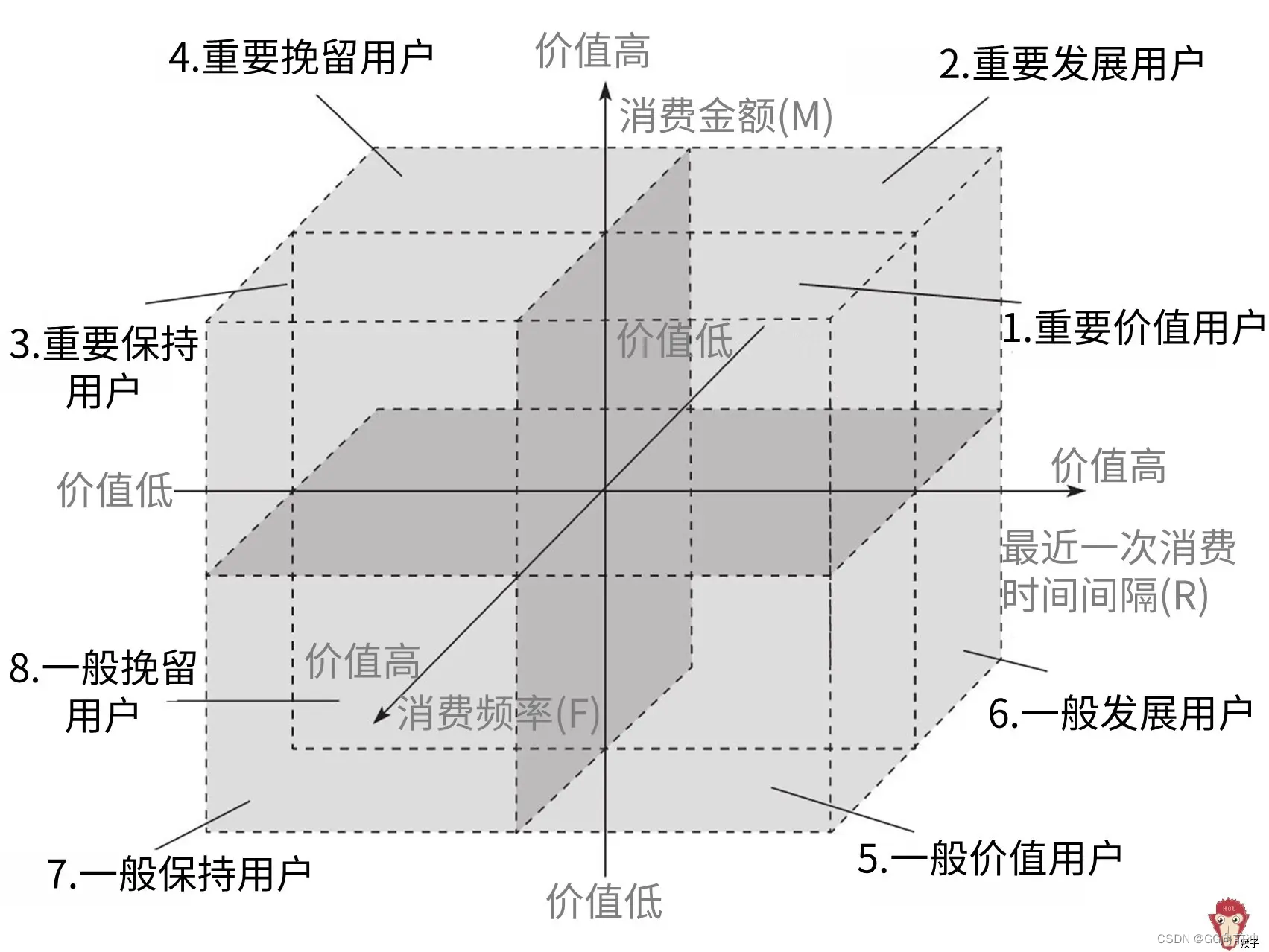
消费金额表示在一段时间内, 客户购买该企业产品金额的总和。
由于航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的
例如,一位购买长航线、低等级舱位票的旅各与一位购买短航线、高等级验位票的旅客相比,后者对于航空公司而言价值可能更高。
因此,这个指标并不适用于航空公司的客户价值分析。
我们选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值两个指标代替消费金额。
此外,考虑航空公司会员人会在时间的长短在定程度上能够影响客户价值,所以在模型中增加客户关系长度L作为区分客户的另一指标。
加粗样式本案例将客户关系长度、消费时间间隔、消费频率、飞行里程和折扣系数的平均值五个指标作为航空公司识别客户价值指标,建立LRFMC模型。
使用Hive对客户数据进行探索分析、数据预处理。
使用K-means对客户进行聚类分群,来实现航空公司利益最大化。
文章目录
一、数据预处理
数据集包含了62988条数据,其中有44个字段,主要字段有客户基本信息(会员卡号,入会时间等)、乘机信息(票价收入,平均折扣率等)、积分信息(积分兑换次数等)。
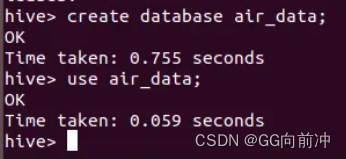
- 首先建立Hive仓库
CREATE DATABASE air_data;USE air_data;
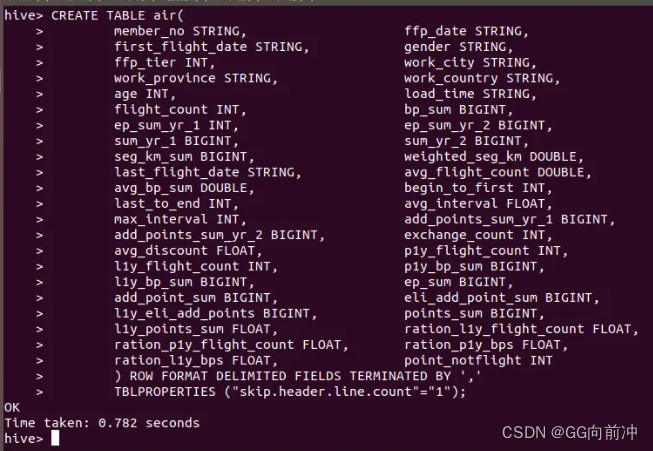
2.建立数据表
CREATE TABLEair(member_no STRING,ffp_date STRING,first_flight_date STRING,gender STRING,ffp_tier INT,work_city STRING,work_province STRING,work_country STRING,age INT,load_time STRING,flight_count INT,bp_sum BIGINT,ep_sum_yr_1 INT,ep_sum_yr_2 BIGINT,sum_yr_1 BIGINT,sum_yr_2 BIGINT,seg_km_sum BIGINT,weighted_seg_km DOUBLE,last_flight_date STRING,avg_flight_count DOUBLE,avg_bp_sum DOUBLE,begin_to_first INT,last_to_end INT,avg_interval FLOAT,max_interval INT,add_points_sum_yr_1 BIGINT,add_points_sum_yr_2 BIGINT,exchange_count INT,avg_discount FLOAT,p1y_flight_count INT,l1y_flight_count INT,p1y_bp_sum BIGINT,l1y_bp_sum BIGINT,ep_sum BIGINT,add_point_sum BIGINT,eli_add_point_sum BIGINT,l1y_eli_add_points BIGINT,points_sum BIGINT,l1y_points_sum FLOAT,ration_l1y_flight_count FLOAT,ration_p1y_flight_count FLOAT,ration_p1y_bps FLOAT,ration_l1y_bps FLOAT,point_notflight INT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','//以,为分隔
TBLPROPERTIES ("skip.header.line.count"="1");//跳过文件的第一行
- 导入数据 根据现实生活世界的业务逻辑,在44个字段中真正能使用到的只有 ffp_date(入会时间) load_time(观测窗口结束时间) flight_count(乘机次数) sum_yr_1(票价收入1) seg_km_sum(飞行里程数) last_flight_date(最后一次乘机时间) avg_discount(平均折扣率) 我们可以剔除其他字段,仅仅保留这些有用的字段
LOAD DATA LOCAL INPATH 'air_data.csv.gz' OVERWRITE INTO TABLE air;//导入本地数据,注意文件路径-- CREATE TABLE air2 AS
--SELECT ffp_date,load_time,flight_count,sum_yr_1,seg_km_sum,last_flight_date,avg_discount
--FROM air;
- 数据探索:空值统计 统计SUM_YR_1、SEG_KM_SUM、AVG_DISCOUNT三个字段的空值记录数,保存到null_count表中
CREATE TABLE null_count AS SELECT * FROM
(SELECTCOUNT(*) AS sum_yr_1 FROM air WHERE sum_yr_1 IS NULL) sum_yr_1,(SELECTCOUNT(*) AS seg_km_sum FROM air WHERE seg_km_sum IS NULL) seg_km_sum,(SELECTCOUNT(*) AS avg_discount FROM air WHERE avg_discount IS NULL) avg_discount;
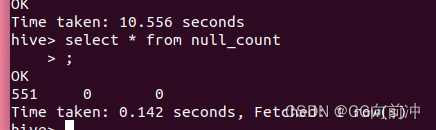
sum_yr_1 中有空值
- 数据探索:最小值统计 统计SUM_YR_1、SEG_KM_SUM、AVG_DISCOUNT三个字段的最小值,保存到min_count表中
CREATE TABLE min_count AS SELECTMIN(sum_yr_1) sum_yr_1,MIN(seg_km_sum) seg_km_sum,MIN(avg_discount) avg_discount
from air;
- 数据清洗 通过数据探索分析,我们发现数据中存在缺失值,但这类数据所占总数据的比例很小,所以直接舍弃。 定义清洗规则如下: 1.丢弃票价为空的记录 2.丢弃平均折扣率为0.0的记录 3.丢弃票价为0、平均折扣率不为0、总飞行公里数大于0的记录
CREATE TABLE sum_yr_1_not_null AS
SELECT * FROM air WHERE sum_yr_1 IS NOT NULL;//非空
CREATE TABLE avg_discount_not_0 AS
SELECT * FROM sum_yr_1_not_null WHERE avg_discount <>0;//不为0
CREATE TABLE seg_km_sum_not_0 AS
SELECT * FROM avg_discount_not_0
WHERE !(sum_yr_1=0 AND avg_discount<>0 AND seg_km_sum>0);//有效数据
- 数据规约 为了建立LRFMC模型,从清洗后的数据集中选择与指标相关的6个属性:LOAD_TIME、FFP_DATE、LAST_TO_END、FLIGHT_COUNT、SEG_KM_SUM、AVG_DISCOUNT
CREATE TABLE flfasl AS
SELECT ffp_date,load_time,flight_count,
avg_discount,seg_km_sum,last_to_end
FROM seg_km_sum_not_0;
- 数据变换 数据变换是将数据转换成“适当的”格式,以适应挖掘任务及算法的需要。 构造LRFMC 5个指标: L:会员入会时间距离观测窗口结束的月数 = 观测窗口的结束时间 - 入会时间 (单位: 月) R:客户最近一次乘坐公司飞机距观测窗口结束的月数 = 最后一次乘机时间至观测窗口末端时长(单位:月) F:客户再观测窗口内乘坐公司飞机的次数 = 观测窗口的飞行次数(单位: 次) M:客户再观测时间内在公司累计的飞行里程 = 观测窗口总飞行公里数(单位: 公里) C:客户在观测时间内乘坐舱位所对应的折扣系数的平均值 = 平均折扣率(单位: 无)
CREATE TABLE lrfmc AS SELECTMONTHS_BETWEEN(REPLACE(load_time,'/','-'),REPLACE(ffp_date,'/','-'))asl,//将时间中/改为-,并计算两个时间的相差月份
last_to_end asr, flight_count asf,
seg_km_sum asm, avg_discount ascFROM flfasl;
- 数据标准化 对5个指标数据分布进行分析,发现5个指标的取值范围数据差异较大,为了消除数量级数据带来的影响,需要对数据进行标准化处理: 标准化值 = x − min ( x ) max ( x ) − min ( x ) \text{标准化值} = \frac{{x - \text{min}(x)}}{{\text{max}(x) - \text{min}(x)}} 标准化值=max(x)−min(x)x−min(x)
SELECTMIN(l),MAX(l),MIN(r),MAX(r),MIN(f),MAX(f),MIN(m),MAX(m),MIN(c),MAX(c)FROM lrfmc;
CREATE TABLE norm_lrfmc AS SELECT
(l-min(l)over())/(max(l)over()-min(l)over())asl,(r-min(r)over())/(max(r)over()-min(r)over())asr,(f-min(f)over())/(max(f)over()-min(f)over())asf,(m-min(m)over())/(max(m)over()-min(m)over())asm,(c-min(c)over())/(max(c)over()-min(c)over())ascFROM lrfmc;

二、K-means聚类
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
聚类分析是一种典型的无监督学习, 用于对未知类别的样本进行划分,将它们按照一定的规则划分成若干个类族,把相似(距高相近)的样本聚在同一个类簇中, 把不相似的样本分为不同类簇,从而揭示样本之间内在的性质以及相互之间的联系规律。
K-means聚类是基于划分的聚类算法,计算样本点与类簇质心的距离,与类簇质心相近的样本点划分为同一类簇。k‐均值通过样本间的距离来衡量它们之间的相似度,两个样本距离越远,则相似度越低,否则相似度越高。
根据业务逻辑,确定将客户大致分为五类,将k=5,以及标准化后的数据,利用之前建立的Kmeans模型,可算出这五类客户群体的聚类中心
根据聚类中心结果,再结合航空公司的业务逻辑,得出结论
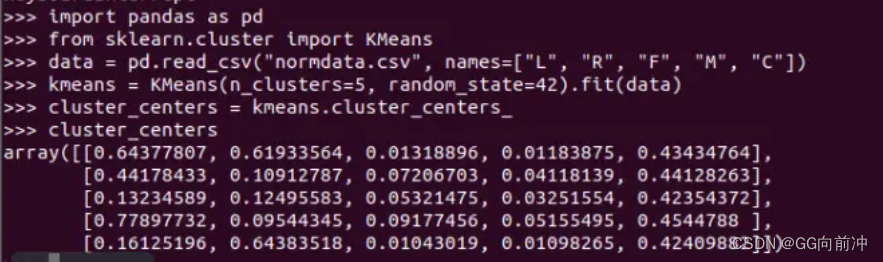
每种客户类别的特征如下:
重要保持客户:‘平均折扣率’(平均折扣率较高、仓位等级较高)、‘飞行总计’、'飞行总里程’较高,‘上一次飞行距今’(最近乘坐航班)低。应将资源优先投放到这类客户身上,进行差异化管理,提高客户的忠诚度和满意度
重要发展客户:'平均折扣率’较高,这类客户入会时长短、当前价值低、发展潜力大,应促使客户增加在本公司和合作伙伴处的消费
重要挽留客户:‘平均折扣率’、‘飞行总计’、'飞行总里程’较高,客户价值变化的不确定性高。应掌握客户最新信息、维持与客户的互动
一般和低价值客户:其他属性都低、'上一次飞行距今’较高。这类客户可能在打折促销时才会选择消费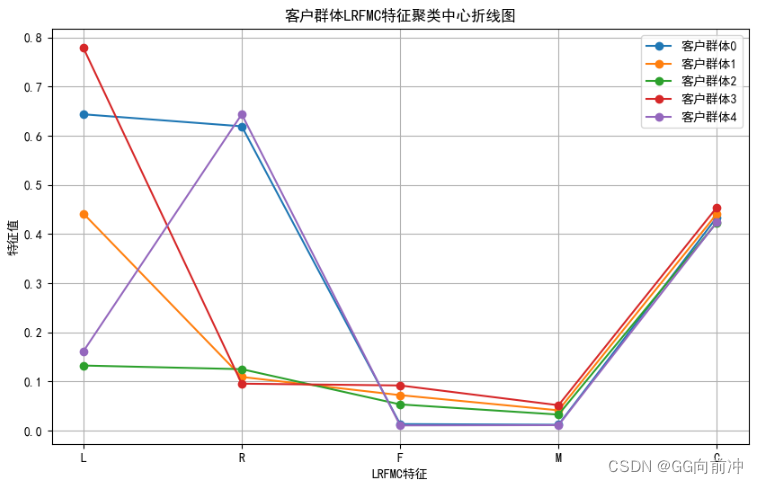
1.客户群体3入会最久,最近一次乘机时间最近,飞行次数最多,总飞行里程最长;
2. 客户群体1入会较短,最近一次乘机时间较近,飞行次数较多,总飞行里程较长;
3. 客户群体2入会最短,最近一次乘机时间较近,飞行次数较多,总飞行里程较长;
4. 客户群体4入会较短,最近一次乘机时间较远,飞行次数较少,总飞行里程较短;
5. 客户群体0入会较久,最近一次乘机时间较远,飞行次数较少,总飞行里程较短。
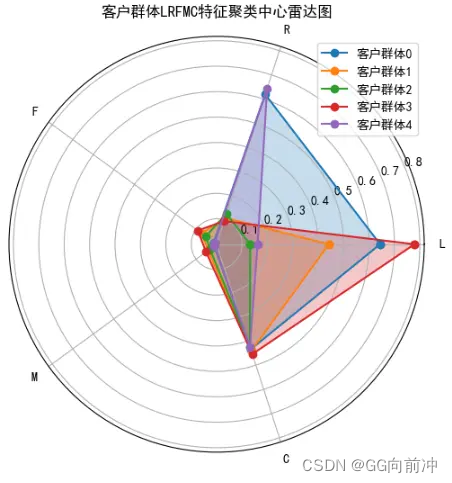
由雷达图可以看出:
客户群3的L、F、M、C属性值最大,R属性值最小;客户群4的R属性值最大,F、M属性值最小;客户群体2的L、C属性值最小。
得出:客户群体3需要重要保持;客户群体0可以重要发展;客户群体1可以重要挽留;客户群体2的群体价值较一般; 客户群体4是低价值的客户群体。
总结
本文主要以利用Hive对数据进行处理,Hive 是一个适用于处理大规模数据的开源数据仓库工具,提供了 SQL-Like 查询语言和良好的容错性,可以方便地进行数据查询和分析。通过对航空公司客户数据进行清洗分析,并通过K-means聚类将客户划分成几种不同的群体,根据不同群体中的各个特征指标,进一步得出客户价值,企业可以对不同的客户采用相关的策略,实现公司利益最大化。
版权归原作者 GG向前冲 所有, 如有侵权,请联系我们删除。